

18 Логическое проектирование баз данных.
Цель второй фазы проектирования базы данных состоит в создании логической модели данных для ис¬следуемой части предприятия.Логическая модель, отражающая особенности представления о функционировании предприятия одновременно многих типов пользователей, называется глобальной логической моделью данных. Для ее создания можно выбрать один из двух основных подходов — централизованный подход (применим только для не слишком сложных баз данных, основан на образовании единого списка требований путем объединения требований всех типов пользователей.) или подход на основе интеграции представлений (осуществляет слияние отдельных локальных логических моделей данных, отражающих представления разных групп пользователей, в единую глобальную логическую модель данных всего предпри¬ятия).Построенная логическая модель данных в дальнейшем будет востребована на этапе физического проектирования, а также на этапе эксплуатации и сопровождения уже готовой системы, позволяя наглядно представить любые вносимые в базу данных изменения.
19 Понятие и классификация компьютерных сетей. Компьютерная сеть - это совокупность компьютеров, соединенных линиями связи, обеспечивающая пользователям сети потенциальную возможность совместного использования ресурсов всех компьютеров. С другой стороны, проще говоря, компьютерная сеть - это совокупность компьютеров и различных устройств, обеспечивающих информационный обмен между компьютерами в сети без использования каких-либо промежуточных носителей информации.Основное назначение компьютерных сетей - совместное использование ресурсов и осуществление интерактивной связи как внутри одной фирмы, так и за ее пределами. Ресурсы (resources) - это данные, приложения и периферийные устройства, такие, как внешний дисковод, принтер, мышь, модем или джойстик.Компьютеры, входящие в сеть выполняют следующие функции :организацию доступа к сети управление передачей информации предоставление вычислительных ресурсов и услуг пользователям сети По способу организации сети подразделяются на реальные и искусственные: Искусственные сети (псевдосети) позволяют связывать компьютеры вместе через последовательные или параллельные порты и не нуждаются в дополнительных устройствах. Иногда связь в такой сети называют связью по нуль-модему (не используется модем). Само соединение называют нуль-модемным. Искусственные сети используются, когда необходимо перекачать информацию с одного компьютера на другой. MS-DOS и WINDOWS снабжены специальными программами для реализации нуль-модемного соединения. Реальные сети позволяют связывать компьютеры с помощью специальных устройств коммутации и физической среда передачи данных.В классификации сетей существует два основных термина: LAN и wAN.
20.Топология и основные компоненты компьютерных сетей Термин «топология», или «топология сети», характеризует физическое расположение компьютеров, кабелей и других компонентов сети. Топология — это стандартный термин, который используется профессионалами при описании основной компоновки сети. Если Вы поймете, как используются различные топологии, Вы сумеете понять, какими возможностями обладают различные типы сетей. Чтобы совместно использовать ресурсы или выполнять другие сетевые задачи, компьютеры должны быть подключены друг к другу. Для этой цели в большинстве сетей применяется кабель. Однако просто подключить компьютер к кабелю, соединяющему другие компьютеры, не достаточно. Различные типы кабелей в сочетании с различными сетевыми платами, сетевыми операционными системами и другими компонентами требуют и различного взаимного расположения компьютеров. Каждая топология сети налагает ряд условий. Например, она может диктовать не только тип кабеля, но и способ его прокладки. Топология может также определять способ взаимодействия компьютеров в сети. Различным видам топологий соответствуют различные методы взаимодействия, и эти методы оказывают большое влияние на сеть.Базовые топологии Все сети строятся на основе трех базовых топологий: шина (bus); звезда (star); кольцо (ring).
Если компьютеры подключены вдоль одного кабеля [сегмента (segment)], топология называется шиной. В том случае, когда компьютеры подключены к сегментам кабеля, исходящим из одной точки, или концентратора, топология называется звездой. Если кабель, к которому подключены компьютеры, замкнут в кольцо, такая топология носит название кольца. Хотя сами по себе базовые топологии несложны, в реальности часто встречаются довольно сложные комбинации, объединяющие свойства нескольких топологий.
Шина
Топологию «шина» часто называют «линейной шиной» (linear bus). Данная топология относится к наиболее простым и широко распространенным топологиям. В ней используется один кабель, именуемый магистралью или сегментом, вдоль которого подключены все компьютеры сети.
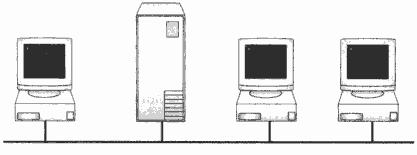
Взаимодействие компьютеров
В сети с топологией «шина» компьютеры адресуют данные конкретному компьютеру, передавая их по кабелю в виде электрических сигналов. Чтобы понять процесс взаимодействия компьютеров по шине, Вы должны уяснить следующие понятия:
передача сигнала;
отражение сигнала; терминатор.
Передача сигнала
Данные в виде электрических сигналов передаются всем компьютерам сети; однако информацию принимает только тот, адрес которого соответствует адресу получателя, ' зашифрованному в этих сигналах. Причем в каждый момент времени только один компьютер может вести передачу.Так как данные в сеть передаются лишь одним компьютером, ее производительность зависит от количества компьютеров, подключенных к шине. Чем их больше, т.е. чем больше компьютеров, ожидающих передачи данных, тем медленнее сеть. Однако вывести прямую зависимость между пропускной способностью сети и количеством компьютеров в ней нельзя. Ибо, кроме числа компьютеров, на быстродействие сети влияет множество факторов, в том числе:
характеристики аппаратного обеспечения компьютеров в сети;
частота, с которой компьютеры передают данные;
тип работающих сетевых приложений;
тип сетевого кабеля;
расстояние между компьютерами в сети.
Шина — пассивная топология. Это значит, что компьютеры только «слушают» передаваемые по сети данные, но не перемещают их от отправителя к получателю. Поэтому, если один из компьютеров выйдет из строя, это не скажется на работе остальных. В активных топологиях компьютеры регенерируют сигналы и передают их по сети.
Отражение сигнала
Данные, или электрические сигналы, распространяются по всей сети -- от одного конца кабеля к другому. Если не предпринимать никаких специальных действий, сигнал, достигая конца кабеля, будет отражаться и не позволит другим компьютерам осуществлять передачу. Поэтому, после того как данные достигнут адресата, электрические сигналы необходимо погасить.
Терминатор
Чтобы предотвратить отражение электрических сигналов, на каждом конце кабеля устанавливают терминаторы (terminators), поглощающие эти сигналы. Все концы сетевого кабеля должны быть к чему-нибудь подключены, например к компьютеру или к баррел-коннектору — для увеличения длины кабеля. К любому свободному — неподключенному — концу кабеля должен быть подсоединен терминатор, чтобы предотвратить отражение электрических сигналов.
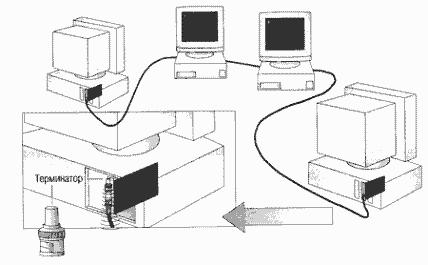
Нарушение целостности сети
Разрыв сетевого кабеля происходит при его физическом разрыве или отсоединении одного из его концов. Возможна также ситуация, когда на одном или нескольких концах кабеля отсутствуют терминаторы, что приводит к отражению электрических сигналов в кабеле и прекращению функционирования сети. Сеть «падает». Сами по себе компьютеры в сети остаются полностью работоспособными, но до тех пор, пока сегмент разорван, они не могут взаимодействовать друг с другом.
Звезда
При топологии «звезда» все компьютеры с помощью сегментов кабеля подключаются к центральному компоненту, именуемому концентратором (hub). Сигналы от передающего компьютера поступают через концентратор ко всем остальным. Эта топология возникла на заре вычислительной техники, когда компьютеры были подключены к центральному, главному, компьютеру.
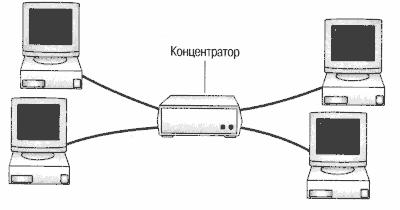
В сетях с топологией «звезда» подключение кабеля и управление конфигурацией сети централизованны. Но есть и недостаток: так как все компьютеры подключены к центральной точке, для больших сетей значительно увеличивается расход кабеля. К тому же, если центральный компонент выйдет из строя, нарушится работа всей сети. А если выйдет из строя только один компьютер (или кабель, соединяющий его с концентратором), то лишь этот компьютер не сможет передавать или принимать данные по сети. На остальные компьютеры в сети это не повлияет.
Кольцо
При топологии «кольцо» компьютеры подключаются к кабелю, замкнутому в кольцо. Поэтому у кабеля просто не может быть свободного конца, к которому надо подключать терминатор. Сигналы передаются по кольцу в одном направлении и проходят через каждый компьютер. В отличие от пассивной топологии «шина», здесь каждый компьютер выступает в роли репитера, усиливая сигналы и передавая их следующему компьютеру. Поэтому, если выйдет из строя один компьютер, прекращает функционировать вся сеть.
Передача маркера
Один из принципов передачи данных в кольцевой сети носит название передачи маркера. Суть его такова. Маркер последовательно, от одного компьютера к другому, передается до тех пор, пока его не получит тот, который «хочет» передать данные. Передающий компьютер изменяет маркер, помещает электронный адрес в данные и посылает их по кольцу.

