

Сортировка посредством слияния списков
Алгоритмы слияния имеют два существенных недостатка:
Большой расход памяти для вспомогательной рабочей области.
Необходимость большого числа перемещений записей.
Э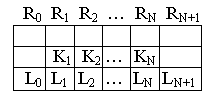 ти
недостатки можно устранить, создав из
сортируемого файла подобие связанного
списка, для чего каждая запись Ri
должна иметь “поле связи” Li,
в котором будет храниться № записи,
следующей за данной записью в порядке
возрастания ключей.
ти
недостатки можно устранить, создав из
сортируемого файла подобие связанного
списка, для чего каждая запись Ri
должна иметь “поле связи” Li,
в котором будет храниться № записи,
следующей за данной записью в порядке
возрастания ключей.
После сортировки L0=№ записи с наименьшим ключом.
Алгоритм L.
Предполагается, что записи R1,…,RN содержат ключи k1,…,kN и поля связи L1,…,LN, в которых могут храниться числа от -(N+1) до (N+1). В начале и в конце файла имеются искусственные записи R0 и RN+1 с полями связи L0 и LN+1. Этот алгоритм сортировки списков устанавливает поля связи таким образом, что записи оказываются связанными в возрастающем порядке.
После завершения сортировки L0 указывает на запись с наименьшим ключом, при 1≤k≤N связь Lk указывает на запись, следующую за Rk , а если Rk – запись с наибольшим ключом, то Lk=0. В процессе выполнения этого алгоритма записи R0 и RN+1 служат “головами” двух линейных списков, подсписки которых в данный момент сливаются.
Отрицательная связь означает коненц подсписка, о котором известно, что он упорядочен; нулевая связь означает конец списка. Предпологается, что N≥2.
Через “|Ls|←p” обозначена операция присвоить Ls значение р или –p, сохранив прежний знак Ls.
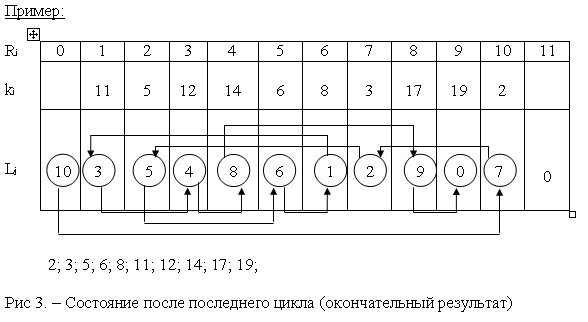
L1. [Подготовить два списка.] Установить L0←1, LN+1←2, Li← -(i+2)
при 1≤i≤N-2 и LN-1←LN←0.
Мы создаём два списка, содержащие соответственно записи
R1,R3,R5,… и R2,R4,R6,…; отрицительные связи говорят о том,
что каждый упорядоченный “подсписок” состоит всего лишь из
одного элемента. Другой способ выполнить этот шаг, извлекая пользу из
упорядоченности, которая могла присутствовать в исходных
данных.
L2. [Начать новый просмотр.] Установить s←0, t←N+1, p←Ls, q←Lt.
Если q=0, то работа алгоритма завершена.
При каждом просмотре p и q пробегают по спискам, которые
подвергаются слиянию; s обычно указывает на последнюю
обработанную запись текущего подсписка, а t – на конец только
что выведенного подсписка.
L3. [Сравнить kp : kq.] Если kp>kq, то перейти к L6.
L4. [Продвинуть p.] Установить |Ls|←p, s←p, p←Lp. Если p>0, то возвратиться к шагу L3.
L5. [Закончить под список.] Установить Ls←q, s←t. Затем установить t←q и q←Lq один или более раз, пока не станет q≤0, после чего перейти к шагу L8.
L6. [Продвинуть q.] (Шаги L6 и L7 двойственны по отношению к L4 и L5.) Установить |Ls|←q, s←q, q←Lq. Если q>0, то возвратиться к шагу L3.
L7. [Закончить подсписок.] Установить Ls ←p, s←t. Затем установить
t←p и p←Lp один или более раз, пока не станет p≤0.
L8. [Конец просмотра.] (К этому моменту p≤0 и q≤0, так как оба
указателя подвинулись до конца соответствующих подсписков.)
Установить p← -p, q← -q. Если q=0, то установить |Ls|←p, |Lt|←0
и возвратиться к шагу L2. В противном случае возвратиться к
шагу L3.
9. Алгоритмы поиска данных. Последовательный, двоичный, блочный, интерполяционный, Фибоначчиев поиск.
В алгоритмах поиска присутствует аргумент поиска К. Задача в том, чтобы отыскать запись, имеющую К своим ключом.
Классификация: 1) группы последовательного поиска 2) поиск посредством сравнения ключей (поиск в таблице)(бинарный, Фибоначчи) 3)поиск цифровой 4) хеширование 5) поиск по вторичным ключам.
Последовательный - наиболее простой способ отыскания записи. Состоит в последовательном просмотре и сравнении их ключей с данными.
