

4.3. Декодирование принимаемой кодовой комбинации.
Процедура исправления
ошибок в коде РС является более сложной,
чем в двоичном коде БЧХ, поскольку,
наряду с определением номера разряда,
в котором допущена ошибка, необходимо
определить значение ошибочно принятого
символа. При этом для определения
местоположения ошибок можно использовать
способы, применяемые для декодирования
кодов БЧХ, в том числе и рассмотренный
в лабораторной работе №2 алгебраический
метод, основанный на использовании
алгоритма Питерсона-Горенстейна-Цирлера
[4, 3]. Однако объём вычислений при его
реализации, связанный в основном с
необходимостью решения приведённого
в [3] матричного уравнения (11), или, что
практически эквивалентно, обращения
(т.е. нахождения обратной по отношению
к заданной) квадратной матрицы размером
![]() в случае применяемых на практике кодов
с высокой исправляющей способностью
оказывается чрезмерно большим (число
умножений пропорционально
в случае применяемых на практике кодов
с высокой исправляющей способностью
оказывается чрезмерно большим (число
умножений пропорционально
![]() ).
Для определения значений ошибок при
развитии этого метода понадобится
обращение ещё одной квадратной матрицы
такого же размера, что удваивает сложность
задачи. В связи с этим был разработан
способ быстрого декодирования кодов
РС, иллюстрируемый алгоритмом,
представленным на рис.1. Рассмотрим
сущность и методику выполнения основных
этапов данного алгоритма на конкретном
примере.
).
Для определения значений ошибок при
развитии этого метода понадобится
обращение ещё одной квадратной матрицы
такого же размера, что удваивает сложность
задачи. В связи с этим был разработан
способ быстрого декодирования кодов
РС, иллюстрируемый алгоритмом,
представленным на рис.1. Рассмотрим
сущность и методику выполнения основных
этапов данного алгоритма на конкретном
примере.
Предположим, что по каналу связи передавалcя двоичный блок кода
![]() ,
,
представляющий
собой двоичный эквивалент разрешённой
кодовой комбинации символов кода РС
(7,3), обеспечивающего
![]() при
,
которая в десятичном представлении
имеет вид
при
,
которая в десятичном представлении
имеет вид
![]() . (8)
. (8)
Допустим далее,
что вследствие воздействия помех блок
![]() превратился в принимаемую кодовую
комбинацию
превратился в принимаемую кодовую
комбинацию
![]() , (9)
, (9)
что в символах кода РС можно записать как
![]() , (10)
, (10)
т.е.
произошло две ошибки в 1-м и 5-м разрядах
(если считать первым − младший, крайний
справа разряд) блока кода РС при
фактическом наличии пяти ошибок в
принимаемой двоичной последовательности
(9). В данной ситуации полином ошибок
имеет вид:![]() (см. табл.П.2), поскольку
(см. табл.П.2), поскольку
![]() ,
где
,
где
![]() и
и
![]() − полиномы, соответствующие блокам
кода РС (10) и (8). (Отметим, что в реальной
ситуации, моделируемой в лабораторной
работе, переданная комбинация
− полиномы, соответствующие блокам
кода РС (10) и (8). (Отметим, что в реальной
ситуации, моделируемой в лабораторной
работе, переданная комбинация
![]() и вид многочлена ошибок неизвестны.)
и вид многочлена ошибок неизвестны.)
Первым этапом в
процедуре определения количества ошибок
и их исправления является процесс
вычисления синдрома принятой кодовой
комбинации (блок 1 алгоритма рис.1). Код
синдрома
![]() состоит из
состоит из
![]() элементов
элементов
![]() ,
которые рассчитываются в поле
,
которые рассчитываются в поле
![]() как
как
![]() , (11)
, (11)
где
![]()
![]() − (12)
− (12)
многочлен над
полем
,
соответствующий принимаемой кодовой
комбинации
![]() (10);
(10);
![]() −
значение
−
значение
![]() -го
разряда (
-го
разряда (![]() )
блока кода
;
−
примитивный элемент поля
.
)
блока кода
;
−
примитивный элемент поля
.
