

Розділ IV Обробка результатів анкетування
Після проведеного анкетування доцільно здійснити обробку результатів опитування.
Водночас з’ясовується узгодженість дій респондентів та встановлюється вірогідність їх оцінок. Найчастіше з цією метою використовують коефіцієнт варіації (СV), який показує ступінь узгодженості дій респондентів та вірогідність їх оцінок.
![]() =
= ![]() * 100% =
* 100% = ![]() *100% =
*100% = 
де, ![]() і
і ![]() –
середньоквадратичне відхилення та
дисперсія оцінок респондентів з j
питання.
–
середньоквадратичне відхилення та
дисперсія оцінок респондентів з j
питання.
![]() і
і
![]() – оцінка
i-го
респондента та середня оцінка всіх
респондентів з j-го
питання.
– оцінка
i-го
респондента та середня оцінка всіх
респондентів з j-го
питання.
і – респондент;
j – номер запитання;
n – кількість респондентів.
Значення коефіцієнта варіації повинно бути якомога меншим.
CV≤ 33, 33%.
Результати оцінювання 15 респондентів наведено в таблиці 3.
Розраховуємо середнє значення оцінок респондентів на кожне з питань:
а7=39/15=2,6;
а9=75/5=5;
а11=51/15=3,4;
а12=55/15=3,67;
а13=56/15=3,73;
а14=57/15=3,8;
а15=62/15=4,13;
а16=66/15=4,4;
а18=51/15=3,4;
а19=60/15=4;
а20=60/15=4;
а21=72/15=4,8;
а25=65/15=4,33;
а26=58/15=3,87;
а27=53/15=3,53;
а28=49/15=3,27;
а29=66/15=4,4;
а30=39/15=2,6;
Розраховуємо середньозважене відхилення оцінок респондентів на кожне із запитань.
![]() =
= ![]()
σ7=0,549;
σ 10=0;
σ 11=1,122;
σ 12=1,026;
σ 13=1,341;
σ 14= 1,105;
σ 15= 0,922 ;
σ 16= 0,803 ;
σ 17= 1,035 ;
σ 18= 0,966 ;
σ 19= 0,577 ;
σ 20= 0,549 ;
σ 21= 0,75;
σ 25= 1,036;
σ 26= 0,81;
σ 27= 1,567;
σ 28= 1,605;
σ 29= 0,778;
σ 30= 1,675;
Розраховуємо коефіцієнт варіації оцінок респондентів на кожне із запитань.
![]() =
=
CV7=0.549/2.6*100%=24.22%;
CV10=0/5*100%=0%;
CV11=1.122/3.4*100%=33%;
CV12=1.026/3.67*100%=27.98%;
CV13=1.341/3.73*100%=35.92%;
CV14=1.105/3.8*100%=29.08%;
CV15=0.922/4.13*100%=22.31%;
CV16=0.803/4.4*100%=13.11%;
CV17=1.035/3.4*100%=30.44%;
CV18=0.966/4*100%=24.15%;
CV19=0.577/4*100%=14.43%;
CV20=0.549/4.8*100%=11.44%;
CV21=0.75/4.33*100%=17.31%;
CV25=1.036/4.33*100%=23.91%;
CV26=0.81/3.87*100%=20.95%;
CV27=1.567/3.53*100%=44.35%;
CV28=1.605/3.27*100%=49.1%;
CV29=0.778/4.4*100%=17.7%;
CV30=1.675/2.6*100%=64.4%.
Розділ V Побудова семантичного диференціалу для оцінюваного, конкурентного та ідеального товарів
Семантичний диференціал - метод побудови індивідуальних або групових семантичних просторів. Координатами об'єкту в семантичному просторі служать його оцінки по ряду біполярних градуйованих (трьох -, п’яти, семибальних) оцінних шкал, протилежні полюси яких задані за допомогою вербальних антонімів. Ці шкали відібрані з безлічі пробних шкал методами факторного аналізу.
Метод семантичного диференціала дозволяє ставити і вирішувати такі типові питання:
відмінність в оцінці одного поняття різними випробуваними (або різними групами випробовуваних в середньому по групі);
відмінність в оцінці двох (або більше) понять одним і тим же випробуваним (або групою);
відмінність в оцінці одного і того ж поняття одним і тим же випробуваним (або групою) в різний час (тобто вимірювати зміни значень, які виникають під впливом засобів масової комунікації, через зміни соціальних чи культурних контекстів, в результаті навчання).
Побудова семантичних просторів і аналіз становища об'єктів в семантичних просторах - важливий інструмент в багатьох практичних додатках:
Для аналізу сприйняття реклами і для її проектування ;
Для порівняльного аналізу різних груп - від груп споживачів в маркетингу до гендерних стереотипів;
Для дослідження економічної поведінки;
Для вивчення найважливіших процесів соціальної самоідентифікації;
Для вирішення багатьох інших завдань соціології;
В політичних технологіях;
В розстановці персоналу.
Таблиця 5.1
Побудова семантичного диференціалу для чаю ТМ «GREENFELD»
№ п/п |
Номер анкетного запитання |
Вагомість параметра ( |
Середня оцінка анкетного запитання |
|||||||||
0 1 |
2 |
3 |
4 |
5 |
||||||||
1 |
11 |
0.14 |
|
|
|
|
|
|
|
|
|
|
2 |
12 |
0,1 |
|
|
|
|
|
|
|
|
|
|
3 |
13 |
0,1 |
|
|
|
|
|
|
|
|
|
|
4 |
15 |
0,08 |
|
|
|
|
|
|
|
|
|
|
5 |
18 |
0,08 |
|
|
|
|
|
|
|
|
|
|
6 |
19 |
0,15 |
|
|
|
|
|
|
|
|
|
|
7 |
20 |
0,13 |
|
|
|
|
|
|
|
|
|
|
8 |
21 |
0,06 |
|
|
|
|
|
|
|
|
|
|
9 |
28 |
0,07 |
|
|
|
|
|
|
|
|
|
|
10 |
29 |
0,09 |
|
|
|
|
|
|
|
|
|
|
Загальна середньозважена оцінка |
1 |
|
|
|
|
|
||||||
















