

Классификация БД. Типология моделей представления информации (инфологические, даталогические, физические).
База данных— представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов и т.п.), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью ЭВМ (База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных).
Классификация БД:
по модели данных
иерархическая – представление базы данных в виде древовидной (иерархической) структуры, состоящей из объектов (данных) различных уровней;
объектная и объектно-ориентированная – модель работы с объектными данными;
объектно-реляционная – реляционная модель данных, поддерживающая объектно-ориентированный подход: объекты, классы и наследование;
реляционная – логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка;
сетевая – логическая модель данных, являющаяся расширением иерархического подхода, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных.
Классификация по среде постоянного хранения:
во вторичной памяти– средой постоянного хранения является периферийная энергонезависимая память (например, жёсткий диск).В оперативную память СУБД помещает лишь кеш и данные для текущей обработки;
в оперативной памяти – все данные на стадии исполнения находятся в оперативной памяти;
в третичной памяти – средой постоянного хранения является отсоединяемое от сервера устройство массового хранения, как правило на основе магнитных лент или оптических дисков;
во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кеш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация по содержимому
географическая;
историческая;
научная;
мультимедийная и т.д.;
Классификация по степени распределённости:
централизованная, или сосредоточенная – БД, полностью поддерживаемая на одном компьютере.
распределённая – БД, составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
неоднородная – фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД
однородная – фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
фрагментированная, или секционированная – методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
тиражированная – методом распределения данных является тиражирование (репликация).
Другие виды БД
пространственная – БД, в которой поддерживаются пространственные свойства сущностей предметной области.
временная, или темпоральная– БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
пространственно-временная БД –в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
циклическая – БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения данных одни и те же записи используются циклически.
Модель данных — это абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов (объекты моделируют структуру данных, а операторы — поведение данных), в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь, которая включает, по меньшей мере, три аспекта:
аспект структуры: методы описания типов и логических структур данных в базе данных;
аспект манипуляции: методы манипулирования данными;
аспект целостности: методы описания и поддержки целостности базы данных.
Аспект структуры определяет, что из себя логически представляет база данных, аспект целостности определяет средства описаний корректных состояний базы данных, аспект манипуляции определяет способы перехода между состояниями базы данных (то есть способы модификации данных) и способы извлечения данных из базы данных.
Инфологическая модель данных - обобщенное неформальное описание создаваемой БД, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием БД
или по-другому – обобщенное, непривязанное к каким-либо СУБД описание предметной области.
Даталогическая модель данных - понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается с учетом конкретной реализации СУБД, также с учетом специфики конкретной предметной области на основе ее инфологической модели.
Физические модели - определяют способы размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне.
Структуры и типы данных. Массивы, деревья, списки, графы. Операции над данными.
Типы данных: Целые числа, дробные числа, строки, бинарные данные, дата и время, OLE, денежный, поле МЕМО, логический
Операции над данными: добавление, изменение, удаление, извлечение, обновление, поиск.
Включить в групповое отношение — связать существующую подчиненную запись с записью-владельцем. Переключить — связать существующую подчиненную запись с другой записью-владельцем в том же групповом отношении.
Массив - упорядоченная структура однотипных данных. Упорядоченность определяется тем, что отдельные элементы массива обозначаются упорядоченной совокупностью n значений, называемых индексами. Число n называется размерностью массива.
Одномерный массив (линейная таблица) - массив, элементами которого являются атомарные переменные, например, одномерный массив вещественных чисел.
Массив, элементами которого являются одномерные массивы, называется двумерным массивом. В данном случае размерностью массива будет количество строк - например, n, количество столбцов - количество элементов в строке - например, m.
Дерево - специальный вид направленного графа. Графы - структуры данных, состоящие из узлов связанных дугами. Каждая дуга показывает однонаправленную связь между двумя узлами. В организационной диаграмме, узлы - сотрудники, а каждая дуга описывает подчинения. В перечне материалов, узлы - модули (в конечном счете, показываемые до индивидуальных частей), и дуги описывают отношение "сделан из".
Вершина дерева называется корнем. В организационной диаграмме, это самый большой начальник; в перечне материалов, это собранная деталь. Двоичное дерево - это дерево, в котором узел может иметь не более двух потомков; В общем случае, n-мерное дерево - то, в котором узел может иметь не больше чем n узлов - потомков.
