

3. Оценка качества эконометрической модели
Существует несколько показателей, характеризующих качество модели регрессии, т.е. степень соответствия построенной модели исходным данным.
Парный линейный коэффициент корреляции оценивает качество линейной модели парной регрессии:
![]()
где Sx - среднеквадратическое отклонение факторной переменной; Sy - среднеквадратическое отклонение результативной переменной.
Можно выделить несколько особенностей парного корреляционного коэффициента:
1) коэффициент изменяется в пределах [-1;+1]. Если ryx [0;+1], то связь между переменными прямая. Если ryx [-1;0], то связь между переменными обратная. Если ryx = 0, то связь между переменными отсутствует;.
2) регрессионный анализ между изучаемыми переменными не проводится, если ryx = 1 или ryx = -1.
Коэффициент детерминации ryx2 рассчитывается как квадрат парного линейного коэффициента корреляции ryx. Коэффициент детерминации характеризует в процентном отношении зависимость вариации результативной переменной от вариации факторной переменной в общем объёме вариации.
3. Для оценки качества линейной множественной модели регрессии используется множественный коэффициент корреляции между результативной переменной у и несколькими факторными переменными х, характеризующий степень тесноты связи между ними:
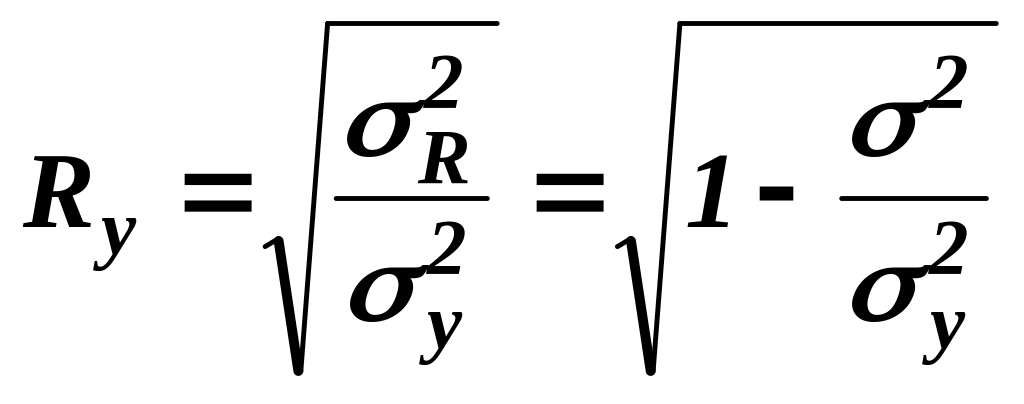
где σ2y - общая дисперсия результативной переменной;
σ2R - объяснённая дисперсия результативной переменной;
σ 2 - необъяснённая дисперсия результативной переменной.
4. Теоретический коэффициент детерминации R2у рассчитывается как квадрат множественного линейного коэффициента корреляции Rу.
5. Среднеквадратическая ошибка модели регрессии:
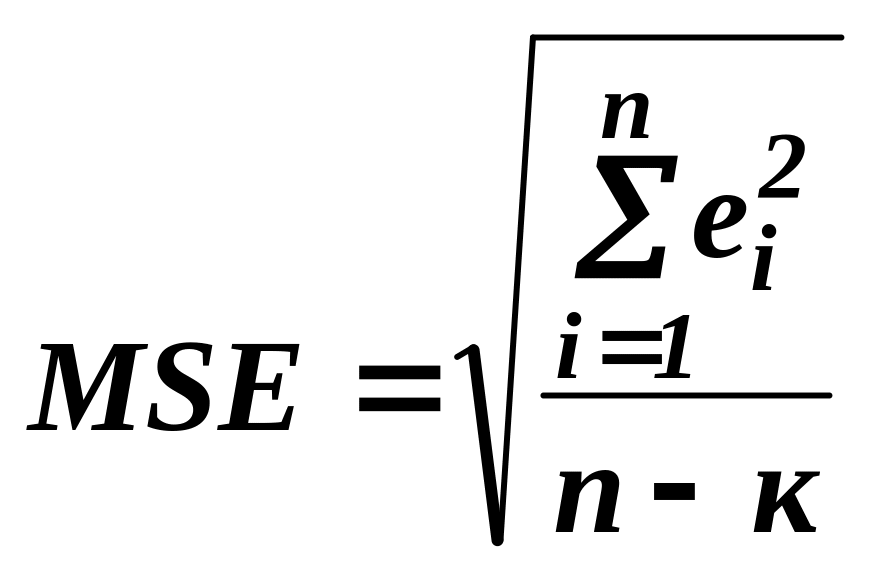
где к - число коэффициентов модели регрессии. Модель регрессии считается качественной, если среднеквадратическая ошибка меньше показателя среднеквадратического отклонения наблюдаемых значений результативной переменной от модельных значений (рассчитанных по модели регрессии).
Проверка гипотезы о значимости коэффициентов модели парной регрессии является весьма важным этапом перед практическим использованием построенной модели регрессии. Значимость коэффициентов означает их значимое отличие от нуля.
Выдвинутые гипотезы проверяются с помощью t-статистики или t-критерия Стьюдента. При этом наблюдаемое значение t-критерия tнабл сравнивают со значением t-критерия, определяемым по таблице распределения Стьюдента, или с критическим значением tкрит.
Критическое значение t-критерия tкрит(α; n-k) зависит от уровня значимости и числа степеней свободы.
Уровень значимости α определяется как α = 1 – γ, где величина γ называется доверительной вероятностью попадания оцениваемого параметра в доверительный интервал. Доверительную вероятность необходимо брать близкую к единице (0,95, 0,99).
Число степеней свободы определяется как разность между объёмом выборки (n) и числом оцениваемых параметров по данной выборке (k). Для модели парной линейной регрессии число степеней свободы равно (n - 2), так как по выборке оцениваются только два параметра b0 и b1.
Наблюдаемое значение t-критерия Стьюдента для проверки гипотезы Н0:b0 = 0:
![]()
где b0 - оценка коэффициента модели регрессии 0 ;
Sb0 - величина стандартной ошибки коэффициента модели регрессии 0.
Наблюдаемое значение t-критерия Стьюдента для проверки гипотезы Н0:b1 = 0:
![]()
где b1 - оценка коэффициента модели регрессии 1;
Sb1- величина стандартной ошибки коэффициента модели регрессии 1.
Если |tнабл| > tкрит, т.е. модуль наблюдаемого значения t-критерия больше критического значения t-критерия, то с вероятностью (1 – α) основная гипотеза о незначимости коэффициентов модели регрессии отвергается (коэффициенты модели регрессии значимо отличаются от нуля).
Если |tнабл| ≤ tкрит, т.е. модуль наблюдаемого значения t-критерия меньше или равен критическому значению t-критерия, то с вероятностью α основная гипотеза о незначимости коэффициентов модели регрессии принимается (коэффициенты модели регрессии почти не отличаются от нуля или равны нулю).
