

Практическая работа №1-2 Первичная обработка опытных данных при помощи модуля Basic Statistics / Tables
1.Начало работы
З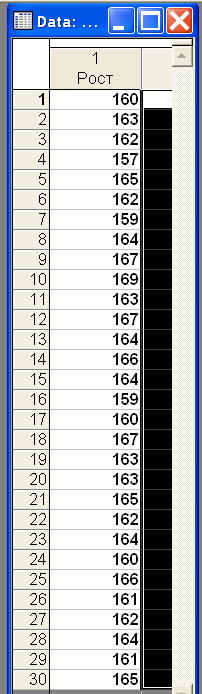
 апустить
программу STATISTICA 6. Создать
новый файл: File→New
→<Имя файла> (Lab1.1)
апустить
программу STATISTICA 6. Создать
новый файл: File→New
→<Имя файла> (Lab1.1)
В окне параметров, вкладка Spreadsheet, ввести Number of variable (число переменных)=1; Number of cases (число вариант)=30 → ОК. В появившемся окне таблицы данных дважды кликнуть по полю Var1 и в окне параметров переменной изменить Name (имя переменной) = Рост → ОК. Ввести данные из таблицы (Рис.1). Войдите еще раз в окно параметров переменной и введите еще одну переменную Вес. Данные для этой переменной в следующей таблице:
49 |
57 |
61 |
52 |
60 |
53 |
51 |
56 |
52 |
54 |
51 |
52 |
59 |
54 |
56 |
52 |
56 |
54 |
51 |
52 |
54 |
57 |
48 |
58 |
60 |
54 |
55 |
53 |
56 |
53 |
Расчет описательных статистик производится при помощи модуля Basic Statistic/Tables. В этом модуле объединены наиболее часто использующиеся на начальном этапе обработки данных процедуры.
В стартовой панели модуля приводится перечень статистических процедур этого модуля (рис. 2):
Descriptive statistics -Описательные статистики;
Correlation matrices -Корреляционные матрицы;
t-test for independent samples -t-тест для независимыхвыборок;
t-test for dependent samples -t-тестдля зависимыхвыборок;
Br eakdown = one-way ANOVA -однофакторный дисперсионный анализ; идр.
Рис. 2. Стартовое окно модуля с перечнем статистических процедур
2. Процедура Descriptive statistics (Описательные статистики)
 Рассмотрим
возможности этой процедуры на примере.
Рассмотрим
возможности этой процедуры на примере.
У нас имеется выборка объемом 30 измерений, представляющая собой результаты замера роста и веса студентов факультета. Файл данных содержит 2 переменных:
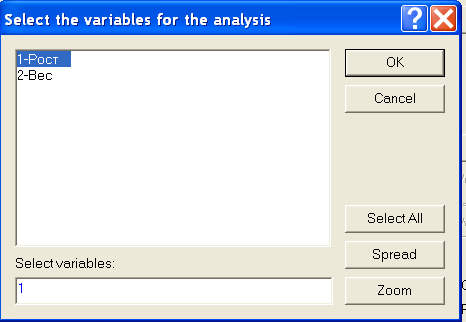
Рост- и Вес. Для дальнейшей работы нужно выделить переменную Рост (рис. 3).
После выбора процедуры Descriptive statistics на экране появится одноименное диалоговоеокно (рис. 4).
