

Системное программное обеспечение, информационное обеспечение систем управления, объектно–ориентированное программирование
Основные элементы реляционной модели данных (отношение, атрибут, домен, кортеж, ключ отношения, схема отношения, схема БД).
Реляционная и постреляционная модели данных
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение (relation).
Отношение представляет собой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицы не удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие:
dBaseIII Plus и dBase IY (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), / FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) и Oracle (Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН УССР), а также система HyTech (МИФИ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x, Системы предыдущих версий вплоть до Oracle 7.x считаются «чисто» реляционными.
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Это означает, что информация в таблице представляется в первой нормальной форме (подраздел 5). Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в записях таблиц. Постреляционная модель данных допускает многозначные поля — поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
На рис. 6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (6) моделей. Таблица INVOICES (накладные) содержит данные о номерах накладных (INVNO) и номерах покупателей (CUSTNO). В таблице INVOICE.ITEMS (накладные-товары) содержатся данные о каждой из накладных: номер накладной (INVNO), название товара (GOODS) и количество товара (QTY). Таблица INVOICES связана с таблицей INVOICE.ITEMS по полю INVNO;
Как видно из рисунка, по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц. Для доказательства на рис. 7 приводятся примеры операторов SELECT выбора данных из всех полей базы на языке SQL для реляционной (а) и постреляционной (б) моделей.
а)
INVOICES
INVNO
|
CUSTNO
|
0373
|
8723
|
8374
|
8232
|
7364
|
8723
|
INVOICE.ITEMS
INVNO
|
GOODS
|
QTY
|
0373
|
Сыр
|
3
|
0373
|
Рыба
|
2
|
8374
|
Лимонад
|
1
|
8374
|
Сок
|
6
|
8374
|
Печенье
|
2
|
7364
|
Йогурт
|
1
|
6)
INVOICES
INVNO
|
CUSTNO
|
GOODS
|
QTY
|
0373
|
8723
|
Сыр
|
3
|
|
|
Рыба
|
2
|
8374
|
8232
|
Лимонад
|
1
|
|
|
Сок
|
6
|
|
|
Печенье
|
2
|
7364
|
8723
|
Йогурт
|
1
|
Рис. 6. Структуры данных реляционной и постреляционной моделей.
Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д.

Рис. 7. Операторы SQL для реляционной и постреляционной моделей.
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеют большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Для описания функций контроля значений в полях имеется возможность создавать процедуры (коды конверсии и коды корреляции), автоматически вызываемые до Или после обращения к данным. Коды корреляции выполняются сразу после чтения данных, перед их обработкой. Коды конверсии, наоборот, выполняются после обработки данных. , .
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb.
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений: Красный, Синий, Банановый, Белая ночь и т.д., однако каждому экземпляру сущности присваивается только одно значение атрибута.
Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность. Например, для автомобильного завода цвет – это только атрибут продукта производства, а для лакокрасочной фабрики цвет – тип сущности.
Ключ (индентификатор) – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Для сущности Расписание ( с атрибутами: Номер_рейса, Дни_недели, Пункт_отправления ,Время_вылета , Пункт_назначения, Время_прибытия, Тип_самолета, Стоимость_билета) ключом является атрибут Номер_рейса или набор: Пункт_отправления, Время_вылета и Пункт_назначения (при условии, что из пункта в пункт вылетает в каждый момент времени один самолет).
Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.
Понятие информационного обеспечения АСУ, базы данных и СУБД. Основные этапы технологии проектирования баз данных.
Определение: Автоматизированная система- это систма, состоящая из персонала и комплекса средств автоматизации его деятельности, реализующая информационную технологию выполнения установленных функций (ГОСТ.34.003-90).
В любой автоматизированной управляющей системе или информационной системе выделяются две основные части: функциональная и обеспечивающая..
Функциональная часть представляет собой систему задач, которые объединяются в подсистемы, обеспечивающие деятельность крупных, относительно самостоятельных функциональных областей в действующей организации, например: планирование перевозок, материально-техническое обеспечение т.п.
