

8.1. Моделі пам'яті
У всіх комп'ютерах пам'ять розділена на комірки, які мають послідовні адреси. В даний час найпоширеніший розмір комірки — 8 бітів, але раніше використовувалися комірки від 1 до 60 бітів. Комірка з 8 бітів називається байтом. Причина використання саме 8-бітових байтів така: символи АSCII коду займають 7 бітів, тому один символ АSCII плюс біт парності якраз підходить під розмір байта. Якщо в майбутньому домінуватиме UNICODE, то комірки пам'яті, можливо, будуть 16-бітовими. Взагалі кажучи, число 24 краще, ніж 23, оскільки 4 — ступінь двійки, а 3 — немає.
Байти звичайно групуються в 4-байтні (32-бітові) або 8-байтн (64-бітові) слова з командами для маніпулювання цілими словами. Багато архітектур вимагають, щоб слова були вирівняні в своїх природних межах. Так, наприклад, 4-байтне слово може починатися з адреси 0,4,8 і т. д., але не з адреси 1 або 2. Так само слово з 8 байтів може починатися з адреси 0,8 або 16, але не з адреси 4 або 6. Розташування 8-байтних слів показано на мал. 8.2.
Деякі машини потребують щоб слова в пам'яті були вирівняні. Вирівнювання адрес потрібне досить часто, оскільки при цьому пам'ять працює більш ефективно. Наприклад, Pentium II, який викликає з пам'яті по 8 байтів за раз, використовує 36-бітові фізичні адреси, але містить тільки 33 адресні біти. Отже, Pentium II навіть не зможе звернутися до невирівняної пам'яті, оскільки молодші три біти не визначено явним чином. Ці біти завжди рівні 0, і всі адреси пам'яті кратні 8 байтам.
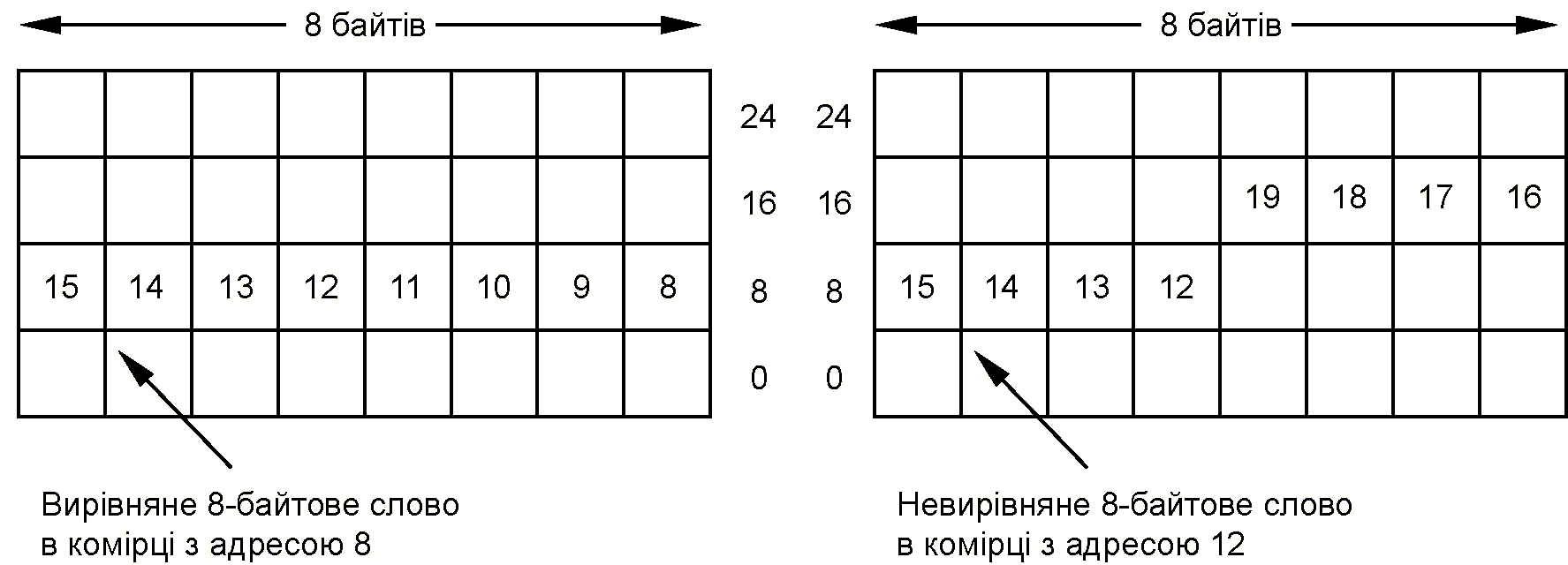
Мал. 8.2 - Розміщені слова з 8 байтів в пам'яті: вирівняне (а); невирівняне (б).