Данные проходят через каждый компьютер, пока не окажутся у того, чей адрес совпадает с адресом получателя, указанным в данных. После этого принимающий компьютер посылает передающему сообщение, где подтверждает факт приёма данных. Получим подтверждение, передающий компьютер создаёт новый маркер и возвращает его в сеть. На первый взгляд кажется, что передача маркера отнимает много времени, однако на самом деле маркер передвигается приктически со скоростью света. В кольце диаметром 200 м маркер может циркулировать с частотой 10 000 оборотов в секунду.
21 Понятие Интернет. Мировая информационная паутина и ее службы. Интернет – это объединенные между собой компьютерные сети, глобальная мировая система передачи информации с помощью информационно-вычислительных ресурсов. Разработка данной системы началась в 1957 году на фоне гонки вооружений. Целью создания такой сети стало решение Министерства обороны США, опасающегося нападения со стороны СССР. В результате была разработана сеть компьютеров, взаимосвязанных друг с другом и способных обмениваться информацией между собой. Началось все с сети компьютеров, расположенной в одной комнате, затем сеть расширилась в пределах здания, города, страны… За 15 лет компьютерная сеть разрослась до международных масштабов, объединив передовых ученых всего мира. Рождение Интернета как Всемирной компьютерной сети произошло в 1973 году – к сети ученых с помощью трансатлантического телефонного кабеля подключились английские и норвежские организации. С тех пор прошло почти 40 лет, компьютерная сеть претерпела ряд существенных изменений – и сейчас Интернет доступен большинству жителей цивилизованного мира. Всемирная паутина Многие используют расхожую фразу о том, что Интернет – это Всемирная (Глобальная) Паутина. На самом деле, это не поэтическая метафора, а расшифровка символов WWW - World Wide Web. WWW-страницы (веб-страницы) представляют собой гипертекстовые документы. Веб-страницы, объединенные одной темой, имеющие одинаковый дизайн и находящиеся на одном веб-серверы, представляют собой веб-сайт. Просматривать веб-страницы можно с помощью специальной программы – браузера. Благодаря современному быстрому соединению и высокой скорости передачи данных, информацию в Интернете получить легко и просто. Новые сайты появляются как грибы после дождя, заманивая к себе посетителей. Сегодня Произнося сегодня слово «Интернет» большинство из нас не думает о технической стороне дела – намного более интересным представляется то, что может дать Интернет человеку. Что такое Интернет в человеческом сознании на сегодняшний день? Анализируя мотивы, которые заставляют людей посвящать ощутимую часть своего времени пребыванию на просторах Сети, можно сделать вывод, что для большинства из нас Интернет - это:- общение. Кто-то покорен социальными сетями, часами просиживая здесь в поисках единомышленников, одноклассников или просто интересных людей. Кому-то больше по душе общение на форумах, при помощи ICQ или Skype. Кто-то ищет свою половинку в сервисах знакомств. И самое главное – Интернет позволяет без проблем общаться с людьми, в каком бы месте земного шара они не находились;- развлечение. Слушать музыку, смотреть фильмы, играть в игры, читать книги, проходить тесты можно не выходя из режима он-лайн – ведь этого добра в Интернете великое множество! - самообразование. Интернет, безусловно, лучший источник информации. Многие люди используют его для пополнения своих знаний в тех или иных сферах: читают полезные статьи, записываются на дистанционные он-лайн курсы и тренинги, просматривают видеоуроки; - творчество, саморазвитие, личностный рост. Интернет вдохновляет на творчество! Достаточно пройтись по рукодельным блогам или кулинарным сайтам, как тут же хочется сделать что-нибудь эдакое самому. Многие нашли свое любимое увлечение именно благодаря Сети; - место совершения покупок, сделок. Специальная Интернет-валюта позволяет совершать покупки он-лайн, не выходя из дома. Деньги можно обменивать, покупать акции, совершать другие денежные операции; - средство заработка. Всемирная Сеть предоставляет большие возможности в плане заработка.Заработать в Интернете можно, открыв собственный Интернет-магазин, заведя сайт или блог, создав уникальный информационный продукт. Новички могут начать с фриланса: наполнять сайты контентом, заниматься программированием и веб-дизайном, продавать фотографии, придумывать слоганы. Понять, что такое Интернет во всем его многообразии, может только тот человек, который постарается максимально использовать в собственных нуждах все перечисленные возможности Всемирной Паутины. За короткое время WWW превратила Интернет в информационную супермагистраль, или «мировую информационную паутину». WWW обеспечила миллионам людей возможность общаться между собой в режиме прямого диалога. По сети стали успешно передавать не только текстовые файлы, но и звук, графику и видеоизображения. Владельцы компьютерных баз данных и коммерческих сетей увидели в Интернете безграничный потребительский рынок и основной канал для распространения деловой информации, позволяющий им эффективно делать свой бизнес в виртуальном пространстве сети. Почему технология WWW названа «всемирной паутиной»? Во-первых, структура сети согласно этой технологии содержит узлы, в которых расположены компьютеры: серверы и клиенты; их обычно называют соответственно Web-серверы и Web-клиенты. Располагаются эти компьютеры по всему миру, на всех континентах и во всех странах, поэтому сеть действительно опутывает весь мир, создавая из него некий виртуальный город (или страну), до каждого компьютера-дома которого подать рукой. Во-вторых, в отличие от привычной большинству компьютерных пользователей древовидной иерархической структуры, логическая сеть WWW имеет структуру паутиновидную: указав на выделенное цветом слово или словосочетание, пользователь попадает на нужный ему узел всемирной паутины, минуя центр, которого в сети просто не существует. В-третьих, поскольку корнями Интернет уходит в разработки американского министерства обороны, были изначально оговорены надежность и неразрываемость связи по сети даже в условиях выхода из строя нескольких ее узлов. Поэтому информация по сети может распространяться от узла к узлу WWW самыми разными путями (за которыми и не следит никто, да и вряд ли возможно реально их отследить), свободными в этот миг и надежными (явно просматривается аналогия возможного передвижения по физической паутине). Web-серверы содержат информационные страницы, которые обычно называют Web-страницами. Особенность информации, представленной на Web-серверах, состоит в том, что она: может быть представлена в различных вариантах —в виде форматированного текста, графических, в том числе анимированных изображений; снабжена перекрестными ссылками для вызова нового текущего сервера, текущей страницы, текущего абзаца на странице. Иными словами, страницы Web-сервера условно могут быть разделены на два класса: собственно содержательные; страницы-посредники, служащие для обеспечения гипертекстовой связи. В основу этой технологии положена технология гипертекста, распространенная на все компьютеры, подключенные к сети Интернета. Суть технологии гипертекста состоит в том, что текст структурируется, т.
22 Адресация в Интернет.Основным протоколом сети Интернет является сетевой протокол TCP/IP. Каждый компьютер, в сети TCP/IP (подключенный к сети Интернет), имеет свой уникальный IP-адрес или IP – номер. Адреса в Интернете могут быть представлены как последовательностью цифр, так и именем, построенным по определенным правилам. Компьютеры при пересылке информации используют цифровые адреса, а пользователи в работе с Интернетом используют в основном имена. Цифровые адреса в Интернете состоят из четырех чисел, каждое из которых не превышает двухсот пятидесяти шести. При записи числа отделяются точками, например: 195.63.77.21. Такой способ нумерации позволяет иметь в сети более четырех миллиардов компьютеров. Для отдельного компьютера или локальной сети, которые впервые подключаются к сети Интернет, специальная организация, занимающейся администрированием доменных имен, присваивает IP – номера. Первоначально в сети Internet применялись IP – номера, но когда количество компьютеров в сети стало больше чем 1000, то был принят метод связи имен и IP – номеров, который называется сервер имени домена (Domain Name Server, DNS). Сервер DNS поддерживает список имен локальных сетей и компьютеров и соответствующих им IP – номеров.В Интернете применяется так называемая доменная система имен. Каждый уровень в такой системе называется доменом. Типичное имя домена состоит из нескольких частей, расположенных в определенном порядке и разделенных точками. Домены отделяются друг от друга точками, например: www.lessons-tva.infoили tva.jino.ru. В Интернете доменная система имен использует принцип последовательных уточнений также как и в обычных почтовых адресах - страна, город, улица и дом, в который следует доставить письмо. Домен верхнего уровня располагается в имени правее, а домен нижнего уровня - левее. В нашем примере домены верхнего уровня info и ru указывают на то, что речь идет о принадлежности сайта www.lessons-tva.info к тематическому домену верхнего уровня info, а сайта tva.jino.ru к российской (ru) части Интернета. Но в России множество пользователей Интернета, и следующий уровень определяет организацию, которой принадлежит данный адрес. В нашем случае это компания jino. Интернет-адрес этой компании - jino.ru. Все компьютеры, подключенные к Интернету в этой компании, объединяются в группу, имеющую такой адрес. Имя отдельного компьютера или сети каждая компания выбирает для себя самостоятельно, а затем регистрирует его в той организации Интернет, которая обеспечивает подключение. Это имя в пределах домена верхнего уровня должно быть уникальным. Далее следует имя хоста tva, таким образом, полное имя домена третьего уровня: tva.jino.ru. В имени может быть любое число доменов, но чаще всего используются имена с количеством доменов от трех до пяти Доменная система образования адресов гарантирует, что во всем Интернете больше не найдется другого компьютера с таким же адресом. Для доменов нижних уровней можно использовать любые адреса, но для доменов самого верхнего уровня существует соглашение. В