Значимость парного коэффициента корреляции между факторной переменной х и результативной переменной у означает его значимое отличие от нуля.
Основной гипотезой, выдвигаемой при проверке значимости коэффициента корреляции, является гипотеза Н0, о незначимости полученного коэффициента: Н0:ryx = 0. Обратной (или альтернативной) является гипотеза Н1 о значимости парного коэффициента корреляции: Н1: ryx ≠ 0.
Выдвинутые гипотезы проверяются с помощью t-статистики или t-критерия Стьюдента в том случае, если объём выборки достаточно велик (n ≥ 30) и коэффициент корреляции по модулю значительно меньше единицы 0,45 ≤ | ryx | ≤ 0,75. Наблюдаемое значение t-критерия tкрит сравнивают со значением t-критерия, определяемым по таблице распределение Стьюдента, или с критическим значением tкрит.
Критическое значение t-критерия определяется по таблице распределений t-критерия Стьюдента:
tкрит(α; n – к) ,
где α - уровень значимости; к - число оцениваемых по выборке коэффициентов; (n - к) - число степеней свободы.
Наблюдаемое значение t-критерия Стьюдента для проверки гипотезы Н0:ryx = 0 в случае линейной модели парной регрессии:
![]()
где rух парный коэффициент корреляции между переменными х и у.
Если |tнабл| > tкрит, т.е. модуль наблюдаемого значения t-критерия больше критического значения t-критерия, то с вероятностью (1 - α) основная гипотеза о незначимости парного линейного коэффициента корреляции отвергается. Между переменными х и у существует корреляционная связь, которую можно оценить с помощью построения модели парной регрессии.
Если |tнабл| ≤ tкрит т.е. модуль наблюдаемого значения t-критерия меньше или равен критическому значению t-критерия, то с вероятностью α основная гипотеза о незначимости коэффициента корреляции принимается.
Значимость линейной модели парной регрессии зависимости между факторной переменной х и результативной переменной у означает её значимое отличие от нуля. Проверка гипотезы о значимости модели регрессии равнозначна проверке гипотез о значимости парного коэффициента детерминации r2xy или коэффициентов регрессии β0 и β1.
Если значимость модели парной регрессии проверяется через значимость парного коэффициента детерминации, то выдвигается основная гипотеза Н0: ryx = 0 о незначимости данного коэффициента и, следовательно, о незначимости модели парной регрессии е целом. Обратной (или альтернативной) является гипотеза Н1: ryx ≠ 0 о значимом отличии от нуля парного коэффициента детерминации и, следовательно, о значимости построенной модели парной регрессии.
Если значимость модели парной регрессии проверяется через значимость коэффициентов регрессии, то выдвигаются основные гипотезы Н0:0 = 0 и Н0:1 = 0 и, следовательно, о незначимости модели парной регрессии в целом. Обратными (или альтернативными) являются гипотезы Н1:0 ≠ 0 и Н1: 1 ≠ 0 о значимом отличии от нуля коэффициентов регрессии и, следовательно, о значимости построенной модели парной модели.
Для проверки гипотезы о значимости модели парной регрессии в целом используется F-критерий Фишера-Снедекора. При этом наблюдаемое значение F-критерия Fнабл сравнивают с критическим значением F-критерия Fкрит, определяемым по таблице распределения Фишера-Снедекора.
Наблюдаемое значение F-критерия для проверки гипотезы о незначимости линейной модели парной регрессии:
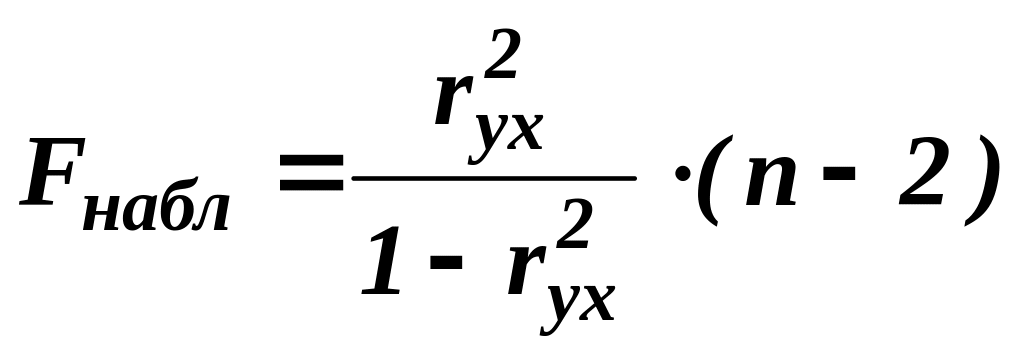 .
.
Критическое значение F-критерия определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости α и числа степеней свободы: k1 = к - 1 и k2 = n – к, где n - объём выборочной совокупности, к - число оцениваемых по выборке коэффициентов. При проверке значимости модели парной регрессии критическое значение F-критерия рассчитывается как Fкрит(α; 1; n – 1).
Если Fнабл > Fкрит, т.е. наблюдаемое значение F-критерия больше критического значения данного критерия, то с вероятностью α основная гипотеза о незначимости парного коэффициента детерминации или коэффициентов модели регрессии отвергается, и модель парной регрессии значимо отличается от нуля.
Если Fнабл < Fкрит т.е. наблюдаемое значение F-критерия меньше критического значения данного критерия, то с вероятностью (1 – α) основная гипотеза о незначимости парного коэффициента детерминации или коэффициентов модели регрессии принимается, и полученная модель парной регрессии является незначимой.
Точечный и интервальный прогнозы для модели парной регрессии.
Одной из основных функций построенной модели парной регрессии является дальнейшее её применение в экономических расчетах. В большинстве случаев модели регрессии используют для расчета прогнозного значения результативной переменной при заданном значении факторной переменной.
