

Контент-анализ как метод исследования
Контент-анализ (от англ, contens — содержание) — специальный достаточно строгий метод качественно-количественного анализа содержания документов в целях выявления или измерения социальных фактов и тенденций, отраженных этими документами. Особенность его состоит в том, что он изучает документы в их социальном контексте.
Контент-анализ может использоваться в качестве основного метода исследования (например, в исследовании социальной направленности газеты); параллельного, т.е. в сочетании с другими методами (например, в исследовании эффективности функционирования средств массовой информации); вспомогательного или контрольного (например, при классификации ответов на открытые вопросы анкет).
Не все документы могут выступить объектом контент-анализа. Необходимо, чтобы исследуемое содержание позволило задать однозначное правило для надежного фиксирования нужных характеристик (принцип формализации), а также чтобы интересующие исследователя элементы содержания встречались с достаточной частотой (принцип статистической значимости). Чаще всего в качестве объектов исследований посредством контент-анализа выступают сообщения печати, радио, телевидения, массовой устной агитации и пропаганды, протоколы собраний, письма, приказы, распоряжения и т.д., а также данные свободных интервью и открытые вопросы анкет.
Существуют три основных направления применения контент-анализа:
а) выявление того, что существовало до текста и что тем или иным образом получило в нем отражение (текст как индикатор определенных сторон изучаемого объекта — окружающей действительности, автора или адресата);
б) определение того, что существует только в тексте как таковом (различные характеристики формы — язык, структура и жанр сообщения, ритм и тон речи);
в) выявление того, что будет существовать после текста, т.е. после его восприятия адресатом (оценка различных эффектов воздействия).
В разработке и практическом применении контент-анализа выделяют несколько стадий. После того, как сформулированы тема, задачи и гипотезы исследования, определяются категории анализа, т.е. наиболее общие, ключевые понятия, соответствующие исследовательским задачам. Система категорий играет роль вопросов в анкете и указывает, какие ответы должны быть найдены в тексте. В практике советских контент-аналитических исследований в свое время сложилась довольно устойчивая система категорий, среди которых можно назвать такие, как знак, цели, ценности, тема, герой, автор, жанр и др. Все более широко распространяется контент-анализ сообщений средств массовой информации, основанный на парадигматическом подходе, в соответствии с которым изучаемые признаки текстов (содержание проблемы, причины ее возникновения, проблемообразующий субъект, степень напряженности проблемы, пути ее решения и др.) рассматриваются как определенным образом организованная структура. Категории контент-анализа должны быть исчерпывающими (т.е. охватывать все части содержания, определяемые задачами данного исследования); взаимоисключающими (одни и те же части не должны принадлежать различным категориям); надежными (т.е. между кодировщиками не должно быть разногласий по поводу того, какие части содержания следует относить к той или иной категории); уместными (т.е. соответствовать поставленной задаче и исследуемому содержанию).
При выборе категорий необходимо избегать двух крайностей: выбора слишком многочисленных и дробных категорий, почти повторяющих текст, и выбора слишком крупных категорий, т.к. это может привести к упрощенному, поверхностному анализу. Иногда же необходимо принимать во внимание и отсутствующие элементы текста, которые могут быть значимыми.
После того, как категории сформулированы, необходимо выбрать соответствующую единицу анализа — лингвистическую единицу речи или элемент содержания, служащие в тексте индикатором интересующих исследователя явлений. Сложные виды контент-анализа обычно оперируют не одной, а одновременно несколькими единицами анализа.
Единицы анализа, взятые изолированно, могут быть не всегда правильно истолкованы, поэтому они рассматриваются на фоне более широких лингвистических или содержательных структур, указывающих на характер членения текста, в пределах которого идентифицируется присутствие или отсутствие единиц анализа — контекстуальных единиц. Например, для единицы анализа «слово» контекстуальная единица — «предложение».
Наконец необходимо установить единицу счета — количественную меру взаимосвязи текстовых и внетекстовых явлений. Наиболее употребительны такие единицы счета, как время-пространство (число строк, площадь в квадратных сантиметрах, минуты, время вещания и т.п), появление признаков в тексте, частота их появления (интенсивность).
Важен выбор необходимых источников, подвергаемых контент-анализу. Проблема выборки содержит в себе выбор источника, числа сообщений, даты сообщения и исследуемого содержания. Все эти параметры выборки определяются задачами и масштабами исследования. Чаще всего контент-анализ проводится на годичной выборке: если это изучение протоколов собраний, то достаточно 12 протоколов (по числу месяцев), если изучение сообщений средств массовой информации — 12-16 номеров газеты или теле- радиодней. Обычно выборка сообщений средств массовой информации составляет 200-600 текстов.
Необходимым условием контентного исследования является разработка таблицы контент-анализа — основного рабочего документа, с помощью которого оно проводится. Тип таблицы определяется этапом исследования. Так, разрабатывая категориальный аппарат, аналитик составляет таблицу, представляющую собой систему скоординированных и субординированных категорий анализа. Такая таблица внешне напоминает анкету: каждая категория (вопрос) предполагает ряд признаков (ответов), по которым квантифицируется содержание текста. Таблица-анкета может быть достаточно объемной.
Для регистрации единиц анализа составляется другая таблица — кодировальная матрица:
Если объем выборки достаточно велик (свыше 100 единиц), то кодировщик, как правило, работает с тетрадью матричных листов. Если выборка сравнительно невелика (до 100 единиц), то можно проводить двумерный или даже многомерный анализ. В этом случае для каждого текста должна быть своя кодировальная матрица. Однако эта работа очень трудоемка и кропотлива, поэтому при больших объемах выборки сопоставление интересующих исследователя признаков осуществляется на компьютере.