Вычисления по формуле (11) удобно выполнить, используя возможности, представляемые пакетом Matlab. Для этого необходимо:
1) в командном окне
системы Matlab
задать полином
![]() над полем
над полем
![]() ,
соответствующий принимаемой комбинации
.
В рассматриваемом нами случае приёма
(10) (при
)
это можно сделать с использованием
команды
,
соответствующий принимаемой комбинации
.
В рассматриваемом нами случае приёма
(10) (при
)
это можно сделать с использованием
команды
![]()
2)
задать вектор
![]() набора степеней примитивного элемента
набора степеней примитивного элемента
![]() поля
,
которые в соответствии с (11) представляют
собой значения аргументов
при вычислении
поля
,
которые в соответствии с (11) представляют
собой значения аргументов
при вычислении
![]() элементов синдрома
элементов синдрома
![]() .
При этом следует использовать десятичные
представления элементов
.
При этом следует использовать десятичные
представления элементов
![]() (см.
Табл. П.2 и П.3 из [3]). В рассматриваемом
примере (при
,
)
этот вектор задаётся командой
(см.
Табл. П.2 и П.3 из [3]). В рассматриваемом
примере (при
,
)
этот вектор задаётся командой
![]()
3)
с использованием команды
![]() ,
вычислить
вектор элементов синдрома. Команда
,
вычислить
вектор элементов синдрома. Команда
![]() ,
позволяет оценить значение многочлена
,
позволяет оценить значение многочлена
![]() в поле
,
которому принадлежат задаваемые в
качестве аргумента значения
в поле
,
которому принадлежат задаваемые в
качестве аргумента значения
![]() .
В нашем примере для расчёта вектора
элементов синдрома
.
В нашем примере для расчёта вектора
элементов синдрома
![]() в командном
окне системы Matlab
следует записать:
в командном
окне системы Matlab
следует записать:
![]() ;
;
Выполнение этой команды даёт следующий результат:
![]() ; (13)
; (13)
Каждое
из полученных чисел отражает собой
десятичное представление значения
соответствующего элемента синдрома в
поле
![]() ,
т.е.
,
т.е.
![]() .
Отметим, что, если принятая комбинация
не содержит ошибок, вектор синдрома
будет содержать одни нули. В этом можно
убедиться, вычислив синдром передаваемой
кодовой комбинации
(8), выполнив команды
.
Отметим, что, если принятая комбинация
не содержит ошибок, вектор синдрома
будет содержать одни нули. В этом можно
убедиться, вычислив синдром передаваемой
кодовой комбинации
(8), выполнив команды
![]()
![]() .
.
Первая
из этих команд позволяет задать
полином
![]() над полем
над полем
![]() ,
соответствующий передаваемой комбинации
(8) а вторая
− оценить значение этого многочлена
при заданном векторе входных аргументов
,
соответствующий передаваемой комбинации
(8) а вторая
− оценить значение этого многочлена
при заданном векторе входных аргументов
![]() .
В результате этого оценивания получается
нулевой синдром
.
В результате этого оценивания получается
нулевой синдром
![]() ,
т.е.
,
т.е.
![]() =0.
=0.
Следующим
этапом процедуры декодирования является
определения полинома локаторов ошибок
![]() (блок 2 алгоритма на рис. 1), корнями
которого являются величины
(блок 2 алгоритма на рис. 1), корнями
которого являются величины
![]() ,
обратные значениям локаторов ошибок
,
обратные значениям локаторов ошибок
![]() ,
определяющих позиции расположения
ошибок в полиноме
,
определяющих позиции расположения
ошибок в полиноме
![]() .
Ввиду отмеченных выше недостатков
рассмотреннного в лабораторной работе
2 алгоритма
Питерсона-Горенстейна-Цирлера
при быстром декодировании кодов РС эта
задача решается на основе алгоритма
Берлекэмпа-Месси
(блок 2 на рис.1). Идея
этого алгоритма базируется на том, что
каждая строка матричного
уравнения (11)
из [3] выражает значение последующего
элемента синдрома через
предшествующих (например, первая строка
выражает
.
