

Архитектура клиент-сервер, различные реализации архитектуры клиент-сервер, понятие 2-х , 3-х звенных моделей.
Типовые архитектурные решения, используемые при реализации многопользовательских СУБД: телеобработкой, файловым сервером и технологией "клиент/сервер".
Традиционной архитектурой многопользовательских систем раньше считалась схема, получившая название телеобработки, при которой один компьютер с единственным процессором был соединен с несколькими терминалами. При этом вся обработка выполнялась с помощью единственного компьютера, а присоединенные к нему пользовательские терминалы были типичными "неинтеллектуальными" устройствами, не способными функционировать самостоятельно. В последние годы был достигнут существенный прогресс в разработке высокопроизводительных персональных компьютеров и составленных из них сетей. При этом во всей индустрии наблюдается заметная тенденция к децентрализации. Эта тенденция привела к появлению следующих двух типов архитектуры СУБД: технологии файлового сервера и технологии "клиент/сервер".
В среде файлового сервера обработка данных распределена в сети, обычно представляющей собой локальную вычислительную сеть (ЛВС). Файловый сервер содержит файлы, необходимые для работы приложений и самой СУБД. Однако пользовательские приложения и СУБД размещены и функционируют на отдельных рабочих станциях, и обращаются к файловому серверу только по мере необходимости получения доступа к нужным им файлами. Таким образом, файловый сервер функционирует просто как совместно используемый жесткий диск. Архитектура с использованием файлового сервера обладает следующими основными недостатками.
1. Большой объем сетевого трафика.
2. На каждой рабочей станции должна находиться полная копия СУБД.
3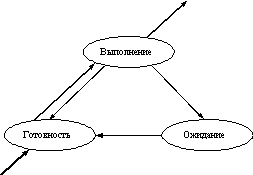 .
Управление параллельной работой,
восстановлением и целостностью
усложняется, поскольку доступ к одним
и тем же файлам могут осуществлять сразу
несколько экземпляров СУБД.
.
Управление параллельной работой,
восстановлением и целостностью
усложняется, поскольку доступ к одним
и тем же файлам могут осуществлять сразу
несколько экземпляров СУБД.
Технология "клиент/сервер" была разработана с целью устранения недостатков, имеющихся в первых двух подходах. В этой технологии используется способ взаимодействия программных компонентов, при котором они образуют единую систему. Сервером называется компьютер или программа, управляющая неким ресурсом. Клиент – компьютер или программа, использующая этот ресурс. Этим ресурсом может быть БД, файловые системы, службы печати, почтовые службы. Соответственно и тип сервера будет сервер БД, файл-сервер, сервер печати, почтовый сервер. При этом совсем не обязательно, чтобы они находились на одном и том же компьютере. На практике принято размещать сервер на одном узле локальной сети, а клиенты — на других узлах.
Положительные стороны данного подхода: удачное сочетание централизованного хранения, обслуживания и коллективного доступа к общей информации
Основные виды технологии распределенной обработки данных архитектуры «клиент-сервер»:
Технология, ориентированная на автономный компьютер. Клиент и сервер размещены на одной ЭВМ. По функциональным возможностям как централизованная СУБД.
Технология, ориентированная на централизованное распределение. Клиент имеет доступ к данным одиночного удаленного сервера. Данные только считываются. Доступ через транзакции и запросы, число которых невелико.
Технология, ориентированная на локальную вычислительную сеть. Единственный сервер обеспечивает доступ к БД. Клиент формулирует запросы на обработку данных. Доступ к базе замедлен.
Технология, ориентированная на изменение данных в одном месте. Реализованы распределенные транзакции. Распределенная СУБД имеет средства работы с противоречивыми запросами.
Технология, ориентированная на изменение данных в нескольких местах. Работа с несколькими серверами ведется с помощью сервера-координатора.
Технология, ориентированная на распределенную СУБД. Обеспечивает независимость клиента от места размещения сервера, глобальную оптимизацию, распределенный контроль целостности базы и распределенное администрирование.
Традиционная двухуровневая архитектура "клиент/сервер"
Деловые приложения для интенсивной работы с данными состоят из четырех основных компонентов: базы данных, алгоритмов проведения транзакций, алгоритмов работы приложения и интерфейса пользователя. Традиционная двухуровневая архитектура "клиент/сервер" предусматривает распределение основных решаемых задач между двумя уровнями. Клиентская часть, или клиент (уровень 1), главным образом отвечает за представление данных на экране компьютера пользователя, а серверная часть, или сервер (уровень 2), — за обеспечение доступа клиента к данным .
Трехуровневая архитектура
Необходимость масштабирования систем по мере развития предприятий стала непреодолимым барьером для традиционной двухуровневой архитектуры "клиент/сервер". В середине 1990-х годов стремительно усложнявшиеся приложения потенциально требовали развертывания их программного обеспечения на сотнях и тысячах компьютеров конечных пользователей. В результате этого при разработке клиентской части четко обозначились две указанные ниже проблемы, препятствующие достижению истинной масштабируемости приложений.
• "Толстый" клиент, для эффективной работы которого требуются значительные вычислительные ресурсы, включая большое пространство на диске, оперативную память и мощность центрального процессора.
• Значительные накладные расходы на администрирование клиентской части приложений.
В 1995 году появился новый вариант модели традиционной двухуровневой архитектуры "клиент/сервер", который был призван решить проблемы масштабируемости приложений. В этой новой архитектуре предлагались три уровня программного обеспечения, каждый из которых может функционировать на разных платформах.
1. Уровень пользовательского интерфейса, который располагается на компьютере конечного пользователя (клиент).
2. Уровень реализации прикладных алгоритмов и средств обработки данных. Этот промежуточный уровень располагается на сервере, который часто называется сервером приложений,
3. СУБД, в которой хранятся данные, необходимые для функционирования промежуточного уровня. Этот уровень может быть реализован на отдельном сервере, который называется сервером базы данных.
Клиент отвечает только за пользовательский интерфейс и, возможно, выполняет некоторую очень простую обработку данных, например проверку введенной информации, поэтому клиентская часть приложения может быть построена с использованием так называемого "тонкого" клиента.
