

Предварительный план комплексирования и отладки.
Содержание последующих стадий в основном совпадает с соответствующими процессами ЖЦ ПО [9]. Вообще технологические стадии выделяются исходя из соображений разумного и рационального планирования и организации работ. Возможный вариант взаимосвязи и стадий работ с процессами ЖЦ ПО показан на рис.5.3.

Рис. 5.3. Взаимосвязь между процессами и стадиями разработки в жизненном цикле программного обеспечения
7. Принцип модульного построения программ
 В
связи с ростом объема кода программ
встает вопрос о разбиении (декомпозиции)
программы на отдельные, функционально
независимые части, которые могут быть
написаны и отлажены раздельно. Для
современных ПС характерен принцип
модульного построения прикладных
программных комплексов. Это позволяет
в большой степени унифицировать модули,
их интерфейсы и протоколы взаимодействия
модулей и тем самым позволяют решать
задачи развития ПС путем замены отдельных
модулей без изменения других частей
системы. Развитие такого рода открытых
систем должно опираться на два существенных
принципа: переносимости, возможности
согласованной работы с другими удаленными
компонентами. По сути задача сводится
к максимально возможному повторному
использованию разработанных и
апробированных программных компонент
при изменении вычислительных аппаратных
платформ и их операционных систем. При
строгом соблюдении правил структурного
построения значительно облегчается
достижения высоких показателей
надежности, поскольку, с одной стороны,
сокращается число возможных ошибок, а,
с другой стороны, упрощается их диагностика
и локализация. При разработке структуры
компонент и ПС в целом необходимо
сформулировать приоритетные критерии
ее формирования. В зависимости от
особенностей предметной области
критериями могут являться: надежность
функционирования и безопасность
применения; эффективное использование
памяти или производительность реализующей
ЭВМ; трудоемкость или длительность
разработки; модифицируемость ПС и
обеспечение возможности изменения
состава и функций компонент с сохранением
принципов структурного построения и
качества базовых версий ПС. Следует
учитывать, что некоторая потеря гибкости
архитектуры ПС и некоторое возрастание
ресурсов, необходимых для реализации
ПС в соответствии с выбранными критериями,
как правило, полностью компенсируются
повышением надежности функционирования
и безопасности применения и меньшими
технико-экономическими затратами на
разработку.
В
связи с ростом объема кода программ
встает вопрос о разбиении (декомпозиции)
программы на отдельные, функционально
независимые части, которые могут быть
написаны и отлажены раздельно. Для
современных ПС характерен принцип
модульного построения прикладных
программных комплексов. Это позволяет
в большой степени унифицировать модули,
их интерфейсы и протоколы взаимодействия
модулей и тем самым позволяют решать
задачи развития ПС путем замены отдельных
модулей без изменения других частей
системы. Развитие такого рода открытых
систем должно опираться на два существенных
принципа: переносимости, возможности
согласованной работы с другими удаленными
компонентами. По сути задача сводится
к максимально возможному повторному
использованию разработанных и
апробированных программных компонент
при изменении вычислительных аппаратных
платформ и их операционных систем. При
строгом соблюдении правил структурного
построения значительно облегчается
достижения высоких показателей
надежности, поскольку, с одной стороны,
сокращается число возможных ошибок, а,
с другой стороны, упрощается их диагностика
и локализация. При разработке структуры
компонент и ПС в целом необходимо
сформулировать приоритетные критерии
ее формирования. В зависимости от
особенностей предметной области
критериями могут являться: надежность
функционирования и безопасность
применения; эффективное использование
памяти или производительность реализующей
ЭВМ; трудоемкость или длительность
разработки; модифицируемость ПС и
обеспечение возможности изменения
состава и функций компонент с сохранением
принципов структурного построения и
качества базовых версий ПС. Следует
учитывать, что некоторая потеря гибкости
архитектуры ПС и некоторое возрастание
ресурсов, необходимых для реализации
ПС в соответствии с выбранными критериями,
как правило, полностью компенсируются
повышением надежности функционирования
и безопасности применения и меньшими
технико-экономическими затратами на
разработку.
8. Основные показатели надежности невосстанавливаемых объектов (вероятность безотказной работы, средняя наработка до отказа, гамма-процентная наработка до отказа, интенсивность отказов)
Вероятность безотказной работы
Вероятность безотказной работы - это вероятность того, что в пределах заданий наработки отказ объекта не возникает. На практике этот показатель определяется статистической оценкой:
|
(2.1) |

где
 - число однотипных объектов (элементов),
поставленных на испытания (находящихся
под контролем); во время испытаний
отказавший объект не восстанавливается
и не заменяется исправным;
- число однотипных объектов (элементов),
поставленных на испытания (находящихся
под контролем); во время испытаний
отказавший объект не восстанавливается
и не заменяется исправным;
 - число отказавших объектов за время
- число отказавших объектов за время
 .
.
Из определения вероятности безотказной работы видно, что эта характеристика является функцией времени, причем она является убывающей функцией и может принимать значения от 1 до 0.
График вероятности безотказной работы объекта изображен на рис. 2.1.

Как видно из графика, функция
 характеризует изменение надежности во
времени и является достаточно наглядной
оценкой. Например, на испытания поставлено
1000 образцов однотипных элементов, то
есть
характеризует изменение надежности во
времени и является достаточно наглядной
оценкой. Например, на испытания поставлено
1000 образцов однотипных элементов, то
есть
 изоляторов.
изоляторов.
При испытании отказавшие элементы не
заменялись исправными. За время
отказало 10 изоляторов. Следовательно,
 и наша уверенность состоит в том, что
любой изолятор из данной выборки не
откажет за время
с вероятностью
.
и наша уверенность состоит в том, что
любой изолятор из данной выборки не
откажет за время
с вероятностью
.
Иногда практически целесообразно
пользоваться не вероятностью безотказной
работы, а вероятностью отказа
 .
Поскольку работоспособность и отказ
являются состояниями несовместимыми
и противоположными, то их вероятности
связаны зависимостью:
.
Поскольку работоспособность и отказ
являются состояниями несовместимыми
и противоположными, то их вероятности
связаны зависимостью:
|
(2.2) |

следовательно:

Если задать время Т, определяющее наработку объекта до отказа, то

то есть вероятность безотказной работы
- это вероятность того, что время
 от момента включения объекта до его
отказа будет больше или равно времени
,
в течение которого определяется
вероятность безотказной работы. Из
вышесказанного следует, что:
от момента включения объекта до его
отказа будет больше или равно времени
,
в течение которого определяется
вероятность безотказной работы. Из
вышесказанного следует, что:

Вероятность отказа есть функция
распределения времени работы
до отказа:  .
Статистическая оценка вероятности
отказа:
.
Статистическая оценка вероятности
отказа:
|
(2.3) |

Т.к. вероятность отказа есть функция распределения времени работы , что производная от вероятности отказа по времени есть плотность вероятности или дифференциальный закон распределения времени работы объекта до отказа
|
(2.4) |

Полученная математическая связь позволяет записать:

Таким образом, зная плотность вероятности
 ,
легко найти искомую величину
,
легко найти искомую величину
 .
.
На практике достаточно часто приходится
определять условную вероятность
безотказной работы объекта в заданном
интервале времени
 при условии, что в момент времени
при условии, что в момент времени
 объект работоспособен и известны
объект работоспособен и известны
 и
и .
На основании формулы вероятности
совместного появления двух зависимых
событий, определяемой произведением
вероятности одного из них на условную
вероятность другого, вычисленную при
условии, что первое событие уже наступило,
запишем:
.
На основании формулы вероятности
совместного появления двух зависимых
событий, определяемой произведением
вероятности одного из них на условную
вероятность другого, вычисленную при
условии, что первое событие уже наступило,
запишем:

Отсюда:
|
(2.5) |

По известным статистическим данным можно записать:

где
 ,
,
 - число объектов, работоспособных к
моментам времени t1 и t2
соответственно.
- число объектов, работоспособных к
моментам времени t1 и t2
соответственно.


Отметим, что не всегда в качестве
наработки выступает время (в часах,
годах). К примеру, для оценки вероятности
безотказной работы коммутационных
аппаратов с большим количеством
переключений (вакуумный выключатель)
в качестве переменной величины наработки
целесообразно брать количество циклов
"включить" - "выключить". При
оценке надежности скользящих контактов
удобнее в качестве наработки брать
количество проходов токоприемника по
этому контакту, а при оценке надежности
движущихся объектов наработку
целесообразно брать в километрах
пробега. Суть математических выражений
оценки
 при
этом остается неизменной.
при
этом остается неизменной.
Средняя наработка до отказа
Средней наработкой до отказа
 называется среднее время работы до
отказа, т.е. математическое ожидание
наработки объекта до первого отказа.
называется среднее время работы до
отказа, т.е. математическое ожидание
наработки объекта до первого отказа.
Вероятностное определение средней наработки до отказа выражается так:

Используя известную связь между , запишем

Зная, что:

Получим:

Т.к. мы исследуем реальные объекты, то логично предположить, что начиная с какого-то момента времени вероятность безотказной работы системы будет равна 0, а, значит и

Учитывая, что

Получаем:
|
(2.6) |

Таким образом, средняя наработка до отказа равна площади, образованной кривой вероятности безотказной работы и осями координат. Статистическая оценка для средней наработки до отказа определяется по формуле:
|
(2.7) |

Где
- число работоспособных однотипных
невосстанавливаемых объектов при
 (в начале испытания);
(в начале испытания);
 – наработка до отказа -го объекта.
– наработка до отказа -го объекта.
Отметим, что, как и в случае с определением , средняя наработка до отказа может оцениваться не только в часах (годах), но и в циклах, километрах пробега и другими аргументами.
Интенсивность отказов
Интенсивность отказов - это условная плотность вероятности возникновения отказа объекта, определяемая при условии, что до рассматриваемого момента времени отказ не наступил. Из вероятностного определения следует, что
|
(2.8) |

Статистическая оценка интенсивности отказов имеет вид :
|
(2.9) |

 – число отказов однотипных объектов
на интервале
– число отказов однотипных объектов
на интервале
 ,
для которого определяется
,
для которого определяется
 .
.

– число отказов к моменту времени .
 – среднее число работоспособных объектов
на интервале
.
– среднее число работоспособных объектов
на интервале
.

 – число работоспособных объектов в
момент времени
.
– число работоспособных объектов в
момент времени
.


Где – число объектов, поставленных на испытания.
Посмотрим, что получится, если устремить
к нулю ( ).
).
Умножим числитель и знаменатель в формуле (2.9) на .

Перейдём к пределу. Учтём, что:





Таким образом, мы получили из статистической оценки (2.9) формулу (2.8) для интенсивности потока отказов.
Проинтегрируем выражение:

Получим:

Отсюда:
|
(2.11) |

Выражение (2.11) показывает связь
 и
.
Из этой связи ясно видно, что по
аналитически заданной функции
легко определить
и
:
и
.
Из этой связи ясно видно, что по
аналитически заданной функции
легко определить
и
:
|
(2.12) |

Если при статистической оценке время эксперимента разбить на достаточно большое количество одинаковых интервалов за длительный срок, то результатом обработки опытных данных будет график, изображенный на рис. 2.3.

Как показывают многочисленные данные
анализа надежности большинства объектов
техники, в том числе и электроустановок,
линеаризованная обобщенная зависимость
представляет собой сложную кривую с
тремя характерными интервалами (I, II,
III). На интервале II

 .
Этот интервал может составлять более
10 лет, он связан с нормальной эксплуатацией
объектов. Интервал I
.
Этот интервал может составлять более
10 лет, он связан с нормальной эксплуатацией
объектов. Интервал I
 часто называют периодом приработки
элементов. Он может увеличиваться или
уменьшаться в зависимости от уровня
организации отбраковки элементов на
заводе-изготовителе, где элементы с
внутренними дефектами своевременно
изымаются из партии выпускаемой
продукции. Величина интенсивности
отказов на этом интервале во многом
зависит от качества сборки схем сложных
устройств, соблюдения требований монтажа
и т.п. Включение под нагрузку собранных
схем приводит к быстрому "выжиганию"
дефектных элементов и по истечении
некоторого времени t1 в схеме
остаются только исправные элементы, и
их эксплуатация связана c
.
На интервале III
часто называют периодом приработки
элементов. Он может увеличиваться или
уменьшаться в зависимости от уровня
организации отбраковки элементов на
заводе-изготовителе, где элементы с
внутренними дефектами своевременно
изымаются из партии выпускаемой
продукции. Величина интенсивности
отказов на этом интервале во многом
зависит от качества сборки схем сложных
устройств, соблюдения требований монтажа
и т.п. Включение под нагрузку собранных
схем приводит к быстрому "выжиганию"
дефектных элементов и по истечении
некоторого времени t1 в схеме
остаются только исправные элементы, и
их эксплуатация связана c
.
На интервале III
 по причинам, обусловленным естественными
процессами старения, изнашивания,
коррозии и т.д., интенсивность отказов
резко возрастает, увеличивается число
деградационных отказов. Для того, чтобы
обеспечить
необходимо заменить неремонтируемые
элементы на исправные новые или
работоспособные, отработавшие время
по причинам, обусловленным естественными
процессами старения, изнашивания,
коррозии и т.д., интенсивность отказов
резко возрастает, увеличивается число
деградационных отказов. Для того, чтобы
обеспечить
необходимо заменить неремонтируемые
элементы на исправные новые или
работоспособные, отработавшие время
 .
Интервал
соответствует экспоненциальной модели
распределения вероятности безотказной
работы. Эта модель подробно проанализирована
в подразделе 3.2. Здесь же отметим, что
при
значительно упрощается расчет надежности
и
.
Интервал
соответствует экспоненциальной модели
распределения вероятности безотказной
работы. Эта модель подробно проанализирована
в подразделе 3.2. Здесь же отметим, что
при
значительно упрощается расчет надежности
и
 наиболее часто используется как исходный
показатель надежности элемента.
наиболее часто используется как исходный
показатель надежности элемента.
Средняя наработка на отказ
Этот показатель относится к восстанавливаемым объектам, при эксплуатации которых допускаются многократно повторяющиеся отказы. Эксплуатация таких объектов может быть описана следующим образом: в начальный момент времени объект начинает работу и продолжает работу до первого отказа; после отказа происходит восстановление работоспособности, и объект вновь работает до отказа и т.д. На оси времени моменты отказов образуют поток отказов, а моменты восстановлений – поток восстановлений.
Средняя наработка на отказ объекта (наработка на отказ) определяется как отношение суммарной наработки восстанавливаемого объекта к числу отказов, происшедших за суммарную наработку:
|
(2.13) |

где
 наработка между
наработка между
 -ым
и -ым отказами (время которое объект
проработал без отказов);
– суммарное число отказов за время
.
-ым
и -ым отказами (время которое объект
проработал без отказов);
– суммарное число отказов за время
.
9. Локальные и глобальные сети, их особенности, отличия, тенденции к сближению
Для классификации компьютерных сетей используются различные признаки, но чаще всего сети делят на типы по территориальному признаку, то есть по величине территории, которую покрывает сеть. И для этого есть веские причины, так как отличия технологий локальных и глобальных сетей очень значительны, несмотря на их постоянное сближение.
1.4.1. Особенности локальных, глобальных и городских сетей
К локальным сетям - Local Area Networks (LAN) - относят сети компьютеров, сосредоточенные на небольшой территории (обычно в радиусе не более 1-2 км). В общем случае локальная сеть представляет собой коммуникационную систему, принадлежащую одной организации. Из-за коротких расстояний в локальных сетях имеется возможность использования относительно дорогих высококачественных линий связи, которые позволяют, применяя простые методы передачи данных, достигать высоких скоростей обмена данными порядка 100 Мбит/с. В связи с этим услуги, предоставляемые локальными сетями, отличаются широким разнообразием и обычно предусматривают реализацию в режиме on-line. Глобальные сети - Wide Area Networks (WAN) - объединяют территориально рассредоточенные компьютеры, которые могут находиться в различных городах и странах. Так как прокладка высококачественных линий связи на большие расстояния обходится очень дорого, в глобальных сетях часто используются уже существующие линии связи, изначально предназначенные совсем для других целей. Например, многие глобальные сети строятся на основе телефонных и телеграфных каналов общего назначения. Из-за низких скоростей таких линий связи в глобальных сетях (десятки килобит в секунду) набор предоставляемых услуг обычно ограничивается передачей файлов, преимущественно не в оперативном, а в фоновом режиме, с использованием электронной почты. Для устойчивой передачи дискретных данных по некачественным линиям связи применяются методы и оборудование, существенно отличающиеся от методов и оборудования, характерных для локальных сетей. Как правило, здесь применяются сложные процедуры контроля и восстановления данных, так как наиболее типичный режим передачи данных по территориальному каналу связи связан со значительными искажениями сигналов. Городские сети (или сети мегаполисов) - Metropolitan Area Networks (MAN) - являются менее распространенным типом сетей. Эти сети появились сравнительно недавно. Они предназначены для обслуживания территории крупного города - мегаполиса. В то время как локальные сети наилучшим образом подходят для разделения ресурсов на коротких расстояниях и широковещательных передач, а глобальные сети обеспечивают работу на больших расстояниях, но с ограниченной скоростью и небогатым набором услуг, сети мегаполисов занимают некоторое промежуточное положение. Они используют цифровые магистральные линии связи, часто оптоволоконные, со скоростями от 45 Мбит/с, и предназначены для связи локальных сетей в масштабах города и соединения локальных сетей с глобальными. Эти сети первоначально были разработаны для передачи данных, но сейчас они поддерживают и такие услуги, как видеоконференции и интегральную передачу голоса и текста. Развитие технологии сетей мегаполисов осуществлялось местными телефонными компаниями. Исторически сложилось так, что местные телефонные компании всегда обладали слабыми техническими возможностями и из-за этого не могли привлечь крупных клиентов. Чтобы преодолеть свою отсталость и занять достойное место в мире локальных и глобальных сетей, местные предприятия связи занялись разработкой сетей на основе самых современных технологий, например технологии коммутации ячеек SMDS или ATM. Сети мегаполисов являются общественными сетями, и поэтому их услуги обходятся дешевле, чем построение собственной (частной) сети в пределах города.
1.4.2. Отличия локальных сетей от глобальных
Рассмотрим основные отличия локальных сетей от глобальных более детально. Так как в последнее время эти отличия становятся все менее заметными, то будем считать, что в данном разделе мы рассматриваем сети конца 80-х годов, когда эти отличия проявлялись весьма отчетливо, а современные тенденции сближения технологий локальных и глобальных сетей будут рассмотрены в следующем разделе.
Протяженность, качество и способ прокладки линий связи. Класс локальных вычислительных сетей по определению отличается от класса глобальных сетей небольшим расстоянием между узлами сети. Это в принципе делает возможным использование в локальных сетях качественных линий связи: коаксиального кабеля, витой пары, оптоволоконного кабеля, которые не всегда доступны (из-за экономических ограничений) на больших расстояниях, свойственных глобальным сетям. В глобальных сетях часто применяются уже существующие линии связи (телеграфные или телефонные), а в локальных сетях они прокладываются заново.
Сложность методов передачи и оборудования. В условиях низкой надежности физических каналов в глобальных сетях требуются более сложные, чем в локальных сетях, методы передачи данных и соответствующее оборудование. Так, в глобальных сетях широко применяются модуляция, асинхронные методы, сложные методы контрольного суммирования, квитирование и повторные передачи искаженных кадров. С другой стороны, качественные линии связи в локальных сетях позволили упростить процедуры передачи данных за счет применения немодулированных сигналов и отказа от обязательного подтверждения получения пакета.
Скорость обмена данными. Одним из главных отличий локальных сетей от глобальных является наличие высокоскоростных каналов обмена данными между компьютерами, скорость которых (10, 16 и 100 Мбит/с) сравнима со скоростями работы устройств и узлов компьютера - дисков, внутренних шин обмена данными и т. п. За счет этого у пользователя локальной сети, подключенного к удаленному разделяемому ресурсу (например, диску сервера), складывается впечатление, что он пользуется этим диском, как "своим". Для глобальных сетей типичны гораздо более низкие скорости передачи данных - 2400, 9600, 28800, 33600 бит/с, 56 и 64 Кбит/с и только на магистральных каналах - до 2 Мбит/с.
Разнообразие услуг. Локальные сети предоставляют, как правило, широкий набор услуг - это различные виды услуг файловой службы, услуги печати, услуги службы передачи факсимильных сообщений, услуги баз данных, электронная почта и другие, в то время как глобальные сети в основном предоставляют почтовые услуги и иногда файловые услуги с ограниченными возможностями - передачу файлов из публичных архивов удаленных серверов без предварительного просмотра их содержания.
Оперативность выполнения запросов. Время прохождения пакета через локальную сеть обычно составляет несколько миллисекунд, время же его передачи через глобальную сеть может достигать нескольких секунд. Низкая скорость передачи данных в глобальных сетях затрудняет реализацию служб для режима on-line, который является обычным для локальных сетей.
Разделение каналов. В локальных сетях каналы связи используются, как правило, совместно сразу несколькими узлами сети, а в глобальных сетях - индивидуально.
Использование метода коммутации пакетов. Важной особенностью локальных сетей является неравномерное распределение нагрузки. Отношение пиковой нагрузки к средней может составлять 100:1 и даже выше. Такой трафик обычно называют пульсирующим. Из-за этой особенности трафика в локальных сетях для связи узлов применяется метод коммутации пакетов, который для пульсирующего трафика оказывается гораздо более эффективным, чем традиционный для глобальных сетей метод коммутации каналов. Эффективность метода коммутации пакетов состоит в том, что сеть в целом передает в единицу времени больше данных своих абонентов. В глобальных сетях метод коммутации пакетов также используется, но наряду с ним часто применяется и метод коммутации каналов, а также некоммутируемые каналы - как унаследованные технологии некомпьютерных сетей.
Масштабируемость. "Классические" локальные сети обладают плохой масштабируемостью из-за жесткости базовых топологий, определяющих способ подключения станций и длину линии. При использовании многих базовых топологий характеристики сети резко ухудшаются при достижении определенного предела по количеству узлов или протяженности линий связи. Глобальным же сетям присуща хорошая масштабируемость, так как они изначально разрабатывались в расчете на работу с произвольными топологиями.
1.4.3. Тенденция к сближению локальных и глобальных сетей
Если принять во внимание все перечисленные выше различия локальных и глобальных сетей, то становится понятным, почему так долго могли существовать раздельно два сообщества специалистов, занимающиеся этими двумя видами сетей. Но за последние годы ситуация резко изменилась. Специалисты по локальным сетям, перед которыми встали задачи объединения нескольких локальных сетей, расположенных в разных, географически удаленных друг от друга пунктах, были вынуждены начать освоение чуждого для них мира глобальных сетей и телекоммуникаций. Тесная интеграция удаленных локальных сетей не позволяет рассматривать глобальные сети в виде "черного ящика", представляющего собой только инструмент транспортировки сообщений на большие расстояния. Поэтому все, что связано с глобальными связями и удаленным доступом, стало предметом повседневного интереса многих специалистов по локальным сетям. С другой стороны, стремление повысить пропускную способность, скорость передачи данных, расширить набор и оперативность служб, другими словами, стремление улучшить качество предоставляемых услуг - все это заставило специалистов по глобальным сетям обратить пристальное внимание на технологии, используемые в локальных сетях. Таким образом, в мире локальных и глобальных сетей явно наметилось движение навстречу друг другу, которое уже сегодня привело к значительному взаимопроникновению технологий локальных и глобальных сетей. Одним из проявлений этого сближения является появление сетей масштаба большого города (MAN), занимающих промежуточное положение между локальными и глобальными сетями. При достаточно больших расстояниях между узлами они обладают качественными линиями связи и высокими скоростями обмена, даже более высокими, чем в классических локальных сетях. Как и в случае локальных сетей, при построении MAN уже существующие линии связи не используются, а прокладываются заново. Сближение в методах передачи данных происходит на платформе оптической цифровой (немодулированной) передачи данных по оптоволоконным линиям связи. Из-за резкого улучшения качества каналов связи в глобальных сетях начали отказываться от сложных и избыточных процедур обеспечения корректности передачи данных. Примером могут служить сети frame relay. В этих сетях предполагается, что искажение бит происходит настолько редко, что ошибочный пакет просто уничтожается, а все проблемы, связанные с его потерей, решаются программами прикладного уровня, которые непосредственно не входят в состав сети frame relay. За счет новых сетевых технологий и, соответственно, нового оборудования, рассчитанного на более качественные линии связи, скорости передачи данных в уже существующих коммерческих глобальных сетях нового поколения приближаются к традиционным скоростям локальных сетей (в сетях frame relay сейчас доступны скорости 2 Мбит/с), а в глобальных сетях ATM и превосходят их, достигая 622 Мбит/с. В результате службы для режима on-line становятся обычными и в глобальных сетях. Наиболее яркий пример - гипертекстовая информационная служба World Wide Web, ставшая основным поставщиком информации в сети Internet. Ее интерактивные возможности превзошли возможности многих аналогичных служб локальных сетей, так что разработчикам локальных сетей пришлось просто позаимствовать эту службу у глобальных сетей. Процесс переноса служб и технологий из глобальных сетей в локальные приобрел такой массовый характер, что появился даже специальный термин - intranet-технологии (intra - внутренний), обозначающий применение служб внешних (глобальных) сетей во внутренних - локальных. Локальные сети перенимают у глобальных сетей и транспортные технологии. Все новые скоростные технологии (Fast Ethernet, Gigabit Ethernet, 100VG-AnyLAN) поддерживают работу по индивидуальным линиям связи наряду с традиционными для локальных сетей разделяемыми линиями. Для организации индивидуальных линий связи используется специальный тип коммуникационного оборудования - коммутаторы. Коммутаторы локальных сетей соединяются между собой по иерархической схеме, подобно тому, как это делается в телефонных сетях: имеются коммутаторы нижнего уровня, к которым непосредственно подключаются компьютеры сети, коммутаторы следующего уровня соединяют между собой коммутаторы нижнего уровня и т. д. Коммутаторы более высоких уровней обладают, как правило, большей производительностью и работают с более скоростными каналами, уплотняя данные нижних уровней. Коммутаторы поддерживают не только новые протоколы локальных сетей, но и традиционные - Ethernet и Token Ring. В локальных сетях в последнее время уделяется такое же большое внимание методам обеспечения защиты информации от несанкционированного доступа, как и в глобальных сетях. Такое внимание обусловлено тем, что локальные сети перестали быть изолированными, чаще всего они имеют выход в "большой мир" через глобальные связи. При этом часто используются те же методы - шифрование данных, аутентификация пользователей, возведение защитных барьеров, предохраняющих от проникновения в сеть извне. И наконец, появляются новые технологии, изначально предназначенные для обоих видов сетей. Наиболее ярким представителем нового поколения технологий является технология ATM, которая может служить основой не только локальных и глобальных компьютерных сетей, но и телефонных сетей, а также широковещательных видеосетей, объединяя все существующие типы трафика в одной транспортной сети.
Выводы
Классифицируя сети по территориальному признаку, различают локальные (LAN), глобальные (WAN) и городские (MAN) сети.
LAN - сосредоточены на территории не более 1-2 км; построены с использованием дорогих высококачественных линий связи, которые позволяют, применяя простые методы передачи данных, достигать высоких скоростей обмена данными порядка 100 Мбит/с. Предоставляемые услуги отличаются широким разнообразием и обычно предусматривают реализацию в режиме on-line.
WAN - объединяют компьютеры, рассредоточенные на расстоянии сотен и тысяч километров. Часто используются уже существующие не очень качественные линии связи. Более низкие, чем в локальных сетях, скорости передачи данных (десятки килобит в секунду) ограничивают набор предоставляемых услуг передачей файлов, преимущественно не в оперативном, а в фоновом режиме, с использованием электронной почты. Для устойчивой передачи дискретных данных применяются более сложные методы и оборудование, чем в локальных сетях.
MAN - занимают промежуточное положение между локальными и глобальными сетями. При достаточно больших расстояниях между узлами (десятки километров) они обладают качественными линиями связи и высокими скоростями обмена, иногда даже более высокими, чем в классических локальных сетях. Как и в случае локальных сетей, при построении MAN уже существующие линии связи не используются, а прокладываются заново.
10. Понятие об объектно-ориентированном программировании.
В середине 80-х годов в программировании возникло новое направление, основанное на понятие объекта. Реальные объекты окружающего мира обладают тремя базовыми характеристиками: они имеют набор свойств, способны разными методами изменять эти свойства и реагировать на события, возникающие как в окружающем мире, так и внутри самого объекта. Именно в таком виде в языках программирования и реализовано понятие объекта, как совокупности свойств (структур данных, характерных для этого объекта), методов их обработки (подпрограмм изменения свойств) и событий, на которые данный объект может реагировать и которые приводят, как правило, к изменению свойств объекта.
Объекты могут иметь идентичную структуру и отличаться только значениями свойств. В таких случаях в программе создается новый тип, основанный на единой структуре объекта. Он называется классом, а каждый конкретный объект, имеющий структуру этого класса, называется экземпляром класса. Объектно-ориентированный подход использует следующие базовые понятия: – объект – совокупность свойств (параметров) определенных сущностей и методов их обработки (программных средств) (объект содержит инструкции (программный код), определяющий действия, которые может выполнять объект, и обрабатываемые данные); – свойство объекта – характеристика объекта, его параметр; – метод обработки – программа действий над объектом или его свойствами; – событие – изменение состояния объекта; – класс объектов – совокупность объектов, характеризующихся общностью применяемых методов обработки или свойств. Объектно-ориентированный подход основан на трёх основополагающих концепциях: – инкапсуляция; – полиморфизм; – наследование. Рассмотрим эти концепции.
Важнейшая характеристика класса – возможность создания на его основе новых классов с наследованием всех его свойств и методов и добавлением собственных. Класс, не имеющий предшественника, называется базовым.
Например, класс «животное» имеет свойства «название», «размер», методы «идти» и «размножаться». Созданный на его основе класс «кошка» наследует все эти свойства и методы, к которым дополнительно добавляется свойство «окраска» и метод «пить».
Наследование позволяет создавать новые классы, повторно используя уже готовый исходный код и не тратя времени на его переписывание.
Таким образом, наследование – это процесс, посредством которого один объект может приобретать свойства другого. Точнее, объект может наследовать основные свойства другого объекта и добавлять к ним черты, характерные только для него. Наследование является важным, поскольку оно позволяет поддерживать концепцию иерархии классов. Например, подумайте об описании жилого дома. Дом – это часть общего класса, называемого строением. С другой стороны, строение – это часть более общего класса – конструкции, который является частью ещё более общего класса объектов, который можно назвать созданием рук человека. В каждом случае порождённый класс наследует все, связанные с родителем, качества и добавляет к ним свои собственные определяющие характеристики. Без использования иерархии классов, для каждого объекта пришлось бы задать все характеристики, которые бы исчерпывающи его определяли. Однако при использовании наследования можно описать объект путём определения того общего класса (или классов), к которому он относится, с теми специальными чертами, которые делают объект уникальным.
Полиморфизм – это свойство, которое позволяет одно и то же имя использовать для решения двух или более схожих, но технически разных задач. Целью полиморфизма, применительно к объектно-ориентированному программированию, является использование одного имени для задания общих для класса действий. Выполнение каждого конкретного действия будет определяться типом данных.
Преимуществом полиморфизма является то, что он помогает снижать сложность программ, разрешая использование того же интерфейса для задания единого класса действий. Выбор же конкретного действия, в зависимости от ситуации, возлагается на компилятор.
Инкапсуляция – это механизм, который объединяет данные и код, манипулирующий этими данными, а также защищает и то, и другое от внешнего вмешательства или неправильного использования.
В объектно-ориентированном программировании код и данные могут быть объединены вместе; в этом случае говорят, что создаётся так называемый «чёрный ящик». Когда коды и данные объединяются таким способом, создаётся объект. Другими словами, объект – это то, что поддерживает инкапсуляцию. Внутри объекта коды и данные могут быть закрытыми. Закрытые коды или данные доступны только для других частей этого объекта.
Таким образом, закрытые коды и данные недоступны для тех частей программы, которые существуют вне объекта. Если коды и данные являются открытыми, то, несмотря на то, что они заданы внутри объекта, они доступны и для других частей программы. Характерной является ситуация, когда открытая часть объекта используется для того, чтобы обеспечить контролируемый интерфейс закрытых элементов объекта. На самом деле объект является переменной определённого пользователем типа. Может показаться странным, что объект, который объединяет коды и данные, можно рассматривать как переменную.
11. Комплексные показатели надежности
Коэффициент готовности
Процесс функционирования восстанавливаемого объекта можно представить как последовательность чередующихся интервалов работоспособности и восстановления (простоя).

Коэффициент готовности - это вероятность того, что объект окажется в работоспособном состоянии в произвольный момент времени, кроме планируемых периодов, в течение которых применение объекта по назначению не предусматривается. Этот показатель одновременно оценивает свойства работоспособности и ремонтопригодности объекта.
Для одного ремонтируемого объекта коэффициент готовности
|
(2.22) |
|
(2.23) |


Заметим, что из определения максимальный
коэффициент готовности равен 1
 .
.
Из выражения (2.23) видно, что коэффициент готовности объекта может быть повышен за счет увеличения наработки на отказ и уменьшения среднего времени восстановления. Для определения коэффициента готовности необходим достаточно длительный календарный срок функционирования объекта.
Зависимость коэффициента готовности
от времени восстановления затрудняет
оценку надежности объекта, так как по
 нельзя судить о времени непрерывной
работы до отказа. К примеру, для одного
и того же численного значения
можно иметь и малые интервалы
нельзя судить о времени непрерывной
работы до отказа. К примеру, для одного
и того же численного значения
можно иметь и малые интервалы  и
,
и значительно большие. Таким образом,
можно доказать, что на конкретном
интервале работоспособности вероятность
безотказной работы будет больше там,
где больше
,
хотя за этим интервалом может последовать
длительный интервал простоя
.
Коэффициент готовности является удобной
характеристикой для объектов, которые
предназначены для длительного
функционирования, а решают поставленную
задачу в течение короткого промежутка
времени (находятся в ждущем режиме),
например, релейная защита, контактная
сеть (особенно при относительно малых
размерах движения), сложная контрольная
аппаратура и т.д.
и
,
и значительно большие. Таким образом,
можно доказать, что на конкретном
интервале работоспособности вероятность
безотказной работы будет больше там,
где больше
,
хотя за этим интервалом может последовать
длительный интервал простоя
.
Коэффициент готовности является удобной
характеристикой для объектов, которые
предназначены для длительного
функционирования, а решают поставленную
задачу в течение короткого промежутка
времени (находятся в ждущем режиме),
например, релейная защита, контактная
сеть (особенно при относительно малых
размерах движения), сложная контрольная
аппаратура и т.д.
Коэффициент оперативной готовности
Коэффициент оперативной готовности
 определяется как вероятность того, что
объект окажется в работоспособном
состоянии в произвольный момент времени
(кроме планируемых периодов, в течение
которых применение объекта по назначению
не предусматривается) и, начиная с этого
момента, будет работать безотказно в
течение заданного интервала времени.
определяется как вероятность того, что
объект окажется в работоспособном
состоянии в произвольный момент времени
(кроме планируемых периодов, в течение
которых применение объекта по назначению
не предусматривается) и, начиная с этого
момента, будет работать безотказно в
течение заданного интервала времени.
Из вероятностного определения следует, что
|
(2.23) |

где – коэффициент готовности;
 – вероятность безотказной работы
объекта в течение времени
– вероятность безотказной работы
объекта в течение времени
 ,
необходимого для безотказного
использования по назначению.
,
необходимого для безотказного
использования по назначению.
Для часто используемого в расчетной
практике простейшего потока отказов,
когда
 ,
определяется выражением:
,
определяется выражением:

Коэффициент технического использования
Коэффициент технического использования
 равен отношению математического ожидания
суммарного времени пребывания объекта
в работоспособном состоянии за некоторый
период эксплуатации к математическому
ожиданию суммарного времени пребывания
объекта в работоспособном состоянии и
простоев, обусловленных техническим
обслуживанием и ремонтом за тот же
период эксплуатации:
равен отношению математического ожидания
суммарного времени пребывания объекта
в работоспособном состоянии за некоторый
период эксплуатации к математическому
ожиданию суммарного времени пребывания
объекта в работоспособном состоянии и
простоев, обусловленных техническим
обслуживанием и ремонтом за тот же
период эксплуатации:
|
(2.25) |

– время сохранения работоспособности в i-м цикле функционирования объекта;
– время восстановления (ремонта) после -го отказа объекта;
 – длительность выполнения -й профилактики,
требующей вывода объекта из работающего
состояния (использования по назначению);
– длительность выполнения -й профилактики,
требующей вывода объекта из работающего
состояния (использования по назначению);
 – число рабочих циклов за рассматриваемый
период эксплуатации;
– число рабочих циклов за рассматриваемый
период эксплуатации;
 – число отказов (восстановлений) за
рассматриваемый период;
– число отказов (восстановлений) за
рассматриваемый период;
 – число профилактик, требующих отключения
объекта в рассматриваемый период.
– число профилактик, требующих отключения
объекта в рассматриваемый период.
Как видно из выражения (2.25), коэффициент технического использования характеризует долю времени нахождения объекта в работоспособном состоянии относительно общей (календарной) продолжительности эксплуатации. Следовательно, отличается от тем, что при его определении учитывается все время вынужденных простоев, тогда как при определении время простоя, связанное с проведением профилактических работ, не учитывается.
Суммарное время вынужденного простоя объекта обычно включает время:
на поиск и устранение отказа;
на регулировку и настройку объекта после устранения отказа;
для простоя из-за отсутствия запасных элементов;
для профилактических работ.
В электроэнергетических объектах, к примеру, в трансформаторах, линиях электропередачи, шинах распределительных устройств и т.п., предусмотрены плановые отключения для проведения плановых ремонтов и технического обслуживания. Эти интервалы времени так же, как и интервалы, связанные с отключением по причине отказа, учитываются при определении анализируемых коэффициентов надежности.
В условиях эксплуатации на уровень надежности объектов большое влияние оказывают техническое обслуживание и ремонт.
ГОСТ 27.002-89 содержит кроме проанализированных здесь наиболее употребляемых показателей надежности и другие показатели:
среднюю трудоемкость восстановления
средний срок сохраняемости
гамма-процентный ресурс
гамма-процентное время восстановления
гамма-процентный срок сохраняемости и др.
При необходимости определения указанных показателей используются специальные методики, где процедура расчета основывается на тех же законах математической статистики и теории вероятностей, по которым определяются и более широко используемые показатели надежности.
12. Case-средства, их состав и назначение
CASE-средства, их назначение и применение, классификация и характеристики"
Рассмотрим особенности современных методов и средств проектирования информационных систем, основанных на использовании CASE-технологии 1. CASE-технологии Появлению CASE-технологии и CASE-средств предшествовали исследования в области методологии программирования. Программирование обрело черты системного подхода с разработкой и внедрением языков высокого уровня, методов структурного и модульного программирования, языков проектирования и средств их поддержки, формальных и неформальных языков описаний системных требований и спецификаций и т.д. Кроме того, появлению CASE-технологии способствовали и такие факторы, как: · подготовка аналитиков и программистов, восприимчивых к концепциям модульного и структурного программирования; · широкое внедрение и постоянный рост производительности компьютеров, позволившие использовать эффективные графические средства и автоматизировать большинство этапов проектирования; · внедрение сетевой технологии, предоставившей возможность объединения усилий отдельных исполнителей в единый процесс проектирования путем использования разделяемой базы данных, содержащей необходимую информацию о проекте. CASE-технология представляет собой методологию проектирования ИС, а также набор инструментальных средств, позволяющих в наглядной форме моделировать предметную область, анализировать эту модель на всех этапах разработки и сопровождения ИС и разрабатывать приложения в соответствии с информационными потребностями пользователей. Большинство существующих CASE-средств основано на методологиях структурного (в основном) или объектно-ориентированного анализа и проектирования, использующих спецификации в виде диаграмм или текстов для описания внешних требований, связей между моделями системы, динамики поведения системы и архитектуры программных средств. Согласно обзору передовых технологий (Survey of Advanced Technology), составленному фирмой Systems Development Inc. в 1996 г. по результатам анкетирования более 1000 американских фирм, CASE-технология в настоящее время попала в разряд наиболее стабильных информационных технологий (ее использовала половина всех опрошенных пользователей более чем в трети своих проектов, из них 85% завершились успешно). Однако, несмотря на все потенциальные возможности CASE-средств, существует множество примеров их неудачного внедрения, в результате которых CASE-средства становятся "полочным" ПО (shelfware). В связи с этим необходимо отметить следующее: · CASE-средства не обязательно дают немедленный эффект; он может быть получен только спустя какое-то время; · реальные затраты на внедрение CASE-средств обычно намного превышают затраты на их приобретение; · CASE-средства обеспечивают возможности для получения существенной выгоды только после успешного завершения процесса их внедрения. Ввиду разнообразной природы CASE-средств было бы ошибочно делать какие-либо безоговорочные утверждения относительно реального удовлетворения тех или иных ожиданий от их внедрения. Можно перечислить следующие факторы, усложняющие определение возможного эффекта от использования CASE-средств: · широкое разнообразие качества и возможностей CASE-средств; · относительно небольшое время использования CASE-средств в различных организациях и недостаток опыта их применения; · широкое разнообразие в практике внедрения различных организаций; · отсутствие детальных метрик и данных для уже выполненных и текущих проектов; · широкий диапазон предметных областей проектов; · различная степень интеграции CASE-средств в различных проектах. Вследствие этих сложностей доступная информация о реальных внедрениях крайне ограничена и противоречива. Она зависит от типа средств, характеристик проектов, уровня сопровождения и опыта пользователей. Некоторые аналитики полагают, что реальная выгода от использования некоторых типов CASE-средств может быть получена только после одно- или двухлетнего опыта. Другие полагают, что воздействие может реально проявиться в фазе эксплуатации жизненного цикла ИС, когда технологические улучшения могут привести к снижению эксплуатационных затрат. Для успешного внедрения CASE-средств организация должна обладать следующими качествами: · Технология. Понимание ограниченности существующих возможностей и способность принять новую технологию; · Культура. Готовность к внедрению новых процессов и взаимоотношений между разработчиками и пользователями; · Управление. Четкое руководство и организованность по отношению к наиболее важным этапам и процессам внедрения. Если организация не обладает хотя бы одним из перечисленных качеств, то внедрение CASE-средств может закончиться неудачей независимо от степени тщательности следования различным рекомендациям по внедрению. Для того, чтобы принять взвешенное решение относительно инвестиций в CASE-технологию, пользователи вынуждены производить оценку отдельных CASE-средств, опираясь на неполные и противоречивые данные. Эта проблема зачастую усугубляется недостаточным знанием всех возможных "подводных камней" использования CASE-средств. Среди наиболее важных проблем выделяются следующие: 1)достоверная оценка отдачи от инвестиций в CASE-средства затруднительна ввиду отсутствия приемлемых метрик и данных по проектам и процессам разработки ПО; 2)внедрение CASE-средств может представлять собой достаточно длительный процесс и может не принести немедленной отдачи. Возможно даже краткосрочное снижение продуктивности в результате усилий, затрачиваемых на внедрение. Вследствие этого руководство организации-пользователя может утратить интерес к CASE-средствам и прекратить поддержку их внедрения; 3) отсутствие полного соответствия между теми процессами и методами, которые поддерживаются CASE-средствами, и теми, которые используются в данной организации, может привести к дополнительным трудностям; 4)CASE-средства зачастую трудно использовать в комплексе с другими подобными средствами. Это объясняется как различными парадигмами, поддерживаемыми различными средствами, так и проблемами передачи данных и управления от одного средства к другому; 5)некоторые CASE-средства требуют слишком много усилий для того, чтобы оправдать их использование в небольшом проекте, при этом, тем не менее, можно извлечь выгоду из той дисциплины, к которой обязывает их применение; 6)негативное отношение персонала к внедрению новой CASE-технологии может быть главной причиной провала проекта. Пользователи CASE-средств должны быть готовы к необходимости долгосрочных затрат на эксплуатацию, частому появлению новых версий и возможному быстрому моральному старению средств, а также постоянным затратам на обучение и повышение квалификации персонала. Несмотря на все высказанные предостережения и некоторый пессимизм, грамотный и разумный подход к использованию CASE-средств может преодолеть все перечисленные трудности. Успешное внедрение CASE-средств должно обеспечить такие выгоды как: · высокий уровень технологической поддержки процессов разработки и сопровождения ПО; · положительное воздействие на некоторые или все из перечисленных факторов: производительность, качество продукции, соблюдение стандартов, документирование; · приемлемый уровень отдачи от инвестиций в CASE-средства. В заключение приведем примеры комплексов CASE-средств обеспечивающих поддержку полного ЖЦ ПО. Здесь хотелось бы еще раз отметить нецелесообразность сравнения отдельно взятых CASE-средств, поскольку ни одно из них не решает в целом все проблемы создания и сопровождения ПО. Это подтверждается также полным набором критериев оценки и выбора, которые затрагивают все этапы ЖЦ ПО. Сравниваться могут комплексы методологически и технологически согласованных инструментальных средств, поддерживающие полный ЖЦ ПО и обеспеченные необходимой технической и методической поддержкой со стороны фирм-поставщиков. По мнению автора, на сегодняшний день наиболее развитым из всех поставляемых в России комплексов такого рода является комплекс технологий и инструментальных средств создания ИС, основанный на методологии и технологии DATARUN. В состав комплекса входят следующие инструментальные средства:
Примерами других подобных комплексов являются:
ные);
новные) и Usoft Developer (альтернативное);
|
14. Устройства для организации локальных сетей (концентраторы и сетевые адаптеры)
3.2. Концентраторы и сетевые адаптеры
Концентраторы вместе с сетевыми адаптерами, а также кабельной системой представляют тот минимум оборудования, с помощью которого можно создать локальную сеть. Такая сеть будет представлять собой общую разделяемую среду. Понятно, что сеть не может быть слишком большой, так как при большом количестве узлов общая среда передачи данных быстро становится узким местом, снижающим производительность сети. Поэтому концентраторы и сетевые адаптеры позволяют строить небольшие базовые фрагменты сетей, которые затем должны объединяться друг с другом с помощью мостов, коммутаторов и маршрутизаторов.
3.2.1. Сетевые адаптеры
Функции и характеристики сетевых адаптеров
Сетевой адаптер (Network Interface Card, NIC) вместе со своим драйвером реализует второй, канальный уровень модели открытых систем в конечном узле сети -компьютере. Более точно, в сетевой операционной системе пара адаптер и драйвер выполняет только функции физического и МАС - уровней, в то время как LLC-уровень обычно реализуется модулем операционной системы, единым для всех драйверов и сетевых адаптеров. Собственно так оно и должно быть в соответствии с моделью стека протоколов IEEE 802. Например, в ОС Windows NT уровень LLC реализуется в модуле NDIS, общем для всех драйверов сетевых адаптеров, независимо от того, какую технологию поддерживает драйвер.
Сетевой адаптер совместно с драйвером выполняют две операции: передачу и прием кадра.
Передача кадра из компьютера в кабель состоит из перечисленных ниже этапов (некоторые могут отсутствовать, в зависимости от принятых методов кодирования),
Прием кадра данных LLC через межуровневый интерфейс вместе с адресной информацией МАС - уровня. Обычно взаимодействие между протоколами внутри компьютера происходит через буферы, расположенные в оперативной памяти. Данные для передачи в сеть помещаются в эти буферы протоколами верхних уровней, которые извлекают их из дисковой памяти либо из файлового кэша с помощью подсистемы ввода/вывода операционной системы.
Оформление кадра данных МАС - уровня, в который инкапсулируется кадр LLC (с отброшенными флагами 01111110). Заполнение адресов назначения и источника, вычисление контрольной суммы.
Формирование символов кодов при использовании избыточных кодов типа 4В/5В. Скрэмблирование кодов для получения более равномерного спектра сигналов. Этот этап используется не во всех протоколах - например, технология Ethernet 10 Мбит/с обходится без него.
Выдача сигналов в кабель в соответствии с принятым линейным кодом - манчестерским, NRZI, MLT-3 и т. п. Прием кадра из кабеля в компьютер включает следующие действия.
Прием из кабеля сигналов, кодирующих битовый поток.
Выделение сигналов на фоне шума. Эту операцию могут выполнять различные специализированные микросхемы или сигнальные процессоры DSP. В результате в приемнике адаптера образуется некоторая битовая последовательность, с большой степенью вероятности совпадающая с той, которая была послана передатчиком.
Если данные перед отправкой в кабель подвергались скрэмблированию, то они пропускаются через дескрэмблер, после чего в адаптере восстанавливаются символы кода, посланные передатчиком.
Проверка контрольной суммы кадра. Если она неверна, то кадр отбрасывается, а через межуровневый интерфейс наверх, протоколу LLC передается соответствующий код ошибки. Если контрольная сумма верна, то из МАС - кадра извлекается кадр LLC и передается через межуровневый интерфейс наверх, протоколу LLC. Кадр LLC помещается в буфер оперативной памяти.
Распределение обязанностей между сетевым адаптером и его драйвером стандартами не определяется, поэтому каждый производитель решает этот вопрос самостоятельно. Обычно сетевые адаптеры делятся на адаптеры для клиентских компьютеров и адаптеры для серверов.
В адаптерах для клиентских компьютеров значительная часть работы перекладывается на драйвер, тем самым адаптер оказывается проще и дешевле. Недостатком такого подхода является высокая степень загрузки центрального процессора компьютера рутинными работами по передаче кадров из оперативной памяти компьютера в сеть. Центральный процессор вынужден заниматься этой работой вместо выполнения прикладных задач пользователя.
Поэтому адаптеры, предназначенные для серверов, обычно снабжаются собственными процессорами, которые самостоятельно выполняют большую часть работы по передаче кадров из оперативной памяти в сеть и в обратном направлении. Примером такого адаптера может служить сетевой адаптер SMS EtherPower со встроенным процессором Intel i960.
В зависимости от того, какой протокол реализует адаптер, адаптеры делятся на Ethernet-адаптеры, Token Ring-адаптеры, FDDI-адаптеры и т. д. Так как протокол Fast Ethernet позволяет за счет процедуры автопереговоров автоматически выбрать скорость работы сетевого адаптера в зависимости от возможностей концентратора, то многие адаптеры Ethernet сегодня поддерживают две скорости работы и имеют в своем названии приставку 10/100. Это свойство некоторые производителиназывают авточувствительностью.
Сетевой адаптер перед установкой в компьютер необходимо конфигурировать. При конфигурировании адаптера обычно задаются номер прерывания IRQ, используемого адаптером, номер канала прямого доступа к памяти DMA (если адаптер поддерживает режим DMA) и базовый адрес портов ввода/вывода.
Если сетевой адаптер, аппаратура компьютера и операционная система поддерживают стандарт Plug-and-Play, то конфигурирование адаптера и его драйвера осуществляется автоматически. В противном случае нужно сначала сконфигурировать сетевой адаптер, а затем повторить параметры его конфигурации для драйвера. В общем случае, детали процедуры конфигурирования сетевого адаптера и его драйвера во многом зависят от производителя адаптера, а также от возможностей шины, для которой разработан адаптер.
Классификация сетевых адаптеров
В качестве примера классификации адаптеров используем подход фирмы 3Com, имеющей репутацию лидера в области адаптеров Ethernet. Фирма 3Com считает, что сетевые адаптеры Ethernet прошли в своем развитии три поколения.
Адаптеры первого поколения были выполнены на дискретных логических микросхемах, в результате чего обладали низкой надежностью. Они имели буферную память только на один кадр, что приводило к низкой производительности адаптера, так как все кадры передавались из компьютера в сеть или из сети в компьютер последовательно. Кроме этого, задание конфигурации адаптера первого поколения происходило вручную, с помощью перемычек. Для каждого типа адаптеров использовался свой драйвер, причем интерфейс между драйвером и сетевой операционной системой не был стандартизирован.
В сетевых адаптерах второго поколения для повышения производительности стали применять метод многокадровой буферизации. При этом следующий кадр загружается из памяти компьютера в буфер адаптера одновременно с передачей предыдущего кадра в сеть. В режиме приема, после того как адаптер полностью принял один кадр, он может начать передавать этот кадр из буфера в память компьютера одновременно с приемом другого кадра из сети.
В сетевых адаптерах второго поколения широко используются микросхемы с высокой степенью интеграции, что повышает надежность адаптеров. Кроме того, драйверы этих адаптеров основаны на стандартных спецификациях. Адаптеры второго поколения обычно поставляются с драйверами, работающими как в стандарте NDIS (спецификация интерфейса сетевого драйвера), разработанном фирмами 3Com и Microsoft и одобренном IBM, так и в стандарте ODI (интерфейс открытого драйвера), разработанном фирмой Novell.
В сетевых адаптерах третьего поколения (к ним фирма 3Com относит свои адаптеры семейства EtherLink III) осуществляется конвейерная схема обработки кадров. Она заключается в том, что процессы приема кадра из оперативной памяти компьютера и передачи его в сеть совмещаются во времени. Таким образом, после приема нескольких первых байт кадра начинается их передача. Это существенно (на 25-55 %) повышает производительность цепочки оперативная память -адаптер - физический канал - адаптер - оперативная память. Такая схема очень чувствительна к порогу начала передачи, то есть к количеству байт кадра, которое загружается в буфер адаптера перед началом передачи в сеть. Сетевой адаптер третьего поколения осуществляет самонастройку этого параметра путем анализа рабочей среды, а также методом расчета, без участия администратора сети. Самонастройка обеспечивает максимально возможную производительность для конкретного сочетания производительности внутренней шины компьютера, его системы прерываний и системы прямого доступа к памяти.
Адаптеры третьего поколения базируются на специализированных интегральных схемах (ASIC), что повышает производительность и надежность адаптера при одновременном снижении его стоимости. Компания 3Com назвала свою технологию конвейерной обработки кадров Parallel Tasking, другие компании также реализовали похожие схемы в своих адаптерах. Повышение производительности канала «адаптер-память» очень важно для повышения производительности сети в целом, так как производительность сложного маршрута обработки кадров, включающего, например, концентраторы, коммутаторы, маршрутизаторы, глобальные каналы связи и т. п., всегда определяется производительностью самого медленного элемента этого маршрута. Следовательно, если сетевой адаптер сервера или клиентского компьютера работает медленно, никакие быстрые коммутаторы не смогут повысить скорость работы сети.
Выпускаемые сегодня сетевые адаптеры можно отнести к четвертому поколению. В эти адаптеры обязательно входит ASIC, выполняющая функции МАС - уровня, а также большое количество высокоуровневых функций. В набор таких функций может входить поддержка агента удаленного мониторинга RMON, схема приоритезации кадров, функции дистанционного управления компьютером и т. п. В серверных вариантах адаптеров почти обязательно наличие мощного процессора, разгружающего центральный процессор. Примером сетевого адаптера четвертого поколения может служить адаптер компании 3Com Fast EtherLink XL 10/100.
3.2.2. Концентраторы
Основные и дополнительные функции концентраторов
Практически во всех современных технологиях локальных сетей определено устройство, которое имеет несколько равноправных названий - концентратор (concentrator), хаб (hub), повторитель (repeator). В зависимости от области применения этого устройства в значительной степени изменяется состав его функций и конструктивное исполнение. Неизменной остается только основная функция - это повторение кадра либо на всех портах (как определено в стандарте Ethernet), либо только на некоторых портах, в соответствии с алгоритмом, определенным соответствующим стандартом.
Концентратор обычно имеет несколько портов, к которым с помощью отдельных физических сегментов кабеля подключаются конечные узлы сети - компьютеры. Концентратор объединяет отдельные физические сегменты сети в единую разделяемую среду, доступ к которой осуществляется в соответствии с одним из рассмотренных протоколов локальных сетей - Ethernet, Token Ring и т. п. Так как логика доступа к разделяемой среде существенно зависит от технологии, то для каждого типа технологии выпускаются свои концентраторы - Ethernet; Token Ring;
FDDI и 100VG-AnyLAN. Для конкретного протокола иногда используется свое, узкоспециализированное название этого устройства, более точно отражающее его функции или же использующееся в силу традиций, например, для концентраторов Token Ring характерно название MSAU.
Каждый концентратор выполняет некоторую основную функцию, определенную в соответствующем протоколе той технологии, которую он поддерживает. Хотя эта функция достаточно детально определена в стандарте технологии, при ее реализации концентраторы разных производителей могут отличаться такими деталями, как количество портов, поддержка нескольких типов кабелей и т. п.
Кроме основной функции концентратор может выполнять некоторое количество дополнительных функций, которые либо в стандарте вообще не определены, либо являются факультативными. Например, концентратор Token Ring может выполнять функцию отключения некорректно работающих портов и перехода на резервное кольцо, хотя в стандарте такие его возможности не описаны. Концентратор оказался удобным устройством для выполнения дополнительных функций, облегчающих контроль и эксплуатацию сети.
Рассмотрим особенности реализации основной функции концентратора на примере концентраторов Ethernet.
В технологии Ethernet устройства, объединяющие несколько физических сегментов коаксиального кабеля в единую разделяемую среду, использовались давно и получили название «повторителей» по своей основной функции - повторению на всех своих портах сигналов, полученных на входе одного из портов. В сетях на основе коаксиального кабеля обычными являлись двухпортовые повторители, соединяющие только два сегмента кабеля, поэтому термин концентратор к ним обычно не применялся.
С появлением спецификации 10Base-T для витой пары повторитель стал неотъемлемой частью сети Ethernet, так как без него связь можно было организовать только между двумя узлами сети. Многопортовые повторители Ethernet на витой паре стали называть концентраторами или хабами, так как в одном устройстве действительно концентрировались связи между большим количеством узлов сети. Концентратор Ethernet обычно имеет от 8 до 72 портов, причем основная часть портов предназначена для подключения кабелей на витой паре. На рис. 3.5 показан типичный концентратор Ethernet, рассчитанный на образование небольших сегментов разделяемой среды. Он имеет 16 портов стандарта 10Base-T с разъемами RJ-45, а также один порт AUI для подключения внешнего трансивера. Обычно к этому порту подключается трансивер, работающий на коаксиал или оптоволокно. С помощью этого трансивера концентратор подключается к магистральному кабелю, соединяющему несколько концентраторов между собой, либо таким образом обеспечивается подключение станции, удаленной от концентратора более чем на 100 м.

Рис. 3.5. Концентратор Ethernet
Для соединения концентраторов технологии 10Base-T между собой в иерархическую систему коаксиальный или оптоволоконный кабель не обязателен, можно применять те же порты, что и для подключения конечных станций, с учетом одного обстоятельства. Дело в том, что обычный порт RJ-45, предназначенный для подключения сетевого адаптера и называемый MDI-X (кроссированный MDI), имеет инвертированную разводку контактов разъема, чтобы сетевой адаптер можно было подключить к концентратору с помощью стандартного соединительного кабеля, не кроссирующего контакты (рис. 3.6). В случае соединения концентраторов через стандартный порт MDI-X приходится использовать нестандартный кабель с перекрестным соединением пар. Поэтому некоторые изготовители снабжают концентратор выделенным портом MDI, в котором нет кроссирования пар. Таким образом, два концентратора можно соединить обычным некроссированным кабелем, если это делать через порт MDI-X одного концентратора и порт MDI второго. Чаще один порт концентратора может работать и как порт MDI-X, и как порт MDI, в зависимости от положения кнопочного переключателя, как это показано в нижней части рис. 3.6.
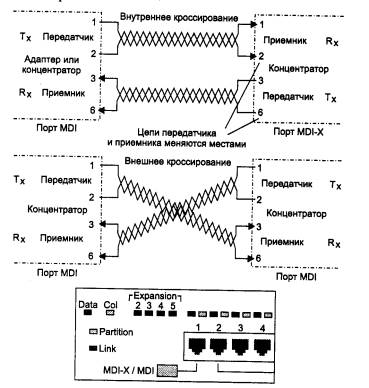
Рис. 3.6. Соединения типа «станция-концентратор» и «концентратор-концентратор» на витой паре
Многопортовый повторитель-концентратор Ethernet может по-разному рассматриваться при использовании правила 4-х хабов. В большинстве моделей все порты связаны с единственным блоком повторения, и при прохождении сигнала между двумя портами повторителя блок повторения вносит задержку всего один раз. Поэтому такой концентратор нужно считать одним повторителем с ограничениями, накладываемыми правилом 4-х хабов. Но существуют и другие модели повторителей, в которых на несколько портов имеется свой блок повторения. В таком случае каждый блок повторения нужно считать отдельным повторителем и учитывать его отдельно в правиле 4-х хабов.
Некоторые отличия могут демонстрировать модели концентраторов, работающие на одномодовый волоконно-оптический кабель. Дальность сегмента кабеля, поддерживаемого концентратором FDDI, на таком кабеле может значительно отличаться в зависимости от мощности лазерного излучателя - от 10 до 40 км.
Однако если существующие различия при выполнении основной функции концентраторов не столь велики, то их намного превосходит разброс в возможностях реализации концентраторами дополнительных функций.
Отключение портов
Очень полезной при эксплуатации сети является способность концентратора отключать некорректно работающие порты, изолируя тем самым остальную часть сети от возникших в узле проблем. Эту функцию называют автосегментацией (autopartitioning). Для концентратора FDDI эта функция для многих ошибочных ситуаций является основной, так как определена в протоколе. В то же время для концентратора Ethernet или Token Ring функция автосегментации для многих ситуаций является дополнительной, так как стандарт не описывает реакцию концентратора на эту ситуацию. Основной причиной отключения порта в стандартах Ethernet и Fast Ethernet является отсутствие ответа на последовательность импульсов link test, посылаемых во все порты каждые 16 мс. В этом случае неисправный порт переводится в состояние «отключен», но импульсы link test будут продолжать посылаться в порт с тем, чтобы при восстановлении устройства работа с ним была продолжена автоматически.
Рассмотрим ситуации, в которых концентраторы Ethernet и Fast Ethernet выполняют отключение порта.
Ошибки на уровне кадра. Если интенсивность прохождения через порт кадров, имеющих ошибки, превышает заданный порог, то порт отключается, а затем, при отсутствии ошибок в течение заданного времени, включается снова. Такими ошибками могут быть: неверная контрольная сумм, неверная длина кадра (больше 1518 байт или меньше 64 байт), неоформленный заголовок кадра.
Множественные коллизии. Если концентратор фиксирует, что источником коллизии был один и тот же порт 60 раз подряд, то порт отключается. Через некоторое время порт снова будет включен.
Затянувшаяся передача (jabber). Как и сетевой адаптер, концентратор контролирует время прохождения одного кадра через порт. Если это время превышает время передачи кадра максимальной длины в 3 раза, то порт отключается.
Поддержка резервных связей
Так как использование резервных связей в концентраторах определено только в стандарте FDDI, то для остальных стандартов разработчики концентраторов поддерживают такую функцию с помощью своих частных решений. Например, концентраторы Ethernet/Fast Ethernet могут образовывать только иерархические связи без петель. Поэтому резервные связи всегда должны соединять отключенные порты, чтобы не нарушать логику работы сети. Обычно при конфигурировании концентратора администратор должен определить, какие порты являются основными, а какие по отношению к ним - резервными (рис. 3.7). Если по какой-либо причине порт отключается (срабатывает механизм автосегментации), концентратор делает активным его резервный порт.
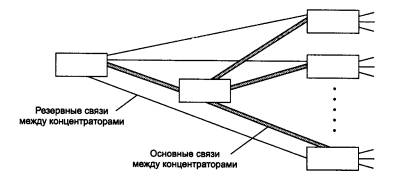
Рис. 3.7. Резервные связи между концентраторами Ethernet
В некоторых моделях концентраторов разрешается использовать механизм назначения резервных портов только для оптоволоконных портов, считая, что нужно резервировать только наиболее важные связи, которые обычно выполняются на оптическом кабеле. В других же моделях резервным можно сделать любой порт.
Защита от несанкционированного доступа
Разделяемая среда предоставляет очень удобную возможность для несанкционированного прослушивания сети и получения доступа к передаваемым данным. Для этого достаточно подключить компьютер с программным анализатором протоколов к свободному разъему концентратора, записать на диск весь проходящий по сети трафик, а затем выделить из него нужную информацию.
Разработчики концентраторов предоставляют некоторый способ защиты данных в разделяемых средах.
Наиболее простой способ - назначение разрешенных МАС - адресов портам концентратора. В стандартном концентраторе Ethernet порты МАС - адресов не имеют. Защита заключается в том, что администратор вручную связывает с каждым портом концентратора некоторый МАС - адрес. Этот МАС - адрес является адресом станции, которой разрешается подключаться к данному порту. Например, на рис. 3.8 первому порту концентратора назначен МАС - адрес 123 (условная запись). Компьютер с МАС - адресом 123 нормально работает с сетью через данный порт. Если злоумышленник отсоединяет этот компьютер и присоединяет вместо него свой, концентратор заметит, что при старте нового компьютера в сеть начали поступать кадры с адресом источника 789. Так как этот адрес является недопустимым для первого порта, то эти кадры фильтруются, порт отключается, а факт нарушения прав доступа может быть зафиксирован.

Рис. 3.8. Изоляция портов: передача кадров только от станций с фиксированными адресами
Заметим, что для реализации описанного метода защиты данных концентратор нужно предварительно сконфигурировать. Для этого концентратор должен иметь блок управления. Такие концентраторы обычно называют интеллектуальными. Блок управления представляет собой компактный вычислительный блок со встроенным программным обеспечением. Для взаимодействия администратора с блоком управления концентратор имеет консольный порт (чаще всего RS-232), к которому подключается терминал или персональный компьютер с программой эмуляции терминала. При присоединении терминала блок управления организует на его экране диалог, с помощью которого администратор вводит значения МАС - адресов. Блок управления может поддерживать и другие операции конфигурирования, например ручное отключение или включение портов и т. д. Для этого при подключении терминала блок управления выдает на экран некоторое меню, с помощью которого администратор выбирает нужное действие.
Другим способом защиты данных от несанкционированного доступа является их шифрация. Однако процесс истинной шифрации требует большой вычислительной мощности, и для повторителя, не буферизующего кадр, выполнить шифрацию «на лету» весьма сложно. Вместо этого в концентраторах применяется метод случайного искажения поля данных в пакетах, передаваемых портам с адресом, отличным от адреса назначения пакета. Этот метод сохраняет логику случайного доступа к среде, так как все станции видят занятость среды кадром информации, но только станция, которой послан этот кадр, может понять содержание поля данных кадра (рис. 3.9). Для реализации этого метода концентратор также нужно снабдить информацией о том, какие МАС - адреса имеют станции, подключенные к его портам. Обычно поле данных в кадрах, направляемых станциям, отличным от адресата, заполняется нулями.
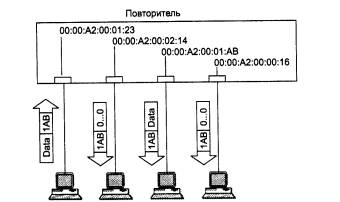
Рис. 3.9. Искажение поля данных в кадрах, не предназначенных для приема станциями
Многосегментные концентраторы
При рассмотрении некоторых моделей концентраторов возникает вопрос - зачем в этой модели имеется такое большое количество портов, например 192 или 240? Имеет ли смысл разделять среду в 10 или 16 Мбит/с между таким большим количеством станций? Возможно, десять - пятнадцать лет назад ответ в некоторых случаях мог бы быть и положительным, например, для тех сетей, в которых компьютеры пользовались сетью только для отправки небольших почтовых сообщений или для переписывания небольшого текстового файла. Сегодня таких сетей осталось крайне мало, и даже 5 компьютеров могут полностью загрузить сегмент Ethernet или Token Ring, a в некоторых случаях - и сегмент Fast Ethernet. Для чего же тогда нужен концентратор с большим количеством портов, если ими практически нельзя воспользоваться из-за ограничений по пропускной способности, приходящейся на одну станцию? Ответ состоит в том, что в таких концентраторах имеется несколько несвязанных внутренних шин, которые предназначены для создания нескольких разделяемых сред. Например, концентратор, изображенный на рис. 3.10, имеет три внутренние шины Ethernet. Если, например, в таком концентраторе 72 порта, то каждый из этих портов может быть связан с любой из трех внутренних шин. На рисунке первые два компьютера связаны с шиной Ethernet 3, а третий и четвертый компьютеры - с шиной Ethernet 1. Первые два компьютера образуют один разделяемый сегмент, а третий и четвертый - другой разделяемый сегмент.

Рис. 3.10. Многосегментный концентратор
Между собой компьютеры, подключенные к разным сегментам, общаться через концентратор не могут, так как шины внутри концентратора никак не связаны.
Многосегментные концентраторы нужны для создания разделяемых сегментов, состав которых может легко изменяться. Большинство многосегментных концентраторов, например System 5000 компании Nortel Networks или PortSwitch Hub компании 3Com, позволяют выполнять операцию соединения порта с одной из внутренних шин чисто программным способом, например с помощью локального конфигурирования через консольный порт, В результате администратор сети может присоединять компьютеры пользователей к любым портам концентратора, а затем с помощью программы конфигурирования концентратора управлять составом каждого сегмента. Если завтра сегмент 1 станет перегруженным, то его компьютеры можно распределить между оставшимися сегментами концентратора.
Возможность многосегментного концентратора программно изменять связи портов с внутренними шинами называетсяконфигурационной коммутацией (configuration switching).

ВНИМАНИЕ Конфигурационная коммутация не имеет ничего общего с коммутацией кадров, которую выполняют мосты и коммутаторы.
Многосегментные концентраторы - это программируемая основа больших сетей. Для соединения сегментов между собой нужны устройства другого типа - мосты/коммутаторы или маршрутизаторы. Такое межсетевое устройство должно подключаться к нескольким портам многосегментного концентратора, подсоединенным к разным внутренним шинам, и выполнять передачу кадров или пакетов между сегментами точно так же, как если бы они были образованы отдельными устройствами-концентраторами.
Для крупных сетей многосегментный концентратор играет роль интеллектуального кроссового шкафа, который выполняет новое соединение не за счет механического перемещения вилки кабеля в новый порт, а за счет программного изменения внутренней конфигурации устройства.
Управление концентратором по протоколу SNMP
Как видно из описания дополнительных функций, многие из них требуют конфигурирования концентратора. Это конфигурирование может производиться локально, через интерфейс RS-232C, который имеется у любого концентратора, имеющего блок управления. Кроме конфигурирования в большой сети очень полезна функция наблюдения за состоянием концентратора: работоспособен ли он, в каком состоянии находятся его порты.
При большом количестве концентраторов и других коммуникационных устройств в сети постоянное наблюдение за состоянием многочисленных портов и изменением их параметров становится очень обременительным занятием, если оно должно выполняться с помощью локального подключения терминала. Поэтому большинство концентраторов, поддерживающих интеллектуальные дополнительные функции, могут управляться централизованно по сети с помощью популярного протокола управления SNMP (Simple Network Management Protocol) из стека TCP/IP.
Упрощенная структура системы управления изображена на рис.3.11.
Рис. 3.11. Структура системы управления на основе протокола SNMP
В блок управления концентратором встраивается так называемый SNMP-агент. Этот агент собирает информацию о состоянии контролируемого устройства и хранит ее в так называемой базе данных управляющей информации - Management In formation Base, MIB. Эта база данных имеет стандартную структуру, что позволяет одному из компьютеров сети, выполняющему роль центральной станции управления, запрашивать у агента значения стандартных переменных базы MIB. В базе MIB хранятся не только данные о состоянии устройства, но и управляющая информация, воздействующая на это устройство. Например, в MIB есть переменная, управляющая состоянием порта, имеющая значения «включить» и «выключить». Если станция управления меняет значение управляющей переменной, то агент должен выполнить это указание и воздействовать на устройство соответствующим образом, например выключить порт или изменить связь порта с внутренними шинами концентратора.
Взаимодействие между станцией управления (по-другому - менеджером системы управления) и встроенными в коммуникационные устройства агентами происходит по протоколу SNMP. Концентратор, который управляется по протоколу SNMP, должен поддерживать основные протоколы стека TCP/IP и иметь IP- и МАС - адреса. Точнее, эти адреса относятся к агенту концентратора. Поэтому администратор, который хочет воспользоваться преимуществами централизованного управления концентраторами по сети, должен знать стек протоколов TCP/IP и сконфигурировать IP-адреса их агентов.
Конструктивное исполнение концентраторов
На конструктивное устройство концентраторов большое влияние оказывает их область применения. Концентраторы рабочих групп чаще всего выпускаются как устройства с фиксированным количеством портов, корпоративные концентраторы - как модульные устройства на основе шасси, а концентраторы отделов могут иметь стековую конструкцию. Такое деление не является жестким, и в качестве корпоративного концентратора может использоваться, например, модульный концентратор.
Концентратор с фиксированным количеством портов - это наиболее простое конструктивное исполнение, когда устройство представляет собой отдельный корпус со всеми необходимыми элементами (портами, органами индикации и управления, блоком питания), и эти элементы заменять нельзя. Обычно все порты такого концентратора поддерживают одну среду передачи, общее количество портов изменяется от 4-8 до 24. Один порт может быть специально выделен для подключения концентратора к магистрали сети или же для объединения концентраторов (в качестве такого порта часто используется порт с интерфейсом AUI, в этом случае применение соответствующего трансивера позволяет подключить концентратор к практически любой физической среде передачи данных).
Модульный концентратор выполняется в виде отдельных модулей с фиксированным количеством портов, устанавливаемых на общее шасси. Шасси имеет внутреннюю шину для объединения отдельных модулей в единый повторитель. Часто такие концентраторы являются многосегментными, тогда в пределах одного модульного концентратора работает несколько несвязанных между собой повторителей. Для модульного концентратора могут существовать различные типы модулей, отличающиеся количеством портов и типом поддерживаемой физической среды. Часто агент протокола SNMP выполняется в виде отдельного модуля, при установке которого концентратор превращается в интеллектуальное устройство. Модульные концентраторы позволяют более точно подобрать необходимую для конкретного применения конфигурацию концентратора, а также гибко и с минимальными затратами реагировать на изменения конфигурации сети.
Ввиду ответственной работы, которую выполняют корпоративные модульные концентраторы, они снабжаются модулем управления, системой терморегулирования, избыточными источниками питания и возможностью замены модулей «на ходу».
Недостатком концентратора на основе шасси является высокая начальная стоимость такого устройства для случая, когда предприятию на первом этапе создания сети нужно установить всего 1-2 модуля. Высокая стоимость шасси вызвана тем, что оно поставляется вместе со всеми общими устройствами, такими как избыточные источники питания и т. п. Поэтому для сетей средних размеров большую популярность завоевали стековые концентраторы.
Стековый концентратор, как и концентратор с фиксированным числом портов, выполнен в виде отдельного корпуса без возможности замены отдельных его модулей. Типичный вид нескольких стековых концентраторов Ethernet показан на рис. 3.12. Однако стековыми эти концентраторы называются не потому, что они устанавливаются один на другой. Такая чисто конструктивная деталь вряд ли удостоилась бы особого внимания, так как установка нескольких устройств одинаковых габаритных размеров в общую стойку практикуется очень давно. Стековые концентраторы имеют специальные порты и кабели для объединения нескольких таких корпусов в единый повторитель (рис. 3.13), который имеет общий блок повторения, обеспечивает общую ресинхронизацию сигналов для всех своих портов и поэтому с точки зрения правила 4-х хабов считается одним повторителем.

Рис. 3.12. Стековые концентраторы Ethernet
Рис. 3.13. Объединение стековых концентраторов в единое устройство с помощью специальных разъемов на задней панели
Если стековые концентраторы имеют несколько внутренних шин, то при соединении в стек эти шины объединяются и становятся общими для всех устройств стека. Число объединяемых в стек корпусов может быть достаточно большим (обычно до 8, но бывает и больше). Стековые концентраторы могут поддерживать различные физические среды передачи, что делает их почти такими же гибкими, как и модульные концентраторы, но при этом стоимость этих устройств в расчете на один порт получается обычно ниже, так как сначала предприятие может купить одно устройство без избыточного шасси, а потом нарастить стек еще несколькими аналогичными устройствами.
Стековые концентраторы, выпускаемые одним производителем, выполняются в едином конструктивном стандарте, что позволяет легко устанавливать их друг на друга, образуя единое настольное устройство, или помещать их в общую стойку. Экономия при организации стека происходит еще и за счет единого для всех устройств стека модуля SNMP-управления (который вставляется в один из корпусов стека как дополнительный модуль), а также общего избыточного источника питания.
Модульно-стековые концентраторы представляют собой модульные концентраторы, объединенные специальными связями в стек. Как правило, корпуса таких концентраторов рассчитаны на небольшое количество модулей (1-3). Эти концентраторы сочетают достоинства концентраторов обоих типов.
Выводы
От производительности сетевых адаптеров зависит производительность любой сложной сети, так как данные всегда проходят не только через коммутаторы и маршрутизаторы сети, но и через адаптеры компьютеров, а результирующая производительность последовательно соединенных устройств определяется производительностью самого медленного устройства.
Сетевые адаптеры характеризуются типом поддерживаемого протокола, производительностью, шиной компьютера, к которой они могут присоединяться, типом приемопередатчика, а также наличием собственного процессора, разгружающего центральный процессор компьютера от рутинной работы.
Сетевые адаптеры для серверов обычно имеют собственный процессор, а клиентские сетевые адаптеры - нет.
Современные адаптеры умеют адаптироваться к временным параметрам шины и оперативной памяти компьютера для повышения производительности обмена «сеть-компьютер».
Концентраторы, кроме основной функции протокола (побитного повторения кадра на всех или последующем порту), всегда выполняют ряд полезных дополнительных функций, определяемых производителем концентратора.
Автосегментация - одна из важнейших дополнительных функций, с помощью которой концентратор отключает порт при обнаружении разнообразных проблем с кабелем и конечным узлом, подключенным к данному порту.
В число дополнительных функций входят функции защиты сети от несанкционированного доступа, запрещающие подключение к концентратору компьютеров с неизвестными МАС - адресами, а также заполняющие нулями поля данных кадров, поступающих не к станции назначения.
Стековые концентраторы сочетают преимущества модульных концентраторов и концентраторов с фиксированным количеством портов.
Многосегментные концентраторы позволяют делить сеть на сегменты программным способом, без физической перекоммутации устройств.
Сложные концентраторы, выполняющие дополнительные функции, обычно могут управляться централизованно по сети по протоколу SNMP.
15. Избыточность как метод повышения надежности асоиу. Структурная, информационная и временная избыточность
В процессе функционирования ПС (особенно если это происходит в режиме реального времени) необходимо максимально быстро обнаруживать искажения и как можно быстрее восстанавливать нормальное функционирование ПС. Поскольку при создании сложных ПС ошибки неизбежны и, кроме того, возможны искажения исходных данных и аппаратные сбои, необходима регулярная автоматическая проверка исполнения программ и сохранности данных.
Достигается же задача максимально быстрого восстановления и ограничения последствий дефектов путем введения избыточности. Выше мы говорили о различных видах избыточности, относящейся к аппаратным средствам. Рассмотрим теперь виды избыточности для ПС.
Временная избыточность состоит в том, что некоторая часть производительности ЭВМ используется для контроля исполнения программ и восстановления (рестарта) вычислительного процесса. Для этого при проектировании ИС предусматривается запас производительности, который затем будет использоваться на контроль и оперативное повышение надежности функционирования. В зависимости от требований к надежности функционирования систем величина временной избыточности может колебаться от 5-10% производительности (для однопроцессорной ЭВМ) до трех, четырехкратного дублирования производительности отдельной машины в мажоритарных вычислительных комплексах.
Временная избыточность используется на контроль и обнаружение искажений, их диагностику, восстановление.
Информационная избыточность состоит в дублировании исходных и промежуточных данных, обрабатываемых программами. Избыточность используется для сохранения достоверности данных, поскольку они в наибольшей степени влияют на функционирование программ и требуют значительного времени для восстановления. Такие данные обычно характеризуют некоторые сведения о внешнем управляемом процессе, и в случае их разрушения процесс обработки информации внешних объектов может прерваться. Обычно важные данные защищают двух-трехкратным дублированием и периодическим обновлением. В некоторых случаях информационная избыточность позволяет не только обнаружить искажение данных, но и исправить в них ошибку (кодирование). Менее важные данные защищают помехоустойчивыми кодами, которые позволяют только обнаружить ошибку, а данные, которые часто обновляются и слабо влияют на вычислительный процесс могут вообще не иметь информационной избыточности.
16. Основные технологии локальных сетей Ethernet и Token Ring
Технология Ethernet
Ethernet – это самый распространенный на сегодняшний день стандарт локальных сетей [3].
Ethernet – это сетевой стандарт, основанный на экспериментальной сети Ethernet Network, которую фирма Xerox разработала и реализовала в 1975 году.
В 1980 году фирмы DEC, Intel и Xerox совместно разработали и опубликовали стандарт Ethernet версии II для сети, построенной на основе коаксиального кабеля, который стал последней версией фирменного стандарта Ethernet. Поэтому фирменную версию стандарта Ethernet называют стандартом Ethernet DIX, или Ethernet II, на основе которых был разработан стандарт IEEE 802.3.
На основе стандарта Ethernet были приняты дополнительные стандарты: в 1995 году Fast Ethernet (дополнение к IEEE 802.3), в 1998 году Gigabit Ethernet (раздел IEEE 802.3z основного документа), которые во многом не являются самостоятельными стандартами.
Для передачи двоичной информации по кабелю для всех вариантов физического уровня технологии Ethernet, обеспечивающих пропускную способность 10 Мбит/с, используется манчестерский код (рис. 3.9).
В манчестерском коде для кодирования единиц и нулей используется перепад потенциала, то есть фронт импульса. При манчестерском кодировании каждый такт делится на две части. Информация кодируется перепадами потенциала, происходящими в середине каждого такта. Единица кодируется перепадом от низкого уровня сигнала к высокому (передним фронтом импульса), а ноль ‑ обратным перепадом (задним фронтом).
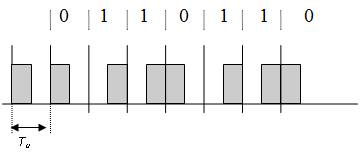
Рис. 3.9. Дифференциальное манчестерское кодирование
В стандарте Ethernet (в том числе Fast Ethernet и Gigabit Ethernet) используется один и тот же метод разделения среды передачи данных ‑ метод CSMA/CD.
Каждый ПК работает в Ethernet согласно принципу «Слушай канал передачи, перед тем как отправить сообщения; слушай, когда отправляешь; прекрати работу в случае помех и попытайся еще раз».
Данный принцип можно расшифровать (объяснить) следующим образом:
1. Никому не разрешается посылать сообщения в то время, когда этим занят уже кто-то другой ( слушай перед тем, как отправить).
2. Если два или несколько отправителей начинают посылать сообщения примерно в один и тот же момент, рано или поздно их сообщения «столкнутся» друг с другом в канале связи, что называется коллизией.
Коллизии нетрудно распознать, поскольку они всегда вызывают сигнал помехи, который не похож на допустимое сообщение. Ethernet может распознать помехи и заставляет отправителя приостановить передачу и подождать некоторое время, прежде, чем повторно отправить сообщение.
Причины широкой распространенности и популярности Ethernet (достоинства):
1. Дешевизна.
2. Большой опыт использования.
3. Продолжающиеся нововведения.
4. Богатство выбора оборудования. Многие изготовители предлагают аппаратуру построения сетей, базирующуюся на Ethernet.
Недостатки Ethernet:
1. Возможность столкновений сообщений (коллизии, помехи).
2. В случае большой загрузки сети время передачи сообщений непредсказуемо.
Технология Token Ring
Сети Token Ring, как и сети Ethernet, характеризует разделяемая среда передачи данных, которая состоит из отрезков кабеля, соединяющих все станции сети в кольцо [5]. Кольцо рассматривается как общий разделяемый ресурс, и для доступа к нему требуется не случайный алгоритм, как в сетях Ethernet, а детерминированный, основанный на передаче станциям права на использование кольца в определенном порядке. Это право передается с помощью кадра специального формата, называемого маркером, или токеном (token) [3].
Технология Token Ring был разработана компанией IBM в 1984 году, а затем передана в качестве проекта стандарта в комитет IEЕЕ 802, который на ее основе принял в 1985 году стандарт 802.5.
Каждый ПК работает в Token Ring согласно принципу «Ждать маркера, если необходимо послать сообщение, присоединить его к маркеру, когда он будет проходить мимо. Если проходит маркер, снять с него сообщение и отправить маркер дальше».
Сети Token Ring работают с двумя битовыми скоростями ‑ 4 и 16 Мбит/с. Смешение станций, работающих на различных скоростях, в одном кольце не допускается.
Технология Token Ring является более сложной технологией, чем Ethernet. Она обладает свойствами отказоустойчивости. В сети Token Ring определены процедуры контроля работы сети, которые используют обратную связь кольцеобразной структуры ‑ посланный кадр всегда возвращается в станцию-отправитель.
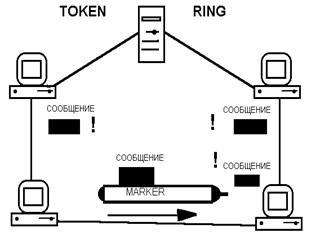
Рис. 3.10. Принцип технологии TOKEN RING
В некоторых случаях обнаруженные ошибки в работе сети устраняются автоматически, например, может быть восстановлен потерянный маркер. В других случаях ошибки только фиксируются, а их устранение выполняется вручную обслуживающим персоналом.
Для контроля сети одна из станций выполняет роль так называемого активного монитора. Активный монитор выбирается во время инициализации кольца как станция с максимальным значением МАС-адреса. Если активный монитор выходит из строя, процедура инициализации кольца повторяется и выбирается новый активный монитор. Сеть Token Ring может включать до 260 узлов.
Концентратор Token Ring может быть активным или пассивным. Пассивный концентратор просто соединяет порты внутренними связями так, чтобы станции, подключаемые к этим портам, образовали кольцо. Ни усиление сигналов, ни их ресинхронизацию пассивный MSAU не выполняет.
Активный концентратор выполняет функции регенерации сигналов, и поэтому иногда называется повторителем, как в стандарте Ethernet.
В общем случае сеть Token Ring имеет комбинированную звездно-кольцевую конфигурацию. Конечные узлы подключаются к MSAU по топологии звезды, а сами MSAU объединяются через специальные порты Ring In (RI) и Ring Out (RO) для образования магистрального физического кольца.
Все станции в кольце должны работать на одной скорости либо 4 Мбит/с, либо 16 Мбит/с. Кабели, соединяющие станцию с концентратором, называются ответвительными (lobe cable), а кабели, соединяющие концентраторы, – магистральными (trunk cable).
Технология Token Ring позволяет использовать для соединения конечных станций и концентраторов различные типы кабеля:
– STP Type 1 ‑ экранированная витая пара (Shielded Twistedpair). В кольцо допускается объединять до 260 станций при длине ответвительных кабелей до 100 метров;
– UTP Туре 3, UTP Туре 6 ‑ неэкранированная витая пара (Unshielded Twistedpair). Максимальное количество станций сокращается до 72 при длине ответвительных кабелей до 45 метров;
– волоконно-оптический кабель.
Расстояние между пассивными MSAU может достигать 100 м при использовании кабеля STP Туре 1 и 45 м при использовании кабеля UTP Type 3. Между активными MSAU максимальное расстояние увеличивается соответственно до 730 м или 365 м в зависимости от типа кабеля.
Максимальная длина кольца Token Ring составляет 4000 м. Ограничения на максимальную длину кольца и количество станций в кольце в технологии Token Ring не являются такими жесткими, как в технологии Ethernet. Здесь эти ограничения в основном связаны со временем оборота маркера по кольцу.
Все значения тайм-аутов в сетевых адаптерах узлов сети Token Ring можно настраивать, поэтому можно построить сеть Token Ring с большим количеством станций и с большей длиной кольца.
Преимущества технологии Token Ring:
· гарантированная доставка сообщений;
· высокая скорость передачи данных (до 160% Ethernet).
Недостатки технологии Token Ring:
· необходимы дорогостоящие устройства доступа к среде;
· технология более сложная в реализации;
· необходимы 2 кабеля (для повышения надежности): один входящий, другой исходящий от компьютера к концентратору;
· высокая стоимость (160-200% от Ethernet).
17. Динамические структуры данных
В языке C++ имеются средства создания динамических структур данных, которые позволяют во время выполнения программы образовывать объекты, выделять для них память, освобождать память, когда в них исчезает необходимость.
Если до начала работы с данными невозможно определить, сколько памяти потребуется для их хранения, память следует распределять во время выполнения программы по мере необходимости отдельными блоками. Блоки связываются друг с другом с помощью указателей. Такой способ организации данных называется динамической структурой данных, поскольку она размещается в динамической памяти и ее размер изменяется во время выполнения программы.
Динамические структуры данных – это структуры данных, память под которые выделяется и освобождается по мере необходимости.
Динамические структуры данных в процессе существования в памяти могут изменять не только число составляющих их элементов, но и характер связей между элементами. При этом не учитывается изменение содержимого самих элементов данных. Такая особенность динамических структур, как непостоянство их размера и характера отношений между элементами, приводит к тому, что на этапе создания машинного кода программа-компилятор не может выделить для всей структуры в целом участок памяти фиксированного размера, а также не может сопоставить с отдельными компонентами структуры конкретные адреса. Для решения проблемы адресации динамических структур данных используется метод, называемый динамическим распределением памяти, то есть память под отдельные элементы выделяется в момент, когда они "начинают существовать" в процессе выполнения программы, а не во время компиляции. Компилятор в этом случае выделяет фиксированный объем памяти для хранения адреса динамически размещаемого элемента, а не самого элемента.
Динамическая структура данных характеризуется тем что:
она не имеет имени;
ей выделяется память в процессе выполнения программы;
количество элементов структуры может не фиксироваться;
размерность структуры может меняться в процессе выполнения программы;
в процессе выполнения программы может меняться характер взаимосвязи между элементами структуры.
Каждой динамической структуре данных сопоставляется статическая переменная типа указатель (ее значение – адрес этого объекта), посредством которой осуществляется доступ к динамической структуре.
Сами динамические величины не требуют описания в программе, поскольку во время компиляции память под них не выделяется. Во время компиляции память выделяется только под статические величины. Указатели – это статические величины, поэтому они требуют описания.
Необходимость в динамических структурах данных обычно возникает в следующих случаях.
Используются переменные, имеющие довольно большой размер (например, массивы большой размерности), необходимые в одних частях программы и совершенно не нужные в других.
В процессе работы программы нужен массив, список или иная структура, размер которой изменяется в широких пределах и трудно предсказуем.
Когда размер данных, обрабатываемых в программе, превышает объем сегмента данных.
Динамические структуры, по определению, характеризуются отсутствием физической смежности элементов структуры в памяти, непостоянством и непредсказуемостью размера (числа элементов) структуры в процессе ее обработки.
Поскольку элементы динамической структуры располагаются по непредсказуемым адресам памяти, адрес элемента такой структуры не может быть вычислен из адреса начального или предыдущего элемента. Для установления связи между элементами динамической структуры используются указатели, через которые устанавливаются явные связи между элементами. Такое представление данных в памяти называется связным.
Достоинства связного представления данных – в возможности обеспечения значительной изменчивости структур:
размер структуры ограничивается только доступным объемом машинной памяти;
при изменении логической последовательности элементов структуры требуется не перемещение данных в памяти, а только коррекция указателей;
большая гибкость структуры.
Вместе с тем, связное представление не лишено и недостатков, основными из которых являются следующие:
на поля, содержащие указатели для связывания элементов друг с другом, расходуется дополнительная память;
доступ к элементам связной структуры может быть менее эффективным по времени.
Последний недостаток является наиболее серьезным и именно им ограничивается применимость связного представления данных. Если в смежном представлении данных для вычисления адреса любого элемента нам во всех случаях достаточно было номера элемента и информации, содержащейся в дескрипторе структуры, то для связного представления адрес элемента не может быть вычислен из исходных данных. Дескриптор связной структурысодержит один или несколько указателей, позволяющих войти в структуру, далее поиск требуемого элемента выполняется следованием по цепочке указателей от элемента к элементу. Поэтому связное представление практически никогда не применяется в задачах, где логическая структура данных имеет вид вектора или массива – с доступом по номеру элемента, но часто применяется в задачах, где логическая структура требует другой исходной информации доступа (таблицы, списки, деревья и т.д.).
Порядок работы с динамическими структурами данных следующий:
создать (отвести место в динамической памяти);
работать при помощи указателя;
удалить (освободить занятое структурой место).
Классификация динамических структур данных
Во многих задачах требуется использовать данные, у которых конфигурация, размеры и состав могут меняться в процессе выполнения программы. Для их представления используют динамические информационные структуры. К таким структурам относят:
однонаправленные (односвязные) списки;
двунаправленные (двусвязные) списки;
циклические списки;
стек;
дек;
очередь;
бинарные деревья.
Они отличаются способом связи отдельных элементов и/или допустимыми операциями. Динамическая структура может занимать несмежные участки оперативной памяти.
Динамические структуры широко применяют и для более эффективной работы с данными, размер которых известен, особенно для решения задач сортировки.
Объявление динамических структур данных
Каждая компонента любой динамической структуры представляет собой запись, содержащую, по крайней мере, два поля: одно поле типа указатель, а второе – для размещения данных. В общем случае запись может содержать не один, а несколько указателей и несколько полей данных. Поле данных может быть переменной, массивом или структурой. Для наилучшего представления изобразим отдельную компоненту в виде:
![]()
где поле Р – указатель; поле D – данные.
Элемент динамической структуры состоит из двух полей:
информационного поля (поля данных), в котором содержатся те данные, ради которых и создается структура; в общем случае информационное поле само является интегрированной структурой – вектором, массивом, другой динамической структурой и т.п.;
адресного поля (поля связок), в котором содержатся один или несколько указателей, связывающий данный элемент с другими элементами структуры;
Объявление элемента динамической структуры данных выглядит следующим образом:
struct имя_типа {
информационное поле;
адресное поле;
};
Например:
struct TNode {
int Data;//информационное поле
TNode *Next;//адресное поле
};
Информационных и адресных полей может быть как одно, так и несколько.
Рассмотрим в качестве примера динамическую структуру, схематично указанную на рис. 28.1:

Рис. 28.1. Схематичное представление динамической структуры
Данная структура состоит из 4 элементов. Ее первый элемент имеет поле Data, равное 73, и связан с помощью своего поля Next со вторым элементом, поле Data которого равно 28, и так далее до последнего, четвертого элемента, поле Data которого равно 85, а поле Next равно NULL, то есть нулевому адресу, что является признаком завершения структуры. Здесь P является указателем, который указывает на первый элемент структуры.
Доступ к данным в динамических структурах
Элемент динамической структуры в каждый момент может либо существовать, либо отсутствовать в памяти, поэтому его называют динамическим. Поскольку элементами динамической структуры являются динамические переменные, то единственным средством доступа к динамическим структурам и их элементам является указатель (адрес) на место их текущего расположения в памяти. Таким образом, доступ к динамическим данным выполняется специальным образом с помощью указателей.
Указатель содержит адрес определенного объекта в динамической памяти. Адрес формируется из двух слов: адрес сегмента и смещение. Сам указатель является статическим объектом и расположен в сегменте данных (рис. 28.2).

Рис. 28.2. Связь указателя с адресуемым объектом
Для обращения к динамической структуре достаточно хранить в памяти адрес первого элемента структуры. Поскольку каждый элемент динамической структуры хранит адрес следующего за ним элемента, можно, двигаясь от начального элемента по адресам, получить доступ к любому элементу данной структуры.
Доступ к данным в динамических структурах осуществляется с помощью операции "стрелка" ( -> ), которую называют операцией косвенного выбора элемента структурного объекта, адресуемого указателем. Она обеспечивает доступ к элементу структуры через адресующий ее указатель того жеструктурного типа. Формат применения данной операции следующий:
УказательНаСтруктуру-> ИмяЭлемента
Операции "стрелка" ( -> ) двуместная. Применяется для доступа к элементу, задаваемому правым операндом, той структуры, которую адресует левыйоперанд. В качестве левого операнда должен быть указатель на структуру, а в качестве правого – имя элемента этой структуры.
Например:
p->Data;
p->Next;
Имея возможность явного манипулирования с указателями, которые могут располагаться как вне структуры, так и "внутри" отдельных ее элементов, можно создавать в памяти различные структуры.
Однако необходимо помнить, что работа с динамическими данными замедляет выполнение программы, поскольку доступ к величине происходит в два шага: сначала ищется указатель, затем по нему – величина.
Работа с памятью при использовании динамических структур
В программах, в которых необходимо использовать динамические структуры данных, работа с памятью происходит стандартным образом. Выделение динамической памяти производится с помощью операции new или с помощью библиотечной функции malloc (calloc). Освобождение динамической памяти осуществляется операцией delete или функцией free.
Например, объявим динамическую структуру данных с именем Node с полями Name, Value и Next, выделим память под указатель на структуру, присвоим значения элементам структуры и освободим память.
struct Node {char *Name;
int Value;
Node *Next
};
Node *PNode; //объявляется указатель
PNode = new Node; //выделяется память
PNode->Name = "STO"; //присваиваются значения
PNode->Value = 28;
PNode->Next = NULL;
delete PNode; // освобождение памяти
Ключевые термины
Адрес сегмента – это одно из машинных слов, составляющих адрес динамического элемента, которое представляет собой адрес первого элемента структуры.
Адресное поле (поле связок) – это поле структуры, в котором содержится указатель, связывающий данный элемент с другими элементами структуры.
Динамические структуры данных – это структуры данных, память под которые выделяется и освобождается не на этапе компиляции, а в процессе работы программы.
Динамический элемент – это элемент динамической структуры, который в конкретный момент выполнения программы может либо существовать, либо отсутствовать в памяти.
Динамическое распределение памяти – это выделение памяти под отдельные элементы в тот момент, когда они "начинают существовать" в процессе выполнения программы.
Информационное поле (поле данных) – это поле структуры, в котором содержатся непосредственно обрабатываемые данные.
Связное представление данных – это установление связи между элементами динамической структуры через указатели.
Смещение – это одно из машинных слов, составляющих адрес динамического элемента, которое представляет собой изменение адреса относительно первого элемента структуры.
Краткие итоги
В программах возникает необходимость обрабатывать данные, размер которых заранее неизвестен.
Для данных с достаточно большим или переменным размером используются динамические структуры.
Динамические структуры не имеют имени, под них выделяется память в процессе выполнения программы, количество их элементов может не фиксироваться, в процессе выполнения программы может меняться характер взаимосвязи между элементами структуры.
Каждой динамической структуре ставится в соответствие статическая переменная – ее адрес.
Представление динамических структур в памяти определяется как связное.
Связное представление данных в программах имеет как достоинства, так и недостатки.
Существует классификация динамических структур данных в зависимости от связей между элементами и допустимых операций.
Элемент динамической структуры состоит как минимум из двух полей: адресного и информационного.
Адресное поле формируется из двух слов: адрес сегмента и смещение.
Доступ к данным в динамических структурах осуществляется с помощью операции косвенного выбора.
18. Основные устройства комбинационной логики (сумматоры, схемы сравнения, шифраторы/дешифраторы, мультиплексоры / демультиплексоры)
Дешифраторы (ДШ) – это устройства, которые преобразуют позиционный код в унитарный.
Унитарный код (unitary code) — двоичный код фиксированной длины, содержащий только одну «1».
ДШ преобразует входной код в номер выхода. Для построения ДШ необходимо записать конъюнкции всех наборов и реализовать их в заданном базисе.
Неполные дешифраторы – это ДШ у которых используются не все входы.

A2 |
A1 |
A0 |
Q7 |
Q6 |
Q5 |
Q4 |
Q3 |
Q2 |
Q1 |
Q0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Шифраторы – это устройства, которые по номеру входа выдают код.
Шифратор — логическое устройство, выполняющее преобразование позиционного кода в n-разрядный двоичный код.
Двоичный шифратор выполняет логическую функцию преобразования унарно n-ичного однозначного кода в двоичный. При подаче сигнала на один из n входов (обязательно на один, не более) на выходе появляется двоичный код номера активного входа.
Если количество входов настолько велико, что в шифраторе используются все возможные комбинации сигналов на выходе, то такой шифратор называется полным, если не все, то неполным. Число входов и выходов в полном шифраторе связано соотношением: n=2m, где n — число входов, m — число выходных двоичных разрядов.
Изображение и таблица аналогично дешифратору.
Мультиплексор — устройство, имеющее несколько сигнальных входов, один или более управляющих входов и один выход. Мультиплексор позволяет передать сигнал с одного из входов на выход; при этом выбор желаемого входа осуществляется подачей соответствующей комбинации управляющих сигналов. Мультиплексоры – цифровые коммутаторы каналов. МП можно использовать для реализаций логических схем. Другими словами на каждом МП можно реализовать сложную булеву функцию (одну). При этом если m адресных входов, то можно организовать функцию m+2 переменных. Переменные подаются на адресный вход.
Мультиплексор – совокупность управляемых шин с общим выходом
A2 |
A1 |
F |
0 |
0 |
D0 |
0 |
1 |
D1 |
1 |
0 |
D2 |
1 |
1 |
D3 |

D0..D3 – информационные входы, A1,A2 – управляющие входы.
Демультиплексор — устройство, в котором сигналы с одного информационного входа поступают в желаемой последовательности по нескольким выходам в зависимости от кода на адресных шинах. Таким образом, демультиплексор в функциональном отношении противоположен мультиплексору. Демультиплексоры – цифровые разделители каналов.
Задавая адреса, мы выбираем канал, который подключится на выход.
ДМП не выпускаются в виде отдельных схем. Они выпускаются с ДШ.
ДМП можно использовать для преобразования последовательного когда в параллельный.
A2 |
A1 |
Y3 |
Y2 |
Y1 |
Y0 |
0 |
0 |
0 |
0 |
0 |
F |
0 |
1 |
0 |
0 |
F |
0 |
1 |
0 |
0 |
F |
0 |
0 |
1 |
1 |
F |
0 |
0 |
0 |
 Демультиплексор
Демультиплексор
Схемы сравнения кодов. Два кода X и Y считаются равными, если попарно равны их одноименные разряды. Можно ввести функцию F(X==Y), которая равна 1, если xi=yi для всех i, иначе ее значение равно нулю. В качестве примера возьмем два двухбитовых числа X=(x1,x0) и Y=(y1,y0).

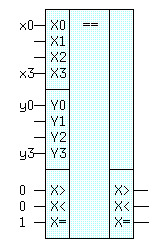 Практические
схемы дополняются функциями "больше/меньше",
как например в микросхеме 555СП1, которая
сравнивает два четырехразрядных числа.
Схема сравнения входит в состав АЛУ
микропроцессора и часто называется
цифровым компаратором.
Практические
схемы дополняются функциями "больше/меньше",
как например в микросхеме 555СП1, которая
сравнивает два четырехразрядных числа.
Схема сравнения входит в состав АЛУ
микропроцессора и часто называется
цифровым компаратором.
Сумматор — устройство, преобразующее информационные сигналы (аналоговые или цифровые) в сигнал, эквивалентный сумме этих сигналов
В зависимости от способа ввода разрядов слагаемых сумматоры делятся на два типа: последовательного и параллельного действия. В сумматоры первого типа разряды чисел вводятся в последовательной форме, т. е. разряд за разрядом (младшим разрядом вперед), в сумматоры второго типа каждое из слагаемых подается в параллельной форме, т. е. одновременно всеми разрядами.
Сумматор последовательного действия. Состоит из одноразрядного сумматора, выход pi+1 которого соединен с входом pi через элемент задержки, параметры которого согласованы со скоростью поступления разрядов слагаемых на входы сумматора. Операция суммирования во всех разрядах слагаемых осуществляется с помощью одного и того же одноразрядного сумматора, но последовательно во времени, начиная с младших разрядов. Такое построение сумматора возможно за счет того, что слагаемые поступают в последовательной форме.
Достоинство сумматора последовательного действия заключается в малом объеме оборудования, требуемого для его построения. Однако в связи с необходимостью последовательной обработке разрядов приводит к низкому быстродействию.
Сумматор параллельного действия. Состоит из отдельных разрядов, каждый из которых содержит одноразрядный сумматор.
При подаче слагаемых цифры их разрядов поступают на соответствующие одноразрядные сумматоры. Каждый из одноразрядных сумматоров формирует на своих выходах цифру соответствующего разряда суммы и перенос, передаваемый на вход одноразрядного сумматора следующего (более старшего) разряда. Такая организация процесса переноса, называемая последовательным переносом, снижает быстродействие многоразрядных сумматоров, т.к. получение результата в старшем разряде сумматора обеспечивается только после завершения распространения переноса по всем разрядам.
19. Понятие устойчивости динамических систем. Основные критерии устойчивости
25. Устойчивость систем автоматического управления. Необходимые и достаточные условия устойчивости.
Определение: Система называется. устойчивой, если после снятия кратковременного воздействия она возвращается в исходное положение.
Определение: Система называется нейтрально-устойчивой, если после снятия кратковременного воздействия она занимает новое положение.
Определение: Система называется неустойчивой, если после снятия кратковременного воздействия она уходит от положения равновесия.
Применим эти определения к САУ.
Кратковременное воздействие: реакция системы на
 -функцию
является весовая функция
-функцию
является весовая функция
 .
.
а )
Система устойчива: б) Система
нейтральная: в) Система
неустойчивая:
)
Система устойчива: б) Система
нейтральная: в) Система
неустойчивая:


Формула
разложения для весовой функции:
 ,
,
где
 -корни
характеристического уравнения А(p)=0;
-корни
характеристического уравнения А(p)=0;
Как влияет расположение корней на характер весовой функции?

1 .
Корни
.
Корни
 :
:
 ;
;
 ;
;
 ;
;  ;
;
 ;
;
 ;
;
 ;
;
Система устойчива.
Корень
 ,
,
 ;
;

 ;
;
Система устойчива.
Корень
 ,
,
,
,
 ;
;
 ;
;
Система устойчива.
Корень
 ,
;
,
;
 ;
;
Система нейтральная.
К
 орень
орень
 ,
,
 ;
;
Система неустойчива.
Корни
 ,
,
 ;
;
 ;
;
Система неустойчива.


Вывод: система устойчива, если все корни её характеристического уравнения лежат в левой части комплексной плоскости. Система нейтрально-устойчивая, если корни её характеристического уравнения лежат в левой части комплексной плоскости и на мнимой оси. Система неустойчива, если хотя бы 1 корень её характеристического уравнения лежит в правой полуплоскости.
Необходимым и достаточным условием устойчивости линейной системы является расположение её корней (полюсов) в левой части комплексной плоскости.
26. Критерий устойчивости Гурвица. Пример.
В основе лежит характеристический полином исследуемой системы.
 ;
;

 ;
;
По главной диагонали все коэффициенты начиная с а1.
Выше главной диагонали коэффициенты в порядке возрастания индексов.
Ниже главной диагонали – в порядке убывания индексов.
Формулировка критерия Гурвица:
Для устойчивости
системы необходимо и достаточно, чтобы
а0>0,
 (i=1..n).
(i=1..n).
Система нейтрально-устойчива, если хотя бы один определитель Гурвица равен нулю.
 на границе колебательной устойчивости;
на границе колебательной устойчивости;
 на границе апериодической устойчивости
(1 из корней попал в ноль);
на границе апериодической устойчивости
(1 из корней попал в ноль);
Определитель
Гурвица
 ,
получается отчеркиванием i
строк и i столбцов из
определителя
,
получается отчеркиванием i
строк и i столбцов из
определителя
 .
.
Частный случай устойчивости системы:
 ,
,
 ;
;
 ;
;
Если:
 , то система устойчива.
, то система устойчива.
27. Принцип аргумента. Критерий устойчивости Михайлова.
Принцип аргумента.
Рассмотрим А(р) при подстановке jw вместо р.
А(jw)-характеристический полином от аргумента jw.
 ;
;
Е сли
рассматривать А(jw):
сли
рассматривать А(jw):
 ;
;
 -это
фаза (аргумент);
-это
фаза (аргумент);
 ;
;
Обычно интересуются приращением:
 при
при
 ;
;
 при
при
 ;
;
Приращение
аргумента вектора А(jw)
равно разности левых и правых полюсов,
умноженной на
 при изменении частоты от
и умноженной на
при изменении частоты от
и умноженной на
 при изменении частоты от
.
при изменении частоты от
.
Критерий Михайлова является геометрической интерпретацией принципа аргумента.
Ответим на вопрос: является ли система с характеристическим полиномом А(р) устойчивой?
П усть
в А(р) нет нулевых корней. Частоту изменяем
от
.
Если l=0, то правых корней
нет, т.е. система устойчива.
усть
в А(р) нет нулевых корней. Частоту изменяем
от
.
Если l=0, то правых корней
нет, т.е. система устойчива.
Примеры устойчивости годографов Михайлова.
 ,
,
 ,
,
 ,
полагаем, что
,
полагаем, что
 >0;
>0; ,
,
 ,
,
 ;
;и т.д.
Для устойчивости системы необходимо и достаточно, чтобы годограф Михайлова, начинаясь на действительной оси обходил в положительном направлении n-квадрантов.
Г одограф
Михайлова-это геометрическое место
конца вектора А(jw).(положительное
направление - против часовой стрелки).
одограф
Михайлова-это геометрическое место
конца вектора А(jw).(положительное
направление - против часовой стрелки).
Примеры неустойчивости:
28. Критерий устойчивости Найквиста для устойчивой в разомкнутом состянии системы.
Критерий Найквиста позволяет судить об устойчивости замкнутой системы по годографу разомкнутой системы. Удобство использования определяется тем, что годограф может быть построен экспериментально.
Критерий Найквиста связывает разомкнутую и замкнутую систему.
Вводится
функция:
 ;
;
где
С(р)-характеристический полином
разомкнутой системы,
 ;
;
 ;
;
При каких условиях замкнутая система устойчива?
При условии
устойчивости замкнутой системы изменение
 в диапазоне от
в диапазоне от
или будет равно:
 ,
при
и
при
.
,
при
и
при
.
Разомкнутая система устойчива.
Характеристический полином разомкнутой системы не имеет правых корней (l=0).
 при
и
при
;
при
и
при
;
Т. о. , система
автоматического регулирования устойчива,
если изменение аргумента вектора F(jw)
при изменении w от 0 до
 ,
равно нулю.
,
равно нулю.
 ;
;
Н а
рис.(*) показаны два годографа
;
1-соответствует устойчивой системе: он
не охватывает точку (0,0), 2-неустойчивой:
он охватывает точку (0,0). Так как
а
рис.(*) показаны два годографа
;
1-соответствует устойчивой системе: он
не охватывает точку (0,0), 2-неустойчивой:
он охватывает точку (0,0). Так как
 отличается от от
отличается от от
 на +1, то сказанное можно сформулировать
непосредственно для характеристики
.
рис.(**)
на +1, то сказанное можно сформулировать
непосредственно для характеристики
.
рис.(**)
Формулировка:
Если разомкнутая система устойчива, то для устойчивой замкнутой системы необходимо и достаточно, чтобы годограф разомкнутой системы не охватывал точку с координатами
(-1, j0).
29. Критерий устойчивости Найквиста для неустойчивой в разомкнутом состянии системы.
Р ассмотрим
неустойчивую систему (
ассмотрим
неустойчивую систему ( ).
).
 ,
при
и
при
.
,
при
и
при
.
Формулировка:
Если разомкнутая система неустойчива и характеристический полином имеет l правых корней, то для устойчивости замкнутой системы необходимо и достаточно, чтобы годограф разомкнутой системы охватывал точку (-1, j0) l раз в положительном направлении при или l/2 раз при .
30. Критерий устойчивости Найквиста для нейтральной в разомкнутом состянии системы.
Рассмотрим нейтральную в разомкнутом состоянии систему.
Передаточная
функция системы:
 ,
где
,
где
 -число
интегрирующих звеньев в системе, K(p)
и D(p)-полиномы
от р, причем D(p)
не имеет нулей в правой полуплоскости
и на мнимой оси.
-число
интегрирующих звеньев в системе, K(p)
и D(p)-полиномы
от р, причем D(p)
не имеет нулей в правой полуплоскости
и на мнимой оси.
По виду комплексного коэффициента, который следует из передаточной функции можно построить годограф, но он будет иметь разрыв при w=0 и нам будет трудно судить об устойчивости данной системы. В этом случае требуется специальное исследование годографа вблизи точки w=0.
Рассмотрим случай, когда =1.
Тогда:
 ;
;
П ри
jw=0 значение ККУ обращается
в бесконечность, поэтому для сохранения
формулировки критерия справедливой
для устойчивых в разомкнутом состоянии
систем, при построении годографа либо,
обходя мнимую ось от
ри
jw=0 значение ККУ обращается
в бесконечность, поэтому для сохранения
формулировки критерия справедливой
для устойчивых в разомкнутом состоянии
систем, при построении годографа либо,
обходя мнимую ось от
 ,
огибают точку (0,0) справа по полуокружности
бесконечно малого радиуса, либо
рассматривают нулевой корень, как предел
отрицательного вещественного корня
,
огибают точку (0,0) справа по полуокружности
бесконечно малого радиуса, либо
рассматривают нулевой корень, как предел
отрицательного вещественного корня
 при
при
 .
.
Воспользуемся
вторым вариантом предельного перехода
от устойчивой разомкнутой системы к
нейтральной. В этом случае вместо функции
воспользуемся
функцией
 ,
которая переходит в
при
.
,
которая переходит в
при
.
 ;
;
Предел от данного ККУ равен какой-то постоянной R.
При малых
частотах годограф
отличается от годографа
,
принимая вид пунктирной кривой, показанной
на рисунке. По мере стремления
 R стремится к бесконечности
и годограф
отличается от годографа
только
четвертью окружности бесконечно большого
радиуса, дополняемой при w
стремящемся к 0. Будем называть такую
часть окружности «дополнением в
бесконечности».
R стремится к бесконечности
и годограф
отличается от годографа
только
четвертью окружности бесконечно большого
радиуса, дополняемой при w
стремящемся к 0. Будем называть такую
часть окружности «дополнением в
бесконечности».
Формулировка:
Система автоматического регулирования , нейтральная в разомкнутом состоянии, устойчива, если годограф разомкнутой системы с его дополнением в бесконечности не охватывает точку (-1, j0).
31. Общая формулировка критерия Найквиста. Логарифмический критерий устойчивости.
Э та
формулировка объединяет все 3 предыдущих
случая.
та
формулировка объединяет все 3 предыдущих
случая.
Формулировка:
Замкнутая система устойчива, если алгебраическая сумма числа переходов годографом действительной оси от - до –1 равна l/2 при изменении w от 0 до или –l при изменении частоты от - до , где l число правых корней характеристического полинома разомкнутой системы.
Логарифмический критерий устойчивости.
Замкнутая
система устойчива, если алгебраическая
сумма переходов фазовой характеристики
разомкнутой системы прямых -3 ...
на отрезках частот, для которых L(w)>0
равна l/2, где l-число
правых корней характеристического
полинома разомкнутой системы. В нашем
примере сумма переходов равна –2, след.
система неустойчива.
...
на отрезках частот, для которых L(w)>0
равна l/2, где l-число
правых корней характеристического
полинома разомкнутой системы. В нашем
примере сумма переходов равна –2, след.
система неустойчива.

20. Логическое кодирование в сетях (избыточные коды и скрэмблирование)
Логическое кодирование выполняется передатчиком до физического кодирования, рассмотренного выше, обычно средствами физического уровня. На этапе логического кодирования борются с недостатками методов физического цифрового кодирования - отсутствие синхронизации, наличие постоянной составляющей. Таким образом, сначала с помощью средств логического кодирования формируются исправленные последовательности данных, которые потом с помощью методов физического кодирования передаются по линиям связи.
Логическое кодирование подразумевает замену бит исходной информационной последовательности новой последовательностью бит, несущей ту же информацию, но обладающей, кроме этого, дополнительными свойствами.
Различают два метода логического кодирования:
избыточные коды;
скремблирование.
Избыточные коды основаны на разбиении исходной последовательности бит на группы и замене каждой исходной группы в соответствии с заданной таблицей кодовым словом, которое содержит большее количество бит.
Логический код 4В/5В заменяет исходные группы (слова) длиной 4 бита словами длиной 5 бит. В результате, общее количество возможных битовых комбинаций 25=32 больше, чем для исходных групп 24=16. В кодовую таблицу включают 16 кодовых слов, которые не содержат более двух нулей подряд, и используют их для передачи данных. Код гарантирует, что при любом сочетании кодовых слов на линии не могут встретиться более трех нулей подряд.
Остальные комбинации кода используются для передачи служебных сигналов (синхронизация передачи, начало блока данных, конец блока данных, управление передачей). Неиспользуемые кодовые слова могут быть задействованы приемником для обнаружения ошибок в потоке данных. Цена за полученные достоинства при таком способе кодирования данных - снижение скорости передачи полезной информации на 25%.
Имеются также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используются кодовые слова из 6 элементов, каждый из которых может принимать одно из трех значений. Избыточность кода 8В/6Т выше, чем кода 4В/5В, так как на 28=256 исходных комбинаций приходится 36=729 результирующих комбинаций.
В коде 8B/10В каждые 8 бит исходной последовательности заменяются десятью битами кодового слова. При этом на 256 исходных комбинаций приходится 1024 результирующих комбинаций. При замене в соответствии с кодовой таблицей соблюдаются следующие правила:
ни одна результирующая комбинация не должна иметь более 4-х одинаковых бит подряд;
ни одна результирующая комбинация не должна содержать более 6 нулей или 6 единиц;
Все рассмотренные избыточные коды применяются в сетях Ethernet, которые нашли самое широкое распространение. Так, код 4B/5B используется в стандартах 100Base-TX/FX, а код 8B/6T — в стандарте 100Base-T4, который в настоящее время практически уже не используется. Код 8B/10В используется в стандарте 1000Base-Х, код 64/66 в стандарте 10 GbE (когда в качестве среды передачи данных используется оптоволокно).
Осуществляют логическое кодирование сетевые адаптеры. Поскольку, использование таблицы перекодировки является очень простой операцией, метод логического кодирования избыточными кодами не усложняет функциональные требования к этому оборудованию.
Для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код, должен работать с повышенной скоростью (тактовой частотой). Так, для обеспечения скорости передачи информации 100 Мбит/с с использованием кодирования 4В/5В + NRZI передатчик должен работать на скорости 125 МБод. При этом спектр линейного сигнала расширяется. Тем не менее, спектр сигнала избыточного потенциального кода уже спектра сигнала в манчестерском коде, что оправдывает дополнительный этап логического кодирования, а также работу приемника и передатчика на повышенной скорости.
Скремблирование представляет собой "перемешивание" исходной последовательности данных таким образом, чтобы вероятность появления единиц и нулей на линии становилась близкой 0,5. Устройства (или программные модули), выполняющие такую операцию, называются скремблерами (scramble - свалка, беспорядочная сборка).
Скремблер в передатчике выполняет преобразование структуры исходного цифрового потока. Дескремблер в приемнике восстанавливает исходную последовательность бит. Практически единственной операцией, используемой в скремблерах и дескремблерах, является XOR - "побитное исключающее ИЛИ" (сложение по модулю 2).

Рис.4.8. Вариант реализации скремблирования
Пусть, например, скремблер реализует соотношение Вi=Ai+Bi-5+Bi-7.
Здесь Bi – бит результирующего кода, полученный на i-м такте работы скремблера; Ai – бит исходного кода, поступающий в передатчике на вход скремблера на i-м такте; Bi-5 и Bi-7 – биты результирующего кода, полученные на предыдущих тактах работы скремблера, соответственно на «i-5» и «i-7» тактах.
Дескремблер в приемнике восстанавливает исходную последовательность, используя соотношение Ci=Bi+Bi-5+Bi-7=(Ai+Bi-5+Bi-7 )+Bi-5+Bi-7=Ai
Выводы
В сетях высокоскоростной передачи данных используются различные виды логического и физического кодирования данных. Логическое кодирование выполняется передатчиком до физического кодирования средствами физического уровня. На этапе логического кодирования борются с недостатками методов физического цифрового кодирования - отсутствие синхронизации, наличие постоянной составляющей. Сформированные исправленные последовательности данных затем с помощью методов физического кодирования передаются по линиям связи.
21. Цифровые автоматы (триггеры, регистры, счетчики)
Регистры — последовательное логическое устройство, используемое для хранения n-разрядных двоичных слов (чисел) и выполнения преобразований над ними.
Регистр представляет собой упорядоченную последовательность триггеров, число которых соответствует числу разрядов в слове. С каждым регистром обычно связано комбинационное цифровое устройство, с помощью которого обеспечивается выполнение некоторых операций над словами.
Фактически любое цифровое устройство можно представить в виде совокупности регистров, соединённых друг с другом при помощи комбинационных цифровых устройств.
Регистром называется функциональный узел, осуществляющий приём, хранение и передачу информации. Регистры состоят из группы триггеров, обычно D. По типу приёма и выдачи информации различают 3 типа регистров:
- С последовательным приёмом и выдачей информации — сдвиговые регистры.
- С параллельным приёмом и выдачей информации — параллельные регистры.
- С параллельно-последовательным приёмом и выдачей информации
Сдвиговые регистры представляют собой последовательно соединённую цепочку триггеров. Основной режим работы — сдвиг разрядов кода от одного триггера к другому на каждый импульс тактового сигнала.
Параллельно-последовательный:
- Ввод осуществляется параллельно
- Вывод последовательно
С четчики.
Счётчик
числа импульсов — устройство, на выходах
которого получается двоичный
(двоично-десятичный) код, определяемый
числом поступивших импульсов. Счётчики
могут строиться на T-триггерах. Основной
параметр счётчика — модуль счёта —
максимальное число единичных сигналов,
которое может быть сосчитано счётчиком.
Счётчики обозначают через СТ (от англ.
counter).
четчики.
Счётчик
числа импульсов — устройство, на выходах
которого получается двоичный
(двоично-десятичный) код, определяемый
числом поступивших импульсов. Счётчики
могут строиться на T-триггерах. Основной
параметр счётчика — модуль счёта —
максимальное число единичных сигналов,
которое может быть сосчитано счётчиком.
Счётчики обозначают через СТ (от англ.
counter).
22. Управляемость и наблюдаемость динамических систем
Для линейных
динамических систем, представленных
на рис. 1, и описываемых уравнениями в
пространстве состояний порядка

 ,
,
 ,
,
полная
управляемость означает существование
ограниченного входного сигнала
 ,
переводящего объект за конечный интервал
времени из любого начального состояния
,
переводящего объект за конечный интервал
времени из любого начального состояния
 в любое наперёд заданное состояние
в любое наперёд заданное состояние
 .
Если бы объект не был полностью
управляемым, то нельзя рассчитывать на
то, что замкнутой системе, содержащей
этот объект, можно придать любые
динамические свойства, т.е. желаемое
расположение корней.
.
Если бы объект не был полностью
управляемым, то нельзя рассчитывать на
то, что замкнутой системе, содержащей
этот объект, можно придать любые
динамические свойства, т.е. желаемое
расположение корней.
Условием полной
управляемости объекта является равенство
ранга его матрицы управляемости
 порядку
объекта. Матрица управляемости выражается
через параметры объекта формулой
порядку
объекта. Матрица управляемости выражается
через параметры объекта формулой
 .
.
Матрица
записана в блочной форме. Если элементы
– блоки
 записать в развернутой форме, то матрица
станет прямоугольной типа
записать в развернутой форме, то матрица
станет прямоугольной типа
 .
.
Рис. 1 Схема
многомерной системы в пространстве
состояний

Наблюдаемость
– произвольное состояние
 можно найти по имеющимися записям
вектора выходного сигнала
можно найти по имеющимися записям
вектора выходного сигнала
 (t>t0 ).
Условием наблюдаемости является
равенство ранга матрицы Q
порядку системы n :
(t>t0 ).
Условием наблюдаемости является
равенство ранга матрицы Q
порядку системы n :

23. Эргономика. Система «человек, техника, среда»
Эргономика. Эргономическая экспертиза
ЭРГОНОМИКА - научная дисциплина, комплексно изучающая трудовую деятельность человека в системах "человек - техника - среда" (СЧТС) с целью обеспечения ее эффективности, безопасности и комфорта. Аналогичную область знаний в США называют "человеческими факторами" (human factors).
ЭРГОНОМИЧЕСКАЯ ЭКСПЕРТИЗА - комплекс научно-технических и организационно-методических мероприятий по оценке выполнения в проектных, предпроектных и рабочих документах и в образцах СЧТС эргономических требований технического задания, нормативно-технических документов, а также по разработке рекомендаций для устранения отступлений от этих требований.
Указанная экспертиза проводится при обосновании выполнения каждого этапа опытно-конструкторской разработки: технического предложения, эскизного проекта, технического проекта, рабочего проекта. Материалы ее - акт либо протокол - включаются в документы, представляемые на защиту проекта.
Эргономическая экспертиза может проводится, например, по таким направлениям, как:
"Интерфейс "человек - компьютер"" по показателям психологическим, психофизиологическим, комфортности, цветовой совместимости элементов, "рабочее место пользователя компьютера" по показателям психологическим, психофизиологическим, антропометрическим, обслуживаемость, осваиваемость.
24. Функциональная и структурная организация процессора
Функциональная и структурная организация процессора
Процессор, или более полно микропроцессор, а также часто называемый ЦПУ (CPU - central processing unit) является центральным компонентом компьютера. Это разум, который управляет, прямо или косвенно, всем происходящим внутри компьютера. Когда фон Нейман впервые предложил хранить последовательность инструкций, так называемые программы, в той же памяти, что и данные, это была поистине новаторская идея. Опубликована она в "First Draft of a Report on the EDVAC" в 1945 году. Этот отчет описывал компьютер состоящим из четырех основных частей: центрального арифметического устройства, центрального управляющего устройства, памяти и средств ввода-вывода. Сегодня, более полувека спустя, почти все процессоры имеют фон-неймановскую архитектуру.
На первый взгляд, процессор – просто выращенный по специальной технологии кристалл кремния (не зря его ещё называют «камень»). Однако камешек этот содержит в себе множество отдельных элементов – транзисторов, которые в совокупности и наделяют компьютер способностью «думать». Точнее, вычислять, производя определённые математические операции с числами, в которые преображается любая поступающая в компьютер информация. Таких транзисторов в любом микропроцессоре многие миллионы.
Сегодняшний процессор – это не просто скопище транзисторов, а целая система множества важных устройств. На любом процессорном кристалле находятся:
Собственно, процессор, главное вычислительное устройство, состоящее из миллионов логических элементов – транзисторов.
Сопроцессор – специальный блок для операций с «плавающей точкой». Применяется для особо точных и сложных расчётов, а так же для работы с рядом графических программ.
Кэш-память первого уровня – небольшая (несколько десятков килобайт) сверхбыстрая память, предназначенная для хранения промежуточных результатов вычислений.
Кэш-память второго уровня – эта память чуть помедленнее, зато больше – от 128 кбайт до 2048 кбайт.
Все эти устройства размещаются на кристалле площадью не более 4-6 квадратных сантиметров. Только под микроскопом можно разглядеть крохотные элементы, из которых состоит микропроцессор, и соединяющие их металлические «дорожки» (для их изготовления ранее использовали алюминий, сейчас же на смену ему пришла медь). Их размер поражает воображение – десятые доли микрона! Сейчас большая часть процессоров производится по 0,09-микронной технологии. Но это не самое важное. Существуют другие, гораздо более важные для нас характеристики процессора, которые прямо связаны с возможностями и скоростью работы.
Основные функциональные компоненты процессора
Ядро: Сердце современного процессора - исполняющий модуль. Современный процессор имеет два параллельных целочисленных потока, позволяющих читать, интерпретировать, выполнять и отправлять две инструкции одновременно.
Предсказатель ветвлений: Модуль предсказания ветвлений пытается угадать, какая последовательность будет выполняться каждый раз когда программа содержит условный переход, так чтобы устройства предварительной выборки и декодирования получали бы инструкции готовыми предварительно.
Блок плавающей точки. Третий выполняющий модуль внутри процессора, выполняющий нецелочисленные вычисления
Первичный кэш: Pentium имеет два внутричиповых кэша по 8kb, по одному для данных и инструкций, которые намного быстрее большего внешнего вторичного кэша.
Шинный интерфейс: принимает смесь кода и данных в CPU, разделяет их до готовности к использованию, и вновь соединяет, отправляя наружу.
Все элементы процессора синхронизируются с использованием частоты часов, которые определяют скорость выполнения операций. Самые первые процессоры работали на частоте 100kHz, сегодня рядовая частота процессора - 200MHz, иначе говоря, часики тикают 200 миллионов раз в секунду, а каждый тик влечет за собой выполнение многих действий. Счетчик Команд (PC) - внутренний указатель, содержащий адрес следующей выполняемой команды. Когда приходит время для ее исполнения, Управляющий Модуль помещает инструкцию из памяти в регистр инструкций (IR). В то же самое время Счетчик команд увеличивается, так чтобы указывать на последующую инструкцию, а процессор выполняет инструкцию в IR. Некоторые инструкции управляют самим Управляющим Модулем, так если инструкция гласит 'перейти на адрес 2749', величина 2749 записывается в Счетчик Команд, чтобы процессор выполнял эту инструкцию следующей.
Многие инструкции задействуют Арифметико-логическое Устройство (ALU), работающее совместно с Регистрами Общего Назначения - место для временного хранения, которое может загружать и выгружать данные из памяти. Типичной инструкцией ALU может служить добавление содержимого ячейки памяти к регистру общего назначения. ALU также устанавливает биты Регистра Состояний (Status register - SR) при выполнении инструкций для хранения информации о ее результате. Например, SR имеет биты, указывающие на нулевой результат, переполнение, перенос и так далее. Модуль Управления использует информацию в SR для выполнения условных операций, таких как 'перейти по адресу 7410 если выполнение предыдущей инструкции вызвало переполнение'.
Это почти все что касается самого общего рассказа о процессорах - почти любая операция может быть выполнена последовательностью простых инструкций, подобных описанным. Большинство процессоров сегодня применяют поточную обработку (pipelining), которая больше похожа на фабричный конвейер. Одна стадия потока выделена под каждый шаг, необходимый для выполнения инструкции, и каждая стадия передает инструкцию следующей, когда она выполнила свою часть. Это значит, что в любой момент времени одна инструкция загружается, другая декодируется, доставляются данные для третьей, четвертая исполняется, и записывается результат для пятой. При текущей технологии одна инструкция за тик может быть достигнута.
Более того, многие процессоры сейчас имеют суперскалярную архитектуру. Это значит, что схема каждой стадии потока дублируется, так что много инструкций могут передаваться параллельно.
Что отличает микропроцессор от его предшественников, сконструированных из ламп, отдельных транзисторов, малых интегральных схем, такими какими они были первое время от полного процессора на едином кремниевом чипе.
Кремний или силикон - это основной материал из которого производятся чипы. Это полупроводник, который, будучи присажен добавками по специальной маске, становится транзистором, основным строительным блоком цифровых схем. Процесс подразумевает вытравливание транзисторов, резисторов, пересекающихся дорожек и так далее на поверхности кремния.
Сперва выращивается кремневая болванка. Она должна иметь бездефектную кристаллическую структуру, этот аспект налагает ограничение на ее размер. В прежние дни болванка ограничивалась диаметром в 2 дюйма, а сейчас распространены 8 дюймов. На следующей стадии болванка разрезается на слои, называемые пластинами (wafers). Они полируются до безупречной зеркальной поверхности. На этой пластине и создается чип. Обычно из одной пластины делается много процессоров.
Электрическая схема состоит из разных материалов. Например, диоксид кремния - это изолятор, из полисиликона изготавливаются проводящие дорожки. Когда появляется открытая пластина, она бомбардируется ионами для создания транзисторов - это и называется присадкой.
Чтобы создать все требуемые детали, на всю поверхность пластины добавляется слои и лишние части вытравливаются вновь. Чтобы сделать это, новый слой покрывается фоторезистором, на который проектируется образ требуемых деталей. После экспозиции проявление удаляет те части фоторезистора, которые выставлены на свет, оставляя маску, через которую проходило вытравливание. Оставшийся фоторезистор удаляется растворителем.
Говоря о скорости процессора, подразумевается его тактовая частота. Это величина, измеряемая в мегагерцах (МГц), показывает, сколько инструкций способен выполнить процессор в течение секунды. Тактовая частота обознается цифрой в названии процессора (например, Pentium 4-2400, то есть процессор поколения Pentium 4 с тактовой частотой 2400 МГц или 2.4 ГГц).
Тактовая частота – бесспорно, самый важный показатель скорости работы процессора. Но далеко не единственный.
Системная шина (FSB = Front Side Bus или System Bus) служит для связи процессора с остальным компьютером. Системная шина является основой для формирования частоты других шин передачи данных компьютера – AGP, память, PCI, путем умножения на определенный коэффициент.
Современные процессоры работают быстрее, чем память.Чем медленнее память, тем больше процессору ждать новых данных от нее и ничего не делать. В кэш памяти находятся машинные слова (можно их назвать данными), которые чаще всего используются процессором. Если ему требуется какое-нибудь слово, то он сначала обращается к кэш памяти. Существует принцип локализации, по которому в кэш вместе с требуемым в данный момент словом загружаются также и соседние с ним слова, т.к. велика вероятность того, что они в ближайшее время тоже понадобятся. В современных десктопных процессорах существует два уровня кэш-памяти (для серверов существует процессоры с третьим уровнем кэша, его также). Кэш первого уровня (Level 1 = L1) обычно разделён пополам, половина выделена для данных, а другая половина под инструкции. Кэш второго уровня (Level 2 = L2) предназначается только для данных. Пропускная способность оперативной памяти конечно высока, но кэш память работает в несколько раз быстрее. У старых процессоров микросхемы кэша L2 находились на материнской плате. Скорость работы кэша при этом была довольно низкой (равнялась частоте FSB), но её хватало. У последних процессоров, в целях увеличения быстродействия, упрощения и удешевления производства, кэш L2 интегрирован в ядро и работает на его полной частоте. Чем больше кэш, тем лучше, но с другой стороны, при увеличении кэша увеличивается время выборки (поиска и извлечения) данных из него. Хотя увеличение кэша L2, не смотря на это, почти всегда дает прирост по скорости.
Ядром называют сам процессорный кристалл, ту часть, которая непосредственно является "процессором". Сам кристалл у современных моделей имеет небольшие размеры, а размеры готового процессора увеличиваются очень сильно за счет его корпусировки и разводки. Процессорный кристалл можно увидеть, например, у процессоров Athlon, у них он не закрыт. У P4 вся верхняя часть скрыта под теплорассеивателем (который так же выполняет защитную функцию
Форм-фактор – это тип исполнения процессора, его «внешности» и способа подключения к материнской плате.
Как правило, все элементы процессора расположены на одном и том же кристалле кремния и имеют квадратную форму (тип разъёма «Socket»). Прямоугольный корпус с торчащими из него ножками-контактами.
Процессоры имеют разные разъёмы по причине принципиальных конструктивных отличий (количество транзисторов, архитектура и т. п.). Пока было только два принципиально разных типа разъёмов - Slot и Soсket. По заверениям Intel (но если посмотреть на Pentium Pro, то всё становится ясно), Slot 1 был использован только из-за необходимости помещения кэша поближе к ядру и больше применяться, скорее всего, не будет. Socket же продолжает развиваться - количество контактов все растёт и растёт (если увеличение числа контактов можно считать развитием)
Коэффициент умножения (Frequency Ratio / Multiplier), это то число, на которое умножается частота системной шины, в результате чего получается рабочая частота процессора. Заблокированный коэффициент означает, что процессор будет умножать системную шину всегда на одну и ту же цифру. Т. е. разгон без увеличения частоты шины для такого процессора невозможен.
Обобщенная структурная схема процессора.

IB
Схема состоит из:
GR – регистр общего назначения
ALU – арифметико-логическое устройство
A – регистр аккумулятор
RB – буферный регистр
F – регистр флагов (признаков)
IP – указатель команд (счетчик команд)
RI (IR) – регистр команд
DC – дешифратор команд
CU – устройство управления
IB –внутренняя общая магистраль
FB – устройство сопряжения с внешней шиной.
Код операции попадает в регистр команд, затем в дешифратор и в устройство управления.
В регистр флагов записывается:
1) С – carry (переполнение)
2) Z (флаг) – z=1, если результат равен 0, z=0 если результат не равен 0.
3) S – флаг указания положительного или отрицательного результата (положительный – s=0, отрицательный – s=1)
4) P – флаг четности (четное либо нечетное количество единиц в операнде)
р=1 – четное число единиц; р=0 – нечетное число единиц;
При выполнении арифметических и логических операций флаги формируются всегда.
Флаги помогают организовать ветвление программы.

Основными особенностями организации современных микропроцессоров и микро-ЭВМ является:
А) Модульная структура, в которой модули являются функционально законченными устройствами
Б) Магистральная организация связей между модулями, при которой общие шины используются разными модулями
В) Микропрограммное управление
Г) Байтовая адресация памяти и побайтовая обработка данных
Д) Использование внутренних сверхоперативных регистров.
В структуре можно выделить три основные части: центральный процессор, блок управления и постоянная память микропрограмм. Центральный процессор содержит АЛУ, сверхоперативную память в виде программно доступных общих регистров и функциональные регистры – командный, индексный, адресный, указатель стека и программный счетчик. АЛУ состоит из двоичного сумматора, сдвигающего регистра, двух регистров операндов и регистра результата. Схемы АЛУ выполняют команды сложения, вычитания, логическое И, ИЛИ, сложение по модулю 2 и сдвигов. Более сложные операции реализуются программно. Блок микропрограммного управления содержит дешифратор кода операции, схему формирования функций перехода к следующему адресу в микропрограмме и регистр адреса микрокоманды. Система прерывания в микропроцессорах достаточно проста и предназначена только для восприятия прерываний от внешних источников. Микропроцессоры имеют упрощенные схемы управления ПУ. В значительной степени управление этими устройствами реализуется посредством микропрограммного управления. Блок постоянной памяти микропрограмм, реализующих команды микропроцессора, обычно выполняется в виде отдельной БИС. В микропроцессорах используют косвенную, непосредственную, индексную адресации основной оперативной памяти и прямую адресацию общих регистров. Сверхоперативная память на общих регистрах, позволяет сократить количество обращений к внешней памяти и уменьшить необходимое количество выводов корпуса за счет сокращения формата команды. Из-за ограниченного числа выводов корпуса БИС не удается реализовать интерфейс микропроцессора с высокой пропускной способностью. Поэтому микропроцессоры имеют так называемый общий интерфейс, обслуживающий как внешнюю оперативную память, так и ПУ. Если не удается выделить для интерфейса достаточное количество выводов, применяют мультиплексирование шин (использование шин для разных целей на основе разделения времени). Для обеспечения совместной работы микропроцессора и внешнего оборудования шины интерфейса снабжаются буферными схемами, в которых используются электронные схемы с тремя состояниями и спец. линии управления выдачи данных.
В любом устройстве обработки цифровой информации можно выделить операционный и управляющий блоки. Такой подход упрощает проектирование, а также облегчает понимание процесса функционирования вычислительного устройства.
Операционный блок состоит из регистров, сумматоров и других узлов, производящих прием из внешней среды и хранение кодов, их преобразование и выдачу результатов работы во внешнюю среду, а также выдачу в управляющий блок и внешнюю среду оповещающих сигналов.
Процесс функционирования во времени устройства обработки состоит из последовательности тактовых интервалов, в которых операционный блок производит элементарные преобразования кодов (передачу кода из одного регистра в другой, взятие обратного кода, сдвиг и т.д.).
Элементарная функциональная операция, выполняемая за один тактовый интервал и приводимая в действие одним управляющим сигналом называется микрооперацией.
Управляющий блок вырабатывает распределенную во времени последовательность управляющих сигналов, порождающих в операционном блоке нужную последовательность микроопераций.
Последовательность управляющих сигналов (микрокоманд) определяется кодом операции, поступающим извне, состоянием операндов и промежуточными результатами преобразований.
Существует два основных типа управляющих автоматов:
1) Управляющий автомат с жесткой логикой.
Для каждой операции, задаваемой кодом операции команды, строится набор комбинационных схем, которые в нужных тактах возбуждают соответствующие управляющие сигналы.
2) Управляющий автомат с хранимой в памяти логикой.
Каждой выполняемой в операционном устройстве операции ставится в соответствие совокупность хранимых в памяти слов - микрокоманд, содержащих информацию о микрооперациях, подлежащих выполнению в течение одного машинного такта, и указание, какая микрокоманда должна выполняться следующей.
Последовательность микрокоманд, обеспечивающая выполнение некоторой операции (например, умножения), называется микропрограммой данной операции.
26. Человек как звено асоиу. Выбор канала восприятия в зависимости от вида информации. Эргономический пользовательский интерфейс
Человек как звено АСОИУ
В зависимости от реализуемого уровня автоматизации и выполняемых функций различают несколько типов систем автоматизации.
Быстродействия человека в большом числе случаев не хватает для управления быстро протекающими процессами. Кроме того, он постепенно устает, теряет внима¬ние... САУ свободны от этих недостатков. Таким образом, одна из целей автоматизации - заменить человека там, где его возможностей не хватает для обеспечения нужного ка¬чества управления. Автоматика освобождает человека от тяжелого, монотонного или рутинного труда, заменяет его во вредных и опасных для здоровья условиях окружаю¬щей среды.
Теория и практика создания САУ способны предложить технические решения как в "нештатных" ситуациях, так и при недостатке знаний об объекте. Это различные спо¬собы диагностики и резервирования систем, алгоритмы адаптации, самонастройки и самообучения. Можно многое, но нужно ли делать это? Здесь на первый план выходят экономические аспекты автоматизации.
С определенной точки зрения САУ являются простейшими по своей организации системами, так как алгоритм управления, хранящийся в управляющем устройстве, дол¬жен полностью соответствовать поведению системы как правило, замкнутой обратны¬ми связями) во всевозможных ситуациях, включая выход из строя отдельных элементов системы. Для этого необходимо знать свойства объекта и не только знать, но и уметь измерять их, т.е. оценивать количественно, в процессе функционирования системы. Это не всегда удается по ряду причин: сложность объекта управления, тяжелые условия для работы датчиков обратных связей, непостоянство свойств объекта правления.... Пред¬ставьте робота за рулем автомобиля.
Структура АСУ автономным объектом по сравнению с САУ содержит дополни¬тельное звено - оператора. Участие человека в управлении объясняется недетерминиро¬ванностью или недостаточной изученностью некоторых этапов управления, чрезмерно сложностью их полной автоматизации или технической сложностью получения полно¬го набора требуемых для управления входных сигналов непосредственно с объекта. Недостаток информации оператор компенсирует не толь с помощью своих органов чувств, но также за счет интуиции и способности к обучению.
Наличие в АСУ чел о века-оператора дополнительно усложняет систему, так как требует специальных средств ввода сигналов от оператора (кнопок, переключатели и другие органы управления, объединенные в пульты /правления и рабочее место опера¬тора) и средств отображения информации с переходом к десятичной системе счисления или графическим средствам (сигнальные лампы, стрелочные и цифровые индикаторы, совмещенные с мнемоническими схемами, табло, дисплеи).
При управлении сложными и многочисленными объектами взаимодействие опе¬ратора со средствами ввода/вывода информации становится серьезной проблемой не столько технического плана, сколько комплексной проблемой технического дизайна, эргономики и инженерной психологии. Наиболее остро это проявляется в почти полно¬стью автоматизированных системах управления особо ответственными объектами (атомные реакторы, летательные аппараты, рельсовый транспорт, непрерывные прокатные станы), где за оператором остаются только функции наблюдения за работой системы и вмешательства при возникновении аварийных ситуаций. Для выработки у операторов необходимых навыков приходится создавать целые тренажерные комплек¬сы, имитирующие поведение системы в различных режимах.
Различают четыре степени автоматизации или режима работы АСУ:
• Индикаторный режим, в котором системой производится контроль параметров объекта управления, сигнализация выхода их значений за допустимые пределы, ве¬дение рабочих журналов, документирование итогов работы. Все управление осу¬ществляется оператором.
• Режим советчика отличается от предыдущего тем, что в дополнение к сказанному система управления обеспечивает более совершенную обработку информации и выработку конкретных предложений (рекомендуемых управляющих воздействий или задающих уставок) для достижения оптимального режима работы объекта.
• В режиме помощника большую или меньшую часть задач управления решает АСУ, упрощая и облегчая оператору управление. Например, система берет на себя функцию формирования требуемой плавной траектории движения, оставляя за оператором только выбор моментов начала разгона и торможения механизма. Сле¬дует заметить, что в любой ситуации управляющие воздействия оператора имеют более высокий приоритет по отношению к воздействиям, формируемым системой.
• Режим автоматического управления полностью исключает оператора из замкнуого контура управления на период нормального функционирования системы
Выбор канала восприятия в зависимости от вида информации. Эргономический пользовательский интерфейс
Пользовательский интерфейс.
Нас с прикладной точки зрения прежде всего будет интересовать пользовательский интерфейс. Разработчики программных комплексов зачастую склонны рассматривать функциональность системы отдельно от её пользовательского интерфейса. При этом предполагается, что ПИ является своего рода дополнением к функциональности системы. Со своей стороны, пользователи программ, как правило, не разделяют функциональность и пользовательский интерфейс. Для пользователей именно ПИ является программой. Для них, если интерфейс хороший, стало быть и сама программа хороша и удобна.
Пользовательский интерфейс часто понимают только как внешний вид программы. Однако на деле пользователь воспринимает через ПИ всю систему в целом, а значит, такое понимание ПИ является слишком узким. В действительности ПИ включает в себя все аспекты дизайна, которые оказывают влияние на взаимодействие пользователя и системы. Это не только экран, который видит пользователь. Пользовательский интерфейс состоит из множества составляющих, таких как:
• набор задач пользователя, которые он решает при помощи системы
• используемая системой метафора (например, рабочий стол в MS Windows и т.п.)
• элементы управления системой
• навигация между блоками системы
• визуальный (и не только) дизайн экранов программы.
Давно уже существуют технологии, позволяющие существенным образом улучшить ПИ. Однако сами по себе они не производят эргономичных интерфейсов. Так, например, сам по себе графический интерфейс пользователя не является более эргономичным, чем текстовый интерфейс, и, как показывает опыт, может быть менее пригоден к использованию, если разработан неправильно.
Для большинства систем на разработку ПИ уходит значительная доля бюджета и усилий программистов (количества строчек исходного текста программы). Проведенные исследования указывают на то, что:
• ПИ составляет от 47 до 60 процентов кода всей программы
• на разработку ПИ уходит как минимум 29 процентов проектного бюджета и в среднем 40 процентов всех усилий разработчиков по созданию системы.
Поскольку с точки зрения пользователя ПИ является ключевым фактором для понимания функциональности программы, плохо разработанный интерфейс резко ограничивает функциональность системы в целом. Компании, которые не стремятся провести разработку эргономичного ПИ для своих продуктов и получить все преимущества, которые обеспечивают современные технологии, ослабляют свои позиции в конкурентной борьбе.
Своевременно и профессионально выполненная разработка интерфейса приводит к увеличению эффективности ПО, уменьшению длительности обучения пользователей, снижению стоимости переработки системы после ее внедрения, полному использованию заложенной в ПО функциональности и т.п.
Отсутствие должного внимания со стороны разработчика программного обеспечения к интерфейсу может привести к резко негативным последствиям. Вот несколько реальных примеров:
• Некая страховая компания инвестировала три миллиона долларов в информационную систему, предназначенную для поддержки работы независимых агентов, продающих ее услуги. Через некоторое время после внедрения системы, агенты полностью отказались от ее использования, поскольку не смогли обучиться работе с ней.
• Крупная финансовая организация была вынуждена отказаться от почти полностью разработанной информационной системы, так как незадолго до ее внедрения компанией-разработчиком было проведено юзабилити–исследование, обнаружившее ошибку, допущенную при проектировании ПИ в модуле, ответственном за ввод данных. Ошибка была такова, что пользователи отказывались от использования модуля. На этом этапе было уже невозможно произвести необходимые изменения, в результате система так и не была внедрена.
• Полный цикл обучения некоторым системам занимает до шести месяцев. При этом средний срок работы служащих на одном месте составляет всего восемнадцать месяцев.
• Мощная и достаточно дорого обошедшаяся функциональность ПО для службы персонала никогда не была использована, потому что пользователи "разучивались" пользоваться ею уже через неделю после окончания обучения.
Между тем, ожидания пользователей меняются. Они уже знают, что создание
программного обеспечения с дружественным интерфейсом возможно, и ожидают, что
информационная система, которую они используют на работе, будет конкурентна по
удобству и простоте освоения.
Преимущества хорошего ПИ
Системы, разработанные с учетом требований юзабилити, эргономичны. Они работают именно так, как пользователи ожидают, и позволяют пользователям фокусироваться на собственных задачах, а не особенностях взаимодействия с системой. Эргономичные программные продукты проще изучить, они более эффективны, они также позволяют минимизировать количество человеческих ошибок и увеличить субъективную удовлетворенность пользователей. Но это не случается само по себе. Эффективный интерфейс является результатом осознания разработчиком необходимости уделить значительное внимание не только данным, с которыми будет работать пользователь, но и собственно пользователю, его задачам и деятельности.
Выделим несколько наиболее существенных преимуществ хорошего пользовательского интерфейса с точки зрения бизнеса:
• Снижение количества человеческих ошибок
• Снижение стоимости поддержки систем
• Снижение стоимости обучения
• Уменьшение потерь продуктивности работников при внедрении системы и более быстрое восстановление утраченной продуктивности
• Улучшение морального состояния персонала
• Уменьшение расходов на редизайн ПИ по требованию пользователей
• Доступность функциональности системы для максимального количества пользователей
Почти всегда при внедрении информационных систем общая эффективность организации увеличивается, при этом ряд исследований показывает, что грамотно разработанные ПИ может значимо увеличить эффективность по сравнению с просто внедренной ИС.
• Одно из проведенных исследований, показало, что производительность увеличилась на четверть, а количество человеческих ошибок уменьшилось на четверть после проведения редизайна ПИ с учетом принципов юзабилити.
• В другой компании обнаружилось, что, помимо прочих положительных эффектов, проведение полной переработки ПИ позволило сократить время обучения персонала на 35%, и повысить производительность труда в целом.
Исследование компании IBM показало, что проведенный с учетом человеческого фактора полный редизайн одной из их систем позволил сократить время обучения пользователей до одного часа. До проведения редизайна на изучение системы уходила неделя.
27. Микропроцессоры с «жестким» и программируемым принципами управления Организация режимов работы процессоров
Режимы работы ЭВМ IBM PC с центральным процессором (ЦП) 80х86 (x > 2)
ЭВМ IВМ РС с ЦП 8086 могла работать только в так называемом реальном режиме. Начиная с ЦП 80286 появилась возможность использования защищенного режима работы, однако вскоре появился более современный ЦП 80386, основные особенности архитектуры которого нашли свое отображение и в следующих моделях ряда этих ЦП: 80486, 80586 и т.д. Поэтому режимы функционирования ряда этих ЦП будем рассматривать для ЦП 80386 и выше. Каждый из этих ЦП может функционировать в одном из трех режимов: реальном, защищенном и виртуальном; далее будут кратко рассмотрены основные особенности функционирования и использования этих режимов.
Реальный режим работы ЦП 80386
При включении питания или после сигнала "Сброс" ЦП 80386 устанавливается в реальный режим работы, который соответствует ЦП 8086 с добавлением возможности использования 32-разрядных регистров. Механизм адресации, пространство адресов памяти, управление прерываниями осуществляется аналогично реальному режиму ЦП 8086. В реальном режиме могут использоваться любые команды ЦП 80386. Размер операнда по умолчанию в реальном режиме составляет 16 бит, как и у ЦП 8086. Для того, чтобы использовать 32-разрядные регистры, необходимо предварительно выполнить соответствующую настройку выполняемой программы. Размер сегмента в реальном режиме равен 64К байт, поэтому 32-разрядные адреса должны быть меньше, чем 0000FFFFh. В реальном режиме максимальный размер памяти составляет 1М байт. Так как в реальном режиме не используется страничная адресация, то линейный адрес равен физическому.
Физические адреса, как и в ЦП 8086, формируются в реальном режиме сложением содержимого соответствующего сегментного регистра, который сдвигается влево на 4 разряда, с исполнительным адресом, указанным в команде. В результате создается адресное пространство, определяемое 20-разрядным физическим адресом, т.е. равное 1М плюс 64К байт.
В реальном режиме имеется две зарезервированные области памяти: зона системной инициализации, находящаяся по адресам с FFFFFFF0h по FFFFFFFFh, и зона таблицы прерываний, находящаяся по адресам с 00000h по 003FFh.
В настоящее время реальный режим на ЭВМ IВМ РС с ЦП 80386 используется для реализации двух целей:
1. выполнения на этих ЭВМ программ, написанных под MS DOS или другие родственные ей ОС;
2. для подготовки перехода этой ЭВМ в защищенный режим.
Защищенный режим работы ЦП 80386
Возможности ЦП 80386 раскрываются полностью, если он работает в защищенном режиме. Защищенный режим позволяет использовать дополнительные команды, специально предназначенные для многозадачных ОС. Главные отличия защищенного режима от реального состоят в следующем:
1. адресное пространство расширяется до 4Г байт, а область виртуальных адресов - до 64Т байт, т.е. практически не ограничена;
2. используются другие механизмы адресации, при этом существенно, что выполняемой в каком-то отрезке времени задаче выделяется определенная область оперативной памяти (ОП), за пределы которой задача не может обращаться, - при попытке такого обращения возникает так называемое нарушение общей защиты, вследствие чего выполнение задачи прекращается и включается принадлежащая ОС программа обработки прерывания по этой причине;
3. используется другая область ОП для размещения векторов прерываний, при этом ввиду того, что номера векторов для одинаковых по смыслу событий могут различаться в этих режимах и к тому же сами наборы прерываний отличаются между собой, при переходе из одного режима в другой требуется произвести соответствующую настройку аппаратных средств с помощью команд программы, производящей переключение из режима в режим.
Защищенный режим может использоваться в следующих случаях:
1. для использования ЭВМ в многопользовательском режиме, например, если ЭВМ является сервером вычислительной сети и на нем установлена многопользовательская ОС для обслуживания запросов рабочих станций этой сети;
2. для использования ЭВМ в однопользовательском многозадачном режиме;
3. для использования ЭВМ в однопользовательском однозадачном режиме, но при этом для решения задачи необходимо выделение ей объема ОП, превышающего величину 1М байт;
4. для использования ЭВМ в однопользовательском однозадачном режиме, но при этом используемая ОС предоставляет пользователю для общения с ЭВМ интерфейс, существенно превосходящий по своим возможностям интерфейс, предоставляемый MS DOS (такие возможности обеспечивают ОС типа Windows).
Виртуальный режим работы ЦП 80386 (режим V86). Эмуляция MS DOS в режиме V86. Основной целью использования режима V86 является одновременное выполнение программ, написанных под MS DOS, под управлением многопользовательской ОС. При этом у каждого пользователя создается иллюзия монопольного владения всеми ресурсами ЭВМ.
Реальный режим работы ЦП 80386, эмулирующий ЦП 8086, и режим виртуального ЦП 8086, работающий в защищенном режиме ЦП 80386, несколько различаются. Когда ЦП работает в режиме V86, его селекторы, несмотря на то, что включен защищенный режим, интерпретируются также, как и в реальном режиме. Эффективный адрес при этом получается сложением смещения со сдвинутым на 4 разряда влево содержимым сегментного регистра. На ОС возлагаются обязанности по определению программ, использующих механизм адресации ЦП 8086, и программ, использующих адресацию собственно ЦП 80386. Отличие адресации виртуального ЦП 8086 от реального заключаются в использовании механизма страничной адресации, благодаря которому адресное пространство задачи в 1М байт может быть размещено в любом месте пространства линейных адресов ЦП 80386 объемом 4Г байт. Адреса, превышающие величину 1М в режиме виртуального ЦП 8086, будут вызывать возникновение прерывания 13 защищенного режима (нарушение общей защиты).
Все программы виртуального режима выполняются на уровне привилегированности 3, т.е. на низшем уровне, в отличие от реального режима, который всегда имеет уровень привилегированности 0, т.е. высший уровень. Поэтому попытка выполнить в виртуальном режиме привилегированную команду также приведет к возникновению прерывания 13.
Аппаратные средства страничной адресации поддерживают параллельную работу нескольких задач, использующий виртуальный режим, и обеспечивают защиту и независимость работы их ОС. Эти средства могут использоваться в многозадачных ОС для обеспечения одновременного выполнения нескольких задач.
Важнейшей чертой программ реального режима является широкое использование средств MS DOS и BIOS. Поэтому виртуальный режим может иметь право на вектора программного прерывания) и передача управления через этот вектор требуемой программе ОС, которая, очевидно, должна выполняться опять в режиме V86. Всю эту процедуру иногда называют "отражением" прерывания на MS DOS (или другую ОС реального режима), или "эмуляцией" DOS в режиме виртуального ЦП 8086. Подобная эмуляция должна осуществляться и при возникновении аппаратных прерываний, обеспечивая обычно их обработку с помощью BIOS.
Таким образом многозадачная ОС, выполняемая на ЦП 80386, может полностью моделировать вызовы однозадачной ОС, например, MS DOS. Кроме того, эта многозадачная ОС должна также выполнять подобным образом производить обработку команд обращения задач, выполняемых в режиме V86, к портам ввода-вывода - команд in и out.
Принципы обеспечения в ОС многозадачного и многопользовательского режимов (на примере ОС типа Windows)
Наиболее характерные примеры, когда возникает необходимость использования таких ОС:
- при размещении ОС на сервере вычислительной сети для управления работой этой сети;
- при управлении работой супер-ЭВМ, работающей в режиме разделения времени;
- при управлении работой системой реального времени, для которых характерна ситуация, когда процесс обслуживания одной заявки может быть прерван ввиду необходимости срочного обслуживания вновь поступившей заявки.
Кроме того, использование многозадачной ОС может оказаться весьма целесообразно и на обычной персональной ЭВМ, например, на фоне вывода на печать уже отредактированной части текста продолжается редактирование другой части текста, и т.д.
По числу одновременно выполняемых задач ОС можно разделить на однозадачные и многозадачные, но на самом деле можно произвести и более подробную классификацию по этому признаку:
- однозадачные ОС (MS DOS в значительной части случаев ее использования);
- использование в среде MS DOS резидентных программ (TSR), включаемых или по вызову пользователя, например, нажатием заданной комбинации клавиш, или от системного таймера; главный недостаток при использовании TSR заключается в отсутствии реентерабельности (повторной входимости) функций MS DOS и BIOS, вызываемых программами пользователей;
- невытесняющая многозадачность, реализованная в Windows 3.0 и Windows 3.1, явилась шагом вперед по сравнению с использованием резидентных программ, так как при использовании этих вновь созданных программных продуктов была решена проблема реентерабельности для ОС; суть невытесняющей многозадачности состоит в том, что передача управления от программы к программе производится тогда, когда выполняемая в данный момент программа этого "пожелает", что является крупным недостатком метода ввиду отсутствия учета приоритетов при предоставлении задачам времени ЦП и вследствие этого низкой эффективности его использования;
- вытесняющая многозадачность, реализованная в ОС типа Windows, начиная с Windows 95, в ОС Unix и т.д., при которой каждой задаче предоставляется для ее выполнения ограниченный квант времени, вследствие чего существенно возрастает эффективность использования времени ЦП по сравнению со случаем использования невытесняющей многозадачности.
Характерные свойства современных многозадачных и многопользовательских ОС
1. Вытесняющая многозадачность;
2. Реентерабельность программ этих ОС;
3. Исключение из процесса обслуживания тех задач пользователей, в процессе решения которых проявились ошибки, которые делают невозможным дальнейшее выполнение этих задач без внесения пользователем коррекции в программу или начальные данные этих же задач; сообщение о сложившейся ситуации выдается на экран монитора пользователя, а процесс обслуживания задач других пользователей при этом не прекращается;
4. Адресное пространство ОП каждой задачи и ОС должно быть защищено от воздействия друг друга; эта защита организуется при блоковой организации ОП (подобная защита отсутствует при функционировании MS DOS, так как при этом используется реальный режим работы ЦП 80х86, в котором отсутствуют средства рассматриваемой защиты);
5. Учитывая, что каждой задаче выделяется относительно небольшой квант времени, обычно порядка нескольких десятков милисекунд, и поэтому переключение с задачи на задачу происходит сравнительноно часто, целесообразно иметь ОП достаточно большого объема, так как в противном случае будут иметь место весьма большие потери времени на обмен данными между ОП и дисковой памятью;
6. Целесообразно, чтобы ОС поддерживала механизм реализации виртуальной памяти, для чего в ОС должен иметься обработчик прерывания, возникающего при обращении к незагруженному в ОП блоку, и средства взаимодействия с ОП, имеющей блочную организацию;
7. Для многопользовательских ОС должен быть предусмотрен ввод имен пользователей и их паролей, причем передачу пароля от терминала пользователя к ЦП ЭВМ предпочтительнее производить в закодированном виде с целью усложнения проникновения злоумышленников к данным, содержащимся в ЭВМ;
8. ОС должна содержать средства синхронизации взаимодействующих задач, необходимость в использовании которых может возникнуть в следующих случаях:
- при использовании задачами общих данных;
- при наличии в задачах критических секций, во время выполнения любой из которых задача не может быть прервана, что в особенности характерно для ОС в системах реального времени;
- при ожидании основной задачей, когда организованная ей вспомогательная задача подготовит для нее данные.
9. ОС должна содержать средства, которые управляют доступом различных задач к файлам на жестком диске; примерами таких средств являются матрица доступа пользователей к файлам и управление доступом к файлам в зависимости от принадлежности пользователя к тому или иному классу.
10.Задачи пользователей не должны иметь непосредственный доступ к системным ресурсам: портам устройств ввода-вывода, установке векторов прерываний и т.д.; при этом все управление системными ресурсами должно осуществляться только самой ОС, в том числе и по заданию задач пользователей.
28. Основные показатели качества систем автоматического управления

Прямые показатели качества определяются по переходному процессу замкнутой системы. Переходной процесс (h(t)) это реакция на единичную ступенчатую функцию.



Рассмотрим два случая.
а) Есть интегрирующее звено.


б) Нет интегрирующего звена.


hуст. не обязательно равно 1.
Показатели качества.
Точность САУ. Характеризуется:
 ;
;
2. Время
регулирования tp
–это время, в течении которого переходной
процесс попадает в некоторую
 зону и не выходит из неё. (
зону и не выходит из неё. (
3. (только для колебательных процессов)
Максимальное
перерегулирование

Относительное перерегулирование

Время первого максимума tM (характеризует быстродействие, нарастание процесса);
Ч
 исло
перерегулирований N.
Число максимумов на время
исло
перерегулирований N.
Число максимумов на время
 .
.
Косвенные показатели качества делятся на:
Частотные
Корневые
Интегральные
Частотные показатели качества характеризуют удаленность системы от границы устойчивости.
Критерий Найквиста.


 -запас
устойчивости по амплитуде (зависит от
К и Т).
-запас
устойчивости по амплитуде (зависит от
К и Т).
АЧХ зависит в большей степени от коэффициента усиления. Поэтому запас устойчивости по амплитуде показывает насколько может быть увеличен К, чтобы замкнутая система оставалась устойчивой.
Запас устойчивости по фазе показывает насколько могут изменяться постоянные времени, чтобы замкнутая система оставалась устойчивой.



Кпред.-предельный коэффициент усиления, может быть найден по годографу. Это предельный коэффициент усиления разомкнутой системы , при котором замкнутая система попадает на границу устойчивости.
 ;
;
Если предельный коэффициент усиления больше коэффициента усиления разомкнутой системы, то система устойчива и обладает запасом устойчивости (по фазе, модулю). В противном случае - система неустойчива.
29. Устройства для логической структуризации сетей (мосты и коммутаторы)
Несмотря на появление новых дополнительных возможностей основной функцией концентраторов остается передача пакетов по общей разделяемой среде. Коллективное использование многими компьютерами общей кабельной системы в режиме разделения времени приводит к существенному снижению производительности сети при интенсивном трафике. Общая среда перестает справляться с потоком передаваемых кадров и в сети возникает очередь компьютеров, ожидающих доступа. Это явление характерно для всех технологий, использующих разделяемые среды передачи данных, независимо от используемых алгоритмов доступа (хотя наиболее страдают от перегрузок трафика сети Ethernet с методом случайного доступа к среде).
Поэтому сети, построенные на основе концентраторов, не могут расширяться в требуемых пределах - при определенном количестве компьютеров в сети или при появлении новых приложений всегда происходит насыщение передающей среды, и задержки в ее работе становятся недопустимыми. Эта проблема может быть решена путем логической структуризации сети с помощью мостов, коммутаторов и маршрутизаторов.
Мост (bridge), а также его быстродействующий функциональный аналог - коммутатор (switching hub), делит общую среду передачи данных на логические сегменты. Логический сегмент образуется путем объединения нескольких физических сегментов (отрезков кабеля) с помощью одного или нескольких концентраторов. Каждый логический сегмент подключается к отдельному порту моста/коммутатора (рис. 1.10). При поступлении кадра на какой-либо из портов мост/коммутатор повторяет этот кадр, но не на всех портах, как это делает концентратор, а только на том порту, к которому подключен сегмент, содержащий компьютер-адресат.
Разница между мостом и коммутатором состоит в том, что мост в каждый момент времени может осуществлять передачу кадров только между одной парой портов, а коммутатор одновременно поддерживает потоки данных между всеми своими портами. Другими словами, мост передает кадры последовательно, а коммутатор параллельно. (Для упрощения изложения далее в этом разделе будет использоваться термин "коммутатор" для обозначения этих обоих разновидностей устройств, поскольку все сказанное ниже в равной степени относится и к мостам, и к коммутаторам.) Следует отметить, что в последнее время локальные мосты полностью вытеснены коммутаторами. Мосты используются только для связи локальных сетей с глобальными, то есть как средства удаленного доступа, поскольку в этом случае необходимость в параллельной передаче между несколькими парами портов просто не возникает.

Рис. 1.10. Разделение сети на логические сегменты
При работе коммутатора среда передачи данных каждого логического сегмента остается общей только для тех компьютеров, которые подключены к этому сегменту непосредственно. Коммутатор осуществляет связь сред передачи данных различных логических сегментов. Он передает кадры между логическими сегментами только при необходимости, то есть только тогда, когда взаимодействующие компьютеры находятся в разных сегментах.
Деление сети на логические сегменты улучшает производительность сети, если в сети имеются группы компьютеров, преимущественно обменивающиеся информацией между собой. Если же таких групп нет, то введение в сеть коммутаторов может только ухудшить общую производительность сети, так как принятие решения о том, нужно ли передавать пакет из одного сегмента в другой, требует дополнительного времени.
Однако даже в сети средних размеров такие группы, как правило, имеются. Поэтому разделение ее на логические сегменты дает выигрыш в производительности - трафик локализуется в пределах групп, и нагрузка на их разделяемые кабельные системы существенно уменьшается.
Коммутаторы принимают решение о том, на какой порт нужно передать кадр, анализируя адрес назначения, помещенный в кадре, а также на основании информации о принадлежности того или иного компьютера определенному сегменту, подключенному к одному из портов коммутатора, то есть на основании информации о конфигурации сети. Для того, чтобы собрать и обработать информацию о конфигурации подключенных к нему сегментов, коммутатор должен пройти стадию "обучения", то есть самостоятельно проделать некоторую предварительную работу по изучению проходящего через него трафика. Определение принадлежности компьютеров сегментам возможно за счет наличия в кадре не только адреса назначения, но и адреса источника, сгенерировавшего пакет. Используя информацию об адресе источника, коммутатор устанавливает соответствие между номерами портов и адресами компьютеров. В процессе изучения сети мост/коммутатор просто передает появляющиеся на входах его портов кадры на все остальные порты, работая некоторое время повторителем. После того, как мост/коммутатор узнает о принадлежности адресов сегментам, он начинает передавать кадры между портами только в случае межсегментной передачи. Если, уже после завершения обучения, на входе коммутатора вдруг появится кадр с неизвестным адресом назначения, то этот кадр будет повторен на всех портах.
Мосты/коммутаторы, работающие описанным способом, обычно называются прозрачными (transparent), поскольку появление таких мостов/коммутаторов в сети совершенно не заметно для ее конечных узлов. Это позволяет не изменять их программное обеспечение при переходе от простых конфигураций, использующих только концентраторы, к более сложным, сегментированным.
Существует и другой класс мостов/коммутаторов, передающих кадры между сегментами на основе полной информации о межсегментном маршруте. Эту информацию записывает в кадр станция-источник кадра, поэтому говорят, что такие устройства реализуют алгоритм маршрутизации от источника (source routing). При использовании мостов/коммутаторов с маршрутизацией от источника конечные узлы должны быть в курсе деления сети на сегменты и сетевые адаптеры, в этом случае должны в своем программном обеспечении иметь компонент, занимающийся выбором маршрута кадров.
За простоту принципа работы прозрачного моста/коммутатора приходится расплачиваться ограничениями на топологию сети, построенной с использованием устройств данного типа - такие сети не могут иметь замкнутых маршрутов - петель. Мост/коммутатор не может правильно работать в сети с петлями, при этом сеть засоряется зацикливающимися пакетами и ее производительность снижается.
Для автоматического распознавания петель в конфигурации сети разработан алгоритм покрывающего дерева (Spanning Tree Algorithm, STA). Этот алгоритм позволяет мостам/коммутаторам адаптивно строить дерево связей, когда они изучают топологию связей сегментов с помощью специальных тестовых кадров. При обнаружении замкнутых контуров некоторые связи объявляются резервными. Мост/коммутатор может использовать резервную связь только при отказе какой-либо основной. В результате сети, построенные на основе мостов/коммутаторов, поддерживающих алгоритм покрывающего дерева, обладают некоторым запасом надежности, но повысить производительность за счет использования нескольких параллельных связей в таких сетях нельзя.
30. Маршрутизаторы как устройства для создания сложной иерархической структуры сетей
Подсети соединяются между собой маршрутизаторами. Компонентами составной сети могут являться как локальные, так и глобальные сети.
Сетевой уровень выступает в качестве координатора, организующего работу всех подсетей, лежащих на пути продвижения пакета по составной сети. Для перемещения данных в пределах подсетей сетевой уровень обращается к используемым в этих подсетях технологиям.
Чтобы сетевой уровень мог выполнить свою задачу, ему необходима собственная система адресации, не зависящая от способов адресации узлов в отдельных подсетях, которая позволила бы на сетевом уровне универсальным и однозначным способами идентифицировать любой узел составной сети. Естественным способом формирования сетевого адреса является уникальная нумерация всех подсетей составной сети и нумерация всех узлов в пределах каждой подсети. Таким образом, сетевой адрес представляет собой пару: номер сети (подсети) и номер узла.
Данные, которые поступают на сетевой уровень и которые необходимо передать через составную сеть, снабжаются заголовком сетевого уровня. Данные вместе с заголовком образуют пакет. Заголовок пакета сетевого уровня имеет унифицированный формат, не зависящий от форматов кадров канального уровня тех сетей, которые могут входить в объединенную сеть, и несет наряду с другой служебной информацией данные о номере сети, которой предназначается этот пакет. Сетевой уровень определяет маршрут и перемещает пакет между подсетями.
При передаче пакета из одной подсети в другую пакет сетевого уровня, инкапсулированный в прибывший канальный кадр первой подсети, освобождается от заголовков этого кадра и окружается заголовками кадра канального уровня следующей подсети. Информацией, на основе которой делается эта замена, являются служебные поля пакета сетевого уровня. В поле адреса назначения нового кадра указывается локальный адрес следующего маршрутизатора.
Кроме номера сети заголовок сетевого уровня должен содержать и другую информацию, необходимую для успешного перехода пакета из сети одного типа в сеть другого типа. К такой информации может относиться, например:
номер фрагмента пакета, необходимый для успешного проведения операций сборки-разборки фрагментов при соединении сетей с разными максимальными размерами пакетов;
время жизни пакета, указывающее, как долго он путешествует по интерсети, это время может использоваться для уничтожения «заблудившихся» пакетов;
качество услуги - критерий выбора маршрута при межсетевых передачах - например, узел-отправитель может потребовать передать пакет с максимальной надежностью, возможно, в ущерб времени доставки.
Когда две или более сети организуют совместную транспортную службу, то такой режим взаимодействия обычно называют межсетевым взаимодействием (internetworking).
Важнейшей задачей сетевого уровня является маршрутизация - передача пакетов между двумя конечными узлами в составной сети.
Задачу выбора маршрута из нескольких возможных решают маршрутизаторы, а также конечные узлы. Маршрут выбирается на основании имеющейся у этих устройств информации о текущей конфигурации сети, а также на основании указанного критерия выбора маршрута. Обычно в качестве критерия выступает задержка прохождения маршрута отдельным пакетом или средняя пропускная способность маршрута для последовательности пакетов. Часто также используется весьма простой критерий, учитывающий только количество пройденных в маршруте промежуточных маршрутизаторов (хопов).
Чтобы по адресу сети назначения можно было бы выбрать рациональный маршрут дальнейшего следования пакета, каждый конечный узел и маршрутизатор анализируют специальную информационную структуру, которая называется таблицей маршрутизации, имеющей следующие поля:
Номер сети назначения |
Сетевой адрес следующего маршрутизатора |
Сетевой адрес выходного порта |
Расстояние до сети назначения |
Задача маршрутизации решается на основе анализа таблиц маршрутизации, размещенных во всех маршрутизаторах и конечных узлах сети.
Для автоматического построения таблиц маршрутизации маршрутизаторы обмениваются информацией о топологии составной сети в соответствии со специальным служебным протоколом. Протоколы этого типа называются протоколами маршрутизации (или маршрутизирующими протоколами). Протоколы маршрутизации (например, RIP, OSPF) следует отличать от собственно сетевых протоколов (например, IP). И те и другие выполняют функции сетевого уровня модели OSI - участвуют в доставке пакетов адресату через разнородную составную сеть. Но в то время как первые собирают и передают по сети чисто служебную информацию, вторые предназначены для передачи пользовательских данных, как это делают протоколы канального уровня. Протоколы маршрутизации используют сетевые протоколы как транспортное средство. При обмене маршрутной информацией пакеты протокола маршрутизации помещаются в поле данных пакетов сетевого уровня или даже транспортного уровня, поэтому с точки зрения вложенности пакетов протоколы маршрутизации формально следовало бы отнести к более высокому уровню, чем сетевой.
В отличие от мостов, которые строят таблицу, пассивно наблюдая за проходящими через него информационными кадрами, посылаемыми конечными узлами сети друг другу, маршрутизаторы по своей инициативе обмениваются специальными служебными пакетами, сообщая соседям об известных им сетях в интерсети, маршрутизаторах и о связях этих сетей с маршрутизаторами. Обычно учитывается не только топология связей, но и их пропускная способность и состояние. Это позволяет маршрутизаторам быстрее адаптироваться к изменениям конфигурации сети, а также правильно передавать пакеты в сетях с произвольной топологией, допускающей наличие замкнутых контуров.
Если каждый маршрутизатор ответственен за выбор только одного шага маршрута, а окончательный маршрут складывается в результате работы всех маршрутизаторов, через которые проходит данный пакет, то такой алгоритм маршрутизации называется одношаговыми.
Существует и прямо противоположный, многошаговый подход - маршрутизация от источника (Source Routing). В соответствии с ним узел-источник задает в отправляемом в сеть пакете полный маршрут его следования через все промежуточные маршрутизаторы. При использовании многошаговой маршрутизации нет необходимости строить и анализировать таблицы маршрутизации. Это ускоряет прохождение пакета по сети, разгружает маршрутизаторы, но при этом большая нагрузка ложится на конечные узлы. Эта схема в вычислительных сетях применяется сегодня гораздо реже, чем схема распределенной одношаговой маршрутизации.
Одношаговые алгоритмы в зависимости от способа формирования таблиц маршрутизации делятся на три класса:
алгоритмы фиксированной (или статической) маршрутизации;
алгоритмы простой маршрутизации;
алгоритмы адаптивной (или динамической) маршрутизации.
В алгоритмах фиксированной маршрутизации все записи в таблице маршрутизации являются статическими. Администратор сети сам решает, на какие маршрутизаторы надо передавать пакеты с теми или иными адресами, и вручную заносит соответствующие записи в таблицу маршрутизации. Таблица, как правило, создается в процессе загрузки, в дальнейшем она используется без изменений до тех пор, пока ее содержимое не будет отредактировано вручную.
В алгоритмах простой маршрутизации таблица маршрутизации либо вовсе не используется, либо строится без участия протоколов маршрутизации. Выделяют три типа простой маршрутизации:
случайная маршрутизация, когда прибывший пакет посылается в первом попавшем случайном направлении, кроме исходного;
лавинная маршрутизация, когда пакет широковещательно посылается по всем возможным направлениям, кроме исходного (аналогично обработке мостами кадров с неизвестным адресом);
маршрутизация по предыдущему опыту, когда выбор маршрута осуществляется по таблице, но таблица строится по принципу моста путем анализа адресных полей пакетов, появляющихся на входных портах.
Самыми распространенными являются алгоритмы адаптивной (или динамической) маршрутизации. Эти алгоритмы обеспечивают автоматическое обновление таблиц маршрутизации после изменения конфигурации сети. Протоколы, построенные на основе адаптивных алгоритмов, позволяют всем маршрутизаторам собирать информацию о топологии связей в сети, оперативно отрабатывая все изменения конфигурации связей. В таблицах маршрутизации при адаптивной маршрутизации обычно имеется информация об интервале времени, в течение которого данный маршрут будет оставаться действительным. Это время называют временем жизни маршрута (Time To Live, TTL).
Адаптивные алгоритмы маршрутизации должны отвечать нескольким важным требованиям. Во-первых, они должны обеспечивать, если не оптимальность, то хотя бы рациональность маршрута. Во-вторых, алгоритмы должны быть достаточно простыми, чтобы при их реализации не тратилось слишком много сетевых ресурсов, в частности они не должны требовать слишком большого объема вычислений или порождать интенсивный служебный трафик. И наконец, алгоритмы маршрутизации должны обладать свойством сходимости, то есть всегда приводить к однозначному результату за приемлемое время.
Адаптивные протоколы обмена маршрутной информацией, применяемые в настоящее время в вычислительных сетях, в свою очередь делятся на две группы, каждая из которых связана с одним из следующих типов алгоритмов:
дистанционно-векторные алгоритмы (Distance Vector Algorithms, DVA);
алгоритмы состояния связей (Link State Algorithms, LSA).
В алгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор, компонентами которого являются расстояния от данного маршрутизатора до всех известных ему сетей. Под расстоянием обычно понимается число хопов. Возможна и другая метрика, учитывающая не только число промежуточных маршрутизаторов, но и время прохождения пакетов по сети между соседними маршрутизаторами. При получении вектора от соседа маршрутизатор наращивает расстояния до указанных в векторе сетей на расстояние до данного соседа. Получив вектор от соседнего маршрутизатора, каждый маршрутизатор добавляет к нему информацию об известных ему других сетях, о которых он узнал непосредственно (если они подключены к его портам) или из аналогичных объявлений других маршрутизаторов, а затем снова рассылает новое значение вектора по сети. В конце концов, каждый маршрутизатор узнает информацию обо всех имеющихся в интерсети сетях и о расстоянии до них через соседние маршрутизаторы.
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. В больших сетях они засоряют линии связи интенсивным широковещательным графиком, к тому же изменения конфигурации могут отрабатываться по этому алгоритму не всегда корректно, так как маршрутизаторы не имеют точного представления о топологии связей в сети, а располагают только обобщенной информацией - вектором дистанций, к тому же полученной через посредников.
Алгоритмы состояния связей обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации. «Широковещательная» рассылка (то есть передача пакета всем непосредственным соседям маршрутизатора) используется здесь только при изменениях состояния связей, что происходит в надежных сетях не так часто. Вершинами графа являются как маршрутизаторы, так и объединяемые ими сети. Распространяемая по сети информация состоит из описания связей различных типов: маршрутизатор-маршрутизатор, маршрутизатор-сеть.
Чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами HELLO со своими ближайшими соседями. Этот служебный трафик также засоряет сеть, но не в такой степени как, например, RIP-пакеты, так как пакеты HELLO имеют намного меньший объем.
Протоколами, основанными на алгоритме состояния связей, являются протоколы IS-IS (Intermediate System to Intermediate System) стека OSI, OSPF (Open Shortest Path First) стека TCP/IP.
Основная функция маршрутизатора - чтение заголовков пакетов сетевых протоколов, принимаемых и буферизуемых по каждому порту, и принятие решения о дальнейшем маршруте следования пакета по его сетевому адресу, включающему, как правило, номер сети и номер узла.
31. Классификация периферийных устройств эвм
Периферийное устройство (ПУ) - устройство, входящее в состав внешнего оборудования микро-ЭВМ, обеспечивающее ввод/вывод данных, организацию промежуточного и длительного хранения данных.
Можно выделить следующие основные функциональные классы периферийных устройств.
ПУ, предназначенные для связи с пользователем. К ним относят различные устройства ввода ( клавиатуры, сканеры, а также манипуляторы - мыши, трекболы и джойстики), устройства вывода (мониторы, индикаторы, принтеры, графопостроители и т.п.) и интерактивные устройства (терминалы, ЖК-планшеты с сенсорным вводом и др.)
Устройства массовой памяти ( винчестеры1), дисководы2), стримеры3)накопители на оптических дисках, флэш-память4) и др.)
Устройства связи с объектом управления (АЦП, ЦАП, датчики, цифровые регуляторы, реле и т.д.)
Средства передачи данных на большие расстояния (средства телекоммуникации) (модемы, сетевые адаптеры).
33. Современные сетевые технологии глобальных сетей (isdn-сети с интегральными услугами, технологии атм)
ISDN-сети с интегральными услугами
Выделенные линии представляют собой наиболее надежное средство соединения локальных сетей через глобальные каналы связи, так как вся пропускная способность такой линии всегда находится в распоряжении взаимодействующих сетей. Однако это и наиболее дорогой вид глобальных связей - при наличии N удаленных локальных сетей, которые интенсивно обмениваются данными друг с другом, нужно иметь Nx(N-l)/2 выделенных линий. Для снижения стоимости глобального транспорта применяют динамически коммутируемые каналы, стоимость которых разделяется между многими абонентами этих каналов.
Наиболее дешевыми оказываются услуги телефонных сетей, так как их коммутаторы оплачиваются большим количеством абонентов, пользующихся телефонными услугами, а не только абонентами, которые объединяют свои локальные сети.
Телефонные сети делятся на аналоговые и цифровые в зависимости от способа мультиплексирования абонентских и магистральных каналов. Более точно, цифровыми называются сети, в которых на абонентских окончаниях информация представлена в цифровом виде и в которых используются цифровые методы мультиплексирования и коммутации, а аналоговыми - сети, которые принимают данные от абонентов аналоговой формы, то есть от классических аналоговых телефонных аппаратов, а мультиплексирование и коммутацию осуществляют как аналоговыми методами, так и цифровыми. В последние годы происходил достаточно интенсивный процесс замены коммутаторов телефонных сетей на цифровые коммутаторы, которые работают на основе технологии TDM. Однако такая сеть по-прежнему останется аналоговой телефонной сетью, даже если все коммутаторы будут работать по технологии TDM, обрабатывая данные в цифровой форме, если абонентские окончания у нее останутся аналоговыми, а аналого-цифровое преобразование выполняется на ближней к абоненту АТС сети.
К телефонным сетям с цифровыми абонентскими окончаниями относятся цифровые сети с интегральными услугами ISDN (Intergrated Services Digital Network). Сети ISDN рассчитаны не только на передачу голоса, но и компьютерных данных, в том числе и с помощью коммутации пакетов, за счет чего они получили название сетей с интегральными услугами. Однако основным режимом работы сетей ISDN остается режим коммутации каналов, а служба коммутации пакетов обладает слишком низкой по современным меркам скоростью - обычно до 9600 бит/с. Новое поколение сетей с интеграцией услуг, названное BISDN (от broadband - широкополосные), основано уже целиком на технике коммутации пакетов (точнее, ячеек технологии ATM).
ISDN (Integrated Services Digital Network - цифровые сети с интегральными услугами) относятся к сетям, в которых основным режимом коммутации является режим коммутации каналов, а данные обрабатываются в цифровой форме.
В результате работ, проводимых по стандартизации интегральных сетей в CCITT, в 1980 году появился стандарт G.705, в котором излагались общие идеи такой сети. Конкретные спецификации сети ISDN появились в 1984 году в виде серии рекомендаций I. Этот набор спецификаций был неполным и не подходил для построения законченной сети. К тому же в некоторых случаях он допускал неоднозначность толкования или был противоречивым. В результате, хотя оборудование ISDN и начало появляться примерно с середины 80-х годов, оно часто было несовместимым, особенно если производилось в разных странах. В 1988 году рекомендации серии I были пересмотрены и приобрели гораздо более детальный и законченный вид, хотя некоторые неоднозначности сохранились. В 1992 и 1993 годах стандарты ISDN были еще раз пересмотрены и дополнены. Процесс стандартизации этой технологии продолжается.
Внедрение сетей ISDN началось достаточно давно - с конца 80-х годов, однако высокая техническая сложность пользовательского интерфейса, отсутствие единых стандартов на многие жизненно важные функции, а также необходимость крупных капиталовложений для переоборудования телефонных АТС и каналов связи привели к тому, что инкубационный период затянулся на многие годы, и сейчас, когда прошло уже более десяти лет, распространенность сетей ISDN оставляет желать лучшего.
Архитектура сети ISDN предусматривает несколько видов служб (рис. ниже):
некоммутируемые средства (выделенные цифровые каналы);
коммутируемая телефонная сеть общего пользования;
сеть передачи данных с коммутацией каналов;
сеть передачи данных с коммутацией пакетов;
сеть передачи данных с трансляцией кадров (frame relay);
средства контроля и управления работой сети.
Как видно из приведенного списка, транспортные службы сетей ISDN действительно покрывают очень широкий спектр услуг, включая популярные услуги frame relay. Кроме того, большое внимание уделено средствам контроля сети, которые позволяют маршрутизировать вызовы для установления соединения с абонентом сети, а также осуществлять мониторинг и управление сетью. Управляемость сети обеспечивается интеллектуальностью коммутаторов и конечных узлов сети, поддерживающих стек протоколов, в том числе и специальных протоколов управления.

Рис.: Службы ISDN
Стандарты ISDN описывают также ряд услуг прикладного уровня: факсимильную связь на скорости 64 Кбит/с, телексную связь на скорости 9600 бит/с, видеотекс на скорости 9600 бит/с и некоторые другие
На практике не все сети ISDN поддерживают все стандартные службы. Служба frame relay хотя и была разработана в рамках сети ISDN, однако реализуется, как правило, с помощью отдельной сети коммутаторов кадров, не пересекающейся с сетью коммутаторов ISDN.
Базовой скоростью сети ISDN является скорость канала DS-0, то есть 64 Кбит/с. Эта скорость ориентируется на самый простой метод кодирования голоса - ИКМ, хотя дифференциальное кодирование и позволяет передавать голос с тем же качеством на скорости 32 или 16 Кбит/с.
Одним из базовых принципов ISDN является предоставление пользователю стандартного интерфейса, с помощью которого пользователь может запрашивать у сети разнообразные услуги. Этот интерфейс образуется между двумя типами оборудования, устанавливаемого в помещении пользователя (Customer Premises Equipment, СРЕ): терминальным оборудованием пользователя ТЕ (компьютер с соответствующим адаптером, маршрутизатор, телефонный аппарат) и сетевым окончанием NT, которое представляет собой устройство, завершающее канал связи с ближайшим коммутатором ISDN.
Пользовательский интерфейс основан на каналах трех типов:
В - со скоростью передачи данных 64 Кбит/с;
D - со скоростью передачи данных 16 или 64 Кбит/с;
Н - со скоростью передачи данных 384 Кбит/с (Н0), 1536 Кбит/с (Н11) или 1920 Кбит/с (Н12).
Каналы типа В обеспечивают передачу пользовательских данных (оцифрованного голоса, компьютерных данных или смеси голоса и данных) и с более низкими скоростями, чем 64 Кбит/с. Разделение данных выполняется с помощью техники TDM. Разделением канала В на подканалы в этом случае должно заниматься пользовательское оборудование, сеть ISDN всегда коммутирует целые каналы типа В. Каналы типа В могут соединять пользователей с помощью техники коммутации каналов друг с другом, а также образовывать так называемые полупостоянные (semipermanent) соединения, которые эквиваленты соединениям службы выделенных каналов. Канал типа В может также подключать пользователя к коммутатору сети Х.25.
Канал типа D выполняет две основные функции. Первой и основной является передача адресной информации, на основе которой осуществляется коммутация каналов типа В в коммутаторах сети. Второй функцией является поддержание услуг низкоскоростной сети с коммутацией пакетов для пользовательских данных. Обычно эта услуга выполняется сетью в то время, когда каналы типа D свободны от выполнения основной функции.
Каналы типа Н предоставляют пользователям возможности высокоскоростной передачи данных. На них могут работать службы высокоскоростной передачи факсов, видеоинформации, качественного воспроизведения звука.
Пользовательский интерфейс ISDN представляет собой набор каналов определенного типа и с определенными скоростями.
Сеть ISDN поддерживает два типа пользовательского интерфейса - начальный (Basic Rate Interface, BRI) и основной (Primay Rate Interface, PRI).
Начальный интерфейс BRI предоставляет пользователю два канала по 64 Кбит/с для передачи данных (каналы типа В) и один канал с пропускной способностью 16 Кбит/с для передачи управляющей информации (канал типа D). Все каналы работают в полнодуплексном режиме. Различные каналы пользовательского интерфейса разделяют один и тот же физический двухпроводный кабель по технологии TDM, то есть являются логическими каналами, а не физическими. Данные по интерфейсу BRI передаются кадрами, состоящими из 48 бит. Каждый кадр содержит по 2 байта каждого из В каналов, а также 4 бита канала D. Передача кадра длится 250 мс, что обеспечивает скорость данных 64 Кбит/с для каналов В и 16 Кбит/с для канала D. Кроме бит данных кадр содержит служебные биты для обеспечения синхронизации кадров, а также обеспечения нулевой постоянной составляющей электрического сигнала.
Интерфейс BRI может поддерживать не только схему 2B+D, но и B+D и просто D (когда пользователь направляет в сеть только пакетизированные данные).
Основной интерфейс PRI предназначен для пользователей с повышенными требованиями к пропускной способности сети. Интерфейс PRI поддерживает либо схему 30B+D, либо схему 23B+D. В обеих схемах канал D обеспечивает скорость 64 Кбит/с. Первый вариант предназначен для Европы, второй - для Северной Америки и Японии. Ввиду большой популярности скорости цифровых каналов 2,048 Мбит/с в Европе и скорости 1,544 Мбит/с в остальных регионах, привести стандарт на интерфейс PRI к общему варианту не удалось.
Возможны варианты интерфейса PRI с меньшим количеством каналов типа В, например 20B+D. Каналы типа В могут объединяться в один логический высоко скоростной канал с общей скоростью до 1920 Кбит/с. При установке у пользователя нескольких интерфейсов PRI все они могут иметь один канал типа D, при этом количество В каналов в том интерфейсе, который не имеет канала D, может увеличиваться до 24 или 31.
Основной интерфейс может быть основан на каналах типа Н. При этом общая пропускная способность интерфейса все равно не должна превышать 2,048 или 1,544 Мбит/с. Для каналов Н0 возможны интерфейсы 3H0+D для американского варианта и 5H0+D для европейского. Для каналов H1 возможен интерфейс, состоящий только из одного канала Н11 (1,536 Мбит/с) для американского варианта или одного канала Н12 (1,920 Мбит/с) и одного канала D для европейского варианта.
Технология ISDN разрабатывалась как основа всемирной телекоммуникационной сети, позволяющей связывать как телефонных абонентов, так и абонентов других глобальных сетей - компьютерных, телексных. Поэтому при разработке схемы адресации узлов ISDN необходимо было, во-первых, сделать эту схему достаточно емкой для всемирный адресации, а во-вторых, совместимой со схемами адресации других сетей, чтобы абоненты этих сетей, в случае соединения своих сетей через сеть ISDN, могли бы пользоваться привычными форматами адресов. Разработчики стека TCP/IP пошли по пути введения собственной системы адресации, независимой от систем адресации объединяемых сетей. Разработчики технологии ISDN пошли по другому пути - они решили добиться использования в адресе ISDN адресов объединяемых сетей.
Основное назначение ISDN - это передача телефонного трафика. Поэтому за основу адреса ISDN был взят формат международного телефонного плана номеров, описанный в стандарте ITUT E.163. Однако этот формат был расширен для поддержки большего числа абонентов и для использования в нем адресов других сетей, например Х.25.
Формат E.163 предусматривает до 12 десятичных цифр в номере, а формат адреса ISDN в стандарте Е.164 расширен до 55 десятичных цифр. В сетях ISDN различают номер абонента и адрес абонента. Номер абонента соответствует точке подключения всего пользовательского оборудования к сети. Например, вся офисная АТС может идентифицироваться одним номером ISDN. Номер ISDN состоит из 15 десятичных цифр и делится, как и телефонный номер по стандарту Е.163, на поле «Код страны» (от 1 до 3 цифр), поле «Код города» и поле «Номер абонента». Адрес ISDN включает номер плюс до 40 цифр подадреса. Подадрес используется для нумерации терминальных устройств за пользовательским интерфейсом.
При вызове абонентов из сети, не относящейся к ISDN, их адрес может непосредственно заменять адрес ISDN. Например, адрес абонента сети Х.25, в которой используется система адресации по стандарту Х.121, может быть помещен целиком в поле адреса ISDN, но для указания, что это адрес стандарта Х.121, ему должно предшествовать поле префикса, в которое помещается код стандарта адресации, в данном случае стандарта Х.121. Коммутаторы сети ISDN могут обработать этот адрес корректно и установить связь с нужным абонентом сети Х.25 через сеть ISDN - либо коммутируя канал типа В с коммутатором Х.25, либо передавая данные по каналу типа D в режиме коммутации пакетов. Префикс описывается стандартом ISO 7498.
Стандарт ISO 7498 определяет достаточно сложный формат адреса, причем основой схемы адресации являются первые два поля. Поле AFI (Athority and Format Identifier) задает значения всех остальных полей адреса и формат этих полей. Значением поля AFI является один из 6 типов поддоменов глобального домена адресации:
четыре типа доменов соответствуют четырем типам публичных телекоммуникационных сетей - сетей с коммутацией пакетов, телексных сетей, публичных телефонных сетей и сетей ISDN;
пятый тип домена - это географический домен, который назначается каждой стране (в одной страна может быть несколько географических доменов);
шестой тип домена - это домен организационного типа, в который входят международные организации, например ООН или ATM Forum.
За полем AFI идет поле IDI (Initial Domain Identifier) - поле начального идентификатора домена, а за ним располагается дополнительное поле DSP (Domain Specific Part), которое может нести дополнительные цифры номера абонента, если разрядности поля IDI не хватает.
Еще одним способом вызова абонентов из других сетей является указание в адресе ISDN двух адресов: адреса ISDN пограничного устройства, например, соединяющего сеть ISDN с сетью Х.25, и адреса узла в сети Х.25. Адреса должны разделяться специальным разделителем. Два адреса используются за два этапа - сначала сеть ISDN устанавливает соединение типа коммутируемого канала с пограничным устройством, присоединенным к сети ISDN, а затем передает ему вторую часть адреса, чтобы это устройство осуществило соединение с требуемым абонентом.
В сети ISDN существуют два стека протоколов: стек каналов типа D и стек каналов типа В.
Каналы типа D образуют достаточно традиционную сеть с коммутацией пакетов. Прообразом этой сети послужила технология сетей Х.25. Для сети каналов D определены три уровня протоколов: физический протокол; канальный протокол LAPD; а на сетевом уровне может использоваться протокол, с помощью которого выполняется маршрутизация вызова абонента службы с коммутацией каналов, или же протокол Х.25 - в этом случае в кадры протокола LAPD вкладываются пакеты Х.25 и коммутаторы ISDN выполняют роль коммутаторов Х.25.
Сеть каналов типа D внутри сети ISDN служит транспортным уровнем для так называемой системы сигнализации номер 7 (Signal System Number 7, SS7). Система SS7 была разработана для целей внутреннего мониторинга и управления коммутаторами телефонной сети общего назначения. Эта система применяется и в сети ISDN. Служба SS7 относится к прикладному уровню модели OSI. Конечному пользователю ее услуги недоступны, так как сообщениями SS7 коммутаторы сети обмениваются только между собой.
Каналы типа В образуют сеть с коммутацией цифровых каналов. В терминах модели OSI на каналах типа В в коммутаторах сети ISDN определен только протокол физического уровня. Коммутация каналов типа В происходит по указаниям, полученным по каналу D.
Несмотря на большие отличия от аналоговых телефонных сетей, сети ISDN сегодня используются в основном так же, как аналоговые телефонные сети, то есть как сети с коммутацией каналов, но только более скоростные: интерфейс BRI дает возможность установить дуплексный режим обмена со скоростью 128 Кбит/с (логическое объединение двух каналов типа В), а интерфейс PRI - 2,048 Мбит/с. Кроме того, качество цифровых каналов гораздо выше, чем аналоговых, а это значит, что процент искаженных кадров будет гораздо ниже и полезная скорость обмена данными существенно выше.
Обычно интерфейс BRI используется в коммуникационном оборудовании для подключения отдельных компьютеров или небольших локальных сетей, а интерфейс PRI - в маршрутизаторах, рассчитанных на сети средних размеров.
Что же касается объединения компьютерных сетей для поддержки службы с коммутацией пакетов, то здесь сети ISDN предоставляют не очень большие возможности.
На каналах типа В режим коммутации пакетов поддерживается следующим образом - либо с помощью постоянного соединения с коммутатором сети Х.25, либо с помощью коммутируемого соединения с этим же коммутатором. То есть каналы типа В в сетях ISDN являются только транзитными для доступа к «настоящей» сети Х.25. Собственно, это сводится к первому случаю использования сети ISDN - только как сети с коммутацией каналов.
Развитие технологии трансляции кадров на каналах типа В - технологии frame relay - привело к тому, что сети frame relay стали самостоятельным видом сетей со своей инфраструктурой каналов и коммутаторов.
Остается служба коммутации пакетов, доступная по каналу D. Так как после передачи адресной информации канал D остается свободным, по нему можно реализовать передачу компьютерных пакетов Х.25, поскольку протокол LAPD позволяет это делать. Чаще всего сеть ISDN используется не как замена сети Х.25, а как разветвленная сеть доступа к менее географически распространенной и узкоспециализированной сети Х.25. Такая услуга обычно называется «доступ к сети Х.25 через канал типа D». Скорость доступа к сети Х.25 по каналу типа D обычно не превышает 9600 бит/с.
Сети ISDN не рассматриваются разработчиками корпоративных сетей как хорошее средство для создания магистрали сети. Основная причина - отсутствие скоростной службы коммутации пакетов и невысокие скорости каналов, предоставляемых конечным пользователям. Для целей же подключения мобильных и домашних пользователей, небольших филиалов и образования резервных каналов связи сети ISDN сейчас используются очень широко, естественно там, где они существуют. Производители коммуникационного оборудования выпускают широкий спектр продуктов для подключения локальных сетей к ISDN - терминальных адаптеров, удаленных мостов и офисных маршрутизаторов невысокой стоимости.
Справка
Коммутация на основе техники разделения частот разрабатывалась в расчете на передачу непрерывных сигналов, представляющих голос. При переходе к цифровой форме представления голоса была разработана новая техника мультиплексирования, ориентирующаяся на дискретный характер передаваемых данных.
Эта техника носит название мультиплексирования с разделением времени (Time Division Multiplexing, TDM). Реже используется и другое ее название - техника синхронного режима передачи (Synchronous Transfer Mode, STM). Рисунок ниже поясняет принцип коммутации каналов на основе техники TDM.
Аппаратура TDM-сетей - мультиплексоры, коммутаторы, демультиплексоры - работает в режиме разделения времени, поочередно обслуживая в течение цикла своей работы все абонентские каналы. Цикл работы оборудования TDM равен 125 мкс, что соответствует периоду следования замеров голоса в цифровом абонентском канале. Это значит, что мультиплексор или коммутатор успевает вовремя обслужить любой абонентский канал и передать его очередной замер далее по сети. Каждому соединению выделяется один квант времени цикла работы аппаратуры, называемый также тайм-слотом. Длительность тайм-слота зависит от числа абонентских каналов, обслуживаемых мультиплексором TDM или коммутатором.

Рис.: Коммутация на основе разделения канала во времени
Мультиплексор принимает информацию по N входным каналам от конечных абонентов, каждый из которых передает данные по абонентскому каналу со скоростью 64 Кбит/с - 1 байт каждые 125 мкс. В каждом цикле мультиплексор выполняет следующие действия:
прием от каждого канала очередного байта данных;
составление из принятых байтов уплотненного кадра, называемого также обоймой;
передача уплотненного кадра на выходной канал с битовой скоростью, равной Nx64 Кбит/с.
Порядок байт в обойме соответствует номеру входного канала, от которого этот байт получен. Количество обслуживаемых мультиплексором абонентских каналов зависит от его быстродействия. Демультиплексор выполняет обратную задачу - он разбирает байты уплотненного кадра и распределяет их по своим нескольким выходным каналам, при этом он считает, что порядковый номер байта в обойме соответствует номеру выходного канала.
Коммутатор принимает уплотненный кадр по скоростному каналу от мультиплексора и записывает каждый байт из него в отдельную ячейку своей буферной памяти, причем в том порядке, в котором эти байты были упакованы в уплотненный кадр. Для выполнения операции коммутации байты извлекаются из буферной памяти не в порядке поступления, а в таком порядке, который соответствует поддерживаемым в сети соединениям абонентов. Так, например, если первый абонент левой части сети (см. рис.) должен соединиться со вторым абонентом в правой части сети, то байт, записанный в первую ячейку буферной памяти, будет извлекаться из нее вторым. «Перемешивая» нужным образом байты в обойме, коммутатор обеспечивает соединение конечных абонентов в сети.
Однажды выделенный номер тайм-слота остается в распоряжении соединения «входной канал-выходной слот» в течение всего времени существования этого соединения, даже если передаваемый трафик является пульсирующим и не всегда требует захваченного количества тайм-слотов. Это означает, что соединение в сети TDM всегда обладает известной и фиксированной пропускной способностью, кратной 64 Кбит/с.
Работа оборудования TDM напоминает работу сетей с коммутацией пакетов, так как каждый байт данных можно считать некоторым элементарным пакетом. Однако, в отличие от пакета компьютерной сети, «пакет» сети TDM не имеет индивидуального адреса. Его адресом является порядковый номер в обойме или номер выделенного тайм-слота в мультиплексоре или коммутаторе. Сети, использующие технику TDM, требуют синхронной работы всего оборудования, что и определило второе название этой техники - синхронный режим передач (STM). Нарушение синхронности разрушает требуемую коммутацию абонентов, так как при этом теряется адресная информация. Поэтому перераспределение тайм-слотов между различными каналами в оборудовании TDM невозможно, даже если в каком-то цикле работы мультиплексора тайм-слот одного из каналов оказывается избыточным, так как на входе этого канала в этот момент нет данных для передачи (например, абонент телефонной сети молчит).
Существует модификация техники TDM, называемая статистическим разделением канала во времени (Statistical TDM, STDM). Эта техника разработана специально для того, чтобы с помощью временно свободных тайм-слотов одного канала можно было увеличить пропускную способность остальных. Для решения этой задачи каждый байт данных дополняется полем адреса небольшой длины, например в 4 или 5 бит, что позволяет мультиплексировать 16 или 32 канала. Однако техника STDM не нашла широкого применения и используется в основном в нестандартном оборудовании подключения терминалов к мэйнфреймам.
Сети TDM могут поддерживать либо режим динамической коммутации, либо режим постоянной коммутации, а иногда и оба эти режима. Так, например, основным режимом цифровых телефонных сетей, работающих на основе технологии TDM, является динамическая коммутация, но они поддерживают также и постоянную коммутацию, предоставляя своим абонентам службу выделенных каналов.
Существует аппаратура, которая поддерживает только режим постоянной коммутации. К ней относится оборудование типа Т1/Е1, а также высокоскоростное оборудование SDH. Такое оборудование используется для построения первичных сетей, основной функцией которых является создание выделенных каналов между коммутаторами, поддерживающими динамическую коммутацию.
Сегодня практически все данные - голос, изображение, компьютерные данные - передаются в цифровой форме. Поэтому выделенные каналы TDM-технологии, которые обеспечивают нижний уровень для передачи цифровых данных, являются универсальными каналами для построения сетей любого типа: телефонных, телевизионных и компьютерных.
Основные принципы технологии АТМ
Сетевая технология - это согласованный набор стандартных протоколов и реализующих их программно-аппаратных средств (например, сетевых адаптеров, драйверов, кабелей и разъемов), достаточный для построения вычислительной сети.
Гетерогенность - неотъемлемое качество любой крупной вычислительной сети, и на согласование разнородных компонентов системные интеграторы и администраторы тратят большую часть своего времени. Поэтому любое средство, сулящее перспективу уменьшения неоднородности сети, привлекает пристальный интерес сетевых специалистов. Технология асинхронного режима передачи (Asynchronous Transfer Mode, ATM) разработана как единый универсальный транспорт для нового поколения сетей с интеграцией услуг, которые называются широкополосными сетями ISDN (Broadband-ISDN, B-ISDN).
Главный недостаток технологии TDM, которую также называют технологией синхронной передачи STM (Synchronous Transfer Mode), заключается в невозможности перераспределять пропускную способность объединенного канала между подканалами. В те периоды времени, когда по подканалу не передаются пользовательские данные, объединенный канал все равно передает байты этого подканала, заполненные нулями.
Попытки загрузить периоды простоя подканалов приводят к необходимости введения заголовка для данных каждого подканала. В промежуточной технологии STDM (Statistical TDM), которая позволяет заполнять периоды простоя передачей пульсаций трафика других подканалов, действительно вводятся заголовки, содержащие номер подканала. Данные при этом оформляются в пакеты, похожие по структуре на пакеты компьютерных сетей. Наличие адреса у каждого пакета позволяет передавать его асинхронно, так как местоположение его относительно данных других подканалов уже не является его адресом. Асинхронные пакеты одного подканала вставляются в свободные таймслоты другого подканала, но не смешиваются с данными этого подканала, так как имеют собственный адрес.
Технология ATM совмещает в себе подходы двух технологий - коммутации пакетов и коммутации каналов. От первой она взяла на вооружение передачу данных в виде адресуемых пакетов, а от второй - использование пакетов небольшого фиксированного размера, в результате чего задержки в сети становятся более предсказуемыми. С помощью техники виртуальных каналов, предварительного заказа параметров качества обслуживания канала и приоритетного обслуживания виртуальных каналов с разным качеством обслуживания удается добиться передачи в одной сети разных типов трафика без дискриминации. Хотя сети ISDN также разрабатывались для передачи различных видов трафика в рамках одной сети, голосовой трафик явно был для разработчиков более приоритетным. Технология ATM с самого начала разрабатывалась как технология, способная обслуживать все виды трафика в соответствии с их требованиями.
Службы верхних уровней сети B-ISDN должны быть примерно такими же, что и у сети ISDN - это передача факсов, распространение телевизионного изображения, голосовая почта, электронная почта, различные интерактивные службы, например проведение видеоконференций.
Сеть ATM имеет классическую структуру крупной территориальной сети - конечные станции соединяются индивидуальными каналами с коммутаторами нижнего уровня, которые в свою очередь соединяются с коммутаторами более высоких уровней. Коммутаторы ATM пользуются 20-байтными адресами конечных узлов для маршрутизации трафика на основе техники виртуальных каналов. Для частных сетей ATM определен протокол маршрутизации PNNI (Private Network to Network Interface), с помощью которого коммутаторы могут строить таблицы маршрутизации автоматически. В публичных сетях ATM таблицы маршрутизации могут строиться администраторами вручную, как и в сетях Х.25, или могут поддерживаться протоколом PNNI.
Коммутация пакетов происходит на основе идентификатора виртуального канала (Virtual Channel Identifier, VCI), который назначается соединению при его установлении и уничтожается при разрыве соединения. Адрес конечного узла ATM, на основе которого прокладывается виртуальный канал, имеет иерархическую структуру, подобную номеру в телефонной сети, и использует префиксы, соответствующие кодам стран, городов, сетям поставщиков услуг и т. п., что упрощает маршрутизацию запросов установления соединения, как и при использовании агрегированных IP-адресов в соответствии с техникой CIDR.
Виртуальные соединения могут быть постоянными (Permanent Virtual Circuit, PVC) и коммутируемыми (Switched Virtual Circuit, SVC). Для ускорения коммутации в больших сетях используется понятие виртуального пути - Virtual Path, который объединяет виртуальные каналы, имеющие в сети ATM общий маршрут между исходным и конечным узлами или общую часть маршрута между некоторыми двумя коммутаторами сети. Идентификатор виртуального пути (Virtual Path Identifier, VPI) является старшей частью локального адреса и представляет собой общий префикс для некоторого количества различных виртуальных каналов. Таким образом, идея агрегирования адресов в технологии ATM применена на двух уровнях - на уровне адресов конечных узлов (работает на стадии установления виртуального канала) и на уровне номеров виртуальных каналов (работает при передаче данных по имеющемуся виртуальному каналу).
Соединения конечной станции ATM с коммутатором нижнего уровня определяются стандартом UNI (User Network Interface). Спецификация UNI определяет структуру пакета, адресацию станций, обмен управляющей информацией, уровни протокола ATM, способы установления виртуального канала и способы управления трафиком.
Стандарт ATM не вводит свои спецификации на реализацию физического уровня. Здесь он основывается на технологии SDH/SONET, принимая ее иерархию скоростей. В соответствии с этим начальная скорость доступа пользователя сети - это скорость ОС-3 155 Мбит/с. На скорости 155 Мбит/с можно использовать не только волоконно-оптический кабель, но и неэкранированную витую пару категории 5. На скорости 622 Мбит/с допустим только волоконно-оптический кабель, причем как SMF, так и MMF.
Все перечисленные выше характеристики технологии ATM не свидетельствуют о том, что это некая «особенная» технология, а скорее представляют ее как типичную технологию глобальных сетей, основанную на технике виртуальных каналов. Особенности же технологии ATM лежат в области качественного обслуживания разнородного трафика и объясняются стремлением решить задачу совмещения в одних и тех же каналах связи и в одном и том же коммуникационном оборудовании компьютерного и мультимедийного трафика таким образом, чтобы каждый тип трафика получил требуемый уровень обслуживания и не рассматривался как «второстепенный».
Трафик вычислительных сетей имеет ярко выраженный асинхронный и пульсирующий характер. Компьютер посылает пакеты в сеть в случайные моменты времени, по мере возникновения в этом необходимости. При этом интенсивность посылки пакетов в сеть и их размер могут изменяться в широких пределах - например, коэффициент пульсаций трафика (отношения максимальной мгновенной интенсивности трафика к его средней интенсивности) протоколов без установления соединений может доходить до 200, а протоколов с установлением соединений - до 20. Чувствительность компьютерного трафика к потерям данных высокая, так как без утраченных данных обойтись нельзя и их необходимо восстановить за счет повторной передачи.
Мультимедийный трафик, передающий, например, голос или изображение, характеризуется низким коэффициентом пульсаций, высокой чувствительностью к задержкам передачи данных (отражающихся на качестве воспроизводимого непрерывного сигнала) и низкой чувствительностью к потерям данных (из-за инерционности физических процессов потерю отдельных замеров голоса или кадров изображения можно компенсировать сглаживанием на основе предыдущих и последующих значений).
Подход, реализованный в технологии ATM, состоит в передаче любого вида трафика - компьютерного, телефонного или видео - пакетами фиксированной и очень маленькой длины в 53 байта. Пакеты ATM называют ячейками - cell. Поле данных ячейки занимает 48 байт, а заголовок - 5 байт.
Чтобы пакеты содержали адрес узла назначения и в то же время процент служебной информации не превышал размер поля данных пакета, в технологии ATM применен стандартный для глобальных вычислительных сетей прием - передача ячеек в соответствии с техникой виртуальных каналов с длиной номера виртуального канала в 24 бит, что вполне достаточно для обслуживания большого количества виртуальных соединений каждым портом коммутатора глобальной (может быть всемирной) сети ATM.
Размер ячейки ATM является результатом компромисса между телефонистами и компьютерщиками - первые настаивали на размере поля данных в 32 байта, а вторые - в 64 байта.
Чем меньше пакет, тем легче имитировать услуги каналов с постоянной битовой скоростью, которая характерна для телефонных сетей. Ясно, что при отказе от жестко синхронизированных временных слотов для каждого канала идеальной синхронности добиться будет невозможно, однако чем меньше размер пакета, тем легче этого достичь.
Для пакета, состоящего из 53 байт, при скорости в 155 Мбит/с время передачи кадра на выходной порт составляет менее 3 мкс. Так что эта задержка не очень существенна для трафика, пакеты которого должны передаваться каждые 125 мкс.
Однако на выбор размера ячейки большее влияние оказала не величина ожидания передачи ячейки, а задержка пакетизации. Задержка пакетизации - это время, в течение которого первый замер голоса ждет момента окончательного формирования пакета и отправки его по сети. При размере поля данных в 48 байт одна ячейка ATM обычно переносит 48 замеров голоса, которые делаются с интервалом в 125 мкс. Поэтому первый замер должен ждать примерно 6 мс, прежде чем ячейка будет отправлена по сети. Именно по этой причине телефонисты боролись за уменьшения размера ячейки, так как 6 мс - это задержка, близкая к пределу, за которым начинаются нарушения качества передачи голоса. При выборе размера ячейки в 32 байта задержка пакетизации составила бы 4 мс, что гарантировало бы более качественную передачу голоса. А стремление компьютерных специалистов увеличить поле данных до 64 байт вполне понятно - при этом повышается полезная скорость передачи данных. Избыточность служебных данных при использовании 48-байтного поля данных составляет 10%, а при использовании 32-байтного поля данных она сразу повышается до 16%.
Выбор для передачи данных любого типа небольшой ячейки фиксированного размера еще не решает задачу совмещения разнородного трафика в одной сети, а только создает предпосылки для ее решения. Для полного решения этой задачи технология ATM привлекает и развивает идеи заказа пропускной способности и качества обслуживания, реализованные в технологии frame relay. Но если сеть frame relay изначально была предназначена для передачи только пульсирующего компьютерного трафика (в связи с этим для сетей frame relay так трудно дается стандартизация передачи голоса), то разработчики технологии ATM проанализировали всевозможные образцы трафика, создаваемые различными приложениями, и выделили 4 основных класса трафика, для которых разработали различные механизмы резервирования и поддержания требуемого качества обслуживания.
Класс трафика (называемый также классом услуг - service class) качественно характеризует требуемые услуги по передаче данных через сеть ATM. Если приложение указывает сети, что требуется, например, передача голосового трафика, то из этого становится ясно, что особенно важными для пользователя будут такие показатели качества обслуживания, как задержки и вариации задержек ячеек, существенно влияющие на качество переданной информации - голоса или изображения, а потеря отдельной ячейки с несколькими замерами не так уж важна, так как, например, воспроизводящее голос устройство может аппроксимировать недостающие замеры и качество пострадает не слишком. Требования к синхронности передаваемых данных очень важны для многих приложений - не только голоса, но и видеоизображения, и наличие этих требований стало первым критерием для деления трафика на классы.
Другим важным параметром трафика, существенно влияющим на способ его передачи через сеть, является величина его пульсаций. Разработчики технологии ATM решили выделить два различных типа трафика в отношении этого параметра - трафик с постоянной битовой скоростью (Constant Bit Rate, CBR) и трафик с переменной битовой скоростью (Variable Bit Rate, VBR).
К разным классам были отнесены трафики, порождаемые приложениями, использующими для обмена сообщениями протоколы с установлением соединений и без установления соединений. В первом случае данные передаются самим приложением достаточно надежно, как это обычно делают протоколы с установлением соединения, поэтому от сети ATM высокой надежности передачи не требуется. А во втором случае приложение работает без установления соединения и восстановлением потерянных и искаженных данных не занимается, что предъявляет повышенные требования к надежности передачи ячеек сетью ATM.
В результате было определено пять классов трафика, отличающихся следующими качественными характеристиками:
наличием или отсутствием пульсации трафика, то есть трафики CBR или VBR;
требованием к синхронизации данных между передающей и принимающей сторонами;
типом протокола, передающего свои данные через сеть ATM, - с установлением соединения или без установления соединения (только для случая передачи компьютерных данных). Основные характеристики классов трафика ATM приведены в таблице.
Таблица: Классы трафика ATM
Класс трафика |
Характеристика |
А |
Постоянная битовая скорость - Constant Bit Rate, CBR. Требуются временные соотношения между передаваемыми и принимаемыми данными. С установлением соединения. Примеры: голосовой трафик, трафик телевизионного изображения |
В |
Переменная битовая скорость - Variable Bit Rate, VBR. Требуются временные соотношения между передаваемыми и принимаемыми данными, С установлением соединения. Примеры: компрессированный голос, компрессированное видеоизображение |
С |
Переменная битовая скорость - Variable Bit Rate, VBR. He требуются временные соотношения между передаваемыми и принимаемыми данными. С установлением соединения. Примеры: трафик компьютерных сетей, в которых конечные узлы работают по протоколам с установлением соединений: frame relay, X.25, LLC2, TCP |
D |
Переменная битовая скорость - Variable Bit Rate, VBR. He требуются временные соотношения между передаваемыми и принимаемыми данными. Без установления соединения. Примеры: трафик компьютерных сетей, в которых конечные узлы работают по протоколам без установления соединений (IP, Ethernet. DNS, SNMP) |
X |
Тип трафика и его параметры определяются пользователем |
Очевидно, что только качественных характеристик, задаваемых классом трафика, для описания требуемых услуг оказывается недостаточно. В технологии ATM для каждого класса трафика определен набор количественных параметров, которые приложение должно задать. Например, для трафика класса А необходимо указать постоянную скорость, с которой приложение будет посылать данные в сеть, а для трафика класса В - максимально возможную скорость, среднюю скорость и максимально возможную пульсацию. Для голосового трафика можно не только указать на важность синхронизации между передатчиком и приемником, но и количественно задать верхние границы задержки и вариации задержки ячеек.
В технологии ATM поддерживается следующий набор основных количественных параметров:
Peak Cell Rate (PCR) - максимальная скорость передачи данных;
Sustained Cell Rate (SCR) - средняя скорость передачи данных;
Minimum Cell Rate (MCR) - минимальная скорость передачи данных;
Maximum Burst Size (MBS) - максимальный размер пульсации;
Cell Loss Ratio (CLR) - доля потерянных ячеек;
Cell Transfer Delay (CTD) - задержка передачи ячеек;
Cell Delay Variation (CDV) - вариация задержки ячеек.
Параметры скорости измеряются в ячейках в секунду, максимальный размер пульсации - в ячейках, а временные параметры - в секундах. Максимальный размер пульсации задает количество ячеек, которое приложение может передать с максимальной скоростью PCR, если задана средняя скорость. Доля потерянных ячеек является отношением потерянных ячеек к общему количеству отправленных ячеек по данному виртуальному соединению. Так как виртуальные соединения являются дуплексными, то для каждого направления соединения могут быть заданы разные значения параметров.
Технология ATM изначально разрабатывалась для поддержки как постоянных, так и коммутируемых виртуальных каналов (в отличие от технологии frame relay, долгое время не поддерживающей коммутируемые виртуальные каналы). Автоматическое заключение трафик-контракта при установлении коммутируемого виртуального соединения представляет собой весьма непростую задачу, так как коммутаторам ATM необходимо определить, смогут ли они в дальнейшем обеспечить передачу трафика данного виртуального канала наряду с трафиком других виртуальных каналов таким образом, чтобы выполнялись требования качества обслуживания каждого канала.

Рис.: Структура стека протоколов ATM

Рис.: Распределение протоколов по узлам и коммутаторам сети ATM
Уровень адаптации (ATM Adaptation Layer, AAL) представляет собой набор протоколов AAL1, AAL5, которые преобразуют сообщения протоколов верхних уровней сети ATM в ячейки ATM нужного формата.
Каждый протокол уровня AAL обрабатывает пользовательский трафик определенного класса. На начальных этапах стандартизации каждому классу трафика соответствовал свой протокол AAL, который принимал в конечном узле пакеты от протокола верхнего уровня и заказывал с помощью соответствующего протокола нужные параметры трафика и качества обслуживания для данного виртуального канала. При развитии стандартов ATM такое однозначное соответствие между классами трафика и протоколами уровня AAL исчезло, и сегодня разрешается использовать для одного и того же класса трафика различные протоколы уровня AAL.
Уровень адаптации состоит из нескольких подуровней. Нижний подуровень AAL называется подуровнем сегментации и реассемблирования (Segmentation And Reassembly, SAR). Эта часть не зависит от типа протокола AAL (и, соответственно, от класса передаваемого трафика) и занимается разбиением (сегментацией) сообщения, принимаемого AAL от протокола верхнего уровня, на ячейки ATM, снабжением их соответствующим заголовком и передачей уровню ATM для отправки в сеть.
Верхний подуровень AAL называется подуровнем конвергенции (Convergence Sublayer, CS). Этот подуровень зависит от класса передаваемого трафика. Протокол подуровня конвергенции решает такие задачи, как, например, обеспечение временной синхронизации между передающим и принимающим узлами (для трафика, требующего такой синхронизации), контролем и возможным восстановлением битовых ошибок в пользовательской информации, контролем целостности передаваемого пакета компьютерного протокола (Х.25, frame relay).
Протоколы AAL для выполнения своей работы используют служебную информацию, размещаемую в заголовках уровня AAL. После приема ячеек, пришедших по виртуальному каналу, подуровень SAR протокола AAL собирает посланное по сети исходное сообщение (которое в общем случае было разбито на несколько ячеек ATM) с помощью заголовков AAL, которые для коммутаторов ATM являются прозрачными, так как помещаются в 48-битном поле данных ячейки, как и полагается протоколу более высокого уровня. После сборки исходного сообщения протокол AAL проверяет служебные поля заголовка и концевика кадра AAL и на их основании принимает решение о корректности полученной информации.
Ни один из протоколов AAL при передаче пользовательских данных конечных узлов не занимается восстановлением потерянных или искаженных данных. Максимум, что делает протокол AAL, - это уведомляет конечный узел о таком событии. Так сделано для ускорения работы коммутаторов сети ATM в расчете на то, что случаи потерь или искажения данных будут редкими. Восстановление потерянных данных (или игнорирование этого события) отводится протоколам верхних уровней, не входящим в стек протоколов технологии ATM.
Протокол AAL1 обычно обслуживает трафик класса А с постоянной битовой скоростью (Constant Bit Rate, CBR), который характерен, например, для цифрового видео и цифровой речи и чувствителен к временным задержкам. В заголовке один байт отводится для нумерации ячеек, чтобы приемная сторона могла судить о том, все ли посланные ячейки дошли до нее или нет. При отправке голосового трафика временная отметка каждого замера известна, так как они следуют друг за другом с интервалом в 125 мкс, поэтому при потере ячейки можно скорректировать временную привязку байт следующей ячейки, сдвинув ее на 125х46 мкс. Потеря нескольких байт замеров голоса не так страшна, так как на приемной стороне воспроизводящее оборудование сглаживает сигнал. В задачи протокола AAL1 входит сглаживание неравномерности поступления ячеек данных в узел назначения.
Протокол AAL2 был разработан для передачи трафика класса В, но при развитии стандартов он был исключен из стека протоколов ATM, и сегодня трафик класса В передается с помощью протокола AAL1, AAL3/4 или AAL5.
Протокол AAL3/4 обрабатывает пульсирующий трафик - обычно характерный для трафика локальных сетей - с переменной битовой скоростью (Variable Bit Rate, VBR). Этот трафик обрабатывается так, чтобы не допустить потерь ячеек, но ячейки могут задерживаться коммутатором. Протокол AAL3/4 выполняет сложную процедуру контроля ошибок при передаче ячеек, нумеруя каждую составляющую часть исходного сообщения и снабжая каждую ячейку контрольной суммой. Правда, при искажениях или потерях ячеек уровень не занимается их восстановлением, а просто отбрасывает все сообщение - то есть все оставшиеся ячейки, так как для компьютерного трафика или компрессированного голоса потеря части данных является фатальной ошибкой. Протокол AAL3/4 образовался в результате слияния протоколов AAL3 и AAL4, которые обеспечивали поддержку трафика компьютерных сетей соответственно с установлением соединения и без установления соединения. Однако ввиду большой близости используемых форматов служебных заголовков и логики работы протоколы AAL3 и AAL4 были впоследствии объединены.
Протокол AAL5 является упрощенным вариантом протокола AAL4 и работает быстрее, так как вычисляет контрольную сумму не для каждой ячейки сообщения, а для всего исходного сообщения в целом и помещает ее в последнюю ячейку сообщения.
Протокол ATM занимает в стеке протоколов ATM примерно то же место, что протокол IP в стеке TCP/IP. Протокол ATM занимается передачей ячеек через коммутаторы при установленном и настроенном виртуальном соединении, то есть на основании готовых таблиц коммутации портов. Протокол ATM выполняет коммутацию по номеру виртуального соединения, который в технологии ATM разбит на две части - идентификатор виртуального пути (Virtual Path Identifier, VPI) и идентификатор виртуального канала (Virtual Channel Identifier, VCI). Кроме этой основной задачи протокол ATM выполняет ряд функций по контролю за соблюдением трафик-контракта со стороны пользователя сети, маркировке ячеек-нарушителей, отбрасыванию ячеек-нарушителей при перегрузке сети, а также управлению потоком ячеек для повышения производительности сети (естественно, при соблюдении условий трафик-контракта для всех виртуальных соединений).
Протокол ATM работает с ячейками следующего формата, представленного на рисунке.

Рис.: Формат ячейки ATM
Поле Управление потоком (Generic Flow Control) используется только при взаимодействии конечного узла и первого коммутатора сети. В настоящее время его точные функции не определены.
Поля Идентификатор виртуального пути (VirtualPath Identifier, VPI) и Идентификатор виртуального канала (Vrtual Channel Identifier, VCI) занимают соответственно 1 и 2 байта. Эти поля задают номер виртуального соединения, разделенный на старшую (VPI) и младшую (VCI) части.
Поле Идентификатор типа данных (Payload Type Identifier, PTI) состоит из 3-х бит и задает тип данных, переносимых ячейкой, - пользовательские или управляющие (например, управляющие установлением виртуального соединения). Кроме того, один бит этого поля используется для указания перегрузки в сети - он называется Explicit Congestion Forward Identifier, EFCI - и играет ту же роль, что бит FECN в технологии frame relay, то есть передает информацию о перегрузке по направлению потока данных.
Поле Приоритет потери кадра (Cell Loss Priority, CLP) играет в данной технологии ту же роль, что и поле DE в технологии frame relay - в нем коммутаторы ATM отмечают ячейки, которые нарушают соглашения о параметрах качества обслуживания, чтобы удалить их при перегрузках сети. Таким образом, ячейки с CLP=0 являются для сети высокоприоритетными, а ячейки с CLP=1 - низкоприоритетными.
Поле Управление ошибками в заголовке (Header Error Control, НЕС) содержит контрольную сумму, вычисленную для заголовка ячейки. Контрольная сумма вычисляется с помощью техники корректирующих кодов Хэмминга, поэтому она позволяет не только обнаруживать ошибки, но и исправлять все одиночные ошибки, а также некоторые двойные.
Рассмотрим методы коммутации ячеек ATM на основе пары чисел VPI/VCI. Коммутаторы ATM могут работать в двух режимах - коммутации виртуального пути и коммутации виртуального канала. В первом режиме коммутатор выполняет продвижение ячейки только на основании значения поля VPI, а значение поля VCI он игнорирует. Обычно так работают магистральные коммутаторы территориальных сетей. Они доставляют ячейки из одной сети пользователя в другую на основании только старшей части номера виртуального канала, что соответствует идее агрегирования адресов. В результате один виртуальный путь соответствует целому набору виртуальных каналов, коммутируемых как единое целое.
После доставки ячейки в локальную сеть ATM ее коммутаторы начинают коммутировать ячейки с учетом как VPI, так и VCI, но при этом им хватает для коммутации только младшей части номера виртуального соединения, так что фактически они работают с VCI, оставляя VPI без изменения. Последний режим называется режимом коммутации виртуального канала.
Адресом конечного узла в коммутаторах ATM является 20-байтный адрес.
Для локальных сетей, в которых замена коммутаторов и сетевых адаптеров равнозначна созданию новой сети, переход на технологию ATM мог быть вызван только весьма серьезными причинами. Гораздо привлекательнее полной замены существующей локальной сети новой сетью ATM выглядела возможность «постепенного» внедрения технологии ATM в существующую на предприятии сеть. При таком подходе фрагменты сети, работающие по новой технологии ATM, могли бы мирно сосуществовать с другими частями сети, построенными на основе традиционных технологий, таких как Ethernet или FDDI, улучшая характеристики сети там, где это нужно, и оставляя сети рабочих групп или отделов в прежнем виде.
В ответ на такую потребность ATM Forum разработал спецификацию, называемую LAN emulation, LANE (то есть эмуляция локальных сетей), которая призвана обеспечить совместимость традиционных протоколов и оборудования локальных сетей с технологией ATM. Эта спецификация обеспечивает совместную работу этих технологий на канальном уровне. При таком подходе коммутаторы ATM работают в качестве высокоскоростных коммутаторов магистрали локальной сети, обеспечивая не только скорость, но и гибкость соединений коммутаторов ATM между собой, поддерживающих произвольную топологию связей, а не только древовидные структуры.
Спецификация LANE определяет способ преобразования кадров и адресов МАС-уровня традиционных технологий локальных сетей в ячейки и коммутируемые виртуальные соединения SVC технологии ATM, а также способ обратного преобразования. Всю работу по преобразованию протоколов выполняют специальные компоненты, встраиваемые в обычные коммутаторы локальных сетей, поэтому ни коммутаторы ATM, ни рабочие станции локальных сетей не замечают того, что они работают с чуждыми им технологиями. Такая прозрачность была одной из главных целей разработчиков спецификации LANE.
Так как эта спецификация определяет только канальный уровень взаимодействия, то с помощью коммутаторов ATM и компонентов эмуляции LAN можно образовать только виртуальные сети, называемые здесь эмулируемыми сетями, а для их соединения нужно использовать обычные маршрутизаторы.
Рассмотрим основные идеи спецификации на примере сети, изображенной на рисунке.
Основными элементами, реализующими спецификацию, являются программные компоненты LEC (LAN Emulation Client) и LES (LAN Emulation Server). Клиент LEC выполняет роль пограничного элемента, работающего между сетью ATM и станциями некоторой локальной сети. На каждую присоединенную к сети ATM локальную сеть приходится один клиент LEC.
Сервер LES ведет общую таблицу соответствия MAC-адресов станций локальных сетей и АТМ-адресов пограничных устройств с установленными на них компонентами LEC, к которым присоединены локальные сети, содержащие эти станции. Таким образом, для каждой присоединенной локальной сети сервер LES хранит один АТМ-адрес пограничного устройства LEC и несколько МАС-адресов станций, входящих в эту сеть. Клиентские части LEC динамически регистрируют в сервере LES МАС-адреса каждой станции, заново подключаемой к присоединенной локальной сети.

Рис.: Принципы работы технологии LAN emulation
Программные компоненты LEC и LES могут быть реализованы в любых устройствах - коммутаторах, маршрутизаторах или рабочих станциях ATM.
Когда элемент LEC хочет послать пакет через сеть ATM станции другой локальной сети, также присоединенной к сети ATM, он посылает запрос на установление соответствия между МАС-адресом и АТМ-адресом серверу LES. Сервер LES отвечает на запрос, указывая АТМ-адрес пограничного устройства LEC, к которому присоединена сеть, содержащая станцию назначения. Зная АТМ-адрес, устройство LEC исходной сети самостоятельно устанавливает виртуальное соединение SVC через сеть ATM обычным способом, описанным в спецификации UNI. После установления связи кадры MAC локальной сети преобразуются в ячейки ATM каждым элементом LEC с помощью стандартных функций сборки-разборки пакетов (функции SAR) стека ATM.
В спецификации LANE также определен сервер для эмуляции в сети ATM широковещательных пакетов локальных сетей, а также пакетов с неизвестными адресами, так называемый сервер BUS (Broadcast and Unknown Server). Этот сервер распространяет такие пакеты во все пограничные коммутаторы, присоединившие свои сети к эмулируемой сети.
На рисунке все пограничные коммутаторы образуют одну эмулируемую сеть. Если же необходимо образовать несколько эмулируемых сетей, не взаимодействующих прямо между собой, то для каждой такой сети необходимо активизировать собственные серверы LES и BUS, а в пограничных коммутаторах активизировать по одному элементу LEC для каждой эмулируемой сети. Для хранения информации о количестве активизированных эмулируемых сетей, а также АТМ-адресах соответствующих серверов LES и BUS вводится еще один сервер - сервер конфигурации LECS (LAN Emulation Configuration Server).
Технология ATM расширяет свое присутствие в локальных и глобальных сетях не очень быстро, но неуклонно. В последнее время наблюдается устойчивый ежегодный прирост числа сетей, выполненных по этой технологии, в 20-30%.
В локальных сетях технология ATM применяется обычно на магистралях, где хорошо проявляются такие ее качества, как масштабируемая скорость (выпускаемые сегодня корпоративные коммутаторы ATM поддерживают на своих портах скорости 155 и 622 Мбит/с), качество обслуживания (для этого нужны приложения, которые умеют запрашивать нужный класс обслуживания), петлевидные связи (которые позволяют повысить пропускную способность и обеспечить резервирование каналов связи). Петлевидные связи поддерживаются в силу того, что ATM - это технология с маршрутизацией пакетов, запрашивающих установление соединений, а значит, таблица маршрутизации может эти связи учесть - либо за счет ручного труда администратора, либо за счет протокола маршрутизации PNNI.
Основной соперник технологии ATM в локальных сетях - технология Gigabit Ethernet. Она превосходит ATM в скорости передачи данных - 1000 Мбит/с по сравнению с 622 Мбит/с, а также в затратах на единицу скорости. Там, где коммутаторы ATM используются только как высокоскоростные устройства, а возможности поддержки разных типов трафика игнорируются, технологию ATM, очевидно, заменит технология Gigabit Ethernet. Там же, где качество обслуживания действительно важно (видеоконференции, трансляция телевизионных передач и т. п.), технология ATM останется. Для объединения настольных компьютеров технология ATM, вероятно, еще долго не будет использоваться, так как здесь очень серьезную конкуренцию ей составляет технология Fast Ethernet.
В глобальных сетях ATM применяется там, где сеть frame relay не справляется с большими объемами трафика, и там, где нужно обеспечить низкий уровень задержек, необходимый для передачи информации реального времени.
Сегодня основной потребитель территориальных коммутаторов ATM - это Internet. Коммутаторы ATM используются как гибкая среда коммутации виртуальных каналов между IP-маршрутизаторами, которые передают свой трафик в ячейках ATM. Сети ATM оказались более выгодной средой соединения IP-маршрутизаторов, чем выделенные каналы SDH, так как виртуальный канал ATM может динамически перераспределять свою пропускную способность между пульсирующим трафиком клиентов IP-сетей.
Сегодня по данным исследовательской компании Distributed Networking Associates около 85% всего трафика, переносимого в мире сетями ATM, составляет трафик компьютерных сетей (наибольшая доля приходится на трафик IP - 32%).
Что же касается совместимости ATM с технологиями компьютерных сетей, то разработанные в этой области стандарты вполне работоспособны и удовлетворяют пользователей и сетевых интеграторов.
34. Принципы организации внешних запоминающих устройств на различных типах носителей – магнитных, оптических и т.П.
Внешняя память компьютера, Внешние запоминающие устройства.
В нешняя
память компьютера или ВЗУ - важная
составная часть электронно-вычислительной
машины, обеспечивающая долговременное
хранение программ и данных на различных
носителях информации. Внешние
запоминающие устройства (ВЗУ) -
можно классифицировать по целому ряду
признаков : по виду носителя, по типу
конструкции, по принципу записи и
считывания информации, по методу доступа
и т.д. При этом под носителем понимается
материальный объект, способный хранить
информацию.
нешняя
память компьютера или ВЗУ - важная
составная часть электронно-вычислительной
машины, обеспечивающая долговременное
хранение программ и данных на различных
носителях информации. Внешние
запоминающие устройства (ВЗУ) -
можно классифицировать по целому ряду
признаков : по виду носителя, по типу
конструкции, по принципу записи и
считывания информации, по методу доступа
и т.д. При этом под носителем понимается
материальный объект, способный хранить
информацию.
Свойства внешней памяти :
ВЗУ энергонезависима, целостность её содержимого не зависит от того, включен или выключен компьютер .
В отличие от оперативной памяти, внешняя память не имеет прямой связи с процессором.
В состав внешней памяти включаются :
НЖМД – накопители на жёстких магнитных дисках.
НГМД – накопители на гибких магнитных дисках.
НОД – накопители на оптических дисках (компакт-дисках CD-R, CD-RW, DVD).
НМЛ – накопители на магнитной ленте (стримеры).
Карты памяти.
Накопители – это запоминающие устройства, предназначенные для длительного (то есть не зависящего от электропитания) хранения больших объемов информации.
Кроме основной своей характеристики – информационной емкости – дисковые накопителихарактеризуются и двумя другими показателями : временем доступа и скоростью считывания последовательно расположенных байтов.
Накопители на жестких дисках.
Н акопитель
на жёстких магнитных дисках (HDD
– Hard Disk Drive, винчестер) - это запоминающее
устройство большой ёмкости, в котором
носителями информации являются круглые
алюминиевые пластины, обе поверхности
которых покрыты слоем магнитного
материала. Используется для постоянного
хранения информации - программ и
данных. HDD обычно
называют«винчестером» – так в
свое время стали называть одну из первых
моделей Накопителя на жёстких
магнитных дисках, которая имела
обозначение «30/30» и этим напоминала
маркировку известного оружия.
акопитель
на жёстких магнитных дисках (HDD
– Hard Disk Drive, винчестер) - это запоминающее
устройство большой ёмкости, в котором
носителями информации являются круглые
алюминиевые пластины, обе поверхности
которых покрыты слоем магнитного
материала. Используется для постоянного
хранения информации - программ и
данных. HDD обычно
называют«винчестером» – так в
свое время стали называть одну из первых
моделей Накопителя на жёстких
магнитных дисках, которая имела
обозначение «30/30» и этим напоминала
маркировку известного оружия.
Примечание
Возможно, также, что название происходит от места первоначальной разработки – филиала фирмы IBM в г. Винчестере (Великобритания), где впервые была применена технология создания винчестеров...
Винчестер.
Поверхность диска рассматривается как последовательность точечных позиций, каждая из которых считается битом и может быть установлена в 0 или 1. Так как расположения точечных позиций определяется неточно, то для записи требуются заранее нанесенные метки, которые помогают записывающему устройству находить позиции записи. Процесс нанесения таких меток называется физическим форматированием и является обязательным перед первым использованием накопителя. Винчестеры имеют очень большую ёмкость : от сотен Мегабайт (самые старые) до десятков терабайт.
Структурные элементы винчестера.
На каждой стороне каждой пластины размечены тонкие концентрические окружности (по ним располагаются синхронизирующиеся метки). Каждая концентрическая окружность называется дорожкой. Группы дорожек (треков) одного радиуса, расположенных на поверхностях магнитных дисков, называются цилиндрами. Номер цилиндра совпадает с номером образующей дорожки. HDD могут иметь по несколько десятков тысяч цилиндров.
Каждая дорожка разбивается на секторы. Сектор – наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Нумерация секторов начинается с 1. Для того чтобы контроллер диска мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора : номер цилиндра, номер поверхности, номер сектора ([c-h-s]).
Операционная система при работе с диском использует, как правило, собственную единицу дискового пространства, называемую кластером. Кластер (ячейка размещения данных) - объем дискового пространства, участвующий в единичной операции чтения/записи, осуществляемой операционной системой.
Магнитные накопители.
Н акопитель
на гибких магнитных дисках - Гибкий
диск, дискета (англ.floppy
disk) – устройство для хранения небольших
объёмов информации, представляющее
собой гибкий пластиковый диск в защитной
оболочке. Наиболее распространены –
«трехдюймовые дискеты». Дискета 3,5 имеет
2 рабочие поверхности, 80 дорожек на
каждой стороне, 18 секторов на каждой
дорожке (512 байт – каждый сектор).
акопитель
на гибких магнитных дисках - Гибкий
диск, дискета (англ.floppy
disk) – устройство для хранения небольших
объёмов информации, представляющее
собой гибкий пластиковый диск в защитной
оболочке. Наиболее распространены –
«трехдюймовые дискеты». Дискета 3,5 имеет
2 рабочие поверхности, 80 дорожек на
каждой стороне, 18 секторов на каждой
дорожке (512 байт – каждый сектор).
Устройство дискеты : Принцип записи на магнитных носителяхоснован на намагниченности отдельных участков магнитного слоя носителя. Информация записывается по концентрическим дорожкам (трекам), которые делятся на секторы. Количество дорожек и секторов зависит от типа и формата дискеты. Сектор хранит минимальную порцию информации, которая может быть записана на диск или считана. Емкость сектора постоянна и составляет 512 байтов.
Примечание
На сегодняшний день дискеты устарели, на смену им «пришли» более надежные, быстродействующие и более емкие носители – оптические диски и карты памяти...
Накопители на магнитной ленте (стримеры).
Стример (англ. tape streamer) – устройство для резервного копирования больших объёмов информации. В качестве носителя здесь применяются кассеты с магнитной лентой ёмкостью 1 - 2 Гбайта и больше. Недостатком стримеров является их сравнительно низкая скорость записи, поиска и считывания информации.
Примечание
На сегодняшний день стримеры устарели и практически не применяются...
35. Классификация информационно-вычислительных сетей. Сети одноранговые и "клиент/сервер"
Локальные, глобальные и территориальные сети могут быть одноранговыми сетями, сетями типа «Клиент/Сервер» (они также называются сетями с выделенным сервером) или смшанными сетями (в которых используются как одноранговые технологии, так и технологии с выделенным сервером).
Компьютеры в одноранговых сетях могут выступать как в роли клиентов, так и в роли серверов. Так как все компьютеры в этом типе сетей равноправны, одноранговые сети не имеют централизованного управления резделением ресурсов. Любой из компьютеров может разделять свои ресурсы с любым компьютером в той же сети. Одноранговые взаимоотношения также означают, что ни один компьютер не имеет ни высшего приоритета на доступ, ни повышенной ответственности за предоставление ресурсов в совместное пользование.
Каждый пользователь в одноранговой сети является одновременно сетевым администратором. Это означает, что каждый пользователь в сети управляет доступом к ресурсам, расположенным на его компьютере. Он может дать всем остальным неограниченный доступ к локальным ресурсам, дать ограниченный доступ, а может не дать вообще никакого доступа другим пользователям. Каждый пользователь также решает, дать другим пользователям доступ просто по их запросу или защитить эти ресурсы паролем.
Основной проблемой в одноранговых сетях является безопасность, т.к. отсутствуют средства обеспечения безопасности в масштабе сети. При этом отдельные ресурсы отдельных компьютеров могут быть защищены системой паролей, и только те пользователи, которые знают пароль, могут получить доступ к ресурсам.
Этот тип сети может быть работоспособным в малых сетях, но так же требует, чтобы пользователи знали и помнили различные пароли для каждого разделенного ресурса в сети. С ростом количества пользователей и ресурсов одноранговая сеть становится неработоспособной. Это происходит не потому, что сеть не может функционировать правильно, а потому, что пользователи не в состоянии справиться со сложностью сети.
К тому же большинство одноранговых сетей состоит из набора типичных персональных компьютеров, связанных общим сетевым носителем. Эти типы компьтеров не были разработаны для работы в качестве сетевых серверов, поэтому производительность сети может упасть, когда много пользователей попытаются одновременно получить доступ к ресурсам какого-то одного компьютера. Кроме того, пользователь, к чьей машине происходит доступ по сети, сталкивается с падением производительности в то время, когда компьютер выполняет затребованные сетевые службы. Например, если к компьютеру пользователя подключен принтер, к которому осуществляется доступ по сети, компьютер будет замедлять свою работу каждый раз, когда пользователи посылают задание на этот принтер. Это может раздражать того, кто работает на данной машине.
В одноранговой сети также трудно организовать хранение и учет данных. Когда каждый сетевой компьютер может служить сервером, пользователям трудно отслеживать, на какой машине лежит интересующая их информация. Децентрализованная природа такого типа сети делает поиск ресурсов чрезвычайно сложным с ростом числа узлов, на которых должна происходить проверка. Децентрализация также затрудняет процедуру резервного копирования данных – вместо копирования централизованного хранилища данных требуется осуществлять резервное копирование на каждом сетевом компьютере, чтобы защитить разделенные данные.
Однако одноранговые сети имеют серьезные преимущества перед сетями с выделенным сервером, особенно для малых организаций и сетей. Одноранговые сети являются наиболее легким и дешевым типом сетей для установки. Большинство одноранговых сетей требует наличия на компьютерах, кроме сетевой карты и сетевого носителя (кабеля), только операционной системы. Как только компьютеры соединены, пользователи немедленно могут начинать предоставление ресурсов и информации в совместное пользование.
Преимущества одноранговых сетей:
Легкость в установке и настройке;
Независимость отдельных машин от выделенного сервера;
Возможность пользователем контролировать свои собственные ресурсы;
Сравнительная дешевизна в прибретении и эксплуатации;
Отсутствие необходимости в дополнительном программном обеспечении, кроме операционной системы;
Отсутствие необходимости иметь отдельного человека в качестве выделенного администратора сети.
Недостатки одноранговых сетей:
Необходимость помнить столько паролей, сколько имеется разделенных ресурсов;
Необходимость производить резервное копирование на каждом компьютере, чтобы защитить все совместные данные;
Падение производительности при доступе к разделенному ресурсу на компьютере, где этот ресурс расположен;
Отсутствие централизованной организационной схемы для поиска и управления доступом к данным.
Сети с выделенным сервером или сети типа «клиент/сервер» опираются на специализированные компьютеры, называемые серверами, представляющими собой централизованные хранилища сетевых ресурсов и объединяющими централизованное обеспечение безопасности и управления доступом. В отличие от сетей с выделенным сервером, одноранговые сети не имеют централизованного обеспечения безопасности и управления. Сервер представляет собой сочетание специализированного программного обеспечения и оборудования, которое предоставляет службы в сети для остальных клиентских компьютеров (рабочих станций) или других процессов.
Имеется несколько причин для реализации сети с выделенным сервером, включающих централизованное управление сетевыми ресурсами путем использования сетевой безопасности и управления доступом посредством установки и настройки сервера. С точки зрения оборудования, сетевые компьютеры обычно имеют более быстрый центральный процессор, больше памяти, большие жесткие диски и дополнительные перифирийные устройства, например, накопители на магнитной ленте и приводы компакт-дисков, по сравнению с клиентскими машинами. Серверы также ориентированы на то, чтобы обрабатывать многочисленные запросы на разделяемые ресурсы быстро и эффективно. Серверы обычно выделены для обслуживания сетевых запросов клиентов. В дополнение, физическая безопасность – доступ к самой машине – является ключевым компонентом сетевой безопасности. Поэтому важно, чтобы серверы располагались в специальном помещении с контролируемым доступом, отделенном от помещений с общим доступом.
Сети с выделенным сервером такжк предоставляют централизованную проверку учетных записей пользователей и паролей. Например, Windows NT использует доменную концепцию для управленя пользователями, группами и машинами и для контроля над доступом к сетевым ресурсам. Прежде чем пользователь сможет получить доступ к сетевым ресурсам, он должен сообщить свое регистрационное имя и пароль контроллеру домена – серверу, который проверяет имена учетных записей и пароли в базе данных с такой информацией. Контроллер домена позволит доступ к определенным ресурсам только в случае допустимой комбинации данных регистрационного имени и пароля. Изменять связанную с безопасностью информацию в базе данных контроллера домена может только сетевой администратор. Этот подход обеспечивает централизованную безопасность и позволяет управлять ресурсами с изменяющейся степенью контроля в зависимсти от их важности и расположения.
В отличи от одноранговой модели, сеть с выделенным сервером обычно требует только один пароль для доступа к самой сети, что уменьшает количество паролей, которые пользователь должен помнить. Кроме того, сетевые ресурсы типа файлов и принтеров легче найти, потому что они расположены на определенном сервере, а не на чьей-то машине в сети. Концентрация сетевых ресурсов на небольшом количестве серверов также упрощает резервное копирование и поддержку данных.
Сети с выделенным сервером лучше масштабируются – в сравнении с одноранговыми сетями. С ростом размера одноранговые сети сильно замедляют свою работу и становятся неуправляемыми. Сети с выделенным сервером, наоборот, могут обслуживать от единичных пользователей до десятков тысяч пользователей и географически распределенных ресурсов. Другими словами, сеть с выделенным сервером может расти с ростом используюущей ее организации.
Подобно одноранговой модели, сеть с выделенным сервером также имеет недостатки. Первой в этом списке стоит необходимость дополнительных расходов на такие сети. Сеть с выделенным сервером требует наличия одного или нескольких более мощных – и, соответственно, более дорогих – компьютеров для запуска специального (и тоже дорогого) серверного программного обеспечения. Вдобавок серверное программное обеспечение требует квалифицированного персонала для его обслуживания. Подготовка персонала для овладения необходимыми для обслуживания сети с выделенным сервером навыками или наем на работу подготовленных сетевых администраторов также увеличивает стоимость такой сети.
Есть и другие негативные аспекты сетей с выделенным сервером. Централизация ресурсов и управления упрощает доступ, контроль и объединение ресурсов, но при этом приводит к появлению точки, которая может привести к неполадкам во всей сети. Если сервер вышел из строя, -- не работает вся сеть. В сетях с несколькими серверами потеря одного сервера означает потерю всех ресурсов, связанных с этим сервером. Также, если неисправный сервер является единственным источником информации о правах доступа определенной части пользователей, эти пользователи не смогут получить доступ к сети.
Преимущества сетей с выделенным сервером:
Обеспечение централизованного управления учетными записями пользователей, безопасностью и доступом, что упрощает сетевое администрирование;
Использование более мощного серверного оборудования означает и более эффективный доступ к сетевым ресурсам;
Пользователям для входа в сеть нужно помнить только один пароль, что позволяет им получить доступ ко всем ресурсам, к которым имеют права.
Недостатки сетей с выделенным сервером:
Неисправность сервера может сделать сеть неработоспособной, что в лучшем случае означает потерю сетевых ресурсов;
Сети требуют квалифицированного персонала для сопровождения сложного специализированного программного обеспечения, что увеличивает общую стоимость сети;
Стоимость также увеличивается благодаря потребности в выделенном оборудовании и специализированном программном обеспечении.
36. Классификация видов моделирования; имитационные модели систем
В основе моделирования лежит теория подобия, которая утверждает, что абсолютное подобие может иметь место лишь при замене одного объекта другим точно таким же. При моделировании абсолютное подобие не имеет места и стремятся к тому, чтобы модель достаточно хорошо отображала исследуемую сторону функционирования объекта.
В качестве одного из первых признаков классификации видов моделирования можно выбрать степень полноты модели и разделить модели в соответствии с этим признаком на полные, неполные и приближенные. В основе полного моделирования лежит полное подобие, которое проявляется как во времени, так и в пространстве. Для неполного моделирования характерно неполное подобие модели изучаемому объекту. В основе приближенного моделирования лежит приближенное подобие, при котором некоторые стороны функционирования реального объекта не моделируются совсем. Классификация видов моделирования систем S приведена на рисунке. В зависимости от характера изучаемых процессов в системе S все виды моделирования могут быть разделены на детерминированные и стохастические, статические и динамические, дискретные, непрерывные и дискретно-непрерывные. Детерминированное моделирование отображает детерминированные процессы, т.е. процессы, в которых предполагается отсутствие всяких случайных воздействий; Стохастическое моделирование отображает вероятностные процессы и события. В этом случае анализируется ряд реализаций случайного процесса и оцениваются средние характеристики, т.е. набор однородных реализаций.
Статическое моделирование служит для описания поведения объекта в какой-либо момент времени, а динамическое моделирование отражает поведение объекта во времени. Дискретное моделирование служит для описания процессов, которые предполагаются дискретными, соответственно непрерывное моделирование позволяет отразить непрерывные процессы в системах, а дискретно-непрерывное моделирование используется для случаев, когда хотят выделить наличие как дискретных, так и непрерывных процессов.
В зависимости от формы представления объект можно выделить мысленное и реальное моделирование. Мысленное моделирование часто является единственным способом моделирования объектов, которые либо практически нереализуемы в заданном интервале времени, либо существуют вне условий, возможных для их физического создания. Например, на базе мысленного моделирования могут быть проанализированы многие ситуации микромира, которые не поддаются физическому эксперименту. Мысленное моделирование может быть реализовано в виде наглядного, символического и математического. Принаглядном моделировании на базе представлений человека о реальных объектах создаются различные наглядные модели, отображающие явления и процессы, протекающие в объекте.
В основу гипотетического моделирования исследователем закладывается некоторая гипотеза о закономерностях протекания процесса в реальном объекте, которая отражает уровень знаний исследователя об объекте и базируется на причинно-следственных связях между входом и выходом изучаемого объекта. Гипотетическое моделирование используется, когда знаний об объекте недостаточно для построения формальных моделей.
Аналоговое моделирование основывается на применении аналогий различных уровней. Наивысшим уровнем является полная аналогия, имеющая место только для достаточно простых объектов. С усложнением объекта используют аналогии последующих уровней, когда аналоговая модель отображает несколько либо только одну сторону функционирования объекта. Существенное место при мысленном наглядном моделировании занимает макетирование. Мысленный макет может применяться в случаях, когда протекающие в реальном объекте процессы не поддаются физическому моделированию, либо может предшествовать проведению других видов моделирования. В основе построения мысленных макетов также лежат аналогии, однако обычно базирующиеся на причинно-следственных связях между явлениями и процессами в объекте.
Если ввести условное обозначение отдельных понятий, т. е. знаки, а также определенные операции между этими знаками, то можно реализовать знаковое моделирование и с помощью знаков отображать набор понятий - составлять отдельные цепочки из слов и предложений. Используя операции объединения, пересечения и дополнения теории множеств, можно в отдельных символах дать описание какого-то реального объекта. В основе языкового моделирования лежит некоторый тезаурус. Последний образуется из набора входящих понятий, причем этот набор должен быть фиксированным.
Следует отметить, что между тезаурусом и обычным словарем имеются принципиальные различия. Тезаурус - словарь, который очищен от неоднозначности, т.е. в нем каждому слову может соответствовать лишь единственное понятие, хотя в обычном словаре одному слову могут соответствовать несколько понятий.
Символическое моделирование представляет собой искусственный процесс создания логического объекта, который замещает реальный и выражает основные свойства его отношений с помощью определенной системы знаков или символов. Математическое моделирование. Для исследования характеристик процесса функционирования любой системы S математическими методами, включая и машинные, должна быть проведена формализация этого процесса, т. е. построена математическая модель.
Под математическим моделированием будем понимать процесс установления соответствия данному реальному объекту некоторого математического объекта, называемого математической моделью, и исследование этой модели, позволяющее получать характеристики рассматриваемого реального объекта. Вид математической модели зависит как от природы реального объекта, так и задач исследования объекта и требуемой достоверности и точности решения этой задачи.
Любая математическая модель, как и всякая другая, описывает реальный объект лишь с некоторой степенью приближения к действительности. Математическое моделирование для исследования характеристик процесса функционирования систем можно разделить на аналитическое, имитационное и комбинированное. Для аналитического моделирования характерно то, что процессы функционирования элементов системы записываются в виде некоторых функциональных соотношений (алгебраических, интегродифференпиальных, конечно-разностных и т. п.) или логических условий.
Аналитическая модель может быть исследована следующими методами:
аналитическим, когда стремятся получить в общем виде явные зависимости для искомых характеристик;
численным, когда, не умея решать уравнений в общем виде, стремятся получить числовые результаты при конкретных начальных данных;
качественным, когда, не имея решения в явном виде, можно найти некоторые свойства решения.
Пример: оценить устойчивость решения)
Наиболее полное исследование процесса функционирования системы можно провести, если известны явные зависимости, связывающие искомые характеристики с начальными условиями, параметрами и переменными системы S. Однако такие зависимости удается получить только для сравнительно простых систем. При усложнении систем исследование их аналитическим методом наталкивается на значительные трудности, которые часто бывают непреодолимыми. Поэтому, желая использовать аналитический метод, в этом случае идут на существенное упрощение первоначальной модели, чтобы иметь возможность изучить хотя бы общие свойства системы. Такое исследование на упрощенной модели аналитическим методом помогает получить ориентировочные результаты для определения более точных оценок другими методами. Численный метод позволяет исследовать по сравнению с аналитическим методом более широкий класс систем, но при этом полученные решения носят частный характер. Численный метод особенно эффективен при использовании ЭВМ.
В отдельных случаях исследования системы могут удовлетворить и те выводы, которые можно сделать при использовании качественного метода анализа математической модели. Такие качественные методы широко используются, например, в теории автоматического управления для оценки эффективности различных вариантов систем управления. В настоящее время распространены методы машинной реализации исследования характеристик процесса функционирования больших систем. Для реализации математической модели на ЭВМ необходимо построить соответствующий моделирующий алгоритм. Приимитационном моделировании реализующий модель алгоритм воспроизводит процесс функционирования системы S во времени, причем имитируются элементарные явления, составляющие процесс, с сохранением их логической структуры и последовательности протекания во времени, что позволяет по исходным данным получить сведения о состояниях процесса в определенные моменты времени, дающие возможность оценить характеристики системы S.
Основным преимуществом имитационного моделирования по сравнению с аналитическим является возможность решения более сложных задач. Имитационные модели позволяют достаточно просто учитывать такие факторы, как наличие дискретных и непрерывных элементов, нелинейные характеристики элементов системы, многочисленные случайные воздействия и др., которые часто создают трудности при аналитических исследованиях. В настоящее время имитационное моделирование - наиболее эффективный метод исследования больших систем, а часто и единственный практически доступный метод получения информации о поведении системы, особенно на этапе ее проектирования. Когда результаты, полученные при воспроизведении на имитационной модели процесса функционирования системы S, являются реализациями случайных величин и функций, тогда для нахождения характеристик процесса требуется его многократное воспроизведение с последующей статистической обработкой информации и целесообразно в качестве метода машинной реализации имитационной модели использовать метод статистического моделирования.
Первоначально был разработан метод статистических испытаний, представляющий собой численный метод, который применялся для моделирования случайных величин и функций, вероятностные характеристики которых совпадали с решениями аналитических задач (такая процедура получила название метода Монте-Карло). Затем этот прием стали применять и для машинной имитации с целью исследования характеристик процессов функционирования систем, подверженных случайным воздействиям, т.е. появился метод статистического моделирования. Таким образом, методом статистического моделирования будем в дальнейшем называть метод машинной реализации имитационной модели, а методом статистических испытаний (Монте-Карло) - численный метод решения аналитической задачи.
Метод имитационного моделирования позволяет решать задачи анализа больших систем S, включая задачи оценки: вариантов структуры системы, эффективности различных алгоритмов управления системой, влияния изменения различных параметров системы. Имитационное моделирование может быть положено также в основу структурного, алгоритмического и параметрического синтеза больших систем, когда требуется создать систему, с заданными характеристиками при определенных ограничениях, которая является оптимальной по некоторым критериям оценки эффективности.
При решении задач машинного синтеза систем на основе их имитационных моделей помимо разработки моделирующих алгоритмов для анализа фиксированной системы необходимо также разработать алгоритмы поиска оптимального варианта системы. Далее в методологии машинного моделирования будем различать два основных раздела: статику и динамику, основным содержанием которых являются соответственно вопросы анализа и синтеза систем, заданных моделирующими алгоритмами.
Комбинированное (аналитико-имитационное) моделирование при анализе и синтезе систем позволяет объединить достоинства аналитического и имитационного моделирования. При построении комбинированных моделей проводится предварительная декомпозиция процесса функционирования объекта на составляющие подпроцессы и для тех из них, где это возможно, используются аналитические модели, а для остальных подпроцессов строятся имитационные модели. Такой комбинированный подход позволяет охватить качественно новые классы систем, которые не могут быть исследованы с использованием только аналитического и имитационного моделирования в отдельности.
Другие виды моделирования
При реальном моделировании используется возможность исследования различных характеристик либо на реальном объекте целиком, либо на его части. Такие исследования могут проводиться как на объектах, работающих в нормальных режимах, так и при организации специальных режимов для оценки интересующих исследователя характеристик (при других значениях переменных и параметров, в другом масштабе времени и т. д.). Реальное моделирование является наиболее адекватным, но при этом его возможности с учетом особенностей реальных объектов ограничены.
Пример: Проведение реального моделирования АСУ (Автоматическая Система Управления) предприятием потребует, во-первых, создания такой АСУ, а во-вторых, проведения экспериментов с управляемым объектом, т. е. предприятием, что в большинстве случаев невозможно.
Натурным моделированием называют проведение исследования на реальном объекте с последующей обработкой результатов эксперимента на основе теории подобия. При функционировании объекта в соответствии с поставленной целью удается выявить закономерности протекания реального процесса.Надо отметить, что такие разновидности натурного эксперимента, как производственный эксперимент и комплексные испытания, обладают высокой степенью достоверности.
С развитием техники и проникновением в глубь процессов, протекающих в реальных системах, возрастает техническая оснащенность современного научного эксперимента. Он характеризуется широким использованием средств автоматизации проведения, применением весьма разнообразных средств обработки информации, возможностью вмешательства человека в процесс проведения эксперимента, и в соответствии с этим появилось новое научное направление - автоматизация научных экспериментов.
Отличие эксперимента от реального протекания процесса заключается в том, что в нем могут появиться отдельные критические ситуации и определяться границы устойчивости процесса. В ходе эксперимента вводятся новые факторы и возмущающие воздействия в процессе функционирования объекта. Одна из разновидностей эксперимента - комплексные испытания, которые также можно отнести к натурному моделированию, когда вследствие повторения испытаний изделий выявляются общие закономерности о надежности этих изделий, о характеристиках качества и т.д. В этом случае моделирование осуществляется путем обработки и обобщения сведений, проходящих в группе однородных явлений.
Наряду со специально организованными испытаниями возможна реализация натурного моделирования путем обобщения опыта, накопленного в ходе производственного процесса, т. е. можно говорить о производственном эксперименте. Здесь на базе теории подобия обрабатывают статистический материал по производственному процессу и получают его обобщенные характеристики.
Другим видом реального моделирования является физическое, отличающееся от натурного тем, что исследование проводится на установках, которые сохраняют природу явлений и обладают физическим подобием. В процессе физического моделирования задаются некоторые характеристики внешней среды и исследуется поведение либо реального объекта, либо его модели при заданных или создаваемых искусственно воздействиях внешней среды.
Физическое моделирование может протекать в реальном и нереальном (псевдореальном) масштабах времени, а также может рассматриваться без учета времени. В последнем случае изучению подлежат так называемые "замороженные" процессы, которые фиксируются в некоторый момент времени. Наибольшие сложность и интерес с точки зрения верности получаемых результатов представляет физическое моделирование в реальном масштабе времени. С точки зрения математического описания объекта и в зависимости от его характера модели можно разделить на модели аналоговые (непрерывные), цифровые (дискретные) и аналого-цифровые (комбинированные).
Под аналоговой моделью понимается модель, которая описывается уравнениями, связывающими непрерывные величины. Под цифровой понимают модель, которая описывается уравнениями, связывающими дискретные величины, представленные в цифровом виде. Под аналого-цифровой понимается модель, которая может быть описана уравнениями, связывающими непрерывные и дискретные величины.
Особое место в моделировании занимает кибернетическое моделирование, в котором отсутствует непосредственное подобие физических процессов, происходящих в моделях, реальным процессам. В этом случае стремятся отобразить лишь некоторую функцию и рассматривают реальный объект как "черный ящик", имеющий ряд входов и выходов, и моделируют некоторые связи между выходами и входами. Чаще всего при использовании кибернетических моделей проводят анализ поведенческой стороны объекта при различных воздействиях внешней среды.
Таким образом, в основе кибернетических моделей лежит отражение некоторых информационных процессов управления, что позволяет оценить поведение реального объекта. Для построения имитационной модели в этом случае необходимо выделить исследуемую функцию реального объекта, попытаться формализовать эту функцию в виде некоторых операторов связи между входом и выходом и воспроизвести на имитационной модели данную функцию, причем на базе совершенно иных математических соотношений и, естественно, иной физической реализации процесса.
37. Стек протоколов. Протокол hdlc. Стек протоколов tcp/ip
Протокол канального уровня HDLC (Higher-levelDataLinkControl), разработанный МОС, является бит-ориентированным протоколом конвейерного типа. Он эквивалентен протоколу ADCCP Американского национального института стандартов (ANSI). Подмножество HDLC используется в качестве канального протокола X.25 МККТТ. Различные промышленные фирмы пользуются своими производными от HDLC, среди которых наиболее известен протокол SDLC фирмы IBM. Протокол HDLC становится наиболее принятым протоколом канального уровня для распределенной обработки и компьютерных сетей. Подробное описание протокола можно найти в [18].
Кадр в протоколе HDLC имеет следующую структуру:
ФЛАГ АДРЕС УПРАВЛЕНИЕ ИНФОРМАЦИЯ КПП ФЛАГ
8 бит 8 бит 8/16 бит N бит 16 бит 8 бит
Этот формат кадра называют информационным. Имеется также управляющий формат, который отличается от информационного тем, что не имеет поля информации. Для обнаружения ошибок в кадрах используется кадровая проверочная последовательность (КПП). В адресном поле записывается адрес вторичной станции или направление передачи кадра по каналу.
В HDLC имеется три типа кадров: информационный (I-кадр), cупервизорный (или управляющий) (S-кадр) и ненумерованный (U-кадр). Полный перечень кадров представлен в табл. 7.1.
Таблица 7.1
Типы кадров HDLC
Название кадра |
Мнемоника |
Функция |
Информационный Супервизорные: Готовность к приему Неготовность к приему Отказ Селективный отказ Ненумерованные: Установить режим нормальных ответов (расширенный) Установить режим асинхронных ответов (расширенный) Установить сбалансированный асинхронный режим (расширенный) Разъединить соединение Установить режим инициализации Запрос режима инициализации Запрос передачи (ненумерованный) Сброс Ненумерованный информационный Обмен идентификаторами Ненумерованное подтверждение Режим разъединения Запрос разъединения Отказ от кадра |
I RR RNR REJ SREJ SNRM(E) SARM(E) SABM(E) DISC SIM RIM UP RSET UI XID UA DM RD FRMR |
Команда/Ответ Команда/Ответ Команда/Ответ Команда/Ответ Команда/Ответ Команда Команда Команда Команда Команда Ответ Команда Команда Команда/Ответ Команда/Ответ Ответ Ответ Ответ Команда/Ответ |
I-кадры предназначены для переноса пользовательских данных. Кодировка управляющего поля I-кадра следующая: бит 1 – 0 (признак информационного кадра); биты 2, 3, 4 – NS; бит 5 – P/F; биты 6, 7, 8 – NR, где NS – номер передаваемого кадра, P/F – бит запроса/ответа, NR – номер ожидаемого (при приеме) кадра.
С помощью S-кадров выполняются функции управления передачей данных. Поле управления S-кадра имеет следующий формат: биты 1, 2 – 10 (признак S-кадра); биты 3, 4 – S; бит 5 – P/F; биты 6, 7, 8 – NR, где S – разновидность S-кадра.
U-кадры используются для дополнительных функций управления звеном передачи и предназначены главным образом для запуска и завершения процедур на уровне канала, а также для передачи информации о состоянии выполнения этих процедур. Поле управления U-кадра имеет следующий формат: биты 1, 2 – 11 (признак U-кадра); бит 5 – P/F; биты 3, 4, 6, 7, 8 – М (модификатор). Поле модификатора определяет разновидность U-кадра.
Кадры делятся на команды и ответы в зависимости от того, станция какого типа их пересылает. В HDLC существует три типа станций:
– первичные станции (ПрС) – те, которые посылают команды, принимают ответы и являются ответственными за восстановление ошибок канального уровня;
– вторичные станции (ВтС) – те, которые принимают команды, посылают ответы и могут участвовать в действиях по восстановлению ошибок;
– комбинированные станции – станции, сочетающие функции первичных и вторичных.
Существует несколько классов процедур HDLC,компонентами которых являются:
– три типа станций: первичная, вторичная и комбинированная;
– три типа потоков данных: сбор данных, рассылка данных или то и другое;
– два типа ответов: нормальный и асинхронный;
– три типа конфигураций: несбалансированная (для первичной и вторичной станций), симметричная (для пар станций первичная – вторичная) и сбалансированная (для комбинированных станций);
– два диапазона порядковых номеров: по модулю 8 и по модулю 128.
Режим нормальных ответов является рабочим режимом, в котором вторичная станция получает разрешение на передачу в тот момент, когда она принимает команду с битом запроса, равным 1. После этого вторичная станция передает серию кадров, а о завершении этого цикла передачи указывает установкой бита окончания, равного 1, в последнем кадре передаваемой последовательности.
В режиме асинхронных ответов вторичная станция сама принимает решение о передаче данных и не должна ждать для этого получения запроса передачи от первичной станции.
В HDLC обеспечиваются четыре метода восстановления потерь I-кадров. Самым основным из них является метод восстановления с помощью тайм-аута, который был рассмотрен на примере АБ-протокола. Кроме этого, в протоколе HDLC предусматривается посылка отрицательных квитанций. С этой целью вводятся две разновидности S-кадров – отказ (REJ) и селективный отказ (SREJ). При нарушении последовательности номеров принимающая станция посылает кадр REJ c номером NR ожидаемого кадра и уничтожает все поступающие I-кадры без каких-либо действий, пока не получит кадр с ожидаемым номером.
Для повышения эффективности использования канала вместо кадра REJ можно воспользоваться кадром селективного отказа SREJ, требующего повторной передачи только одного I-кадра. После передачи кадра REJ или SREJ передача другого кадра отказа запрещается до получения требуемого I-кадра.
Последний метод, который может использоваться в процедурах HDLC, для восстановления после ошибок, – это контроль с помощью бита запроса/окончания. Станция, выдавшая команду с битом запроса, равным 1, не может передать вторую команду с этим же битом, пока не получит ответную реакцию на первый бит запроса в виде ответа с битом конца передачи, равным 1. Станция может повторить передачу команды с битом запроса, равным 1, при отсутствии ответа на ранее выданный запрос только в случае окончания тайм-аута. Станция, принявшая команду с признаком запроса, должна при первой возможности выдать ответ с битом окончания, равным 1. В фазе нормального переноса данных номер NR ответа с битом окончания должен подтверждать все I-кадры, переданные до кадра с запросом или одновременно с ним. Если этого не происходит, что означает возникновение ошибки, то станция, выдавшая запрос передачи, будет передавать еще раз кадры, начиная с номера NR, указанного в ответе с признаком окончания.
Все описанные выше процедуры восстановления после ошибок можно объединять для получения устойчивого ко внешним воздействиям и эффективного протокола. Однако делать это надо с осторожностью, чтобы избежать взаимного влияния процедур друг на друга, которое в определенных случаях может вызвать неправильное функционирование протокола, включая блокировки
38. Основные этапы моделирования систем
Этап 1. Постановка задачи.
Под задачей понимается некая проблема, которую надо решить. На этапе постановки задачи необходимо:
описать задачу,
определить цели моделирования,
проанализировать объект или процесс.
Описание задачи. Задача формулируется на обычном языке, и описание должно быть понятным. Главное здесь — определить объект моделирования и понять, что должен представлять собой результат.
Цели моделирования.
Познание окружающего мира. Зачем человек создает модели? Чтобы ответить на этот вопрос, надо заглянуть в далекое прошлое. Несколько миллионов лет назад, на заре человечества, первобытные люди изучали окружающую природу, чтобы научиться противостоять природным стихиям, пользоваться природными благами, просто выживать. Накопленные знания передавались из поколения в поколение устно, позже письменно, наконец с помощью предметных моделей. Так родилась, к примеру, модель земного шара — глобус, — позволяющая получить наглядное представление о форме нашей планеты, ее вращении вокруг собственной оси и расположении материков. Такие модели позволяют понять, как устроен конкретный объект, узнать его основные свойства, установить законы его развития и взаимодействия с окружающим миром моделей.
Создание объектов с заданными свойствами (задача типа «Как сделать, чтобы...»). Накопив достаточно знаний, человек задал себе вопрос: «Нельзя ли создать объект с заданными свойствами и возможностями, чтобы противодействовать стихиям или ставить себе на службу природные явления?» Человек стал строить модели еще не существующих объектов. Так родились идеи создания ветряных мельниц, различных механизмов, даже обыкновенного зонтика. Многие из этих моделей стали в настоящее время реальностью. Это объекты, созданные руками человека.
Определение последствий воздействия на объект и принятие правильного решения (задача типа «Что будет, если...»: что будет, если увеличить плату за проезд в транспорте, или что произойдет, если закопать ядерные отходы в такой-то местности?) Например, для спасения Петербурга от постоянных наводнений, приносящих огромный ущерб, решено было возвести дамбу. При ее проектировании было построено множество моделей, в том числе и натурных, именно для того, чтобы предсказать последствия вмешательства в природу.
Эффективность управления объектом (или процессом). Поскольку критерии управления бывают весьма противоречивыми, то эффективным оно окажется только при условии, если будут «и волки сыты, и овцы целы». Например, нужно наладить питание в школьной столовой. С одной стороны, оно должно отвечать возрастным требованиям (калорийное, содержащее витамины и минеральные соли), с другой — нравиться большинству ребят и к тому же быть «по карману» родителям, а с третьей — технология приготовления должна соответствовать возможностям школьных столовых. Как совместить несовместимое? Построение модели поможет найти приемлемое решение.
Анализ объекта. На этом этапе четко выделяют моделируемый объект, его основные свойства, его элементы и связи между ними. Простой пример подчиненных связей объектов — разбор предложения. Сначала выделяются главные члены (подлежащее, сказуемое), затем второстепенные члены, относящиеся к главным, затем слова, относящиеся к второстепенным, и т. д.
Этап 2. Разработка модели.
Информационная модель. На этом этапе выясняются свойства, состояния, действия и другие характеристики элементарных объектов в любой форме: устно, в виде схем, таблиц. Формируется представление об элементарных объектах, составляющих исходный объект, т. е. информационная модель. Модели должны отражать наиболее существенные признаки, свойства, состояния и отношения объектов предметного мира. Именно они дают полную информацию об объекте.
Пример 1.3.3.
Этот пример показывает, что информации не обязательно должно быть много. Важно, чтобы она была «по существу вопроса», т. е. соответствовала цели, для которой используется.
Например, в школе учащиеся знакомятся с информационной моделью кровообращения. Предлагаемой в учебнике анатомии информации достаточно для школьника, но мало для тех, кто проводит операции на сосудах в больницах. Информационные модели играют очень важную роль в жизни человека. Знания, получаемые вами в школе, имеют вид информационной модели, цель которой — изучение предметов и явлений. Уроки истории дают возможность построить модель развития общества, а знание этой модели позволяет строить собственную жизнь, либо повторяя ошибки предков, либо учитывая их. На уроках географии вам сообщают информацию о географических объектах: горах, реках, странах и др. Это тоже информационные модели. Многое, о чем рассказывается на занятиях по географии, вы никогда не увидите в реальности. На уроках химии информация о свойствах разных веществ и законах их взаимодействия подкрепляется опытами, которые есть не что иное, как реальные модели химических процессов. Информационная модель никогда не характеризует объект полностью. Для одного и того же объекта можно построить различные информационные модели.
Пример 1.3.4.
Другой пример различных информационных моделей для одного и того же объекта.( Пример 1.3.5. )
Выбор наиболее существенной информации при создании информационной модели и сложность этой модели обусловлены целью моделирования.
Построение информационной модели является отправным пунктом этапа разработки модели. Все входные параметры объектов, выделенные при анализе, располагают в порядке убывания значимости и проводят упрощение модели в соответствии с целью моделирования.
Знаковая модель. Прежде чем приступить к процессу моделирования, человек делает предварительные наброски чертежей либо схем на бумаге, выводит расчетные формулы, т. е. составляет информационную модель в той или иной знаковой форме, которая может быть либо компьютерной, либо некомпьютерной.
Компьютерная модель
— это модель, реализованная средствами программной среды.
Существует множество программных комплексов, которые позволяют проводить исследование (моделирование) информационных моделей. Каждая программная среда имеет свой инструментарий и позволяет работать с определенными видами информационных объектов. Человек уже знает, какова будет модель, и использует компьютер для придания ей знаковой формы. Например, для построения геометрических моделей, схем используются графические среды, для словесных или табличных описаний — среда текстового редактора.
Основные функции компьютера при моделировании систем:
исполнение роли вспомогательного средства для решения задач, решаемых и обычными вычислительными средствами, алгоритмами, технологиями;
исполнение роли средства постановки и решения новых задач, не решаемых традиционными средствами, алгоритмами, технологиями;
исполнение роли средства конструирования компьютерных обучающих и моделирующих сред типа: «обучаемый — компьютер — обучающий», «обучающий — компьютер — обучаемый», «обучающий — компьютер — группа обучаемых», «группа обучаемых — компьютер — обучающий», «компьютер — обучаемый — компьютер»;
исполнение роли средства моделирования для получения новых знаний;
«обучение» новых моделей (самообучение моделей).
Этап 3. Компьютерный эксперимент.
Компьютерное моделирование — основа представления знаний в ЭВМ. Компьютерное моделирование для рождения новой информации использует любую информацию, которую можно актуализировать с помощью ЭВМ. Прогресс моделирования связан с разработкой систем компьютерного моделирования, а прогресс в информационной технологии — с актуализацией опыта моделирования на компьютере, с созданием банков моделей, методов и программных систем, позволяющих собирать новые модели из моделей банка.
Разновидность компьютерного моделирования — вычислительный эксперимент, т. е. эксперимент, осуществляемый экспериментатором над исследуемой системой или процессом с помощью орудия эксперимента — компьютера, компьютерной среды, технологии.
Вычислительный эксперимент становится новым инструментом, методом научного познания, новой технологией также из-за возрастающей необходимости перехода от исследования линейных математических моделей систем (для которых достаточно хорошо известны или разработаны методы исследования, теория) к исследованию сложных и нелинейных математических моделей систем (анализ которых гораздо сложнее). Грубо говоря, наши знания об окружающем мире линейны, а процессы в окружающем мире нелинейны.
Вычислительный эксперимент позволяет находить новые закономерности, проверять гипотезы, визуализировать ход событий и т. д.
Чтобы дать жизнь новым конструкторским разработкам, внедрить новые технические решения в производство или проверить новые идеи, нужен эксперимент. В недалеком прошлом такой эксперимент можно было провести либо в лабораторных условиях на специально создаваемых для него установках, либо на натуре, т. е. на настоящем образце изделия, подвергая его всяческим испытаниям.
С развитием вычислительной техники появился новый уникальный метод исследования — компьютерный эксперимент. Компьютерный эксперимент включает некоторую последовательность работы с моделью, совокупность целенаправленных действий пользователя над компьютерной моделью.
Этап 4. Анализ результатов моделирования.
Конечная цель моделирования — принятие решения, которое должно быть выработано на основе всестороннего анализа полученных результатов. Этот этап решающий — либо вы продолжаете исследование, либо заканчиваете. Возможно, вам известен ожидаемый результат, тогда необходимо сравнить полученный и ожидаемый результаты. В случае совпадения вы сможете принять решение.
Основой для выработки решения служат результаты тестирования и экспериментов. Если результаты не соответствуют целям поставленной задачи, значит, допущены ошибки на предыдущих этапах. Это может быть либо слишком упрощенное построение информационной модели, либо неудачный выбор метода или среды моделирования, либо нарушение технологических приемов при построении модели. Если такие ошибки выявлены, то требуется корректировка модели, т. е. возврат к одному из предыдущих этапов. Процесс повторяется до тех пор, пока результаты эксперимента не будут отвечать целяммоделирования. Главное, надо всегда помнить: выявленная ошибка — тоже результат. Как говорит народная мудрость, на ошибках учатся.
39. Реляционная алгебра и язык манипулирования данными sql
Реляционная база данных — это связанная информация, представленная в виде двумерных таблиц.
Для обеспечения максимальной гибкости при работе с данными строки таблицы, по определению, никак не упорядочены.
SQL — это язык, ориентированный специально на реляционные базы данных. Он позволяет исключить большую работу, выполняемую при использовании языка программирования общего назначения. Для создания реляционной базы данных, например на языке С, пришлось бы начать с определения объекта, называемого таблицей, который может иметь произвольное число строк, а затем создавать процедуры для ввода значений в таблицу и для поиска в ней данных.
SQL освобождает от подобной работы. Команды SQL могут выполняться над целой группой таблиц, как над единственным объектом, а также могут оперировать любым количеством информации, которая извлекается или выводится из них как из единого целого.
SQL символизирует структурированный язык запросов (Structured Query Language). Запросы являются наиболее часто используемым аспектом SQL. Есть категория пользователей SQL, которые используют язык только для формулировки запросов.
Что такое запрос? Это команда, которая формулируется для СУБД и требует предоставить определенную указанную информацию. Эта информация обычно выводится непосредственно на экран дисплея компьютера или используемый терминал, хотя в ряде случаев ее можно направить на принтер, сохранить в файле или использовать в качестве исходных данных для другой команды или процесса.
Язык SQL
Как и большинство современных реляционных языков, SQL основан на исчислении кортежей. В результате, каждый запрос, сформулированный с помощью исчисления кортежей (или иначе говоря, реляционной алгебры), может быть также сформулирован с помощью SQL. Однако, он имеет способности, лежащие за пределами реляционной алгебры или исчисления. Вот список некоторых дополнительных свойств, предоставленных SQL, которые не являются частью реляционной алгебры или исчисления:
Команды вставки, удаления или изменения данных.
Арифметические возможности: в SQL возможно вызвать арифметические операции, так же как и сравнения, например A < B + 3. Заметим, что + или других арифметических операторов нет ни в реляционной алгебре ни в реляционном исчислении.
Команды присвоения и печати: возможно напечатать отношение, созданное запросом и присвоить вычисленному отношению имя отношения.
Итоговые функции: такие операции как average, sum, max, и т.д. могут применяться к столбцам отношения для получения единичной величины.
Выборка
Наиболее часто используемая команда SQL - это оператор SELECT, используемый для получения данных. Синтаксис:
SELECT [ALL|DISTINCT]
{ * | expr_1 [AS c_alias_1] [, ...
[, expr_k [AS c_alias_k]]]}
FROM table_name_1 [t_alias_1]
[, ... [, table_name_n [t_alias_n]]]
[WHERE condition]
[GROUP BY name_of_attr_i
[,... [, name_of_attr_j]] [HAVING condition]]
[{UNION [ALL] | INTERSECT | EXCEPT} SELECT ...]
[ORDER BY name_of_attr_i [ASC|DESC]
[, ... [, name_of_attr_j [ASC|DESC]]]];
Итоговые операторы
SQL снабжён итоговыми операторами (например AVG, COUNT, SUM, MIN, MAX), которые принимают название атрибута в качестве аргумента. Значение итогового оператора высчитывается из всех значений заданного атрибута(столбца) всей таблицы. Если в запросе указана группа, то вычисления выполняются только над значениями группы (смотри следующий раздел).
Итоги по группам
SQL позволяет разбить кортежи таблицы на группы. После этого итоговые операторы, описанные выше, могут применяться к группам (т.е. значение итогового оператора вычисляется не из всех значений указанного столбца, а над всеми значениями группы. Таким образом, итоговый оператор вычисляет индивидуально для каждой группы.)
Разбиение кортежей на группы выполняется с помощью ключевых слов GROUP BY и следующим за ними списком атрибутов, которые определяют группы. Если мы имеем GROUP BY A1, ⃛, Ak мы разделяем отношение на группы так, что два кортежа будут в одной группе, если у них соответствуют все атрибуты A1, ⃛, Ak.
Заметим, что для получения результата запроса, использующего GROUP BY и итоговых операторов, атрибуты сгруппированных значений должны также быть в списке объектов. Все остальные атрибуты, которых нет в выражении GROUP BY, могут быть выбраны при использовании итоговых функций. С другой стороны ты можешь не использовать итоговые функции на атрибутах, имеющихся в выражении GROUP BY.
Having
Оператор HAVING выполняет ту же работу что и оператор WHERE, но принимает к рассмотрению только те группы, которые удовлетворяют определению оператора HAVING. Выражения в операторе HAVING должны вызывать итоговые функции. Каждое выражение, использующее только простые атрибуты, принадлежат оператору WHERE. С другой стороны каждое выражение вызывающее итоговую функцию должно помещаться в оператор HAVING.
Подзапросы
В операторах WHERE и HAVING используются подзапросы (вложенные выборки), которые разрешены в любом месте, где ожидается значение. В этом случае значение должно быть получено предварительно подсчитав подзапрос. Использование подзапросов увеличивает выражающую мощность SQL.
Объединение, пересечение, исключение
Эти операции вычисляют объединение, пересечение и теоретико-множественное вычитание кортежей из двух подзапросов.
Определение данных
Существует набор команд, использующихся для определения данных, включенных в язык SQL.
Создание таблицы
Самая основная команда определения данных - это та, которая создаёт новое отношение (новую таблицу). Синтаксис команды CREATE TABLE:
CREATE TABLE table_name
(name_of_attr_1 type_of_attr_1
[, name_of_attr_2 type_of_attr_2
[, ...]]);
Типы данных SQL
Вот список некоторых типов данных, которые поддерживает SQL:
INTEGER: знаковое полнословное двоичное целое (31 бит для представления данных).
SMALLINT: знаковое полсловное двоичное целое (15 бит для представления данных).
DECIMAL (p[,q]): знаковое упакованное десятичное число с p знаками представления данных, с возможным q знаками справа от десятичной точки. (15 ≥ p ≥ qq ≥ 0). Если q опущено, то предполагается что оно равно 0.
FLOAT: знаковое двусловное число с плавающей точкой.
CHAR(n): символьная строка с постоянной длиной n.
VARCHAR(n): символьная строка с изменяемой длиной, максимальная длина n.
Создание индекса
Индексы используются для ускорения доступа к отношению. Если отношение R проиндексировано по атрибуту A, то мы можем получить все кортежи t имеющие t(A) = a за время приблизительно пропорциональное числу таких кортежей t, в отличие от времени, пропорциональному размеру R.
Для создания индекса в SQL используется команда CREATE INDEX. Синтаксис:
CREATE INDEX index_name
ON table_name ( name_of_attribute );
Создание представлений
Представление можно рассматривать как виртуальную таблицу, т.е. таблицу, которая в базе данных не существует физически, но для пользователя она как-бы там есть. По сравнению, если мы говорим о базовой таблице, то мы имеем в виду таблицу, физически хранящую каждую строку где-то на физическом носителе.
Представления не имеют своих собственных, физически самостоятельных, различимых хранящихся данных. Вместо этого, система хранит определение представления (т.е. правила о доступе к физически хранящимся базовым таблицам в порядке претворения их в представление) где-то в системных каталогах . Для определения представлений в SQL используется команда CREATE VIEW. Синтаксис:
CREATE VIEW view_name
AS select_stmt
где select_stmt, допустимое выражение выборки, как определено в Выборка. Заметим, что select_stmt не выполняется при создании представления. Оно только сохраняется в системных каталогах и выполняется всякий раз когда делается запрос представления.
Drop Table, Drop Index, Drop View
Для уничтожения таблицы (включая все кортежи, хранящиеся в этой таблице) используется команда DROP TABLE:
DROP TABLE table_name;
Для уничтожения таблицы SUPPLIER используется следующее выражение:
DROP TABLE SUPPLIER;
Команда DROP INDEX используется для уничтожения индекса:
DROP INDEX index_name;
Наконец, для уничтожения заданного представления используется команда DROP VIEW:
DROP VIEW view_name;
Манипулирование данными
Insert Into
После создания таблицы её можно заполнять кортежами с помощью команды INSERT INTO. Синтаксис:
INSERT INTO table_name (name_of_attr_1
[, name_of_attr_2 [,...]])
VALUES (val_attr_1
[, val_attr_2 [, ...]]);
Обновление
Для изменения одного или более значений атрибутов кортежей в отношении используется команда UPDATE. Синтаксис:
UPDATE table_name
SET name_of_attr_1 = value_1
[, ... [, name_of_attr_k = value_k]]
WHERE condition;
Удаление
Для удаления кортежа из отдельной таблицы используется команда DELETE FROM. Синтаксис:
DELETE FROM table_name
WHERE condition;
Системные каталоги
В каждой системе базы данных SQL определены системные каталоги, которые используются для хранения записей о таблицах, представлениях, индексах и т.д. К системным каталогам также можно строить запросы, как если бы они были нормальными отношениями. Например, один каталог используется для определения представлений. В этом каталоге хранятся запросы об определении представлений. Всякий раз когда делается запрос к представлению, система сначала берёт запрос определения представления из этого каталога и материализует представление перед тем, как обработать запрос пользователя (подробное описание смотри в SIM98). Более полную информацию о системных каталогах смотри у Дейта.
Встраивание SQL
В этом разделе мы опишем в общих чертах как SQL может быть встроен в конечный язык (например в C). Есть две главных причины, по которым мы хотим пользоваться SQL из конечного языка:
Существуют запросы, которые нельзя сформулировать на чистом SQL(т.е. рекурсивные запросы). Чтобы выполнить такие запросы, нам необходим конечный язык, обладающий большей мощностью выразительности, чем SQL.
Просто нам необходим доступ к базе данных из другого приложения, которое написано на конечном языке (например, система бронирования билетов с графическим интерфейсом пользователя написана на C и информация об оставшихся билетах хранится в базе данных, которую можно получить с помощью встроенного SQL).
Программа, использующая встроенный SQL в конечном языке, состоит из выражений конечного языка и выражений встроенного SQL (ESQL). Каждое выражение ESQL начинается с ключевых слов EXEC SQL. Выражения ESQL преобразуются в выражения на конечном языке с помощью прекомпилятора (который обычно вставляет вызовы библиотечных процедур, которые выполняют различные команды SQL)
41. ER- модель. Понятие атрибутов и сущностей предметной области
Сущность служит для представления набора реальных или абстрактных предметов (людей, мест, событий и т.п.), которые обладают общими атрибутами или характеристиками. Сущность - “логический” объект, который в физической среде СУБД представлен таблицей. сущность в ERwin обычно описывает три части информации: атрибуты, являющиеся первичными ключами, неключевые атрибуты и тип сущности.
Case-метод Баркера
Цель моделирования данных состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных.
Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных.
Нотация ERD была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера. Метод Баркера будет излагаться на примере моделирования деятельности компании по торговле автомобилями. Ниже приведены выдержки из интервью, проведенного с персоналом компании.
Главный менеджер: одна из основных обязанностей - содержание автомобильного имущества. Он должен знать, сколько заплачено за машины и каковы накладные расходы. Обладая этой информацией, он может установить нижнюю цену, за которую мог бы продать данный экземпляр. Кроме того, он несет ответственность за продавцов и ему нужно знать, кто что продает и сколько машин продал каждый из них.
Продавец: ему нужно знать, какую цену запрашивать и какова нижняя цена, за которую можно совершить сделку. Кроме того, ему нужна основная информация о машинах: год выпуска, марка, модель и т.п.
Администратор: его задача сводится к составлению контрактов, для чего нужна информация о покупателе, автомашине и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи.
Первый шаг моделирования - извлечение информации из интервью и выделение сущностей.
С ущность
(Entity) - реальный либо воображаемый
объект, имеющий существенное значение
для рассматриваемой предметной области,
информация о котором подлежит хранению
(рисунок 3.18).
ущность
(Entity) - реальный либо воображаемый
объект, имеющий существенное значение
для рассматриваемой предметной области,
информация о котором подлежит хранению
(рисунок 3.18).
Рис. 3.18. Графическое изображение сущности
Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами:
каждая сущность должна иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация. Одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами;
сущность обладает одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности;
каждая сущность может обладать любым количеством связей с другими сущностями модели.
О бращаясь
к приведенным выше выдержкам из интервью,
видно, что сущности, которые могут быть
идентифицированы с главным менеджером
- это автомашины и продавцы. Продавцу
важны автомашины и связанные с их
продажей данные. Для администратора
важны покупатели, автомашины, продавцы
и контракты. Исходя из этого, выделяются
4 сущности (автомашина, продавец,
покупатель, контракт), которые изображаются
на диаграмме следующим образом (рисунок
3.19).
бращаясь
к приведенным выше выдержкам из интервью,
видно, что сущности, которые могут быть
идентифицированы с главным менеджером
- это автомашины и продавцы. Продавцу
важны автомашины и связанные с их
продажей данные. Для администратора
важны покупатели, автомашины, продавцы
и контракты. Исходя из этого, выделяются
4 сущности (автомашина, продавец,
покупатель, контракт), которые изображаются
на диаграмме следующим образом (рисунок
3.19).
Рис. 3.19.
Следующим шагом моделирования является идентификация связей.
Связь (Relationship) - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя.
Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка.
Например, связь продавца с контрактом может быть выражена следующим образом:
продавец может получить вознаграждение за 1 или более контрактов;
контракт должен быть инициирован ровно одним продавцом.
Степень связи и обязательность графически изображаются следующим образом (рисунок 3.20).
Рис. 3.20.
Т
 аким
образом, 2 предложения, описывающие
связь продавца с контрактом, графически
будут выражены следующим образом
(рисунок 3.21).
аким
образом, 2 предложения, описывающие
связь продавца с контрактом, графически
будут выражены следующим образом
(рисунок 3.21).
Рис. 3.21.
Описав также связи остальных сущностей, получим следующую схему (рисунок 3.22).

Рис. 3.22.
Последним шагом моделирования является идентификация атрибутов.
Атрибут - любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута.
Атрибут может быть либо обязательным, либо необязательным (рисунок 3.23). Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа).
У никальный
идентификатор - это атрибут или
совокупность атрибутов и/или связей,
предназначенная для уникальной
идентификации каждого экземпляра
данного типа сущности. В случае полной
идентификации каждый экземпляр данного
типа сущности полностью идентифицируется
своими собственными ключевыми атрибутами,
в противном случае в его идентификации
участвуют также атрибуты другой
сущности-родителя (рисунок 3.24).
никальный
идентификатор - это атрибут или
совокупность атрибутов и/или связей,
предназначенная для уникальной
идентификации каждого экземпляра
данного типа сущности. В случае полной
идентификации каждый экземпляр данного
типа сущности полностью идентифицируется
своими собственными ключевыми атрибутами,
в противном случае в его идентификации
участвуют также атрибуты другой
сущности-родителя (рисунок 3.24).
Рис. 3.23.
Р ис.
3.24.
ис.
3.24.
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком "#".
Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности - это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные - как альтернативные ключи.
С учетом имеющейся информации дополним построенную ранее диаграмму (рисунок 3.25).
Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных.
Подтипы и супертипы: одна сущность является обобщающим понятием для группы подобных сущностей (рисунок 3.26).
Взаимно исключающие связи: каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей (рисунок 3.27).
Р
 ис.
3.25
ис.
3.25
Р ис.
3.26. Подтипы и супертипы
ис.
3.26. Подтипы и супертипы


Рис. 3.27. Взаимно исключающие связи
Рекурсивная связь: сущность может быть связана сама с собой (рисунок 3.28).
Неперемещаемые (non-transferrable) связи: экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 3.29).
Рис. 3.28. Рекурсивная связь Рис. 3.29. Неперемещаемая связь
42. Методы доступа в сетях. Множественный доступ с контролем несущей и обнаружением конфликтов
В сетях Ethernet используется метод доступа к среде передачи данных, называемый методом коллективного доступа с опознаванием несущей и обнаружением коллизий (carrier-sense-multiply-access with collision detection, CSMA/CD). Передача ведется попеременно в обоих направлениях, т. е. мы имеем дело с полудуплексным режимом работы. Чтобы получить возможность передачи данных, станция должна убедиться, что разделяемая среда свободна. Признак незанятости среды – отсутствие на ней несущей частоты. Если две или более станции одновременно начинают передачу, решив, сто среда свободна, возникает коллизия.
Этот метод применяется исключительно в сетях с логической общей шиной (к которым относятся и радиосети, породившие этот метод). Все компьютеры такой сети имеют непосредственный доступ к общей шине, поэтому она может быть использована для передачи данных между любыми двумя узлами сети. Одновременно все компьютеры сети имеют возможность немедленно (с учетом задержки распространения сигнала по физической среде) получить данные, которые любой из компьютеров начал передавать на общую шину. Простота схемы подключения - это один из факторов, определивших успех стандарта Ethernet. Говорят, что кабель, к которому подключены все станции, работает в режиме коллективного доступа (Multiply Access, MA).
Множественный доступ с контролем несущей и обнаружением коллизий
При множественном доступе с контролем несущей и обнаружением коллизий (сокращенно CSMA/CD) все компьютеры в сети - и клиенты, и серверы © «прослушивают» кабель,стремясь обнаружить передаваемые данные (т.е. трафик).
Компьютер «понимает», что кабель свободен (т.е. трафик отсутствует).
Компьютер может начать передачу данных.
Пока кабель не освободится (в течение передачи данных), ни один из сетевых компьютеров не может вести передачу.
В случае коллизии компьютеры приостанавливают передачу на случайный интервал времени, а затем вновь стараются отправить пакеты.
В то же время способность обнаружить коллизии - причина, которая ограничивает область действия метода. Из-за ослабления сигнала при расстояниях свыше 2500 м (1,5 мили) механизм обнаружения коллизий не эффективен. Если расстояние до передающего компьютера превышает это ограничение, некоторые компьютеры могут не «услышать»©его и начнут передачу данных, что приведет к коллизии и разрушению пакетов данных.
CSMA/CD известен как состязательный метод, поскольку сетевые компьютеры конкурируют между собой за право передавать данные. Он кажется достаточно громоздким, но современные реализации CSMA/CD настолько быстры, что пользователи даже не задумываются над тем, что применяют состязательный метод доступа.
Чем больше компьютеров в сети, тем интенсивнее сетевой трафик. При интенсивном трафике число коллизий возрастает, а это приводит к замедлению сети (уменьшению ее пропускной способности). Поэтому в некоторых ситуациях метод CSMA/CD может оказаться недостаточно быстрым. После каждой коллизии обоим компьютерам приходится возобновлять передачу, Если сеть очень загружена, повторные попытки опять могут привести к коллизиям, но уже с другими компьютерами. Теперь уже четыре компьютера (два от первой неудачной попытки и два от второй неудачной попытки первых) будут возобновлять передачу. Результат может оказаться тем же, что и в предыдущем случае, только пострадавших компьютеров станет еще больше. Такое лавинообразное нарастание вторных передач может парализовать работу всей сети.
Вероятность возникновения подобной ситуации зависит от числа пользователе пытающихся получить доступ к сети, и приложений, с которыми они работают.
Сеть с методом доступа CSMA/CD, обслуживающая многих пользователей, которые работают с несколькими системами управления базами данных (критическое числоло пользователей зависит от аппаратных компонентов, кабельной системы и сетев программного обеспечения), может практически остановиться из-за чрезмерного сетвого трафика.
Множественный доступ с контролем несущей и предотвращением коллизий
Множественный доступ с контролем несущей и предотвращением коллизий (сок щенно CSMA/CA) основан на том, что каждый компьютер перед передачей данных в сеть сигнализирует о своем намерении, поэтому остальные компьютеры узнают о готовящейся передаче и могут избежать коллизий. Однако широковещательное оповещение увеличивает общий трафик сети уменьшает ее пропускную способность. Поэтому CSMA/CA работает медленнее, чем CSMA/CD.
44. Целостность и непротиворечивость данных в базе данных
Понятия целостности, полноты и непротиворечивости могут толковаться по разному применительно к разным объектам, поскольку они существенно зависят от природы объекта .
Для реляционных баз данных критерии целостности, полноты и непротиворечивости традиционны . Непротиворечивость означает, что одинаковые атрибуты одних и тех же объектов совпадают. Следовательно, например, дублирование данных в базе повышает риск противоречивости.
Полнота базы данных предполагает , что все запросы пользователя в рамках задачи должны быть удовлетворены. Понятно, что такое определение непригодно для объективного анализа системы и нуждается в уточнении. Множество выходных данных формально описано на языке предикатов.
Целостность базы данных предполагает согласованное представление информации для связанных объектов. Все связи в базе данных должны быть явно описаны в спецификациях системы. Для определения условий целостности данных в базе данных проекта могут быть использованы установленные между таблицами отношения.
Проверка целостности данных может осуществляться как программными средствами, так и средствами базы данных. Для того, чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints).
Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, например, целостность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Ограничения целостности реализуются с помощью специальных средств, таких как привила (rules), триггеры (triggers) и домены (domains).
45. Роль структуры управления в информационных системах. Характеристика уровней управления и их влияние на функции информационных систем.
Для любой организации создание и использование информационной системы (ИС) нацелено на решение задач:
- соответствие целям, стоящим перед организацией (фирма - эффективный бизнес, гос. предприятие – решение социальных и экономических задач);
- производство достоверной, надежной, своевременной и систематизированной информации;
- ИС должна контролироваться персоналом, быть понятной, использоваться в соответствии с основными социальными и этическими принципами.
Для создания ИС необходимо обследовать структуру, функции и политику организации, цели управления и принимаемых решений, возможности компьютерных технологий. Поскольку ИС – часть организации, обязательно должны учитываться её ключевые элементы: структура и органы управления, стандартные процедуры, персонал, субкультура.
Уровни управления определяются сложностью решаемых задач (чем сложнее задача, тем более высокий уровень управления требуется). Традиционно имеется три уровня структуры управления: 1)операционный (оперативный) – нижний уровень в пирамиде управления, 2)функциональный (тактический) - средний и 3)стратегический - верхний.
Роль уровней структуры управления в ИС следующая: 1)Первый (нижний) уровень: решение многократно повторяющихся задач и операций, быстрое реагирование на входную информацию. Велик объем выполняемых операций, они носят рутинный характер. Динамика принимаемых решений велика (т.к. время от момента поступления информации, на основе которой принимается решение, до принятия решения, его реализации и получения результатов решения мало – минуты, часы, день). Много решается задач учетного типа. Пример: учет количества произведенной, проданной продукции, сырья, материалов; бухгалтерский учет.
2)Функциональный (тактический) уровень – решение задач, требующих предварительного анализа информации. Возрастает сложность, ответственность, уменьшается динамика принимаемых решений (т.к. тратится определенное время на анализ, сбор недостающих сведений, осмысление. От момента принятия решений до их реализации тратятся недели, месяцы). Пример: разработка плана выпуска продукции на основе: спроса, ценах конкурентов, прогнозов информационно-аналитических служб и пр.
3)Стратегический – выработка управленческих задач, направленных на долгосрочные стратегические цели организации. Результаты решений проявляются спустя длительное время. Долгосрочное (стратегическое) планирование. Динамика принимаемых решений мала, время до получения результатов решений – кварталы, годы.
Таким образом, функции информационных систем напрямую зависят от структуры организации, функций её подразделений и уровней.
46. Классификация информационных систем по функциональному признаку назначения подсистем и уровням управления
Функциональный признак определяет назначение подсистемы, а также её основные цели, задачи и функции. Структура информационной системы может быть представлена как совокупность её функциональных подсистем, а функциональный признак может быть использован при классификации информационных систем.
В хозяйственной практике производственных и коммерческих объектов типовыми видами деятельности, которые определяют функциональный признак классификации информационных систем, являются: производственная, маркетинговая, финансовая, кадровая.
Производственная деятельность связана с непосредственным выпуском продукции и направлена на создание и внедрение в производство научно-технических новшеств.
Маркетинговая деятельность включает в себя:
анализ рынка производителей и потребителей выпускаемой продукции, анализ продаж;
организацию рекламной кампании по продвижению продукции;
рациональную организацию материально-технического снабжения.
Финансовая деятельность связана с организацией контроля и анализа финансовых ресурсов фирмы на основе бухгалтерской, статистической, оперативной информации.
Кадровая деятельность направлена на подбор и расстановку необходимых фирме специалистов, а также ведение служебной документации по различным аспектам.
Указанные направления деятельности определили типовой набор информационных систем:
производственные системы;
системы маркетинга;
финансовые и учётные системы;
системы кадров (человеческих ресурсов);
прочие типы, выполняющие вспомогательные функции в зависимости от специфики деятельности фирмы.
В крупных фирмах основная информационная система функционального назначения может состоять из нескольких подсистем для выполнения подфункций. Например, производственная информационная система имеет следующие подсистемы: управления запасами, управления производственным процессом, компьютерного инжиниринга и т.д.
Типы информационных систем
Тип информационной системы зависит от того, чьи интересы она обслуживает и на каком уровне управления.
На рис.9.2 показан один из возможных вариантов классификации информационных систем по функциональному признаку с учётом уровней управления и уровней квалификации персонала.
Из рис.9.2 видно, что чем выше по значимости уровень управления, тем меньше объём работ, выполняемых специалистом и менеджером с помощью информационной системы.
Рис. 9.2. Типы информационных систем в зависимости от функционального признака с учётом уровней управления и квалификации персонала
Однако при этом возрастают сложность и интеллектуальные возможности информационной системы и её роль в принятии менеджером решений. Любой уровень управления нуждается в информации из всех функциональных систем, но в разных объёмах и с разной степенью обобщения.
Основание пирамиды составляют информационные системы, с помощью которых сотрудники - исполнители занимаются операционной обработкой данных, а менеджеры низшего звена – оперативным управлением.
Наверху пирамиды на уровне стратегического управления информационные системы изменяют свою роль и становятся стратегическими, поддерживающими деятельность менеджеров высшего звена по принятию решений в условиях плохой структурированности поставленных задач.
Информационная система оперативного (операционного) уровня
Информационная система оперативного уровня поддерживает специалистов - исполнителей, обрабатывая данные о сделках и событиях (счета, накладные, зарплата, кредиты, поток сырья и материалов). Назначение ИС на этом уровне – отвечать на запросы о текущем состоянии и отслеживать поток сделок в фирме, что соответствует оперативному управлению. Чтобы с этим справляться, информационная система должна быть легкодоступной, непрерывно действующей и предоставлять точную информацию.
Задачи, цели и источники информации на операционном уровне заранее определены и в высокой степени структурированы. Решение запрограммировано в соответствии с заданным алгоритмом.
Информационная система оперативного уровня является связующим звеном между фирмой и внешней средой. Если система работает плохо, то организация либо не получает информации извне, либо не выдаёт информацию. Кроме того, система – это основной поставщик информации для остальных типов информационных систем в организации, так как содержит и оперативную, и архивную информацию.
Отключение этой ИС привело бы к необратимым негативным последствиям.
Информационные системы специалистов
Информационные системы этого уровня помогают специалистам, работающим с данными, повышают продуктивность и производительность работы инженеров и проектировщиков. Задача подобных информационных систем – интеграция новых сведений в организацию и помощь в обработке бумажных документов.
По мере того как индустриальное общество трансформируется в информационное, производительность экономики всё больше будет зависеть от уровня развития этих систем. Такие системы, особенно в виде рабочих станций и офисных систем, наиболее быстро развиваются сегодня в бизнесе.
В этом классе информационных систем можно выделить две группы:
информационные системы офисной автоматизации;
информационные системы обработки знаний.
Информационные системы офисной автоматизации вследствие своей простоты и многопрофильности активно используются работниками любого организационного уровня. Наиболее часто их применяют работники средней квалификации: бухгалтеры, секретари, клерки. Основная цель – обработка данных, повышение эффективности их работы и упрощение канцелярского труда.
ИС офисной автоматизации связывают воедино работников информационной сферы в разных регионах и помогают поддерживать связь с покупателями, заказчиками и другими организациями. Их деятельность в основном охватывает управление документацией, коммуникации, составление расписаний и т.д. Эти системы выполняют следующие функции:
обработка текстов на компьютерах с помощью различных текстовых процессоров;
производство высококачественной печатной продукции;
архивация документов;
электронные календари и записные книжки для ведения деловой информации;
электронная и аудиопочта;
видео- и телеконференции.
Информационные системы обработки знаний, в том числе и экспертные системы, вбирают в себя знания, необходимые инженерам, юристам, учёным при разработке или создании нового продукта. Их работа заключается в создании новой информации и нового знания. Так, например, существующие специализированные рабочие станции по инженерному и научному проектированию позволяют обеспечить высокий уровень технических разработок.
Информационные системы для менеджеров среднего звена
Информационные системы уровня менеджмента используются работниками среднего управленческого звена для мониторинга (постоянного слежения), контроля, принятия решений и администрирования. Основные функции этих информационных систем:
сравнение текущих показателей с прошлыми;
составление периодических отчётов за определённое время, а не выдача отчётов по текущим событиям, как на оперативном уровне;
обеспечение доступа к архивной информации и т.д.
Некоторые ИС обеспечивают принятие нетривиальных решений. В случае, когда требования к информационному обеспечению определены не строго, они способны отвечать на вопрос: "что будет, если ...?".
На этом уровне можно выделить два типа информационных систем: управленческие (для менеджмента) и системы поддержки принятия решений.
Управленческие ИС имеют крайне небольшие аналитические возможности. Они обслуживают управленцев, которые нуждаются в ежедневной, еженедельной информации о состоянии дел. Основное их назначение состоит в отслеживании ежедневных операций в фирме и периодическом формировании строго структурированных сводных типовых отчётов. Информация поступает из информационной системы операционного уровня.
Характеристики управленческих информационных систем:
используются для поддержки принятия решений структурированных и частично структурированных задач на уровне контроля за операциями;
ориентированы на контроль, отчётность и принятие решений по оперативной обстановке;
опираются на существующие данные и их потоки внутри организации;
имеют малые аналитические возможности и негибкую структуру.
Системы поддержки принятия решений обслуживают частично структурированные задачи, результаты которых трудно спрогнозировать заранее. Они имеют более мощный аналитический аппарат с несколькими моделями. Информацию получают из управленческих и операционных информационных систем. Используют эти системы все, кому необходимо принимать решение: менеджеры, специалисты, аналитики и пр. Например, их рекомендации могут пригодиться при принятии решения покупать или взять оборудование в аренду и пр.
Характеристики систем поддержки принятия решений:
обеспечивают решение проблем, развитие которых трудно прогнозировать;
оснащены сложными инструментальными средствами моделирования и анализа;
позволяют легко менять постановки решаемых задач и входные данные;
отличаются гибкостью и легко адаптируются к изменению условий по несколько раз в день;
имеют технологию, максимально ориентированную на пользователя.
Стратегические информационные системы
Развитие и успех любой организации (фирмы) во многом определяются принятой в ней стратегией. Под стратегией понимается набор методов и средств решения перспективных долгосрочных задач.
В этом контексте можно воспринимать и понятия "стратегический метод", "стратегическое средство", "стратегическая система" и т.п. В настоящее время в связи с переходом к рыночным отношениям вопросу стратегии развития и поведения фирмы стали уделять большое внимание, что способствовало коренному изменению во взглядах на информационные системы. Они стали расцениваться как стратегически важные системы, которые влияют на изменение выбора целей фирмы, её задач, методов, продуктов, услуг, позволяя опередить конкурентов, а также наладить более тесное взаимодействие с потребителями и поставщиками. Появился новый тип информационных систем – стратегический.
Стратегическая информационная система – компьютерная информационная система, обеспечивающая поддержку принятия решений по реализации стратегических перспективных целей развития организации.
Известны ситуации, когда новое качество информационных систем заставляло изменять не только структуру, но и профиль фирм, содействуя их процветанию. Однако при этом возможно возникновение нежелательной психологической обстановки, связанное с автоматизацией некоторых функций и видов работ, так как это может поставить некоторую часть сотрудников и рабочих под угрозу сокращения.
Рассмотрим качество информационной системы как стратегического средства деятельности любой организации на примере фирмы, выпускающей продукцию, аналогичную уже имеющейся на потребительском рынке. В этих условиях необходимо выдержать конкуренцию с другими фирмами. Что может принести использование информационной системы в этой ситуации?
Чтобы ответить на этот вопрос, нужно понять взаимосвязь фирмы с её внешним окружением. На рис.9.3 показано воздействие на фирму внешних факторов:

Рис. 9.3. Внешние факторы, воздействующие на деятельность фирмы
конкурентов, проводящих на рынке свою политику;
покупателей, обладающих разными возможностями по приобретению товаров и услуг;
поставщиков, которые проводят свою ценовую политику.
Фирма может обеспечить себе конкурентное преимущество, если будет учитывать эти факторы и придерживаться следующих стратегий:
создание новых товаров и услуг, которые выгодно отличаются от аналогичных;
отыскание рынков, где товары и услуги фирмы обладают рядом отличительных признаков по сравнению с уже имеющимися там аналогами;
создание таких связей, которые закрепляют покупателей и поставщиков за данной фирмой и делают невыгодным обращение к другой;
снижение стоимости продукции без ущерба качества.
Информационные системы стратегического уровня помогают высшему звену управленцев решать неструктурированные задачи, подобные описанным выше, осуществлять долгосрочное планирование. Основная задача – сравнение происходящих во внешнем окружении изменений с существующим потенциалом фирмы. Они призваны создать общую среду компьютерной и телекоммуникационной поддержки решений в неожиданно возникающих ситуациях. Используя самые совершенные программы, эти системы способны в любой момент предоставить информацию из многих источников. Для некоторых стратегических систем характерны ограниченные аналитические возможности.
На данном организационном уровне ИС играют вспомогательную роль и используются как средство оперативного предоставления менеджеру необходимой информации для принятия решений.
В настоящее время еще не выработана общая концепция построения стратегических информационных систем вследствие многоплановости их использования не только по целям, но и по функциям. Существуют две точки зрения: одна базируется на мнении, что сначала необходимо сформулировать свои цели и стратегии их достижения, а только затем приспосабливать информационную систему к имеющейся стратегии; вторая – на том, что организация использует стратегическую ИС при формулировании целей и стратегическом планировании. По-видимому, рациональным подходом к разработке стратегических информационных систем будет методология синтеза этих двух точек зрения.
Информационные системы в фирме
Любой фирме желательно иметь несколько локальных ИС разного назначения, которые взаимодействуют между собой и поддерживают управленческие решения на всех уровнях. На рис.9.4 показан один из таких вариантов.

Рис. 9.4. Примеры информационных систем, поддерживающих деятельность фирмы
Между локальными ИС организуются связи различного характера и назначения. Одни локальные ИС могут быть связаны с большим количеством работающих в фирме систем и иметь выход во внешнюю среду, другие связаны только с одной или несколькими родственными. Современный подход к организации связи основан на применении локальных внутрифирменных компьютерных сетей с выходом на аналогичную ИС другой фирмы или подразделение корпорации. При этом пользуются ресурсами региональных и глобальных сетей.
На основе интеграции ИС разного назначения с помощью компьютерных сетей в фирме создаются корпоративные ИС. Подобные ИС предоставляют пользователю возможность работать как с общефирменной базой данных, так и с локальными базами данных.
Рассмотрим роль корпоративной ИС в фирме относительно формирования стоимости выпускаемой продукции.
Информационные системы в фирме, поддерживая все стадии выпуска продукции, могут предоставлять информацию разной степени подробности для анализа, в результате которого выявляются этапы, где происходит сверхнормативное увеличение стоимости продукции. В этом случае может быть выбрана стратегия по уменьшению стоимости продукции. Результаты принимаемых мер, в свою очередь, отразятся в информационной системе. Снова можно будет использовать полученную информацию для анализа. И так до тех пор, пока не будет достигнута поставленная цель.
Информационная система может иметь наибольший эффект, если фирму рассматривать как цепь действий, в результате которых происходит постепенное формирование стоимости производимых продуктов или услуг. Тогда с помощью информационных систем различного функционального назначения, включенных в эту цепь, можно оказывать влияние на стратегию принятия управленческих решений, направленных на увеличение доходов фирмы.
47. Методология использования информационных технологий. Характеристика централизованной и децентрализованной обработки информации. Выбор вариантов внедрения информационных технологий на предприятии, проблемы ориентации на существующую или будущую структуру фирмы
Методология использования информационной технологии
Централизованная обработка информации на ЭВМ вычислительных центров была первой исторически сложившейся технологией. Создавались крупные вычислительные центры (ВЦ) коллективного пользования, оснащенные большими ЭВМ ( в нашей стране - ЭВМ ЕС). Применение таких ЭВМ позволяло обрабатывать большие массивы входной информации и получать на этой основе различные виды информационной продукции, которая затем передавалась пользователям. Такой технологический процесс был обусловлен недостаточным оснащением вычислительной техникой предприятий и организаций в 60-70-е гг.
Достоинства методологии централизованной технологии:
возможность обращения пользователя к большим массивам информации в виде баз данных и к информационной продукции широкой номенклатуры;
сравнительная легкость внедрения методологических решений по развитию и совершенствованию информационной технологии благодаря централизованному их принятию.
Недостатки такой методологии очевидны:
ограниченная ответственность низшего персонала, который не способствует оперативному получению информации пользователем, тем самым препятствуя правильности выработки управленческих решений;
ограничение возможностей пользователя в процессе получения и использования информации.
Децентрализованная обработка информации связана с появлением в 80-х гг. персональных компьютеров и развитием средств телекоммуникаций. Она весьма существенно потеснила предыдущую технологию, поскольку дает пользователю широкие возможности в работе с информацией и не ограничивает его инициатив.
Достоинствами такой методологии являются:
гибкость структуры, обеспечивающая простор инициативам пользователя:
усиление ответственности низшего звена сотрудников;
уменьшение потребности в пользовании центральным компьютером и соответственно контроле со стороны вычислительного центра;
более полная реализация творческого потенциала пользователя благодаря использованию средств компьютерной связи.
Однако эта методология имеет свои недостатки:
сложность стандартизации из-за большого числа уникальных разработок;
психологическое неприятия пользователями рекомендуемых вычислительным центром стандартов и готовых программных продуктов;
неравномерность развития уровня информационных технологии на локальных местах, что в первую очередь определяется уровнем квалификации конкретного работника.
Описанные достоинства и недостатки централизованной и децентрализованной информационной технологии привели к необходимости придерживаться линии разумного применения и того и другого подхода. Такой подход назовем рациональной методологией и покажем, как в этом случае будут распределяется обязанности:
вычислительный центр должен отвечать за выработку общей стратегии использования информационной технологии, помогать пользователям как в работе, так и в обучении, устанавливать стандарты и определять политику применения программных и технических средств;
персонал, использующий информационную технологию, должен придерживаться указании вычислительного центра, осуществлять разработку своих локальных систем и технологии в соответствии с общим планом организации.
Рациональная методология использование информационной технологии позволить постичь большей гибкости, поддерживать общие стандарты, осуществить совместимость информационных локальных продуктов, снизить дублирование деятельности и др.
3.3 Выбор вариантов внедрения информационной технологии в фирме
При внедрении информационной технологии в фирму необходимо выбрать одну из двух основных концепции, отражающих сложившиеся точки зрения на существующую структуру организации и роль в ней компьютерной обработки информации.
П е р в а я концепция ориентируется на существующую структуру фирмы. Информационная технология приспосабливается к организационной структуре, и происходит лишь модернизация методов работы. Коммуникации развиты слабо, рационализируются только рабочие места. Происходить распределения функции между техническими работниками и специалистами. Степень риска от внедрения новой информационной технологии минимальна, так как затраты незначительны и организационная структура фирмы не меняется.
Основной недостаток такой стратегии - непрерывных изменении формы представления информации, приспособленной к конкретным технологическим методам и техническим средствам. Любое оперативное решение «вязнет» на различных этапах информационной технологии.
К достоинствам стратегии можно отнести минимальные степень риска и затраты.
В т о р а я концепция ориентируется на будущую структуру фирмы. Существующая структура будет модернизироваться.
Данная стратегия предполагает максимальное развитие коммуникации и разработку новых организационных взаимосвязей. Продуктивность организационной структуры фирмы возрастает, так как рационально распределяются архивы данных, снижается объем циркулирующей по системным каналам информации и достигается сбалансированность между решаемыми задачами.
К основным ее недостаткам следует отнести:
существенные затраты на первом этапе, связанном с разработкой общей концепции и обследованием всех подразделении фирмы;
наличие психологической напряженности, вызванной предполагаемыми изменениями структуры фирмы и, как следствие, изменениями штатного расписания и должностных обязанностей.
Достоинствами данной стратегии являются:
рационализация организационной структуры фирмы;
максимальная занятость всех работников;
интеграция профессиональных функции за счет использования компьютерных сетей.
Новая информационная технология в фирме должна быть такой, чтобы уровни информации и подсистемы, ее обрабатывающие, связывались между собой единым массивом информации. При этом предъявляются два требования. Во - первых, структура системы переработки информации должна соответствовать распределению полномочии в фирме. Во - вторых, информация внутри системы должна функционировать так, чтобы достаточно полно отражать уровни управления.
48. Защита информации в сетях
Методы защиты информации в канале связи
Методы защиты информации в канале связи можно разделить на две группы:
основанные на ограничении физического доступа к линии и аппаратуре связи;
основанные на преобразовании сигналов в линии к форме, исключающей (затрудняющей) для злоумышленника восприятие или искажение содержания передачи.
Методы первой группы в основном находят применение в системах правительственной связи, где осуществляется контроль доступа к среде передачи данных.
Методы второй группы направлены на обратимое изменение формы представления передаваемой информации. Преобразование должно придавать информации вид, исключающий ее восприятие при использовании аппаратуры, стандартной для данного канала связи. При использовании же специальной аппаратуры восстановление исходного вида информации должно требовать затрат времени и средств, которые по оценке владельца защищаемой информации делают бессмысленным для злоумышленника вмешательство в информационный процесс.
При защите обмена данными решающее значение имеет форма представления сигнала в канале связи.
Следует учесть, что деление на "аналоговый" или "цифровой" сигнал условно. Для некоторых вариантов механизмов защиты информации требуется взаимная синхронизация и обмен служебными посылками между взаимодействующей аппаратурой защиты, т.е. присутствует цифровой режим, однако, поскольку этот режим не связан непосредственно с речевым обменом, требования к его скоростным характеристикам достаточно свободны.
С другой стороны, символьный (цифровой) обмен в протяженных каналах всегда осуществляется через модемное преобразование в виде аналогового сигнала.
Основная проблема, с которой сталкиваются пользователи сетей, где применяется сквозное шифрование, связана с тем, что служебная информация. используемая для учстановления соединения, передается по сети в незашифрованном виде. Опытный криптоаналитик может извлечь для себя массу полезной информации, зная кто с кем, как долго и в какие часы общается через сеть доступа. Для этого ему даже не потребуется быть в курсе предмета общения.
По сравнению с канальным, сквозное шифрование характеризуется более сложной работой с ключами, поскольку каждая пара пользователей должна быть снабжена одинаковыми ключами, прежде чем они смогут связаться друг с другом. А поскольку криптографический алгоритм реализуется на верхних уровнях модели OSI, приходится также сталкиваться со многими существенными различиями в коммуникационных протоколах и интерфейсах сети доступа (для примера: отправитель - канал ТЧ, получатель - 2B+D). Все это затрудняет практическое применение сквозного шифрования.
Приведенные выше методы защиты информации уже не удолетворяют современных требованиям. При использовании этих методов злоумышленник может перехватывать адресную информацию, вести мониторинг передаваемых данных, несанкционированно подключаться к линии, искажать передаваемую информацию.
Единственным возможным методом, удовлетворяющим всем современны требованиям, является использования комбинации канального и сквозного шифрования. При этом может закрывается вся передаваемая по каналу связи информация.
Комбинация канального и сквозного шифрования данных в сети доступа обходится значительно дороже, чем каждое из них по отдельности. Однако именно такой подход позволяет наилучшим образом защитить данные, передаваемые по сети. Шифрование в каждом канале связи не позволяет злоумышленнику анализировать служебную информацию, используемую для маршрутизации. А сквозное шифрование уменьшает вероятность доступа к незашифрованным данным в узлах сети.
При этом злоумышленник может проводить анализ только открыто передаваемых данных, но не может нелегально использовать линию связи.
Межсетевые экраны (FireWall) должны удовлетворять следующим группам более детальных требований. По целевым качествам — обеспечивать безопасность защищаемой внутренней сети и полный контроль над внешними подключениями и сеансами связи. Межсетевой экран должен иметь средства авторизации доступа пользователей через внешние подключения. Типичной является ситуация, кагда часть персонала организации должна выезжать, например, в командировку, и в процессе работы им требуется доступ к некоторым ресурсам внутренней компьютерной сети организации. Брандмауэр должен надежно распознавать таких пользователей и предоставлять им необходимые виды доступа.
По управляемости и гибкости — обладать мощными и гибкими средствам управления для полного воплощения в жизнь политики безопасности организации. Брандмауэр должен обеспечивать простую реконфигурацию системы при изменении структуры сети. Если у организации имеется несколько внешних подключений, в том числе и в удаленных филиалах, система управления экранами должна иметь возможность централизованно обеспечивать для них проведение единой политики межсетевых взаимодействий.
По производительности и прозрачности — работать достаточно эффективно и успевать обрабатывать весь входящий и исходящий трафик при максимальной нагрузке. Это необходимо для того, чтобы брандмауэр нельзя было перегрузить большим количеством вызовов, которые привели бы к нарушению его работы. Межсетевой экран должен работать незаметно для пользователей локальной сети и не затруднять выполнение ими легальных действий. В противном случае пользователи будут пытаться любыми способами обойти установленные уровни защиты.
По самозащищенности — обладать свойством самозащиты от любых несанкционированных воздействий. Поскольку межсетевой экран является и ключом и дверью к конфиденциальной информации в организации, он должен блокировать любые попытки несанкционированного изменения его параметров настройки, а также включать развитые средства самоконтроля своего состояния и сигнализации. Средства сигнализации должны обеспечивать своевременное уведомление службы безопасности при обнаружении любых несанкционированных действий, а также нарушении работоспособности межсетевого экрана.
Криптографические методы защиты информации в автоматизированных системах могут применяться как для защиты информации, обрабатываемой в ЭВМ или хранящейся в различного типа ЗУ, так и для закрытия информации, передаваемой между различными элементами системы по линиям связи. Криптографическое преобразование как метод предупреждения несационированного доступа к информации имеет многовековую историю. В настоящее время разработано большое колличество различных методов шифрования, созданы теоретические и практические основы их применения. Подавляющие число этих методов может быть успешно использовано и для закрытия информации. Под шифрованием в данном едаваемых сообщений, хранение информации (документов, баз данных) на носителях в зашифрованном виде.
Криптография занимается поиском и исследованием математических методов преобразования информации.
Сфера интересов криптоанализа - исследование возможности расшифровывания информации без знания ключей.
Современная криптография включает в себя четыре крупных раздела:
Симметричные криптосистемы.
Криптосистемы с открытым ключом.
Системы электронной подписи.
Управление ключами.
Основные направления использования криптографических методов - передача конфиденциальной информации по каналам связи (например, электронная почта), установление подлинности передаваемых сообщений ,хранение информации (документов,баз данных) на носителях в зашифрованном виде.
Криптографические методы защиты информации в автоматизированных системах могут применяться как для защиты информации, обрабатываемой в ЭВМ или хранящейся в различного типа ЗУ, так и для закрытия информации, передаваемой между различными элементами системы по линиям связи. Криптографическое преобразование как метод предупреждения несационированного доступа к информации имеет многовековую историю. В настоящее время разработано большое колличество различных методов шифрования, созданы теоретические и практические основы их применения. Подавляющие число этих методов может быть успешно использовано и для закрытия информации.
Итак, криптография дает возможность преобразовать информацию таким образом, что ее прочтение (восстановление) возможно только при знании ключа.
Криптосистемы разделяются на симметричные и с открытым ключом.
В симметричных криптосистемах и для шифрования, и для дешифрования используется один и тот же ключ.
В системах с открытым ключом используются два ключа - открытый и закрытый, которые математически связаны друг с другом. Информация шифруется с помощью открытого ключа, который доступен всем желающим, а расшифровывается с помощью закрытого ключа, известного только получателю сообщения.
Термины распределение ключей и управление ключами относятся к процессам системы обработки информации, содержанием которых является составление и распределение ключей между пользователями.
Электронной (цифровой) подписью называется присоединяемое к тексту его криптографическое преобразование, которое позволяет при получении текста другим пользователем проверить авторство и подлинность сообщения.
49. Модели информационных процессов передачи, обработки, накопления данных
Информация передаётся в виде сообщений от некоторого источника информации к её приёмнику посредством канала связи между ними. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал. Этот сигнал посылается по каналу связи. В результате в приёмнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
канал связи ИСТОЧНИК-----------?ПРИЁМНИК
Примеры:
1.сообщение, содержащее информацию о прогнозе погоды, передаётся приёмнику (телезрителю) от источника - специалиста-метеоролога посредством канала связи - телевизионной передающей аппаратуры и телевизора;
2.живое существо своими органами чувств (глаз, ухо, кожа, язык и т.д.) воспринимает информацию из внешнего мира, перерабатывает её в определенную последовательность нервных импульсов, передает импульсы по нервным волокнам, хранит в памяти в виде состояния нейронных структур мозга, воспроизводит в виде звуковых сигналов, движений и т.п., использует в процессе своей жизнедеятельности.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Информацию можно:
·создавать;
·передавать;
·воспринимать;
·использовать;
·запоминать;
·принимать;
·копировать;
·формализовать;
·распространять;
·преобразовывать;
·комбинировать;
·обрабатывать;
·делить на части;
·упрощать;
·собирать;
·хранить;
·искать;
·измерять;
·разрушать;
·и др.
Все эти процессы, связанные с определенными операциями над информацией, называются информационными процессами.
Свойства информации:
·достоверность;
·полнота;
·ценность;
·своевременность;
·понятность;
·доступность;
·краткость;
и др.
Информация достоверна, если она отражает истинное положение дел. Недостоверная информация может привести к неправильному пониманию или принятию неправильных решений.
Достоверная информация со временем может стать недостоверной, так как она обладает свойством устаревать, то есть перестаёт отражать истинное положение дел.
Информация полна, если её достаточно для понимания и принятия решений. Как неполная, так и избыточная информация сдерживает принятие решений или может повлечь ошибки.
Точность информации определяется степенью ее близости к реальному состоянию объекта, процесса, явления и т.п.
Ценность информации зависит от того, насколько она важна для решения задачи, а также от того, насколько в дальнейшем она найдёт применение в каких-либо видах деятельности человека.
Только своевременно полученная информация может принести ожидаемую пользу. Одинаково нежелательны как преждевременная подача информации (когда она ещё не может быть усвоена), так и её задержка.
Если ценная и своевременная информация выражена непонятным образом, она может стать бесполезной.
Информация становится понятной, если она выражена языком, на котором говорят те, кому предназначена эта информация.
Информация должна преподноситься в доступной (по уровню восприятия) форме. Поэтому одни и те же вопросы по-разному излагаются в школьных учебниках и научных изданиях.
Информацию по одному и тому же вопросу можно изложить кратко (сжато, без несущественных деталей) или пространно (подробно, многословно). Краткость информации необходима в справочниках, энциклопедиях, учебниках, всевозможных инструкциях.
Обработка информации - получение одних информационных объектов из других информационных объектов путем выполнения некоторых алгоритмов.
Обработка является одной из основных операций, выполняемых над информацией, и главным средством увеличения объёма и разнообразия информации.
Средства обработки информации - это всевозможные устройства и системы, созданные человечеством, и в первую очередь, компьютер - универсальная машина для обработки информации.
Компьютеры обрабатывают информацию путем выполнения некоторых алгоритмов.
Живые организмы и растения обрабатывают информацию с помощью своих органов и систем.
Человечество занималось обработкой информации тысячи лет. Первые информационные технологии основывались на использовании счётов и письменности. Около пятидесяти лет назад началось исключительно быстрое развитие этих технологий, что в первую очередь связано с появлением компьютеров.
51. Анализ и оценка производительности вычислительных комплексов асоиу
Теоретические положения системного анализа определенное время рассматривались только как некая философия инженера и поэтому при решении задач создания искусственных систем иногда не учитывались. Однако развитие техники привело к тому, что без СА, одним из результатов к-го явл-ся концептуальные модели, исследование функционирования систем становится невозможным.
Первоначально комп отождествлялся с центральным процессором, основной и понятной х-кой были быстродействие, измеряемое числом команд в единицу времени. Поэтому современные методики оценки отражают только возможности центрального процессора. В основе такой оценки лежит понятие производительности. При этом выделяют так называемое «чистое» процессорное время – период работы собственно процессора при выполнении внутренних операций и время ответа, включающее выполнение операций ввода-вывода, работу ОС и т.д.
Есть 2 показателя производительности процессов по «чистому» времени:
показатель производительности процессоров на операциях с данными целочисленного типа
MIPS – отношение числа команд в программе к времени ее выполнения
показатель производительности процессоров на операциях с данными вещественного типа
при все кажущейся простоте критерия оценки (чем > MIPS, тем быстрее выполняется программа) его использование затруднено вследствие нескольких причин:
процессоры разной архитектуры имеют различный набор команд
применение матем-х сопроцессоров и оптимизирующих компиляторов увеличивает
производительность системы, но рейтинг MIPS может уменьшится, т.к. время выполнения команд для операций над данными с плавающей точкой значительно больше и за единицу времени м.б. выполнено меньшее число команд, нежели при выполнении соответствующих этим командам подпрограмм
научные приложения в основном связаны с интенсивными вычислениями над вещественными
числами с плавающей точкой, коммерческие и офисные – с целочисленной арифметикой и обработкой транзакций БД. Графические приложения критичны и к вычислительным мощностям, и к параметрам графической подсистемы.
Еще более сложные проблемы появляются при необходимости оценок многопроцессорных систем. Такое положение привело к разработке и использованию ряда тестов, ориентированных на оценку вычислительных систем с учетом специфики их предполагаемого использования. Поэтому оценка процессоров с разной архитектурой основана на создании тестовой смеси из типовых операторов, влияющих на их производительность.
52. Критерии качества программного обеспечения
1 Функциональные возможности
-функциональная пригодность
-корректность-правильность
-способность к взаимодействию (с ОС и аппаратурой, м-ду др программами)
-защищенность (от предумышленных угроз, случайных дефектов программ)
2 Надежность
-завершенность (наработка на отказ при отсутствии рестарта)
-устойчивость к дефектам (наработка при наличие рестарта)
-восстанавливаемость
-доступность, готовность
3 Эффективность
-временная эффективность
- используемые ресурсы (процессорное время, память и т.д)
4 Практичность
-понятность
-простота использования
-изучаемость
-привлекательность
5 Сопровождаемость
-анализируемость
-изменяемость
-стабильность
-тестируемость
6 Мобильность
-адаптируемость
-простота установки
-сосуществование соответствия
-замещаемость
54. Основные современные методологии проектирования сложных программных средств: rad, msf, rup
Быстрая разработка приложений. RAD (от англ. rapid application development — быстрая разработка приложений) — концепция создания средств разработки программных продуктов, уделяющая особое внимание быстроте и удобству программирования, созданию технологического процесса, позволяющего программисту максимально быстро создавать компьютерные программы. С конца XX века RAD получила широкое распространение и одобрение. Концепцию RAD также часто связывают с концепцией визуального программирования.
Основные принципы RAD:
а) Инструментарий должен быть нацелен на минимизацию времени разработки;
б) Создание прототипа для уточнения требований заказчика;
в) Цикличность разработки: каждая новая версия продукта основывается на оценке результата работы предыдущей версии заказчиком;
г) Минимизация времени разработки версии, за счёт переноса уже готовых модулей и добавления функциональности в новую версию;
д) Команда разработчиков должна тесно сотрудничать, каждый участник должен быть готов выполнять несколько обязанностей;
е) Управление проектом должно минимизировать длительность цикла разработки.
Концепция RAD стала ответом на неуклюжие методы разработки программ 1970-х и начала 1980-х годов, такие как «модель водопада» (англ. Waterfall model). Эти методы предусматривали настолько медленный процесс создания программы, что зачастую даже требования к программе успевали измениться до окончания разработки. Основателем RAD считается сотрудник IBM Джеймс Мартин, который в 1980-х годах сформулировал основные принципы RAD, основываясь на идеях Барри Бойма и Скотта Шульца. А в 1991 году Мартин опубликовал известную книгу, в которой детально изложил концепцию RAD и возможности её применения. В настоящее время RAD становится общепринятой схемой для создания средств разработки программных продуктов. Именно средства разработки, основанные на RAD, имеют наибольшую популярность среди программистов.
Методология Rational Software. Rational Unified Process (RUP) — методология разработки программного обеспечения, созданная компанией Rational Software.
Rational Unified Process, был разработан в корпорации IBM, одной из дочерних компаний которой являюется Rational Software. Методология RUP описывает абстрактный общий процесс, на основе которого организация или проектная команда должна создать специализированный процесс, ориентированный на ее потребности. Можно выделить следующие основные характеристики RUP:
а) Разработка требований. Основой для разработки требований в этом процессе являются так называемые прецеденты использования (т.е. сценарии взаимодействия пользователя с программой). Полный набор прецедентов использования системы вместе с логическими отношениями между ними (прецеденты могут включать и расширять другие прецеденты) называется моделью прецедентов использования, и должен описать по возможности все возможный случаи работы с приложением;
б) Итеративность. Как уже было сказано выше, в основе RUP лежит итеративная модель. Создателями рекомендуется перед началом каждой итерации выделить те преценденты, которые должны быть реализованы в данный момент, но не завышать их количество, чтобы итерация не затянулась;
в) Цикл проекта.
Для удобства разделим итерации на т.н.
фазы. RUP предусматривает прохождение
четырех фаз: начало (необходимо пределить
видение и границы проекта, создать
экономическое обоснование , идентифицировать
большую часть прецедентов использования
и подробно описать несколько ключевых
прецедентов, найти хотя бы одно возможное
архитектурное решение, оценить бюджет,
график и риски проекта), проектирование
(необязательная фаза, на которой
происходит детальное описание большей
части прецедентов использования,
снижение основных рисков и уточнение
бюджета и графика проекта), построение
(разработка окончательного продукта,
написание основной части кода) и
внедрение.
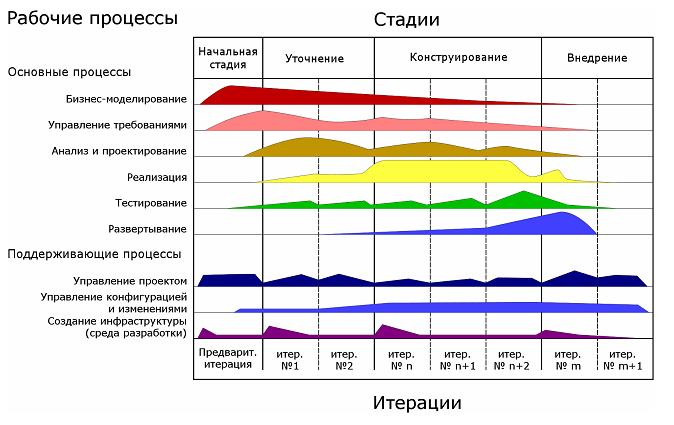 Рис.
2 RUP.
Рис.
2 RUP.
Методология Microsoft.
Microsoft Solutions Framework (MSF) — это методология разработки программного обеспечения от Microsoft. MSF опирается на практический опыт корпорации Майкрософт и описывает управление людьми и рабочими процессами в процессе разработки решения. MSF представляет собой согласованный набор концепций, моделей и правил. MOF призван обеспечить организации, создающие критически важные (mission-critical) IT решения на базе продуктов и технологий Майкрософт, техническим руководством по достижению их надежности (reliability), доступности (availability), удобства сопровождения (supportability) и управляемости (manageability). MOF затрагивает вопросы, связанные с организацией персонала и процессов; технологиями и менеджментом в условиях сложных (complex), распределенных (distributed) и разнородных (heterogeneous) IT-сред. MOF основан на лучших производственных методиках, собранных в IT Infrastructure Library (ITIL), составленной Central Computer and Telecommunications Agency — Агентством правительства Великобритании. Создание бизнес-решения в рамках отведенных времени и бюджета требует наличия испытанной методологической основы.MSF предлагает проверенные методики для планирования, проектирования, разработки и внедрения успешных IT-решений. Благодаря своей гибкости, масштабируемости и отсутствию жестких инструкций MSF способен удовлетворить нужды организации или проектной группы любого размера. Методология MSF состоит из принципов, моделей и дисциплин по управлению персоналом, процессами, технологическими элементами и связанными со всеми этими факторами вопросами, характерными для большинства проектов. Информация по MSF доступна в Internet по адресу [2]. MSF состоит из двух моделей и трех дисциплин. Они подробно описаны в 5 whitepapers. Начинать изучение MSF лучше с моделей, а затем перейти к дисциплинам.
MSF содержит:
а) модели: модель проектной группы;
модель процессов;
б) дисциплины: дисциплина управление проектами; дисциплина управление рисками;дисциплина управление подготовкой.
56. Способы записи алгоритма программы
Алгоритм, составленный для некоторого исполнителя, можно представить различными способами: графического и словесного описания, в виде таблицы, последовательностью формул, записанным на алгоритмическом языке (язык программирования).
Хотя алгоритмы обычно предназначены для автоматического выполнения, они создаются и разрабатываются людьми. Поэтому первоначальная запись алгоритма обычно производится в форме, доступной для восприятия человеком.
Самой простой является словесная форма записи алгоритмов на естественном языке. В этом виде алгоритм представляет собой описание последовательности этапов обработки данных, изложенное в произвольной форме. Словесная форма удобна для человеческого восприятия, но страдает многословностью и неоднозначностью. Отказ от естественного языка требует частичной формализации способа записи алгоритма и использования стандартных приемов построения алгоритмов в виде комбинаций базовых алгоритмических структур. Таких базовых структур всего три: следование, ветвление и цикл. Характерной особенностью всех базовых структур является наличие одного входа и одного выхода.

Графическая записьалгоритмов также предназначена для наглядного восприятия человеком. Она более компактна, наглядна и формальна, чем запись в словесном виде. Алгоритм изображается как последовательность функциональных блоков, соответствующих одной или нескольким командам алгоритма. Такое графическое представление алгоритма называют блок-схемой. Элементы блок-схемы, блочные символы, — это геометрические фигуры. Они представляют базовые алгоритмические структуры.
Блок-схема– это ориентированный граф, указывающий порядок исполнения команд алгоритма. Вершины такого графа могут быть одного из трех типов: функциональная, предикатная и объединяющая (рис)
На практике при составлении блок-схем удобно использовать следующие графические знаки:

Термины метаязык или псевдокод используют в тех случаях, когда запись алгоритма формализована частично. В таком случае она содержит как элементы естественного языка, так и формальные конструкции, описывающие базовые алгоритмические структуры. Подобная запись алгоритма предназначена для чтения человеком. Она не может использоваться для подготовки алгоритма к автоматическому выполнению. Однако использование жестких языковых конструкций облегчает переход к формальной записи алгоритма. Формального определения псевдокода или строгих правил записи алгоритмов в таком формате не существует. Можно представить себе разные псевдокоды, использующие различные ключевые слова и способы представления базовых алгоритмических структур.
Термины алгоритмический язык и язык программирования часто используют как синонимы. При использовании этих языков запись алгоритма совершенно формальна. Синтаксис языка однозначно определяет, что допустимо, а что нет.
Алгоритмические языки считаются машинно-независимыми. Запись на алгоритмическом языке используют, например, при публикации алгоритмов.
Чтобы выполнить вычислительный алгоритм на компьютере, его записывают на языке программирования. Для подготовки алгоритма, записанного на языке программирования, к выполнению, применяют автоматические средства. Специальная программа – транслятор переводит каждую команду алгоритма в последовательность инструкций процессора. Получается программа на машинном языке, которая уже может быть выполнена.
Отдельная инструкция языка программирования называется оператором. Программа — это упорядоченная последовательность операторов. Способ отделения операторов друг от друга определяется правилами языка. Во многих ранних языках программирования существовало правило: новая строка — новый оператор.
Современные языки программирования обычно позволяют поместить на одну строку несколько операторов или, наоборот, разбить оператор на несколько строк. В этом случае для отделения операторов друг от друга используется символ-разделитель. В большинстве других языков программирования (Паскаль, Си) в качестве разделителя используется точка с запятой (;).
Запись операторов в языках программирования обычно производится с помощью ключевых слов, хотя некоторые операторы их не требуют. Конкретные ключевые слова различны в разных языках программирования. Обычно это слова английского языка, значение которых примерно соответствует назначению оператора. Говоря об операторах, обычно указывают их назначение (оператор присваивания, условный оператор, оператор цикла, оператор вызова подпрограммы и т.п.).
59. Принципы построения операционных систем. Основные компоненты сетевых операционных систем
Основные принципы построения операционных систем
Принцип модульности - обособление составных частей ОС в отдельные модули (функционально законченные элементы системы), выполненное в соответствии с принятыми межмодульными интерфейсами;
Принцип генерируемости ОС - определяет такой способ исходного представления ядра ОС и основных компонентов ОС, который позволяет производить их настройку, исходя из конкретной конфигурации конкретного вычислительного комплекса и круга решаемых задач;
Принцип функциональной избыточности - учитывает возможность проведения одной и той же работы различными средствами;
Принцип виртуализации - представляет структуру системы в виде определенного набора планировщиков процессов и распределителей ресурсов и позволяет использовать единую централизованную схему распределения ресурсов, организуя тем самым работу виртуальной машины;
Принцип независимости программ от внешних устройств - связь программ с конкретными устройствами производится не на уровне трансляции программы, а в период планирования ее исполнения;
Принцип совместимости - способность ОС выполнять программы, написанные для других ОС или для более ранних версий данной операционной системы, а также для другой аппаратной платформы;
Принцип открытой и наращиваемой ОС - позволяет не только использовать возможности генерации, но и вводить в ее состав новые модули;
Принцип обеспечения безопасности при выполнении вычислений - является желательным свойством для любой многопользовательской системы;
Компоненты сетевых ОС
Функциональные модули (сетевые службы и средства транспортировки сообщений по сети) должны быть добавлены к ОС, чтобы она могла называться сетевой:

Функциональные компоненты сетевой ОС
Среди сетевых служб можно выделить такие, которые ориентированы не на простого пользователя, как, например, файловая служба или служба печати, а на администратора. Такие службы направлены на организацию работы сети. Например, централизованная справочная служба, или служба каталогов (например, Active Directory в Windows), предназначена для ведения базы данных о пользователях сети, обо всех ее программных и аппаратных компонентах1. В качестве других примеров можно назватьслужбу мониторинга сети, позволяющую захватывать и анализировать сетевой трафик, службу безопасности, в функции которой может входить, в частности, выполнение процедуры логического входа с проверкой пароля, службу резервного копирования и архивирования.
От того, насколько богатый набор сетевых служб и услуг предлагает операционная система конечным пользователям, приложениям и администраторам сети, зависит ее позиция в общем ряду сетевых ОС.
Помимо сетевых служб сетевая ОС должна включать программные коммуникационные (транспортные) средства, обеспечивающие совместно с аппаратными коммуникационными средствами передачу сообщений, которыми обмениваются клиентские и серверные части сетевых служб. Задачу коммуникации между компьютерами сети решают драйверы и протокольные модули. Они выполняют такие функции, как формирование сообщений, разбиение сообщения на части (пакеты, кадры), преобразование имен компьютеров в числовые адреса, дублирование сообщений в случае их потери, определение маршрута в сложной сети и т. д.
И сетевые службы, и транспортные средства могут являться неотъемлемыми (встроенными) компонентами ОС или существовать в виде отдельных программных продуктов. Например, сетевая файловая служба обычно встраивается в ОС, а вот веб-браузер чаще всего приобретается отдельно. Типичная сетевая ОС имеет в своем составе широкий набор драйверов и протокольных модулей, однако у пользователя, как правило, есть возможность дополнить этот стандартный набор необходимыми ему программами. Решение о способе реализации клиентов и серверов сетевой службы, а также драйверов и протокольных модулей принимается разработчиками с учетом самых разных соображений: технических, коммерческих и даже юридических. Так, например, именно на основании антимонопольного закона США компании Microsoft было запрещено включать ее браузер Internet Explorer в состав ОС этой компании.
60. Методы распределения памяти. Сегментная, страничная, странично–сегментная
Понятие виртуальной памяти
Уже достаточно давно пользователи столкнулись с проблемой размещения в памяти программ, размер которых превышал имеющуюся в наличии свободную память. Решением было разбиение программы на части, называемые оверлеями. 0-ой оверлей начинал выполняться первым. Когда он заканчивал свое выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами операционной системы. Однако разбиение программы на части и планирование их загрузки в оперативную память должен был осуществлять программист.
Развитие методов организации вычислительного процесса в этом направлении привело к появлению метода, известного под названием виртуальная память. Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает. Так, например, пользователю может быть предоставлена виртуальная оперативная память, размер которой превосходит всю имеющуюся в системе реальную оперативную память. Пользователь пишет программы так, как будто в его распоряжении имеется однородная оперативная память большого объема, но в действительности все данные, используемые программой, хранятся на одном или нескольких разнородных запоминающих устройствах, обычно на дисках, и при необходимости частями отображаются в реальную память.
Таким образом, виртуальная память - это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи:
размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске;
перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память;
преобразует виртуальные адреса в физические.
Все эти действия выполняются автоматически, без участия программиста, то есть механизм виртуальной памяти является прозрачным по отношению к пользователю.
Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично-сегментное распределение памяти, а также свопинг.
Страничное распределение
На рисунке 2.12 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками).
Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т.д., это позволяет упростить механизм преобразования адресов.
При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. При загрузке операционная система создает для каждого процесса информационную структуру - таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в оперативную память, или делается отметка о том, что виртуальная страница выгружена на диск. Кроме того, в таблице страниц содержится управляющая информация, такая как признак модификации страницы, признак невыгружаемости (выгрузка некоторых страниц может быть запрещена), признак обращения к странице (используется для подсчета числа обращений за определенный период времени) и другие данные, формируемые и используемые механизмом виртуальной памяти.

Рис. 2.12. Страничное распределение памяти
При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса.
При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из оперативной памяти.
В данной ситуации может быть использовано много разных критериев выбора, наиболее популярные из них следующие:
дольше всего не использовавшаяся страница,
первая попавшаяся страница,
страница, к которой в последнее время было меньше всего обращений.
В некоторых системах используется понятие рабочего множества страниц. Рабочее множество определяется для каждого процесса и представляет собой перечень наиболее часто используемых страниц, которые должны постоянно находиться в оперативной памяти и поэтому не подлежат выгрузке.
После того, как выбрана страница, которая должна покинуть оперативную память, анализируется ее признак модификации (из таблицы страниц). Если выталкиваемая страница с момента загрузки была модифицирована, то ее новая версия должна быть переписана на диск. Если нет, то она может быть просто уничтожена, то есть соответствующая физическая страница объявляется свободной.
Рассмотрим механизм преобразования виртуального адреса в физический при страничной организации памяти (рисунок 2.13).
Виртуальный адрес при страничном распределении может быть представлен в виде пары (p, s), где p - номер виртуальной страницы процесса (нумерация страниц начинается с 0), а s - смещение в пределах виртуальной страницы. Учитывая, что размер страницы равен 2 в степени к, смещение s может быть получено простым отделением k младших разрядов в двоичной записи виртуального адреса. Оставшиеся старшие разряды представляют собой двоичную запись номера страницы p.

Рис. 2.13. Механизм преобразования виртуального адреса в физический при страничной организации памяти
При каждом обращении к оперативной памяти аппаратными средствами выполняются следующие действия:
на основании начального адреса таблицы страниц (содержимое регистра адреса таблицы страниц), номера виртуальной страницы (старшие разряды виртуального адреса) и длины записи в таблице страниц (системная константа) определяется адрес нужной записи в таблице,
из этой записи извлекается номер физической страницы,
к номеру физической страницы присоединяется смещение (младшие разряды виртуального адреса).
Использование в пункте (3) того факта, что размер страницы равен степени 2, позволяет применить операцию конкатенации (присоединения) вместо более длительной операции сложения, что уменьшает время получения физического адреса, а значит повышает производительность компьютера.
На производительность системы со страничной организацией памяти влияют временные затраты, связанные с обработкой страничных прерываний и преобразованием виртуального адреса в физический. При часто возникающих страничных прерываниях система может тратить большую часть времени впустую, на свопинг страниц. Чтобы уменьшить частоту страничных прерываний, следовало бы увеличивать размер страницы. Кроме того, увеличение размера страницы уменьшает размер таблицы страниц, а значит уменьшает затраты памяти. С другой стороны, если страница велика, значит велика и фиктивная область в последней виртуальной странице каждой программы. В среднем на каждой программе теряется половина объема страницы, что в сумме при большой странице может составить существенную величину. Время преобразования виртуального адреса в физический в значительной степени определяется временем доступа к таблице страниц. В связи с этим таблицу страниц стремятся размещать в "быстрых" запоминающих устройствах. Это может быть, например, набор специальных регистров или память, использующая для уменьшения времени доступа ассоциативный поиск и кэширование данных.
Страничное распределение памяти может быть реализовано в упрощенном варианте, без выгрузки страниц на диск. В этом случае все виртуальные страницы всех процессов постоянно находятся в оперативной памяти. Такой вариант страничной организации хотя и не предоставляет пользователю виртуальной памяти, но почти исключает фрагментацию за счет того, что программа может загружаться в несмежные области, а также того, что при загрузке виртуальных страниц никогда не образуется остатков.
Сегментное распределение
При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным. Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Кроме того, разбиение программы на "осмысленные" части делает принципиально возможным разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же математическую подпрограмму, то в оперативную память может быть загружена только одна копия этой подпрограммы.
Рассмотрим, каким образом сегментное распределение памяти реализует эти возможности (рисунок 2.14). Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.

Рис. 2.14. Распределение памяти сегментами
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g - номер сегмента, а s - смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента, найденного в таблице сегментов по номеру g, и смещения s.
Недостатком данного метода распределения памяти является фрагментация на уровне сегментов и более медленное по сравнению со страничной организацией преобразование адреса.
Странично-сегментное распределение
Как видно из названия, данный метод представляет собой комбинацию страничного и сегментного распределения памяти и, вследствие этого, сочетает в себе достоинства обоих подходов. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс. На рисунке 2.15 показана схема преобразования виртуального адреса в физический для данного метода.

Рис. 2.15. Схема преобразования виртуального адреса в физический для сегментно-страничной организации памяти
61. Структура операционной системы. Модель клиент – сервер
1.4 Структура операционных систем
1.4.1 Монолитная система
Структура системы:
Главная программа, которая вызывает требуемые сервисные процедуры.
Набор сервисных процедур, реализующих системные вызовы.
Набор утилит, обслуживающих сервисные процедуры.

Простая модель монолитной системы
В этой модели для каждого системного вызова имеется одна сервисная процедура (например, читать из файла). Утилиты выполняют функции, которые нужны нескольким сервисным процедурам(например, для чтения и записи файла необходима утилита работы с диском).
Этапы обработки вызова:
Принимается вызов
Выполняется переход из режима пользователя в режим ядра
ОС проверяет параметры вызова для того, чтобы определить, какой системный вызов должен быть выполнен
После этого ОС обращается к таблице, содержащей ссылки на процедуры, и вызывает соответствующую процедуру.
1.4.2 Многоуровневая структура ос
Обобщением предыдущего подхода является организация ОС как иерархии уровней. Уровни образуются группами функций операционной системы - файловая система, управление процессами и устройствами и т.п. Каждый уровень может взаимодействовать только со своим непосредственным соседом - выше- или нижележащим уровнем. Прикладные программы или модули самой операционной системы передают запросы вверх и вниз по этим уровням.