Ввиду отмеченных выше недостатков
рассмотреннного в лабораторной работе
2 алгоритма
Питерсона-Горенстейна-Цирлера
при быстром декодировании кодов РС эта
задача решается на основе алгоритма
Берлекэмпа-Месси
(блок 2 на рис.1). Идея
этого алгоритма базируется на том, что
каждая строка матричного
уравнения (11)
из [3] выражает значение последующего
элемента синдрома через
предшествующих (например, первая строка
выражает
![]() через
через
![]() ,
вторая −
,
вторая −
![]() через
через
![]() и т.д.). Этот последовательный процесс
описывается выражением
и т.д.). Этот последовательный процесс
описывается выражением
![]() . (14)
. (14)
Отметим, что, в
случае, когда в исследуемом блоке кода
имеет место
![]() ошибок, соотношение
(14) принимает вид:
ошибок, соотношение
(14) принимает вид:
![]() . (15)
. (15)
Выражение (15) можно
трактовать как разностное уравнение
рекурсивного цифрового фильтра,
представляющего собой регистр сдвига
неизвестной заранее длины
![]() с коэффициентами
с коэффициентами
![]() в ветвях обратной связи. Таким образом,
задача определения коэффициентов
полинома локаторов
сводится к построению регистра
сдвига минимальной длины с обратными
связями, отображающими
,
порождающего первые 2t
членов синдромного многочлена
в ветвях обратной связи. Таким образом,
задача определения коэффициентов
полинома локаторов
сводится к построению регистра
сдвига минимальной длины с обратными
связями, отображающими
,
порождающего первые 2t
членов синдромного многочлена
![]() .
.
Не вдаваясь в
теоретическое обоснование алгоритма
Берлекэмпа-Месси,
приводимое, например, в [4], поясним его
основное содержание
[4,5].
Вначале находят самый короткий регистр
сдвига, генерирующий
![]() .
Далее проверяют, порождает ли этот
регистр также
.
Далее проверяют, порождает ли этот
регистр также
![]() .
Если порождает, то данный регистр
по-прежнему остается наилучшим решением,
и нужно проверить, порождает ли он
следующие символы синдромного многочлена.
На каком-то шаге очередной символ уже
не будет генерироваться. В этот момент
нужно изменить регистр таким образом,
чтобы он:
.
Если порождает, то данный регистр
по-прежнему остается наилучшим решением,
и нужно проверить, порождает ли он
следующие символы синдромного многочлена.
На каком-то шаге очередной символ уже
не будет генерироваться. В этот момент
нужно изменить регистр таким образом,
чтобы он:
1) правильно предсказывал следующий символ,
2) не менял предсказание предыдущих символов,
3) увеличивал длину регистра на минимально возможную величину.
Процесс вычисления продолжается до тех пор, пока не будут порождены первые 2t символов синдрома.
Алгоритм
строится на основе итеративной процедуры.
При каждой итерации должны сохраняться
как многочлен связей
![]() ,
так и добавка
,
так и добавка
![]() .
Для каждого новой составляющей
.
Для каждого новой составляющей
![]() предусматривается проверка правильности
предсказания этого символа текущим
многочленом связи. Если предсказание
правильно, то многочлен связей не
меняется, а добавка умножается на x.
Если предсказание неправильно (ошибка
предусматривается проверка правильности
предсказания этого символа текущим
многочленом связи. Если предсказание
правильно, то многочлен связей не
меняется, а добавка умножается на x.
Если предсказание неправильно (ошибка
![]() ),
то изменяют текущий многочлен связей,
прибавляя к нему добавку. После этого
проверяют, увеличилась ли длина регистра.
Если она не увеличилась, то текущую
добавку оставляют. Если длина регистра
возрастает, то лучшей добавкой считают
предыдущий многочлен связей. Для
недвоичных полей добавку нормируют,
чтобы ошибка стала равной 1. Далее при
каждом исправлении эту нормализованную
добавку умножают на значение текущей
ошибки.
),
то изменяют текущий многочлен связей,
прибавляя к нему добавку. После этого
проверяют, увеличилась ли длина регистра.
Если она не увеличилась, то текущую
добавку оставляют. Если длина регистра
возрастает, то лучшей добавкой считают
предыдущий многочлен связей. Для
недвоичных полей добавку нормируют,
чтобы ошибка стала равной 1. Далее при
каждом исправлении эту нормализованную
добавку умножают на значение текущей
ошибки.