Точечный прогноз результативной переменной у при заданном значении факторной переменной хk в случае линейной модели парной регрессии рассчитывается по формуле:
![]() = b0
+ b1xk
+ ek
= b0
+ b1xk
+ ek
Точечная оценка прогноза результативной переменной с доверительной вероятностью (1 - α) попадает в интервал прогноза, который определяется по формуле:
– t·S ≤ yk* ≤ + t· S ,
где yk* - прогнозное значение результативной переменной; t - t-критерий Стьюдента, который определяется в зависимости от заданного уровня значимости α и числа степеней свободы (n - 2) для модели парной регрессии; S - величина ошибки прогноза в точке k:
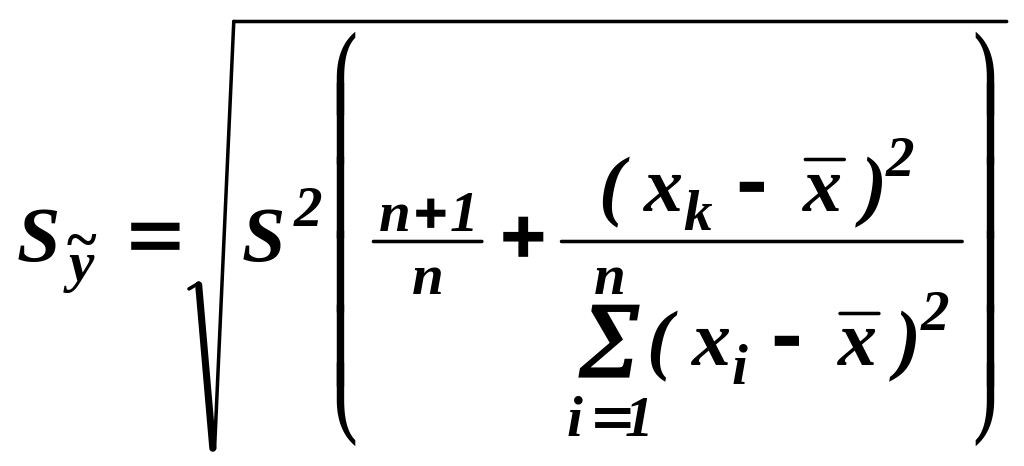 ,
,
где S2 - несмещённая оценка дисперсии случайной ошибки линейной модели парной регрессии σ2(); n - объём выборочной совокупности.
Линейная модель множественной регрессии используется для характеристики формы связи между результативной (зависимой) переменной и несколькими факторными (независимыми) переменными.
При построении нормальной (классической) линейной модели множественной регрессии учитываются следующие пять условий:
1) х1i … хmi, - неслучайные и независимые переменные;
2) E(i)=0, где i = 1, 2 … n, т.е. математическое ожидание случайной ошибки модели регрессии равно нулю во всех наблюдениях;
3) D() = Е(i2) = σ2 = const, т.е. дисперсия случайной ошибки модели регрессии постоянна для всех наблюдений;
4) соv(i , j) = Е(i j) = 0, где i ≠ j, т.е. случайные ошибки модели регрессии не коррелируют между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю). Это условие не выполняется для временных рядов;
5) i - N(0,σ2) т.е. случайная ошибка модели регрессии - случайная величина, подчиняющаяся нормальному закону распределения с нулевым математическим ожиданием и дисперсией σ2.
Общий вид линейной модели множественной регрессии:
yi = β0 + β1 x1i +…+ βn xni + i
где уi – значение i-ой результативной переменной, i=1,2 … n;
x1i … хmi - значения факторных переменных;
β0 … βn, неизвестные коэффициенты модели множественной регрессии; i - случайные ошибки модели множественной регрессии.
Матричный вид линейной модели множественной регрессии:
Y = XB +
где Y - вектор значений результативной переменной размерности n1; Х - вектор значений факторной переменной размерности n(m+1). Первый столбец является единичным, поскольку в модели регрессии коэффициент β0 умножается на единицу; B - вектор неизвестных коэффициентов размерности (m+1)1; - вектор случайных ошибок размерности n1.
Добавление в модель такого компонента, как вектор случайных ошибок, необходимо в связи с практической невозможностью оценить связь между переменными со стопроцентной точностью.
Классический метод наименьших квадратов для модели множественной регрессии.
Предположим, что между несколькими факторными переменными х и результативной переменной у существует линейная связь, которая описывается равенством:
yi = β0 + β1 x1i +…+ βm xmi + i
где уi - значение i-ой результативной переменной, i=1,2…n;
хi1...хmi - значения факторных переменных; β0…βm - неизвестные коэффициенты модели множественной регрессии; i - случайные ошибки модели множественной регрессии.
Неизвестные
коэффициенты линейной модели множественной
регрессии β0…βm
оцениваются с помощью классического
метода наименьших квадратов (МНК),
основная идея которого заключается в
определении такого вектора оценки β,
который минимизировал бы сумму квадратов
отклонений (остатков) наблюдаемых
значений результативной переменной у
от модельных значений
![]() (рассчитанных на основании построенной
модели регрессии).
(рассчитанных на основании построенной
модели регрессии).
Для модели множественной регрессии в общем случае минимизируется функционал вида:
![]() .
.
Решением системы нормальных уравнений будут МНК-оценки неизвестных коэффициентов модели множественной регрессии вида:
B = (XTX)-1XTY.
Применение соизмеримых показателей тесноты связи возможно из-за несопоставимости единиц измерения факторных переменных. К соизмеримым показателям тесноты связи относят коэффициенты частной эластичности и стандартизированные частные коэффициенты регрессии.
Коэффициент частной эластичности рассчитывается по формуле:
![]()
где
Хi
- среднее значение факторной переменной
хi
по выборке, i = 1,2…n;Y
- среднее значение результативной
переменной у по выборке;
![]() -
первая производная у по х.
-
первая производная у по х.
Частный коэффициент эластичности характеризует процентное изменение результативной переменной у при намерении на 1% от среднего уровня факторной переменной х, при постоянном значении остальных факторных переменных, участвующих в модели регрессии.
Частный коэффициент эластичности для линейной модели множественной регрессии определяется по формуле:
![]()
где βi - коэффициент модели множественной регрессии.
Частный коэффициент корреляции оценивает взаимосвязь между результативной переменной и одной из факторных переменных при постоянном значении остальных факторных переменных, включённых в модель регрессии.
Следовательно, частный коэффициент корреляции позволяет исключить влияние на результативную переменную всех факторных переменных, кроме одной.
Определим частные коэффициенты корреляции на примере линейной модели регрессии с двумя факторными переменными:
yi = β0 + β1 xi + β2 zi + i
где уi - результативная переменная, i = 1,2…n;
хi - первая факторная переменная; zi - вторая факторная переменная; β0, β1, β2 - неизвестные коэффициенты модели регрессии; i - случайная ошибка модели регрессии.
Частные коэффициенты корреляции позволяют оценить степень зависимости между результативной переменной уi и первой факторной переменной хi при постоянном значении второй факторной переменной zi, и наоборот, оценить степень зависимости между результативной переменной уi и второй факторной переменной zi при постоянном значении первой факторной переменной хi.
Подобные частные коэффициенты корреляции называются коэффициентами первого порядка, потому что исключается влияние только одной факторной переменной. Порядок частного коэффициента корреляции определяется количеством переменных, влияние которых исключается.
Частный коэффициент корреляции между переменными у и х при постоянном значении переменной z определяется по формуле:
![]()
где ryx , ryz , rxz - обычные парные коэффициенты корреляции.
Коэффициент множественной корреляции используется для оценки совокупного влияния всех факторных переменных, включенных в модель множественной регрессии, на результирующую переменную.
Определим коэффициент множественной корреляции для линейной модели множественной регрессии с m факторными переменными.
Общий вид линейной модели множественной регрессии:
yi = β0 + β1 x1i +…+ βm xmi + i
где уi - значение i-ой результативной перемен i = 1, 2, ... n;
хji - значение факторных переменных, i = 1, 2,...n, j = 1, 2,…m; β0, βm - неизвестные коэффициенты модели множественной регрессии; i – случайные ошибки модели множественной регрессии.