системе адресов Интернета приняты домены, представленные географическими регионами. Они имеют имя, состоящее из двух букв, например: Украина - ua Франция - fr; Канада - са; США - us; Россия - ru. Существуют и домены, разделенные по тематическим признакам, например: Учебные заведения - edu. Правительственные учреждения - gov. Коммерческие организации - com. В последнее время добавлены новые зоны, например: biz, info, in, .cn и так далее При работе в Internet используются не доменные имена, а универсальные указатели ресурсов, называемые URL (Universal Resource Locator). URL - это адрес любого ресурса (документа, файла) в Internet, он указывает, с помощью какого протокола следует к нему обращаться, какую программу следует запустить на сервере и к какому конкретному файлу следует обратиться на сервере. Общий вид URL: протокол://хост-компьютер/имя файла (например: http://www.lessons-tva.info/book.html). Регистрация домена осуществляется в выбранной пользователем зоне ua, ru, com, net, info и так далее. В зависимости от назначения сайта выбирается его зона регистрации. Для регистрации сайта желательно выбрать домен второго уровня, например lessons-tva.info, хотя можно работать и с доменом третьего уровня, например tva.jino.ru. Домен второго уровня регистрируется у регистратора – организации занимающейся администрированием доменных имен, например http://www.imhoster.net/domain.htm. Домен третьего уровня приобретается, как правило, вместе с хостингом у хостинговой компании. Имя сайта выбирают исходя из вида деятельности, названия компании или фамилии владельца сайта. Компьютеpы IP-сетей обмениваются между собой, используя в качестве адpесов 4-байтные коды, котоpые в литеpатуpе пpинято пpедставлять соответствующей комбинацией десятичных чисел, напоминающей нумерацию абонентов в телефонии.В общем случае, такие числовые адреса могут иметь некотоpое pазнообpазие тpактовок, из котоpых приведем здесь лишь следующую:<класс сети> <номер сети> <номер компьютера>.Такая комбинация подразумевает, что множество представимых числовых номеров делится на сети разного масштаба. С помощью специального механизма (маскирования) любая сеть, в свою очередь, может быть пpедставлена набоpом более мелких сетей. Беспрецедентный рост числа компьютеров в internet (более 30 млн. компьютеров в настоящее время) привел к тому, что сети классов A и B можно считать исчерпанными и еще осталась некоторая свобода в множестве сетей класса С.Владельцу сети пpедпpиятия или коpпоpации, напpимеp, обычно выделяется не полная сеть (того или иного класса), а лишь некоторая ее часть. Заказывать сеть без хотя бы некотоpого pезеpва для последующего pазвития тоже не имеет смысла, поэтому часть выданных адресов все равно остается неиспользуемой.Пользователям коммутируемых линий нередко вообще не предоставляется фиксированного адреса и он "мутирует" от сеанса к сеансу, поскольку все pавно одновpеменная работа всех так же невозможна как и одновременные телефонные разговоры всего населения.Что же все-таки теpяет пользователь, не получивший постоянного адреса? Он не может объявить себя информационным источником, откpытым для доступа той или иной гpуппе своих коллег или приятелей (наиболее искушенные, правда, умудpяются обходить и не такие пpепятсвия). Однако, далеко не все пользователи готовы выступать в такой pоли, не говоpя уже о том, что сколь-нибудь шиpокий доступ к такому инфоpмационному источнику обычно существенно огpаничивается паpаметpами используемой коммутиpуемой линии.В ряде случаев локальная сеть может быть создана вообще с предоставлением ей только одного числового адреса (пpевpащение всего pеального в виpтуальное - известный "фокус"; системщиков). Разработан и утвержден новый стандарт уже 16-байтного адреса (стаpый адрес - стандарт IPv4, новый - IPv6), пpедусматpивающий pадикальное pазpешение адpесного кpизиса (а заодно и решение некотоpых дpугих пpоблем) в internet. Числовые адреса удобны для компьютеров, но не для пользователей. Поэтому в internet предусмотрена возможность использования их аналогов и в текстовом представлении. Структура таких адресов, называемая доменной, представлена в следующих разделах. Здесь же ограничимся пока тем замечанием, что наличие двух пpедставлений адpесов в internet пpиводит к необходимости (где надо и когда надо) их пpеобpазования из одной формы в другую или наоборот, реализуемое так называемыми серверами DNS (Domain Name System). Большинство пользователей, независимо от того, по каким линиям - коммутиpуемым или выделенным (используемым как правило в сетях организаций и корпораций) - подключены их компьютеры в internet, не занимаются pазpаботкой собственных локальных сетей и, поэтому, вполне могут огpаничиться еще более упpощенным пpедставлением о числовых адpесах.1.2 Доменные адреса Domain - домен - теppитоpия, область, сфера, фрагмент, описывающий ту или часть адреса в текстовой форме, подобно тому как это делается при оформлении конвертов обычных писем, но, в отличие от них, в доменном адресе (равно как и в других используемых текстовых адресах) не допускается использования пробелов. В конкpетных адpесах может быть пpедставлено pазличное число доменов. Адpес, состоящий, скажем, из четырех доменов, представляется следующим образом: domain4.domain3.domain2.domain1Каждый, кому пpиходилось обмениваться обычными письмами с загpаничными адpесатами, напpимеp, из США или Италии, знает, что по сравнению с нашими внутрироссийскими письмами, "у них" адреса на конвертах пишутся в обратном порядке, то есть начиная с имени и фамилии (впрочем, новый стандарт конверта международного письма, недавно внедренный у нас - шаг на пути заимствования такой практики). Аналогичное имеет место и в доменной адpесации. Пpедставленный выше пpимеp адpеса, поэтому, в частном случае может быть пpоинтеpпpетиpован следующим обpазом: domain1 -- двухбуквенный код страны, domain2 -- код города (обычно тяготеют к сокращению исходного названия),domain3 -- наименование организации,domain4 -- имя компьютера.Истоpия Internet отсчитывается ее создателями с 1969 года, реальное появление internet как объединения шести крупных IP-сетей США в единую научную сеть NSFNET (являющуюся сегодня в этой стране опорной сетью и играющую особую роль во всей internet, поскольку без регистрации в ней не обходится подключение сетей никакой другой страны) состоялось значительно позже - в 1986 году. Сокращенные наименования составляющих сети NSFNET стали использоваться в качестве следующих доменов веpхнего уpовня:com Коммерческие организацииedu Учебные и научные организацииgov Правительственные организацииmil Военные организацииnet Сетевые организации разных сетейorg Другие организации Недостатки такого pешения сегодня очевидны: почти все эти сети давно "перешагнули" гpаницы США и по доменному адpесу без дополнительной инфоpмации сегодня зачастую пpосто невозможно опpеделить какой стpане миpа он соответствует. С другой стороны, успех интегpационной политики в Internet неразрывно связан с подобными компромиссными решениями (коих немало), а всем известно, что реальная политика -- это политика компромиссов.
2.Адресация в электронной почте Поскольку в internet обеспечивается доступ не только к компьютерам -информационным источником ( www -, gopher -, ftp - серверам и др.), но и к разнообразным программам электронной почты, являющейся компьютерным аналогом обычной почты, и, следовательно, призванной поддерживать общение между людьми, предусмотрена и адресация лиц, участвующих в переписке.Почтовый адрес пользователя имеет следующую структуру:<имя пользователя>@<адрес компьютера>Поскольку уже рассмотренная адресация компьютеров безусловно должна обеспечивать уникальность адреса каждого компьютеpа, с именем пользователя все уже проще. В общем случае, фоpмат почтового адpеса подpазумевает, что один компьютер может быть использован и несколькими пользователями, имена которых (в такой группе) должны, естественно, различаться. Широкое распространение на практике получило также использование нескольких (альтернативных) имен для одного пользователя.Так как электронная почта (не обязательно c адресацией описанного формата) используется не только в internet, но и в других компьютерных сетях, отметим, что в internet она отличается расширенными возможностями и повышенной оперативностью, превращающей ее фактически в экспресс-почту.2.1 Адpесация документов в WWW-технологииВ WWW-технологии документом, принято называть содержимое того или иного файла, независимо от характера информации, размещенной в нем. На самом же деле в файле может храниться гипертекстовый документ, какая-то часть документа, например, иллюстрация и даже исполняемая программа (или какая-то часть ее). Адресом документа здесь является так называемый URL (Uniform Resource Locator), включающий весь комплекс сведений, необходимый для его поиска и правильной интерпретации тем или иным броузером или WWW - навигатором - программой, выполняющей роль комплекса, состоящего из "штурвала" и монитора, и используемой при "плавании" по просторам информационных источников мира. Наиболее популярны из них сегодня - Netscape Navigator и Microsoft Internet Explorer ( relcom/Services/Infoline/TechSupport/).3.Адpесация и сетевая интеграция в InternetПредставленное выше, несколько искажает ситуацию в том плане, что на самом деле основы доменной адpесации были пpоpаботаны задолго до фактического создания и укpепления internet и такая адресация уже широко использовалась и используется и в сетях, не поддерживающих IP-технологию. Internet, собственно, тем и отличается от internet, что первая явлется расширением второй за счет обеспечения возможности обмена данными с компьютерами, вообще не использующими числовых IP-адресов. Исторически существует несколько вариантов такого подключения в Internet (см. схему "Составляющие Интернет"), обеспечивающих пользователям практически полный доступ к ресурсам internet, но существенной потерей качества за счет, прежде всего, отсутствия возможности (прямого) использования средств WWW-технологии. Работа получается технологически существенно более сложной и, как правило, медленной, но зато огpаничивается весьма скpомными тpебованиями к конфигуpации компьютеpов пользователей и, нередко, даже к хаpактеpистикам линий связи, используемых для их подключения в Internet.