Рассмотренный
алгоритм изображён на рис.2 (блоки 1 −
7). По найденному с его применением
полиному локаторов ошибок, как отмечалось
выше, можно определить их местонахождение
в принятой комбинации. Для определения
значений ошибок при быстром декодировании
используется алгоритм Форни. Для его
реализации вначале необходимо найти
многочлен значений ошибок
![]() (блок
3 на рис.1), определяемый выражением:
(блок
3 на рис.1), определяемый выражением:
![]() . (16)
. (16)
Вместе
с тем, как показано в [5],
вычисления по формуле (16) можно заменить
дополнением к рассмотренному алгоритму
Берлекэмпа – Месси, позволяющим
одновременно с нахождением значения
многочлена локаторов ошибок
находить
многочлен значений ошибок
.
Это
дополнение на рис. 2 представлено блоками
8 −
10. Его идея
заключается в том, что, поскольку
находится
умножением
на
![]() ,
можно задать последовательность
многочленов
,
можно задать последовательность
многочленов
![]() ,
удовлетворяющих тем же рекуррентным
соотношениям, что и многочлены
,
удовлетворяющих тем же рекуррентным
соотношениям, что и многочлены
![]() .
Обозначая добавку при нахождении
через
.
Обозначая добавку при нахождении
через
![]() ,
имеем:
,
имеем:

что и
реализуется блоками 8
−
10 алгоритма рис.2 при начальных условиях
![]() и
и
![]() .
Тот факт, что в (16) умножение осуществляется
по
.
Тот факт, что в (16) умножение осуществляется
по
![]() ,
в алгоритме учитывается соответствующим
диапазоном изменения переменной цикла
,
в алгоритме учитывается соответствующим
диапазоном изменения переменной цикла
![]() ,
задающей число шагов итерации.
,
задающей число шагов итерации.
Рассмотрим, как реализуются вычисления, предписываемые алгоритмом рис. 2, применительно к нашему примеру.
1.
В соответствии с блоком 1 алгоритма
задаёмся начальными условиями:
![]()
![]()
![]()
![]()
![]()
![]() .
.
2.
Первая итерация:![]() .
.
Приведённая
в блоке 2 алгоритма рис.2 формула для
вычисления ошибки
![]() предполагает проведение вычислений по
правилам поля
предполагает проведение вычислений по
правилам поля
![]() (в рассматриваемом примере −
),
причём использованное в ней обозначение
(в рассматриваемом примере −
),
причём использованное в ней обозначение
![]() соответствует
соответствует
![]() -му
коэффициенту полинома локаторов, который
в конечном итоге имеет вид:
-му
коэффициенту полинома локаторов, который
в конечном итоге имеет вид:
![]() ;
значения
были вычислены ранее (см. (13)). Итак, при
,
кода в соответствии с начальным условием
;
значения
были вычислены ранее (см. (13)). Итак, при
,
кода в соответствии с начальным условием
![]() ,
имеем:
,
имеем:
![]() .
.
Правила вычислений в поле изложены в [2], вместе с тем их можно выполнить в системе Matlab, записав:
![]() ;
;
![]() ;
;
![]()
В
результате выполнения этих команд в
командном окне появится результат:
![]() .
.
Условие
![]() не выполняется, поэтому переходим к
блоку 4 алгоритма и записываем:
не выполняется, поэтому переходим к
блоку 4 алгоритма и записываем:
![]() .
.
Условие
![]() выполняется (
выполняется (![]() и
и
![]() ),
поэтому переходим к выполнению блока
6 и вычисляем:
),
поэтому переходим к выполнению блока
6 и вычисляем:
![]() .
.
При
выполнении этой операции вычисления
производятся по правилам поля
.
В системе Matlab,
учитывая, что на данной итерации
![]() это можно сделать с помощью команды
это можно сделать с помощью команды
![]() .
.
В
результате её выполнения получаем
![]() .
Далее в соответствии с предписаниями
блока 6 алгоритма имеем:
.
Далее в соответствии с предписаниями
блока 6 алгоритма имеем:
![]() ;
;
![]() .
