Стандартные способы описания свойств данных – схема rdf
Схема RDF – это семантическое расширение RDF. Она обеспечивает механизмы описания связанных ресурсов, а также собственно этих связей.
Система классов и свойств схемы RDF похожа на систему классов языков объектно-ориентированного программирования, таких, например, как Java, но отличается от многих других систем. Так, описательный язык словаря RDF определяет свойства в терминах того класса ресурсов, к которому эти свойства относятся. Другие системы же описывают класс в терминах свойств его элементов.
RDF и схема RDF основаны на XML и схеме XML. Существование стандартов для описания данных (RDF) и их атрибутов (схема RDF) позволяет создавать пакеты легко доступных инструментов для чтения и использования данных из многочисленных источников. То, насколько глубоко различные приложения могут обмениваться данными и использовать их, называется синтаксическим взаимодействием (syntactic interoperability). Чем более стандартизированными и распространенными являются эти инструменты работы с данными, тем выше степень синтаксического взаимодействия и тем легче и привлекательнее становится использование подхода на основе Semantic Web по сравнению с точечными интеграционными решениями.
Онтология
Стандартные способы описания связей между объектами данных: онтология, определяемая с помощью онтологического языка Web.
Синтаксическое взаимодействие – необходимое условие для того, чтобы множественные приложения могли по-настоящему «понимать» данные и работать с ними как с информацией. Это также необходимое условие для корректной проверки данных. Синтаксическое взаимодействие требует преобразования («мэппирования») между терминами, для чего, в свою очередь, необходим контент-анализ.
Контент-анализ требует формальных и подробных спецификаций моделей доменов, которые определяют используемые термины и их связи. Подобные формальные модели доменов называются онтологиями. Они определяют модели данных в терминах классов, подклассов и свойств.
Онтология является искусственно созданным объектом и состоит:
из конкретного словаря, используемого для описания определенной предметной области;
множества явных допущений, относящихся к подразумеваемому значению словаря.
Онтология описывает формальную спецификацию определенной предметной области:
общее понимание рассматриваемой предметной области;
формальная, допускающая машинную обработку модель рассматриваемой предметной области.
Опять возвращаясь к примеру с запросом о погоде – если представить, что информация на метеосайте структурирована в соответствии с принципами RDF, то и запрос можно формулировать формализовано – <южный берег Крыма><температура воздуха><значение температуры?>. Но объект <южный берег Крыма> может и не иметь атрибут <температура воздуха>. Но необходимую информацию могут содержать два RDF-описания: <южный берег Крыма><прогноз погоды><описание погоды> и <описание погоды><температура воздуха><значение температуры>. Здесь возникает проблема – в запросе ничего не было сказано о погоде. Web-агент, обрабатывающий запрос, самостоятельно не сможет связать термины <температура воздуха> и <описание погоды>, для этого ему необходимо обратиться к онтологии, задачей которой и является описание терминов и, что очень важно в данном случае, связей между ними.
Онтологический язык Web (Web Ontology Language, сокр. OWL), рекомендуемый консорциумом W3C, помогает в выражении онтологий. Рабочий онтологический язык добавляет больше словарных возможностей для описания свойств и классов, чем RDF или схема RDF. В частности, он позволяет описывать связи между классами (например, неперекрываемость), мощность множества (например, «ровно один»), равенство, более богатую типологию свойств и их характеристики (например, симметрия).
Преимущества Semantic Web для Интернета CITATION Тим01 \l 1049
Интернет – это крупнейший из когда-либо существовавших информационных репозиториев, причем его содержание все время растет и представлено на самых разнообразных языках и практически во всех областях знаний. Но, в конечном счете, становится все труднее находить смысл во всем этом содержимом. Поисковые системы способны находить информацию, содержащую определенные слова, но эта информация не всегда оказывается именно той, что требуется. Какой-то элемент всегда оказывается упущенным. Поиск основан на содержании страниц, но не на семантическом значении этого содержания или информации о странице.
