

52. Особливості процесів в ос unix.
Ядро UNIX існує для виконання потреб процесів. З точки зору процесів, ядро це витрати, з якими треба миритись. З точки зору ядра, процеси – це каталогізовані структури даних, над якими за певними правилами виконуються маніпуляції.
Процес – це програма під час виконання в деякий момент часу довільної програми може відповідати один або декілька процесів, або не відповідати жодний. Процес – це об’єкт, що враховується в спеціальній таблиці ядра системи.
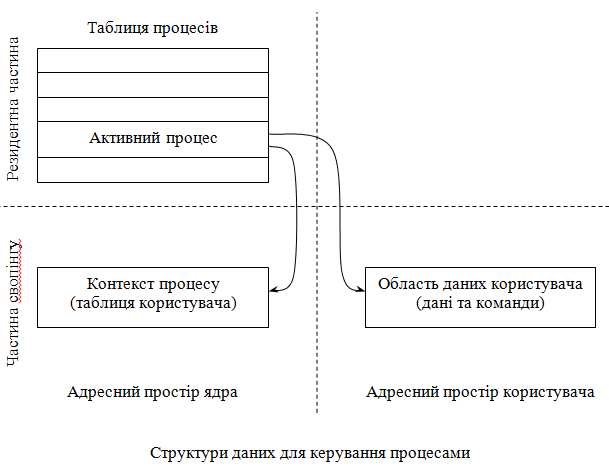
Найбільш важлива інформація про процес зберігається в двох місцях:
- в таблиці процесів;
- в таблиці користувача (контекст процесу).
Перша – завжди знаходиться в пам’яті і містить на кожний процес по одному елементу, в якому відображається точний стан процесу:
– розташування процесу (адреса в пам’яті або адреса свопінгу);
– розмір;
– ідентифікатори процесу;
– ідентифікатори користувача що запустив процес.
Менш актуальна інформація про процес зберігається в таблиці користувача. Така таблиця існує для кожного активного процесу і тільки до неї можуть безпосередньо звертатись програми ядра. При всіх ситуаціях, що виникають при виконанні процесу, відбувається звертання до його таблиці. Створення процесу включає ініціалізацію відповідного контексту та сегмента таблиці процесів а також формування даних та тексту цього процесу. Зміна стану (виконання, очікування, повернення в пам’ять та інше) та отримання стану від паралельного процесу – все це фіксується в таблиці процесів.
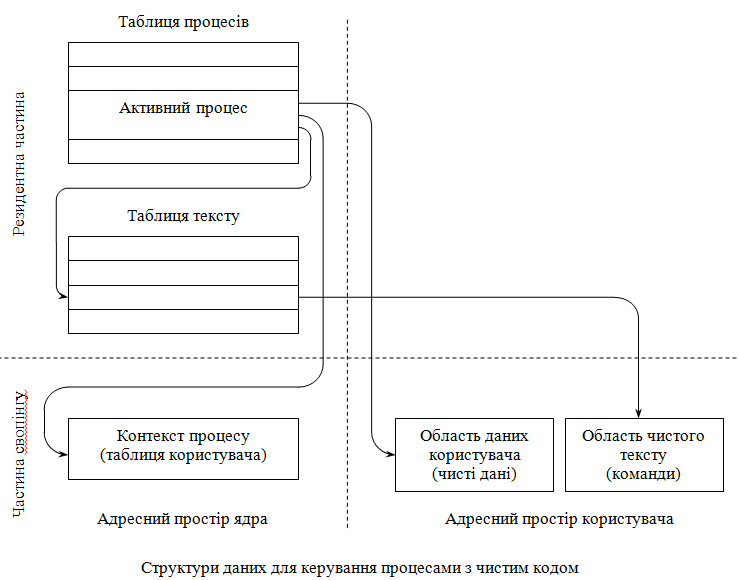
Якщо процес складається з чистих машинних кодів (дані існують окремо), то структура даних буде наступна.
Після завершення деякого процесу відповідний елемент таблиці звільняється для того, щоби потім його використовували для інших процесів.
Таблиця процесів резидентна в основній пам’яті, що забезпечує ядру можливість реагувати на зміни стану процесу, що тимчасово зберігається на диску. Ядро резервує по одному контексту на кожний активний процес. В цій таблиці інформація, що необхідна під час виконання процесу. Якщо процес призупинено, контекст стає недоступним та не модифікованим. Окрім того, оскільки ця структура даних є складовою частиною області даних кожного процесу, то при виконанні свопінгу переписується на диск разом з усім образом процесу.
Біжуча інформація про процес в основному вміщується в його контексті. Сюди записуються:
– ідентифікаційні номера користувача і групи, що призначені для визначення привілеїв доступу до файлів;
– посилання на системну таблицю файлів для всіх відкритих процесом файлів;
– покажчик на індексний дескриптор біжучого каталогу в таблиці індексних дескрипторів;
– список реакцій на різні сигнали.
Для створення нових, існуючі процеси використовують два основних механізми:
Fork – системний виклик (команда) для створення процесом своєї власної копії; це єдиний спосіб для збільшення числа процесів; після його виконання є два процеси, породжуючий (батьківський, джерело) та породжений (дочірній, приймач).
Exec – для перетворення процесу, що ініціював цей системний виклик. У цьому випадку міняється не кількість процесів, а їх якість.
Звичайно для створення дочірнього процесу з новим ідентифікатором послідовно викликають fork, а потім exec. Саме в такий спосіб запускаються інтерпретатори shell та довільна викликана програма. Пара fork–exec, як правило, працює разом із системним викликом wait. Wait дозволяє процесу–батьку дочекатись завершення породженого ним процесу