Проте вимога вирівнювання адрес іноді викликає деякі проблеми. В процесорі Pentium II програми можуть звертатися до слів, починаючи з будь-якої адреси, — ця якість сходить до моделі 8088 з шиною даних завширшки в 1 байт, в якій не було такої вимоги, щоб комірки розташовувалися в 8-байтних межах. Якщо програма в процесорі Pentium II прочитує 4-байтне слово з адреси 7, апаратне забезпечення повинне зробити одне звернення до пам'яті, щоб викликати байти з 0-го по 7-й, і друге звернення до пам'яті, щоб викликати байти з 8-го по 15-й. Потім центральний процесор повинен витягнути необхідні 4 байти з 16 байтів, лічених з пам'яті, і упорядкувати їх в потрібному порядку, щоб сформувати 4-байтне слово.
Можливість прочитувати слова з довільними адресами вимагає ускладнення мікросхеми, яка після цього стає більшою за розміром і дорожча. Розробники були б раді позбавитися такої мікросхеми і просто вимагати, щоб всі програми зверталися до слів пам'яті, а не до байтів. Проте на питання інженерів: «Кому потрібне виконання старих програм для машини 8088, які неправильно звертаються до пам'яті?» послідує відповідь продавців: «Нашим покупцям».
Більшість машин має єдиний лінійний адресний простір, який тягнеться від адреси 0 до якогось максимуму, переважно 232 байтів або 264 байтів. В деяких машинах містяться окремі адресні простори для команд і для даних, так що при виклику команди з адресою 8 і виклику даних з адресою 8 відбувається звернення до різних адресних просторів. Така система набагато складніше, ніж єдиний адресний простір, та зате вона має дві переваги. По-перше, з'являється можливість мати 232 байтів для програми і додаткові 232 байтів для даних, використовуючи тільки 32-бітні адреси. По-друге, оскільки запис завжди автоматично відбувається тільки в простір даних, випадковий перезапис програми стає неможливим, і отже, усувається одне з джерел програмних збоїв.
Відзначимо, що окремі адресні простори для команд і для даних — це не те ж саме, що розділена кеш-пам'ять першого рівня. В першому випадку весь адресний простір цілком дублюється, і зчитування з будь-якої адреси викликає різні результати залежно від того, що саме прочитується: слово чи команда. При розділеній кеш-пам'яті існує тільки один адресний простір, просто в різних блоках кеш-пам'яті зберігаються різні частини цього простору.
Ще один аспект моделі пам'яті — семантика пам'яті. Природно чекати, що команда LOAD, яка зустрічається після команди STORE і яка звертається до тої ж адреси, поверне тільки що збережене значення. Проте, як ми бачили в розділі 4, в багатьох машинах мікрокоманди переупорядковуються.
Яку архітектуру команд можна вважати хорошою? Існує два основні чинники. По-перше, хороша архітектура повинна визначати набір команд, які можна ефективно реалізувати в сучасній і майбутній техніці, що приводить до рентабельних розробок на декілька поколінь. Поганий проект реалізувати складніше. При погано розробленій архітектурі команд може бути потрібна більша кількість вентилів для процесора і більший об'єм пам'яті для виконання програм. Крім того, машина може працювати повільніше, оскільки така архітектура команд погіршує можливості перекриття операцій, тому для досягнення більш високої продуктивності тут буде потрібний складніший проект. Розробка, в якій використовуються особливості конкретної техніки, може спричинити за собою виробництво цілого покоління комп'ютерів, і ці комп'ютери зможе випередити тільки більш продвинута архітектура команд.
По-друге, хороша архітектура команд повинна забезпечувати ясну мету для відтрансльованої програми. Регулярність і повнота варіантів — важливі риси, які не завжди властиві архітектури команд. Ці якості важливі для компілятора, якому важко зробити кращий вибір з декількох можливих, особливо коли деякі очевидні на перший погляд варіанти не дозволені архітектурою команд. Якщо говорити коротко, оскільки рівень команд є проміжною ланкою між апаратним і програмним забезпеченням, він повинен бути зручний і для розробників апаратного забезпечення, і для складачів програмного забезпечення.