Как только будет создан семантический Интернет, он даст возможность разметки всего содержания Интернета, описания каждого элемента информации и обеспечения семантического значения этих элементов. Таким образом, поисковые системы становятся более эффективными, чем сейчас, а пользователи могут находить именно ту информацию, которая им необходима. Организации, оказывающие различные услуги, способны индексировать их с особым значением. А пользователи будут в состоянии оперативно находить эти услуги, используя программные средства на основе Интернета, и использовать их для своей пользы или в сочетании с другими услугами.
Семантика – это будущее сервис-ориентированной интеграции. Семантические технологии обеспечивают существование определенного уровня абстракции над существующими IT-технологиями. Этот уровень позволяет осуществлять связь данных, содержания и процессов между различными видами бизнеса и изолированными IT-структурами. Наконец, с точки зрения взаимодействия людей, семантические технологии добавляют новый уровень семантических порталов, которые обеспечивают гораздо более аналитические, соответствующие теме и контексту взаимодействия, чем те, которые доступны с помощью традиционных точечных подходов к интеграции, использующихся в информационных порталах.
XML
Язык XML (Extensible Markup Language) был разработан рабочей группой XML Working Group консорциума World Wide Web Consortium (W3C) в феврале 1998 г.
XML является метаязыком и содержит правила разметки документа, но XML – это не замена HTML, XML и HTML преследуют различные цели:
XML был создан для описания данных, концентрируя свое внимание на сущность этих данных;
HTML был создан для показа данных, концентрируя внимание на том, как данные будут отображаться;
XML ничего не делает, XML не предназначен для осуществления каких-либо действий.
Пакет данных, описанный на XML, называют XML-документом. XML-документ, как и HTML-документ, является обычным текстовым файлом, в который при помощи угловых скобкок (символов < и >) включаются специальные маркеры – теги. Слово, заключенное в угловые скобки называется именем тега. Теги парные – начальный и конечный. Конечный тег отличается от начального знаком "/" (слеш) после открывающей угловой скобки. Пара тегов и текст, заключенный между ними, называется элементом XML-документа, текст, заключенный между тегами – содержимое элемента. Например:
<element>это элемент XML-документа</element>
В XML теги используются не для указания способа отображения содержимого элемента или определения какого-либо другого действия, а для того, чтобы просто как-то отметить этот текст. Выбор имен тегов при этом зависит лишь от фантазии автора документа, а их конкретное значение определяется специальными правилами – описателями грамматики языка, определяемыми также автором документа. XML был создан не для того чтобы что-то делать, он был создан для хранения информации.
Простое напоминание в виде XML-документа CITATION Тим01 \l 1049 :
<?xml version="1.0" encoding="windows-1251"?>
<Записка>
<кому>Иван Иванович</кому>
<от_кого>Петров П.П.</от_кого>
<заголовок>Внимание!</заголовок>
<содержание>
Сдать отчет к
<дата>21.01.2005</дата>
</содержание>
</Записка>
В записке есть заголовок и содержание (смысловая часть) этой записки. В ней также есть информация о том, кому и от кого поступила эта записка. Но, тем не менее, этот XML документ не выполняет никаких действий. Это всего лишь информация, заключенная в XML-теги. Например, для такого формата записки можно написать программу, которая будет составлять и посылать подобные записки.
Возможность создавать собственные элементы и присваивать им любые имена – именно поэтому язык XML является расширяемым (eXtensible) – позволяет использовать XML для описания практически любого документа, от музыкалькой партитуры до базы данных. XML имеет ряд приложений, предназначенных для описания нетекстовых документов и их частей. Примерами могут служить:
MathML – для описания математических формул (см. 4)
Описание молекулярных структур (CML – Chemical Markup Language).
Кодирование и отображение информации о ДНК, РНК и цепочках (BSML – Bioinformatic Sequence Markup Language).
Кодирование генеалогических данных (GeDML – Genealogical Data Markup Language).
Обмен астрономическими данными (AML – Astronomical Markup Language).