4.1 Три основных класса IP-адресовIP-адрес имеет длину 4 байта и обычно записывается в виде четырех чисел, представляющих значения каждого байта в десятичной форме, и разделенных точками, например: 128.10.2.30 - традиционная десятичная форма представления адреса, 10000000 00001010 00000010 00011110 - двоичная форма представления этого же адреса.Адрес состоит из двух логических частей - номера сети и номера узла в сети. Какая часть адреса относится к номеру сети, а какая к номеру узла, определяется значениями первых битов адреса:Если адрес начинается с 0, то сеть относят к классу А, и номер сети занимает один байт, остальные 3 байта интерпретируются как номер узла в сети. Сети класса А имеют номера в диапазоне от 1 до 126. (Номер 0 не используется, а номер 127 зарезервирован для специальных целей, о чем будет сказано ниже.) В сетях класса А количество узлов должно быть больше 216 , но не превышать 224.Если первые два бита адреса равны 10, то сеть относится к классу В и является сетью средних размеров с числом узлов 28 - 216. В сетях класса В под адрес сети и под адрес узла отводится по 16 битов, то есть по 2 байта.Если адрес начинается с последовательности 110, то это сеть класса С с числом узлов не больше 28. Под адрес сети отводится 24 бита, а под адрес узла - 8 битов.Если адрес начинается с последовательности 1110, то он является адресом класса D и обозначает особый, групповой адрес - multicast. Если в пакете в качестве адреса назначения указан адрес класса D, то такой пакет должны получить все узлы, которым присвоен данный адрес. Если адрес начинается с последовательности 11110, то это адрес класса Е, он зарезервирован для будущих применений.
23.Универсальный указатель ресурсов URL.Для уникальной идентификации (адресации) информационных ресурсов Веб используются универсальные указатели ресурсов (URL). Они могут идентифицировать:Явным или неявным образом домашнюю страницу Веб-сайта, представляющую точку входа в сайт и обычно отражающую в своем содержании общие сведения о данном сайтеИмя и местоположение в сети HTML-файла - носителя какой либо HTML-страницыЯкорную точку в HTML-странице - начальную точку фрагмента страницы, к которой можно будет проследовать по гиперссылкамФайлы различного формата, хранимые в узлах Интернет, на которые имеются ссылки в HTML-страницах и к которым осуществляется доступ из Веб-браузера через посредство ftp-сервера; такие файлы могут быть вызваны на сторону клиента Веб и запомнены на локальном диске; в случае, когда для таких файлов существуют программы просмотра, эти программы могут быть подключены к Веб-браузеру и позволяют непосредственно, без выхода из браузера просматривать их содержимое; примером могут служить PDF-файлы, которые могут просматриваться с помощью свободно распространяемой программы Acrobat Reader компании Adobe.Общий формат URL в несколько упрощенном виде таков:<протокол>://<имя узла><полный путь><имя файла>#<якорь>Здесь:<протокол> - указывает с помощью какого из информационных сервисов можно получить доступ к ресурсу, идентифицируемому с помощью данного URL; возможные значения для этого компонента - http, ftp, tn, gopher и т.д.;<имя узла> - это доменное имя узла Интернет, в котором хранится указанный в URL файл;<полный путь> - полный путь на диске данного узла по структуре его папок к нужному файлу;<имя файла> - имя нужного файла с расширением;<якорь> - имя якорной точки - идентификатора некоторого фрагмента HTML-файла, указываемого с помощью специального тега в начале этого фрагмента.В составе URL некоторые из указанных компонентов являются необязательными, в зависимости от контекста использования. Например, если нужно сослаться на файл того же узла Интернет, к которому относится HTML-файл, содержащий гиперссылку с данным URL, то можно не указывать протокол и доменное имя узла. Если при этом целевой файл ссылки содержится на том же диске и в той же папке, что и файл, содержащий URL, то можно также не указывать полный путь. Если подразумевается начало HTML-файла, то не указывается якорь. Наконец, если имеется в виду якорная точка в том же HTML-файле, то можно не указывать имя файла и все предшествующие ему компоненты URL.Нетрудно видеть, что значение URL, соответствующее HTML-странице или другому информационному ресурсу Веб, уникальным образом их идентифицирует, указывая их местоположение в Интернет.
24 Поиск информации в ИнтернетеКак говорилось ранее, одним из основных аспектов проведения вторичных маркетинговых исследований при помощи Интернета является поиск источников информации. Сотни миллионов сайтов, находящихся сегодня в Сети делают поставленную задачу достаточно сложной. Для того чтобы облегчить этот процесс и сделать его более эффективным, в данном разделе описывается подход к решению задачи поиска информации в Интернете.Для получения качественного результата при проведении поиска необходимо соблюдать ряд условий. Основными из них являются контроль полноты охвата ресурсов и достоверности найденной информации.Прежде всего, возможность нахождения той или иной информации в Сети определяется полнотой охвата ее ресурсов. Зачастую проведение поиска требует задействования максимального объема возможных источников, в роли которых могут выступать не только web-сайты, но и базы данных, региональные телеконференции, FTP-архивы и т. д. При этом необходимым условием успешного планирования и проведения поисковых работ становится знание всех основных существующих на сегодняшний день типов ресурсов Интернета, понимание технической и тематической специфики их информационного наполнения и особенностей доступа к ним.Наряду с полнотой охвата ресурсов, качество проводимого поиска определяется достоверностью найденной информации. Контроль ее достоверности может производиться разными способами, в которые входит нахождение и сверка с альтернативными источниками информации, установление частоты его использования другими источниками, выяснение статуса документа и сайта, на котором он находится, получение сведений о компетентности и положении автора материала и ряд других.Проблема определения достоверности информации, размещаемой в Интернете, выходит за пределы рассмотрения в рамках данной книги, поэтому основное внимание будет уделено вопросу ее поиска.
Сетевые информационные ресурсы
По способу организации и хранения информации ее источники в Интернете можно разделить на следующие основные категории:
· файловые серверы — являются традиционным способом хранения данных и представляют собой компьютеры, часть дискового пространства которых доступна через Интернет. Доступ к данным на таком сервере осуществляется с помощью специальных программ, поддерживающих протокол передачи файлов — FTP. Данный протокол в общем случае требует авторизации, то есть идентификации пользователя. Для осуществления доступа к файлам со стороны произвольного пользователя Сети обычно используется так называемый анонимный вход под регистрационным именем anonymous, для которого пароль не требуется. Этот протокол поддерживается всеми стандартными браузерами;
· web-сайты являются сегодня основным и наиболее распространенным типом информационных ресурсов в Сети. Сайт может содержать информацию, представленную в самой произвольной форме: графической, звуковой, видеоизображения и т. д.;
· телеконференции могут являться источником необходимой информации, как правило, носящей неофициальный характер. Телеконференции представляют собой способ общения людей, имеющих доступ в Сеть, и предназначены для обсуждения каких-либо вопросов или распространения информации. Они позволяют добиться обратной связи со множеством лиц и произвести детальное обсуждение какой-либо проблемы территориально разобщенными людьми;
· базы данных могут содержать самую произвольную информацию: публикации, справочную информацию, другие данные. Наиболее широко распространен способ доступа к базам данных через стандартные браузеры, так как он обеспечивает максимальную потенциальную аудиторию потребителей информации. Наряду с непосредственным извлечением информации из баз данных широко используется динамическое построение web-страниц в процессе исполнения пользовательских запросов.
Все названные ранее источники можно классифицировать по ряду признаков:
· по языковому признаку — в силу историко-географических причин наиболее распространенным языком в Интернете является английский, однако в Сети представлены практически все основные языки мира и, как отмечают исследовательские компании, их доля постоянно растет. Часто встречается ситуация, когда сайт поддерживают одновременно несколько языков — на выбор пользователя;
· по географическому признаку — у информационных ресурсов обычно есть своя целевая аудитория, и ее местонахождение часто может быть сопоставлено с каким-то географическим регионом. Следует заметить, что территориальное разделение не относится к возможности доступа к ресурсам, который может быть осуществлен из любой точки земного шара;
· по виду и характеру представляемой информации (новости, рекламная информация, тематическая информация, справочная информация) — это наиболее важное, с практической точки зрения, разделение по виду и характеру представляемой информации, поскольку именно информационное наполнение в конечном итоге оказывается решающим при отборе источников. В то же время как раз этот аспект может являться наиболее трудно формализуемым по причине неоднородности представляемой информации. Например, один и тот же web-сайт может содержать информацию самых разных видов. Поэтому приведенное разделение на подгруппы в достаточной степени условно.
Средства поиска информации
По принципу организации и использования средства поиска можно выделить следующие инструменты:
· поисковые машины — являются ключевым инструментом поиска информации, поскольку содержат индексы большинства web-серверов Интернета. Однако именно это достоинство оборачивается их главным недостатком. На любой запрос они выдают обычно чрезмерно большое количество информации, среди которой только незначительная часть является полезной, после чего требуется значительный объем времени для ее извлечения и обработки;
· мета-средства поиска — позволяют ускорить выполнение запроса путем передачи аргументов поиска, то есть ключевых слов, одновременно нескольким поисковым системам. При значительном ускорении процесса и увеличении охвата поиска, этот способ имеет ряд недостатков, связанных с необходимостью координации во времени поступления результатов обработки запроса от нескольких систем, а также тем, что они не позволяют использовать возможности языка запроса каждого из применяемых поисковых средств;
· специализированные средства поиска — представляют собой «программы-пауки», которые в автоматическом режиме просматривают web-страницы, отыскивая на них нужную информацию. Механизм их работы близок к механизму, который используют поисковые системы для построения своих индексных таблиц. Выбор между первыми и вторыми представляет собой классический выбор между применением универсальных или специализированных средств;
· каталоги — как и поисковые машины, используются посетителями Интернета для нахождения необходимой информации. Каталог представляет собой иерархически организованную структуру, в которую данные заносится по инициативе пользователей. Как следствие, объем информации в них несколько ограничен по сравнению с поисковыми системами, но в то же время более упорядочен благодаря лежащей в их основе иерархической тематической структуре.
