

2.6. Асимптотическое оценивание пропускной способности математической модели измерения
При последовательном накоплении измеряемой информации возможно асимптотическое оценивание пропускной способности в соответствии с теоремой.
Теорема 2.6.1. Пропускная способность многопараметрической ММИ
П(Pi;
fi)
![]() ,
,
где
2(![]() )
=1 – ,
= P(x
EH2),
1(E)
= 1 – ,
= P(x
H1).
)
=1 – ,
= P(x
EH2),
1(E)
= 1 – ,
= P(x
H1).
Доказательство.
Поскольку для устройства измерения
лишь только одна k
– я переменная является доминирующей,
то из приведенной выше теоремы следует
![]() = 1 = Pk,
а предельный объем модели равен
= 1 = Pk,
а предельный объем модели равен
П(Pi;
fi)
=
![]() i(xi)logfi(xi)/f(x1,...,
xN)d(x).
i(xi)logfi(xi)/f(x1,...,
xN)d(x).
В частности, для модели, состоящей из двух обособленных (независимых) переменных xi E и xj , получаем
П(Pi;
fi)=![]() i(xi)logfi(xi)/f(xi,
xj)d(x)
i(xi)logfi(xi)/f(xi,
xj)d(x)![]() i(x
i)dxi)logd
i(x
i)dxi)logd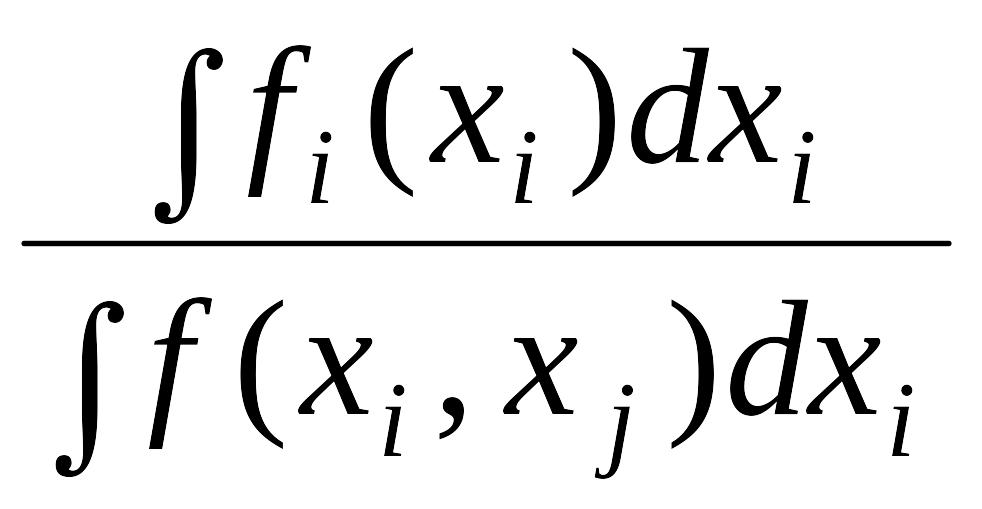 xj
xj
![]() i(x
i)dxi)log
i(x
i)dxi)log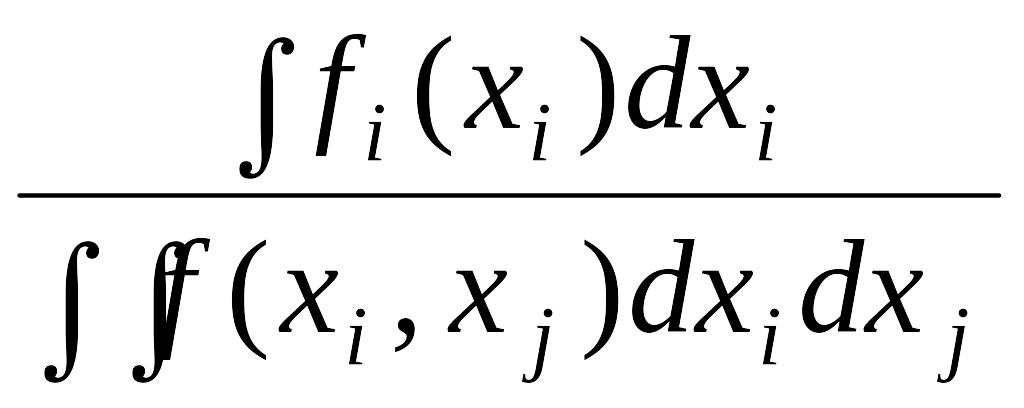
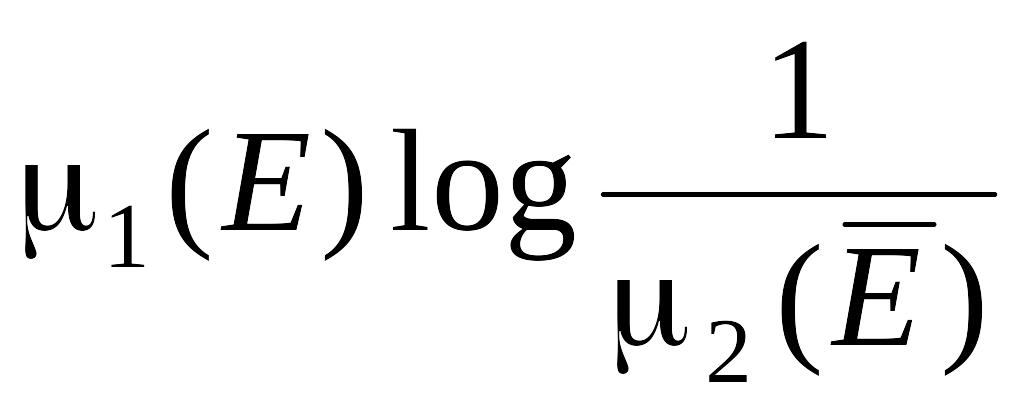 =
,
=
,
где 2( ) =1 – , = P(x EH2), 1(E) = 1 – , = P(x H1).