Основные прикладные алгоритмы теперь реализованы на отдельном уровне — на сервере приложений, который физически связан с клиентом и сервером базы данных посредством локальной (Local Area Network — LAN) или распределенной (Wide Area Network — WAN) вычислительной сети. При этом предполагается, что один сервер приложений может обслуживать множество клиентов.
Трехуровневая архитектура имеет многие преимущества перед одно- и двух- уровневой моделями. Ниже перечислены некоторые их них.
• "Тонкий" клиент, для которого требуется менее дорогостоящее аппаратное обеспечение,
• Централизация сопровождения приложений благодаря передаче средств реализации прикладных алгоритмов, применяемых многочисленными конечными пользователями, на единственный сервер приложений. При этом
устраняется необходимость развертывания программного обеспечения на множестве компьютеров, что представляет собой одну из самых сложных задач в двухуровневой модели "клиент/сервер".
• Дополнительная модульность, которая упрощает модификацию или замену программного обеспечения каждого уровня без оказания влияния на остальные уровни.
• Отделение основных средств реализации прикладных алгоритмов от функций базы данных упрощает задачу равномерного распределения нагрузки.
Эта трехуровневая архитектура оказалась более подходящей для некоторых сред — например, для сетей Internet и внутренних сетей компании.
Понятие процесса: параллельные и псевдопараллельные процессы, диаграмма состояний процесса; взаимодействие процессов: синхронизация, взаимоисключение, взаимоблокировка, коммуникация между процессами; реализация мультипрограммирования: прерывания, механизмы реализации, супервизор, системные и пользовательские процессы.
Процессом называется выполняемое приложение, обладающее собственной памятью, описателями файлов и другими системными ресурсами. Потоком называется код, исполняемый внутри процесса. Процесс может иметь как один поток, так и множество параллельно выполняющихся потоков. Все пространство кода и данных процесса доступно всем его потокам. Несколько потоков могут обращаться к одним и тем же глобальным переменным или функциям. Потоками управляет операционная система, и у каждого потока есть свой собственный стек.
Процесс характеризуется контекстом и дескриптором. Состояние регистров и программного счетчика, режим работы процессора, указатели на открытые файлы, информация о незавершенных операциях ввода-вывода и т.д - это контекст процесса. Идентификатор процесса, состояние процесса, данные о степени привилегированности процесса, место нахождения кодового сегмента и др. инф-я - дескриптор процесса.
В многозадачной (многопроцессной) системе процесс может находиться в одном из трех основных состояний: выполнение; ожидание - процесс заблокирован, не может выполняться по своим внутренним причинам, он ждет осуществления некоторого события, например, освобождения какого-либо необходимого ему ресурса; готовность - пассивное состояние процесса, процесс имеет все требуемые для него ресурсы, он готов выполняться, однако процессор занят выполнением другого процесса. Граф состояний процесса показан на рисунке.
Алгоритмы планирования процессов
Планирование процессов включает в себя решение следующих задач:
определение момента времени для смены выполняемого процесса;
выбор процесса на выполнение из очереди готовых процессов;
переключение контекстов "старого" и "нового" процессов.
Основные алгоритмы: алгоритмы, основанные на квантовании, и алгоритмы, основанные на приоритетах.
В соответствии с алгоритмами, основанными на квантовании, смена активного процесса происходит, если:
процесс завершился и покинул систему,
произошла ошибка,
процесс перешел в состояние ОЖИДАНИЕ,
исчерпан квант процессорного времени, отведенный данному процессу.
Другая группа алгоритмов использует понятие "приоритет" процесса. Приоритет - это число, характеризующее степень привилегированности процесса при использовании ресурсов вычислительной машины, в частности, процессорного времени: чем выше приоритет, тем выше привилегии.
Во многих операционных системах алгоритмы планирования построены с использованием как квантования, так и приоритетов процессов.
Вытесняющие и невытесняющие алгоритмы планирования
Non-preemptive multitasking - невытесняющая многозадачность - это способ планирования процессов, при котором активный процесс выполняется до тех пор, пока он сам, по собственной инициативе, не отдаст управление планировщику операционной системы для того, чтобы тот выбрал из очереди другой, готовый к выполнению процесс.
Preemptive multitasking - вытесняющая многозадачность - это такой способ, при котором решение о переключении процессора с выполнения одного процесса на выполнение другого процесса принимается планировщиком операционной системы, а не самой активной задачей.
Средства синхронизации и взаимодействия процессов
Проблема синхронизации
Процессам часто нужно взаимодействовать друг с другом, например, один процесс может передавать данные другому процессу, или несколько процессов могут обрабатывать данные из общего файла. Во всех этих случаях возникает проблема синхронизации процессов, которая может решаться приостановкой и активизацией процессов, организацией очередей, блокированием и освобождением ресурсов.
Критическая секция
Критическая секция - это часть программы, в которой осуществляется доступ к разделяемым данным. Чтобы исключить эффект гонок по отношению к некоторому ресурсу, необходимо обеспечить, чтобы в каждый момент в критической секции, связанной с этим ресурсом, находился максимум один процесс. Этот прием называют взаимным исключением.
Простейший способ обеспечить взаимное исключение - позволить процессу, находящемуся в критической секции, запрещать все прерывания. Однако этот способ непригоден, так как опасно доверять управление системой пользовательскому процессу; он может надолго занять процессор, а при крахе процесса в критической области крах потерпит вся система, потому что прерывания никогда не будут разрешены.
Другим способом является использование блокирующих переменных. С каждым разделяемым ресурсом связывается двоичная переменная, которая принимает значение 1, если ресурс свободен (то есть ни один процесс не находится в данный момент в критической секции, связанной с данным процессом), и значение 0, если ресурс занят. существенный недостаток: в течение времени, когда один процесс находится в критической секции, другой процесс, которому требуется тот же ресурс, будет выполнять действия по опросу блокирующей переменной, бесполезно тратя процессорное время. Для устранения такой ситуации используются системные функции аналогичного назначения, которые условно назовем WAIT(x) и POST(x), где x - идентификатор некоторого события. Если ресурс занят, то процесс не выполняет циклический опрос, а вызывает системную функцию WAIT(D), здесь D обозначает событие, заключающееся в освобождении ресурса D. Функция WAIT(D) переводит активный процесс в состояние ОЖИДАНИЕ и делает отметку в его дескрипторе о том, что процесс ожидает события D. Процесс, который в это время использует ресурс D, после выхода из критической секции выполняет системную функцию POST(D), в результате чего операционная система просматривает очередь ожидающих процессов и переводит процесс, ожидающий события D, в состояние ГОТОВНОСТЬ.