Рис.3. Диалоговое окно Выбор переменной для анализа
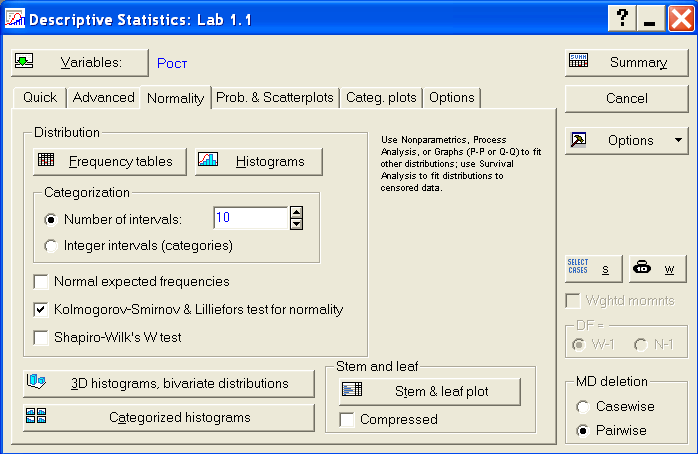
Рис.4. Диалоговое окно "Descriptive statistics
На первом этапе обработки данных часто возникает необходимость в их группировке. Группировка позволяет представить первичные данные в компактном виде, выявить закономерности варьирования изучаемого признака. Количество классов можно приблизительно наметить, пользуясь следующими рекомендациями: при количестве наблюдений 25-40 - 5-6 классов, при количестве наблюдений 40-60 - 6-8 классов, 60-100 - 7-10, 100-200 наблюдений - 8-12, более 200 наблюдений - 10-15 классов.
Параметры группировки задаются во вкладке Normality/ Число классов (интервалов) группировки данных устанавливается при помощи счетчика переключателя Number of intervals группы Categorization (Группировка). Если активировать переключатель Integer intervals (categories), то классы (интервалы) группировки будут представлять из себя целые числа.
Для построения гистограмм и таблиц частот используется группа кнопок Distribution окна Descriptive statistics. Нажатием кнопки Frequency tables получим окно с результатами группировки роста студентов (переменная Рост) представлены (рис.5).
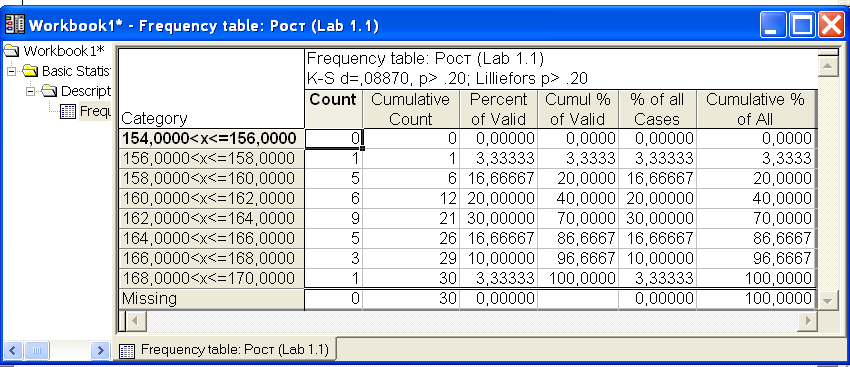
Рис.5. Окно Frequency table с результатами группировки.
Представим распределение переменных на гистограммах.
Для этого предназаначенак нопка Histograms группа кнопок Distribution окна Descriptive statistics.
На гистограмму при необходимости можно наложить плотность нормального распределения, проверить близость распределения к нормальному виду при помощи критериев Колмогорова-Смирнова, Лилиефорса; вычислить статистику Шапиро-Уилкса. Для этого в группе опций Distribution необходимо установить флажок напротив соответствующих статистик. Значения статистик показываются прямо на гистограммах.
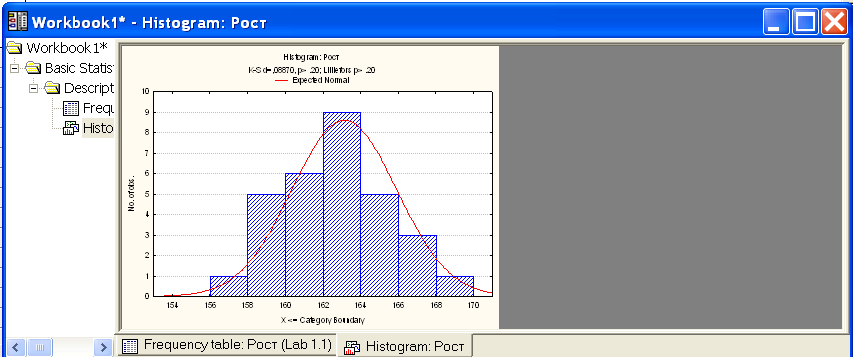
Рис.6. Гистограмма распределения длины надземной части сеянцев
На рис. 6 приведена гистограмма распределения роста студентов (переменная Рост).
