

4.2.3 Метод idef1x.
Метод IDEF1x очень похож на метод Баркера. В его основе лежат те же идеи и принципы. Отличия, конечно, имеются, но в большинстве случаев, модели, построенные с помощью метода Баркера, можно преобразовать в модели IDEF1x и обратно. Рассмотрение этого метода оправдано тем, что он (или его вариации) чаще используются в различных программных средствах для проектирования баз данных.
Сущность. Атрибуты сущности.
Сущность в методе IDEF1x определяется так же, как в методе Баркера. Изображение сущности также весьма похоже, основное отличие состоит в том, что атрибуты, входящие в первичный ключ, отделяются от остальных и помещаются в верхнюю часть прямоугольника. В качестве примера создадим ту же сущность «Студент», она приведена на рис. 4.9.

Рис. 4.9 Пример сущности в методе IDEF1x.
Видно, что принципиальных отличий от метода Баркера нет. Можно отметить, что обязательные и необязательные атрибуты визуально не выделяются. Представляется, что более подробные пояснения не нужны.
Связи. Идентифицирующие и неидентифицирующие связи.
Связи в методе IDEF1x несколько отличаются по своим характеристикам от связей метода Баркера. Они точно так же обладают степенью, и можно выделить связи со степенью «многие ко многим», «один ко многим», правда, для связей «один к одному» специального обозначения нет. Но также связь может быть идентифицирующей и неидентифицирующей.
Если между двумя сущностями имеется идентифицирующая связь, то первичный ключ главной сущности включается в состав первичного ключа подчиненной сущности. Кроме того, подчиненная сущность явно выделяется. В случае, если связь неидентифицирующая, то первичный ключ из главной сущности включается в число атрибутов подчиненной сущности, а сама она никак не изменяется. Рассмотрим это на примере. На рисунке 4.10 показана идентифицирующая связь между студентом и группой, а на рисунке 4.11 - неидентифицирующая.

Рис. 4.10 Идентифицирующая связь.

Рис. 4.11 Неидентифицирующая связь.
На рисунках хорошо видна разница между идентифицирующей и неидентифицирующей связью. В первом случае первичный ключ стал состоять из двух атрибутов, а для обозначения сущности используется прямоугольник со скругленными углами, во втором случае первичный ключ сущности «Группа» просто включен в число атрибутов сущности «Студент», при этом сама сущность «Студент» не изменилась.
Смысл такого деления вытекает из самого его названия. Бывают ситуации, когда сущность не имеет самостоятельного смысла, и может существовать только в связи с главной сущностью. Как следствие, для однозначной идентификации ее экземпляров ее атрибутов недостаточно. И в этом случае первичный ключ главной сущности как раз и выступает дополнительным идентифицирующим признаком и включается в первичный ключ подчиненной сущности. Примером может служить сущность «Банковский счет». Счета в банке обладают номером, однако, номера уникальны только внутри банка. Поэтому, мы можем использовать номер счета в качестве первичного ключа, если дополним его кодом банка, в котором этот счет открыт. Здесь нам нужна именно идентифицирующая связь.
Если вернуться к примерам, то очевидно, что для связи студента и группы нам подойдет неидентифицирующая связь. Студент может менять группу, может какое-то время вообще не входить в состав какой-либо группы (например, после зачисления, но до формирования учебных групп, или находясь в академическом отпуске и так далее). При этом он остается тем же самым студентом, указывать группу, чтобы понять, о ком идет речь, не нужно.
Класс принадлежности также реализован несколько иначе. Есть возможность указать, допускаются ли пустые значения внешнего ключа, то есть, если обратиться к нашему примеру, обязательно ли студенту входить в группу. Для идентифицирующих связей, как легко понять, пустые значения в подчиненной сущности не допускаются, для неидентифицирующих можно выбирать. В случае, если участие в связи не обязательно, связь помечается ромбом. Именно такая ситуация и изображена в нашем примере неидентифицирующей связи на рисунке 4.11.
Связи «многие ко многим» также допускаются только на начальных этапах и должны преобразовываться аналогично тому, как предполагает метод Баркера. В некоторых средах проектирования (например, в ERwin Data Modeler) это выполняется автоматически при переходе от моделирования предметной области к проектированию БД.
Объединение связей в группы и задание неперемещаемых связей в методе IDEF1x не предусмотрено. Тем не менее, в целом можно сказать, что возможности по заданию связей в методе Баркера и методе IDEF1x примерно совпадают.
Производные сущности.
Метод IDEF1x также позволяет выстраивать иерархию сущностей, но здесь она также реализована несколько иначе. Воспроизведем пример, использованный при рассмотрении этой возможности в методе Баркера и обсудим сходства и различия.
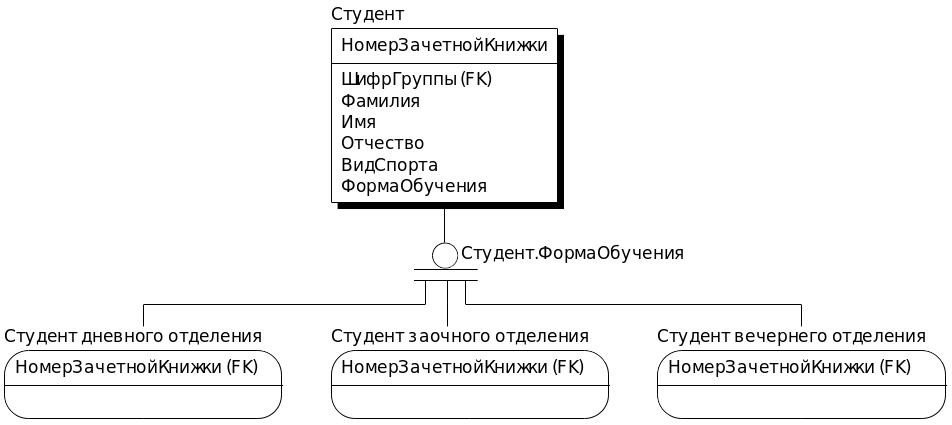
Рис. 4.12 Обобщенная и производные сущности.
Во-первых, видно, что в методе IDEF1x обобщение – это разновидность связи, то есть, мы могли бы ввести несколько различных классификаций студентов. Отличать их можно при помощи так называемого дискриминатора – атрибута, значения которого и позволяют относить экземпляр сущности к тому или иному производному виду. Дискриминатор указывается рядом с символом обобщения, в нашем случае в качестве дискриминатора выступает атрибут «ФормаОбучения». Еще одним существенным отличием от метода Баркера является возможность задавать неполные классификации. В нашем примере мы полностью указали все возможные варианты обучения, и классификация у нас полная. Это видно из того, что в символе классификации под кружком две линии. Если бы имелись еще какие-то разновидности студентов, которые мы не привели в модели (то есть, они считались бы просто студентами), то в символе классификации под кружком была бы одна линия. Как мы помним, в методе Баркера таких вариаций нет, и мы обязаны указывать все возможные типы производных сущностей (пусть даже и добавляя сущность «Прочие»).
В общих чертах, мы рассмотрели возможности, представляемые методом IDEF1x, и их отличия от возможностей метода Баркера. Можно сказать, что эти два метода в целом очень похожи, как и было отмечено выше. Теперь можно перейти к рассмотрению вопросов получения схемы БД из построенных моделей.