Бинарный поиск Разыскивается аргумент К в таблице R1....RN, у которых ключи упорядочены k1<=...<=kN.
Идея: 1) Сравнить К со средним ключом в таблице. Результат сравнения определит в какой половине находится запись. Применяя к ней туже процедуру, через log 2N будет установлено есть ли такая запись:
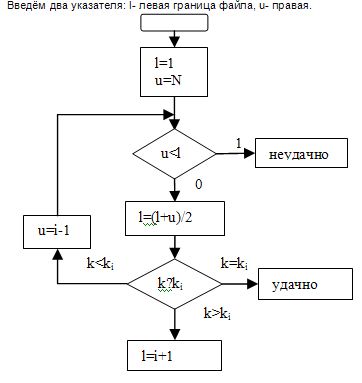
| 7 | 11 | 12| 15 | 18| 19 | 21 | 22 | 25 | 27 | 31 | 35 | 40 |
l u
Метод Фибоначчи. N<=Fk+1 - 1
N – количество элементов в массиве;
k – порядковый номер в дереве Фибоначчи;
Fk+1 – число Фибоначчи;
Если k= 0 или k= 1, то корень дерева равен 0.
Если k>= 2, то корнем является число Fk, левое Fk-1, правое Fk-2
| 0 | 1 | 1| 2 | 3| 5 | 8 | 13 | 21 | 34 |
Алгоритм предназначен для поиска аргумента К в табл записей R1,R2,…,Rn, распсположенных в порядке возрастания ключей К1<K2<…<Kn. Предполагается, что N+1 есть число Фибоначчи Fk+1.Подходящей нач.установкой данный метод можно сделать пригодным для любого N.В алгоритме p и q-последов числа Фибоначчи.

Представьте себе, что Вы ищете слово в словаре. Если нужное слово начинается с буквы 'А', вы наверное начнете поиск где-то в начале словаря. Когда найдена отправная точка для поиска, ваши дальнейшие действия мало похожи на рассмотренные выше методы.Если Вы заметите, что искомое слово должно находиться гораздо дальше открытой страницы, вы пропустите порядочное их количество, прежде чем сделать новую попытку. Это в корне отличается от предыдущих алгоритмов, не делающих разницы между 'много больше' и 'чуть больше'. Мы приходим к алгоритму, называемому интерполяционным поиском: Если известно, что К лежит между Kl и Ku, то следующую пробу делаем на расстоянии (u-l)(K-Kl)/(Ku-Kl) от l, предполагая, что ключи являются числами, возрастающими приблизительно в арифметической прогрессии. Интерполяционный поиск работает за log log N операций, если данные распределены равномерно. Как правило, он используется лишь на очень больших таблицах, причем делается несколько шагов интерполяционного поиска, а затем на малом подмассиве используется бинарный или последовательный варианты.
Блочный поиск Если элементы упорядочены по ключу, то при сканировании списка не требуется чтение каждого элемента. Компьютер мог бы, например, просматривать каждый n-ный элемент в последовательности возрастания ключей. При нахождении элемента с ключом, большим, чем ключ, используемый при поиске, просматриваются последние n-1 элементов, которые были пропущены. Этот способ называется блочным поиском: элементы группируются в блоки, и каждый блок проверяется по одному разу до тех пор, пока ни будет найден нужный блок. Вычисление оптимального для блочного поиска размера блока выполняется следующим образом: в списке, содержащем N элементов, число просмотренных элементов минимально при длине блока, равной N. При этом в среднем анализируется N элементов.
10. Хеширование, хеш-функции. Способы разрешения коллизий.
Хеширование – есть один из методов поиска. Основная проблема хеширования – это проблема однозначности, т.к. возможно совпадение адресов при несовпадающих ключах: ki≠kj.
Коллизия (h(ki)=h(kj)) – это совпадение вычисленных значений адресов в 2-х или более записях файла, имеющих различные значения ключа. Хеширование – это способ вычисления адреса, при которых функция расстановки выдаёт различные значения для различных входных данных.
Существует специальная программа разрешения коллизий
Хеш-функция – это функция расстановки, основанная на использовании метода хеширования и обеспечивающая равномерное заполнение файла.
Хеш-функция. Предположим, что хеш-функция h(k) имеет M различных значений, удовлетворяющих условию 0≤ h(k)<М для всех k. В реальном файле очень много почти одинаковых ключей, поэтому желательно выбрать хеш-функцию, рассеивающую их по таблице. Наиболее распространённые методы:
а)деления; функция хеширования определяется h(k)=k mod M, где k – ключ, М – количество свободных ячеек таблицы(не должно быть кратным 3 и не должно быть равным степени основания СИ ЭВМ).
б)умножения; h(k)=МАk/W,
умножение ключа k на некоторую фиксированную константу А и выбор нескольких цифр из середины результата, W – максимальное число; А – константа не имеющая общих делителей с W, кроме 1;
М равно степени 2.
в) Метод середины квадрата (midsquare technique) предусматривает преобразование ключа в целое число, возведение его в квадрат и возвращение в качестве значения функции последовательности битов, извлеченных из середины полученного числа. Предположим, что ключ есть целое 32-битное число. Тогда следующая хеш-функция извлекает средние 10 бит возведенного в квадрат ключа.