Полученная в теореме 2.6.1 зависимость пропускной способности многопараметрической ММИ от вероятностей ошибок первого и второго рода приведена на рис. 2.1. Из данной зависимости следует, что при последовательном накоплении измеряемой информации увеличение ошибок требует увеличения пропускной способности устройства измерения.
R()
=1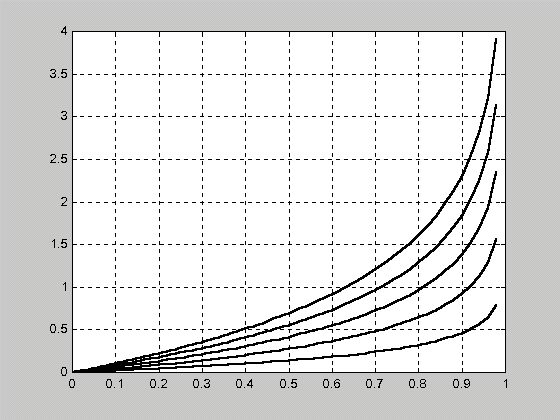
=0,8
=0,6
=0,4
=0,2
Рис. 2.1.
Зависимость пропускной способности
многопараметрической ММИ от вероятностей
ошибок первого и второго рода при
последовательном накоплении информации
контроля
2.7. Асимптотический метод выделения признаков модели измерения
Выделение
общей ММИ сводится к определению каждого
из ее признаков, т.е. выделение
соответствующего класса, который
определяется областью определения
этого признака в общей области определения
всей модели. Таким образом, задача
выделения признака ММИ, постановка
которой приведена в разд. 3.3, заключается
в разбиении области определения общей
ММИ на области определения каждого
признака. В частном случае, если область
определения двухпризнаковой общей
модели (пространство выборок в n
независимых наблюдений) X
разбита на непересекающиеся множества
E
и
![]() (Е
= 0, X =
E
)
индикатором множества E(x).