Обобщающее средство синхронизации процессов предложил Дейкстра, который ввел два новых примитива. В абстрактной форме эти примитивы, обозначаемые P и V, оперируют над целыми неотрицательными переменными, называемыми семафорами. Пусть S такой семафор. Операции определяются следующим образом:
V(S) : переменная S увеличивается на 1 одним неделимым действием; выборка, инкремент и запоминание не могут быть прерваны, и к S нет доступа другим процессам во время выполнения этой операции.
P(S) : уменьшение S на 1, если это возможно. Если S=0, то невозможно уменьшить S и остаться в области целых неотрицательных значений, в этом случае процесс, вызывающий P-операцию, ждет, пока это уменьшение станет возможным. Успешная проверка и уменьшение также является неделимой операцией.
В частном случае, когда семафор S может принимать только значения 0 и 1, он превращается в блокирующую переменную. Операция P заключает в себе потенциальную возможность перехода процесса, который ее выполняет, в состояние ожидания, в то время как V-операция может при некоторых обстоятельствах активизировать другой процесс, приостановленный операцией P.
Тупики
Одна из проблемм синхронизации - взаимные блокировки (тупики).
Пример тупика. Пусть двум процессам, выполняющимся в режиме мультипрограммирования, для выполнения их работы нужно два ресурса, например, принтер и диск. И пусть после того, как процесс А занял принтер (установил блокирующую переменную), он был прерван. Управление получил процесс В, который сначала занял диск, но при выполнении следующей команды был заблокирован, так как принтер оказался уже занятым процессом А. Управление снова получил процесс А, который в соответствии со своей программой сделал попытку занять диск и был заблокирован: диск уже распределен процессу В. В таком положении процессы А и В могут находиться сколь угодно долго.
Проблема тупиков включает в себя следующие задачи:
предотвращение тупиков,
распознавание тупиков,
восстановление системы после тупиков.
Тупики могут быть предотвращены на стадии написания программ, то есть программы должны быть написаны таким образом, чтобы тупик не мог возникнуть ни при каком соотношении взаимных скоростей процессов.
Монитор - это набор процедур, переменных и структур данных. Процессы могут вызывать процедуры монитора, но не имеют доступа к внутренним данным монитора. Мониторы имеют важное свойство, которое делает их полезными для достижения взаимного исключения: только один процесс может быть активным по отношению к монитору. Компилятор обрабатывает вызовы процедур монитора особым образом. Обычно, когда процесс вызывает процедуру монитора, то первые несколько инструкций этой процедуры проверяют, не активен ли какой-либо другой процесс по отношению к этому монитору. Если да, то вызывающий процесс приостанавливается, пока другой процесс не освободит монитор. Таким образом, исключение входа нескольких процессов в монитор реализуется не программистом, а компилятором, что делает ошибки менее вероятными.
Прерывания - это принудительная передача управления от выполняющейся программы к системе, а через неё к соответствующей программе обработки прерываний, происходящая при определенном событии. Основная цель введения прерываний - реализация асинхронного режима работы и распараллеливания работы отдельных устройств вычислительного комплекса.
Во многих ОС секция обработки прерываний выделяется в специальный программный модуль, наз. супервизором прерываний. Этот модуль сохраняет в дескрипторе текущей задачи рабочие регистры процессора, которые определяют контекст прерываемого вычислительного процесса. Определяет ту подпрограмму, которая должна выполнять действия связанные с обслуживанием текущего запроса на прерывание. Перед тем. как передать управление этой подпрограмме супервизор прерываний устанавливает необходимый режим обработки прерывания. После выполнения подпрограммы управление передается вновь супервизору, но уже на тот модуль, который занимается диспетчеризацией задач. Диспетчер задач в свою очередь, в соответствии с принятым режимом распределения процессорного времени между выполняющимися процессами восстановит контекст той задачи, которой будет решено выделить процессор.
Обработка прерываний при участии супервизора ОС.
1. отключение прерываний. Производится в соотв. модулях ОС. Сохранение контекста прерванной задачи. Установка режима системы прерываний.
2. определение адреса программного модуля. который обслуживает запрос на прерывание и передача управления на него. Включение подпрограммы обработки прерываний.
Диспетчер задач: выбор готовой к выполнению задачи на основе принятой дисциплины обслуживания. Восстановление контекста прерванной задачи. Установление прежнего режима работы системы прерываний и передача управления этой задаче.
Процессы подразделяются на системные и пользовательские. Системные процессы принадлежат административным учетным именам, автоматически порождаются при старте системы и выполняются в режиме ядра. Они могут непосредственно манипулировать внутренними данными и структурами ядра. Пользовательские процессы принадлежат обычным - не административным учетным именам, исполняются в пользовательском режиме и для доступа к таблицам ядра используют системные вызовы.
Структура ядра ОС: монолитное ядро, микроядро; планирование и диспетчеризация: планирование с переключением и без переключения, выбор величины кванта, алгоритмы планирования (FIFO, RR, SJF, SRT, HNR), многоуровневое планирование.
Монолитное ядром хар-ся тем, что драйверы являются частью ядра и не имеют права исполнять обычные системные вызовы. Ни один пользовательский процесс не может получить управление, пока какой-то из модулей ядра активен.
Микроядро - это минимальная функционально полная часть операционной системы, которая обычно состоит из планировщика и базовых средств передачи данных между процессами и синхронизации. Микроядро, таким образом, реализует базовые функции ОС, на которые опираются другие системные службы и приложения. Модули системы, не включенные в микроядро, являются отдельными процессами, взаимодействующими с ядром и друг с другом.
Алгоритмы планирования без переключений выбирают процесс и позволяют работать ему вплоть до блокировки, или пока он сам не отдаст процессор. Процесс не будет прерван, даже если он работает часами. Т. е. решения планирования не принимаются по прерываниям таймера. После обработки преравания таймера управление всегда возвращается приостановленному процессу.