Обеспечивающая часть образует основу любой АС и состоит из информационного, программного, математического, лингвистического, технического и организационного видов обеспечения. Информационное обеспечение (ИО) является одной из из наиболее важных частей АС и представляет собой совокупность реализованных решений по объему, размещению и формам организации информации, циркулирующей в АС при ее функционировании. Основное назначение ИО- это создание и поддержание в действующей АС информационной базы. Информационная база подразделяется на внутримашинную и внемашинная. Внемашинная информационная база представляет собой совокупность сообщений, сигналов, документов, используемых при функционировании системы в форме удобной для восприятия человеком и не связанная с применением ВТ. Данные, используемые в АС и хранящиеся в ЗУ ЭВМ образуют внутримашинную информационную базу

.
В современных АС внутримашинная составляющая информационной базы реализуется по принципам АбнД.
2. Назначение и основные компоненты банка данных
Анализ концепции построения и развития отечественных и зарубежных автоматизированных систем сбора и обработки данных, получаемых с помощью комплексов радиотехнической разведки, позволяет сделать заключение о том, что перспективные системы такого класса по основным архитектурным принципам построения будут предстапвлять собой многоуровневые распределенные автоматизированные банки данных (БнД) о предметной области, силах и средствах системы. Существует множество определений БнД. В изучаемой дисциплине под БнД понимают следующие.
Определение: Банк данных—это система специальным образом организованных данных (баз данных), программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных.
В приведенном определении подчеркивается, что банк данных является сложной системой, включающей в себя все обеспечивающие подсистемы, необходимые для функционирования любой системы автоматизированной обработки данных. Использование БнД в автоматизированных системах позволяет получить следующие преимущества:
Обеспечивается непротиворечивость и целостность информации, возможность обращаться к ней не только при решении заранее предопределенных задач, но и с нерегламентированными запросами.
Сокращается избыточность хранимых данных, что приводит к сокращению затрат не только на создание и хранение данных, но и на поддержание их в актуальном состоянии.
Существенно изменяется деятельность организации, где он внедряется (сокращается документооборот, количество форм документов, перераспределяются функции между сотрудниками).
Обеспечивается возможность более полной реализации принципа независимости прикладных программ от данных, чем это возможно при организации локальных файлов.
Наличие в составе СУБД средств, ориентированных на разные категории пользователей, делает возможной работу с базой данных не только профессионалов в области обработки данных, но и практически любого, причем это использование может быть как для их профессиональных целей, так и для удовлетворения потребности в информации в быту и т. п.
Данные преимущества накладывают и определенные требования к БнД:
• адекватность отображения предметной области (полнота, целостность и непротиворечивость данных, актуальность информации, т. е. ее соответствие состоянию объекта на данный момент времени);
• возможность взаимодействия пользователей разных категорий и в разных режимах,, обеспечение высокой эффективности доступа для разных приложений;
• дружелюбность интерфейсов и малое время на освоение системы, особенно для конечных пользователей;
• обеспечение секретности и конфиденциальности для некоторой части данных; определение групп пользователей и их полномочий;
• обеспечение взаимной независимости программ и данных;
• обеспечение надежности функционирования БнД: защита данных от случайного и преднамеренного разрушения; возможность быстрого и полного восстановления данных в случае их разрушения; технологичность обработки данных, приемлемые характеристики функционирования БнД (стоимость обработки, время реакции системы на запросы, требуемые машинные ресурсы и др.).
По своей структуре современный БнД является сложной человеко-машинной системой, включающей в свой состав различные взаимосвязанные и взаимозависимые компоненты (рис. 1.1).
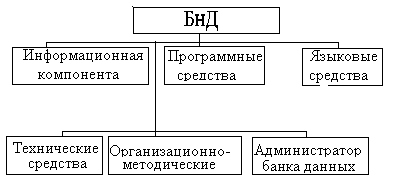
Рис. 1.1
Рассмотрим основные компоненты БнД. Информационная компонента, Ядром ее является база данных.
Определение: База данных – это совокупность используемых при функционировании АСУ данных, организованных по определенным правилам, предусматривающих общие принципы описания, хранения и манипулирования данными и независимых от прикладных программ.
Программные средства БнД. Программные средства БнД представляют собой сложный комплекс, обеспечивающий взаимодействие всех частей информационной системы при ее функционировании (рис. 1.2).
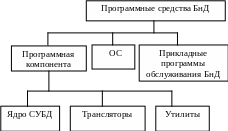
Рис. 1.2
Основу программных средств БнД представляет СУБД.