Причем процедура разбиения заключается
в том, что если выборка xE
(E(x)=1),
принимается гипотеза H1
(отвергается H2),
и если выборка x
(E(x)=0),
принимается гипотеза H2
(отвергается H1).
Гипотеза H2
рассматривается как нулевая гипотеза,
а E
является критической областью. Вероятность
неправильного принятия гипотезы H1,
ошибка первого рода, равна =P(xE1H2)=2(E1),
а вероятность неправильного принятия
гипотезы H2,
ошибка второго рода, равна
= P(x
E2H1)
= 1(E2).
(Е
= 0, X =
E
)
индикатором множества E(x).
Причем процедура разбиения заключается
в том, что если выборка xE
(E(x)=1),
принимается гипотеза H1
(отвергается H2),
и если выборка x
(E(x)=0),
принимается гипотеза H2
(отвергается H1).
Гипотеза H2
рассматривается как нулевая гипотеза,
а E
является критической областью. Вероятность
неправильного принятия гипотезы H1,
ошибка первого рода, равна =P(xE1H2)=2(E1),
а вероятность неправильного принятия
гипотезы H2,
ошибка второго рода, равна
= P(x
E2H1)
= 1(E2).
При этом риск разбиения, в соответствии с теоремой 3.1 [66], которая определяет условия минимума различающей информации, для статистики Т(x)=E(x) определяется выражением
Rр(1:2)
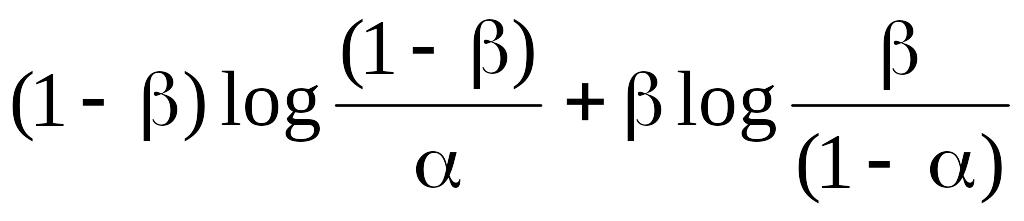 (2.20)
(2.20)
с равенством, совпадающим с минимумом, при
f1(x)
=
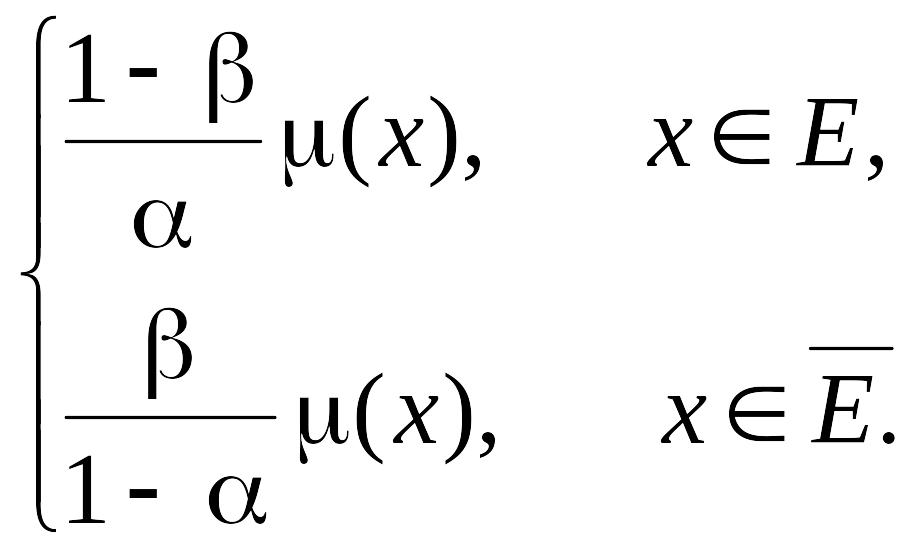
Установленные в данном выражении зависимости риска разбиения от вероятности ошибки первого и второго рода при последовательном накоплении информации измерения приведены на рис. 2.2 и 2.3 соответственно.