Методы поиска информации
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен при помощи двух основных методов, которые, в зависимости от его целей и задач, могут быть использованы по отдельности или в комбинации друг с другом:
· использование поисковых систем — сегодня этот метод является одним из основных при проведении предварительного поиска. Его применение основано на ключевых словах, которые передаются системе в качестве аргумента поиска. Результатом является список ресурсов Интернета, подлежащих детальному рассмотрению. Получение наиболее релевантного результата требует проведения предварительной работы по составлению тезауруса;
· поиск по гипертекстовым ссылкам — поскольку все сайты Интернета связаны между собой гиперссылками, поиск информации может быть произведен путем последовательного просмотра с помощью браузера связанных ссылками web-страниц. К этому виду поиска также относится использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников. Такой метод наиболее трудоемок, однако «ручной» просмотр web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, требующего глубокого анализа. Он может быть также более эффективен при проведении повторных циклов или просмотре вновь образованных ресурсов.
Поиск с использованием поисковых машин
Наиболее широко используемым, но в то же время наиболее сложным является метод поиска с использованием поисковых систем. Его широкая распространенность обусловлена тем, что поисковые системы содержат в себе индексы громадного количества сайтов и при правильно сформированном запросе можно сразу же получить ссылки на интересующие ресурсы. Сложность метода состоит в том, что для того, чтобы результат был качественным, необходимо уметь выбрать наиболее подходящие поисковые системы, правильно формулировать запросы к ним, учитывать их особенности и функциональные возможности.
Двоякая характеристика данного метода связана с тем, что проведение эффективного поиска требует одновременного решения двух противоположных задач: увеличении охвата с целью извлечения максимального количества значимой информации и уменьшении охвата с целью минимизации шумовой информации. Нетрудно увидеть, что одновременно осуществить и то и другое довольно сложно, хотя найти оптимальное соотношение все-таки возможно.
Составление тезауруса
Для эффективного использования поисковых серверов, прежде всего необходим список ключевых слов, организованный с учетом семантических отношений между ними, то есть тезаурус.
Одним из подходов [1] к составлению тезауруса может стать использование законов Ципфа. Рассмотрим их более подробно.
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется рангом частоты. Вероятность обнаружения слова в тексте равно отношению частоты вхождения слова к числу слов в тексте. Ципф определил, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:

где f — частота вхождения слов, r — ранг частоты, n — число слов
Это значит, что график зависимости ранга от частоты представляет из себя равностороннюю гиперболу.
Ципф также установил, что зависимость количества слов с данной частотой от частоты постоянна для всех текстов в пределах одного языка и также является гиперболой.
Исследование вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой, как правило, являются предлогами, частицами, местоимениями, в английском языке — артиклями (так называемые «стоп-слова»), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Таким образом, данная особенность может помочь правильно выбрать ключевые слова для проведения поиска информации.
Процедура оптимального выбора ключевых слов, основанная на применении законов Ципфа, заключается в следующем: берут любой текст-источник, близкий к искомой теме, то есть «образец», и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, web-страница, любой другой документ. Анализ текста производится в следующем порядке: 1. «стоп-слова» удаляются из текста; 2. вычисляется частота вхождения каждого слова и составляется список, в котором слова расположены в порядке убывания их частоты; 3. выбирается диапазон частот, лежащий в середине списка, и из него отбираются слова, наиболее полно соответствующие смыслу текста; 4. составляется запрос к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором OR(ИЛИ) Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов, то есть расположению их в порядке убывания частоты вхождения в документ слов запроса, применяемому в большинстве поисковых машин, на первых страницах найденных ресурсов практически все документы должны оказаться релевантными.
Отбор поисковых систем
Данный этап требует установить последовательность использования поисковых машин в соответствии с убыванием ожидаемой эффективности поиска с применением каждой машины.
Всего известно около нескольких сотен поисковых систем, различающихся по регионам охвата, принципам проведения поиска (а, следовательно, по входному языку и характеру воспринимаемых запросов), объему индексной базы, скорости обновления информации, способности искать «нестандартную» информацию и т. д. Основными критериями выбора поисковых систем являются объем индексной базы сервера и степень развитости самой поисковой машины, то есть уровень сложности воспринимаемых ею запросов.
Составление и выполнение запросов к поисковым машинам
Это наиболее сложный и трудоемкий этап, связанный с обработкой значительного количества информации, большая часть которой обычно является шумовой. На основе тезауруса формируются запросы к выбранным поисковым серверам. После получения первоначальных результатов возможно уточнение запросов с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска, и данные с ресурсов, признанных релевантными, собираются для последующего анализа.
Как формат, так и семантика запросов может варьироваться в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы должны составляться так, чтобы область поиска была максимально конкретизирована и сужена, то есть предпочтение следует отдавать использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится их пробная реализация — как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Языки запроса различных машин поиска в основном являются сочетанием следующих функций: · осуществление поиска документов при помощи операторов булевой алгебры AND, OR, NOT. AND (И) — содержащих все термины, соединенные им, OR (ИЛИ) — искомый текст должен содержать хотя бы один из терминов, соединенных данным оператором; NOT (НЕ) — поиск документов, в тексте которых отсутствуют термины, следующие за данным оператором; · осуществление поиска документов при помощи операторов расстояния, ограничения порядка следования и расстояния между словами. NEAR — второй термин должен находиться на расстоянии от первого, не превышающем определенного числа слов; FOLLOWED BY — термины следуют в заданном порядке; ADJ — термины, соединенные оператором, являются смежными; · возможность усечения терминов — использование символа * вместо его окончания термина; позволяет включить в искомый список все слова, производные от его начальной части шаблона; · учет морфологии языка — машина автоматически учитывает все формы данного термина, возможные в языке, на котором ведется поиск; · возможность поиска по словосочетанию, фразе; · ограничение поиска элементом документа (слова запроса должны находиться именно в заголовке, первом абзаце, ссылках и т. д.); · ограничение по дате опубликования документа; · ограничение на количество совпадений терминов; · возможность поиска графических изображений; · чувствительность к строчным и прописным буквам.
Результат запроса, то есть выведенный системой список ссылок на найденные ресурсы, обрабатывается в два этапа. На первом этапе производится отсечение очевидно нерелевантных источников, попавших в выборку в силу несовершенства поисковой машины или недостаточной «интеллектуальности» запроса. Параллельно проводится семантический анализ, имеющий целью уточнение тезауруса для модификации последующих запросов. Дальнейшая обработка производится путем последовательного обращения на каждый из найденных ресурсов и анализа находящейся там информации.
Анализ ресурсов и сбор информации
Конечной стадией поиска является анализ ресурсов и сбор искомой информации. Первичный анализ ресурсов может основываться на аннотациях, если они есть, а при их отсутствии — на ознакомлении с информационным наполнением ресурса. Далее информация извлекается с отобранных источников и используется в соответствующих поиску целях.