Иногда таблица может быть необходимой и на этапе количественной обработки данных. Например, при использовании анализа случайностей, разработанного американским социальным психологом Ч. Осгудом, строится т.наз. матрица случайностей:
С помощью такой матрицы выявляются меры случайности совпадения каждой классификационной единицы со всеми остальными. Например, единица А встречается в 30% анализируемых текстов (Р = 0,3), а единица В — в 50% текстов (Р = 0,5), тогда ожидаемая частота совместного появления этих единиц будет равна: РАВ = РА • Рв=0,3 • 0,5 = 0,15. В действительности же признаки А и В совместно встретились лишь в 5% текстов АВ = 0,05. Сравнивая ожидаемые и реальные совпадения признаков, можно определить, какие фактические зависимости оказались не случайными (напр., из приведенной выше таблицы видно, что совместное появление единиц А и В — случайное, т.к. реальное совпадение меньше ожидаемого, а единиц В и С — не случайное, т.е. реальное совпадение выше ожидаемого). Цели применения данной матрицы могут быть различными: проследить случайность-неслучайность совпадения признаков для проверки гипотезы, отметить устойчивые-неустойчивые парные сочетания признаков, что может оказаться значимым для характеристики деятельности отправителя информации, и т.д.
Важным условием К.-А. является разработка инструкции кодировщику — системы правил и пояснений для того, кто будет собирать эмпирическую информацию, кодируя (регистрируя) заданные единицы анализа. В инструкции точно и однозначно излагается алгоритм действий кодировщика, даются операциональное определение категорий и единиц анализа, правила их кодирования, приводятся конкретные примеры из текстов, являющихся объектом исследования, оговаривается, как следует поступать в спорных случаях, и т.д.
Процедура подсчета при количественном контент-анализе. в общем виде аналогична стандартным приемам классификация по выделенным группировкам ранжирования и измерения ассоциаций. Существуют также специальные процедуры подсчета применительно к контент-анализу, напр., формула коэффициента Яниса (с), предназначенного для вычисления соотношения положительных и отрицательных (относительно избранной позиции) оценок, суждений, аргументов. В случае, когда число положительных оценок превышает число отрицательных, коэффициент Яниса подсчитывается по формуле
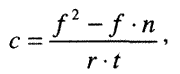
где;- число положительных оценок; п — число отрицательных оценок; г — объем содержания текста, имеющего прямое отношение к научаемой проблеме; t — общий объем анализируемого текста.
В случае, когда число положительных оценок меньше, чем отрицательных, коэффициент Яниса находится по формуле
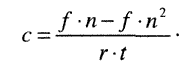
Есть и более простые способы измерения.
Удельный вес той или иной категории
можно вычислить с помощью формулы
![]()
оявление контент-анализа было реакцией на возникшую потребность в создании объективных методов анализа текстов, результаты которых не зависели бы ни от личности исследователя, ни от того, где и когда эти исследования проводятся. Т.е. требовалось найти такие методы оценки текстов, которые не вызывали бы разногласий между исследователями и были воспроизводимы в любое время и в любом месте.
Существует целый ряд заблуждений относительно того, что же такое контент-анализ. Очень часто этот термин дословно переводят на русский язык как "анализ содержания" и считают, что все поняли, что это просто содержательный анализ текстов, их истолкование. В других случаях контент-анализ путают с реферированием текстов или с поиском информации в текстовых базах данных.
Никто не возражает против содержательного анализа текстов, их истолкования и пр. Просто не следует называть это контент-анализом, который изначально он задумывался именно как строгий метод оценки текстов.
Одним из определений контент-анализа является следующее: "Контент-анализ - это методика выявления частоты появления в тексте определенных интересующих исследователя характеристик, которая позволяет ему делать некоторые выводы относительно намерений создателя этого текста или возможных реакций адресата."(1)
Когда в качестве наиболее объективной оценки текстов избрали частоту появления в нем различных характеристик, казалось, что оптимальное решение найдено. Вскоре поняли, что не все так просто.
Если попросить двух экспертов подсчитать, сколько раз, например, было упомянуто имя президента в конкретном номере конкретной газеты, то скорее всего их ответы совпадут. Причиной расхождений может стать лишь невнимательность при подсчете. Но вот если попросить этих же экспертов подсчитать в той же газете количество слов с негативной окраской, то результаты будут явно отличаться. Более того, один и тот же эксперт на одном и том же материале в разные моменты времени даст разные ответы. Причина кроется в неоднозначности критериев. Эта проблема стоит настолько остро, что она даже отдельно изучается. Существуют специальные методы оценки надежности результатов ручного контент-анализа, когда можно доверять экспертам, а когда нельзя.
Отдельный вопрос - трудоемкость контент-анализа. Имеется интересная методика, позволяющая по тексту объемом от 80 до 150 слов получить достаточно полный психологический портрет автора. Анализируются в основном грамматические характеристики. На ручной анализ одного текста по той же методике уходит от 4 до 6 часов времени.
Гораздо хуже обстоят дела, когда приходится оценивать большие массивы текстов, поступающих непрерывно. Ручной контент-анализ становится просто невозможным.
Выходом в данной ситуации является разработка компьютерных методов контент-анализа. Невнимательность исключена; неоднозначность исключена, если критерии приняты; трудоемкость решается за счет быстродействия. Именно компьютерным методам контент-анализа текстов и посвящена настоящая статья.
Характеристиками или элементами содержания, по отношению к которым применяется процедура подсчета, могут быть отдельные слова, словосочетания, предложения, абзацы, тексты. При этом сами характеристики никогда не являются самоцелью. Они интересны лишь в той степени, в какой являются индикаторами происходящего во внеязыковой реальности. В этом заключается существенное отличие контент-анализа от методов квантитативной лингвистики, от методов статистического изучения языка.