Алгоритмы планирования с переключениями, выбирают процесс и позволяют работать ему некоторое максимально возможное фиксированное время. Если к концу заданного интервала процесс все еще работает, он приостанавливается и управление переходит к другому процессу. Приоритетное планирование требует прерываний по таймеру, происходящих в конце отведенного периода времени, чтобы передать управление планировщику.
Выбор величины кванта.
слишком малый квант времени приведет к частому переключению процессов и небольшой эффективности, но слишком большой квант может привести к медленному реагированию на короткие интерактивные запросы. Значение кванта около 20-50 мс часто является наиболее оптимальным.
CPU burst – промежуток времени непрерывного использования процессора.
FIFO (первым пришел – первым обслужен). Процессор предоставляется процессам в том порядке, в котором они его запрашивают. Когда процесс переходит в состояние готовность, он помещается в конец очереди. Выбор нового процесса для исполнения осуществляется из начала очереди. Такой алгоритм выбора процесса осуществляет невытесняющее планирование. Процесс, получивший в свое распоряжение процессор, занимает его до истечения своего текущего CPU burst. После этого для выполнения выбирается новый процесс из начала очереди.
RR (Round Robin - это вид детской карусели в США). По сути дела это тот же самый алгоритм, только реализованный в режиме вытесняющего планирования. Можно представить себе все множество готовых процессов организованным циклически - процессы сидят на карусели. Карусель вращается так, что каждый процесс находится около процессора небольшой фиксированный квант времени, обычно 10 - 100 миллисекунд (см. рисунок 3.4.). Пока процесс находится рядом с процессором, он получает процессор в свое распоряжение и может исполняться.
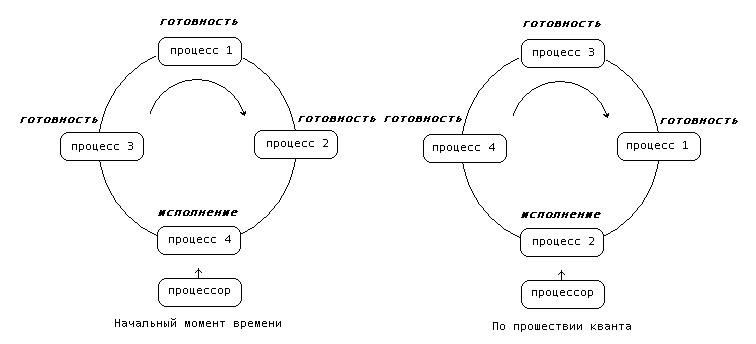
При выполнении процесса возможны два варианта:
Время непрерывного использования процессора, требующееся процессу, (остаток текущего CPU burst) меньше или равно продолжительности кванта времени. Тогда процесс по своей воле освобождает процессор до истечения кванта времени, на исполнение выбирается новый процесс из начала очереди и таймер начинает отсчет кванта заново.
Продолжительность остатка текущего CPU burst процесса больше, чем квант времени. Тогда по истечении этого кванта процесс прерывается таймером и помещается в конец очереди процессов готовых к исполнению, а процессор выделяется для использования процессу, находящемуся в ее начале.
SJF (Shortest-Job-First - кратчайшая работа первой). На выполнение выбирается процесс с минимальной длительностью CPU burst. SJF алгоритм краткосрочного планирования может быть как вытесняющим, так и невытесняющим. При невытесняющем SJF планировании процессор предоставляется избранному процессу на все требующееся ему время, независимо от событий происходящих в вычислительной системе. При вытесняющем SJF планировании учитывается появление новых процессов в очереди готовых к исполнению (из числа вновь родившихся или разблокированных) во время работы выбранного процесса. Если CPU burst нового процесса меньше, чем остаток CPU burst у исполняющегося, то исполняющийся процесс вытесняется новым.
SRT (по наименьшему остающемуся времени). Принцип SRT – это аналог принципа SJF, но с переключением, применимый в системах с разделением времени. По принципу SRT всегда выполняется процесс, имеющий минимальное оценочное время до завершения, причем с учетом новых поступающих процессов. По принципу SJF задание, которое запущено в работу, выполняется до завершения. По принципу SRT выполняющийся процесс может быть прерван при поступлении нового процесса, имеющего более короткое оценочное время работы.
HRN (highest-response-ratio-next – по наибольшему относительному времени реакции). Это алгоритм планирования без переключений, по которому приоритет каждого задания определяется не только временем обслуживания этого задания, но также и временем, затраченным заданием на ожидание обслуживания. После того как задание получает в свое распоряжение ЦП, оно выполняется до завершения. Динамические приоритеты при алгоритме HRN вычисляются по формуле:
ПРИОРИТЕТ = (ВРЕМЯ ОЖИДАНИЯ + ВРЕМЯ ОБСЛУЖИВАНИЯ) / ВРЕМЯ ОБСЛУЖИВАНИЯ
Поскольку время обслуживания находится в знаменателе, предпочтение будет оказываться более коротким заданиям. Однако, поскольку в числителе имеется время ожидания, более длинные задания, которые уже довольно долго ждут, будут также получать определенное предпочтение. Сумма ВРЕМЯ ОЖИДАНИЯ + ВРЕМЯ ОБСЛУЖИВАНИЯ есть время ответа системы для данного задания, если бы это задание инициировалось немедленно.
Многоуровневые очереди. Для систем, в которых процессы могут быть легко рассортированы на разные группы, был разработан другой класс алгоритмов планирования. Для каждой группы процессов создается своя очередь процессов, находящихся в состоянии готовность. Этим очередям приписываются фиксированные приоритеты. Например, приоритет очереди системных процессов устанавливается больше, чем приоритет очередей пользовательских процессов. А приоритет очереди процессов, запущенных студентами, - ниже, чем для очереди процессов, запущенных преподавателями. Это значит, что ни один пользовательский процесс не будет выбран для исполнения, пока есть хоть один готовый системный процесс, и ни один студенческий процесс не получит в свое распоряжение процессор, если есть процессы преподавателей, готовые к исполнению. Внутри этих очередей для планирования могут применяться самые разные алгоритмы. Так, например, для больших счетных процессов, не требующих взаимодействия с пользователем (фоновых процессов), может использоваться алгоритм FIFO, а для интерактивных процессов - алгоритм RR. Подобный подход, получивший название многоуровневых очередей, повышает гибкость планирования: для процессов с различными характеристиками применяется наиболее подходящий им алгоритм.
