

Mastering Enterprise JavaBeans™ and the Java 2 Platform, Enterprise Edition - Roman E
..pdfWriting Container-Managed Persistent Entity Beans 
 259
259
Your EJB container’s generated classes are incorrect because your interfaces and classes haven’t fully complied with the EJB specification.
Your EJB container’s tools should ship with compliance checkers to help resolve this. But know that not everything can be checked.
Your EJB container has a real bug. This is a definite possibility that you must be prepared to encounter. In the future, however, this should not happen very often because EJB containers that comply with the Java 2 Platform, Enterprise Edition must test their source code against Sun Microsystems’ robust test suite.
There is a user error that occurs within the EJB container. For example, let’s say that in the product line example we gave, you used the field “desc” rather than “description” to describe your products. Unfortunately, the keyword “desc” is an SQL reserved keyword. This means that your JDBC driver would throw an exception when trying to execute any database updates that involved the word “desc.” These exceptions might be cryptic at best, depending on your JDBC driver. And when you try to figure out what JDBC code is acting up, you will run into a roadblock: With container-managed persistence, the JDBC code won’t be available because your bean does not perform its own data access! What do you do in this situation?
When you’re faced with grim situations such as this, contacting your EJB vendor is probably not going to be very helpful. If you are operating with a deadline, it may be too late by the time your vendor comes up with a solution. If you could only somehow get access to the JDBC code, you could try out the query yourself in Cloudscape or a similar program.
There are several options you can try here:
1.Some EJB containers support debugging environments, allowing you to step through your code in real time to pinpoint problems. This is something you should look for when choosing a container.
2.Check your database’s logfile to view a snapshot of what is really happening.
3.Your EJB container tools may have an option to keep generated Java files, rather than delete them when compiling them into classes. You can do this with BEA’s WebLogic with the -keepgenerated option to its deployer program. This is quite analogous to how you can use the -keepgenerated option to keep generated proxies with Java RMI’s rmic compiler.
4.As a last resort, you may have to decompile the offending classes to see what’s going on. A good decompiler is Jad by Pavel Kouznetsov (see the book’s accompanying Web site for a link). Of course, decompiling may be illegal depending on your container’s license agreement.
Go back to the first page for a quick link to buy this book online!

260 
 M A S T E R I N G E N T E R P R I S E J A V A B E A N S
M A S T E R I N G E N T E R P R I S E J A V A B E A N S
Summary
In this chapter, you learned how to write container-managed persistent entity beans. We saw how the bean instance callback methods differ between beanmanaged persistence and container-managed persistence. We then went through an example modeling product line using container-managed persistent entity beans. Finally, we wrapped up with a discussion of the promises and realities of container-managed persistence.
Congratulations, you’ve reached the conclusion of Part II! You now understand the basics of writing Enterprise JavaBeans. From this point, you have several choices. You can dive right into EJB and start writing your own beans to get a better grip on developing them. Or you can join us for Part III, where we’ll tackle more advanced concepts—including transaction theory and integrating EJB with CORBA. We promise you an intriguing ride.
Go back to the first page for a quick link to buy this book online!

P A R T THREE
Advanced Enterprise
JavaBeans Concepts
f you’ve read up to this point, you should be quite familiar with the basics of IEnterprise JavaBeans development. In Part III, we raise the bar by moving on
to more advanced concepts. These include the following:
Transactions. Chapter 10 explains the basics of transaction theory, assuming you know nothing about transactions already. We’ll relate transactions to EJB and explain the Java Transaction API (JTA). If you are performing any serious deployment, transaction knowledge is a must-have.
CORBA. Chapter 11 focuses on the Common Object Request Broker Architecture (or CORBA). CORBA is closely related to EJB, and it is a core technology in the Java 2 Platform, Enterprise Edition (J2EE). Understanding how CORBA and EJB relate is necessary when integrating with legacy systems.
These are extremely interesting middleware topics; indeed, many books have been written on their subjects alone. We will cover both these topics from an EJB perspective, relating them to the concepts we’ve explained thus far.
261
Go back to the first page for a quick link to buy this book online!