.
После этого корректируем многочлен значений ошибок (блок 8 алгоритма):
![]() .
.
Условие
![]() не выполняется (
не выполняется (![]() ;
;![]() ),
поэтому вычисляем
),
поэтому вычисляем
![]() как (блок 10)
как (блок 10)
![]() .
.
Вычисления,
предписываемые блоком 10, также нужно
производить по правилам поля
,
однако умножение на ноль в любом поле
даёт ноль. Поскольку условие
![]() не выполняется, переходим к следующей
итерации.
не выполняется, переходим к следующей
итерации.
3.
Вторая итерация:![]() .
.
![]() .
.
Для выполнения этих вычислений по правилам поля в системе Matlab нужно записать следующие команды:
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
В результате их
выполнения получаем:
![]() .
.
Условие не выполняется, поэтому переходим к блоку 4 алгоритма и вычисляем (по правилам поля ):
![]() .
.
Условие
не выполняется (![]() и
и
![]() ),
поэтому переходим к последовательному
выполнению блоков 5 и 7 и записываем:
),
поэтому переходим к последовательному
выполнению блоков 5 и 7 и записываем:
![]()
![]() .
.
Далее корректируем многочлен значений ошибок (блок 8 алгоритма):
![]() .
.
Условие
выполняется (![]() ;
;![]() ),
поэтому вычисляем
),
поэтому вычисляем
![]() как (блок 9)
как (блок 9)
![]() .
.
Поскольку условие не выполняется, переходим к следующей итерации.
4.
Третья итерация:![]() .
.
![]() .
.
Условие не выполняется, поэтому переходим к блоку 4 алгоритма и вычисляем:
![]() .
.
Условие
выполняется (
и
![]() ),
поэтому переходим к выполнению блока
6 и получаем:
),
поэтому переходим к выполнению блока
6 и получаем:
![]() .
.
![]() ;
;
![]() .
.
После этого корректируем многочлен значений ошибок (блок 8 алгоритма):
![]() .
.
Условие
не выполняется (![]() ;
;![]() ),
поэтому вычисляем
как (блок 10)
),
поэтому вычисляем
как (блок 10)
![]() .
.
Поскольку условие не выполняется, переходим к следующей итерации.
5.
Четвёртая итерация:![]() .
.
![]() .
.
В системе Matlab эти вычисления можно выполнить следующим образом:
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Условие не выполняется, поэтому переходим к блоку 4 алгоритма и вычисляем:
![]() .
.
Условие
не выполняется (![]() и
и
![]() ),
поэтому переходим к последовательному
выполнению блоков 5 и 7 и записываем:
),
поэтому переходим к последовательному
выполнению блоков 5 и 7 и записываем:
![]() ;
;
![]() .
.
Далее корректируем многочлен значений ошибок (блок 8 алгоритма):
![]() .
.
Условие
выполняется (![]() ;
;![]() ),
поэтому вычисляем
),
поэтому вычисляем
![]() как (блок 9)
как (блок 9)
![]() .
.
Поскольку условие выполняется, выполнение алгоритма на этом заканчивается.
Таким образом, полином локаторов ошибок имеет вид:
![]() , (17)
, (17)
а многочлен значений ошибок −
![]() . (18)
. (18)
В корректности полученных результатов можно убедиться, вычислив по формуле (16). С использованием системы Matlab это можно сделать с помощью команд:
![]()
![]()
![]()
![]()
Возвращаемый
при этом вектор
![]() соответствует вычисленному полиному
.
соответствует вычисленному полиному
.
В
рассматриваемом примере в принимаемой
комбинации
(10) присутствуют две ошибки. В полученном
результате об этом говорит тот факт,
что степень полинома
равна 2.
В том случае, если число ошибок
![]() ,
она была бы на 1 меньше. Таким образом,
о числе ошибок
(при условии
,
она была бы на 1 меньше. Таким образом,
о числе ошибок
(при условии
![]() )
можно судить по степени полученного
многочленов локаторов.
)
можно судить по степени полученного
многочленов локаторов.