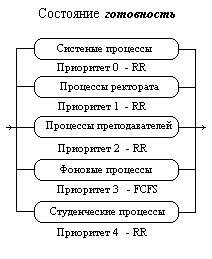
Многоуровневые очереди с обратной связью (Multilevel Feedback Queue)
Дальнейшим развитием алгоритма многоуровневых очередей является добавление к нему механизма обратной связи. Здесь процесс не постоянно приписан к определенной очереди, а может мигрировать из очереди в очередь, в зависимости от своего поведения.
через некоторое время все процессы, требующие малого времени работы процессора окажутся размещенными в высокоприоритетных очередях, а все процессы, требующие большого счета и с низкими запросами к времени отклика, - в низкоприоритетных.
Монопольный доступ и взаимоисключение: обеспечение монопольного доступа к разделяемым ресурсам, семафоры, синхронизация при помощи семафоров, мониторы (кольцевой буфер, читатели и писатели), событийная синхронизация.
Non-preemptive multitasking - невытесняющая многозадачность - это способ планирования процессов, при котором активный процесс выполняется до тех пор, пока он сам, по собственной инициативе, не отдаст управление планировщику операционной системы для того, чтобы тот выбрал из очереди другой, готовый к выполнению процесс. При этом задача во время каждой итерации использует ресурсы их монопольно и уверена, что на протяжении этого периода никто другой не изменит эти данные.
Проблема синхронизации Процессам часто нужно взаимодействовать друг с другом, например, один процесс может передавать данные другому процессу, или несколько процессов могут обрабатывать данные из общего файла. Во всех этих случаях возникает проблема синхронизации процессов, которая может решаться приостановкой и активизацией процессов, организацией очередей, блокированием и освобождением ресурсов.
Критическая секция Критическая секция - это часть программы, в которой осуществляется доступ к разделяемым данным. Чтобы исключить эффект гонок по отношению к некоторому ресурсу, необходимо обеспечить, чтобы в каждый момент в критической секции, связанной с этим ресурсом, находился максимум один процесс. Этот прием называют взаимным исключением.
Простейший способ обеспечить взаимное исключение - позволить процессу, находящемуся в критической секции, запрещать все прерывания. Однако этот способ непригоден, так как опасно доверять управление системой пользовательскому процессу; он может надолго занять процессор, а при крахе процесса в критической области крах потерпит вся система, потому что прерывания никогда не будут разрешены.
Другим способом является использование блокирующих переменных (рис. слева). С каждым разделяемым ресурсом связывается двоичная переменная, которая принимает значение 1, если ресурс свободен (то есть ни один процесс не находится в данный момент в критической секции, связанной с данным процессом), и значение 0, если ресурс занят.
Реализация критических секций с использованием блокирующих переменных имеет существенный недостаток: в течение времени, когда один процесс находится в критической секции, другой процесс, которому требуется тот же ресурс, будет выполнять действия по опросу блокирующей переменной, бесполезно тратя процессорное время. Для устранения такой ситуации используются системные функции аналогичного назначения, которые условно назовем WAIT(x) и POST(x), где x - идентификатор некоторого события (рис. справа). Если ресурс занят, то процесс не выполняет циклический опрос, а вызывает системную функцию WAIT(D), здесь D обозначает событие, заключающееся в освобождении ресурса D. Функция WAIT(D) переводит активный процесс в состояние ОЖИДАНИЕ и делает отметку в его дескрипторе о том, что процесс ожидает события D. Процесс, который в это время использует ресурс D, после выхода из критической секции выполняет системную функцию POST(D), в результате чего операционная система просматривает очередь ожидающих процессов и переводит процесс, ожидающий события D, в состояние ГОТОВНОСТЬ.
Обобщающее средство синхронизации процессов предложил Дейкстра, который ввел два новых примитива. В абстрактной форме эти примитивы, обозначаемые P и V, оперируют над целыми неотрицательными переменными, называемыми семафорами. Пусть S такой семафор. Операции определяются следующим образом:
V(S) : переменная S увеличивается на 1 одним неделимым действием; выборка, инкремент и запоминание не могут быть прерваны, и к S нет доступа другим процессам во время выполнения этой операции.
P(S) : уменьшение S на 1, если это возможно. Если S=0, то невозможно уменьшить S и остаться в области целых неотрицательных значений, в этом случае процесс, вызывающий P-операцию, ждет, пока это уменьшение станет возможным. Успешная проверка и уменьшение также является неделимой операцией.
В частном случае, когда семафор S может принимать только значения 0 и 1, он превращается в блокирующую переменную. Операция P заключает в себе потенциальную возможность перехода процесса, который ее выполняет, в состояние ожидания, в то время как V-операция может при некоторых обстоятельствах активизировать другой процесс, приостановленный операцией P.
Для того, чтобы облегчить написание корректных программ, было предложено высокоуровневое средство синхронизации, называемое монитором. Монитор – это механизм организации параллелизма, который содержит как данные, так и процедуры, необходимые для реализации динамического распределения конкретного общего ресурса или группы общих ресурсов. Чтобы обеспечить выделение нужного ему ресурса, процесс должен обратиться к конкретной процедуре монитора. Необходимость входа в монитор в различные моменты времени может возникать у многих процессов. Однако вход в монитор находится под жестким контролем — здесь осуществляется взаимоисключение процессов, так что в каждый момент времени только одному процессу разрешается войти в монитор. Процессам, которые хотят войти в монитор, когда он уже занят, приходится ждать, причем режимом ожидания автоматически управляет сам монитор.
Если процесс обращается к некоторой процедуре монитора и обнаруживается, что соответствующий ресурс уже занят, эта процедура монитора выдает команду ожидания WAIT. Процесс мог бы оставаться внутри монитора, однако это привело бы к нарушению принципа взаимоисключения, если в монитор затем вошел бы другой процесс. Поэтому процесс, переводящийся в режим ожидания, должен вне монитора ждать того момента, когда необходимый ему ресурс освободится.