C H A P T E R10
Transactions
n Chapter 1, we first touched on the middleware services needed for robust, se- Icure, scalable, and reliable server-side development. This includes resource pooling services, security services, remotability services, persistence services, and more. We then saw how component developers can leverage these services through EJB products without writing to complex middleware APIs. Component developers can harness these services automatically and implicitly from the underlying EJB architecture, yielding rapid server-side application development.
A key service that is required for robust server-side development is transactions. Transactions, when used properly, can make your mission-critical operations run predictably in an enterprise environment. Transactions are an advanced programming paradigm that allows you to write robust code. Transactions are also very useful constructs to use when performing persistent operations, such as updates to a database.
In the past, transactions have been difficult to use. Product developers needed to code directly to a transaction API. But with EJB, you can gain the benefits of transactions without performing any transaction programming.
In this chapter, we’ll see some of the problems that transactions solve. We’ll also see how transactions work and show how they’re used in EJB. Because transactions are at the very core of EJB and are somewhat difficult to understand, we’ll provide extensive background on the subject. To explain transactions properly, we’ll occasionally get a bit theoretical. If the theory presented in this chapter piques your interest, there are many tomes written on transactions available for further reading. See the book’s accompanying Web site for links to more information.
263
Go back to the first page for a quick link to buy this book online!

264 
 M A S T E R I N G E N T E R P R I S E J A V A B E A N S
M A S T E R I N G E N T E R P R I S E J A V A B E A N S
The Motivation for Transactions
We begin our discussion with a few motivational problems that transactions address.
Atomic Operations
Imagine that you’d like to perform multiple discrete operations, yet have them execute as one contiguous, large, atomic operation. Take the classic bank account example. When you transfer money from one bank account to another, you want to withdraw funds from one account and deposit those funds into the other account. Ideally, both operations will succeed. But if an error occurs, you’d like both operations to always fail—otherwise, you’ll have incorrect funds in one of the accounts. You never want one operation to succeed and the other to fail because both operations are part of a single atomic transaction.
One simplistic way to handle this is to perform exception handling. You could use exceptions to write a banking module to transfer funds from one account to another, as in the following pseudo-code:
try {
// Withdraw funds from account 1
}
catch (Exception e) {
//If an error occurred, do not proceed.
return;
}
try {
//Otherwise, deposit funds into account 2
}
catch (Exception e) {
//If an error occurred, do not proceed,
//and redeposit the funds back into account 1.
return;
}
This code tries to withdraw funds from account 1. If a problem occurs, then the application exits, and no permanent operations occur. Otherwise, we try to deposit the funds into account 2. If a problem occurs here, we redeposit the money back into account 1 and exit the application.
There are many problems with this approach:
■■The code is bulky and unwieldy.
■■We need to consider every possible problem that occurs at every step of the way and code error-handling routines to consider how to roll back our changes.
Go back to the first page for a quick link to buy this book online!
Transactions 
 265
265
■■Error-handling gets out of control if we perform more complex processes than a simple withdrawal and a deposit. It is easy to imagine, for example, a 10-step process that updates several financial records. We’d need to code error-handling routines for each step. In the case of a problem, we need to code facilities to undo each operation. This gets very tricky and errorprone to write.
■■Testing this code is yet another challenge. You’d have to simulate logical problems as well as failures at many different levels.
Ideally, we would like a way to perform both operations in a single, large, atomic operation, with a guarantee that either both operations will either always succeed or both will always fail.
Network or Machine Failure
Let’s extend our classic bank account example and assume our bank account logic is distributed across a multi-tier deployment. This may be necessary for security, scalability, and modularization reasons. In a multi-tier deployment, any client code that wants to use our bank account application must do so across the network via a remote method invocation. We show this in Figure 10.1.
Distributing our application across the network introduces failure and reliability concerns. For example, what happens if the network crashes during a banking operation? Typically, an exception will be generated and thrown back to the client code—but this exception is quite ambiguous in nature. The network may have failed before money was withdrawn from an account. It’s also possible that the network failed after we withdrew the money. There’s no way to distinguish between these two cases—all the client code sees is a network failure exception. Thus, we can never know for sure how much money is in the bank account.
Bank Application
(with GUI)
Tier Boundary
Bank Logic
Implementation
Figure 10.1 A distributed banking application.
Go back to the first page for a quick link to buy this book online!