Определение 3: Система управления базами данных (СУБД) - совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
В ней можно выделить ядро СУБД, обеспечивающее организацию ввода, обработки и хранения данных, а также другие компоненты, обеспечивающие настройку системы, средства тестирования, утилиты, обеспечивающие выполнение вспомогательных функций, таких, как восстановление баз данных, сбор статистики о функционировании БнД и др. Важной компонентой СУБД являются трансляторы или компиляторы для используемых ею языковых средств.
Подавляющее большинство СУБД работает в среде универсальных операционных систем и взаимодействует е ОС при обработке обращений к БнД. Поэтому можно считать, что ОС также входит в состав БнД.
Для обработки запросов к БД пишутся соответствующие программы, которые представляют прикладное программное обеспечение БнД.
Языковые средства БнД. Языковые средства СУБД являются важнейшей компонентой банков данных, так как, в конечном счете, они обеспечивают интерфейс пользователей разных категорий с банком данных. Спектр языковых средств, применяемых в СУБД, широк. Можно выделить две концепции развития языковых средств: концепцию разделения и концепцию интеграции. При использовании концепции разделения различают языки описания данных (ЯОД), языки манипулирования данными (ЯМД), языки запросов и другие языковые средства.
В составе языков описания данных в зависимости от особенностей СУБД поддерживаются все или некоторые из следующих языков: язык описания схем, язык описания подсхем, язык описания хранимых данных, языки описания внешних данных (входных, выходных).
Языки манипулирования данными разделяются на две большие группы: процедурные и непроцедурные. При пользовании процедурными языками надо указать, какие действия и над какими объектами необходимо выполнить, чтобы получить результат. В непроцедурных языках указывается, что надо получить в ответе, а не как этого достичь.
Процедурные языки могут различаться по основным информационным единицам, которыми они манипулируют. Это могут быть языки, ориентированные на позаписную обработку данных, и языки, ориентированные на операции над множеством записей. Так, операции реляционной алгебры оперируют целиком отношением, а не каждой его записью. Примерами непроцедурных языков являются языки, основанные на реляционном исчислении. Представителем языков, основанных на реляционном исчислении кортежей, является широко используемый язык запросов SQL.
Языковые средства предназначаются для пользователей разных категорий: конечных пользователей, системных аналитиков, профессиональных программистов. Повышение уровня языковых средств, их дружелюбности приводит к тому, что все большее число функций выполняется пользователями-непрограммистами самостоятельно, без посредников.
Технические средства БнД. В качестве технических средств используются большие ЭВМ и персональные компьютеры.
Организационно-методические средства. Организационно-методические средства банка данных представляют собой различные инструкции, методические и регламентирующие материалы, предназначенные для пользователей разных категорий, взаимодействующих с банком данных.
Администраторы банка данных. Функционирование БнД невозможно без участия специалистов, обеспечивающих создание, функционирование и развитие БнД. Такая группа специалистов называется администратором банка данных (АБД).
Этапы проектирования баз данных
В широком смысле проектирование баз данных АС представляет собой процесс выработки и документирования решений по составу информационных элементов (имен атрибутов и соответствующих им множеств допустимых значений); по организации элементов в структуры, соответствующие принятым в системе уровням представления данных, и определению связей (отображений друг в друга) структур различных уровней; по определению ограничений целостности БД и соответствующих процедур их контроля по разграничению доступа к БД и описанию процессов первоначальной загрузки и ведения баз данных; по разработке или выбору требуемого программного обеспечения, а также формированию организационно-методических и инструктивных материалов. Часто понятие "проектирование базы данных" трактуется более узко: как определение структуры БД и разработка ее схемы на ЯОД конкретной СУБД.
Рассматриваемые здесь методы и средства проектирования связаны с единым итеративным нисходящим процессом, состоящим из последовательности этапов, включающих многие точки принятия решений. Хотя вся методология в перспективе ориентирована на широкое использование средств вычислительной техники, рассматриваемые методы и приемы также являются конструктивными, полезными и эффективными при ручном проектировании. Заметим, что при современном уровне развития вычислительной технологии процесс проектирования БД не может быть сделан автоматическим, так как для решения многих сложных (трудноформализуемых) проблем участие человека пока является обязательным.