25 Информационная безопасность и защита информацииЗащита информации и информационная безопасность Появление новых информационных технологий и развитие мощных компьютерных систем хранения и обработки информации повысили уровни защиты информации и вызвали необходимость в том, чтобы эффективность защиты информации росла вместе со сложностью архитектуры хранения данных. Так постепенно защита экономической информации становится обязательной: разрабатываются всевозможные документы по защите информации; формируются рекомендации по защите информации; даже проводится ФЗ о защите информации, который рассматривает проблемы защиты информации и задачи защиты информации, а также решает некоторые уникальные вопросы защиты информации. Таким образом, угроза защиты информации сделала средства обеспечения информационной безопасности одной из обязательных характеристик информационной системы. На сегодняшний день существует широкий круг систем хранения и обработки информации, где в процессе их проектирования фактор информационной безопасности Российской Федерации хранения конфиденциальнойинформации имеет особое значение. К таким информационным системам можно отнести, например, банковские или юридические системы безопасного документооборота и другие информационные системы, для которых обеспечение защиты информации является жизненно важным для защиты информации в информационных системах. Что же такое «защита информации от несанкционированного доступа» или информационная безопасность Российской Федерации? Методы защиты информации Под информационной безопасностью Российской Федерации (информационной системы) подразумевается техника защиты информации от преднамеренного или случайного несанкционированного доступа и нанесения тем самым вреда нормальному процессу документооборота и обмена данными в системе, а также хищения, модификации и уничтожения информации. Другими словами вопросы защиты информации и защиты информации в информационных системах решаются для того, чтобы изолировать нормально функционирующую информационную систему от несанкционированных управляющих воздействий и доступа посторонних лиц или программ к данным с целью хищения. Под фразой «угрозы безопасности информационных систем» понимаются реальные или потенциально возможные действия или события, которые способны исказить хранящиеся в информационной системе данные, уничтожить их или использовать в каких-либо целях, не предусмотренных регламентом заранее. Первое разделение угрозы безопасности информационных систем на виды Если взять модель, описывающую любую управляемую информационную систему, можно предположить, что возмущающее воздействие на нее может быть случайным. Именно поэтому, рассматривая угрозы безопасности информационных систем, следует сразу выделить преднамеренные и случайные возмущающие воздействия. Комплекс защиты информации (курсовая защита информации) может быть выведен из строя, например из-за дефектов аппаратных средств. Также вопросы защиты информации встают ребром благодаря неверным действиям персонала, имеющего непосредственный доступ к базам данных, что влечет за собой снижение эффективности защиты информации при любых других благоприятных условиях проведения мероприятия по защите информации. Кроме этого в программном обеспечении могут возникать непреднамеренные ошибки и другие сбои информационной системы. Все это негативно влияет на эффективность защиты информации любого вида информационной безопасности, который существует и используется в информационных системах. В этом разделе рассматривается умышленная угроза защиты информации, которая отличается от случайной угрозы защиты информации тем, что злоумышленник нацелен на нанесение ущерба системе и ее пользователям, и зачастую угрозы безопасности информационных систем – это не что иное, как попытки получения личной выгоды от владения конфиденциальной информацией. Защита информации от компьютерных вирусов (защита информации в информационных системах) предполагает средства защиты информации в сети, а точнее программно аппаратные средства защиты информации, которые предотвращают несанкционированное выполнение вредоносных программ, пытающихся завладеть данными и выслать их злоумышленнику, либо уничтожить информацию базы данных, но защита информации от компьютерных вирусов неспособна в полной мере отразить атаку хакера или человека, именуемого компьютерным пиратом. Задача защиты информации и защиты информации от компьютерных вирусов заключается в том, чтобы усложнить или сделать невозможным проникновение, как вирсов, так и хакера к секретным данным, ради чего взломщики в своих противоправных действиях ищут наиболее достоверный источник секретных данных. А так как хакеры пытаются получить максимум достоверных секретных данных с минимальными затратами, то задачи защиты информации - стремление запутать злоумышленника: служба защиты информации предоставляет ему неверные данные, защита компьютерной информации пытается максимально изолировать базу данных от внешнего несанкционированного вмешательства и т.д. Защита компьютерной информации для взломщика – это те мероприятия по защите информации, которые необходимо обойти для получения доступа к сведениям. Архитектура защиты компьютерной информации строится таким образом, чтобы злоумышленник столкнулся с множеством уровней защиты информации: защита сервера посредством разграничения доступа и системы аутентификации (диплом «защита информации») пользователей и защита компьютера самого пользователя, который работает с секретными данными. Защита компьютера и защита сервера одновременно позволяют организовать схему защиты компьютерной информации таким образом, чтобы взломщику было невозможно проникнуть в систему, пользуясь столь ненадежным средством защиты информации в сети, как человеческий фактор. То есть, даже обходя защиту компьютера пользователя базы данных и переходя на другой уровень защиты информации, хакер должен будет правильно воспользоваться данной привилегией, иначе защита сервера отклонит любые его запросы на получение данных и попытка обойти защиту компьютерной информации окажется тщетной. Публикации последних лет говорят о том, что техника защиты информации не успевает развиваться за числом злоупотреблений полномочиями, и техника защиты информации всегда отстает в своем развитии от технологий, которыми пользуются взломщики для того, чтобы завладеть чужой тайной. Существуют документы по защите информации, описывающие циркулирующую в информационной системе и передаваемую по связевым каналам информацию, но документы по защите информации непрерывно дополняются и совершенствуются, хотя и уже после того, как злоумышленники совершают все более технологичные прорывы модели защиты информации, какой бы сложной она не была. Сегодня для реализации эффективного мероприятия по защите информации требуется не только разработка средства защиты информации в сети и разработка механизмов модели защиты информации, а реализация системного подхода или комплекса защиты информации – это комплекс взаимосвязанных мер, описываемый определением «защита информации». Кроме того, модели защиты информации (реферат на тему защита информации) предусматривают ГОСТ «Защита информации», который содержит нормативно-правовые акты и морально-этические меры защиты информации и противодействие атакам извне. ГОСТ «Защита информации» нормирует определение защиты информации рядом комплексных мер защиты информации, которые проистекают из комплексных действий злоумышленников, пытающихся любыми силами завладеть секретными сведениями. И сегодня можно смело утверждать, что постепенно ГОСТ (защита информации) и определение защиты информации рождают современную технологию защиты информации в сетях компьютерных информационных системах и сетях передачи данных, как диплом «защита информации». Какие сегодня существуют виды информационной безопасности и умышленных угроз безопасности информации Виды информационной безопасности, а точнее виды угроз защиты информации на предприятии подразделяются на пассивную и активную. Пассивный риск информационной безопасности направлен на внеправовое использование информационных ресурсов и не нацелен на нарушение функционирования информационной системы. К пассивному риску информационной безопасности можно отнести, например, доступ к БД или прослушивание каналов передачи данных. Активный риск информационной безопасности нацелен на нарушение функционирования действующей информационной системы путем целенаправленной атаки на ее компоненты. К активным видам угрозы компьютерной безопасности относится, например, физический вывод из строя компьютера или нарушение его работоспособности на уровне программного обеспечения. Необходимость средств защиты информации. Системный подход к организации защиты информации от несанкционированного доступа К методам и средствам защиты информации относят организационно-технические и правовые мероприятия информационной защиты и меры защиты информации (правовая защита информации, техническая защита информации, защита экономической информации и т.д.). Организационные методы защиты информации и защита информации в России обладают следующими свойствами: Методы и средства защиты информации обеспечивают частичное или полное перекрытие каналов утечки согласно стандартам информационной безопасности (хищение и копирование объектов защиты информации);Система защиты информации – это объединенный целостный орган защиты информации, обеспечивающий многогранную информационную защиту;Методы и средства защиты информации (методы защиты информации реферат) и основы информационной безопасности включают в себя: Безопасность информационных технологий, основанная на ограничении физического доступа к объектам защиты информации с помощью режимных мер и методов информационной безопасности; Информационная безопасность организации и управление информационной безопасностью опирается на разграничение доступа к объектам защиты информации – это установка правил разграничения доступа органами защиты информации, шифрование информации для ее хранения и передачи (криптографические методы защиты информации, программные средства защиты информации и защита информации в сетях);Информационная защита должна обязательно обеспечить регулярное резервное копирование наиболее важных массивов данных и надлежащее их хранение ( физическая защита информации );Органы защиты информации должны обеспечивать профилактику заражение компьютерными вирусами объекта защиты информации.Правовые основы защиты информации и закон о защите информации. Защита информации на предприятии Правовые основы защиты информации – это законодательный орган защиты информации, в котором можно выделить до 4 уровней правового обеспечения информационной безопасности информации и информационной безопасности предприятия. Первый уровень правовой основы защиты информации Первый уровень правовой охраны информации и защиты состоит из международных договоров о защите информации и государственной тайны, к которым присоединилась и Российская Федерация с целью обеспечения надежной информационной безопасности РФ. Кроме того, существует доктрина информационной безопасности РФ, поддерживающая правовое обеспечение информационной безопасности нашей страны. Правовое обеспечение информационной безопасности РФ: Международные конвенции об охране информационной собственности, промышленной собственности и авторском праве защиты информации в интернете;Конституция РФ (ст. 23 определяет право граждан на тайну переписки, телефонных, телеграфных и иных сообщений);Гражданский кодекс РФ (в ст. 139 устанавливается право на возмещение убытков от утечки с помощью незаконных методов информации, относящейся к служебной и коммерческой тай¬не);Уголовный кодекс РФ (ст. 272 устанавливает ответственность за неправомерный доступ к компьютерной информации, ст. 273 — за создание, использование и распространение вредоносных про¬грамм для ЭВМ, ст. 274 — за нарушение правил эксплуатации ЭВМ, систем и сетей);Федеральный закон «Об информации, информатизации и защите информации» от 20.02.95 № 24-ФЗ (ст. 10 устанавливает разнесение информационных ресурсов по категориям доступа: открытая информация, государственная тайна, конфиденциаль¬ная информация, ст. 21 определяет порядок защиты информа¬ции);Федеральный закон «О государственной тайне» от 21.07.93 № 5485-1 (ст. 5 устанавливает перечень сведений, составляющих государственную тайну; ст. 8 — степени секретности сведений и грифы секретности их носителей: «особой важности», «совершен¬но секретно» и «секретно»; ст. 20 — органы по защите государ¬ственной тайны, межведомственную комиссию по защите госу¬дарственной тайны для координации деятельности этих органов; ст. 28 — порядок сертификации средств защиты информации, от¬ носящейся к государственной тайне); Защита информации курсовая работа.