Данные выражения позволяют разбивать пространства X с ошибками , без потери информации, поскольку это разбиение достаточное. Причем риск выбора модели для соответствующих переменных при заданных значениях ошибок их идентификации , по областям определения можно получить, равным нулю (рис. 2.2, 2.3). В общем случае, если Ei S, i = 1,2,..., Ei Ej и X = Ei, т.е. если Х разбито на попарно непересекающиеся множества E1, E2,..., то в соответствии со следствием 3.3.2 [66]
Rр(1:2)
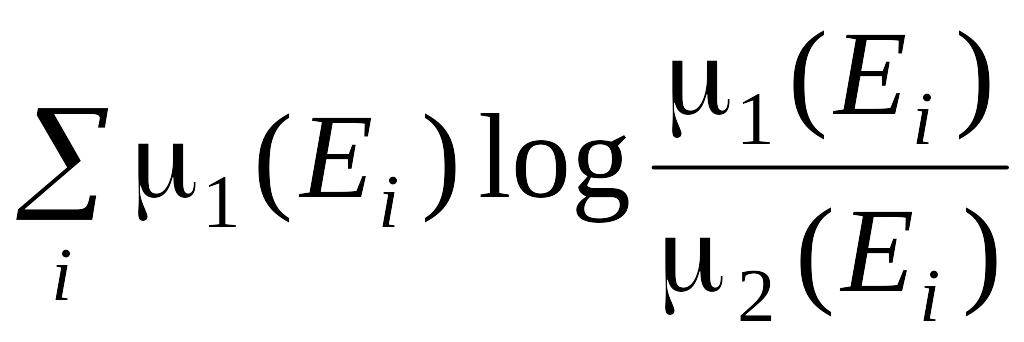 ,
,
а равенство достигается при условии
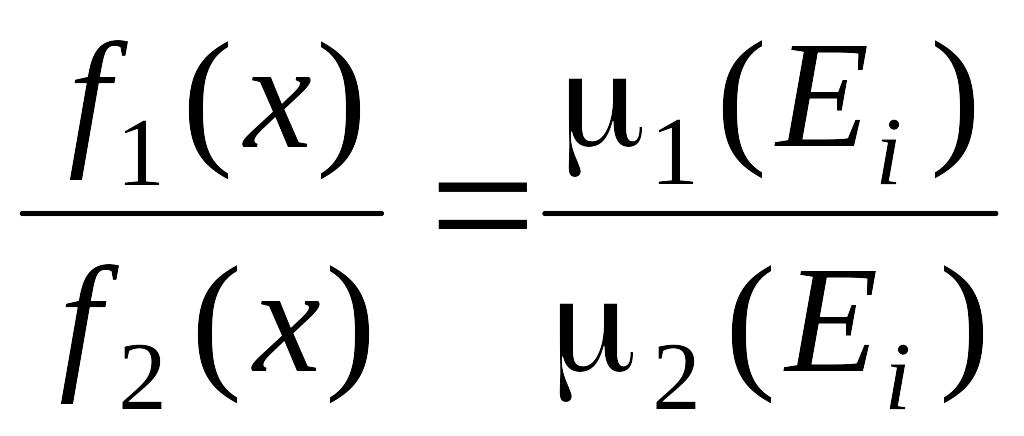
для x Ei, i = 1, 2,...
R()
Рис. 2.2.