Узлы дерева, которые не имеют поддеревьев, называются листьями. В перечне материалов, это - минимальные части, на которые может быть разобрана деталь. Потомки, или дети, родительского узла - все узлы в поддереве, имеющего родительский узел корнем.
В SQL, любые отношения явно явно описываются данными.. Типичный способ представления деревьев состоит в том, чтобы поместить матрицу смежности в таблицу. Т.е. один столбец - родительский узел, и другой столбец в той же самой строке - дочерний узел (пара представляет собой дугу в графе).
Линейный список представляет собой линейную последовательность элементов. Для каждого из них, кроме последнего, имеется следующий элемент, и для каждого, кроме первого - предыдущий. Список традиционно изображают в виде последовательности элементов, каждый из которых содержит ссылку (указатель) на следующий и/или предыдущий элемент, однако заметим, что физически в представлении элементов списка может и не быть никаких ссылок.
Типичный набор операций над списком будет включать добавление, удаление и поиск его элементов, вычисление длины списка, последовательную обработку элементов (итерацию) списка.
Фактографические, документальные, мультимедийные типы баз данных.
Документальные - обслуживают класс задач, которые не предполагают однозначного ответа на поставленный вопрос. Базу данных таких систем образует совокупность неструктурированных текстовых документов (статьи, тексты законов) и графических объектов, снабженная тем или иным формализованным аппаратом поиска. Цель системы, как правило, - выдать в ответ на запрос пользователя список документов или объектов, в какой-то мере удовлетворяющих сформулированным в запросе условиям. Принципиальной особенностью документальной системы является ее способность, с одной стороны, выдавать ненужные пользователю документы, а с другой - не выдавать нужные (например, если автор употребил какой-то синоним или ошибся в написании). Документальная система должна уметь по контексту определять смысл того или иного термина, например, различать «ромашка» (растение), «ромашка» (тип печатающей головки принтера).
Фактографическая - это массив фактов - конкретных значений данных об объектах реального мира. Информация в фактографической БД хранится в четко структурированном виде, поэтому она способна давать однозначные ответы на поставленные вопросы, например: «Кто стал Президентом России на выборах в марте 2002 года?» и т. д. Фактографические БД используются в науке, материальном производстве, на транспорте, в медицине, спорте и т.д.
Мультимедийная база данных может содержать текстовую, звуковую, графическую, а также фото- и видеоинформацию. Мультимедийные БД используются при создании различных презентаций, мультимедийных представлений или игр.
Реляционная алгебра и реляционное исчисление. Основные операции реляционной алгебры и реляционного исчисления.
Основной компонент реляционной модели– реляционная алгебра, которая, в основном, состоит из набора операторов, использующих отношения в качестве операндов и возвращающих отношения в качестве результата. Реляционная алгебра – алгебраическое изображение, в котором запросы выражаются с помощью специальных операторов отношений.
В реляционной алгебре существует понятие реляционной замкнутости – результат выполнения любой операции над отношением также является отношением. Поскольку результат выполнения любой операции имеет тот же тип, что и исходные объекты (отношения), результат одной операции может использоваться в качестве исходных данных для другой.
Реляционная алгебра состоит из восьми операторов, составляющих две группы по четыре оператора:
Основные операции над множествами: объединение, пересечение, разность и декартово произведение (все они модифицированы с учетом того, что их операндами являются отношения, а не произвольные множества).
произведение –(реляционное) декартово произведение двух отношений А и В (что записывается как A TIMES В) как новое отношение с заголовком, представляющим собой объединение заголовков двух исходных отношений А и В, и с телом, состоящим из множества всех кортежей t, таких, что каждый кортеж t представляет собой объединение двух кортежей, один из которых принадлежит отношению А, а другой — отношению В.
объединение – для заданных отношений А и В одного и того же типа (например, оба отношения содержат кортежи поставщиков или кортежи деталей, но не комбинацию этих типов кортежей)объединением этих двух отношений (что записывается как «A UNION В») называется новое отношение того же типа с телом, состоящим из множества всех кортежей t, которые принадлежат либо отношению А, либо отношению В, либо обоим отношениям одновременно.
пересечение – для двух совместимых по типу отношений А и В (что записывается как A INTERSECT В) пересечением называется отношение того же типа с телом, состоящим из множества всех кортежей t, которые принадлежат одновременно обоим исходным отношениям А и В;
разность – вычитанием двух совместимых по типу отношений А и В (что записывается как AMINUS В, причем порядок их указания здесь играет роль) называется отношение того же типа, что и отношения А и В, с телом, состоящим из множества всех кортежей t, которые принадлежат отношению А, но не принадлежат отношению В.