266 
 M A S T E R I N G E N T E R P R I S E J A V A B E A N S
M A S T E R I N G E N T E R P R I S E J A V A B E A N S
In fact, the network may not be the only source of problems. Because we’re dealing with bank account data, we’re dealing with persistent information residing in a database. It’s entirely feasible that the database itself could crash. The machine that the database is deployed on could also crash. If a crash occurs during a database write, the database could be in an inconsistent, corrupted state.
For a mission-critical enterprise application, none of these situations is acceptable. Mainframe systems and other highly available systems offer preventive measures to avoid system crashes. But in reality, nothing is perfect. Machines, processes, or networks will always fail. There needs to be a recovery process to handle these crashes.
Multiple Users Sharing Data
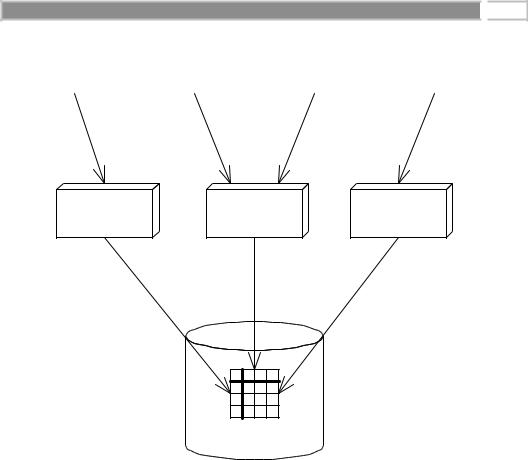
In any enterprise-level distributed system, you will see the familiar pattern of multiple clients connecting to multiple application servers, with those application servers maintaining some persistent data in a database. Let’s assume these application servers all share the same database, as in Figure 10.2. Because each server is tied to the same database image, servers could potentially be modifying the same set of data records within that database.
For example, you might have written a tool to maintain your company’s catalog of products in a database. Your catalog may contain product information that spans more than one database record. Information about a single product could span several database records or even tables.
It is conceivable that several people in your organization may need to use your tool simultaneously. But if two users modify the same product data simultaneously, their operations may become interleaved. Therefore, it is entirely possible that your database may contain product data that’s been partially supplied by one tool and partially supplied by another tool. This is essentially corrupted data, and it is not acceptable in any serious deployment. The wrong data in a bank account could result in millions of dollars in loss to a bank or the bank’s customers.
Thus, there needs to be a mechanism to deal with multiple users concurrently modifying data. We must guarantee that the many users concurrently updating data will not corrupt the data.
The Benefits of Transactions
The problems raised in the previous sections can lead to catastrophic errors. You can avoid these problems by properly using transactions.
Go back to the first page for a quick link to buy this book online!
Transactions 
 267
267
Client Code |
|
Client Code |
|
Client Code |
|
Client Code |
|
|
|
|
|
|
|
Application |
Application |
Application |
Server |
Server |
Server |
table
Database
Figure 10.2 Application servers tied to a single database.
A transaction is a series of operations that appear to execute as one large, atomic operation. Transactions guarantee an all-or-nothing value proposition: Either all of your operations will succeed, or none of them will. Transactions account for network or machine failure in a graceful, reliable way. Transactions allow multiple users to share the same data, and they guarantee that any set of data they update will be completely and wholly written, with no interleaving of updates from other clients.
By using transactions properly, you can enforce that multiuser interactions with databases (or other storages) occur independently. For example, if two clients are both reading and writing from the same database, they will be mutually exclusive if transactions are properly used. The database system will automatically perform the necessary concurrency control (i.e., locking) on the database to keep client threads from affecting each other.
Go back to the first page for a quick link to buy this book online!
268 
 M A S T E R I N G E N T E R P R I S E J A V A B E A N S
M A S T E R I N G E N T E R P R I S E J A V A B E A N S
Transaction Vocabulary
Before we get into the specifics of transactions, let’s get some vocabulary down. There are several types of participants in a transaction: transactional objects, transaction managers, resources, and resource managers. Let’s take a look at each of these parties in more detail.
A transactional object (or transactional component) is an application component, such as a banking component, that is involved in a transaction. This could be an enterprise bean, a Microsoft Transaction Server component, a CORBA component, and so on.
These components perform operations that need to execute in a robust fashion, such as database interactions.
A transaction manager is responsible for managing the transactional operations of the transactional components. It manages the entire overhead of a transaction, running behind the scenes to coordinate things (similar to how a conductor coordinates a symphony).
A resource is a persistent storage from which you read or write. A resource could be a database, a message queue, or other storage.
A resource manager manages a resource. An example of a resource manager is a driver for a relational database, object database, message queue, or other store. Resource managers are responsible for managing all state that is permanent. The most popular interface for resource managers is the X/Open XA resource manager interface. Most database drivers support this interface. Because X/Open XA is the de facto standard for resource managers, a deployment with heterogeneous resource managers from different vendors can interoperate.
As you will find out, transactions offer far more than simply letting simultaneous users use the same persistent stores. By having your operations run within a transaction, you are effectively performing an advanced form of concurrency control and exception handling.
The ACID Properties
When you properly use transactions, your operations will always execute with a suite of four guarantees. These four guarantees are well-known as the ACID properties of transactions. The word ACID stands for Atomicity, Consistency, Isolation, and Durability. Here’s the breakdown of each property:
Atomicity guarantees that many operations are bundled together and appear as one contiguous unit of work. In our banking example, when you transfer money from one bank account to another, you want to add funds to one account and remove funds from the other account, and you want both operations to occur
Go back to the first page for a quick link to buy this book online!