Методы разрешения коллизий.
Разрешение коллизий "открытой адресацией" состоит в том, чтобы полностью отказаться от ссылок и просто просматривать один за другим различные элементы таблицы, пока не будут найдены ключ K или свободная позиция. Не плохо было бы иметь правило, согласно которому каждый ключ K определяет последовательность проб, т.е. последовательность позиций в таблице, которые нужно просматривать всякий раз при вставке или поиске K. Если мы, используя определяемую K последовательность проб, натолкнемся на свободную позицию, то можно сделать вывод, что K нет в таблице, так как та же последовательность проб выполняется каждый раз при обработке данного ключа. Этот общий класс методов У. Петерсон назвал открытой адресацией.(метод случайного зондирования, метод линейного зондирования, метод квадратичного зондирования)
.Метод цепочек. В процессе хеширования возможно появление одинаковых адресов для различных ключей. Способ разрешения таких коллизий состоит в поддерживании М связанных списков по одному на каждый возможный хеш-адрес. Все связи должны содержать поля связей и нужно образовать массив ссылок, которые будут являться головами списков HEAD[i], где i÷1→М. После хеширования ключа выполняется последовательный поиск в списке с номером h(k).
Метод раздельных цепочек
Ключ k one two three four five six seven
Адрес h(k) 3 1 4 1 5 9
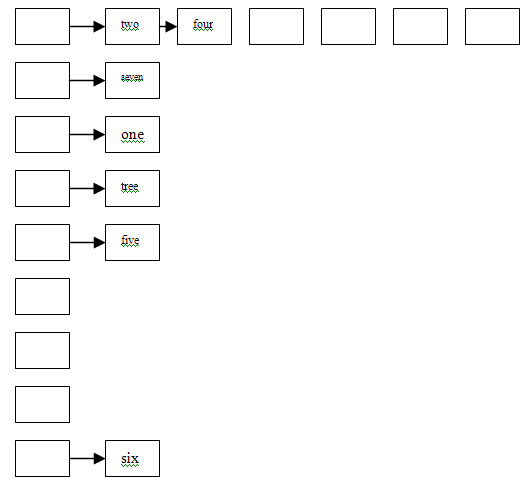
Метод по рассеянной таблицей со сросшимися цепочками. Этот алгоритм позволяет отыскать в таблице из N элементов ключ k. Если ключа нет и таблица не полная, то ключ k вставляется в неё. Элементы таблицы TABLE[i], где 0≤і≤М. Эти элементы могут быть 2-х типов: заняты и свободны. Занятый узел содержит ключевое поле KEY[i], поле связи LINK[i] и т.д.
Метод сросшихся цепочек
two |
|
seven |
|
one |
|
three |
|
five |
|
|
|
|
|
six |
|
four |
|
Алгоритм для этого метода: М – размер таблицы; i – массив элементов; R – вспомогательная переменная.
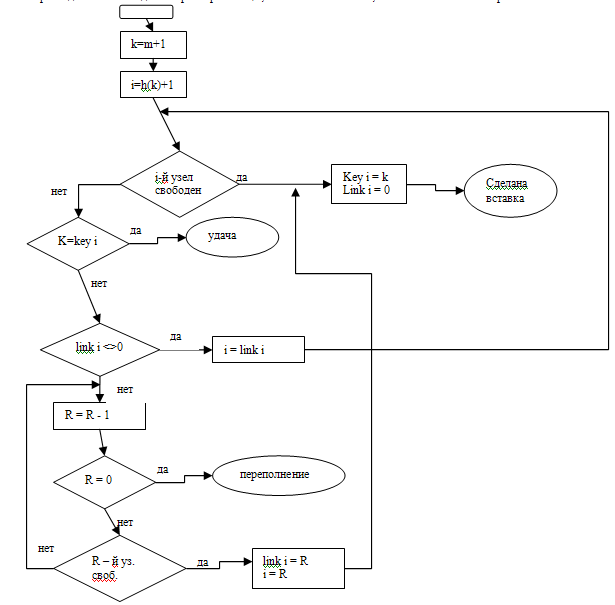
Алгоритм использует хеш-функцию h(k). Для облегчения поиска свободного пространства используют R (R= М+1 для пустой таблицы). Узел TABLE[0] – всегда свободен.
Метод свертывания: Ключ разбивается на части,каждая из которых имеет длину требуемого адреса
187|249|653
Затем части складываются и не учитывается перенос в старшем разряде
187
+ 249
653__
1089 -результат равен 89
Метод гранич свертывания:инвертируются цифры в крайних границах ключа
78
+ 24
_356__
386- результат
Метод преобразования систем исчисления: Ключ, представленный в системе исчисления q, где q=2 или 10 обычно
p>q
возьмем число: 530476 (ключ в десятичном виде)
530476=5*115+3*114+0*113+4*112+7*111=849745
Отсекаем 3 разряда в правой части
Должно попасть в интервал 000 – 999
745-попал в интервал