Со временем процесс, который занимал данный ресурс, обратится к монитору, чтобы возвратить ресурс системе. монитор выполняет примитив оповещения (сигнализации) SIGNAL, чтобы один из ожидающих процессов мог занять данный ресурс и покинуть монитор. Если процесс сигнализирует о возвращении (иногда называемом освобождением) ресурса и в это время нет процессов, ожидающих данного ресурса, то подобное оповещение не вызывает никаких других последствий, кроме того, что монитор естественно вновь вносит ресурс в список свободных. Очевидно, что процесс, ожидающий освобождения некоторого ресурса, должен находиться вне монитора, чтобы другой процесс имел возможность войти в монитор и возвратить ему этот ресурс.Чтобы гарантировать, что процесс, находящийся в ожидании некоторого ресурса, со временем действительно получит этот ресурс, считается, что ожидающий процесс имеет более высокий приоритет, чем новый процесс, пытающийся войти в монитор.
Фактически у процессов может возникнуть необходимость находиться в режиме ожидания вне монитора по многим различным причинам. Поэтому было введено понятие переменной-условия. Для каждой отдельно взятой причины, по которой процесс может быть переведен в состояние ожидания, назначается свое условие. В связи с этим команды ожидания и сигнализации модифицируются — в них включаются имена условий:
wait (имя условия) и signal (имя условия)
Когда определяется переменная-условие, заводится очередь. Процесс, выдавший команду ожидания, включается в эту очередь, а процесс, выдавший команду сигнализации, тем самым позволяет ожидающему процессу выйти из очереди и войти в монитор.
Пример монитора: кольцевой буфер
Производителю иногда требуется передать данные, в то время как потребитель еще не готов их принять, а потребитель иногда пытается принять данные, которые производитель еще не выдал.
В ОС часто предусматривается выделение некоторого фиксированного количества ячеек памяти для использования в качестве буфера передач между процессом-производителем и процессом-потребителем. Этот буфер можно представить в виде массива заданного размера. Процесс-производитель помещает передаваемые данные в последовательные элементы этого массива. Процесс-потребитель считывает данные в том порядке, в котором они помещались. Производитель может опережать потребителя на несколько шагов. Со временем процесс-производитель займет последний элемент массива. Когда он сформирует после этого очередные данные для передачи, он должен будет «возвратиться к исходной точке» и снова начать с записи данных в первый элемент массива (при этом естественно предполагается, что потребитель уже прочитал те данные, которые ранее сюда поместил производитель). Такой массив по сути работает как замкнутое кольцо.
Пример монитора: читатели и писатели
В вычислительных системах обычно имеются некоторые процессы, которые читают данные (и называются «читателями»), и другие процессы, которые записывают данные (и называются «писателями»).
Монитор под названием «читателииписатели»: в каждый конкретный момент времени работать может только один писатель; когда какой-либо писатель работает, логическая переменная «ктотопишет» имеет истинное значение. Ни один из читателей не может работать, во время работы какого-либо писателя. Переменная «читатели» указывает количество активных читателей. Когда число читателей оказывается равным нулю, ожидающий процесс-писатель получает возможность начать работу. Новый процесс-читатель не может продолжить свое выполнение, пока не появится истинное значение условия «читатьразрешается», а новый процесс-писатель — пока не появится истинное значение условия «писатьразрешается».
Сообщения. Это метод межпроцессорного взаимодействия, который использует два примитива: send и receive. Первый запрос посылает сообщение адресату, а второй получает сообщение от указанного источника. Если сообщения нет, второй запрос блокируется до получения сообщения.
Предпологается, что все сообщения имеют одинаковый размер и сообщения, которые посланы, но еще не получены, автоматически помещаются ОС в буфер. В этом решении используются N сообщений, по аналогии с N сегментами в буфере. Потребитель начинает с того, что посылает производителю N пустых сообщений. Как только у производителя оказывается элемент данных, который он может представить потребителю, он берет пустое сообщение и отсылает назад полное. Таким образом общее число сообщений в системе постоянно и их можно хранить в заранее заданном участке памяти.
Если производитель работает быстрее, чем потребитель, все сообщения будут ожидать потребителя в заполненном виде. При этом производитель блокируется в ожидании пустого сообщения. Если потребитель работает быстрее, ситуация инвертируется: все сообщения будут пустыми, а потребитель будет блокирован в ожидании полного сообщения.
передача сообщений в пределах одного компьютера происходит существенно медленнее, чем работа с семафорами и мониторами
Тупики: условия возникновения, методы борьбы, стратегия Ханвендера; метод редукции графа - представление состояний системы в виде направленных графов; представление графа – матричное, с помощью связного списка; алгоритмы обнаружения тупиков - метод прямого обнаружения, алгоритм со счетчиком ожиданий; обход тупиков - алгоритм банкира; обнаружение и восстановление работоспособности системы.
Тупики
Одна из проблемм синхронизации - взаимные блокировки (тупики).
Пример тупика. Пусть двум процессам, выполняющимся в режиме мультипрограммирования, для выполнения их работы нужно два ресурса, например, принтер и диск. И пусть после того, как процесс А занял принтер (установил блокирующую переменную), он был прерван. Управление получил процесс В, который сначала занял диск, но при выполнении следующей команды был заблокирован, так как принтер оказался уже занятым процессом А. Управление снова получил процесс А, который в соответствии со своей программой сделал попытку занять диск и был заблокирован: диск уже распределен процессу В. В таком положении процессы А и В могут находиться сколь угодно долго.
Условия возникновения тупиков
1. Условие взаимоисключения (Mutual exclusion). Каждый ресурс выделен в точности одному процессу или доступен. Процессы требуют предоставления им монопольного управления ресурсами, которые им выделяются.
2. Условие ожидания ресурсов (Hold and wait). Процессы удерживают за собой ресурсы, уже выделенные им, ожидая в то же время выделения дополнительных ресурсов (которые при этом обычно удерживаются другими процессами).