Transactions 
 269
269
or neither to occur. Atomicity guarantees that operations performed within a transaction undergo an all-or-nothing paradigm—either all the database updates are performed, or nothing happens if an error occurs at any time. Many different parties can participate in a transaction, such as an enterprise bean, a CORBA object, a servlet, and a database driver. These transaction participants can force the transaction to result in “nothing” happening for any reason. This is similar to a voting scheme—each transaction participant votes on whether the transaction should be successful, and if any vote “no” the transaction fails. If a transaction fails, all the partial database updates are automatically undone. In this way, you can think of transactions as a robust way of performing error handling.
Consistency guarantees that a transaction will leave the system’s state to be consistent after a transaction completes. What is a consistent system state? A bank system state could be consistent if the rule “bank account balances must always be positive” is always followed. This is an example of an invariant set of rules that define a consistent system state. During the course of a transaction, these rules may be violated, resulting in a temporarily inconsistent state. For example, your enterprise bean component may temporarily make your account balance negative during a withdrawal.When the transaction completes, the state is consistent once again. That is, your bean never leaves your account at a negative balance. And even though your state can be made inconsistent temporarily, this is not a problem. Remember that transactions execute atomically as one, contiguous unit of work (from the Atomicity property above). Thus, to a third party, it appears as though the system’s state is always consistent. Atomicity helps enforces that the system will always appear to be consistent.
Isolation protects concurrently executing transactions from seeing each other’s incomplete results. Isolation allows multiple transactions to read or write to a database without knowing about each other because each transaction is isolated from the others. Without isolation, your application state may become inconsistent. This is very useful for multiple clients modifying a database at once. To each client, it appears as though he or she is the only client modifying the database at that time. The transaction system achieves Isolation by using low-level synchronization protocols on the underlying database data. This synchronization isolates the work of one transaction from another. During a transaction, locks on data are automatically assigned as necessary. If one transaction holds a lock on data, the lock prevents other concurrent transactions from interacting with that data until the lock is released. For example, if you write bank account data to a database, the transaction may obtain locks on the bank account record or table. The locks guarantee that, while the transaction is occurring, no other concurrent updates can interfere. This allows many users to modify the same set of database records simultaneously without concern for interleaving of database operations.
Go back to the first page for a quick link to buy this book online!