Специальные реляционные операции: выборка, проекция, соединение и деление.
A |
||
S# |
SNAME |
City |
1 |
Smith |
London |
4 |
John |
New York |
B |
||
S# |
SNAME |
City |
1 |
Smith |
London |
2 |
Brian |
London |
S# |
SNAME |
City |
1 |
Smith |
London |
4 |
John |
New York |
2 |
Brian |
London |
Пересечение: A INTERSECT B
S# |
SNAME |
City |
1 |
Smith |
London |
Вычитание: AMINUSB BMINUS A
S# |
SNAME |
City |
4 |
John |
New York |
S# |
SNAME |
City |
2 |
Brian |
London |
Декартово произведение: A Times B
A |
S# |
S1 |
S2 |
B |
P# |
P1 |
P2 |
S# |
P# |
S1 |
P1 |
S1 |
P2 |
S2 |
P1 |
S2 |
P2 |
Реляционное исчисление – логическое изображение, в котором запросы выражаются с помощью формулирования некоторых логических ограничений, которым должны удовлетворять кортежи. Базисными понятиями исчисления являются понятие переменной с определенной для нее областью допустимых значений и понятие правильно построенной формулы, опирающейся на переменные, предикаты и кванторы.
В зависимости от того, что является областью определения переменной, различаются исчисление кортежей и исчисление доменов. В исчислении кортежей областями определения переменных являются отношения базы данных, т.е. допустимым значением каждой переменной является кортеж некоторого отношения. В исчислении доменов областями определения переменных являются домены, на которых определены атрибуты отношений базы данных, т.е. допустимым значением каждой переменной является значение некоторого домена.
Исчисление кортежей: для определения кортежной переменной используется оператор RANGE. Например, для того, чтобы определить переменную СОТРУДНИК, областью определения которой является отношение СОТРУДНИКИ, нужно употребить конструкцию
RANGE СОТРУДНИК IS СОТРУДНИК
При использовании кортежных переменных в формулах можно ссылаться на значение атрибута переменной (для того, чтобы сослаться на значение атрибута СОТР_ИМЯ переменной СОТРУДНИК, нужно употребить конструкцию СОТРУДНИК.СОТР_ИМЯ).
исчисление доменов: областью определения переменных являются не отношения, а домены. Применительно к базе данных «сотрудники-отделы» можно говорить, например, о доменных переменных ИМЯ (значения - допустимые имена) или НОМСОТР (значения - допустимые номера сотрудников).
Основным формальным отличием исчисления доменов от исчисления кортежей является наличие дополнительного набора предикатов, позволяющих выражать так называемые условия членства. Если R - это n-арное отношение с атрибутами a1, a2, ..., an, то условие членства имеет вид
R (ai1:vi1, ai2:vi2, ...,aim:vim) (m<= n),
где vij– это либо литерально задаваемая константа, либо имя кортежной переменной. Условие членства принимает значение true в том случае, если в отношении R существует кортеж, содержащий указанные значения указанных атрибутов. Если vij - константа, то на атрибут aij задается жесткое условие, не зависящее от текущих значений доменных переменных; если же vij - имя доменной переменной, то условие членства может принимать разные значения при разных значениях этой переменной.
Реляционная модель данных. Специальные операции реляционной алгебры.
Реляционная модель данных (РМД) — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка.
Реляционная модель данных включает следующие компоненты:
структурный аспект – данные в базе воспринимаются пользователем, как таблицы (и никак иначе);
аспект целостности – эти таблицы удовлетворяют определенным условиям целостности;
аспект обработки – в распоряжении пользователя имеются операторы манипулирования данными (например, выборки информации), которые генерируют новые таблицы на основании уже имеющихся и среди которых есть по крайней мере операторы выборки (restrict), проекции (project) и объединения (join);
Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). Реляционная модель данных предполагает следующее:
данные представлены посредством строк в таблицах;
для обработки строк данных представляются операторы, которые напрямую поддерживают процесс логического получения дополнительных таблиц.
В реляционной модели объекты и взаимосвязи
между ними представляются с помощью
таблиц. Для ее формального определения
используется фундаментальное понятие
отношения.
реляционной модели объекты и взаимосвязи
между ними представляются с помощью
таблиц. Для ее формального определения
используется фундаментальное понятие
отношения.
В реляционной базе данных каждая таблица должна иметь первичный ключ (ключевой элемент) – поле или комбинацию полей, которые единственным образом идентифицируют каждую строку в таблице (требование целостности базы данных).
В реляционных базах данных допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных данных (дата, время, временной интервал).
Домен – допустимое потенциальное множество значений данного типа (например, список допустимых имен). Данные считаются сравнимыми только в том случае, когда они относятся к одному домену.
Схема отношения базы данных – это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}.
Схема базы данных (в структурном смысле) – это набор именованных схем отношений.
Кортеж, соответствующий данной схеме отношения в базе данных – множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" – допустимое значение домена (типа данных) данного атрибута.
Отношение – множество кортежей данной базы данных, соответствующих одной схеме отношения. Обычным представлением отношения является таблица, заголовком которой является схема отношения, а строками – кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы.
Важным преимуществом реляционной модели является то, что в ее рамках действия над данными могут быть сведены к операциям реляционной алгебры, которые выполняются над отношениями. Это такие операции, как объединение, пересечение, вычитание, декартово произведение, выборка, проекция, соединение, деление.Специальнымиоперациями реляционной алгебры являются выборка, проекция, соединение и деление.
в
 ыборка
– возвращает отношение, содержащее
все кортежи из заданного отношения,
которые удовлетворяют указанным
условиям. Операцию выборки также иногда
называют операцией ограничения.
ыборка
– возвращает отношение, содержащее
все кортежи из заданного отношения,
которые удовлетворяют указанным
условиям. Операцию выборки также иногда
называют операцией ограничения.
п
 роекция
– с помощью оператора проекции создается
"вертикальное" подмножество
заданного отношения, т.е. подмножество,
получаемое путем исключения всех
атрибутов, не указанных в заданном
списке атрибутов, с последующим
исключением дублирующихся кортежей
(подкортежей) из того, что осталось от
исходного отношения;
роекция
– с помощью оператора проекции создается
"вертикальное" подмножество
заданного отношения, т.е. подмножество,
получаемое путем исключения всех
атрибутов, не указанных в заданном
списке атрибутов, с последующим
исключением дублирующихся кортежей
(подкортежей) из того, что осталось от
исходного отношения;соединение(естественное) – возвращает отношение, содержащее все возможные кортежи, которые представляют собой комбинацию атрибутов двух кортежей, принадлежащих двум заданным отношениям, при условии, что в этих двух комбинируемых кортежах присутствуют одинаковые значения в одном или нескольких общих для исходных отношений атрибутах (причем эти общие значения в результирующем кортеже появляются один раз, а не дважды). Пример – S Join P по общему атрибуту City:

д
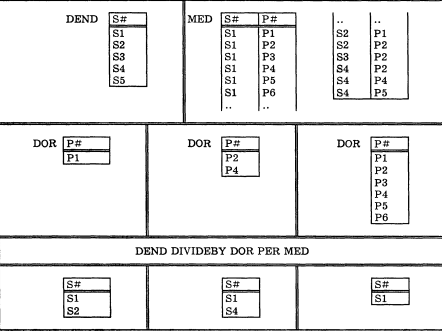 еление
– для заданных двух унарных отношений
и одного бинарного возвращает отношение,
содержащее все кортежи из первого
унарного отношения, которые содержатся
также в бинарном отношении и соответствуют
всем кортежам во втором унарном
отношении.
еление
– для заданных двух унарных отношений
и одного бинарного возвращает отношение,
содержащее все кортежи из первого
унарного отношения, которые содержатся
также в бинарном отношении и соответствуют
всем кортежам во втором унарном
отношении.
Основным достоинством реляционной модели является ее простота.
В целостной части реляционной модели базы данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной системе управления базами данных. Первое требование называется требованием целостности сущностей: любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом.
Второе требование называется требованием целостности по ссылкам (требование внешнего ключа – атрибута, значения которого однозначно характеризуют сущности, представленные кортежами некоторого другого отношения). Отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом. Требование целостности по ссылкам, или требование внешнего ключасостоит в том, что для каждого значения внешнего ключа в базе данных, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать).
При удалении кортежа из отношения, на которое ведет ссылка, существуют три подхода, каждый из которых поддерживает целостность по ссылкам. Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). При втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным. Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи.