Федеральные законы «О лицензировании отдельных видов дея¬тельности» от 08.08.2001 № 128-ФЗ, «О связи» от 16.02.95 № 15-ФЗ, «Об электронной цифровой подписи» от 10.01.02 № 1-ФЗ, «Об ав¬торском праве и смежных правах» от 09.07.93 № 5351-1, «О право¬ вой охране программ для электронных вычислительных машин и баз данных» от 23.09.92 № 3523-1 (ст. 4 определяет условие при¬ знания авторского права — знак © с указанием правообладателя и года первого выпуска продукта в свет; ст. 18 — защиту прав на программы для ЭВМ и базы данных путем выплаты компенсации в размере от 5000 до 50 000 минимальных размеров оплаты труда при нарушении этих прав с целью извлечения прибыли или пу¬тем возмещения причиненных убытков, в сумму которых включа¬ются полученные нарушителем доходы). Термины и определения системы защиты информации Утечка конфиденциальной информации – это проблема информационной безопасности, неподконтрольная владельцу, которая предполагает, что политика информационной безопасности допускает выход данных за пределы информационных систем или лиц, которые по долгу службы имеют доступ к данной информации. Утечка информации может быть следствем разглашения конфиденциальной информации (защита информации от утечки путем жесткой политики информационной безопасности и правовой защиты информации по отношению к персоналу), уходом данных по техническим каналам (проблемы информационной безопасности решаются с помощью политики информационной безопасности, направленной на повышение уровня компьютерной безопасности, а также защита информации от утечки обеспечивается здесь аппаратной защитой информации и технической защитой информации, обеспечивающие безопасное надежное взаимодействие баз данных и компьютерных сетей), несанкционированного доступа к комплексной системе защиты информации и конфиденциальным данным. Несанкционированный доступ – это противоправное осознанное приобретение секретными данными лицами, не имеющими права доступа к данным. В этом случае обеспечение защиты информации (курсовая работа) лежит на плечах закона о защите информации. Защита информации от утечки через наиболее распространенные пути несанкционированного доступа Любая комплексная система защиты информации после того, как производится аудит информационной безопасности объекта, начинает опираться на наиболее распространенные пути перехвата конфиденциальных данных, поэтому их важно знать, для того чтобы понимать, как разрабатывается комплексная система защиты информации. Проблемы информационной безопасности в сфере технической защиты информации:
Перехват электронных излучений. Проблема решается обеспечением защиты информации, передаваемой по радиоканалам связи и обмена данными информационной системы;
Принудительное электромагнитное облучение (подсветка) линий связи с целью получения паразитной модуляции несущей. Проблема решается с помощью инженерной защитой информацией или физическая защита информации, передаваемой по связевым кабельным линиям передачи данных. Сюда также относится защита информации в локальных сетях, защита информации в интернете и технические средства информационной безопасности;
применение подслушивающих устройств;
дистанционное фотографирование, защита информации реферат;
перехват акустических излучений и восстановление текста принтера;
копирование носителей информации с преодолением мер защиты;
маскировка под зарегистрированного пользователя;
маскировка под запросы системы;
использование программных ловушек;
использование недостатков языков программирования и операционных систем;
незаконное подключение к аппаратуре и линиям связи специально разработанных аппаратных средств, обеспечивающих доступ информации;
злоумышленный вывод из строя механизмов защиты;
расшифровка специальными программами зашифрованной: информации;
информационные инфекции;
реферат средства защиты информации
Вышеперечисленные пути утечки информации по оценке информационной безопасности требуют высокого уровня технических знаний для того чтобы использовать наиболее эффективные методы и системы защиты информации, кроме этого необходимо обладать высоким уровнем аппаратных и программных средств защиты информации, так как взломщик, охотящийся за ценными сведениями, не пожалеет средств для того, чтобы обойти защиту и безопасность информации системы. Например, физическая защита информации предотвращает использование технических каналов утечки данных к злоумышленнику. Причина, по которой могут появиться подобные «дыры» - конструктивные и технические дефекты решений защиты информации от несанкционированного доступа, либо физический износ элементов средств обеспечения информационной безопасности. Это дает возможность взломщику устанавливать преобразователи, которые образуют некие принципы действующего канала передачи данных, и способы защиты информации должны предусматривать и идентифицировать подобные «жучки». Средства обеспечения информационной безопасности от вредоносного ПО К сожалению, Закон о защите информации работает только в случае, когда нарушитель чувствует и может понести ответственность за несанкционированный обход службы защиты информации. Однако, сегодня существует и постоянно создается гигантское количество вредоносного и шпионского ПО, которое преследует целью порчу информации в базах данных и, хранящихся на компьютерах документов. Огромное количество разновидностей таких программ и их постоянное пополнение рядов не дает возможности раз и навсегда решить проблемы защиты информации и реализовать универсальную систему программно аппаратной защиты информации, пригодной для большинства информационных систем. Вредоносное программное обеспечение, направленное на нарушение системы защиты информации от несанкционированного доступа можно классифицировать по следующим критериям: Логическая бомба используется для уничтожения или нарушения целостности информации, однако, иногда ее применяют и для кражи данных. Логическая бомба является серьезной угрозой, и информационная безопасность предприятия не всегда способна справиться с подобными атаками, ведь манипуляциями с логическими бомбами пользуются недовольные служащие или сотрудники с особыми политическими взглядами, то есть, информационная безопасность предприятия подвергается не типовой угрозе, а непредсказуемой атаке, где главную роль играет человеческий фактор. Например, есть реальные случаи, когда предугадавшие свое увольнение программисты вносили в формулу расчета зарплаты сотрудников компании корректировки, вступающие в силу сразу после того, как фамилия программиста исчезает из перечня сотрудников фирмы. Как видите, ни программные средства защиты информации, ни физическая защита информации в этом случае на 100% сработать не может. Более того, выявить нарушителя и наказать по всей строгости закона крайне сложно, поэтому правильно разработанная комплексная защита информации способна решить проблемы защиты информации в сетях. Троянский конь – это программа, запускающаяся к выполнению дополнительно к другим программным средствам защиты информации и прочего ПО, необходимого для работы. То есть, троянский конь обходит систему защиты информации путем завуалированного выполнения недокументированных действий. Такой дополнительный командный блок встраивается в безвредную программу, которая затем может распространяться под любым предлогом, а встроенный дополнительный алгоритм начинает выполняться при каких-нибудь заранее спрогнозированных условиях, и даже не будет замечен системой защиты информации, так как защита информации в сетях будет идентифицировать действия алгоритма, работой безвредной, заранее документированной программы. В итоге, запуская такую программу, персонал, обслуживающий информационную систему подвергает опасности компанию. И опять виной всему человеческий фактор, который не может на 100% предупредить ни физическая защита информации, ни любые другие методы и системы защиты информации. Вирус – это специальная самостоятельная программа, способная к самостоятельному распространению, размножению и внедрению своего кода в другие программы путем модификации данных с целью бесследного выполнения вредоносного кода. Существует специальная защита информации от вирусов! Обеспечение безопасности информационных систем от вирусных атак традиционно заключается в использовании такой службы защиты информации, как антивирусное ПО и сетевые экраны. Эти программные решения позволяют частично решить проблемы защиты информации, но, зная историю защиты информации, легко понять, что установка системы защиты коммерческой информации и системы защиты информации на предприятии на основе антивирусного ПО сегодня еще не решает проблему информационной безопасности общества завтра. Для повышения уровня надежности системы и обеспечения безопасности информационных систем требуется использовать и другие средства информационной безопасности, например, организационная защита информации, программно аппаратная защита информации, аппаратная защита информации. Вирусы характеризуются тем, что они способны самостоятельно размножаться и вмешиваться в вычислительный процесс, получая возможность управления этим процессом. то есть, если Ваша программно аппаратная защита информации пропустила подобную угрозу, то вирус, получив доступ к управлению информационной системой, способен автономно производить собственные вычисления и операции над хранящейся в системе конфиденциальной информацией. Наличие паразитарных свойств у вирусов позволяет им самостоятельно существовать в сетях сколь угодно долго до их полного уничтожения, но проблема обнаружения и выявления наличия вируса в системе до сих пор не может носить тотальный характер, и ни одна служба информационной безопасности не может гарантировать 100-процентную защиту от вирусов, тем более, что информационная безопасность государства и любой другой способ защиты информации контролируется людьми. Червь – программа, передающая свое тело или его части по сети. Не оставляет копий на магнитных носителях и использует все возможные механизмы для передачи себя по сети и заражения атакуемого компьютера. Рекомендацией по защите информации в данном случае является внедрение большего числа способов защиты информации, повышение качества программной защиты информации, внедрение аппаратной защиты информации, повышение качества технических средств защиты информации и в целом развитие комплексной защиты информации информационной системы. Перехватчик паролей – программный комплекс для воровства паролей и учетных данных в процессе обращения пользователей к терминалам аутентификации информационной системы. Программа не пытается обойти службу информационной безопасности напрямую, а лишь совершает попытки завладеть учетными данными, позволяющими не вызывая никаких подозрений совершенно санкционировано проникнуть т информационную систему, минуя службу информационной безопасности, которая ничего не заподозрит. Обычно программа инициирует ошибку при аутентификации, и пользователь, думая, что ошибся при вводе пароля повторяет ввод учетных данных и входит в систему, однако, теперь эти данные становятся известны владельцу перехватчика паролей, и дальнейшее использование старых учетных данных небезопасно. Важно понимать, что большинство краж данных происходят не благодаря хитроумным способам, а из-за небрежности и невнимательности, поэтому понятие информационной безопасности включает в себя: информационную безопасность (лекции), аудит информационной безопасности, оценка информационной безопасности, информационная безопасность государства, экономическая информационная безопасность и любые традиционные и инновационные средства защиты информации.
