

27. Особенности архитектуры микропроцессоров 6-го поколения семейства х86 фирмы Intel (Pentium Рrо, Pentium II)
Pentium Pro полностью поддерживает систему команд х86. Архитектурные особенности процессора делают эффективным его применение для 32-разрядных приложений, тогда как для 16-разрядных программ скорость выполнения может оказаться существенно меньшей, чем для Pentium с той же тактовой частотой.
В данном микропроцессоре применена новая конструкция корпуса, процессор состоит из двух микросхем, помещенных в один керамический корпус, и не согласуется по выводам с процессорами Pentium. Для его использования необходим переход на новые системные платы.
Достижение высокой производительности обеспечивается за счет использования следующих архитектурных и технологических новшеств:
- динамического выполнения команд; двойной независимой шины; интегрированного вторичного кэша; расширения системы команд.
Динамическое выполнение - комбинация методов предсказания переходов, анализа прохождения данных и виртуального выполнения. При этом команды, не зависящие от результатов предыдущих операций, могут выполняться в измененном порядке (спекулятивное выполнение), но последовательность выгрузки результатов в память и порты будет соответствовать исходному программному коду.
Команда готова к выполнению, как только готовы ее входные операнды. Однако есть ряд ограничений, связанных с доступностью физических ресурсов, таких как исполнительные устройства, коммутаторы и порты регистровых файлов. Для организации исполнения используются различные методы:
одной очереди; многих очередей; метод резервирующей станции.
Если имеется одна очередь, то переименования регистров не требуется, так как доступность значений операндов может отмечаться битом резервирования, сопоставленным каждому регистру (при выполнении программ используется механизм динамического отображения определяемых текстом программы логических ресурсов (ячеек памяти, регистров) на физические ресурсы микропроцессора. С одним логическим ресурсом может быть связано несколько значений в различных физических ресурсах, каждое из которых соответствует значению логической величины в один из моментов времени последовательного выполнения программы. Когда команда создает новое значение для логического ресурса, физический ресурс, в который помещается это значение, получает имя. Последующие команды, использующие это значение, снабжаются именем физического ресурса. Данная процедура называется переименованием регистров). Регистр резервируется, когда модифицирующая его команда назначается на исполнение. И регистр освобождается, когда заканчивается исполнение команды. Если для команды ресурсы не были зарезервированы, то она приостанавливает свое исполнение.
В методе многих очередей каждая очередь организуется для команд одного типа, например, команд с плавающей точкой или работы с памятью.
Третий метод предполагает использование резервирующей станции, состоящей из совокупности элементов, каждый из которых содержит позиции для размещения кода операции, имени первого операнда, самого первого операнда, имени второго операнда, самого второго операнда, признака доступности второго операнда и имени регистра результата. Когда команда завершает исполнение и вырабатывает результат, то имя результата сравнивается с именами операндов резервирующей станции.
Если в резервирующей станции обнаруживается команда, ждущая этого результата, то данные записываются в соответствующую позицию и устанавливается признак их доступности. Когда у команды доступны все операнды, инициируется ее исполнение. Резервирующая станция следит за доступностью операндов. Когда команда при диспетчеризации попадает в резервирующую станцию, все готовые операнды из регистрового файла переписываются в поля этой команды. Когда все операнды готовы, команда исполняется. Иногда резервирующая станция содержит не сами операнды, а указатели на них в регистровом файле или переупорядочивающем буфере.
Двойная независимая шина. Динамическое выполнение резко повышает частоту запросов процессорного ядра к шине за данными и инструкциями, поскольку ядро одновременно обрабатывает несколько инструкций. Для обхода «узкого места» - внешней шины - процессорное ядро использует архитектуру двойной независимой шины DIB (Dual Independent Bus). Одна из этих шин используется только для связи с кристаллом вторичного кэша, расположенным в том же корпусе микросхемы. Проводники этой локальной шины имеют длину порядка единиц сантиметров, что позволяет ее использовать на частоте ядра процессора. Значительный объем вторичного кэша позволяет удовлетворить большинство запросов к памяти сугубо локально, при этом коэффициент загрузки шины достигает 90 %. Вторая шина выходит на внешние выводы микросхемы и является системной шиной процессора. Эта шина работает на внешней частоте независимо от внутренней шины. По статистике загрузка процессором внешней шины для обычных применений составляет примерно 10% от ее пропускной способности, а для серверных применений может достигать 60 % при четырехпроцессорной конфигурации. Таким образом, ограниченная пропускная способность внешней шины перестает служить фактором, обесценивающим производительность процессора. Кроме этого, шина позволяет без дополнительных схем объединять до четырех процессоров.