Основной компонент реляционной модели– реляционная алгебра, которая, в основном, состоит из набора операторов, использующих отношения в качестве операндов и возвращающих отношения в качестве результата. Реляционная алгебра – алгебраическое изображение, в котором запросы выражаются с помощью специальных операторов отношений.
Иерархические, сетевые, реляционные и объектные базы данных, сравнение их принципов построения и областей применения.
О сновными
информационными единицами в иерархической
модели являются: база данных (БД), сегмент
и поле. Поле данных определяется как
минимальная, неделимая единица данных,
доступная пользователю с помощью СУБД.
Выделяют также тип поля, представляющий
собой совокупность полей одного типа.
Сегмент состоит из конкретных экземпляров
полей. Тип сегмента - совокупность
входящих в него типов полей. Иерархическая
модель представляет собой неориентированный
граф, в вершинах которого располагаются
сегменты (или типы сегмента). Дуги,
соединяющие узлы, представляют собой
связи или типы связей. Особенностью
такой модели является то, что каждый
сегмент может иметь не более одного
предка, произвольное количество потомков
и, по крайней мере, одно поле. Все
экземпляры одного типа потомка с общим
экземпляром типа предка называются
близнецами.Сегмент, который не имеет
потомков, называют листовым сегментом.
Иерархическое дерево начинается с
одного сегмента, называемого корневым.
Каждый сегмент должен иметь свое
уникальное имя или идентификатор.
Иерархическая модель не поддерживает
отношения «многие ко многим», когда
множество объектов одного типа связаны
с множеством объектов другого типа.
Основной единицей обработки в иерархической
модели является сегмент. К сегментам
могут применяться такие операции как
запомнить, модифицировать, удалить,
извлечь, найти. Иерархические СУБД
поддерживают, обычно, правило: никакой
сегмент не может существовать без своего
родителя (исключая корневой сегмент).
Подобные правила, поддерживаемые СУБД,
называют ограничениями целостности.
сновными
информационными единицами в иерархической
модели являются: база данных (БД), сегмент
и поле. Поле данных определяется как
минимальная, неделимая единица данных,
доступная пользователю с помощью СУБД.
Выделяют также тип поля, представляющий
собой совокупность полей одного типа.
Сегмент состоит из конкретных экземпляров
полей. Тип сегмента - совокупность
входящих в него типов полей. Иерархическая
модель представляет собой неориентированный
граф, в вершинах которого располагаются
сегменты (или типы сегмента). Дуги,
соединяющие узлы, представляют собой
связи или типы связей. Особенностью
такой модели является то, что каждый
сегмент может иметь не более одного
предка, произвольное количество потомков
и, по крайней мере, одно поле. Все
экземпляры одного типа потомка с общим
экземпляром типа предка называются
близнецами.Сегмент, который не имеет
потомков, называют листовым сегментом.
Иерархическое дерево начинается с
одного сегмента, называемого корневым.
Каждый сегмент должен иметь свое
уникальное имя или идентификатор.
Иерархическая модель не поддерживает
отношения «многие ко многим», когда
множество объектов одного типа связаны
с множеством объектов другого типа.
Основной единицей обработки в иерархической
модели является сегмент. К сегментам
могут применяться такие операции как
запомнить, модифицировать, удалить,
извлечь, найти. Иерархические СУБД
поддерживают, обычно, правило: никакой
сегмент не может существовать без своего
родителя (исключая корневой сегмент).
Подобные правила, поддерживаемые СУБД,
называют ограничениями целостности.
С етевой
подход к организации данных является
расширением иерархического. В сетевой
структуре данных потомок может иметь
любое число предков (рисунок). Сетевая
модель данных опирается на математическую
теорию направленных графов. Базовыми
элементами сетевой модели являются:
етевой
подход к организации данных является
расширением иерархического. В сетевой
структуре данных потомок может иметь
любое число предков (рисунок). Сетевая
модель данных опирается на математическую
теорию направленных графов. Базовыми
элементами сетевой модели являются:
Элемент данных (атрибут) – минимальная информационная единица, доступная пользователю.
Агрегат данных – именованная совокупность элементов данных внутри записи или другого агрегата. Агрегат бывает двух видов – агрегат типа «вектор» и агрегат типа «повторяющаяся группа». Например, агрегат <город, улица, дом, квартира>, которому можно присвоить имя «Адрес», является агрегатом типа вектор. Примером агрегата типа «повторяющаяся группа» может служить агрегат <месяц, сумма> с названием Зарплата. Данный агрегат характеризуется числом повторений.