Следующим
этапом процедуры быстрого декодирования
является определение локаторов ошибок
![]() и
и
![]() (блок 4 алгоритма рис. 1). Для этого, так
же как и в лабораторной работе 2, сначала
определим обратные им величины
(блок 4 алгоритма рис. 1). Для этого, так
же как и в лабораторной работе 2, сначала
определим обратные им величины
![]() и
и
![]() ,
являющиеся корнями полинома
.
В нашем случае в Matlab
эту операцию можно выполнить с помощью
команд:
,
являющиеся корнями полинома
.
В нашем случае в Matlab
эту операцию можно выполнить с помощью
команд:
![]() .
.
В
результате их выполнения получаем:![]() ,
что соответствует
,
что соответствует
![]() Для нахождения значений локаторов
ошибок
и
необходимо вычислить величины, обратные
значениям найденных корней, т.е.
Для нахождения значений локаторов
ошибок
и
необходимо вычислить величины, обратные
значениям найденных корней, т.е.
![]() .
Это нетрудно сделать, воспользовавшись
данными табл. П.2, или с помощью команды
Matlab
.
Это нетрудно сделать, воспользовавшись
данными табл. П.2, или с помощью команды
Matlab
![]() .
.
В
результате её выполнения выводятся
значения
![]() ,
которые в степенном представлении (см.
табл.П.2) соответствуют значениям
,
которые в степенном представлении (см.
табл.П.2) соответствуют значениям
![]() и
и
![]() .
Это указывает на то, что ошибки в кодовой
комбинации
(10) находится на позициях, соответствующих
.
Это указывает на то, что ошибки в кодовой
комбинации
(10) находится на позициях, соответствующих
![]() и
и
![]() в многочлене
в многочлене
![]() (12).
(12).
Для
вычисления значений ошибок
![]() (блок 5 алгоритма рис. 1) воспользуемся
алгоритмом Форни [4], по которому
(блок 5 алгоритма рис. 1) воспользуемся
алгоритмом Форни [4], по которому
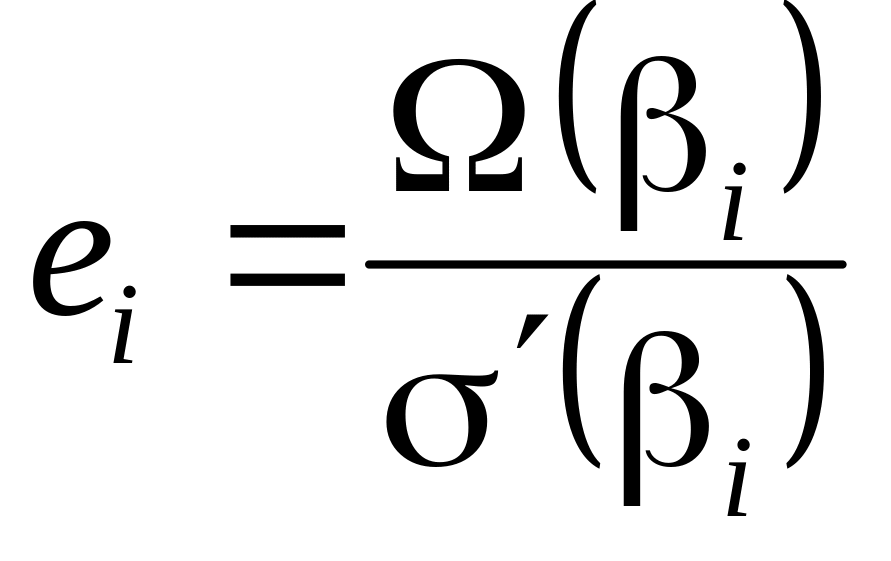 , (19)
, (19)
где
![]() − производная от полинома локаторов
.
Вычисление производной от многочлена
− производная от полинома локаторов
.
Вычисление производной от многочлена
![]() над полем
над полем
![]() осуществляется по следующему правилу:
осуществляется по следующему правилу:
![]() ,
,
причём выражение
![]() для каждого
для каждого
![]() вычисляется в обычной арифметике, а
результат этого вычисления интерпретируется
как элемент поля
,
и далее произведение этого элемента на
соответствующий коэффициент
вычисляется в обычной арифметике, а
результат этого вычисления интерпретируется
как элемент поля
,
и далее произведение этого элемента на
соответствующий коэффициент
![]() ,
также являющийся элементом поля
,
определяется по правилам умножения
поля [6].