Интегрированный вторичный кэш имеет объем 256 Кб. Всего микропроцессор содержит раздельные кэш-памяти первого уровня для данных и команд, каждая объемом 8 Кб, и объединенный кэш второго уровня. Кэш-память первого уровня двухпортовая, поддерживает одну операцию загрузки и одну операцию записи за такт. Интерфейс кэш-памяти второго уровня работает с тактовой частотой центрального процессора и может передавать 64 бита за такт.
Расширение системы команд. В систему команд введены инструкции условной пересылки данных, позволяющие сократить количество условных переходов. При этом повышается предсказуемость программного кода и, следовательно, эффективность использования конвейера.
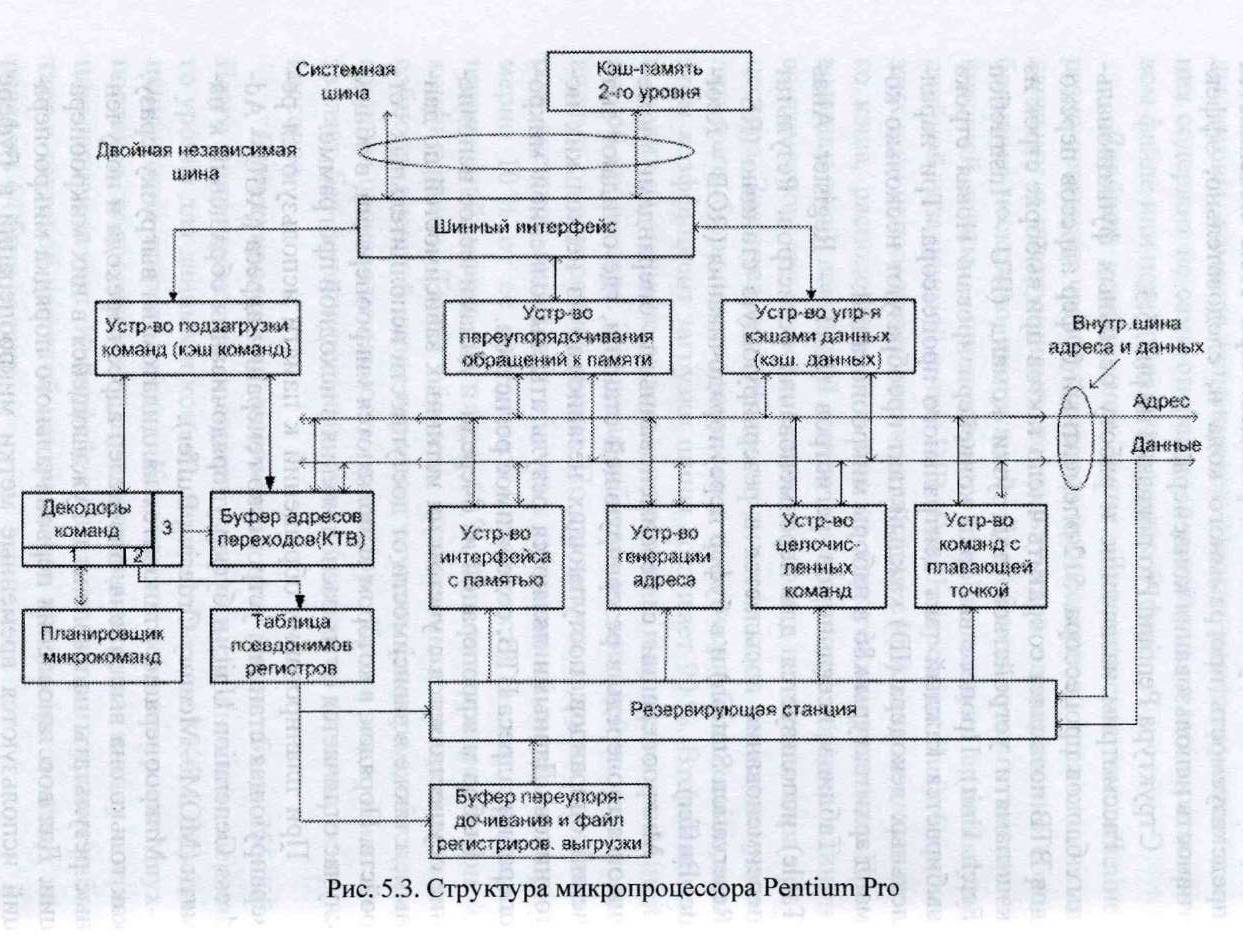
Рассмотрим назначение и работу основных функциональных блоков процессора. 512-элементный буфер адресов переходов ВТВ позволяет сократить число тактов при выборке строк из кэш-памяти устройством подгрузки команд (IFU - Instruction Fetch Unit). Процесс выборки конвейеризирован. Новая строка выбирается каждый такт центрального процессора. Три параллельных декодера (ID) каждый такт преобразуют несколько команд архитектуры х86 в наборы микроопераций.