Запись – совокупность агрегатов или элементов данных, отражающих некоторую сущность предметной области. Например, записью будет <Фамилия, Зарплата>, где Фамилия – это элемент данных, а Зарплата – агрегат. Данную запись можно назвать «Зарплата сотрудника».
Т
 ип
записей – эта совокупность подобных
записей. Например, в предыдущем примере
типом записи будет совокупность всех
записей «Зарплата сотрудника», выражающая
множество сотрудников некоторого
отдела. Тип записей представляет
(моделирует) некоторый класс реального
мира.
ип
записей – эта совокупность подобных
записей. Например, в предыдущем примере
типом записи будет совокупность всех
записей «Зарплата сотрудника», выражающая
множество сотрудников некоторого
отдела. Тип записей представляет
(моделирует) некоторый класс реального
мира.
Набор – именованная двухуровневая иерархическая структура, которая содержит запись владельца и запись (или записи) членов. Наборы отражают связи «один ко многим» и «один к одному» между двумя типами записей. Среди всех наборов в сетевой модели допускается существование наборов, не имеющих владельцев (сингулярные наборы). Владельцами сингулярных наборов формально считается система. Сингулярные наборы предназначены для доступа к экземплярам отдельных записей.
Среди достоинств систем управления данными, основанных на иерархической или сетевой моделях, могут быть названы их компактность и, как правило, высокое быстродействие, а среди недостатков - неуниверсальность, высокая степень зависимости от конкретных данных.
Р еляционная
база данных представляет собой
множество взаимосвязанных таблиц,
каждая из которых содержит информацию
об объектах определенного вида. Каждая
таблица состоит из фиксированного числа
столбцов и некоторого (переменного)
количества строк.Каждая строка таблицы
содержит данные об одном объекте
(автомобиле, компьютере, клиенте), а
столбцы таблицы содержат характеристики
этих объектов – атрибуты (номер
двигателя, марка процессора, телефоны
клиентов). Строки таблицы называются
записями. Все записи таблицы имеют
одинаковую структуру – они состоят из
полей (элементов данных), в которых
хранятся атрибуты объекта. Каждое поле
записи содержит одну характеристику
объекта и представляет собой заданный
тип данных (например, текстовая строка,
число, дата), имеет имя и дополнительные
характеристики длину, формат, точность).
Для идентификации записей используется
первичный ключ – набор полей таблицы,
комбинация значений которых однозначно
определяет каждую запись в таблице.
Запрос к таким базам данных возвращает
таблицу, которая повторно может
участвовать в следующем запросе.
еляционная
база данных представляет собой
множество взаимосвязанных таблиц,
каждая из которых содержит информацию
об объектах определенного вида. Каждая
таблица состоит из фиксированного числа
столбцов и некоторого (переменного)
количества строк.Каждая строка таблицы
содержит данные об одном объекте
(автомобиле, компьютере, клиенте), а
столбцы таблицы содержат характеристики
этих объектов – атрибуты (номер
двигателя, марка процессора, телефоны
клиентов). Строки таблицы называются
записями. Все записи таблицы имеют
одинаковую структуру – они состоят из
полей (элементов данных), в которых
хранятся атрибуты объекта. Каждое поле
записи содержит одну характеристику
объекта и представляет собой заданный
тип данных (например, текстовая строка,
число, дата), имеет имя и дополнительные
характеристики длину, формат, точность).
Для идентификации записей используется
первичный ключ – набор полей таблицы,
комбинация значений которых однозначно
определяет каждую запись в таблице.
Запрос к таким базам данных возвращает
таблицу, которая повторно может
участвовать в следующем запросе.
Объектная база данных – база данных, в которой данные моделируются в виде объектов, их атрибутов, методов и классов. Объектно-ориентированные базы данных используются, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру.
Обязательные характеристики:
в системе должна быть предусмотрена возможность создания составных объектов за счет применения конструкторов составных объектов.
все объекты должны иметь уникальный идентификатор, который не зависит от значений их атрибутов.
поддержка инкапсуляции – данные и реализация методов скрыты внутри объектов.
поддержка типов и классов.
Поддержка наследования типов и классов от их предков.
Перегрузка в сочетании с полным связыванием. Методы должны применяться к объектам разных типов. Реализация метода должна зависеть от типа объектов, к которым данный метод применяется.