3. Условие неперераспределяемости (No preemtion). Ресурс, данный ранее, не может быть принудительно забран у процесса. Освобождены они могут быть только процессом, который их удерживает.
4. Условие кругового ожидания (Circular wait). Существует кольцевая цепь процессов, в которой каждый процесс удерживает за собой один или более ресурсов, требующихся другим процессам цепи.
Для тупика необходимо выполнение всех четырех условий.
Основные направления борьбы с тупиками:
1.Игнорировать данную проблему; 2. Обнаружение тупиков; 3. Восстановление после тупиков;4. Предотвращение тупиков за счет тщательного выделения ресурсов или нарушения одного из условий возникновения тупиков.
Алгоритм страуса. Простейший подход - игнорировать проблему тупиков.
Стратегия Хавендера.
Первый стратегический принцип Хавендера требует, чтобы процесс сразу же запрашивал все ресурсы, которые ему понадобятся. Система должна предоставлять эти ресурсы по принципу «все или ничего». Если в текущий момент полного набора ресурсов, необходимых процессу, нет, этому процессу придется ждать, пока они не освободятся. Однако когда процесс находится в состоянии ожидания, он не должен удерживать какие-либо ресурсы. Второй стратегический принцип Хавендера требует, чтобы процесс, имеющий в своем распоряжении некоторые ресурсы, если он получает отказ на запрос о выделении дополнительных ресурсов, должен освобождать свои ресурсы и при необходимости запрашивать их снова вместе с дополнительными. Третий стратегический принцип Хавендера исключает круговое ожидание. Поскольку всем ресурсам присваиваются уникальные номера и поскольку процессы должны запрашивать ресурсы в порядке возрастания номеров, круговое ожидание возникнуть не может.
Обнаружение тупиков. Обнаружение тупика это установление факта, что возникла тупиковая ситуация и определение процессов и ресурсов, вовлеченных в эту ситуацию. Представление графа с пом-ю связного списка
Пример:
Процесс A удерживает ресурс R и ожидает ресурс S.
Процесс B претендует на ресурс T.
Процесс C претендует на ресурс S.
Процесс D удерживает ресурс U и ожидает ресурсы S и T.
П
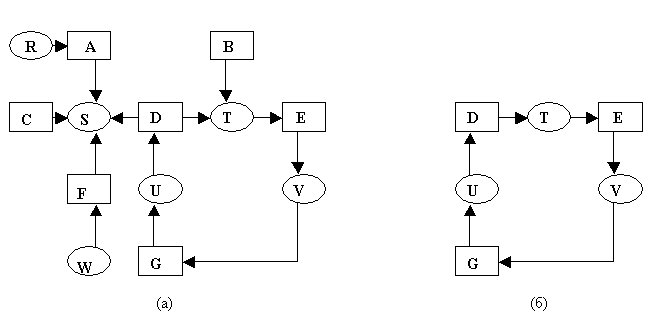 роцесс
E удерживает ресурс T и ожидает ресурс
V.
роцесс
E удерживает ресурс T и ожидает ресурс
V.Процесс F удерживает ресурс W и ожидает ресурс S.
Процесс G удерживает ресурс V и ожидает ресурс U.
Вопрос состоит в том, является ли данная ситуация тупиковой, и если да, то какие процессы в ней участвуют.
Рис. 1. (а) Граф ресурсов. (б) Цикл, извлеченный из графа (a).
Для ответа на этот вопрос можно сконструировать граф ресурсов, как показано на рис. Из рисунка видно, что имеется цикл, моделирующий условие кругового ожидания, и процессы D,E,G в тупиковой ситуации
Матричное представление графа
m – число классов ресурсов. E – вектор существующих ресурсов, где Ei – количество ресурсов класса i (пр. E1=2 – означ., что в системе есть два диска). В любой момент времени некоторые из ресурсов могут оказаться занятыми и, соответственно, недоступными. Пусть А будет вектором доступных ресурсов, где Аi равно количеству экзампляров ресурса i, доступных в текущий момент.
Д ва
массива: C
– матрица текущего распределения и R
– матрица запросов. i-я
строка в матрице С говорит о том, сколько
представителей каждого класса ресурсов
в данный момент использует процесс Pi.
Сij
– это количество экземпляров ресурса
j,
которые занимает процесс i.
Rij
– это количество экземпляров ресурса
j,
которые хочет получить процесс i.
ва
массива: C
– матрица текущего распределения и R
– матрица запросов. i-я
строка в матрице С говорит о том, сколько
представителей каждого класса ресурсов
в данный момент использует процесс Pi.
Сij
– это количество экземпляров ресурса
j,
которые занимает процесс i.
Rij
– это количество экземпляров ресурса
j,
которые хочет получить процесс i.
Алгоритм обнаружения тупиков состоит из следующих шагов:
Ищем немаркированный процесс Pi для которого i-я строка матрицы R меньше вектора А или равна ему.
Если такой процесс найден, прибавляем i-ю строку матрицы С к вектору А, маркируем процесс и возвращаемся к шагу 1.
Если таких процессов не существует, работа алгоритма заканчивается.
Завершение алгоритма означает, что все немаркированные процессы, если такие есть, попали в тупик.
Алгоритм банкира, предложенный Дейкстрой
Когда при описании алгоритма банкира мы будем говорить о ресурсах, мы будем подразумевать ресурсы одного и того же типа, однако этот алгоритм можно легко распространить на пулы ресурсов нескольких различных типов. Рассмотрим, например, проблему распределения некоторого количества t идентичных лентопротяжных устройств. Операционная система должна обеспечить распределение некоторого фиксированного числа t одинаковых лентопротяжных устройств между некоторым фиксированным числом пользователей и каждый пользователь заранее указывает максимальное число устройств, которые ему потребуются во время выполнения своей программы на машине. Операционная система примет запрос пользователя в случае, если максимальная потребность этого пользователя в лентопротяжных устройствах не превышает t.
Пользователь может занимать или освобождать устройства по одному. Возможно, что иногда пользователю придется ждать выделения дополнительного устройства, однако операционная система гарантирует, что ожидание будет конечным. Текущее число устройств, выделенных пользователю, никогда не превысит указанную максимальную потребность этого пользователя. Если операционная система в состоянии удовлетворить максимальную потребность пользователя в устройствах, то пользователь гарантирует, что эти устройства будут использованы и возвращены операционной системе в течение конечного периода времени.