Коэффициент множественной корреляции характеризуется следующими свойствами:
1) он изменяется в пределах [0; +1] и поэтому не используется для определения направления связи между результативной переменной и факторными переменными;
2) между результативной и факторными переменными существует сильная взаимосвязь если значение множественного коэффициента корреляции близко к единице. Если значение множественного коэффициента корреляции близко к нулю, то между результативной и факторными переменными существует слабая взаимосвязь.
Коэффициент множественной детерминации характеризует, на сколько процентов построенная модель регрессии объясняет разброс значений результативной переменной относительно её среднего значения.
Коэффициент множественной детерминации рассчитывается как квадрат коэффициента множественной корреляции.
Коэффициент множественной детерминации также называется количественной характеристикой объясненной построенной моделью множественной регрессии дисперсии результативной переменной. Чем больше значение коэффициента множественной детерминации, тем лучше модель регрессии описывает анализируемую взаимосвязь между переменными.
Коэффициент множественной детерминации можно рассчитать на основании теоремы о разложении сумм квадратов.
Сумма квадратов разностей между значениями результативной переменной и её средним значением по выборке может быть представлена следующим образом:
![]() =
=![]() +
+![]()
где - общая сумма квадратов модели множественной регрессии с n переменными (Total Sum of Squares - TSS); - сумма квадратов остатков модели множественной регрессии с n переменными (Error Sum of Squares – ESS); сумма квадратов объясненной регрессии модели множественной регрессии с n переменными (Regression Sum of Squares - RSS).
Коэффициент множественной детерминации, рассчитанный через теорему о разложении сумм квадратов:
R2(y, x1…xn) = 1- ESS/TSS
Воздействие на качество дополнительно включенной в модель регрессии факторной переменной не всегда можно определить с помощью обычного коэффициента множественной детерминации. Для этой цели рассчитывается скорректированный (adjusted) коэффициент множественной детерминации, в котором учитывается количество факторных переменных в модели регрессии:
![]() ,
,
где n - количество наблюдений в выборочной совокупности;
к - число оцениваемых коэффициентов в модели регрессии.
При большом объёме выборки значения обычного и скорректированного коэффициентов множественной детерминации практически не отличаются
Значимость частного коэффициента корреляции между факторной переменной хi и результативной переменной у означает его значимое отличие от нуля.
Основной гипотезой, выдвигаемой при проверке значимости частного коэффициента корреляции, является гипотеза Н0 о незначимости полученного коэффициента: Н0:r(ухi/х1....хn-1) = 0. Обратной является гипотеза H1, о значимости частного коэффициента корреляции: Н1:r(ухi/х1....хn-1) ≠ 0. Гипотезы проверяются с помощью t-статистики или t-критерия Стьюдента.
Критическое значение t-критерия, определяемое по таблице распределений t-критерия Стьюдента:
tкрит(α/2; n-к-1),
где α/2 - уровень значимости; n - объём выборки; к - число оцениваемых по выборке коэффициентов; (n–к–1) – степень свободы.
Наблюдаемое значение t-критерия Стьюдента для проверки гипотезы Н0:r(ухi/х1....хn-1) = 0:
![]() .
.
Если |tнабл| > tкрит, то с вероятностью (1 - α) основная гипотеза о незначимости частного коэффициента корреляции отвергается. Между переменными хi и у существует корреляционная связь при постоянных значениях остальных факторных переменных, включенных в модель.
Если |tнабл| ≤ tкрит, то с вероятностью α основная гипотеза о незначимости частного коэффициента корреляции принимается. Между переменными хi и у отсутствует корреляционная связь при постоянных значениях остальных факторных переменных, включённых в модель.
Основной гипотезой, выдвигаемой при проверке значимости частного коэффициента корреляции, является гипотеза Н0 о незначимости полученного коэффициента: Н0:R(ухi) = 0, i = 1, 2, …, n. Обратной является гипотеза Н1 о значимости коэффициента множественной корреляции: Н1:R(ухi) ≠ 0.
Гипотезы проверяются с помощью F-статистики или F-критерия Фишера.
Критическое значение F-критерия определяется по таблице распределения Фишера-Снедекора:
Fкрит(α; k1; k2),
где α - уровень значимости; k1 = к - 1 и k2 = n – к – число степеней свободы,.
Наблюдаемое значение F-критерия Фишера для проверки гипотезы Н0:R(ухi) = 0,:
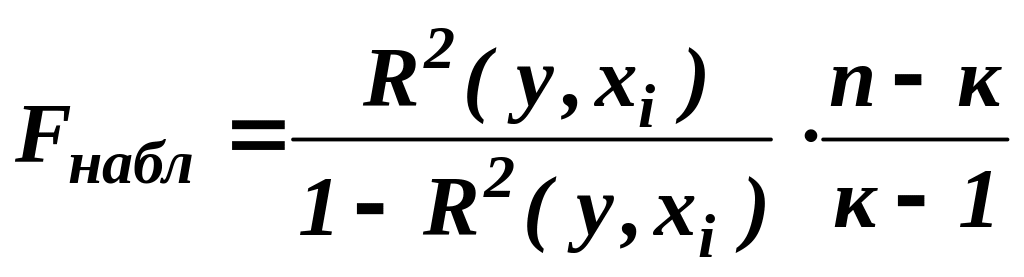 ,
,
где R2(у, хi) - коэффициент множественный детерминации.
Если Fнабл > Fкрит, то с вероятностью α основная гипотеза о незначимости коэффициента множественной регрессии отклоняется, и он признается значимым.
Основной гипотезой, выдвигаемой при проверке значимости коэффициентов регрессии, является гипотеза Н0 о незначимости полученных коэффициентов:
![]() .
.
Обратной
является гипотеза Н1 о
значимости коэффициентов регрессии:
![]() .
.
Гипотезы проверяются с помощью t-статистики или t-критерия Стьюдента, который рассчитывается через частный F-критерий Фишера. Между этими критериями существует взаимосвязь, используемая при проверке значимости коэффициентов модели множественной регрессии:
![]() ,
,
Критическое значение t-критерия: tкрит(α; n-к-1),
где α - уровень значимости; n - объем выборки; к - число оцениваемых по выборке коэффициентов; (n - к - 1) - степень свободы, определяемая по таблице распределений t-критерия Стьюдента.
Наблюдаемое значение частного F-критерия для проверки гипотезы
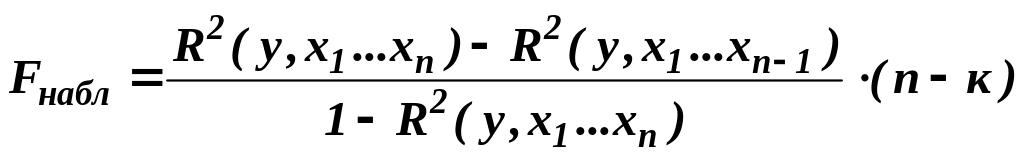 .