Вычислительная полнота. Язык манипулирования данными должен быть языком программирования общего назначения.
Набор типов данных должен быть расширяемым. Пользователь должен иметь средства создания новых типов данных на основе набора предопределенных системных типов.
Необязательные характеристики:
Множественное наследование
Проверка типов
Распределение
Проектные транзакции
Открытые характеристики:
Парадигмы программирования (процедурное, декларативное)
Система представления
Система типов
Однородность. Реализация — язык программирования — интерфейс.
Модели и технологии инфологического проектирования реляционных БД. Модель сущность-связь. ER-диаграмма. Пять нормальных форм ER-диаграмм.
Целью инфологического проектирования есть создание структурированной информационной модели ПО, для которой будет разрабатываться БД. При проектировании на инфологическом уровне создается информационно-логическая модель (ИЛМ), которая должна отвечать таким требованиям: - обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных; - корректность схемы БД, то есть адекватное отображение моделированной ПО; -простота и удобство использования на следующих этапах проектирования, то есть ИЛМ может легко отображаться на модели БД, которые поддерживаются известными СУБД (сетевые, иерархические, реляционные и др.); - ИЛМ должна быть описана языком, понятным проектировщикам БД, программистам, администратору и будущим пользователям.
Суть инфологического моделирования состоит в выделении сущностей (информационных объектов ПО), которые подлежат хранению в БД, а также в определении характеристик (атрибутов) объектов и взаимосвязей между ними. Существует два подхода к инфологическому проектированию: анализ объектов и синтез атрибутов. Подход, который базируется на анализе объектов, называется нисходящим, а на синтезе атрибутов — восходящим.
Модель "сущность-связь"
Модели «сущность-связь», дающие возможность представлять структуру и ограничения реального мира, а затем трансформировать их в соответствии с возможностями промышленных СУБД, являются весьма распространенными. Под сущностью понимают основное содержание того явления, процесса или объекта, о которых собирают информацию для БД. В качестве сущности могут выступать место, вещь, личность, явление и т.д. Связь - это связь между разными информационными объектами, а также между информационным объектом и его характеристиками возникают определенные ассоциации.
E R-диаграммы
используются для разработки данных и
представляют собой стандартный способ
определения данных и отношений между
ними. Таким образом осуществляется
детализация хранилищ данных. ER-диаграмма
содержит информацию о сущностях системы
и способах их взаимодействия, включает
идентификацию объектов, важных для
предметной области (сущностей), свойств
этих объектов (атрибутов) и их отношений
с другими объектами (связей). Во многих
случаях информационная модель очень
сложна и содержит множество объектов.
Пример ER-диаграммы
можно видеть на рисунке. Прямоугольником
описываются сущности («Товар», «Склад»
и т.д.), внутри сущностей изображаются
атрибуты (для сущности «Товар» атрибутами
являются «Наименование товара», «Текущая
цена» и т.д.). При этом подчеркнутый
атрибут является ключевым (ключом
сущности), значения
которого в совокупности являются
уникальными для каждого экземпляра
сущности (сущность может иметь несколько
различных ключей). Связь сущностей может
иметь одну из двух модальностей связи:
R-диаграммы
используются для разработки данных и
представляют собой стандартный способ
определения данных и отношений между
ними. Таким образом осуществляется
детализация хранилищ данных. ER-диаграмма
содержит информацию о сущностях системы
и способах их взаимодействия, включает
идентификацию объектов, важных для
предметной области (сущностей), свойств
этих объектов (атрибутов) и их отношений
с другими объектами (связей). Во многих
случаях информационная модель очень
сложна и содержит множество объектов.
Пример ER-диаграммы
можно видеть на рисунке. Прямоугольником
описываются сущности («Товар», «Склад»
и т.д.), внутри сущностей изображаются
атрибуты (для сущности «Товар» атрибутами
являются «Наименование товара», «Текущая
цена» и т.д.). При этом подчеркнутый
атрибут является ключевым (ключом
сущности), значения
которого в совокупности являются
уникальными для каждого экземпляра
сущности (сущность может иметь несколько
различных ключей). Связь сущностей может
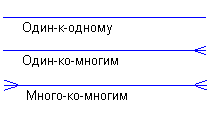
иметь одну из двух модальностей связи:
-
может
- - - - - - - - - - -
должен
––––––––––––
и один из следующих типов связи:
Пять нормальных форм ER-диаграмм
1НФ. В ER-диаграмме устраняются повторяющиеся атрибуты или группы атрибутов, т. е. производится выявление неявных сущностей, «замаскированных» под атрибуты.