Таблица псевдонимов регистров (RAT - Register Alias Table) используется для переименования регистров. Результат переименования посылается в резервирующую станцию (RS - Reservation Station) и в буфер переупорядочивания (ROB - Reorder Buffer).
Микрооперации с переименованными операндами помещаются в очередь в резервирующей станции, где ожидают значений операндов, поступающих независимо из нескольких источников. Данными являются результаты выполненной микрооперации, адреса ВТВ, содержимое регистров.
Выбор микроопераций из очереди и динамическое исполнение осуществляется с учетом их истинных зависимостей по данным, а также в зависимости от доступности исполнительных устройств. Порядок, в котором выполняются микрооперации, в общем случае отличается от их расположения в исходной программе.
При планировании обращений к памяти используются резервирующая станция, устройство генерации адреса (AGU - Address Generation Unit) и буфер упорядочивания обращений к памяти (MOM - Memory Ordering Buffer).
Микрооперация становится кандидатом на выгрузку сразу, как только она выполнена, определен адрес перехода и полученные результаты направлены к нуждающейся в них микрооперации. Для восстановления первоначального порядка микроопераций используются временные метки микроопераций в буфере переупорядочивания и файле регистров выгрузки (RRF - Retirement Register File).
Процесс выгрузки должен обеспечить не только восстановление первоначального порядка микроопераций, но и гарантировать правильную обработку прерываний и ошибок, а также отменять все или часть результатов, полученных после неправильного предсказания ветвления. В момент выгрузки микрооперации ее результат из буфера переупорядочивания помещается в файл регистров выгрузки.
Процессоры Pentium II сочетают архитектуру Pentium Pro с технологией ММХ. По сравнению с Pentium Pro удвоен размер первичного кэша (16 + 16 Кб), размер вторичного кэша варьируется в диапазоне от 0 до 2 Мб. В процессоре используется новая технология корпусов - картридж с печатным краевым разъемом, на который выведена системная шина, на картридже размером 14x6,2x1,6 см установлена микросхема ядра процессора, несколько микросхем, реализующих вторичный кэш, и вспомогательные дискретные элементы (резисторы, конденсаторы). Снятие вторичного кэша с микросхемы процессора позволяет использовать для кэш-памяти и памяти тегов микросхемы сторонних производителей, специализирующихся на выпуске сверхбыстродействующей памяти. Объем вторичного кэша определяется емкостью и числом установленных микросхем памяти. В то же время сохраняется независимость шины вторичной кэш-памяти, которая тесно связана с ядром процессора собственной локальной шиной.
Первые процессоры Pentium II (весна 1997 г., технология 0,35 мкм) имели тактовые частоты ядра 233, 266 и 300 МГц при частоте системной шины 66,6 МГц. Следующее поколение Pentium II (1998 г., технология 0,25 мкм) имело более высокие тактовые частоты (333, 350, 400, 450 МГц). Причем для процессоров с частотой 350 и 400 МГц частота системной шины была увеличена до 100 МГц. Это стало возможным потому, что с уменьшением размеров элементов уменьшается рассеиваемая мощность.
По производительности Pentium II превосходил Pentium ММХ, однако уступал Pentium Pro.
Основным недостатком первых Pentium II было то, что они не содержали средств интеграции в мультипроцессорную систему.