.
Если tнабл ≥ tкрит, то основная гипотеза о незначимости коэффициентов модели множественной регрессии отклоняется,
Если tнабл < tкрит, то основная гипотеза о незначимости коэффициентов модели множественной регрессии принимается.
Проверка гипотезы о значимости модели множественной регрессии состоит в проверке гипотезы о значимости множественного коэффициента корреляции или значимости коэффициентов модели регрессии. В большинстве случаев значимость модели множественной регрессии проверяется через значимость коэффициента множественной корреляции.
Основной гипотезой, выдвигаемой при проверке значимости модели множественной регрессии, является гипотеза Н0 о её незначимости: Н0:r(ухi/х1....хn-1) = 0.
Гипотезы проверяются с помощью F-критерия Фишера. Критическое значение F-критерия определяется по таблице распределения Фишера-Снедекора: Fкрит(α; k1; k2),
где α - уровень значимости; k1 = к – 1; k2 = n – к - число степеней свободы,.
Наблюдаемое значение F-критерия для проверки гипотезы Н0:r(ухi/х1....хn-1) = 0:
где R2(y, хi) – коэффициент множественной детерминации.
Если Fнабл > Fкрит, то с вероятностью α основная гипотеза о незначимости коэффициента множественной корреляции отклоняется, и модель множественной регрессии признается значимой.
Последствия мультиколлинеарности и методы её обнаружения.
Мультиколлинеарность - это нарушение первой предпосылки линейной модели множественной регрессии о независимости факторных переменных х1i, ... хmi, включённых в модель.
Мультиколлинеарность в матричном виде - это зависимость между столбцами матрицы факторных переменных Х.
Основная причина мультиколлинеарности заключается в неправильном подборе факторных переменных х1i, ... хmi, включённых в модель.
Последствия, к которым может привести наличие мультиколлинеарности в модели множественной регрессии:
1) основная гипотеза о незначимости коэффициентов множественной регрессии в большинстве случаев подтверждается, однако сама модель регрессии при проверке с помощью F-критерия оказывается значимой;
2) полученные оценки коэффициентов модели множественной регрессии неоправданно завышены или имеют неправильные знаки;
3) добавление или исключение из исходных данных одного-двух наблюдений оказывает сильное влияние на оценки коэффициентов модели регрессии;
4) наличие мультиколлинеарности в модели множественной регрессии может сделать её непригодной для дальнейшего применения (например, для построения прогнозов).
С целью обнаружения мультиколлинеарности анализируется корреляционная матрица факторных переменных R.
Корреляционная матрица факторных переменных - это симметричная относительно главной диагонали матрица линейных парных коэффициентов корреляции факторных переменных:

где rij - коэффициент парной линейной корреляции между i-ой и j-ой факторными переменными, i,j =1,2, ... n.
Если в корреляционной матрице факторных переменных есть парный коэффициент корреляции между i-ой и j-ой переменными r>0,8, то в модели множественной регрессии присутствует мультиколлинеарность.
Если собственное число корреляционной матрицы факторных переменных λmax<10-5, то в модели множественной регрессии присутствует мультиколлинеарность.
Если отношение собственных чисел корреляционной матрицы факторных переменных λmin/λmax<10-5, то в модели множественной регрессии присутствует мультиколлинеарность.
Если при прогнозировании результативной переменной величина ошибки прогноза является удовлетворительной, то модель множественной регрессии можно использовать и при наличии мультиколлинеарности. Если же прогноз получается неудовлетворительным, то мультиколлинеарность необходимо устранять.
Сбор дополнительных данных - простой способ устранения мультиколлинеарности, однако на практике это не всегда возможно.
Метод преобразования переменных - это способ замены всех переменных, включенных в модель. Например, вместо значений результативной переменной и факторных переменных можно взять их логарифмы. Тогда модель множественной регрессии имеет вид:
.ln y = b0 + b1ln x1 + b2ln x2 + e.
Однако этот метод не гарантирует устранения мультиколлинеарности.
Метод пошагового включения факторных переменных в модель регрессии – это метод определения из возможного набора факторных переменных именно тех, которые усилят качество модели регрессии.
Суть метода пошагового включения состоит в том, что из числа всех факторных переменных в модель регрессии включаются переменные, имеющие наибольший модуль парного линейного коэффициента корреляции с результативной переменной. При добавлении в модель регрессии новых факторных переменных их значимость проверяется с помощью F-критерия Фишера. Если Fнабл > Fкрит, то включение факторной переменной в модель множественной регрессии является обоснованным. Проверка факторных переменных на значимость осуществляется до тех пор, пока не найдётся хотя бы одна переменная, для которой не выполняется условие Fнабл > Fкрит.
Гетероскедастичность - это явление неоднородности дисперсий случайных ошибок (остатков) модели регрессии (рис. 2).
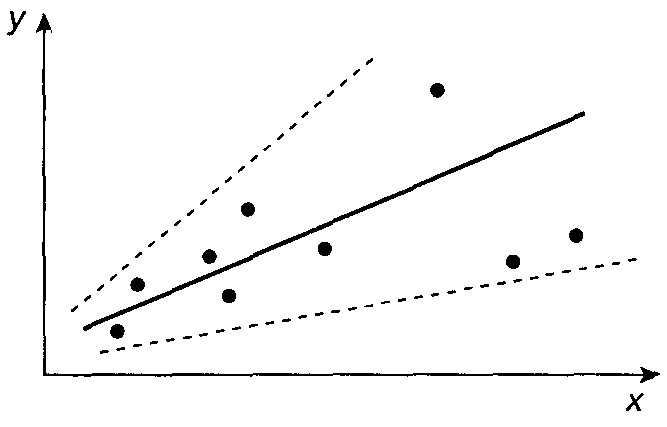
Рис. 2. Случай гетероскедастичности остатков
Случайная ошибка модели регрессии - это величина отклонения в модели линейной множественной регрессии:
i = yi – β0 – β1x1i – …– βmxmi.
Величина случайной ошибки модели регрессии неизвестна, поэтому вычисляется выборочная оценка случайной ошибки модели регрессии:
еi = yi – – b0 – b1x1i –…– bmxmi,
где еi - остатки модели регрессии. Одно из условий нормальной линейной модели множественной регрессии заключается в том, что D(i) = Е(i 2) = σ2 = const, т.е. дисперсия случайной ошибки модели регрессии является постоянной для всех наблюдений, данное условие называется гомоскедастичностью дисперсий случайных ошибок модели регрессии.
Гомоскедастичность - это ситуация постоянства дисперсии случайной ошибки еi для всех i наблюдений модели регрессии.
Но на практике условие гомоскедастичности случайной ошибки i, или остатков модели регрессии еi не всегда выполняется. Поэтому предположение о разнородности дисперсий случайных ошибок для всех i наблюдений модели регрессии выглядит так:
D(i) ≠ Е(i 2) ≠ σ2 ≠ const,
где i ≠ j.