Визначення загальної середньозваженої оцінки здійснюємо за формулою:
![]() =
= ![]()
![]()
![]()
– середня оцінка анкетного запитання;
![]() – вагомість параметра;
– вагомість параметра;
n – кількість запитань;
Х=0,14*3,4+0,1*3,67+0,1*3,73+0,08*4,13+0,08*4+0,15*4+0,13*4,8+0,06* 4,33+0,07*3,27+0,09*4,4=3,906
Таблиця 5.2
Побудова семантичного диференціалу конкурентного товару ТМ «LIPTON» та ідеального товару
№ п/п |
Номер анкетного запитання |
Вагомість Параметра ( ) |
Середня оцінка анкетного запитання |
|||||||||
0 1 |
2 |
3 |
4 |
5 |
||||||||
1 |
11 |
0.14 |
|
|
|
|
|
|
|
|
|
|
2 |
12 |
0,1 |
|
|
|
|
|
|
|
|
|
|
3 |
13 |
0,1 |
|
|
|
|
|
|
|
|
|
|
4 |
15 |
0,08 |
|
|
|
|
|
|
|
|
|
|
5 |
18 |
0,08 |
|
|
|
|
|
|
|
|
|
|
6 |
19 |
0,15 |
|
|
|
|
|
|
|
|
|
|
7 |
20 |
0,13 |
|
|
|
|
|
|
|
|
|
|
8 |
21 |
0,06 |
|
|
|
|
|
|
|
|
|
|
9 |
28 |
0,07 |
|
|
|
|
|
|
|
|
|
|
10 |
29 |
0,09 |
|
|
|
|
|
|
|
|
|
|
Загальна середньозважена оцінка |
1 |
|
|
|
|
|
||||||


















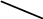

 Чай
ТМ «LIPTON»;
Чай
ТМ «LIPTON»;
 Ідеальний
чай.
Ідеальний
чай.
Хконк=0,14*3+0,1*3,5+0,1*3,6+0,08*4,5+0,08*4,1+0,15*3,8+4,3*4+0,06* 4+0,07*3+0,09*4=3,843;
Хідеал=0,15*3,5+0,1*3,6+0,1*3,8+0,1*4,2+0,1*4,3+0,15*4,4+0,1*4,6+0,1*4,1+0,05*3+0,05*4,5=4,029.