Создание музыкальных партитур (MusicML – Music Markup Language)
 .
.Заполнение юридических документов и электронный обмен юридической информацией (XCL – XML Court Interface).
Кодирование прогнозов погоды (OMF – Weather Observation Markup Format).
Представление религиозной информации и разметка текстов богослужений (ThML – Theological Markup Language, LitML – Liturgical Markup Language).
Например, можно описать перечень книг, подобно представленному в следующем XML-документе.
<?xml version="1.0" encoding="windows-1251"?>
<Library>
<Book>
<Title>Война и мир</Title>
<Author>Толстой Л.Н</Author>
<Pages>600</Pages>
<Type>роман</Type>
<Text Type=’text’>http://www.text.com/book1</Text>
</Book>
<Book>
<Title>Евгений Онегин</Title>
<Author>Пушкин А.С.</Author>
<Text Type=’html’>http://www.text.com/book2</Text>
<Pages>100</Pages>
<Type>роман в стихах</Type>
</Book>
<Book>
…
</Library>
Имена элементов в XML-документе (такие как Library, Book и Title в приведенном выше примере) не являются определениями языка XML и можно выбирать любые корректно заданные имена (List вместо Library, либо Item вместо Book).
В предыдущем примере XML-документ имеет иерархическую структуру в виде дерева с элементами, вложенными в другие элементы, и с одним элементом верхнего уровня (в нашем примере – Library). Он носит название элемент Документ или Корневой элемент и содержит все другие элементы.
Таким образом, с помощью XML можно описать иерархическую структуру документа, например, такого как книга, содержащего части, главы и разделы.
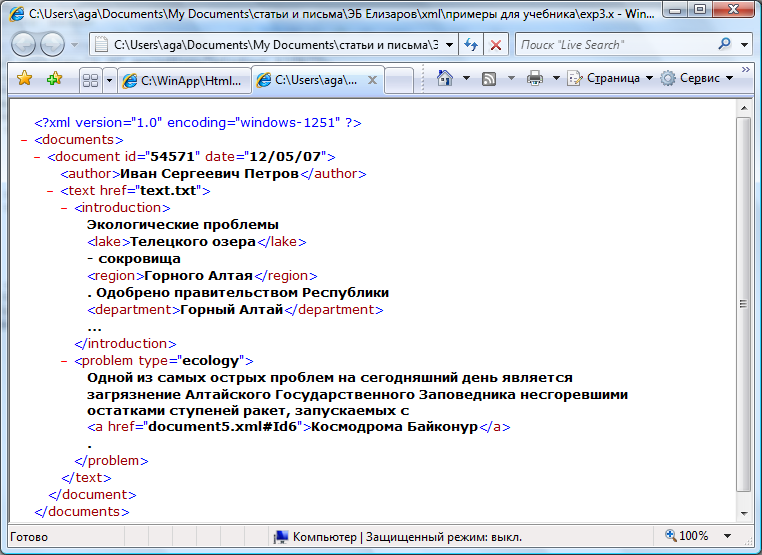
Следующий пример несложного XML-документа, в котором теги используются для уточнения семантики некоторых фрагментов текста, а вложенность элементов определяет их иерархию:
<?xml version="1.0" encoding="windows-1251"?>
<documents>
<document id="54571" date="12/05/07">
<author>Иван Сергеевич Петров</author>
<text href="text.txt">
<introduction>
Экологические проблемы <lake>Телецкого озера </lake> -
сокровища <region>Горного Алтая </region>. Одобрено
правительством Республики <department>Горный
Алтай</department> …
</introduction>
<problem type="ecology">
Одной из самых острых проблем на сегодняшний день
является загрязнение Алтайского Государственного
Заповедника несгоревшими остатками ступеней ракет,
запускаемых с <a href="document5.xml#Id6"> Космодрома
Байконур</a>.
</problem>
</text>
</document>
</documents>
Вид XML-документа из примера 3 в браузере Internet Explorer: