

Системы распознавания речи.
Речь выступает в роли основного средства коммуникации между людьми и поэтому речевое общение считается одним из важнейших компонентов системы искусственного интеллекта. Распознавание речи представляет собой процесс преобразования акустического сигнала, формируемого на выходе микрофона или телефона, в последовательность слов.
Более сложной задачей является задача понимания речи, которая сопряжена с выявлением смысла акустического сигнала. В этом случае выход подсистемы распознавания речи служит входом подсистемы понимания высказываний. Автоматическое распознавание речи (системы АРР) является одним из направлений технологий обработки естественного языка.
Автоматическое распознавание речи применяется при автоматизации ввода текстов в ЭВМ, при формировании устных запросов к базам данных или информационно-поисковым системам при формировании устных команд различным интеллектуальным устройствам.
Основные понятия систем распознавания речи.
Системы распознавания речи характеризуются многими параметрами.
Одним из основных параметров является ошибка распознавания слов (ОРС). Этот параметр представляет собой отношение количества нераспознанных слов к общему количеству произнесенных слов.
Другими параметрами, характеризующими системы автоматического распознавания речи, являются:
размер словаря,
режим речи,
стиль речи,
предметная область,
дикторозависимость,
уровень акустических шумов,
качество входного канала.
В зависимости от размера словаря системы АРР подразделяются на три группы:
- с малым размером словаря (до 100 слов),
- со средним размером словаря (от 100 слов до нескольких тысяч слов),
- с большим размером словаря (более 10 000 слов).
Режим речи характеризует способ произнесения слов и фраз. Выделяют системы распознавания слитной речи и системы, позволяющие распознавать только изолированные слова речи. В режиме распознавания изолированных слов требуется, чтобы диктор делал краткие паузы между словами.
По стилю речи системы АРР подразделяются на две группы: системы детерминированной речи и системы спонтанной речи.
В системах распознавания детерминированной речи диктор воспроизводит речь, следуя грамматическим правилам языка. Спонтанная речь характеризуется нарушениями грамматических правил и ее сложнее распознавать.
В зависимости от предметной области выделяют системы АРР, ориентированные на применение в узкоспециальных областях (например, доступ к базам данных) и системы АРР с неограниченной областью применения. Последние требуют наличия большого объема словаря и должны обеспечивать распознавание спонтанной речи.
Многие системы автоматического распознавания речи являются дикторозависимыми. Это предполагает предварительную настройку системы на особенности произношения конкретного диктора.
Сложность решения задачи распознавания речи объясняется большой изменчивостью акустических сигналов. Эта изменчивость объясняется несколькими причинами:
Во-первых, различной реализацией фонем – основных единиц звукового строя языка. Изменчивость реализации фонем вызвана влиянием соседних звуков в потоке речи. Оттенки реализации фонем, обусловленные звуковым окружением, называют аллофонами.
Во-вторых, положением и характеристиками акустических приемников.
В-третьих, изменениями параметрами речи одного и того же диктора, которые обусловлены различным эмоциональным состоянием диктора, темпом его речи.
На рисунке представлены основные компоненты системы распознавания речи:
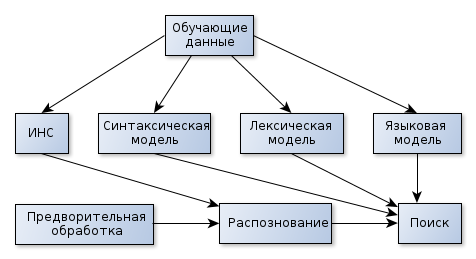
Оцифрованный речевой сигнал поступает на блок предварительной обработки, где осуществляется выделение признаков, необходимых для распознавания звуков. Распознавание звуков часто осуществляется с помощью моделей искусственных нейронных сетей. Выделенные звуковые единицы используют в дальнейшем для поиска последовательности слов, в наибольшей степени соответствующей входному речевому сигналу.
Поиск последовательности слов выполняется с помощью акустической, лексической и языковой моделей. Параметры моделей определяют по обучающим данным на основе соответствующих алгоритмов обучения.