2НФ. Устраняются атрибуты, зависящие только от части уникального идентификатора. Эта часть уникального идентификатора определяет отдельную сущность.
3НФ. Устраняются атрибуты, зависящие от атрибутов, не входящих в уникальный идентификатор. Эти атрибуты являются основой отдельной сущности.
4НФ. Применяется при наличии более чем одной многозначной функциональной зависимости - отношение находится в нормальной форме Бойса-Кодда или 3НФ и не содержит независимых многозначных функциональных зависимостей;
5НФ. Отношение находится в 4НФ и не содержит функциональных зависимостей по соединению.
Объектные базы данных. Принципы построения, модель данных, области применения. Преимущества и недостатки.
Общепринятого определения "объектно-ориентированной модели данных" не существует. Сейчас можно говорить лишь о неком "объектном" подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации. Любая модель данных должна включать три аспекта: структурный, целостный и манипуляционный.
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция - каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов - процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира.
наследование - подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков).
полиморфизм - различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования
возможность объявить некоторые поля данных и методы объекта как "скрытые", не видимые для других объектов; такие поля и методы используются только методами самого объекта
создание процедур контроля целостности внутри объекта
Средства манипулирования данными:
В объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель:
- естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели "сущность-связь" в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции.
- имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
- отсутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста.
- вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами - расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
9.Иерархические базы данных. Принципы построения, модель данных, области применения. Преимущества и недостатки.
Иерархическая модель данных организует данные в виде древовидной структуры и является реализацией логических связей между данными типа родовидовых отношений или отношений "часть-целое".
Иерархическая БД состоит из упорядоченного набора нескольких экземпляров одного типа дерева. Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя
Элементы описания данных в этой модели такие же, как и в сетевой: простое поле, группа, запись, групповое отношение и БД. Существенное ее отличие от сетевой модели данных касается средств организации связей, а именно, допускаются связи между объектами модели в виде древовидной структуры.
Особенностью такого представления данных является наличие нескольких подчиненных уровней. В иерархической модели имеется корневой узел или корень дерева. Он располагается на 1-м, самом высоком уровне и не имеет узлов-предшественников. Остальные узлы называются порожденными и связаны между собой следующим образом: каждый узел имеет исходный, находящийся на вышестоящем уровне. На следующем уровне каждый узел может иметь более одного узла-потомка или не иметь потомков вовсе. Узлы, не имеющие порожденных, называются листьями. В иерархии рассматривают уровни, на которых расположен тот или иной узел или совокупность узлов.
Между исходным узлом и порожденными узлами по условию модели существует связь "один-ко-многим" (или "многие-к-одному").
Иерархические базы данных по существу являются навигационными, т.е. доступ возможен только с помощью заранее определенных связей.
Иерархия должна удовлетворять следующим условиям:
Иерархия имеет исходный узел (корень), из которого строится дерево. Каждое дерево имеет только один корень.
Узел имеет непустое множество атрибутов, которые описывают объект, моделируемый в данном узле.
Порожденные узлы могут добавляться в дерево как в вертикальном, так и в горизонтальном направлении.
Доступ к порожденным узлам возможен только через исходный узел, поэтому существует только один путь доступа к каждому узлу.
Возможно существование нескольких экземпляров каждого узла каждого уровня. При этом каждый экземпляр исходного узла начинает логическую запись.
К основным недостаткам иерархической модели можно отнести:
сложность отображения связи "многие-к-многим"
усложнение операции включения новых объектов и удаления устаревших объектов непосредственно в базе данных (в особенности обновление и удаление связей);
неоднозначность представления данных о предметной области.
Громоздкость для обработки информации с достаточно сложными логическими связями.
Сложность понимания для обычного пользователя
Информационный поиск из нижних уровней иерархии нельзя направить по вышележащим узлам
отсутствие прямого доступа к данным делают ее непригодной в условиях частого выполнения запросов, не запланированных заранее
Достоинство иерархической базы данных
обеспечивает очень быстрый доступ при следовании вдоль заранее определенных связей.
Эффективное использование памяти ЭВМ
Неплохие показатели времени выполнения операций над данными