Зависимость риска разбиения от
вероятности ошибки первого рода при
последовательном накоплении измерительной
информации
=0,2
=0,4
=0,6
=0,8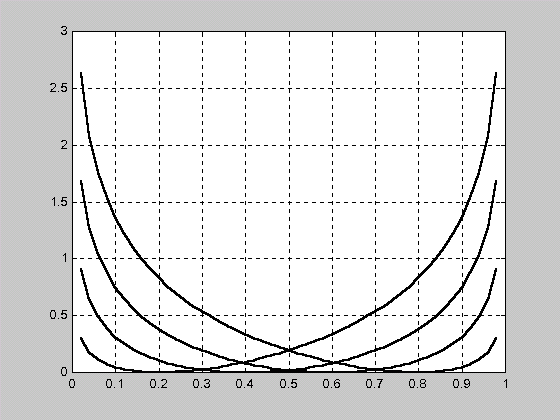
R()
Рис. 2.3.
Зависимость риска разбиения от
вероятности ошибки второго рода при
последовательном накоплении измерительной
информации
=0,2
=0,4
=0,6
=0,8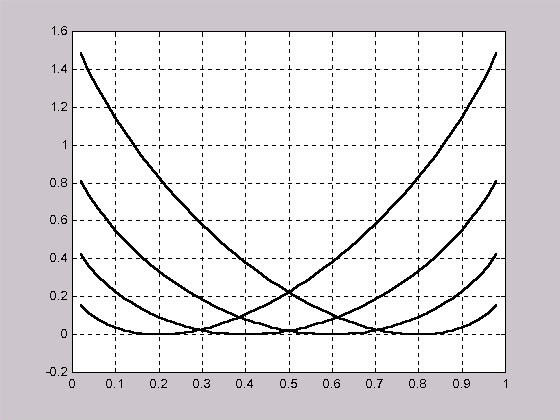
При оценке качества асимптотического выделения признака ММИ методом последовательного анализа, необходимо использовать теорему 4.3.1 [66], которая совпадает с выражением, полученным в разделе 3.8.
Теорема:
Rр(On)
= nRр(O1)
log![]() + (1 – )log
+ (1 – )log![]() ,
,
где On – выборка в n независимых наблюдений, а O1 – выборка, состоящая из одного наблюдения.
Для фиксированного значения , скажем 0, 0 < 0 < 1, нижняя граница минимума всех возможных = n* получается из формулы
Rр(O1)
n–10log + (1 – 0)log
+ (1 – 0)log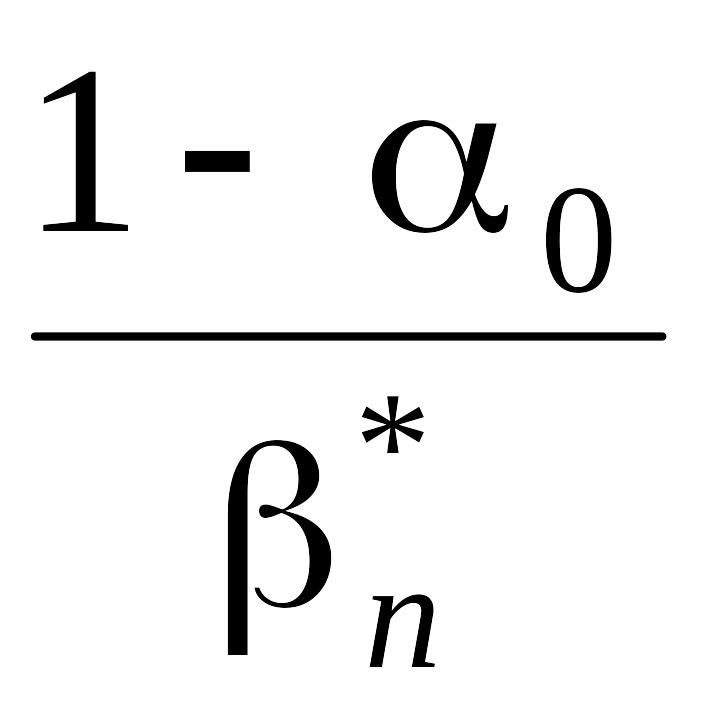 .
.