Синтез речи по тексту. Основные понятия
Во многих случаях создание систем искусственного интеллекта с элементами ея-общения требуют вывода сообщений в речевой форме. На рисунке представлена структурная схема интеллектуальной вопросно-ответной системы с речевым интерфейсом:
Рисунок 1.
Кусок лекций взять у Олега
Рассмотрим особенности эмпирического подхода на примере распознавания частей речи. Задача состоит в присвоении словам предложения меток: существительное, глагол, предлог, прилагательное и тому подобное. Кроме этого, необходимо определять некоторые дополнительные признаки существительных и глаголов. Например, для существительного – число, а для глагола – форму. Формализуем задачу.
Представим предложение в виде последовательности слов: W=w1 w2…wn, где wn – случайные переменные, каждая из которых получает одно из возможных значений, принадлежащих словарю языка. Последовательность меток, назначаемых словам предложения, представим последовательностью X=x1 x2 … xn, где xn – случайные переменные, значения которых определены на множестве возможных меток.
Тогда задача распознавания частей речи состоит в поиске наиболее вероятной последовательности меток x1, x2, …, xn по заданной последовательности слов w1, w2, …, wn. Иными словами, необходимо найти такую последовательность меток X*=x1 x2 … xn, которая обеспечивает максимум условной вероятности P(x1, x2, …, xn| w1 w2.. wn).
Перепишем условную вероятность P(X| W) в следующем виде P(X| W)=P(X,W) / P(W). Так как требуется найти максимум условной вероятности P(X,W) по переменной X, получим X*=argx max P(X,W). Совместную вероятность P(X,W) можно записать в виде произведения условных вероятностей: P(X,W)=произведение по и-1 до н от P(xi|x1,…,xi-1, w1,…,wi-1) P(wi|x1,…,xi-1, w1,…,wi-1). Непосредственный поиск максимума данного выражения представляет собой сложную задачу, так как при больших значениях n поисковое пространство становится очень большим. Поэтому вероятности, которые записаны в этом произведении, аппроксимируют более простыми условными вероятностями: P(xi|xi-1) P(wi|wi-1). В этом случае полагают, что значение метки xi связано только с предыдущей меткой xi-1 и не зависит от более ранних меток, а также что вероятность слова wi определяется только текущей меткой xi. Указанные предположения называют марковскими, а для решения задачи привлекают теорию марковских моделей. С учетом марковских предположений можно записать:
X*= arg x1, …, xn max Пi=1n P(xi|xi-1) P(wi|wi-1)
Где условные вероятности оцениваются на множестве обучающих данных
Поиск последовательности меток Х* осуществляют с помощью алгоритма динамического программирования Витерби. Алгоритм Витерби может рассматриваться как вариант алгоритма поиска на графе состояний, где вершинам соответствуют метки слов.
Характерно, что для любой текущей вершины множество дочерних меток всегда одно и то же. Более того, для каждой дочерней вершины множества родительских вершин тоже совпадают. Это объясняется тем, что на графе состояний осуществляются переходы с учетом всех возможных сочетаний меток. Предположение Маркова обеспечивают существенное упрощение задачи распознавания частей речи при сохранении высокой точности назначения меток словам.
Так, при наличии 200 меток точность назначения примерно равна 97%. Долгое время имперический анализ выполнялся с помощью стохастических контекстно-свободных грамматик. Однако для них характерен существенный недостаток. Он заключается в том, что различным грамматическим разборам могут назначаться одинаковые вероятности. Это происходит из-за того, что вероятность грамматического разбора представляется в виде произведения вероятностей правил, участвующих в разборе. Если в ходе разбора используются различные правила, характеризуемые одинаковыми вероятностями, то это и порождает указанную проблему. Лучшие результаты дает грамматика, учитывающая лексику языка.
В этом случае в правила включаются необходимые лексические сведения, которые обеспечивают различные значения вероятности для одного и того же правила в разных лексических окружениях. Имперический синтаксический анализ в большей степени соответствует распознаванию образов, чем традиционному грамматическому разбору в его классическом понимании.
Сравнительные исследования показали, что правильность имперического грамматического разбора приложений естественного языка оказывается выше по сравнению с традиционным грамматическим разбором.