

3.3.5 Получение информации об имеющихся gpu и их возможностях
Перед тем как начать распараллеливание программы необходимо иметь информацию об имеющихся GPU, которые могут быть использованы CUDA, и обо всех возможностях графического процессора. Учет этих данных позволит решить задачу наиболее оптимально и эффективно. В связи с этим расскажем о простом способе получения таких данных, предоставляемый CUDA runtime Информация о возможностях GPU возвращается в виде структуры cudaDeviceProp.
struct cudaDeviceProp
{ char name[256]; - название устройства.
size_t totalGlobalMem; - полный объем глобальной памяти в байтах.
size_t sharedMemPerBlock; - объем разделяемой памяти в блоке в байтах.
int regsPerBlock; - количество 32-битовых регистров в блоке.
int warpSize; - размер варпа.
size_t memPitch; - максимальный pinch в байтах, допустимый функциями копирования памяти, выделенной через cudaMallocPitch
int maxThreadsPerBlock; - максимальное число активных нитей в блоке.
int maxThreadsDim [3]; - максимальный размер блока по каждому измерению.
int maxGridSize [3]; - максимальный размер сетки по каждому измерению.
size_t totalConstMem;- объем константной памяти в байтах.
int major; - Computer Capability, старший номер.
int minor; - Computer Capability, младший номер.
int clockRate; - частота в килогерцах.
size_t textureAlignment; - выравнивание памяти для текстур.
int deviceOverlap; - можно ли осуществлять копирование параллельно с вычислениями.
int multiProcessorCount; - количество мультипроцессоров в GPU. }
Для обозначение возможностей CUDA использует понятие Compute Capability, выражаемое парой чисел - major.minor. Первое число обозначает глобальную архитектурную версию, второе - небольшие изменение. Так как в дальнейшем будем писать программу для видеокарты GeForce 9600 GT, то остановимся на ее возможности. Она имеет Compute Capability равную 1.1, которая поддерживает атомарные операции над 32-битовыми словами в глобальной памяти.
3.3.6 Компиляция
В завершении следует уделить внимание компиляции программы CUDA, которая осуществляется в два этапа. Сначала извлекается код, относящийся к CPU, который передаётся стандартному компилятору NVCC. Код, предназначенный для GPU, сначала преобразовывается в промежуточный язык PTX. Он подобен ассемблеру и позволяет изучать код в поисках потенциальных неэффективных участков. Наконец, последняя фаза заключается в трансляции промежуточного языка в специфические команды GPU и создании двоичного файла.
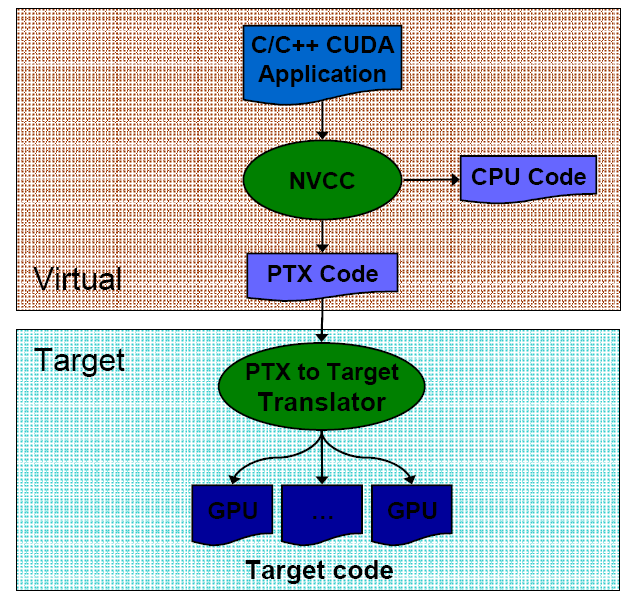
Рис. 18 Компиляция программы CUDA
Заключение
В данной работе рассмотрены вопросы организации параллельных вычислений для решения эллиптических уравнений. Описаны последовательные методы решения дифференциальных уравнений данного вида на примере задачи Дирихле для уравнения Пуассона. Последовательно разбираются возможные способы распараллеливания сеточных методов на многопроцессорных вычислительных системах с общей памятью. При этом большое внимание уделяется проблемам, возникающим при организации параллельных вычислений, анализу причин появления таких проблем и нахождению путей их преодоления.
Описываются особенности организации параллельных вычислений на видеокартах с использованием технологии CUDA. Для лучшего понимания механизма параллелизации рассматриваются архитектура графического процессора, потоковая модель и модель памяти CUDA. Также подробно разбирается расширения языка С, которые необходимы при написания кода для GPU. Применение технологии CUDA для распараллеливания сеточных методов на видеокарте будет реализовано в дальнейшем.
Список используемых источников