Условие гетероскедастичности можно выразить через ковариационную матрицу:
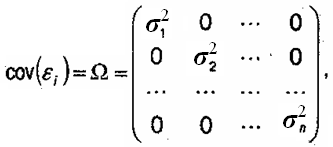
где σ12 ≠ σ22 ≠…≠ σn2.
Последствия гетероскедастичности остатков модели регрессии:
1) оценки нормальной линейной модели регрессии остаются несмещенными и состоятельными, но теряется эффективность;
2) появляется вероятность неверного вычисления оценок стандартных ошибок коэффициентов модели регрессии, что может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом.
Обнаружить гетероскедастичность остатков модели регрессии можно путем проверки гипотез.
Основной Н0 является гипотеза о гомоскедастичности остатков модели регрессии Н0:σ12=σ22=…=σn2=σ2. Обратной, или альтернативной, является гипотеза Н1 о гетероскедастичности остатков модели регрессии
Н1:σ12 ≠ σ22 ≠…≠ σn2
В основе теста Голдфелда-Квандта обнаружения гетероскедастичности остатков модели регрессии лежит предположение о нормальном законе распределения случайной ошибки i модели регрессии.
Тест Голдфелда-Квандта проводится в несколько этапов.
1. Предположим, что на основе выборочных данных была построена линейная модель множественной регрессии:
уi = b0 + b1x1i + b2x2i + b3x3i + ei
где уi - результативная переменная, i = 1,2…, n;
xmi - факторные переменные (m = 1, 2, 3; i=1,2…, n);
b0, b1, b2, b3 - неизвестные коэффициенты модели регрессии;
ei - случайная ошибка модели регрессии.
2. В модели множественной регрессии выбирается факторная переменная xmi (m = 1, 2, 3; i=1,2…, n), от которой могут зависеть остатки модели еi. Значения переменной xmi ранжируются, располагаются по возрастанию и делятся на три части.
3. Для первой и третьей частей строятся две независимые модели регрессии:
уi1 = b01 + b11x1i + b21x2i + b31 x3i , где i = 1,…,n’;
уi3 = b03 + b13x1i + b23x2i + b33 x3i где i = n’+1,…,n
4. По каждой из построенных моделей регрессий рассчитываются суммы квадратов остатков:
![]()
![]()
5. Осуществляется проверка основной гипотезы об отсутствии гетероскедастичности в основной модели множественной регрессии через F-критерий Фишера.
Критическое значение F-критерия, определяемое по таблице распределения Фишера-Снедекора
Fкрит(α; k1; k2),
где α - уровень значимости; k1 = n’- к и k2 = n’- к - степени свободы; к - количество оцениваемых коэффициентов в основной модели регрессии,.
Наблюдаемое значение F-критерия:
![]() если ESS3
> ESS1;
если ESS3
> ESS1;
или
![]() если ESS1
> ESS3;
если ESS1
> ESS3;
Если Fнабл > Fкрит, то основная гипотеза отклоняется, и в основной модели регрессии присутствует гетероскедастичность, зависящая от факторной переменной xmi.
Если Fнабл ≤ Fкрит, то основная гипотеза принимается, и гетерскедастичность в основной модели регрессии не зависит от факторной переменной xmi.
Взвешивание членов модели регрессии - это наиболее простой метод устранения гетероскедастичности остатков модели регрессии. Суть состоит в том, что отдельным наблюдениям результативной переменной уi с максимальным среднеквадратическим отклонением случайной ошибки придаётся больший вес, а остальным наблюдениям результативной переменной уi с минимальным среднеквадратическим отклонением случайной ошибки придается меньший вес.
Процесс взвешивания параметров модели регрессии осуществляется в несколько этапов.
1. Предположим, что по данным выборочной совокупности была построена линейная модель парной регрессии вида:
![]()
В данной модели регрессии доказано наличие гетероскедастичности остатков, т.е. σ2(i) ≠ σ2(j),
где i ≠ j.
2. Разделим все члены модели регрессии на среднеквадратическое отклонение случайной ошибки S(i).
Общий вид процесса взвешивания для модели парной регрессии:
![]() ,
i = 1, 2,…, n
,
i = 1, 2,…, n
3. Полученную модель регрессии приведем к линейному виду с помощью метода замен:
![]()
![]()
![]()
![]()
Запишем модель регрессии в линеаризованном виде:
![]()
Полученная модель регрессии является моделью с двумя факторными переменными - ui и zi.
4. Дисперсия случайной ошибки взвешенной модели регрессии определяется по формуле:

Данное равенство говорит о постоянстве дисперсий случайных ошибок преобразованной модели регрессии, т.е., о присутствии условия гомоскедастичности остатков модели регрессии.
Главная проблема метода взвешивания членов модели регрессии - необходимость априорного знания среднеквадратических отклонений случайных ошибок модели регрессии.
Автокорреляция - это корреляция, которая возникает между уровнями исследуемой переменной, т.е. корреляция во времени. Свойство автокорреляции чаще всего проявляется во временных рядах.
Автокорреляция остатков модели регрессии еi (или случайных ошибок модели регрессии i) - это корреляционная зависимость между настоящими и прошлыми значениями остатков.
Временной лаг - это величина сдвига между рядами остатков модели регрессии. Величина временного лага определяет порядок коэффициента автокорреляции.
Например, если существует корреляционная зависимость между остатками еn и еn-2, то величина временного лага равняется двум. Следовательно, данную зависимость будет характеризовать коэффициент автокорреляции второго порядка между рядами остатков е1...еn-2 и е3.. .еn.
Одно из условий нормальной линейной модели регрессии заключается в том, что cov(i,j) = E(i j) = 0, где i ≠ j, т.е. случайные ошибки модели регрессии не коррелированы между собой, ковариация случайных ошибок любых двух разных наблюдений равна нулю. Нарушение этого условия приводит к автокорреляции остатков модели регрессии.
Последствий автокорреляции остатков модели регрессии аналогичны последствиям гетероскедастичности остатков модели регрессии:
1) оценки нормальной линейной модели регрессии остаются несмещенными и состоятельными, но теряется эффективность;
2) появляется вероятность неверного вычисления оценок стандартных ошибок коэффициентов модели регрессии, что может привести к утверждению неверной гипотезы о значимости коэффициентов регрессии и значимости модели регрессии в целом.
Применение автокорреляционной и частной автокорреляционной функций - это наиболее простой способ обнаружения автокорреляции остатков модели регрессии.
Автокорреляционная функция (АКФ) - это функция оценки коэффициента автокорреляции в зависимости от величины временного лага между исследуемыми рядами.
Коррелограмма - это график автокорреляционной функции. На коррелограмме отражаются коэффициенты автокорреляции (и их стандартные ошибки) для последовательности лагов из определенного диапазона (например, от 1 до 15). По оси Х откладываются значения τ (тау) - величины сдвига между рядами остатков. Значение τ совпадает с порядком автокорреляционного коэффициента.