Лаконичная содержательная формулировка проблемы проектированимя заключается в создании за минимальное время хорошо продуманной системы баз данных, обладающей свойствами расширяемости (учет новых требований) и целостности. Эту проблему удобно рассматривать в сопоставлении с этапами жизненного цикла системы, которые к настоящему времени можно считать общепринятыми. Жизненный цикл системы БД делится на две фазы: фазу системного анализа и проектирования и фазу эксплуатации. В течение первой фазы проектировщнк осуществляет сбор и анализ требований всех категорий пользователей и выполняет проектирование БД. В течение второй фазы осуществляется машинная реализация системы, сбор статистики и анализ функционирования.
Детализацию содержания фаз будем представлять следующими этапами.
Фаза системного анализа и проектирования:
информационно-логическое проектирование;
концептуальное проектирование;
логическое проектирование;
физическое проектирование.
Фаза реализации, функционирования и модификации:
реализация базы данных;
анализ функционирования;
модернизация и адаптация.
Здесь не нашли отражения два важнейших этапа создания АС: выбор (или разработка) системных технических средств (комплекса средств автоматизации, ЭВМ и т.д.) и системного программного обеспечения. Основой для решения этих вопросов являются первые два этапа, которые поэволяют обоснованно сформировать систему требований, определяющих желаемый облик создаваемой системы и ее технического (KCA, ЭВМ) и программного (ОС, СУБД, СМПО) обеспечений. Только после того, как организация-разработчик АС примет основные проектные решения по составу и типам ЭВМ, операционным системам и системам управления базами данных, специалисты по этим компонентам на основе концептуального проекта смогут приступить к логическому и физическому проектированию БД, а также к завершению разработки специального математического и программного обеспечении (СМПО).
Схема, представленная на рис.2.1., иллюстрирует содержание и взаимосвязь этапов фазы системного анализа и проектирования информационной базы.

Рис. 1.
Решение этой проблемы представляется в реализации двух взаимосвязанных действий: структурирования процессов и функций организационной системы и структурирования информационного содержания процессов и функций.
Функциональную модель организационной системы будем представлять совокупностью схем и описаний технологической последовательности процедур и действий должностных лиц системы по переработке информации, включая описание задач, запросов, документооборота по всем уровням организации. Основной задачей является сбор всех требований, предъявляемых к содержанию и процессу обработки данных всеми известными и потенциальными пользователями информационных ресурсов системы.
Одним из результатов информационно-функционального анализа является информационно-логическая (инфологическая) модель данных системы, соответствующая анализируемой части предметной области. Инфологическую модель данных будем формализовать семантической сетью в виде инфологического графа (ИЛГ):
Mил=<Sил, Pил, Qил>. (1)
где Sил - множество типов информационных объектов (сущностей), и информационных связей (отношений), задаваемых именами типов и составом типов своих свойств (характеристик, атрибутов) и их значений; Pил — правила интерпретации семантической сети (инфологического графа) данных; Qил — эакононерности предметной области, существенные для контроля целостности и согласованности информационной модели.
Информационно-логическая модель (ИЛМ) данных обеспечивает первоначальную формализацию описания информационного содержания автоматизируеных процессов, согласовывая и объединяя в себе представления всех категорий пользователей. Основными критериями оценки качества ИЛМ являются ее полнота и простота понимания. детальность, ясность и согласованность описаний элементов. Соответственно методы, средства и технология, применяемые на данном этапе, должны обеспечивать достижение указанных свойств модели.
Концептуальное проектирование имеет целью создания обобщенной точки зрения на информационную систму всех категорий пользователей АС, а также создание модели обработки данных (транзакций) в виде последовательности взаимосвязанных действий с базой данных в процессе ее ведения.
Концептуальная модель информационной системы понимается здесь как математически точное формализованное описание элементов данных, их семантических связей и организационной структуры с указанием ограничений целостности и согласованности данных, а также соответствующих алгоритмов контроля. Кроме того, КМ должна быть ясной, однозначно и просто понимаемой, легко трансформируемой при изменении требований или появлении новых приложений. Перечисленным требованиям к описанию КМ наилучшим образом удовлетворяют формализма реляционной модели данных. В этом случае
Мк=<Sк, Рк, Qк>. (2)
где Sк - схема модели; Рк - системы операторов реляционной алгебры; Q — система ограничений целостности.
В предложениях ANSI/SPARC понятие концептуальной схемы относится к конкретному типу СУБД (рис.1.4). Это определяет сильную зависимость схемы БД от конкретных типов ЭВМ и их программного обеспечения. В большей части работ последних лет для записи КМ используются недостаточно формальные, не очень точные и не всегда однозначно понимаемые средства. Средства с подобными свойствами будут использоваться здесь для реализации некоторых процессов проектирования на инфологическом уровне.