Аналогично, для фиксированного значения 0, 0<0<1, нижняя граница , n* получается из формулы
Rр(O1)
n–10log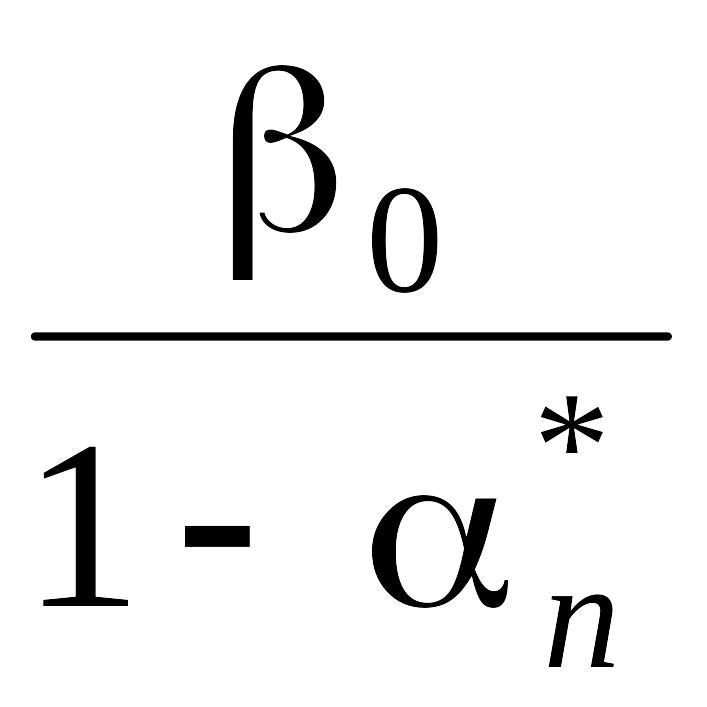 + (1 – 0)log
+ (1 – 0)log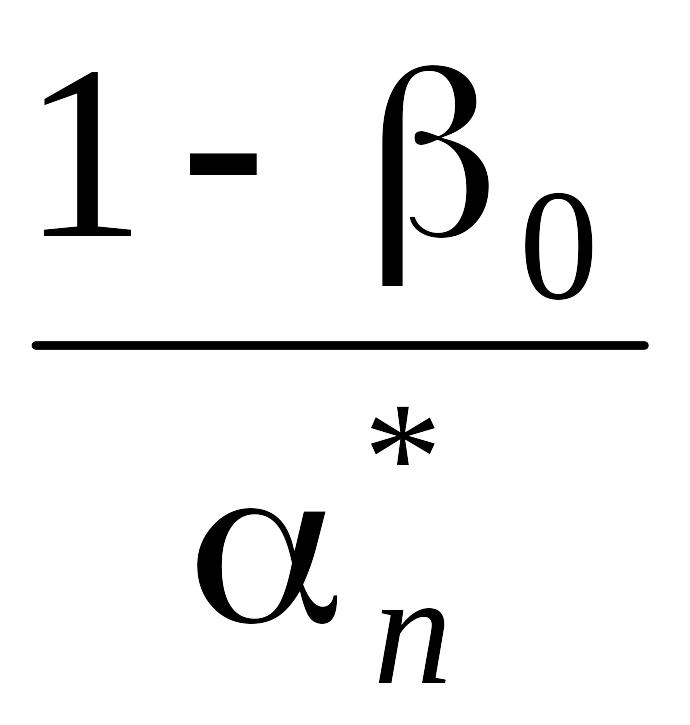 .
.
Величины Rр(1:2; X)/Rр(1:2; Y) и Rр(2:1; X)/Rр(2:1; Y) могут быть использованы (для больших выборок) как мера относительной эффективности конкурирующих переменных X и Y в том смысле, что
Rр(1:2; X)/Rр(1:2; Y) = ny/nx или Rр(2:1; X)/Rр(2:1; Y) = Ny/Nx,
где nx, ny и Nx, Ny – соответственно объемы выборок, необходимых для того, чтобы получить для данного 0 то же n* и для данного 0 – то же n*.