На гистограмме красной линией показана кривая плотности нормального распределения, а также критерий Колмогорова-Смирнова (d). Статистика КолмогороваСмирнова оказалась равной 0,0887. Чем меньше величина этой статистики, тем ближе распределение случайной величины к нормальному. Вероятность нулевой гипотезы (р) менее 0,20.
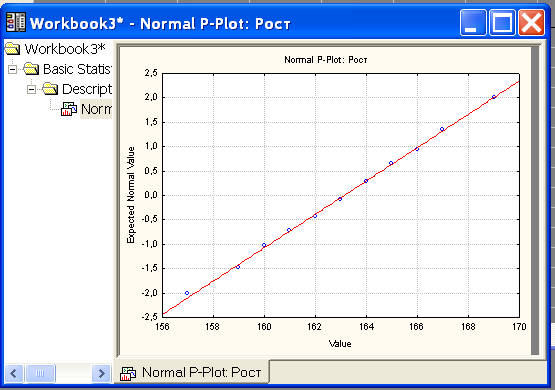
О нормальности распределения можно судить по графику на нормальной построенному при помощи опции Normal probability plot во вкладке Categ. plots окна Descriptive statistics. (рис.4). Чем ближе распределение к нормальному виду, тем лучше значения ложатся на прямую линию.
 Этот
метод оценки является фактически
глазомерным. В сомнительных случаях
проверку на нормальность можно продолжить
с использованием специальных статистических
критериев (Колмогорова-Смирнова,
Омега-квадрат (w2)). Однако детальная
проверка гипотезы о нормальности выборки
требует довольно значительных объемов
выборки (по мнению некоторых авторов
не менее 100 наблюдений).
Этот
метод оценки является фактически
глазомерным. В сомнительных случаях
проверку на нормальность можно продолжить
с использованием специальных статистических
критериев (Колмогорова-Смирнова,
Омега-квадрат (w2)). Однако детальная
проверка гипотезы о нормальности выборки
требует довольно значительных объемов
выборки (по мнению некоторых авторов
не менее 100 наблюдений).
Рис. 7. График на нормальной вероятностной бумаге для выборки Роста
Чтобы выбрать статистики, подлежащие вычислению, нужно перейти во вкладку Advanced установить флажки в нужных параметрах и нажать кнопку Summary (рис. 8)
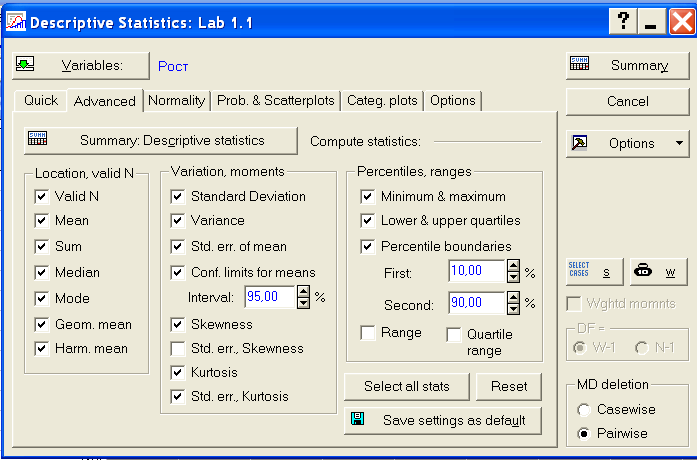
Рис. 8. Окно выбора статистик