Частная автокорреляционная функция (ЧАКФ) - это более глубокое понятие обычной АКФ. ЧАКФ на конкретном лаге отличается от обычной АКФ на величину удаленных автокорреляций с меньшими временными лагами, т.е. ЧАКФ даёт более точную картину автокорреляционных зависимостей остатков модели.
Для обнаружения автокорреляции первого порядка (между соседними рядами данных) остатков модели регрессии применяется критерий Дарбина-Уотсона.
Предположим, что по выборочным данным была построена модель множественной регрессии:
Y= XB + t.
Ошибка, возникшая в связи с наличием в модели регрессии автокорреляции первого порядка, может быть представлена выражением:
t = t-1,
где ρ - коэффициент автокорреляции первого порядка, |ρ| < 1;
vt - независимые, одинаково распределенные случайные величины с нулевым математическим ожиданием и дисперсией σ2(vt). Для подтверждения наличия в модели регрессии автокорреляции первого порядка необходимо проверить значимость коэффициента автокорреляции первого порядка ρ (его значимое отличие от нуля).
При проверке значимости коэффициента автокорреляции первого порядка основной Н0 является гипотеза о незначимости данного коэффициента: Н0:ρ1= 0. Обратной, или альтернативной, является гипотеза Н1 о значимости коэффициента автокорреляции первого порядка: Н1:ρ1 ≠ 0.
Выдвинутые гипотезы проверяются с помощью критерия Дарбина-Уотсона.
Критическое значение критерия Дарбина-Уотсона dкрит(n; к–1) определяется с помощью специальных таблиц, в которых указаны значения верхней d1, и нижней d2 границы критерия. Данные границы рассчитываются на основании объёма выборки n и числа степеней свободы (к - 1), где к - количество оцениваемых по выборке коэффициентов.
Наблюдаемое значение критерия Дарбина-Уотсона dнабл для проверки гипотезы Н0:ρ1= 0:
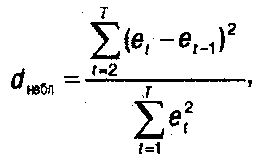
где еt остатки модели регрессии в наблюдении t, et-1 - остатки модели регрессии в наблюдении t-1:
Приближённое значение величины критерия Дарбина-Уотсона можно также вычислить по формуле: dнабл2(1-r1),
где r1 - выборочный коэффициент автокорреляции первого порядка.
Устранение автокорреляции остатков модели регрессии - это необходимый этап в оценивании модели регрессии в связи c теми негативными последствиями, к которым может привести корреляционная зависимость между значениями случайных ошибок.
Авторегрессионная схема первого порядка - это метод устранения автокорреляции первого порядка между соседними членами ряда остатков в линейных моделях регрессии либо моделях регрессии, сводящихся к линейному виду. Для практического использования данной схемы необходимо знать величину коэффициента автокорреляции. Поскольку величина коэффициента автокорреляции ρ1 неизвестна, то в качестве его оценки используется выборочный автокорреляционный коэффициент остатков первого порядка r1:

Предположим, что на основе выборочных данных была построена модель парной регрессии, содержащая автокорреляцию остатков первого порядка:
yt = β0 + β1xt + t
Модель регрессии в момент времени t с учётом процесса автокорреляции остатков первого порядка может быть представлена в виде:
yt = β0 + β1xt + t-1 + vt
где ρ - коэффициент автокорреляции, |ρ| < 1;
vt - независимые, одинаково распределенные случайные величины с нулевым математическим ожиданием и дисперсией σ2(vt).
Модель регрессии в момент времени (t-1) можно представить в виде:
yt-1 = β0 + β1xt-1 + t-1
Если модель регрессии в момент времени (t-1) умножить на коэффициент автокорреляции первого порядка ρ и вычесть его из исходной модели регрессии в момент времени t, то получим преобразованную модель регрессии с учётом автокорреляции первого порядка:
yt - yt-1 = β0 (1-) + β1(xt - xt-1) + vt
Для упрощения модели регрессии воспользуемся методом замен:
Yt = yt - yt-1; Xt = xt - xt-1; Zt= 1-.
С учётом замен модель регрессии может быть представлена в виде:
Yt = Zt β0 + β1Xt + vt
Случайная ошибка vt модели регрессии не подвержена процессу автокорреляции, поэтому автокорреляцию остатков модели регрессии можно считать устранённой.
Авторегрессионную схему первого порядка можно применить ко всем строкам матрицы исходных данных Х, кроме первого наблюдения. Но отсутствие значений Y1 и Х1 в небольшой выборочной совокупности может привести к неэффективности оценок коэффициентов модели регрессии.
Обобщённый метод наименьших квадратов. Нормальная линейная модель регрессии характеризуется выполнением двух условий о случайных ошибках:
1) D(i) = Е(i) = σ2 = const, т.е. дисперсия случайной ошибки модели регрессии является величиной, постоянной для всех наблюдений;
2) cov(i, j) = Е(i j) = 0, где i ≠ j, т.е. ошибки модели регрессии не коррелированы между собой (ковариация случайных ошибок любых двух разных наблюдений равна нулю).
При наличии в модели регрессии гетероскедастичности остатков нарушается первое из указанных условий, т.е. D(i) ≠ D(j) ≠ σ2 ≠ const, i ≠ j. При условии наличия в модели регрессии автокорреляции остатков нарушается второе условие, т.е. cov(i, j) ≠ Е(i j) ≠ 0.
Обобщенная модель регрессии - это модель регрессии, для которой не выполняются вышеперечисленные условия о случайных ошибках.
Матричный вид обобщённой линейной модели
Y = XB + ,
где Х - неслучайная матрица факторных переменных;
- случайная ошибка модели регрессии с нулевым математическим ожиданием Е() = 0 и дисперсией σ2()Ω, i ~ N(0, σ2 Ω); Ω - ковариационная матрица случайных ошибок обобщённой модели регрессии.
Ковариационная матрица в обобщённой модели регрессии строится, исхода из условия непостоянства дисперсий остатков модели регрессии D(i) ≠ D(j) ≠ σ2 ≠ const:
Для получения оценок неизвестных коэффициентов модели регрессии с гетероскедастичными или коррелированными случайными ошибками, удовлетворяющих свойствам состоятельности, несмещённости и эффективности, используется обобщенный метод наименьших квадратов (ОМНК).
Теорема Айткена. В классе линейных несмещённых оценок неизвестных коэффициентов обобщённой модели регрессии оценка будет иметь наименьшую ковариационную матрицу.
![]()
Общая формула для расчёта матрицы ковариаций ОМНК-оценок коэффициентов обобщенной модели регрессии:
![]()
Оценка величины σ2() рассчитывается по формуле:
![]()
Проверка гипотез о значимости коэффициентов обобщённой модели регрессии и модели регрессии в целом осуществляется с помощью тех же статистических критериев, что и в случае нормальной линейной модели регрессии.