,
также являющийся элементом поля
,
определяется по правилам умножения
поля [6].
Применяя
данное правило к найденному полиному
локаторов (17) над полем
![]() ,
находим, что
,
находим, что
![]() .
Подставляя этот результат в (19) и учитывая
(18), с использованием арифметики поля
получаем:
.
Подставляя этот результат в (19) и учитывая
(18), с использованием арифметики поля
получаем:
 ;
;
 .
.
В Matlab эти вычисления можно выполнить с использованием команд:
![]() ;
;
![]() ;
;
![]() .
.
После
их выполнения получаем:![]() .
.
Найденные
значения
;
;
![]() и
и
![]() позволяют записать вычисленный полином
ошибок в виде
позволяют записать вычисленный полином
ошибок в виде
![]() ,
,
после
чего процедура исправления ошибок (блок
6 алгоритма рис. 1) сводится к сложению
![]() с
с
![]() (12), выполняемого по правилам поля
.
Это сложение даёт:
(12), выполняемого по правилам поля
.
Это сложение даёт:
![]()
![]()
![]() ,
,
что соответствует вектору переданной кодовой комбинации (8).
4.4. Краткое описание алгоритма моделирующей программы и методики работы с ней.
Блок-схема
укрупненного алгоритма моделирующей
программы представлена на рис.1.1, она
включает в себя 10 блоков. В блоке 1
осуществляется ввод определяющих режим
моделирования данных. К их числу
относятся: значение вероятности ошибки
в дискретном канале, а также исправляющая
способность исследуемого кода
и число бит
![]() ,
содержащихся в одном символе кода РС.
,
содержащихся в одном символе кода РС.
В блоке 2 по заданным
и
определяются общее число недвоичных
символов в блоке кода
и число информационных символов
,
а также производится формирование
последовательности передаваемых
равновер оятных
недвоичных сообщений (символов кода РС
с объёмом алфавита
оятных
недвоичных сообщений (символов кода РС
с объёмом алфавита
![]() ),
разбиение её на блоки, содержащие по
символов, и кодирование их исследуемым
кодом. В блоке 3 производится преобразование
сформированной (
),
разбиение её на блоки, содержащие по
символов, и кодирование их исследуемым
кодом. В блоке 3 производится преобразование
сформированной (![]() )
и закодированной (
)
и закодированной (![]() )
последовательностей
)
последовательностей
![]() -ичных
знаков в двоичные (соответственно
-ичных
знаков в двоичные (соответственно
![]() и
и
![]() ).
Последовательности
и
необходимы для определения оценок
вероятностей ошибок в канале и системе
с кодеком, осуществляемого по двоичным
символам; кроме того, сигнал
подаётся далее на вход моделируемого
двоичного канала. Посредством блоков
4, 5 и 6 осуществляется моделирование
дискретного симметричного канала без
памяти, включающего в себя передатчик
(блок 4) и приёмник (блок 6) модема с
фазоманипулированным (ФМ) сигналом и
непрерывный канал (блок 5), имитирующий
линию связи. В блоке 4 последовательность
двоичных символов
преобразуется в отсчёты соответствующего
ей фазоманипулированного (ФМ) сигнала,
передаваемого в канал связи. В качестве
модели непрерывного канала в данной
работе используется гауссов канал (т.е.
канал с аддитивным гауссовским шумом).
При этом соотношение «сигнал-шум» в
непрерывном канале
).
Последовательности
и
необходимы для определения оценок
вероятностей ошибок в канале и системе
с кодеком, осуществляемого по двоичным
символам; кроме того, сигнал
подаётся далее на вход моделируемого
двоичного канала. Посредством блоков
4, 5 и 6 осуществляется моделирование
дискретного симметричного канала без
памяти, включающего в себя передатчик
(блок 4) и приёмник (блок 6) модема с
фазоманипулированным (ФМ) сигналом и
непрерывный канал (блок 5), имитирующий
линию связи. В блоке 4 последовательность
двоичных символов
преобразуется в отсчёты соответствующего
ей фазоманипулированного (ФМ) сигнала,
передаваемого в канал связи. В качестве
модели непрерывного канала в данной
работе используется гауссов канал (т.е.