Необходимо также отметить, что при разработке большинства сложных АС, как правило, нельзя предвидеть заранее какие будут применены СУБД и технические средства. Более того, эти виды обеспечения будут изменяться и совершенствоваться быстрее, нежели автоматизируемые с их помощью процессы. В специальных системах, к классу которых относятся АС военного назначения, видимо, вообще не целесообразно применять СУБД общего назначения, так как они слишком универсальны и мало специализированы, что в каждом конкретном случае связано с потерей производительности.
Таким образом, излагаемый здесь подход к проектированию баз данных развивает предложения ANSI/SPARC и позволяет рассматривать логическое проектирование как процесс отображения созданной концептуальной модели в различные типы моделей, поддерживаемых конкретными СУБД. Смена типа ЭВМ и (или) СУБД может происходить как в процессе создания АС, так и в процессе ее эволюции, однако концептуальная модель данных системы остается относительно постоянной, обеспечивая устойчивую основу для развития АС.
Содержание последующих этапов жизненного цикла системы БД рассмотрим кратко.
Логическое проектирование состоит из двух взаимосвязанных процессов: проектирования логической модели БД (пере формулирование КМ в терминах ЯОД конкретной СУБД) и проектирование программ обработки данных (модели транзакций на ЯМД). В результате этого этапа разрабатывается логическая схема данных и структурированное описание обрабатывающих программ в терминах языковых средств конкретной системы.
Физическое проектирование состоит в определении способов размещения БД на носителях информации и в окончательной отладке программ обработки данных, специфицированных на предыдущем этапе. Результатом этого этапа является полностью готовая к внедрению система БД.
Фаза реализации, функционирования и модификации требует осуществить либо загрузку БД и проведение испытаний функционирования системы, либо имитационное моделирование процессов функционирования. Только на этом этапе могут быть получены такие характеристики, как времена реакции системы на различные категории запросов, время, затрачиваемое на создание, обновление, реорганизацию и контроль целостности. Этап анализа функционирования используется для определения путей совершенствования системы, оценки ее качества. Этап модернизации и адаптации предусматривает внесение в реализованный проект изменений, возникающих вследствие появления новых требований (приложений, задач), а также при оптимизации функционирующей системы путем реорганизации БД и/или внесения изменений в программное обеспечение. Реорганизация БД связана с необходимостью пере проектирования (изменения) модели базы данных. начиная с некоторого уровня представления.
Итак, процесс проектирования базы данных будем определять как процесс последовательной трансформации (отображения) моделей различных уровней друг в друга:
Mил -> Mк -> Mл -> Mф (3)
где Мл, Мф - соответственно модели данных логического и физического уровней. При этом на каждом последующем этапе увеличивается количество понятий, с помощью которых описываются результаты проектирования, другими словами, к описанию модели предыдущего уровня как бы добавляется описание проектных решений последующего уровня.
Информационно-логическая модель данных (Определение ИЛМ, основные элементы ER- диаграммы).
Цель инфологического моделирования – обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому инфологическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки текстов и неоднозначности любого естественного языка). Основными конструктивными элементами инфологических моделей являются сущности, связи между ними и их свойства (атрибуты).
Сущность – любой различимый объект (объект, который мы можем отличить от другого), информацию о котором необходимо хранить в базе данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д. Необходимо различать такие понятия, как тип сущности и экземпляр сущности. Понятие тип сущности относится к набору однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а экземпляром – Москва, Киев и т.д.
Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений: Красный, Синий, Банановый, Белая ночь и т.д., однако каждому экземпляру сущности присваивается только одно значение атрибута.
Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность. Например, для автомобильного завода цвет – это только атрибут продукта производства, а для лакокрасочной фабрики цвет – тип сущности.
Ключ (индентификатор) – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности. Минимальность означает, что исключение из набора любого атрибута не позволяет идентифицировать сущность по оставшимся. Для сущности Расписание ( с атрибутами: Номер_рейса, Дни_недели, Пункт_отправления ,Время_вылета , Пункт_назначения, Время_прибытия, Тип_самолета, Стоимость_билета) ключом является атрибут Номер_рейса или набор: Пункт_отправления, Время_вылета и Пункт_назначения (при условии, что из пункта в пункт вылетает в каждый момент времени один самолет).
Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей.