

Объектно-ориентированный подход в проектировании ос.
Используется для добавления многих расширений к ядру ОС.
Одним из примеров Объектных систем является программное обеспечение промежуточного уровня (ППО, middleware).
COM (OLE/ActiveX)
DCOM/COM+
Apple OpenDoc
CORBA – OO технология, ориентированная на различных архитектурных производителей (интероперабельность).
Виртуальная машина (вм), Экзоядро
Машина VM/370 разработана в центре IBM, (Кембридж, Массачусетс).
Проект ОС основан на следующих наблюдениях:
Система с разделением времени обеспечивает:
Многозадачность
Расширенную машину
Идея заключалась в полном разделении этих функций.
Многозадачность обеспечивает VM/370, а расширенную машину может обеспечить любая другая однопользовательская ОС.
Монитор ВМ работает с оборудованием и обеспечивает многозадачность. Но представленная ВМ не является расширенной, т.к. любая ВМ идентична оборудованию, на каждой может работать любая ОС, которая работает на аппаратуре.
Используется в технологии виртуализации в серверах.
Экзоядро развивает идею виртуальной машины, но обеспечивает каждого пользователя копией реального компьютера с подмножеством ресурсов. Например, виртуальным машинам отводится блоки на дисках от 0 до 1023, от 1024 до 2047 и т. д.
Преимущества: можно минимизировать реализацию уровня отображения и реализует многозадачность с меньшими затратами.
Управление локальными ресурсами. Управление процессами
Процесс – абстракция, описывающая выполняющуюся последовательно программу.
Процесс представляет собой единицу работы и заявку на потребление системных ресурсов.
Состояние процессов:
Выполнение – активное состояние процесса, во время которого процесс обладает всеми необходимыми ресурсами и непосредственно исполнения процессором.
Ожидание – пассивное состояние процесса, процесс заблокирован, не может выполниться по своим внутренним причинам (завершение операции ввода/вывода, получение сообщение от другого процесса, освобождение ресурсов).
Готовность – пассивное состояние процесса, процесс заблокирован в связи с внешними обстоятельствами. Процесс готов выполниться, но процессор занят выполнением другого процесса.
Эти состояния присущи любому процессу.
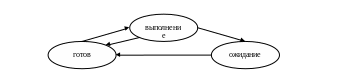
Как только процесс создаётся, он переходит в режим «Готов». Процессы группируются в очередь, откуда они переходят в состояние «Выполнение», если исчерпан определённый лимит. При истечении лимита (например, процессорного времени) процесс снова переходит в состояние «Готов», или в состояние «Ожидания».
Если процессу потребовалось ожидать некоторого события, то он переходит в состояние «Ожидания», т.е. он попадает в очередь, связанную с определённым событием (например, в очередь ожидающих завершения события ввода/вывода).
После наступления соответствующего события, процесс переходит из состояния ожидания в состояние готовности (переходит из очереди «Ожидание» в очередь «готовых» процессов).
Контекст и дескриптор процесса
На протяжении своего существования, выполнение процесса может быть многократно прервано и продолжено. Для того, чтобы возобновить выполнение процесса необходимо восстановить состояние его операционной среды (состояние регистров, состояние программного счётчика, состояние режима работы процессора, информацию о незавершенных операциях ввода/вывода, указатели на открытые файлы и т.д.). Эта информация называется контекстом процесса.
Однако, для реализации планировщика процессов требуется дополнительная информация (идентификатор процесса, данные о степени привилегированности процесса, данные о нахождении процесса в системных очередях планировщика, указатель на контекст). Эта информация называется дескриптором процесса.
Программный код начнет выполняться, когда для него ОС-ой будет процесс.
Создание процесса состоит из таких этапов:
Создать информационные структуры, описывающие процесс.
Включить дескриптор процесса в очередь готовых процессов.
Загрузить кодовый сегмент процесса в ОП или в область свопинга.
WIN32.API скрывает от пользователя реальные системные вызовы (для совместимости с разными версиями Windows).
WIN32.API – CreateProcess() - NT CreateProcess() - NTCreateThread ()
Алгоритм планирования решает следующие задачи: определение момента времени смены выполняемого процесса, выбор процесса из очереди готовых процессов.
Переключение контекстов между старым и новым процессом (аппаратно-зависимая задача).
Множество алгоритмов планирования можно разделить на 2 группы:
Алгоритмы, основанные на квантовании.
Алгоритмы, основанные на приоритетах.
Кванты, выделяемые процессу, могут быть одинаковыми для всех процессов, а могут и не быть. Могут быть как фиксированной величиной, так и изменяться в течение жизни процесса. Процессы, не использующие кванты времени могут получить, а могут и не получить компенсацию при последующем обслуживании. Возможны разные дисциплины организации очередей готовых процессов (FIFO; LIFO).
Приоритет – число, характеризующее степень привилегированности. Чем выше приоритет, тем меньше времени процесс проводит в очередях. Приоритет может назначаться директивно или вычисляться ОС по определенным правилам. Приоритет может быть постоянный или изменяющийся в течение жизни процесса. Может быть абсолютным или относительным. При относительном приоритете активный процесс не прекращает своего выполнения при появлении более приоритетного процесса, в противном случае – абсолютный приоритет.
Невытесняющая многозадачность: способ планирования процессов, при котором активный процесс выполняется до тех пор, пока он по собственной инициативе не отдаст управление ОС (планировщику, чтобы он выбрал следующий процесс для исполнения).
Вытесняющая многозадачность – способ планирования, при котором решение о переключении на новый процесс, принимает планировщик ОС, а не активная задача.
Распределение функций между планировщиком и приложением в невытесняющей многозадачности может давать определенный преимущества: возможность самостоятельно проектировать алгоритм планирования, решается проблема совместно используемых ресурсов, более высокая скорость переключения с задачи на задачу.
Нити
Это потоки, облегченные процессы. В некоторых ОС, например, Windows NT, управление единицами работы и управление ресурсами разделены между собой (NTCreateProcess(), NTCreateThread()).
Нити – те сущности, которые отвечают за управление единицами работы.
Планировщик ОС (NT) “видит” только нити и ничего не знает о процессах. Нити имеют собственные:
программные счетчики;
регистры;
стеки;
состояния.
Нити разделяют адресное пространство, глобальные переменные, открытые файлы, статическую информацию.
Лекция №5
Многозадачность в Windows.
MSDN: Platform SDK documentation/base services/dll processes and threads
В Windows имеется 2 способа использования многозадачности: многозадачность на уровне процессов и на уровне потоков.
Если требуется изоляция адресного пространства и ресурсов, используется многозадачность на уровне процессов.
Пример: системные службы Windows – автономные процессы. Крах системной службы не приводит к краху других процессов.
Процесс может использовать несколько нитей для выполнения следующих задач:
управление вводом из нескольких окон (IE, который для каждой папки создаёт отдельный поток);
управление вводом из нескольких коммуникационных устройств (например, сервер, обслуживающий подключенных клиентов отдельными потоками);
различение задач различного приоритета (например, выполнение критичных по времени задач высокоприоритетным потоком);
сохранение интерактивности приложения при выполнении фоновой задачи.
Реализация многозадачности с использованием одного процесса и нескольких потоков предпочтительна по следующим соображениям:
более быстрое переключение контекста между нитями одного процесса;
нити одного процесса разделяют глобальные переменные;
нити одного процесса разделяют описатели системных ресурсов HANDLE (в Windows).
Win32API обеспечивает альтернативные нитям методы многозадачности:
асинхронный ввод/вывод;
порты завершения ввода/вывода (I/O Completion Port);
асинхронный вызовы процедур (APC);
возможность ожидать множества коммуникационных событий с использованием WaitForMultipeObjects().
Данные способы более быстрые, чем использование нескольких нитей, каждой ожидающей своего события с WaitForSingleObject().
Рекомендации по многозадачности: использовать как можно меньше потоков для одного приложения, т.к. требуются ресурсы для хранения контекста потока, для отслеживания нескольких активных потоков и, обычно, более сложная синхронизация.
Планировщик Windows
В документации MSDN не описывается конкретный алгоритм планирования, он может изменяться в разных версиях ОС. Основными средствами, влияющими на алгоритм планирования в API, является класс и уровень приоритета (Class и Level).
Класс указывается при создании процесса (используется функция CreateProcess()). Существует 6 классов приоритета:
IDLE_PRIORITY_CLASS – самый низкий уровень приоритета, его имеют хранители экрана, средства сбора диагностики.
BELOW_NORMAL_ PRIORITY_CLASS
NORMAL_ PRIORITY_CLASS – приоритет по умолчанию.
ABOVE_NORMAL_ PRIORITY_CLASS – приоритет по умолчанию.
HIGH_PRIORITY_CLASS – приоритет, непосредственно работающий с оборудованием.
REALTIME_PRIORITY_CLASS – более приоритетен, чем многие системные потоки, работает с диском, клавиатурой и мышью.
Класс приоритета определяется и задается с помощью функций GetPriorityClass() и SetPriorityClass().
Типичному процессу нужно гарантировать непрерывное выполнение некоторой операции, для этого кратковременно приоритет повышается, затем понижается.
Внутри процесса устанавливаются относительные приоритеты для нитей (уровни приоритета, levels):
THREAD_PRIORITY_IDLE
THREAD_PRIORITY_LOWEST
THREAD_PRIORITY_BELOW_NORMAL
THREAD_PRIORITY_NORMAL
THREAD_PRIORITY_ABOVE _NORMAL
THREAD_PRIORITY_HIGHEST
THREAD_PRIORITY_TIME_CRITICAL
Уровень приоритета нити определяется и задается с помощью функций GetThreadPriority() и SetThreadPriority().
Всем нитям по умолчанию назначается нормальный уровень приоритета.
Если возникает необходимость задать уровень приоритета при создании нити, то последовательность действий:
CreateThread(CREATE_SUSPE NDED)
SetThreadPriority(…)
ResumeThread(…)
Диспетчер системы планирует нити и ничего не знает о процессах, поэтому класс приоритета и уровень комбинируется в базовый приоритет. Windows использует 32 базовых приоритета (от 0 до 31).
Переключение контекста.
Windows использует следующую последовательность шагов:
сохранить контекст только что завершившегося потока;
поместить этот поток в очередь соответствующего приоритета;
найти очередь наибольшего приоритета, содержащую готовые потоки;
удалить дескриптор потока из головы этой очереди, загрузить контекст, приступить к исполнению.
Структуры данных планировщика:
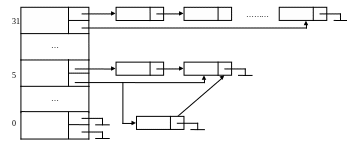
Потоки, не являющиеся готовыми:
потоки, созданные флагом SUSPENDED;
остановленные командой SuspendThread();
ожидающие события синхронизации (WaitFor…Object) или ввод/вывод.
Причины вытеснения текущего потока:
истёк квант времени;
появился более приоритетный готовый поток;
ожидание события или ввод/вывод.
Динамический приоритет используется для продвижения потоков при наличии более приоритетных.
Windows кратковременно повышает приоритеты простаивающих готовых потоков.(Priority Boost) в случае, когда:
процесс, содержащий поток, переходит на передний план.
окно процесса получает событие от мыши и клавиатуры
наступило событие, которое ожидал поток или завершился ввод/вывод.
Также Windows может увеличить квант времени потока.
В любом случае динамический приоритет не может быть меньше базового приоритета. По истечению каждого кванта динамический приоритет уменьшается на 1 до тех пор, пока не достигнет базового приоритета.
Priority Boost получают потоки с базовым приоритетом, не превышающим 15.
Лекция №6
Инверсия приоритетов
Наличие приоритетов может привести к неявной рокировке, когда более высокоприоритетный поток ждет сигнал от менее приоритетного потока.

Поток T1 выполняет код в критической секции.
Появляется поток T3 с наивысшим приоритетом в готовом состоянии
 поток T1 вытесняется.
поток T1 вытесняется.Поток T3, ожидая событие, отдает управление потоку T1, потому что в данный момент поток T1 наиболее приоритетный поток в готовом состоянии.
Если в системе появляется готовый поток T2 в то время, как T1 не успел выйти из критической секции, то он (T2) блокирует более приоритетный поток T3, т.о. происходит инверсия приоритета.
Решение проблемы Win 2000 и Win 98:
В Win 2000 планировщик учитывает время простоя готовых потоков и случайным образом повышает их динамический приоритет.
В Win 98 диспетчер обнаруживает зависимости более приоритетного потока от менее приоритетного потока через объект ядра и повышает приоритет менее приоритетного потока до уровня приоритета более приоритетного потока.
Управление несколькими процессорами
Распределение потоков между процессорами.
ThreadAffinity (соответствие потока определенному процессору). Указание данного свойства вынуждает поток исполняться на указанном подмножестве процессоров.
SetProcessAffinityMask() GetProcessAffinityMask()
SetThreadAffinityMask() GetThreadAffinityMask()
Установка аффинности может использоваться в двух случаях:
Отладка многозадачного приложения (при отладке можно наблюдать за активностью каждой отдельной нити);
Оптимизация под архитектуры с неоднородным доступом к памяти (NUMA).
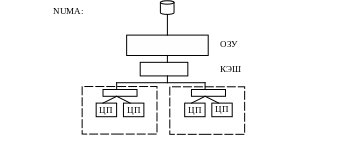
Если зависимые нити поместить на один процессор, то они будут выполняться быстрее, так как будут обрабатываться через один внутренний КЭШ процессора, а не внешний, как в противном случае.
MSDN: назначение (жесткое) нитей на процессора может снизить производительность.
Thread Ideal Processor (это не жесткая привязка, а “рекомендация” диспетчеру назначать поток на данный процессор).
SetIdealProcessor() GetProcessIdealProcessor()
Оптимизация в режиме пользователя
Указатели на функции/методы/классы.
Указатель на функцию, возвращающую значение Int.
int (*f)( ); – объявление указателя на функцию, возвращающую целое значение.
При этом: *f( ) – сама функция, f( ) – указатель.
На этот указатель выделяется память в статической области.
int *f( ); – функция, возвращает указатель на int.
int f( int (*f1)( ) ); – прототип функции, принимающей указатель на функцию в качестве аргумента.
Также можно записать следующим образом:
typedef int (*F1)( );
int f(F1 f1); – прототип функции, принимающей в качестве аргумента f1 указатель на функцию (возвращающую целое значение), имеющий тип F1, описанный ранее оператором typedef.
Обращение к методам:
Для вызова метода meth( ) объекта obj можно воспользоваться одной из следующих записей:
obj![]() meth(
);
meth(
);
obj.meth( );
(*obj).meth( );
class Std_interface {
public: virtual void start( ) = 0;
virtual void suspend( ) = 0;
}
typedef void (Std_interface::* Pstd_mem)( ); //Оператор :: – разрешение области
// видимости класса
void f(Std_interfece *p) {
Pstd_mem S = &Std_interface::suspend;//возвращает смещение до метода
//suspend( ) в таблице виртуальных
//методов Std_interface
(p *S)( );
p suspend( );
}
Данные указатели являются смещениями указателей в таблице Виртуальных методов.
Синхронизации в пользовательском режиме
Типы синхронизации:
Совместное использование разделяемого ресурса (конкурентное взаимодействие);
Уведомление потоков о завершении какой-либо операции (кооперативное взаимодействие).
Иллюстрация условия Гонки (race condition):
long g_x = 0;
DWORD WINAPI Thr1(PVOID) {
g_x++;
return 0;
}
DWORD WINAPI Thr2(PVOID) {
g_x++;
return 0;
}
LPTHREAD_START_ROUTINE thr_arr [2] = {Thr1, Thr2}
HANDLE trh_hnd [2];
Int main(…) {
DWORD id;
g_x = 0;
for (int i=0; i<2; i++) {
thr_hnd [i] = CreateThread (NULL, 0, thr_arr [i], NULL, 0, &id);
if (thr_hnd [i] = = NULL) ExitProcess(-1);
}
WaitForMultipleObjects(2, thr_hnd, TRUE, INFINITE)
}
Лекция №7
При ассемблировании возможно незапланированное переключение контекста:
Thr1 Thr2

MOV EAX, [g_x]
ADD EAX, 1
MOV [g_x], EAX
Из-за “расщепления” команды inc возможно возникновение “условия гонки” (race condition). Нужно, чтобы эти три ассемблерные команды выполнялись как единое целое.
Для того, чтобы достичь неделимости арифметических операций в WinAPI имеется функция Interlock.
DWORD WinAPI Thr1(PVOID) {
InterlockExchangeAdd (&g_x, 1);
return 0;
}
Эта функция и другие функции семейства Interlock работают в пользовательском режиме.
Варианты реализаций:
Блокирование прерываний;
Блокирование шины;
В системе команд используется специальная инструкция TestAndSetLock (TSL), при помощи которой можно реализовать обобщенную критическую секцию.
enter: TSL Reg, [Lock]
CMP Reg, #0; ;0 значит, что текущий поток выполнил блокировку
JNE enter ;и ему можно войти в критическую секцию
RET
…
leave: MOV [Lock], #0
RET
TSL неразрывным образом изменяет значение по адресу Lock на ненулевое число, при этом в регистр помещается старое значение. Такой метод называется Спин-Блокировка.
Еще один вариант Спин-Блокировки:
BOOL g_ResInUse = FALSE;
вход: while (InterlockedExchange(&g_ResInUse, TRUE) = = TRUE) sleep(0);
выход: InterlockedExchange(&g_ResInUse, FALSE);
Эти протоколы входа/выхода присваивают значение, переданное во втором параметре InterlockedExchange(), переменной, адрес которой указан в первом, и возвращают значение до модификации.
PVOID InterlockedExchangePointer(PVOID * pvTarget, PVOID * pvValue);
Long InterlockedComparePointer(PLONG plDest, LONG lExchange, Long
lComparand )
Алгоритм Петерсона для Спин-Блокировки
Peterson, 1981г.
Алгоритм разрыва узла через обмен через файлы.
white (True) {
< протокол входа //enter( ) >;
< вход в критической секции >;
< протокол выхода //leave( ) >;
< код вне критической секции >;
}
Для обеспечения работоспособности требуется выполнение 4-х условий:
Процессы не должны находиться одновременно в критических областях;
Не должно быть предположений о скорости выполнения процесса;
Процесс вне критической секции не должен блокировать другие процессы;
Ели процесс начал выполнять протокол входа, то он рано или поздно должен войти в критическую секцию.
Проанализируем это:
int lock = 0
void enter( ) {
while (lock != 0) /*ждем*/;
lock = 1;
}
void leave( ) { lock = 0; }
Гарантируют ли такие протоколы условия взаимного исключения? Нет. Введем переменную, которая определяет, чья очередь входа в критическую секцию.
int turn = 0;
w hile
(TRUE) { -//-
hile
(TRUE) { -//-
while (turn != 0) /*ждем*/; while ( turn != 1 ) -//-
< критическая секция > -//-
turn = 1; turn = 0;
< вне критической секции >; -//-
} -//-
Этим способом обеспечивается условие взаимного исключения (1 условие). Не выполняется 3 условие: застряв вне критической секции, процесс 0 блокирует процесс 1.
int turn = 0;
int interested[2] = { FALSE, FALSE };
void enter( int process) {
int other = 1–process;
interested[process] = TRUE;
turn = process;
while (turn = = process && interested[other] = = TRUE) /*ждем*/;
}
void leave( int process ) { interested [process] = FALSE; }
Этот способ обеспечивает соблюдение всех условий.
Идея алгоритма:
модификацию условий нужно выполнять до проверки, а не после;
для каждого из процессов нужно завести по флагу (массив Interested[]); ненулевое значение флага свидетельствует о том, что соответствующий процесс готов войти в критический участок, поэтому каждый из процессов перед входом в критический участок должен выполнять проверку while (Interested = = TRUE) и ждать;
если два процесса одновременно начинают выполнять проверку, то возникает тупик. Для разрешения тупика («разрыва узла») вводится вспомогательная переменная turn, которая в случае конфликта разрешает ввод в критическую секцию только одному процессу.
Так же известен алгоритм Lamport.
Лекция №8
Особенности:
volatile BOOL g_fFinished = FALSE;
/*volatile – загружаем значение из памяти при каждом обращении к переменной (отключает оптимизации компилятора).*/
int main( ) {
CreateThread (…, CalcFunc,…);
While (g_fFinished = = FALSE);
}
DWORD WINAPI CalcFunc (PVOID) {
…
g_fFinished = TRUE;
}
Если не будем использовать ключевое слово volatile, то возникнет риск того, что значения флага загрузятся в регистр процессора перед вычислением while, и в дальнейшем проверяться будет значение из регистра, т.е. ждущий процесс никогда не увидит окончания вычислений.
Thr1 Thr2

При реализации спин-блокировки возможна ситуация, когда поток длительное время опрашивает условие входа E, периодически это условие оказывается истинным, тем не менее, поток не может войти в критический участок. Происходит «отталкивание» (starvation, голодание). Можно решить, добавив Sleep(0) в конец Thr1.
Влияние КЭШ-линий.
volatile int x = 0; // Thread1( ) x++
volatile int y = 0; // Thread2( ) y++

Для ускорения работы с ОЗУ каждый из процессоров использует локальный КЭШ, однако подгрузка в КЭШ производится не побайтно, а загружается целиком КЭШ-линия (участок памяти, выровненный по 32-байтной границе). Если две переменные попадают в одну КЭШ-линию, то эффект от использования КЭШа пропадает: нужно обновлять данные и в ОЗУ и во втором КЭШе. Поэтому следует выровнять переменные по границам КЭШ-линии или вводить фиктивные переменные, чтобы гарантировать, что переменные не попадут в одну КЭШ-линию. Для того чтобы избежать этих проблем, в Windows реализован такой объект, как критическая секция.
Критическая Секция Windows
void InitializeCriticalSection (PCritical_Section);
void DeleteCriticalSection();
void EnterCriticalSection();
bool TryEnterCriticalSection();
void LeaveCriticalSection();
bool InitializeCriticalSectionAndCount();
setCriticalSectionSpinCount();
Достоинство: высокое быстродействие.
Недостатки: interlocked функции не переводят поток в режиме ожидания, нельзя указать тайм-аут, нельзя использовать при межпроцессном взаимодействии.
Синхронизация в режиме ядра
Для такой синхронизации используются объекты ядра, которые могут находиться в сигнальном (свободном) и несигнальном (занятом) состоянии.
Это – процессы, потоки, задания, файлы, консольный ввод, уведомления об изменении файлов, события, ожидаемые таймеры, мьютексы, семафоры.
WaitForSingleObject(HANDLE, DWORD dwMultiSec);
WaitForMultipleObject(…, BOOL fWaitAll, …);
Если происходит переход объект в сигнальное состояние в момент блокировки, то обычно происходит снятие блокировки, и выполняются некоторые действия, зависящие от объекта ядра.
Возвращают:
- В случае завершения тайм-аута: WAIT_TIMEOUT;
- В случае ошибки: WAIT_FAILED;
- “Указатель” на следующий в порядке ожидания объект: WAIT_OBJECT_0;
Чтобы узнать, какой именно объект перешел в сигнальное состояние, проверяем, что значение не равно WAIT_FAILED и WAIT_TIMEOUT и вычитаем из него WAIT_OBJECT_0 и получаем индекс в массиве, переданном в WaitForMultipleObject().
Управление объектами ядра
Создание CreateMutex()
Закрытие BOOL CloseHandle(HANDLE)
Каждый процесс имеет таблицу описателей:
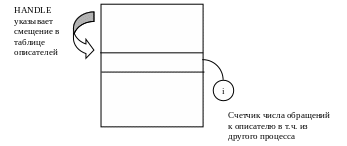
При закрытии HANDLE мы удаляем описатель из таблицы и декрементируем счетчик i. Если i = 0 – уничтожение объекта.
Наследование: SECURITY_ATTRIBUTE sa;
sa.nlength = sizeof(sa);
sa.lpSecurityDescriptor=NULL; /*NULL – защита по умолчанию; определяет, кто может пользоваться объектом (при NULL – создатель процесса и администраторы) */
sa.bInHeritHandle=TRUE; /*наследовать HANDLE*/
HANDLE hMutex = CreateMutex (&sa, FALSE, NULL);

Для передачи описателя в дочерний процесс обычно используется командная строка или переменные окружения.
Если объект создается уже после создания дочернего процесса, то дочерний процесс не содержит наследованного описателя.
Лекция №9
SetHandleInformation
GetHandleInformation
HANDLE_FLAG_INHERIT
HANDLE_FLAG_PROTECT_FROM_CLOSE (CloseHandle)
flag


Именование:
Можно задать имя:
HANDLE hMut = CreateMutex(NULL, FALSE, “SomeMutex”);
Проводится проверка, имеется ли объект ядра с нашим именем и происходит проверка типа объекта ядра.
Если объект с таким именем и типом уже существует, то функция не создает новый объект, а возвращает описатель существующего объекта (при этом 1-й и 2-й параметры игнорируются) и генерирует код оштбки.
Можно осуществить проверку на возникновение ошибки:
If (GetLastError() = = ERROR_ALREADY_EXISTS) {…}
Пространство имен объектов ядра является глобальным, если только не запущен терминал. В последнем случае к имени добавляются префиксы Global\, Local\.
Дублирование:
BOOL DuplicateHandle(
HANDLE hSourceProcessHandle,//описатель исходного процесса (GetCurrentProcess())
HANDLE hSourceHandle, //дублируемый описатель процесса-источника
HANDLE hTargetProcessHandle, //процесс-приемник
PHANDLE phTargetHandle, //описатель в процессе-приемнике
DWORD dwPesiredAccess,
DWORD dwQotions);
Особенность: нужно использовать механизм межпроцессного взаимодействия для передачи продублированного описателя (DuplicateHandle его сформирует, но нужно также поставить в известность и сам процесс-приемник).
События
События бывают:
- со сбросом вручную;
- с автоматическим сбросом.
HANDLE CreateEvent (
PSECURITY_ATTRIBUTES sa,
BOOL fManualReset,
BOOL fInitialState,
hPCTSTR name);
BOOL SetEvent (HANDLE); – устанавливает в сигнальное состояние
BOOL ResetEvent (HANDLE); – устанавливает в несигнальном состояние
BOOL PulseEvent (HANDLE); – “комбинация” Set и Reset (устанавливает в сигнальное состояние и сбрасывает в несигнальное)

Если событие с автосбросом, только один поток продолжит исполнение, а если со сбросом вручную – оба потока.
Семафоры
Смысл семафоров – подсчет числа доступных ресурсов (счетчик). Определены 2 операции:
возврата ресурсов в пул доступных ресурсов (up-операция, v-операция). Увеличивает счетчик.
захвата ресурсов (down-операция, p-операция).
Если счетчик ресурсов принимает значение 0, то поток блокируется (семафор находится в несигнальном состоянии).
Счетчик не может быть больше максимального числа ресурсов и меньше 0.
CreateSemaphore (
PSECURITY_ATTRIBUTES sa,
LONG lInitialCount,
LONG lMaxCount,
hPCTSTR name);
Операция DOWN:
BOOL ReleaseSemaphore (HANDLE, LONG ReleaseCount);
Мьютексы
Мьютекс, Mutex – от англ. Mutual Exclusion, взаимное исключение.
HANDLE CreateMutex(
PSECURITY_ATTREBUTES sa,
BOOL fInitialOwner,
LPCTSTR name);
BOOL ReleaseMutex (HANDLE);
Мьютекс можно рассматривать как бинарный семафор. Также мьютекс похож и на критическую секцию.
От семафора мьютекс отличается тем, что определено владение мьютексом для захвативших его потоков.
Отличие от критических секций: можно синхронизировать потоки в разных процессах, можно указывать тайм-аут.
Если поток «владеет» мьютексом, то вызов Wait-функции с этим мьютексом завершится успешно, при этом увеличится внутренний счетчик рекурсий. ReleaseMutex выполняет декремент счетчика рекурсий и освобождает мьютекс, если счетчик достигает «0».
Если попытаться освободить мьютекс из процесса, который им не владеет, то будет ошибка:
GetLastError = ERROR_NOT_OWNED
Если поток, владеющий мьютексом, завершается, то он переходит в несигнальное состояние, может быть использован другими потоками, на Wait-функция вернет ошибку.
GetLastError = WAIT_ABANDONED
Тупики и защита от них
Группа процессов находится в тупиковой ситуации, если каждый процесс из группы ожидает событие, которое может вызвать только другой процесс из этой же группы.
Условия возникновения тупика:
Условие взаимного исключения: каждый ресурс отдан или доступен ровно одному процессу.
Условие удержания и ожидания: процессы, удерживающие полученные ранее ресурсы, могут запрашивать новые.
Условие отсутствия принудительной выгрузки: у процесса нельзя забрать ранее полученный ресурс, процесс, владеющий ресурсом, должен сам освободить его.
Условие циклического ожидания: должно существовать 2 или более процессов, каждый из которых ждет доступа к ресурсу, удерживаемому следующим участком последовательности.
Моделирование блокировок, Холт (Holt)
Введем графические обозначения:
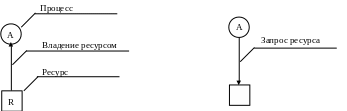
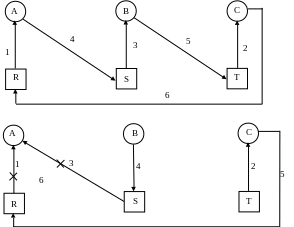
Простейший тупик:

DWORD Thr2(PVOID){ WaitforSingleObject(U); WaitforSingleObject(T);
//критическая
секция ReleaseMutex(T);
ReleaseMutex(U); }
DWORD Thr1(PVOID){
WaitforSingleObject(T);
WaitforSingleObject(U);
//критическая секция
ReleaseMutex(U);
ReleaseMutex(T); }
Лекция №10
Процесс |
Порядок захвата ресурсов |
Порядок освобождения ресурсов |
A |
|
S, R |
B |
|
T, S |
C |
|
T, R |
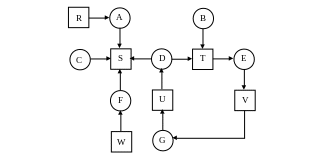
Последовательность:
![]()
Последовательность:
![]()
Здесь
![]() – захват потоком A ресурса
R;
– захват потоком A ресурса
R;
![]() – освобождение потоком A
ресурсов R и S.
– освобождение потоком A
ресурсов R и S.
Вывод:
тупики возникают не при каждом исполнении;
аккуратным планированием можно избежать блокировок;
блокировки можно обнаружить;
Стратегии борьбы с блокировками
«Страусовый алгоритм»:
Допущение, что блокировки в системе можно игнорировать. Усилия, затраченные на преодоление блокировок, могут себя не оправдать.
Обнаружение и устранение:
Дать возможность произойти блокировке, обнаружить ее и предпринять действия для ее исправления.
Способы восстановления:
- принудительная выгрузка ресурса;
- восстановление через откат (прежде чем захватить ресурс, процесс сохраняет свое состояние (checkpoint, контрольная точка), в случае конфликта можно вернуться к сохраненному состоянию);
- выгрузить процесс целиком (если нет побочных эффектов (процесс не влияет на состояние системы)).
Обнаружение тупика в случае единственности ресурса каждого типа:
В текущем состоянии построить граф Холта;
Обнаружить на нем цикл по какому-либо алгоритму:
Процесс |
Захват ресурса |
Ждет ресурс |
A |
R |
S |
B |
- |
T |
C |
- |
S |
D |
V |
S, T |
E |
T |
V |
F |
W |
S |
G |
V |
U |
Алгоритм:
Выполняется для каждой вершины графа, в начале все ребра не маркированы.
Список посещенных вершин пустой, выбираем начальную вершину M.
M добавляем в список. Если M в списке есть, то обнаружен цикл.
Если у M имеется немаркированное исходящее ребро, то идем к шагу 4, иначе – к шагу 5.
Выбираем любое немаркированное ребро, маркируем его, переходим к новой вершине и объявляем её текущей; переходим к шагу 2.
Удаляем последнюю вершину из списка, выбираем ее текущей, переходим к шагу 3.
Обнаружение тупика, если имеется несколько ресурсов каждого типа:
(E1, E2, …, Em)=E – вектор ресурсов;
Ej-
сколько ресурсов типа j
(1![]() j
m)
j
m)
(A1, A2, …, Am)=A – вектор доступных ресурсов
Матрица текущего распределения ресурсов:
![]() , где
, где
![]() – сколько процесс i
получил ресурсов типа
j.
– сколько процесс i
получил ресурсов типа
j.
Матрица запросов ресурсов:
![]()
![]()
Алгоритм:
Все процессы не маркированы:
В матрице R ищем строку, соответствующую немаркированному процессу, которая меньше либо равна А, (ri A).
Если такая строка найдена, то маркируем процесс, прибавляем строку к вектору А, возвращаемся к шагу 1.
Если процессов нет, то конец.
Если находятся немаркированные процессы, то они в тупике.
Пример: Находится ли система в тупике?
E=(4, 2, 3, 1) A=(2, 1, 0, 0)
![]()
![]()
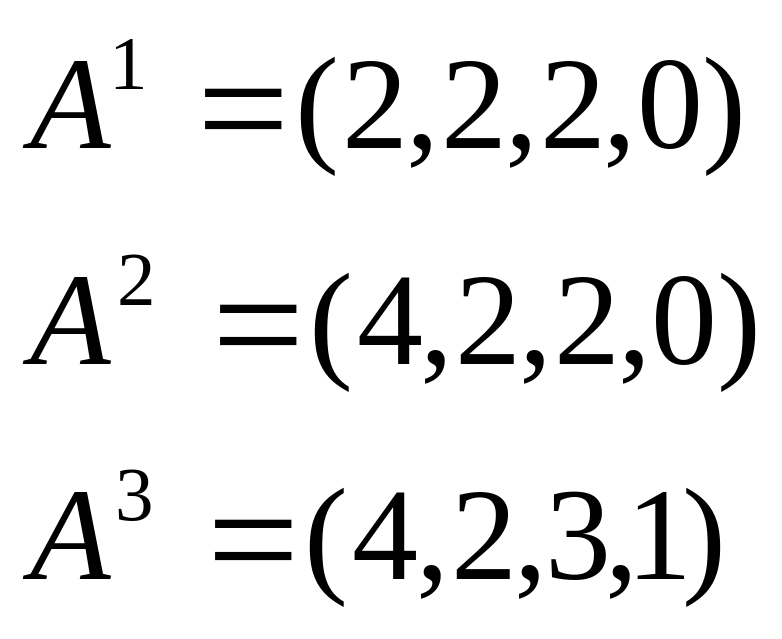
Лекция №11
Избежание взаимных блокировок
Траектория ресурсов
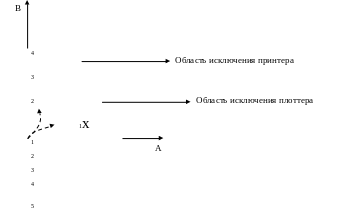
1 – захват принтера
2 – захват плоттера
3 – освобождение принтера
4 – освобождение плоттера
Точка на траектории ресурсов может двигаться только вверх и вправо.
Если во время планирования точка, обозначающая состояние системы, попадет в область Х, то со временем в системе возникнет блокировка, т.к. точка не может двигаться вниз и влево; любое состояние в области серого цвета является безопасным состоянием. В таком состоянии планировщик, путем аккуратного планирования ресурсов может избежать возникновения тупика.
Алглритм Банкира для одного вида ресурсов
Цель алгоритма: проверить, приводит ли удовлетворение запроса на ресурс к выходу из безопасного состояния системы.
Пусть имеется один ресурс некоторого типа.
А |
3 |
9 |
В |
2 |
4 |
С |
2 |
7 |

Максимальное число ресурсов, которое процесс может запросить без учета уже запрошеных
Сколько процесс уже имеет ресурсов
Чтобы проверить, приводит ли запрос к безопасному состоянию, необходимо описать матрицу распределения ресурсов (см. выше). При этом:
A, B, C – имена банка;
2ой столбец – выданные кредиты;
3ий столбец – необходимо кредитов.
Свободных кредитов 3. Можем полностью обеспечить кредитами клиента В.
A |
3 |
9 |
|
A |
3 |
9 |
|
A |
3 |
9 |
|
A |
3 |
9 |
|
A |
0 |
- |
B |
2 |
4 |
B |
4 |
4 |
B |
0 |
- |
B |
0 |
- |
B |
0 |
- |
||||
C |
2 |
7 |
C |
2 |
7 |
C |
2 |
7 |
C |
0 |
- |
C |
0 |
- |
||||
Свободно 3 |
Свободно 1 |
Свободно 5 |
Свободно 7 |
Свободно 10 |
||||||||||||||

Клиент, чей запрос будет полностью удовлетворен, вернет все взятые кредиты.
Рассмотрим состояние:
A |
3 |
9 |
2
|
A |
4 |
9 |
|
A |
4 |
9 |
|
A |
4 |
9 |
B |
2 |
4 |
B |
4 |
4 |
B |
4 |
4 |
B |
0 |
- |
|||
C |
2 |
7 |
C |
2 |
7 |
C |
2 |
7 |
C |
2 |
7 |
|||
Свободно 3 |
Свободно 2 |
Свободно 0 |
Свободно 7 |
|||||||||||
|
небезопасно |
небезопасно |
небезопасно |
|||||||||||



Недопустимо
Т.о., запрос от А на предоставление ему 1 единицы кредита следует отклонить.
Предотвращение блокировок:
Атака взаимного исключения;
Атака условия удержания и ожидания;
Пример: Если все ресурсы запрашиваются одновременно, то тупиков не возникнет; если мы ожидаем несколько ресурсов WaitForMultipleObjects(), то тупиков тоже нет.
Атака условия отсутствия принудительной выгрузки;
Атака условия циклического ожидания. Если все ресурсы пронумерованы и каждый процесс имеет право захватывать ресурс только с большим порядковым номером, чем номера уже захваченных ресурсов, то тупика не возникнет.
Лекция №12
Управление памятью
Типы адресов:
Символьные имена |
|
Id переменных в программе |
|
Транслятор |
|
Виртуальные адреса |
Условные адреса, вырабатываемые транслятором |
|
|
|
|
Физические адреса |
Номера ячеек |

При загрузке программы в память, виртуальные адреса отображаются в физические.
Работа перемещающего загрузчика состоит из загрузки программы в последовательные ячейки, начиная с некоторого адреса, и настройки смещений внутри программы относительно этого адреса.
0 |
|
|
#100 |
Величины смещений в коде программы складываются с БА (при загрузке программы) |
|
Jmp #10 |
|||
#10 |
|
|||
|
||||
|
||||
|
||||
|
|
|||
|
||||
|
Виртуальное адресное пространство |
Физическое адресное пространство |


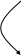
Динамическое преобразование адреса происходит при каждом обращении к адресу, но при этом используются виртуальные адреса.
Методы распределения памяти
Существует 2 основных способа:
- без использования дискового пространства (ДП);
- с использованием ДП.
Методы без использования ДП разделяются на:
с использованием фиксированных разделов;
с использованием динамических разделов;
с использованием перемещаемых разделов;
Методы с использованием ДП разделяются на:
страничный способ;
сегментный способ;
сегментно-страничный.
Без использования ДП с использованием фиксированных разделов
|
|
Физическая память |
|
|
|
Индивидуальные очереди задач |
|||||||
|
|
|
|
|
|
||||||||
|
Раздел |
|
|
|
|
|
|||||||
|
|
|
|
||||||||||
Очередь задач к разделам (общая) |
|
|
|
|
|
||||||||
Раздел |
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
||||||
|
|
|
|
………… |
|||||||||
|
Раздел |
|
|||||||||||
|
|
|
|||||||||||
|
|
|
|
|
|
||||||||
|
Раздел |
|
|
|
|
|
|||||||
|
|
|
|
||||||||||


Перед началом работы оператор разделяет физическую память на разделы заданного размера. Поступающие в систему задачи либо занимают свободный раздел подходящего размера, либо попадают в очередь. Очередь может быть либо общей для всех разделов, либо индивидуальной для каждого.
Достоинства: простота
Недостатки: недостаточная гибкость
Динамические разделы
ОС |
|
ОС |
|
ОС |
|
ОС |
|
|
31 |
|
33 |
|
33 |
|
|
|
|
|
||
|
32 |
|
32 |
|
32
|
|
|
|
|
|
|
34 |
|
|
|
|
||||
|
||||||
t0 |
|
t1 |
|
t2 |
|
t3 |



|
Занятая память |
|
Свободная память |
Распределение памяти по разделам заранее неизвестно. ОС ведет таблицы занятых и свободных разделов. При поступлении новой задачи для ее загрузки выбирается свободный раздел подходящего размера.
Принцип выбора (способы):
первый подходящий
наименьший подходящий
наибольший подходящий
Достоинства: большая гибкость, уровень мультипрограммирования не зависит от начального разбиения на разделы
Недостатки: фрагментация памяти (наличие большого числа несмежных свободных участков памяти маленького размера)
Такой способ разделения памяти используется для управления кучей процесса.
Перемещаемые разделы
Данный способ расширят управление динамическими разделами путем добавления процедуры сжатия (перемещение занятой области в одну последовательную область). В результате свободная память размещается в последовательных ячейках.
Достоинства: неразделенная свободная область памяти
Недостатки: в отличии от предыдущих способов нельзя использовать перемещающий загрузчик; процедура сжатия может быть затратна по времени (поэтому обычно сжатие выполняется когда не удается выполнить загрузку программы)
Страничный способ
Мотивом использования адресного пространства является предоставление виртуальной памяти (виртуальная память – совокупность программно-аппаратных средств, позволяющих писать программы, размер которых превосходит доступную оперативную память).
Для прикладного программиста механизм виртуальной памяти является прозрачным.

При страничной организации памяти виртуальное пространство процессов делится на страницы равного размера (размер страницы кратен степени двойки (=2k)). Физическое адресное пространство тоже делится на страницы такого же размера.
Процессы при таком разбиении размещаются в физическом адресном пространстве необязательно по непрерывным адресам памяти. Часть адресного пространства процесса может быть выгружена во внешнюю память.
Обращение к памяти выполняется по следующей схеме:

В случае, если виртуальная страница присутствует в физической памяти, старшие биты виртуального адреса (Р) содержат номер виртуальной страницы. По таблице страниц устанавливаем соответствующий адрес физической страницы. Он конкатенируется с младшими k разрядами виртуального адреса. Получается физический адрес.
В случае, если виртуальный адрес отсутствует в физической памяти (клетка ВП, содержимое располагается во внешней памяти) происходит страничное прерывание. Процесс переходит к ожиданию на системном объекте ядра, и запускается процедура подгрузки страниц, а контекст переключается на следующий готовый процесс.
Для подгрузки страниц определяется место в физической памяти. Если оно есть, то выполняется подгрузка, коррекция таблицы страниц, перевод процесса в готовое состояние. В противном случае, выбирается страница для вытеснения. Если страница была модифицирована, то предварительно необходимо записать страницу на диск, иначе содержание страницы переписывается загружаемой страницей.
Кандидаты на выгрузку определяются управляющей информацией ОС.
Лекция №13
Сегментный способ

В таблице сегментов указывается базовый адрес сегмента в физической памяти (а не номер, как в случае страничного способа). Размер сегмента не фиксирован, в отличие от страничного способа адресации.
Сегментно-страничный способ
Схема преобразования адреса

При страничном распределении памяти адресное пространство делится механически на страницы равного размера. При сегментном распределенные размеры сегментов произвольны, сегменты снабжены атрибутами, определяющими способ их использования.
Разделение программы на сегменты определяется программистом или компилятором. Атрибуты сегмента определяют способ его использования: для исполнения, чтения, записи. Сегментное распределение позволяет использовать общие сегменты.
Цель сегментно-страничной организации памяти: сохраняя преимущества сегментного распределения (осмысленное распределение памяти), решить проблему фрагментации физической памяти.
При сегментно-страничной организации виртуальный адрес состоит из 3 частей: g, p, S. Номер сегмента преобразуется с использованием таблицы сегментов, а номер страницы – с использованием таблицы страниц. В результате линейный физический адрес состоит из 2 частей: номера физической страницы n и смещения S.
Свопинг
Виртуализация памяти может быть осуществлена на основе двух подходов – это виртуальная память и свопинг. Свопинг (swapping) – способ управления памятью, при котором образы процессов выгружаются на диск и возвращаются в оперативную память целиком. Свопинг представляет собой частный случай виртуальной памяти и, следовательно, более простой в реализации способ совместного использования оперативной памяти и диска. Однако подкачке свойственна избыточность.

Чтобы загрузить процессор вычислительными задачами, задачи ввода/вывода целесообразно сбросить на диск.
Кэш-память

Кэш-память – способ организации совместной работы устройств хранения, различающихся стоимостью хранения единицы информации и скоростью доступа.
Цель: увеличить скорость, понизить стоимость за счет размещения часто используемой информации в более быстром ЗУ.
Механизм кэша прозрачен для пользователя.

Кэш одновременно с памятью «прослушивает» запрос ЦП, но ответить (если данные есть) успевает быстрее.
Тег – адрес нескольких последовательно расположенных ячеек.
Последствия такой организации памяти для программиста: память разбивается на кэш-линии (несколько последовательных ячеек), следовательно, требуется выравнивание по границе кэш-линии.
Работа кэша основана на принципах пространственной и временной локальности, обеспечивающих высокий процент «попадания» в кэш.
tдоступа =p·tкэш + (1-p)·tпамяти; p~90%
Пространственная локальность: если обращение происходит по адресу At , то с большой долей вероятности в момент времени (t+1) происходит обращение по адресу (А±1).
Временная локальность: существует большая вероятность того, что в следующий момент времени (t+τ) произойдет обращение к этой же области с адресом А: Аt→A t+τ.
Средства аппаратной поддержки управления памятью Intel i386
Микропроцессоры семейства i386 имеют два режима работы: реальный (real mode) и защищенный (protected mode).
В защищенном режиме доступны сегментный и страничный механизмы виртуальной памяти.
В реальном режиме процессор работает, как и 8086, с расширенным набором команд.
Для работы в адресном пространстве 1МБ надо сформировать адрес определенным образом:

Этот режим (реальный) устанавливается по сбросу и используется для начальной инициализации системы. Путем записи управляющих битов в регистры командой MOV процессор переводится в защищенный режим. В защищенном режиме всегда включен сегментный механизм, и может быть установлен режим v86 (virtual 86), при котором процессор работает как несколько процессоров 8086 с общей памятью. Кроме того, в защищенном режиме может быть включен режим страничной адресации.
Лекция №14
Сегментный механизм
Структуры данных
а) Селектор
GDT – глобальная дескрипторная таблица
LDT – локальная дескрипторная таблица
б) Регистр GDTR

в) Дескриптор сегмента (данных/кода)

Регистр GDTR описывает положение глобальной дескрипторной таблицы в физической памяти. В нем указывается размер таблицы в байтах.
Поскольку в сегментном регистре на указание индекса дескриптора сегмента отводится 13 бит, всего сегментов 213 = 8192.
Размер дескриптора 8 байт; с учетом 8192 возможных сегментов, размер дескрипторной таблицы составит 8·8192 = 216 = 64 КБ.
Бит G определяет способ изменения размера сегмента (в байтах – G=0, или в страницах – G=1).
Если G=0, то размер сегмента 220 = 1 МБ (совместимость с 8086, используется в режиме v86).
Если G=1, то при 4КБ страницах, 4КБ·220 = 4 ГБ.
Бит D определяет выравнивание сегментов по 32-битной (D=1) или 16-битной границе (D=0).
Бит P – бит присутствия сегмента в физической памяти.
Бит DPL – уровень привилегий дескриптора, определяет, можем ли мы пользоваться дескриптором. Если CPL≤DPL – доступ разрешен.
Тип сегмента:
·S=0 – системные сегменты (LDT – локальная дескрипторная таблица; TSS – сегмент состояния задачи, в который отображается содержимое контекста при переключении задач; ловушки (шлюзы) вызова – специальные регистры, предназначенные для вызова высшего уровня привилегий с низшего, и т. д.).
·S=1 – пользовательские сегменты:
E=0 – сегмент данных;
Е=1 – сегмент кода;
ED – бит распространения сегмента:
ED=0 – в сторону старших адресов,
ED=1 – в сторону младших адресов (стек);
W – бит, указывающий, была ли запись в сегмент с момента последней очистки (устанавливается аппаратно, сбрасывается программно);
А – бит доступа к сегменту (А=1 – произошел доступ с момента загрузки);
С – бит подчинения (если C=1, то проверка CPL≤DPL игнорируется, и мы можем вызвать более привилегированный код);
R – возможность чтения кодового сегмента.

Если используется адресация из таблицы GDT, то индекс сдвигается влево на 3 разряда (т.к. дескриптор имеет размер 8 Б = 23), получается смещение в таблице GDT. Проверяем, не выходит ли смещение за границы таблицы (смотрим на младшие 16 разрядов GDTR, хранящих ее размер). Далее берем 32-битный адрес GDT и складываем с этими смещением. В итоге получается 32-битный адрес дескриптора в физической памяти. При этом определяется, присутствует ли сегмент в физической памяти и разрешен ли доступ к нему. Если доступ разрешен, то берется базовый адрес сегмента из дескриптора (“база”) и складывается со смещением из команды. Также на этой стадии производится контроль выхода за границу сегмента. Результатом является 32-битный адрес в физической памяти.
Если обращение идет через локальную дескрипторную таблицу LDT (см. соответствующий признак в селекторе), то используется регистр LDTR, который указывает на дескриптор LDT в глобальной дескрипторной таблице GDT. С использованием этого дескриптора вычисляется базовый адрес LDT в физической памяти. Далее преобразование происходит аналогичным способом.
Для увеличения скорости преобразования адреса каждому (из 6) сегментному регистру соответствует теневой 8-байтный (64 бита) регистр, хранящий дескриптор, соответствующий значению сегментного регистра.
Таким образом, для инициализации системы в защищенном режиме необходимо как минимум создать дескрипторную таблицу с одним входом и проинициализировать GDTR.
Если включен страничный механизм, то вычисленный 32-битный адрес подвергается дальнейшему преобразованию блоком управления страничной памятью.
Лекция №15
Страничный механизм
Дескриптор страниц:

220 = 1 М – число страниц
32-20 = 12, 12 бит – смещение
212 = 4 К – размер страницы
AVL – резерв ОС;
D – признак модификации;
А – признак того, был ли доступ;
PCD, PWT – управление кэшированием страницы;
U – пользователь/супервизор;
W – разделение записи в страницу;
Р – бит присутствия страницы в физической памяти.
Таким образом, для хранения таблицы страниц в физической памяти потребуется 4 МБ оперативной памяти, что привело бы к нерациональному использованию физической памяти. Поэтому в архитектуре i386 используется двухуровневый механизм преобразования линейного виртуального адреса в физический.
Схема преобразования адреса:

Идея механизма состоит в том, чтобы использовать страничный механизм для управления самой таблицей страниц, т.е. части таблицы страниц могут храниться во внешней памяти и подгружаться в ОП по мере необходимости.
Таблица страниц состоит из каталога разделов и разделов.
Старшие 10 бит линейного виртуального адреса используются для адресации раздела внутри каталога разделов. Следующие 10 бит используются для адресации страницы внутри раздела. Т.е., каталог разделов, так же как и раздел, может включать в себя 1024 (210) дескриптора. Т.к. размер дескриптора 4 Б (32 бита), то данная структура целиком умещается в физическую страницу (4 КБ).
Каталог разделов всегда присутствует в физической памяти, его адрес содержится в управляющем регистре CR3.
Старшие 10 бит умножаются на 4 (т.к. дескриптор имеет размер 4 Б = 22) и складываются с адресом в CR3, получается адрес дескриптора раздела в физической памяти. В нем содержится номер физической страницы раздела. С его использованием вычисляется адрес дескриптора запрашиваемой страницы внутри раздела. Наконец, этот дескриптор содержит адрес запрашиваемой физической страницы.
В блоке управления страницами кэшируется 20 последних комбинаций номеров виртуальной и физической страницы.
Средства вызова подпрограмм и задач
Существуют внутрисегментные и межсегментные вызовы, которые осуществляются командами CALL и JMP. Внутрисегментные вызовы не имеют особенностей в i386. Различаются межсегментные вызовы: с использованием дескриптора сегмента кода, шлюза вызова и вызова с переключением задачи через TSS (сегмент состояния задачи).
1) Непосредственный вызов (вызов через дескриптор кода)

С=0: вызов разрешен в случае CPL≤DPL;
С=1: вызов разрешен в любом случае.
При вызове может указываться дескриптор сегмента кода. В этом случае возможны подчиненный и неподчиненный вызовы. При подчиненном вызове (С=1) можно вызвать сегмент кода с более высоким уровнем привилегий, чем CPL, при этом текущий уровень привилегий не изменяется. При неподчиненном вызове (C=0) вызов осуществляется только в случае CPL≤DPL. Недостаток механизма в том, что он не обеспечивает защиту кода ОС (можно задать произвольную точку входа в кодовый сегмент); требуется разделять стеки ОС и стеки пользователя.
2) Вызов через шлюз

Селектор – селектор сегмента кода, в котором находится вызываемая процедура или TSS.
Смещение – точка входа в процедуру.
Счетчик слов показывает, сколько слов требуется скопировать из стека текущего уровня привилегий в стек уровня привилегий вызываемой подпрограммы. Вызов разрешен, если CPL≤DPL, но DPL сегмента, на который указывает селектор, может быть любым, и при удачном вызове процедура выполняется именно с указанным в требуемом сегменте уровнем привилегий DPL.

В команде CALL может быть непосредственно указан селектор сегмента TSS, в котором хранится полное состояние задачи, на которую выполняется переключение. Состояние текущей задачи запоминается в сегменте TSS, на который указывает регистр TR.
Лекция №16
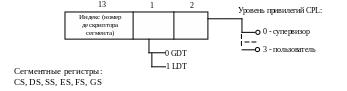
Структура виртуального адресного пространства процесса
А) Серверные версии ОС (Win 2k Advanced Server)
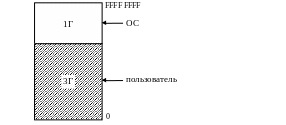
Б) ”Десктопные” (Win NT/2k)
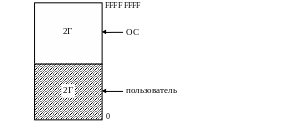
В) Win 95/98/ME
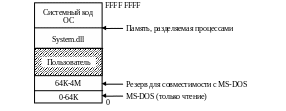
В ОС Windows (32 bit) пользователь может выделить блок памяти, располагающийся по непрерывным адресам, размером ~2-3 ГБ в зависимости от настройки в реестре. Системный код ОС помещается (проецируется) в адресное пространство процесса (в его сегмент 4 ГБ).
В Win 98/ME не используется защита памяти от ошибочных или злонамеренных действий пользователя.
Для выделения памяти в 2 ГБ следует использовать функцию VirtualAlloc.
Пример:
Поиск простых чисел методом решета Эратосфена.
int main (int args, char *args[]){
BOOL bSuccess;
SYSTEM_INFO sSysInfo;
// ввод размера массива флагов в 1MБ
MAXNUM *= numMB; //размер массива в байтах
GetSystemInfo(&sSysInfo);
dwPageSize = sSysInfo.dwPageSize;
/*
Резервирование блока памяти размером MAXNUM в произвольной области виртуальной памяти процесса.
*/
arr = (LPSTR)VirtualAlloc(NULL, MAXNUM, MEM_RESERVE,
PAGE_NOACCESS);
// NULL – адрес, MAXNUM – размер, MEM_RESERVE – область памяти,
// PAGE_NOACCESS – доступ
if (arr = = NULL) ExitProcess(-1);
else printf(“VirtualAlloc Succeeded\n”);
/*
Вся виртуальная память процесса разделена на страницы, которые находятся в следующем состоянии:
free – свободная (доступ к таким страницам запрещен). При обращении к таким страницам возникает страничное прерывание.
reserve – зарезервированная (OC подготавливает необходимые управляющие структуры для этих страниц, но физическая память не выделена, и возникает страничное прерывание).
committed – выделенная (страница присутствует в физической памяти, при обращении прерывание не происходит).
*/
_ _try {
//начало блока структурированной обработки исключений
for (i=0; i<MAXNUM; i++) { num=i; arr[num]=0; }
for (i=2; i<MAXNUM; i++) {
num=i;
if (arr[num]) continue;
printf(“%d\n”, i);
for (j=i*2; j<MAXNUM; j+=i) { num=j; arr[num]=1; }
}
}
/*
в блоке выполняем обращение к массиву arr, как будто память действительно выделена, при этом перехватываем возникающие страничные прерывания и вручную выделяем память под запрашиваемые страницы.
*/
_ _except(PageFaultException(GetExceptionCode()))
{
ExitProcess(-2)
}
/*обработка исключительной ситуации находится в обработчике
_ _except(PageFaultException())
*/
/*
Стандартная конструкция C++ для перехвата исключений try/catch/finally
catch(ExceptionType C) {…}
В отличие от обработки исключений в языке C++, фильтр исключения (см. _ _except(PageFaultException())) содержит выражение, вычисляемое в момент исключения. Значение этого выражения управляет передачей управления.
Также используются _ _finally, _ _leave.
_ _finally выполняется всегда после try (не смотря на то, произошло ли исключение, или нет).
Специальные ключевые слова, обрабатываемые компилятором:
GetExceptionCode()
GetExceptionInformation()
…
*/
}
INT PageFaultException(DWORD dwCode) {
LPVOID lpvResult;
DWORD comsize;
if (dwCode != EXCEPTION_ACCESS_VIOLATION)
return EXCEPTION_EXECUTE_HANDLER;
if (MAXNUM-num>dwPageSize)
comSize = dwPageSize
else comSize=MAXNUM-num;
lpvResult = VirtualAlloc(&arr[num], comSize, MEM_COMMIT,
PAGE_READWRITE);
if (lpvResult = = NULL) return EXCEPTION_EXECUTE_HANDLER;
return EXCEPTION_CONTINUE_ EXECUTION;
}
/* в отличие от обычных обработчиков исключений, здесь определена семантика продолжения обработки (EXCEPTION_CONTINUE_ EXECUTION)
EXCEPTION_CONTINUE_ SEARCH – продолжает искать следующий фильтр.
Глобальная переменная num используется для передачи информации об адресе, в котором возникло исключение. В общем случае получить этот адрес можно с помощью GetExceptionInformation()
*/
Пример:
Файлы, отображаемые в память
hMapFile = CreateFileMapping(hFile,
NULL, // безопасность
PAGE_READWRITE, // доступ
0, 0, // размер объекта и файла
''Name'');
lpMapAddress = MapVievOfFile(hMapFile, FILE_MAP_ALL_ACCESS, 0, 0, 0);
*((LPDWORD) pMapAddress)
MapFile можно использовать для доступа к области памяти другого процесса (разделение файла между процессами); упрощает доступ к файлу (не нужно использовать ReadFile, WriteFile, достаточно использовать разадресацию).
Средства ввода/вывода
Классификация устройств:
Блок-ориентированные
Байт-ориентированные
Другие
Как адресовать регистры контроллера?
Move (отображение на память)
Достоинства: удобство
Недостатки: сокращается объем доступной памяти, устройства ввода/вывода имеют более низкое быстродействие, чем обмен между процессором и памятью, поэтому используются специальные приёмы (представление окружающего адресного пространства как более медленной шины, для чего используются мосты чипсета).