Поэтому выделять лентопротяжные устройства пользователям можно только в случае, когда после очередного выделения устройств состояние системы остается надежным. Надежное состояние — это состояние, при котором общая ситуация с ресурсами такова, что все пользователи имеют возможность со временем завершить свою работу.
Восстановление после тупиков
Сложность восстановления обусловлена рядом факторов.
в большинстве систем нет достаточно эффективных средств для приостановки процесса, вывода его из системы и возобновления впоследствии;
если даже такие средства есть, то их использование требует затрат и внимания оператора;
восстановление после серьезного тупика может потребовать много работы.
Восстановление при помощи перераспределения ресурсов
Один из способов восстановления - принудительный вывод некоторого процесса из системы для последующего использования его ресурсов. Для определения того, какой процесс выводить из системы зачастую требуются усилия оператора. В некоторых случаях может оказаться возможным временно забрать ресурс у его текущего владельца и передать его другому процессу.
Восстановление через откат назад
Это, по всей вероятности, самый эффективный способ приостановки и возобновления.
Если проектировщики системы знают, что тупик вероятен, они могут периодически организовывать для процессов контрольные точки. Когда тупик обнаружен, видно какие ресурсы вовлечены в цикл кругового ожидания. Чтобы осуществить восстановление, процесс, который владеет таким ресурсам, должен быть отброшен к моменту времени, предшествующему его запросу на этот ресурс.
Восстановление через ликвидацию одного из процессов
Грубый, но простейший способ устранить тупик - убить один или более процессов. Например, убить процесс, который в цикле. Тогда при удаче остальные процессы смогут выполняться. Если это не помогает, то можно ликвидировать еще один процесс.
Иерархия памяти: уровни иерархии, вертикальное и горизонтальное управление, распределение основной памяти, особенности основной памяти как ресурса ВС, алгоритмы распределения памяти, защита памяти.
Память - функциональная часть компьютера, предназначенная для записи, хранения и считывания информации. Технически память реализуется в виде запоминающих устройств.
В самом простейшем случае можно выделить основную память и внешнюю память. Основные классы памяти, которые могут присутствовать на современных компьютерах.
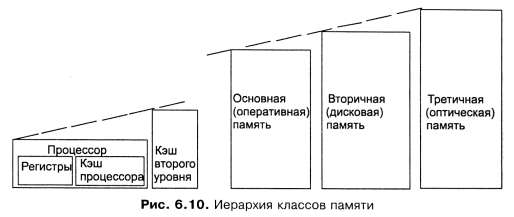
В основе иерархии памяти современных компьютеров лежат два принципа.
Принцип локальности обращений. Большинство запросов процессов на обращение к памяти имеет, как правило, неравномерный характер с высокой степенью локальной концентрации, как временной, так и пространственной;
Соотношение скорость доступа - объем памяти. Чем быстрее может быть осуществлен доступ к памяти, тем она более дорогая. Следовательно, тем менее она практична с точки зрения использования и тем меньше будет ее объем, который разумно устанавливать в компьютер.
Распределение памяти может быть:
статическим, когда привязка к конкретным ячейкам памяти выполняется либо до, либо во время загрузки модуля;
динамическим, когда задание может перемешаться в памяти, допуская настройку и получение абсолютных значений ячеек памяти при каждом обращении к ним.
Существуют следующие основные способы реализации отображения памяти:
оверлеи (overlay) - возможность расположить модули в памяти таким образом, чтобы один из них (корневой) постоянно находился там, а остальные - попеременно загружались в ходе выполнения программы в одну и ту же область, сменяя и перекрывая друг друга;
свопинг (swapping) - разрешение системе вводить в память и выводить из нее задания целиком;
поблочное отображение - возможность группировать элементы информации в блоки (если блоки имеют одинаковый размер, то это страницы, если разный, то сегменты).
Основная память
Привязка адресов
Функция именования, которая однозначно отображает данное пользовательское имя в идентификатор информации, к которому относится имя. Эта функция реализуется обычно редактором связей.
Функция памяти, которая однозначно отображает определение идентификатора в истинные номера ячеек памяти, в которых он будет находиться. Эта функция реализуется частью операционной системы, называемой загрузчиком.
Управление виртуальной памятью
Распределенная общая память
Защита памяти — это еще одна важная задача операционной системы, которая состоит в том, чтобы не позволить выполняемому процессу записывать или читать данные из памяти, назначенной другому процессу. Эта функция, как правило, реализуется программными модулями ОС в тесном взаимодействии с аппаратными средствами.
Вертикальное и горизонтальное управление
Все методы управления памятью могут быть разделены на два класса: методы, которые используют перемещение процессов между оперативной памятью и диском (вертикальное управление), и методы, которые не делают этого(горизонтальное управление).
Распределение памяти фиксированными разделами
Разделение памяти на несколько разделов фиксированной величины. Это может быть выполнено вручную оператором во время старта системы или во время ее генерации. Очередная задача, поступившая на выполнение, помещается либо в общую очередь, либо в очередь к некоторому разделу.
Подсистема управления памятью в этом случае выполняет следующие задачи:
сравнивая размер программы, поступившей на выполнение, и свободных разделов, выбирает подходящий раздел, осуществляет загрузку программы и настройку адресов.
Так как в каждом разделе может выполняться только одна программа, то уровень мультипрограммирования заранее ограничен числом разделов не зависимо от того, какой размер имеют программы. Даже если программа имеет небольшой объем, она будет занимать весь раздел, что приводит к неэффективному использованию памяти. С другой стороны, даже если объем оперативной памяти машины позволяет выполнить некоторую программу, разбиение памяти на разделы не позволяет сделать этого.
Распределение памяти разделами переменной величины
Сначала вся память свободна. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Программный код не перемещается во время выполнения, то есть может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика. Данному методу присущ очень серьезный недостаток - фрагментация памяти. Фрагментация - это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Перемещаемые разделы
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область. В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется "сжатием". Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц, а во втором - реже выполняется процедура сжатия. Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов из виртуальной формы в физическую должно выполняться динамическим способом.