Если в обобщённой модели регрессии случайные ошибки автокоррелированны, но гомоскедастичны, то для определения оценок неизвестных коэффициентов регрессии используется доступный обобщенный метод наименьших квадратов (ДОМНК).
Оценки неизвестных коэффициентов обобщённой модели регрессии рассчитываются с помощью ДОМНК по формуле:
![]()
где
![]() - оценка матрицы ковариаций случайных
ошибок обобщённой модели регрессии.
- оценка матрицы ковариаций случайных
ошибок обобщённой модели регрессии.
Обобщённая модель парной регрессии с автокоррелированными, но гомоскедастичными случайными ошибками:
yt = β0 + β1xt + t
Предположим, что случайные ошибки полученной модели регрессии подчиняются авторегрессионному процессу первого порядка. Тогда исходную модель регрессии можно представить в виде:
yt = β0 + β1xt + t-1 + vt
где ρ - коэффициент автокорреляции первого порядка, |ρ| < 1;
vt - независимые, одинаково распределённые случайные величины с нулевым математическим ожиданием и дисперсией σ2(vt).
Математическое ожидание случайной ошибки обобщённой модели регрессии:
E(t) =E(t-1 + vt ) = E(t-1) + E(vt) = 0.
Дисперсия случайной ошибки обобщённой модели регрессии:
![]()
Ковариация между двумя случайными ошибками модели регрессии 2 и 1.
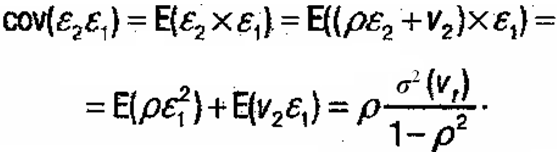
Ковариация между следующими случайными ошибками модели регрессии 3 и 1.

Дальнейший процесс расчета ковариаций продолжается для всех случайных ошибок обобщённой модели регрессии по тому же принципу.
В результате проведенных расчётов получим ковариационную матрицу случайных ошибок обобщённой линейной модели регрессии:

Величина σ2(vt) является дисперсией случайной ошибки модели регрессии.
Модели регрессии с переменной структурой. Фиктивные переменные.
В большинстве случаев в модель регрессии включаются количественные факторные переменные. Однако при проведении некоторых исследований может возникнуть необходимость во включении в модель регрессии качественных факторных переменных (таких например, образование, возраст, пол и т.д.).
Фиктивная переменная - это атрибутивная, или качественная, факторная переменная, которая представлена с помощью определённого цифрового кода.
Модель регрессии с переменной структурой - это модель регрессии, которая включает в качестве факторной переменной (факторных переменных) фиктивную переменную.
В качестве примера модели регрессии с переменной структурой можно привести модель регрессии размера заработной платы (результативная переменная у от стажа работников с различным образованием (факторная переменная х).
Факторная переменная «образование» является качественной. Она может принимать три значения:
1) среднее образование;
2) среднее специальное образование;
3) высшее образование.
Для включения факторной переменной «образование» в модель регрессии используются только две фиктивные переменные, потому что фиктивных переменных в модель регрессии должно быть на единицу меньше, чем значений качественной факторной переменной.
Фиктивные переменные, характеризующие факторную переменную «образование»:
![]()
![]()
В результате получим модель регрессии с переменной структурой вида:
y = β0 + β1x + β2 D1 + β3 D2.
Данная модель регрессии называется моделью регрессии без ограничений.
Если все значения фиктивных переменных в модели регрессии равны нулю (D1=D2=0), то модель регрессии вида: у = β0+β1х называется базисной моделью регрессии, или моделью регрессии с ограничениями.
Частная модель регрессии заработной платы работников со средним специальным образованием от стажа:
у = β0+β1х+β2D1.
Коэффициент β2 показывает, насколько большую заработную плату получают рабочие со средним специальным образованием по сравнению с рабочими со средним образованием при одинаковом стаже работы.
Частная модель регрессии заработной платы работников с высшим образованием от стажа:
у = β0+β1х+β3D2.
Коэффициент β3 показывает, насколько большую заработную плату получают рабочие с высшим образованием по сравнению с рабочими со средним образованием при одинаковом стаже работы.
Тест Чоу - это метод который позволяет проверить предположение необходимости разбиения основной выборочной совокупности на части, или подвыборки.
Предположим, что на основании выборочных данных была построена основная модель регрессии без ограничений UN, т.е. все фиктивные переменные, включенные в данную модель, не равны нулю. В качестве подвыборок основной модели регрессии без ограничений будем считать частные модели регрессии.
Введем следующие обозначения:
РR1 - первая подвыборка (первая частная модель регрессии);
РR2 - вторая подвыборка (вторая частная модель регрессии);
ЕSS(РR1) - сумма квадратов остатков для первой подвыборки;
ЕSS(РR2) - сумма квадратов остатков для второй подвыборки;
ЕSS(UN) - сумма квадратов остатков для основной модели регрессии без ограничений;
ESSUNPR1 - сумма квадратов остатков для наблюдений первой подвыборки в основной модели регрессии без ограничений;
ESSUNPR2 - сумма квадратов остатков для наблюдений второй подвыборки в основной модели регрессии без ограничений.
Для частных моделей регрессии должны выполняться следующие условия:
ESS(PR1)< ESSUN(PR1); ESS(PR2)< ESSUN(PR2), или
(ESS(PR1)+ ESS(PR2))< ESS(UN).
Значимость частных моделей регрессии определяется с помощью F-критерия Фишера.
При проверке значимости частных моделей регрессии основной Н0 является гипотеза о том, что качество основной модели регрессии без ограничений лучше качества частных моделей регрессии, или подвыборок. Обратной, или альтернативной, является гипотеза Н1.
Критическое значение F-критерия Фишера, определяемое по таблице распределения Фишера-Снедекора:
Fкрит(α; k1; k2),
где α - уровень значимости; k1=m+1 и k2=n-2m-2 – степени свободы; m - количество факторных переменных (в том числе фиктивных); n - объём общей выборочной совокупности.
Наблюдаемое значение F-критерия:
![]()
где ESS(UN) - ESS(PR1) - ESS(PR2) - величина, характеризующая улучшение качества модели регрессии после разделения её на подвыборки; m - количество факторных переменных (в том числе фиктивных); n - объем общей выборочной совокупности.
Если Fнабл > Fкрит, то основная гипотеза отклоняется, и качество частных моделей регрессии превосходит качество основной модели регрессии без ограничений.
Если Fнабл ≤ Fкрит, то основная гипотеза принимается, и нет необходимости разбивать основную модель регрессии без ограничений на подвыборки.
Спецификация переменных - это проблема отбора наиболее важных факторных переменных при построении модели регрессии.
Последствия неправильной спецификации переменных: исключение существенных и включение несущественных факторных переменных.