канал с аддитивным гауссовским шумом).
При этом соотношение «сигнал-шум» в
непрерывном канале
![]() ,
где
,
где
![]() − энергия одной посылки сигнала;
− энергия одной посылки сигнала;
![]() − односторонний энергетический спектр
шума, выбирается из условия обеспечения
заданной вероятности ошибки
в дискретном симметричном канале с ФМ,
образуемом блоками 3, 4 и 5 рассматриваемой
модели, на основе известного соотношения:
− односторонний энергетический спектр
шума, выбирается из условия обеспечения
заданной вероятности ошибки
в дискретном симметричном канале с ФМ,
образуемом блоками 3, 4 и 5 рассматриваемой
модели, на основе известного соотношения:
![]() ,
где
,
где
![]() − интеграл вероятностей. В блоке 5
осуществляется измерение энергии
модулированного сигнала, соответствующего
передаче одного элементарного сообщения,
а затем формируются отсчеты дискретного
белого гауссовского шума, энергетический
спектр которого при измеренном значении
обеспечивает заданное на моделирование
отношение «сигнал-шум»
− интеграл вероятностей. В блоке 5
осуществляется измерение энергии
модулированного сигнала, соответствующего
передаче одного элементарного сообщения,
а затем формируются отсчеты дискретного
белого гауссовского шума, энергетический
спектр которого при измеренном значении
обеспечивает заданное на моделирование
отношение «сигнал-шум»
![]() .
Отсчеты этого шума складываются с
отсчетами передаваемого сигнала,
формируя тем самым выходной сигнал
непрерывного канала.
.
Отсчеты этого шума складываются с
отсчетами передаваемого сигнала,
формируя тем самым выходной сигнал
непрерывного канала.
В блоке 6 производится моделирование оптимального приемника ФМ сигнала, осуществляющего его демодуляцию.
В блоке 7 полученные в результате демодуляции оценки принимаемых символов сравниваются с символами последовательности , сформированными на выходе блока 3; при несовпадении фиксируются ошибки. Отношение количества обнаруженных ошибок к общему числу переданных символов кода и представляет собой оценку вероятности ошибки в дискретном канале.
В блоке 8 полученные после демодуляции двоичные кодовые символы преобразуются в последовательность -ичных знаков, что необходимо для выполнения операции декодирования, осуществляемой в блоке 9. Результат декодирования в этом же блоке преобразуется в двоичные символы, которые в блоке 10 сравниваются с с символами последовательности , сформированными на выходе блока 3. При несовпадении символов фиксируются ошибки. Отношение числа ошибок к общему количеству знаков последовательности (которое меньше числа переданных символов, содержащихся в , поскольку отражает только информационные символы передаваемых кодовых комбинаций кода РС) и представляет собой оценку вероятности ошибки в системе с кодеком.
Для запуска моделирующей программы необходимо в командном окне системы Matlab набрать название программы lab_rab_3 и нажать клавишу Enter. Также программу можно запустить щелчком левой кнопки мыши по кнопке Run (зелёный треугольник) на панели инструментов окна Editor системы Matlab (при условии, что в этом окне активирована программа lab_rab_3). После запуска программы в командном окне появляется сообщение: “Введите значение вероятности ошибки в канале без кодека p=”. При его получении нужно ввести (т.е. набрать в командном окне) значение в соответствии с вариантом задания и нажать клавишу Enter. При этом в качестве символа, разделяющего целую и дробную части числа при его десятичном представлении следует использовать не запятую, а точку. Получив два последующих сообщения “Введите значение исправляющей спосбности t=” и “Введите число бит, содержащихся в одном символе кода m=”нужно аналогичным образом ввести запрашиваемые программой данные. После этого начинается выполнение программы. Этапы её выполнения индицируются сообщениями, выводимыми на экран (в командном окне). По окончании выполнения программы в командном окне выводятся значения (p_kan) и (p_kod), являющиеся результатами компьютерного эксперимента.