Методы и средства информационной безопасности, защита информации в компьютерных сетях Одним из методов защиты информации является создание физической преграды пути злоумышленникам к защищаемой информации (если она хранится на каких-либо носителях). Управление доступом – эффективный метод защиты информации, регулирующий использование ресурсов информационной системы, для которой разрабатывалась концепция информационной безопасности. Методы и системы защиты информации, опирающиеся на управление доступом, включают в себя следующие функции защиты информации в локальных сетях информационных систем: Информационная безопасность сети и информационная безопасность общества в шифровании данных! Механизмами шифрования данных для обеспечения информационной безопасности общества является криптографическая защита информациипосредством криптографического шифрования. Криптографические методы защиты информации применяются для обработки, хранения и передачи информации на носителях и по сетям связи. Криптографическая защита информации при передаче данных на большие расстояния является единственно надежным способом шифрования. Криптография – это наука, которая изучает и описывает модель информационной безопасности данных. Криптография открывает решения многих проблем информационной безопасности сети: аутентификация, конфиденциальность, целостность и контроль взаимодействующих участников. Термин «Шифрование» означает преобразование данных в форму, не читабельную для человека и программных комплексов без ключа шифрования-расшифровки. Криптографические методы защиты информации дают средства информационной безопасности, поэтому она является частью концепции информационной безопасности. Криптографическая защита информации (конфиденциальность) Цели защиты информации в итоге сводятся к обеспечению конфиденциальности информации и защите информации в компьютерных системах в процессе передачи информации по сети между пользователями системы. Защита конфиденциальной информации, основанная на криптографической защите информации, шифрует данные при помощи семейства обратимых преобразований, каждое из которых описывается параметром, именуемым «ключом» и порядком, определяющим очередность применения каждого преобразования. Важнейшим компонентом криптографического метода защиты информации является ключ, который отвечает за выбор преобразования и порядок его выполнения. Ключ – это некоторая последовательность символов, настраивающая шифрующий и дешифрующий алгоритм системы криптографической защиты информации. Каждое такое преобразование однозначно определяется ключом, который определяет криптографический алгоритм, обеспечивающий защиту информации и информационную безопасность информационной системы. Один и тот же алгоритм криптографической защиты информации может работать в разных режимах, каждый из которых обладает определенными преимуществами и недостатками, влияющими на надежность информационной безопасности России и средства информационной безопасности. Основы информационной безопасности криптографии (Целостность данных) Защита информации в локальных сетях и технологии защиты информации наряду с конфиденциальностью обязаны обеспечивать и целостность хранения информации. То есть, защита информации в локальных сетях должна передавать данные таким образом, чтобы данные сохраняли неизменность в процессе передачи и хранения. Для того чтобы информационная безопасность информации обеспечивала целостность хранения и передачи данных необходима разработка инструментов, обнаруживающих любые искажения исходных данных, для чего к исходной информации придается избыточность. Информационная безопасность в России с криптографией решает вопрос целостности путем добавления некой контрольной суммы или проверочной комбинации для вычисления целостности данных. Таким образом, снова модель информационной безопасности является криптографической – зависящей от ключа. По оценке информационной безопасности, основанной на криптографии, зависимость возможности прочтения данных от секретного ключа является наиболее надежным инструментом и даже используется в системах информационной безопасности государства. Как правило, аудит информационной безопасности предприятия, например, информационной безопасности банков, обращает особое внимание на вероятность успешно навязывать искаженную информацию, а криптографическая защита информации позволяет свести эту вероятность к ничтожно малому уровню. Подобная служба информационной безопасности данную вероятность называет мерой имитостойкости шифра, или способностью зашифрованных данных противостоять атаке взломщика. Защита информации и государственной тайны (Аутентификация криптографической защиты информации) Защита информации от вирусов или системы защиты экономической информации в обязательном порядке должны поддерживать установление подлинности пользователя для того, чтобы идентифицировать регламентированного пользователя системы и не допустить проникновения в систему злоумышленника, о ч ем Вы можете прочитать любой реферат средства защиты информации. Проверка и подтверждение подлинности пользовательских данных во всех сферах информационного взаимодействия – важная составная проблема обеспечения достоверности любой получаемой информации и системы защиты информации на предприятии. Информационная безопасность банков особенно остро относится к проблеме недоверия взаимодействующих друг с другом сторон, где в понятие информационной безопасности ИС включается не только внешняя угроза с третьей стороны, но и угроза информационной безопасности (лекции) со стороны пользователей. Понятие информационной безопасности. Цифровая подпись Иногда пользователи ИС хотят отказаться от ранее принятых обязательств и пытаются изменить ранее созданные данные или документы. Доктрина информационной безопасности РФ учитывает это и пресекает подобные попытки. Защита конфиденциальной информации с использованием единого ключа невозможно в ситуации, когда один пользователь не доверяет другому, ведь отправитель может потом отказаться от того, что сообщение вообще передавалось. Далее, не смотря на защиту конфиденциальной информации, второй пользователь может модифицировать данные и приписать авторство другому пользователю системы. Естественно, что, какой бы не была программная защита информации или инженерная защита информации, истина установлена быть не может в данном споре. Цифровая подпись в такой системе защиты информации в компьютерных системах является панацеей проблемы авторства. Защита информации в компьютерных системах с цифровой подписью содержит в себе 2 алгоритма: для вычисления подписи и для ее проверки. Первый алгоритм может быть выполнен лишь автором (см. Рекомендации по защите информации), а второй – находится в общем доступе для того, чтобы каждый мог в любой момент проверить правильность цифровой подписи (см. Рекомендации по защите информации). Криптографическая защита и безопасность информации. Криптосистема Криптографическая защита и безопасность информации или криптосистема работает по определенному алгоритму и состоит из одного и более алгоритмов шифрования по специальным математическим формулам. Также в систему программной защиты информации криптосистемы входят ключи, используемые набором алгоритмов шифрования данных, алгоритм управления ключами, незашифрованный текст и шифртекст. Работа программы для защиты информации с помощью криптографии, согласно доктрине информационной безопасности РФ сначала применяет к тексту шифрующий алгоритм и генерирует ключ для дешифрования. После этого шифртекст передается адресату, где этот же алгоритм расшифровывает полученные данные в исходный формат. Кроме этого в средствах защиты компьютерной информации криптографией включают в себя процедуры генерации ключей и их распространения. Симметричная или секретная методология криптографии (Технические средства защиты информации). Защита информации в России В этой методологии технические средства защиты информации, шифрования и расшифровки получателем и отправителем используется один и тот же ключ, оговоренный ранее еще перед использованием криптографической инженерной защиты информации. В случае, когда ключ не был скомпрометирован, в процессе расшифровке будет автоматически выполнена аутентификация автора сообщения, так как только он имеет ключ к расшифровке сообщения (Защита информации - Реферат). Таким образом, программы для защиты информации криптографией предполагают, что отправитель и адресат сообщения – единственные лица, которые могут знать ключ, и компрометация его будет затрагивать взаимодействие только этих двух пользователей информационной системы. Проблемой организационной защиты информации в этом случае будет актуальна для любой криптосистемы, которая пытается добиться цели защиты информации или защиты информации в Интернете, ведь симметричные ключи необходимо распространять между пользователями безопасно, то есть, необходимо, чтобы защита информации в компьютерных сетях, где передаются ключи, была на высоком уровне. Любой симметричный алгоритм шифрования криптосистемы программно аппаратного средства защиты информации использует короткие ключи и производит шифрование очень быстро, не смотря на большие объемы данных, что удовлетворяет цели защиты информации (защиты банковской информации). Информационно психологическая безопасность, где используется симметричная методология работы защиты информации, обладает следующими средствами:
Kerberos – это алгоритм аутентификации доступа к сетевым ресурсам, использующий центральную базу данных копий секретных ключей всех пользователей системы защиты информации и информационной безопасности, а также защиты информации на предприятии (скачать защита информации).
Многие сети банкоматов являются примерами удачной системы информационной безопасности (курсовая) и защиты информации (реферат), и являются оригинальными разработками банков, поэтому такую информационную безопасность скачать бесплатно невозможно – данная организация защиты информации не продается!
Открытая асимметричная методология защиты информации. Защита информации в России Зная историю защиты информации, можно понять, что в данной методологии ключи шифрования и расшифровки разные, хотя они создаются вместе. В такой системе защиты информации (реферат) один ключ распространяется публично, а другой передается тайно (Реферат на тему защита информации), потому что однажды зашифрованные данные одним ключом, могут быть расшифрованы только другим. Все асимметричные криптографические средства защиты информации являются целевым объектом атак взломщиком, действующим в сфере информационной безопасности путем прямого перебора ключей. Поэтому в такой информационной безопасности личности или информационно психологической безопасности используются длинные ключи, чтобы сделать процесс перебора ключей настолько длительным процессом, что взлом системы информационной безопасности (курсовая) потеряет какой-либо смысл. Совершенно не секрет даже для того, кто делает курсовую защиту информации, что для того чтобы избежать медлительности алгоритмов асимметричного шифрования создается временный симметричный ключ (Реферат на тему защита информации) для каждого сообщения, а затем только он один шифруется асимметричными алгоритмами. 26 Основные принципы разработки политики информационной безопасности.
Политика информационной безопасности – это высокоуровневый документ, который включает в себя принципы и правила, определяющие и ограничивающие определенные виды деятельности объектов и участников системы информационной безопасности, направленные на защиту информационных ресурсов организации. Как известно, стратегическое планирование позволяет определить основные направления деятельности организации, связав воедино маркетинг, производство и финансы. Долгосрочный стратегический план позволяет компании выстроить все свои бизнес-процессы с учетом микро и макросреды для достижения наилучших финансовых показателей и темпов экономического роста. Важной составляющей в стратегическом планировании является учет требований политики информационной безопасности, которые должны быть краеугольным камнем при определении среднесрочных и долгосрочных целей и задач организации. С ростом компании и пересмотром планов политика также должна пересматриваться. Низкоуровневые документы информационной безопасности необходимо пересматривать в соответствии с реализацией краткосрочных планов. Политика информационной безопасности неразрывно связана с развитием компании, ее стратегическим планированием, она определяет общие принципы и порядок обеспечения информационной безопасности на предприятии. Политика информационной безопасности тесно интегрируется в работу предприятия на всем этапе его существования. Все решения, предпринимаемые на предприятии, должны учитывать её требования. Эффективное обеспечение требуемого уровня информационной безопасности организации возможно только при наличии формализованного и системного подхода к выполнению мер по защите информации. Целью разработки политики информационной безопасности организации является создание единой системы взглядов и понимания целей, задач и принципов обеспечения информационной безопасности.
Конкретные проекты необходимых документов каждого типа определяются в ходе обследования существующего уровня информационной безопасности Заказчика, её организационной структуры и основных бизнес процессов.