Пример структуры многоуровневой системы
Преимущества:
Высокая производительность
Недостатки:
Большой код ядра, и как следствие большое содержание ошибок
Ядро плохо защищено от вспомогательных процессов
Пример реализации многоуровневой модели UNIX.

Структура ОС UNIX

Ядро ОС UNIX
Пример реализации многоуровневой модели Windows

Структура Windows 2000
1.4.3 Модель экзоядра
Если предыдущие модели брали на себя максимум функций, принцип экзоядра, все отдать пользовательским программам. Например, зачем нужна файловая система? Почему не позволить пользователю просто читать и писать участки диска защищенным образом? Т.е. каждая пользовательская программа сможет иметь свою файловую систему. Такая операционная система должна обеспечить безопасное распределение ресурсов среди соревнующихся за них пользователей.
1.4.4 Микроядерная архитектура (модель клиент-сервер)
Эта модель является средним между двумя предыдущими моделями.
В развитии современных операционных систем наблюдается тенденция в сторону дальнейшего переноса задач из ядра в уровень пользовательских процессов, оставляя минимальное микроядро.
В этой модели вводятся два понятия:
Серверный процесс (который обрабатывает запросы)
Клиентский процесс (который посылает запросы)
В задачу ядра входит только управление связью между клиентами и серверами.

Модель клиент-сервер
Преимущества:
Малый код ядра и отдельных подсистем, и как следствие меньшее содержание ошибок.
Ядро лучше защищено от вспомогательных процессов.
Легко адаптируется к использованию в распределенной системе.
Недостатки:
Уменьшение производительности.
1.4.5 Обобщение сравнения моделей

Сравнения моделей.
62. Иерархические каталоговые системы. Операции с каталогами
11.2.3 Иерархические каталоговые системы
Каждый пользователь может создавать столько каталогов, сколько ему нужно.

Иерархическая каталоговая система
Почти все современные универсальные ОС, организованы таким образом. Специализированным ОС это может быть не нужным.
11.2.4 Имя пути
Для организации дерева каталогов нужен некоторый способ указания файла.
Два основных метода указания файла:
абсолютное имя пути - указывает путь от корневого каталога, например: - для Windows \usr\ast\mailbox - для UNIX /usr/ast/mailbox - для MULTICS >usr>ast>mailbox
относительное имя пути - путь указывается от текущего каталога (рабочего каталога), например: - если текущий каталог /usr/, то абсолютный путь /usr/ast/mailbox перепишется в ast/mailbox - если текущий каталог /usr/ast/, то абсолютный путь /usr/ast/mailbox перепишется в mailbox - если текущий каталог /var/log/, то абсолютный путь /usr/ast/mailbox перепишется в ../../usr/ast/mailbox
./ - означает текущий каталог
../ - означает родительский каталог
11.2.5 Операции с каталогами
Основные системные вызовы для работы с каталогами:
Create - создать каталог
Delete - удалить каталог
OpenDir - закрыть каталог
CloseDir - закрыть каталог
ReadDir - прочитать следующий элемент открытого каталога
Rename - переименование каталога
Link - создание жесткой ссылки, позволяет файлу присутствовать сразу в нескольких каталогах.
Unlink - удаление ссылки из каталога
64. Модели представления знаний: логические, фреймовые, сетевые, продукционные, нечеткие
Важное место в теории искусственного интеллекта занимает проблема представления знаний, являющаяся, по мнению многих исследователей, ключевой. В общем виде модели представления знаний могут быть условно разделены на следующие классы:
1. Концептуальные модели используют эвристический метод, что позволяет при распознавании проблемы уменьшать время для ее предварительного анализа. Концептуальное описание не дает гарантии того, что метод может быть применен во всех соответствующих практических ситуациях. Практическое использование концептуальной модели влечет за собой необходимость преобразования ее в эмпирическую модель.
2. Эмпирические модели – это модели, как правило, описательного характера. Они могут варьировать от простого набора правил до полного описания.
3. Декларативные модели представления знаний основываются на предположении, что проблема представления некоей предметнойобласти решается независимо от того, как эти знания потом будут использоваться. Поэтому модель как бы состоит из двух частей: статических описательных структур знаний и механизма вывода, оперирующего этими структурами и практически независимого от их содержательного наполнения. При этом в какой-то степени оказываются раздельными синтаксические и семантические аспекты знания, что является определенным достоинством указанных форм представления из-за возможности достижения их определенной универсальности.Эти модели представляют собой обычно множество утверждений. Предметная область представляется в виде синтаксического описания ее состояния. Вывод решений основывается в основном на процедурах поиска в пространстве состояний.
4. Процедурные модели представляют собой модели, в которых знания содержатся в процедурах небольших программ, которые определяют, как выполнять характерные действия. При этом можно не описывать все возможные состояния среды или объекта для реализации вывода. Достаточно хранить некоторые начальные состояния и процедуры, генерирующие необходимые описания ситуаций и действий.
При процедурном представлении знаний семантика заложена в описание элементов базы знаний, за счет чего повышается эффективность поиска решений. Статическая база знаний содержит только утверждения, приемлемые в данный момент, которые могут быть изменены или удалены. Общие знания и правила вывода представлены в виде специальных целенаправленных процедур, активизирующихся по мере надобности. Для повышения эффективности генерации вывода в систему добавляются знания о том, каким образом использовать накопленные знания для решения конкретной задачи.
Преимущества процедурных моделей: имеют большую эффективность механизмов вывода за счет введения дополнительных знаний, способны смоделировать практически любую модель представления знаний, имеют большую выразительную силу, которая проявляется в расширенной системе выводов.
Представление знаний в экспертных системах производится с помощью специально разработанных моделей.
1. Логические модели. Классическим механизмом представления знаний в системах является исчисление предикатов. Предикатом или логической функцией называется функция от любого числа аргументов, принимающая истинные значения 1 и 0. В исследованиях по искусственному интеллекту данная модель стала использоваться начиная с 50-х годов.
В системах, основанных на исчислении предикатов, знания представляются с помощью перевода утверждений об объектах некоторой предметной области в формулы логики предикатов и добавления их как аксиом в систему. Знания отображаются совокупностью таких формул, а получение новых знаний сводится к реализации процедур логического вывода. Однако действительность не укладывается в рамки классической логики, потому что человеческая логика, применяемая при работе с неструктурированными знаниями – это интеллектуальная модель с нечеткой структурой. При использовании нечеткой логики часто применяются два метода логического вывода: прямой и обратный метод.
Достоинство логических моделей:
– модель базируется на классическом аппарате математической логики, методы которой хорошо изучены и обоснованы;
– имеются достаточно эффективные процедуры вывода;
– база знаний предназначена для хранения большого количества аксиом, из которых по правилам вывода можно получать другие знания.
Основной недостаток: логики, адекватно отражающей человеческое мышление, еще не создано
2. Продукционные модели. Впервые были предложены Постом в 1943 г., применены в системах искусственного интеллекта в 1972 г.При исследовании процессов рассуждения и принятия решений человеком пришли к выводу, что человек в процессе работы использует продукционные правила. Правило продукций (англ. Production) – это правило вывода, порождающее правило.
Суть правила продукции для представления знаний состоит в том, что в левой части ставится в соответствие некоторое условие, а в правой части действие: если <перечень условия>[90], то <перечень действий>. Если это действие соответствует значению «истина», то выполняется действие, заданное в правой части продукции. В общем случае под условием понимается некоторое предложение, по которому осуществляется поиск в базе знаний, а под действием – действия, выполняемые при успешном исходе поиска.
Продукционные модели – это набор, правил вида «условия – действие», где условиями являются утверждения о содержимом некой базы данных, а действия представляют собой процедуры, которые могут изменять содержимое базы данных. Например: Если коэффициент соотношения заемных и собственных средств превышает единицу при низкой оборачиваемости, то финансовая автономность и устойчивость критическая.
Правила (в них выражены знания) и факты (их оценивают с помощью правил) являются основным структурным элементом систем искусственного интеллекта. Часто в практики управления правила выводятся эмпирически из совокупности фактов, а не путем математического анализа или алгоритмического решения. Такие правила называют эвристиками.
В продукционной модели база знаний состоит из набора правил. Программа, управляющая перебором правил – машина вывода, связывает знание воедино и выводит из последовательности знаний заключение.
В процессе обработки информации часто применяются два метода: прямой и обратный. В случае прямого подхода – метода сопоставления для поиска решений образцом служит левая часть продукционного правила – условие и задача решается в направлении от исходного состояния к целевому. В случае обратного подхода обработка информации осуществляется по методу генерации или выдвижения гипотезы[91] и ее проверки. Проверяются правые части продукционных правил с целью обнаружения в них искомого утверждения. Если такие продукционные правила существуют, то проверяется, удовлетворяет ли левая часть продукционного правила. Если да, то гипотеза подтверждается, если нет – отвергается.
В продукционных системах выделяют три основные компоненты:
– неструктурированная или структурированная БД;
– набор продукционных правил или продукций, каждая продукция состоит из двух частей:
a) условий (антецендент); в этой части определяются некоторые условия, которые должны выполняться в БД для того, чтобы были выполнены соответствующие действия;
b) действий (консеквент); эта часть содержит описание действий, которые должны быть совершены над БД в случае выполнения соответствующих условий. В простейших продукционных системах они только определяют, какие элементы следует добавить (или иногда удалить) в БД.
– интерпретатор, который последовательно определяет, какие продукции могут быть активированы в зависимости от условий, в них содержащихся; выбирает одно из применимых в данной ситуации правил продукций; выполняет действие из выбранной процедуры.
Продукционные модели близки к логическим моделям, но более наглядно отражают знания, поэтому являются наиболее распространенными средствами представления знаний. Чаще всего они применяются в промышленных экспертных системах, в качестве решателей или механизмов выводов.
Достоинства продукционных моделей:
– наглядность;
– высокая модульность – отдельные логические правила могут быть добавлены в базу знаний, удалены или изменены независимо от других, модульный принцип разработки систем позволяет автоматизировать их проектирование;
– легкость внесения дополнений и изменений;
– простота логического вывода.
Недостатки продукционных моделей:
– при большом количестве продукционных правил в базе знаний, изменение старого правила или добавления нового приводит к непредсказуемым побочным эффектам;
– затруднительна оценка целостного образа знаний, содержащего в системе.
3. Семантические сети[92]. Способ представления знаний с помощью сетевых моделей наиболее близок к тому, как они представлены в текстах на естественном языке. В его основе лежит идея о том, что вся необходимая информация может быть описана как совокупность троек: объекты или понятия и бинарное отношение между ними.
Наиболее общей сетевой моделью представления знаний являются семантические сети, в которых узлы и связи представляют собой объекты или понятия и их отношения, таким образом, что можно выяснить их значение. Это связано с тем, что в данной модели имеются средства реализации всех характерных для знаний свойств: внутренней интерпретации, стуктурированности, семантической метрики[93] и активности. Впервые понятие семантических сетей было введено в 60-х годах для представления семантических связей между концепциями слов.
Семантические сети применительно к задачам проектирования структуры баз данных экспертных систем используются в сравнительно узком диапазоне – для отражения структуры понятий и структуры событий. Они представляют собой модель, основой которой является формализация знаний в виде ориентированных графов с помеченными дугами, которая позволяют структурировать имеющуюся информацию и знания. Вершины графа соответствуют конкретным объектам, а дуги, их соединяющие, отражают имеющиеся между ними отношения. Построение сети способствует осмыслению информации и знаний, поскольку позволяет установить противоречивые ситуации, недостаточность имеющейся информации и т.п.
В семантических сетях, используются следующие отношения:
– лингвистические, включающие в себя отношения типа «объект», «агент», «условие», «место», «инструмент», «цель», «время» и др.;
– атрибутивные, к которым относят форму, размер, цвет и т.д.;
– характеризации глаголов, т. е. род, время, наклонение, залог, число;
– логические, обеспечивающие выполнение операций для исчисления высказываний (дизъюнкция, конъюнкция, импликация, отрицание);
– квантифицированные, т. е. использующие кванторы общности и существования;
– теоретико-множественные, включающие понятия «элемент множества», «подмножество», «супермножество» и др.
Различают:
– интенсиональную семантическую сеть, которая описывает предметную область на обобщенном, концептуальном уровне;
– экстенсиональную семантическую сеть, в которой производится конкретизация и наполнение фактическими данными.
Статические базы знаний, представленные с помощью семантических сетей, могут быть объектом действий, производимых активными процессами. Стандартные операции включают в себя процессы поиска и сопоставления, с помощью которых определяется, представлена ли в семантической модели (и где именно) специфическая информация.
Достоинство семантической сети:
– описание объектов и событий производится на уровне очень близком к естественному языку;
– обеспечивается возможность соединения различных фрагментов сети;
– отношения между понятиями и событиями образуют небольшое, хорошо организованное множество;
– для каждой операции над данными или знаниями можно выделить некоторый участок сети, который охватывает необходимые в данном запросе характеристики;
– обеспечивается наглядность системы знаний, представленной графически:
– близость структуры сети, представляющей знания, семантической структуре фраз на естественном языке;
– соответствие сети современным представлениям об организации долговременной памяти человека.
Недостатки семантической сети:
– сетевая модель не дает ясного представления о структуре предметной области, поэтому формирование и модификация такой модели затруднительны;
– сетевые модели представляют собой пассивные структуры, для обработки которых необходим специальный аппарат формального вывода и планирования.
Семантические сети нашли применение в основном в системах обработки естественного языка, частично в вопросно-ответных системах, а также в системах искусственного видения. В последних семантические сети используются для хранения знаний о структуре, форме и свойствах физических объектов. В области обработки естественного языка с помощью семантических сетей представляют семантические знания, знания о мире, эпизодические знания (т.е. знания о пространственно-временных событиях и состояниях).
Пример: Поставщик отгрузил товар из склада автотранспортом. На рис. 3.14. представлена интенсиональная семантическая модель, а на рис. 3.15. – экстенсиональная семантическая сеть. Факты обозначены овалом, понятия и объекты прямоугольником.
4. Фреймовые модели. Фреймы были впервые предложены в качестве аппарата для представления знаний М. Минским в 1975 г.Фреймовые модели представляют собой систематизированную в виде единой теории технологическую модель памяти человека и его сознания. Под фреймом понимают минимальные структуры информации, необходимые для представления класса объектов, явлений или процессов.
Фрейм можно представить в виде сети, состоящей из вершин и дуг (отношений), в которых нижние уровни фрейма заканчиваются слотами (переменными), которые заполняются конкретной информацией при вызове фрейма. Значением слота может быть любая информация: текст, числа, математические соотношения, программы, ссылки на другие фреймы. На заполнение слотов могут быть наложены ограничения, например цена не может быть отрицательной. Ниже приведены основные свойства фреймов.
– Наследование свойств. Все фреймы взаимосвязаны и образуют единую фреймовую структуру, поэтому достаточно просто производить композицию и декомпозицию информационных структур. Например: слот более низкого уровня указывает на слот более высокого уровня иерархии, откуда неявно наследуются (переносятся) значения аналогичных слотов, причем наследование свойств может быть частичным.
– Базовый тип. При эффективном использовании фреймовой системы, можно добиться быстрого понимания сущности данного предмета и его состояния, однако для запоминания различных позиций в виде фреймов необходимы большие объемы памяти. Поэтому только наиболее важные объекты данного предмета запоминаются в виде базовых фреймов, на основании которых строятся фреймы для новых состояний. При этом каждый фрейм содержит слот, оснащенный указателем подструктуры, который позволяет различным фреймам совместно использовать одинаковые части.
– Процесс сопоставления – процесс, в ходе которого проверяется правильность выбора фрейма, осуществляется в соответствии с текущей целью и информацией, содержащийся в данном фрейме. Фрейм содержит условия, ограничивающие значения слота, а цель используется для определения, какое из этих условий, имея отношение к данной ситуации, является существенным.
– Иерархическая структура, особенность которой заключается в том, что информация об атрибутах, которую содержит фрейм верхнего уровня, совместно используются всеми связанными с ним фреймами нижних уровней.
– Сети фреймов. Поиск фрейма, подобного предыдущему, осуществляется с использованием указателей различия. Поиск возможен благодаря соединению фреймов, описывающих объекты с небольшими различиями, с данными указателями и образованию сети подобных фреймов.
– Отношения «абстрактное – конкретное» и «целое – часть». Иерархическая структура фреймов основывается на отношениях «абстрактное – конкретное». На верхних уровнях расположены абстрактные объекты, на нижних уровнях – конкретные объекты. Объекты нижних уровней наследуют атрибуты объектов верхних уровней. Отношение «целое – часть» касается структурированных объектов и показывает, что объект нижнего уровня является частью объекта верхнего уровня. Наибольшее практическое применение получили отношения «абстрактное – конкретное».
Схема фрейма приведена на рис. 3.16. Теория фреймов послужила толчком к разработке языков представления знаний. Например, концепция объектно-ориентированного программирования в традиционных языках программирования использует понятия, близкие к фрейму. Модели фреймов имеют следующие достоинства:
– способность отображать концептуальную основу организации памяти человека;
– естественность и наглядность представления, модульность;
– поддержку возможности использования значений слотов по умолчанию.
– универсальность, так как позволяют отобразить все многообразие знаний.

В отличие от моделей других типов во фреймовых моделях более жесткая структура, которая называется протофреймом. Основной недостаток: отсутствие механизмов управления выводом, который частично устраняется при помощи присоединенных процедур, реализуемый силами пользователя системы.
В системах искусственного интеллекта могут использоваться одновременно несколько моделей представления знаний. Например, фрейм можно рассматривать как фрагмент семантической сети, предназначенной для описания объекта (ситуации) проблемной области со всей совокупностью присущих ему свойств. Значением некоторых слотов фрейма может быть продукция. В продукционных моделях используются некоторые элементы логических и сетевых моделей. Поэтому появляется возможность организовывать эффективные процедуры вывода и наглядное отображение знаний в виде сетей; отсутствие жестких ограничений позволяет изменять интерпретацию элементов продукции.
5. Нейронные сети. В настоящее время сформировалось новое научно-практическое направление – создание нейрокомпьютера, ЭВМ нового поколения, который способен к самоорганизации, обучению и имитирует некоторые способности человеческого мозга по обработке информации. Результатами явились представления знаний, основанные на массированной параллельной обработке, быстром поиске больших объемов информации и способности распознавать образцы. Технологии, направленные на достижение этих результатов относятся к нейронным вычислениям или искусственным нейронным сетям.
65. Экспертные системы (эс): определение, структура, назначение основных блоков, примеры применения
Экспертные системы
это направление исследований в области искусственного интеллекта по созданию вычислительных систем, умеющих принимать решения, схожие с решениями экспертов в заданной предметной области.
1. Назначение экспертных систем
Для ознакомления с таким новым для нас понятием, как экспертные системы мы, для начала, пройдемся по истории создания и разработки направления «экспертные системы», а потом определим и само понятие экспертных систем.
В начале 80-х гг. XX в. в исследованиях по созданию искусственного интеллекта сформировалось новое самостоятельное направление, получившее название экспертных систем. Цель этих новых исследований по экспертным системам состоит в разработке специальных программ, предназначенных для решения особых видов задач. Что это за особый вид задач, потребовавший создания целой новой инженерии знаний? К этому особому виду задач могут быть отнесены задачи из абсолютно любой предметной области. Главное, что отличает их от задач обычных, – это то, что человеку-эксперту решить их представляется очень сложным заданием. Тогда и была разработана первая так называемая экспертная система (где в роли эксперта выступал уже не человек, а машина), причем экспертная система получает результаты, не уступающие по качеству и эффективности решениям, получаемым обычным человеком – экспертом. Результаты работы экспертных систем могут быть объяснены пользователю на очень высоком уровне. Данное качество экспертных систем обеспечивается их способностью рассуждать о собственных знаниях и выводах. Экспертные системы вполне могут пополнять собственные знания в процессе взаимодействия с экспертом. Таким образом, их можно с полной уверенностью ставить в один ряд с вполне оформившимся искусственным интеллектом.
Исследователи в области экспертных систем для названия своей дисциплины часто используют также уже упоминавшийся ранее термин «инженерия знаний», введенный немецким ученым Е. Фейгенбаумом как «привнесение принципов и инструментария исследований из области искусственного интеллекта в решение трудных прикладных проблем, требующих знаний экспертов».
Однако коммерческие успехи к фирмам-разработчикам пришла не сразу. На протяжении четверти века в период с 1960 по 1985 гг. успехи искусственного интеллекта касались в основном исследовательских разработок. Тем не менее, начиная примерно с 1985 г., а в массовом масштабе с 1987 по 1990 гг. экспертные системы стали активно использоваться в коммерческих приложениях.
Заслуги экспертных систем довольно велики и состоят в следующем:
1) технология экспертных систем существенно расширяет круг практически значимых задач, решаемых на персональных компьютерах, решение которых приносит значительный экономический эффект и существенно упрощает все связанные с ними процессы;
2) технология экспертных систем является одним из самых важных средств в решении глобальных проблем традиционного программирования, таких как продолжительность, качество и, следовательно, высокая стоимость разработки сложных приложений, вследствие которой значительно снижался экономический эффект;
3) имеется высокая стоимость эксплуатации и обслуживания сложных систем, которая зачастую в несколько раз превосходит стоимость самой разработки, а также низкий уровень повторной используемости программ и т. п.;
4) объединение технологии экспертных систем с технологией традиционного программирования добавляет новые качества к программным продуктам за счет, во-первых, обеспечения динамичной модификации приложений рядовым пользователем, а не программистом; во-вторых, большей «прозрачности» приложения, лучшей графики, интерфейса и взаимодействия экспертных систем.
По мнению рядовых пользователей и ведущих специалистов, в недалекой перспективе экспертные системы найдут следующее применение:
1) экспертные системы будут играть ведущую роль на всех стадиях проектирования, разработки, производства, распределения, отладки, контроля и оказания услуг;
2) технология экспертных систем, получившая широкое коммерческое распространение, обеспечит революционный прорыв в интеграции приложений из готовых интеллектуально-взаимодействующих модулей.
В общем случае экспертные системы предназначены для так называемыхнеформализованных задач, т. е. экспертные системы не отвергают и не заменяют традиционного подхода к разработке программ, ориентированного на решение формализованных задач, но дополняют их, тем самым значительно расширяя возможности. Именно этого и не может сделать простой человек-эксперт.
Такие сложные неформализованные задачи характеризуются:
1) ошибочностью, неточностью, неоднозначностью, а также неполнотой и противоречивостью исходных данных;
2) ошибочностью, неоднозначностью, неточностью, неполнотой и противоречивостью знаний о проблемной области и решаемой задаче;
3) большой размерностью пространства решений конкретной задачи;
4) динамической изменчивостью данных и знаний непосредственно в процессе решения такой неформализованной задачи.
Экспертные системы главным образом основаны на эвристическом поиске решения, а не на исполнении известного алгоритма. В этом одно из главных преимуществ технологии экспертных систем перед традиционным подходом к разработке программ. Именно это и позволяет им так хорошо справляться с поставленными перед ними задачами.
Технология экспертных систем используется для решения самых различных задач. Перечислим основные из подобных задач.
1. Интерпретация.
Экспертные системы, выполняющие интерпретацию, чаще всего применяют показания различных приборов с целью описания положения дел.
Интерпретирующие экспертные системы способны обрабатывать самые различные виды информации. Примером может послужить использование данных спектрального анализа и изменения характеристик веществ для определения их состава и свойств. Также примером может служить интерпретация показаний измерительных приборов в котельной для описания состояния котлов и воды в них.
Интерпретирующие системы чаще всего имеют дело непосредственно с показаниями. В связи с этим возникают затруднения, которых нет у других видов систем. Что это за затруднения? Эти затруднения возникают из-за того, что экспертным системам приходится интерпретировать засоренную лишним, неполную, ненадежную или неверную информацию. Отсюда неизбежны либо ошибки, либо значительное увеличение обработки данных.
2. Прогнозирование.
Экспертные системы, осуществляющие прогноз чего-либо, определяют вероятностные условия заданных ситуаций. Примерами служат прогноз ущерба, причиненного урожаю хлебов неблагоприятными погодными условиями, оценивание спроса на газ на мировом рынке, прогнозирование погоды по данным метеорологических станций. Системы прогнозирования иногда применяют моделирование, т. е. такие программы, которые отображают некоторые взаимосвязи в реальном мире, чтобы воссоздать их в среде программирования, и потом спроектировать ситуации, которые могут возникнуть при тех или иных исходных данных.
3. Диагностика различных приборов.
Экспертные системы производят такую диагностику, применяя описания какой-либо ситуации, поведения или данных о строении различных компонентов, чтобы определить возможные причины неисправно работающей диагностируемой системы. Примерами служат установление обстоятельств заболевания по симптомам, которые наблюдаются у больных (в медицине); определение неисправностей в электронных схемах и определение неисправных компонентов в механизмах различных приборов. Системы диагностики довольно часто являются помощниками, которые не только ставят диагноз, но и помогают в устранении неполадок. В таких случаях данные системы вполне могут взаимодействовать с пользователем, чтобы оказать помощь при поиске неполадок, а потом привести список действий, необходимых для их устранения. В настоящее время многие диагностические системы разрабатываются в качестве приложений к инженерному делу и компьютерным системам.
4. Планирование различных событий.
Экспертные системы, предназначенные для планирования, проектируют различные операции. Системы предопределяют практически полную последовательность действий, прежде чем начнется их реализация.
Примерами такого планирования событий могут служить создания планов военных действий как оборонительного, так и наступательного характера, предопределенного на определенный срок с целью получения преимущества перед вражескими силами.
5. Проектирование.
Экспертные системы, выполняющие проектирование, разрабатывают различные формы объектов, учитывая сложившиеся обстоятельства и все сопутствующие факторы.
В качестве примера можно рассмотреть генную инженерию.
6. Контроль.
Экспертные системы, осуществляющие контроль, сравнивают настоящее поведение системы с ее ожидаемым поведением. Наблюдающие экспертные системы обнаруживают контролируемое поведение, которое подтверждает их ожидания по сравнению с нормальным поведением или их предположением о потенциальных отклонениях. Контролирующие экспертные системы по своей сути должны работать в режиме реального времени и реализовывать зависящую как от времени, так и от контекста интерпретацию поведения контролируемого объекта.
В качестве примера можно привести слежение за показаниями измерительных приборов в атомных реакторах с целью обнаружения аварийных ситуаций или оценку данных диагностики пациентов, находящихся в блоке интенсивного лечения.
7. Управление.
Ведь широко известно, что экспертные системы, осуществляющие управление, весьма результативно руководят поведением системы в целом. Примером служит управление различными производствами, а также распределением компьютерных систем. Управляющие экспертные системы должны включать в себя наблюдающие компоненты, для того, чтобы контролировать поведение объекта на протяжении длительного времени, но они могут нуждаться и в других компонентах из уже проанализированных типов задач.
Экспертные системы применяются в самых различных областях: финансовых операциях, нефтяной и газовой промышленности. Технология экспертных систем может быть применена также в энергетике, транспортном хозяйстве, фармацевтическом производстве, космических разработках, металлургической и горной промышленностях, химии и многих других областях.
2. Структура экспертных систем
Разработка экспертных систем имеет ряд существенных отличий от разработки обычного программного продукта. Опыт создания экспертных систем показал, что использование при их разработке методологии, принятой в традиционном программировании, либо сильно увеличивает количество времени, затраченного на создание экспертных систем, либо вовсе приводит к отрицательному результату.
Экспертные системы в общем случае подразделяются на статические и динамические.
Для начала рассмотрим статическую экспертную систему.
Стандартная статическая экспертная система состоит из следующих основных компонентов:
1) рабочей памяти, называемой также базой данных;
2) базы знаний;
3) решателя, называемого также интерпретатором;
4) компонентов приобретения знаний;
5) объяснительного компонента;
6) диалогового компонента.
Рассмотрим теперь каждый компонент более подробно.
Рабочая память (по абсолютной аналогии с рабочей, т. е. оперативной памятью компьютера) предназначена для получения и хранения исходных и промежуточных данных решаемой в текущий момент задачи.
База знаний предназначена для хранения долгосрочных данных, описывающих конкретную предметную область, и правил, описывающих рациональное преобразование данных этой области решаемой задачи.
Решатель, называемый также интерпретатором, функционирует следующим образом: используя исходные данные из рабочей памяти и долгосрочные данные из базы знаний, он формирует правила, применение которых к исходным данным приводит к решению задачи. Одним словом, он действительно «решает» поставленную перед ним задачу;
Компонент приобретения знаний автоматизирует процесс заполнения экспертной системы знаниями эксперта, т. е. именно этот компонент обеспечивает базу знаний всей необходимой информацией из данной конкретной предметной области.
Компонент объяснений разъясняет, как система получила решение данной задачи, или почему она это решение не получила и какие знания она при этом использовала. Иначе говоря, компонент объяснений создает отчет о проделанной работе.
Данный компонент является очень важным во всей экспертной системе, поскольку он значительно облегчает тестирование системы экспертом, а также повышает доверие пользователя к полученному результату и, следовательно, ускоряет процесс разработок.
Диалоговый компонент служит для обеспечения дружественного интерфейса пользователя как в ходе решения задачи, так и в процессе приобретения знаний и объявления результатов работы.
Теперь, когда мы знаем, из каких компонент в общем состоит статистическая экспертная система, построим диаграмму, отражающую структуру такой экспертной системы. Она имеет следующий вид:
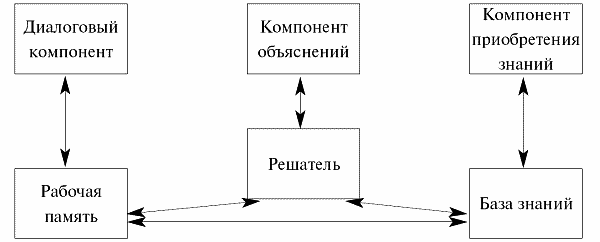
Статические экспертные системы чаще всего используются в технических приложениях, где можно не учитывать изменения окружающего среды, происходящие во время решения задачи. Любопытно знать, что первые экспертные системы, получившие практическое применение, были именно статическими.
Итак, на этом закончим пока рассмотрение статистической экспертной системы, перейдем к анализу экспертной системы динамической.
К сожалению, в программу нашего курса не входит подробное рассмотрение этой экспертной системы, поэтому ограничимся разбором только самых основных отличий динамической экспертной системы от статических.
В отличие от статической экспертной системы в структуру динамической экспертной системы дополнительно вводятся два следующих компонента:
1) подсистема моделирования внешнего мира;
2) подсистема связей с внешним окружением.
Подсистема связей с внешним окружением как раз и осуществляет связи с внешним миром. Делает она это посредством системы специальных датчиков и контроллеров.
Помимо этого, некоторые традиционные компоненты статической экспертной системы подвергаются существенным изменениям, для того чтобы отобразить временную логику событий, происходящих в данный момент в окружающей среде.
Это главное различие между статической и динамической экспертными системами.
Пример динамической экспертной системы – управление производством различных медикаментов в фармацевтической промышленности.
66. Продукционные экспертные системы (эс): структура, примеры применения
Продукционные системы
В настоящее время экспертными системами наиболее широко применяемого типа являются системы, основанные на правилах. В системах, основанных на правилах, знания представлены не с помощью относительно декларативного, статического способа (как ряд истинных утверждений), а в форме многочисленных правил, которые указывают, какие заключения должны быть сделаны или не сделаны в различных ситуациях. Система, основанная на правилах, состоит из правил IF-THEN, фактов и интерпретатора, который управляет тем, какое правило должно быть вызвано в зависимости от наличия фактов в рабочей памяти.
Системы, основанные на правилах, относятся к двум главным разновидностям: системы с прямым логическим выводом и системы с обратным логическим выводом.
Система с прямым логическим выводом начинает свою работу с известных начальных фактов и продолжает работу, используя правила для вывода новых заключений или выполнения определённых действий. Система с обратным логическим выводом начинает свою работу с некоторой гипотезы, или цели, которую пользователь пытается доказать, и продолжает работу, отыскивая правила, которые позволят доказать истинность гипотезы. Для разбиения крупной задачи на мелкие фрагменты, которые можно будет более легко доказать, создаются новые подцели. Системы с прямым логическим выводом в основном являются управляемыми данными, а системы с обратным логическим выводом - управляемыми целями.
Широкое применение систем, основанных на правилах, обусловлено описанными ниже причинами.
Модульная организация. Благодаря такой организации упрощается представление знаний и расширениеэкспертной системы.
Наличие средств объяснения. Такие экспертные системы позволяют легко создавать средства объяснения с помощью правил, поскольку антецеденты правила точно указывают, что необходимо для активизации правила. Средство объяснения позволяет следить за тем, запуск каких правил был осуществлён, поэтому даёт возможность восстановить ход рассуждений, которые привели к определённому заключению.
Наличие аналогии с познавательным процессом человека. Согласно результатам, полученным Ньюэллом и Саймоном, правила представляют собой естественный способ моделирования процесса решения задач человеком. А при осуществлении попытки выявить знания, которыми обладают эксперты, проще объяснить экспертам структуру представления знаний, поскольку применяется простое представление правил IF-THEN.
Продукционные системы Поста
Продукционные системы были впервые использованы в символической логике Постом (Post), поэтому имя этого учёного вошло в название указанных систем. Пост доказал такой важный и неожиданный результат, что любая система математики или логики может быть оформлена в виде системы продукционных правил определённого типа. Этот результат показал огромные возможности применения продукционных правил для представления важных классов знаний, а это означает, что продукционные правила не сводятся к нескольким ограниченным типам. Кроме того, продукционные правила, обозначаемые термином правила подстановки, используются также в лингвистике как способ определения грамматики языка. Компьютерные языки обычно определяются с помощью формы продукционных правил, известной как нормальная форма Бэкуса-Наура (Backus-Naur Form — BNF. Основная идея Поста заключалась в том, что любая математическая или логическая система представляет собой набор правил, который указывает, как преобразовать одну строку символов в другой последовательный набор символов. Это означает, что продукционное правило после получения входной строки (антецедента) способно выработать новую строку (консеквент). Такая идея является также действительной по отношению к программам и экспертным системам, в которых начальная строка символов представляет собой входные данные, а выходная строка становится результатом определённых преобразований, которым были подвергнуты входные данные.
В качестве очень простого случая можно представить себе, что если входной строкой является "у пациента имеется высокая температура", то выходной строкой может быть "пациент должен принять аспирин". За этими строками не закреплён какой-либо смысл. Иными словами, манипуляции со строками основаны на синтаксисе, а не на семантике, т.е. не на понимании того, что скрывается за словами "высокая температура", "аспирин" и "пациент". Люди знают, что означают эти строки в реальном мире, а продукционная система Поста применяется лишь в качестве способа преобразования одной строки в другую. Для данного примера может быть предусмотрено следующее продукционное правило:
антецедент —> консеквент
у пациента имеется высокая температура —> пациент должен принять аспирин
В этом правиле стрелка означает, что одна строка должна быть преобразована в другую. Указанное правило можно интерпретировать с помощью более знакомой системы обозначений IF-THEN следующим образом:
IF у пациента имеется высокая температура THEN пациент должен принять аспирин.
Rete – алгоритм
Если требуется создать экспертную систему для решения реальных задач, содержащую сотни или тысячи правил, то проблема эффективности приобретает наибольшую важность. Независимо от того, насколько приемлемыми являются все прочие характеристики системы, если пользователю придётся долго ожидать ответа, то он не станет работать с такой системой. Поэтому фактически требуется алгоритм, который имеет полную информацию обо всех правилах и может применить любое нужное правило, не предпринимая попытки последовательно проверять каждое правило.
Решением этой проблемы является rete-алгоритм, разработанный Чарльзом Л. Форги (Charles L. Forgy) в университете Карнеги-Меллона в 1979 году в рамках диссертации по командному интерпретатору экспертной системы OPS (Official Production System — стандартная продукционная система) на получение степени доктора философии. Термин rete - алгоритм происходит от латинского слова rete (по-английски читается "рити", а по-русски — "реете"), которое означает сеть. Rete-алгоритм функционирует как сеть, которая предназначена для хранения большого объёма информации и обеспечивает значительное сокращение времени отклика. Кроме того, он обеспечивает повышение быстродействия при запуске правил по сравнению с большими группами правил IF-THEN, которые должны проверяться один за другим в обычной системе, основанной на правилах. Rete-алгоритм основан на использовании динамической структуры данных, подобной стандартному дереву В+, которая автоматически реорганизуется в целях оптимизации поиска.
Rete-алгоритм представляет собой очень быстрое средство сопоставления с шаблонами, высокое быстродействие которого достигается благодаря хранению в оперативной памяти информации о правилах, находящихся в сети. Этот алгоритм предназначен для повышения быстродействия систем с прямым логическим выводом, основанных на правилах, благодаря ограничению объёма работы, требуемой для повторного вычисления конфликтного множества после запуска одного из правил. Недостатком этого алгоритма являются его высокие потребности в памяти. Однако в наши дни, когда микросхемы памяти стали такими дешёвыми, этот недостаток не имеет большого значения. В rete - алгоритме воплощены два описанных ниже эмпирических наблюдения, на основании которых была предложена структура данных, лежащая в его основе.
Временная избыточность. Изменения, возникающие в результате запуска одного из правил, обычно затрагивают лишь несколько фактов, а каждое из этих изменений влияет только на несколько правил.
Структурное подобие. Один и тот же шаблон часто обнаруживается в левой части больше чем одного правила.
Если в системе заданы сотни или тысячи правил, то подход к организации работы, в котором компьютер последовательно проверяет вероятность того, должен ли быть выполнен запуск каждого правила, становится очень неэффективным. Благодаря разработке rete - алгоритма появилась практическая возможность создания инструментальных средств экспертных систем даже на тех медленных компьютерах, которые применялись в 1970-х годах. В наши дни rete - алгоритм продолжает оставаться важным средством повышения быстродействия в тех случаях, когда экспертная система содержит много правил.
В rete - алгоритме в каждом цикле контролируются только изменения в согласованиях, поэтому в каждом цикле "распознавание - действие" не приходится согласовывать факты с каждым правилом. Благодаря этому существенно повышается скорость согласования фактов с антецедентами, поскольку статические данные, которые не изменяются от цикла к циклу, могут быть проигнорированы.
На рис.11.19 показаны технологии, которые образуют фундамент современных экспертных систем, основанных на правилах.

Рис. 11.19. Современные экспертные системы, основанные на правилах
Пример разработки экспертной системы
Рассмотрим на конкретном примере организацию взаимодействия пользователя с экспертной системой. Предметная область этой экспертной системы– продажи бухгалтерских и правовых систем (режим диалога с пользователем для правильного выбора программного обеспечения). Предположим, что фрагмент базы знаний содержит следующий набор правил:
ЕСЛИ класс – бухгалтерские программы
И форма конфигурирования системы должна быть жёсткой (пользователь не будет иметь возможности сам конфигурировать какие-либо входные или выходные документы)
ТО лучше всего подходит бухгалтерская программа 1С версия 6.0.
ЕСЛИ класс – бухгалтерские программы
И форма конфигурирования системы должна быть лояльной (т.е. пользователь может сам конфигурировать какие-либо входные или выходные документы)
И программа разработана под оболочку DOS.
ТО лучше всего подходит система бухгалтерских программ "Бест".
ЕСЛИ класс – бухгалтерские программы
И форма конфигурирования системы должна быть лояльной (т.е. пользователь может сам конфигурировать какие-либо входные или выходные документы)
И программа разработана под оболочку Windows95.
И программа одноуровневая.
ТО лучше всего подходит бухгалтерская программа "Инфо Бухгалтер".
ЕСЛИ класс – бухгалтерские программы
И форма конфигурирования системы должна быть лояльной (т.е. пользователь может сам конфигурировать какие-либо входные или выходные документы).
И программа разработана под оболочку Windows95.
И программа не одноуровневая.
ТО лучше всего подходит система бухгалтерских программ "Турбо Бухгалтер".
ЕСЛИ тип – правовые системы
И пополнение информационной базы происходит еженедельно (минимум), посредством курьера
ТО лучше всего подходит правовая программа "Гарант".
ЕСЛИ тип – правовые системы
И пополнение информационной базы происходит ежемесячно (минимум), через покупку нового CD-ROM.
ТО лучше всего подходит правовая программа "Кодекс".
ЕСЛИ тип – правовые системы
И пополнение информационной базы происходит ежемесячно (минимум), через покупку нового CD-ROM или еженедельно (минимум), посредством курьера
ТО лучше всего подходит правовая программа "Эталон".
ЕСЛИ тип – складские программы
И форма конфигурирования системы должна быть жёсткой (пользователь не будет иметь возможности сам конфигурировать какие-либо входные или выходные документы)
ТО лучше всего подходит правовая складская программа "Фолио".
ЕСЛИ тип – складские программы.
И форма конфигурирования системы должна быть лояльной (т.е. пользователь может сам конфигурировать какие-либо входные или выходные документы)
ТО лучше всего подходит правовая программа склад "1С версия 7.5".
Предположим, что перед пользователем стоит задача: узнать, какое обеспечение из широкого спектра предлагаемого сейчас программного обеспечения ему наиболее подойдет, учитывая специфику ПК, на который предполагается установить это ПО. С помощью некоторых базовых правил фирмы "Элком-Информ" составлена некоторая экспертная система, которая поможет пользователю в его нелёгком выборе. Сеанс диалога может иметь следующий вид:
ЭС: Какое программное обеспечение вы хотели бы приобрести? (правовое, бухгалтерское, складское).
Пользователь: Бухгалтерское
ЭС: Форма конфигурирования системы должна быть жёсткой (пользователь не будет иметь возможности сам конфигурировать какие-либо входные или выходные документы)? (да, нет).
Пользователь: Нет.
ЭС: Форма конфигурирования системы должна быть лояльной (т.е. пользователь может сам конфигурировать какие-либо входные или выходные документы)?
Пользователь: Да
ЭС: Программа должна быть разработана под оболочку Windows95?
Пользователь: Да.
ЭС: Программа должна быть одноуровневая? (да, нет).
Пользователь: Нет.
ЭС: Программа должна быть не одноуровневая?
Пользователь: Да
ЭС: Лучше всего для вас подходит система бухгалтерских программ "Турбо Бухгалтер".
Если пользователь заинтересуется, почему сделаны такие выводы, то экспертная система выдаст эти правила и укажет соответствие между ответами пользователя, правилами и ответом экспертной системы.
Правила типа "если – то" для представления знаний
В качестве кандидата на использование в экспертной системе можно рассматривать, в принципе, любой непротиворечивый формализм, в рамках которого можно описывать знания о некоторой проблемной области. Однако самым популярным формальным языком представления знаний является язык правил типа "если – то" (или кратко: "если – то" - правил), называемых также продукциями. Каждое такое правило есть, вообще говоря, некоторое условное утверждение, но возможны и различные другие интерпретации. Вот примеры:
если предварительное условие P, то заключение (вывод) C;
если ситуация S, то действие A;
если выполнены условия C1 и C2, то не выполнено условие C.
"Если – то" - правила обычно оказываются весьма естественным выразительным средством представления знаний. Кроме того, они обладают следующими привлекательными свойствами:
Модульность: каждое правило описывает небольшой, относительно независимый фрагмент знаний.
Возможность инкрементного наращивания: добавление новых правил в базу знаний происходит относительно независимо от других правил.
Удобство модификации (как следствие модульности): старые правила можно изменять и заменять на новые относительно независимо от других правил.
Применение правил способствует "прозрачности системы".
Последнее свойство - это важное, относительное свойство экспертных систем. Под прозрачностью понимается способность системы к объяснению принятых решений и полученных результатов. Применение "если – то" - правил облегчает получение ответов на следующие основные типы вопросов пользователя:
Вопросы типа "как": Как вы пришли к этому выводу?
Вопросы типа "почему": Почему вас интересует эта информация?
"Если – то" - правила часто применяют для определения логических отношений между понятиями предметной области. Про чисто логические отношения можно сказать, что они принадлежат к "категорическим знаниям", "категорическим" - потому, что соответствующие утверждения всегда абсолютно верны. Однако в некоторых предметных областях преобладают "мягкие" или вероятностные знания. Эти знания являются "мягкими" в том смысле, что говорить об их применимости к любым практическим ситуациям можно только до некоторой степени ("часто, но не всегда"). В таких случаях используют модифицированные "если – то" - правила, дополняя их логическую интерпретацию вероятностной оценкой. Например:
если условие A, то заключение B с уверенностью F
Вообще говоря, если вы хотите разработать серьёзную экспертную систему для некоторой выбранной предметной области, то необходимо провести консультации с экспертами в этой области и многое узнать о ней самим. Достигнуть определённого понимания предметной области после общения с экспертами и чтения литературы, а затем облечь это понимание в форму представления знаний в рамках выбранного формального языка - искусство, называемое инженерией знаний. Как правило, это сложная задача, требующая больших усилий.
Преимущества экспертных систем
Как описано ниже, экспертные системы обладают многими привлекательными особенностями.
Повышенная доступность. Для обеспечения доступа к экспертным знаниям могут применяться любые подходящие компьютерные аппаратные средства. В определённом смысле вполне оправдано утверждение, что экспертная система - это средство массового производства экспертных знаний.
Уменьшенные издержки. Стоимость предоставления экспертных знаний в расчёте на отдельного пользователя существенно снижается.
Уменьшенная опасность. Экспертные системы могут использоваться в таких вариантах среды, которые могут оказаться опасными для человека.
Постоянство. Экспертные знания никуда не исчезают. В отличие от экспертов - людей, которые могут уйти на пенсию, уволиться с работы или умереть, знания экспертной системы сохраняются в течение неопределённо долгого времени.
Возможность получения экспертных знаний из многих источников. С помощью экспертных систем могут быть собраны знания многих экспертов и привлечены к работе над задачей, выполняемой одновременно и непрерывно, в любое время дня и ночи. Уровень экспертных знаний, скомбинированных путём объединения знаний нескольких экспертов, может превышать уровень знаний отдельно взятого эксперта-человека.
Повышенная надёжность. Применение экспертных систем позволяет повысить степень доверия к тому, что принято правильное решение, путём предоставления еще одного обоснованного мнения эксперту-человеку или посреднику при разрешении несогласованных мнений между несколькими экспертами - людьми. (Разумеется, такой метод разрешения несогласованных мнений не может использоваться, если экспертная система запрограммирована одним из экспертов, участвующих в столкновении мнений.) Решение экспертной системы должно всегда совпадать с решением эксперта; несовпадение может быть вызвано только ошибкой, допущенной экспертом, что может произойти, только если эксперт-человек устал или находится в состоянии стресса.
Объяснение. Экспертная система способна подробно объяснить свои рассуждения, которые привели к определённому заключению. А человек может оказаться слишком усталым, не склонным к объяснениям или неспособным делать это постоянно. Возможность получить объяснение способствует повышению доверия к тому, что было принято правильное решение.
Быстрый отклик. Для некоторых приложений может потребоваться быстрый отклик или отклик в реальном времени. В зависимости от используемого аппаратного и программного обеспечения экспертная система может реагировать быстрее и быть более готовой к работе, чем эксперт - человек. В некоторых экстремальных ситуациях может потребоваться более быстрая реакция, чем у человека; в таком случае приемлемым вариантом становится применение экспертной системы, действующей в реальном времени.
Неизменно правильный, лишенный эмоций и полный ответ при любых обстоятельствах. Такое свойство может оказаться очень важным в реальном времени и в экстремальных ситуациях, когда эксперт-человек может оказаться неспособным действовать с максимальной эффективностью из-за воздействия стресса или усталости.
Возможность применения в качестве интеллектуальной обучающей программы. Экспертная система может действовать в качестве интеллектуальной обучающей программы, передавая учащемуся на выполнение примеры программ и объясняя, на чём основаны рассуждения системы.
Возможность применения в качестве интеллектуальной базы данных.
Экспертные системы могут использоваться для доступа к базам данных с помощью интеллектуального способа доступа. В качестве примера можно привести анализ скрытых закономерностей в данных.
67. Нечеткие экспертные системы (эс): структура, назначение основных блоков, примеры
Нечеткая экспертная система - экспертная система, которая для вывода решения использует место Булевой логики совокупность нечетких функций принадлежности и правил. Правила в нечеткой экспертной системе имеют обычно вид, подобный следующему: Если x низок, и y высок, тогда z = средний,где x b y - входные переменные ( для которых известны значения ), z -выходная переменная ( значение, которое будет вычислено), низко - функция принадлежности (нечеткое подмножество) определенная на x, высоко - функция принадлежности, определенная на y, и среднее - функция принадлежности, определенная на z. Антецедент правила (предпосылка правила) описывает, когда правило применяется, в то время как заключение (следствие правила) назначает функцию принадлежности к каждому из выведенных значений переменных. Большинство инструментальных средств, работающих с нечеткими экспертными системами позволяют применять в правиле несколько заключений. Совокупность правил в нечеткой экспертной системе известна как база знаний. В общем случае вывод решения происходит за три (или четыре) шага.
1. С помощью функций ПРИНАДЛЕЖНОСТИ, определенных на входных переменных, вычисляются их фактические значения и определяется степень уверенности для каждой предпосылки правила. 2. Используя процедуру ВЫВОДА, вычисляется значение истинности для предпосылки каждого правила, которое применяется к заключению каждого правила. В результате этого каждой переменной вывода для каждого правила назначается одно значения из нечеткого подмножества значений. Обычно в качестве для вывода используется МИНИМИЗАЦИЯ или правила ПРОДУКЦИИ. При МИНИМИЗИРУЮЩЕМ логическом выводе , выходная функция принадлежности ограничена сверху в соответствии с вычисленной степенью истинности предпосылок (нечеткое логическое И). В логическом выводе с использованием ПРОДУКЦИЙ , выходная функция принадлежности масштабируется с помощью вычисленной степенью истинности предпосылки правила. 3. Используя КОМПОЗИЦИЮ, все нечеткие подмножества, назначенные для каждой выходной переменной объединяются вместе и формируется единственное нечеткое подмножество значение для каждой выводимой переменной .Наконец снова, обычно используются функции MAX или SUM . При использовании композиции MAX объединенное выходное нечеткое подмножество значений создается путем нахождения максимума из всех нечетких подмножеств, назначенных переменным в соответствии с правилом вывода (нечеткое логическое ИЛИ). В композиции SUM объединенное выходное нечеткое подмножество создается суммированием всех нечетких значений из подмножеств, назначенных для переменной вывода с помощью правил вывода. 4. Наконец - (необязательный) процесс точной интерпретации , который используется тогда, когда полезно преобразовывать нечеткий набор значений выводимых переменных к точным значениям. Имеется достаточно большое количество методов перехода к точным значениям (по крайней мере 30). Два из общих методов - это методы Полной интерпретации и по Максимуму.В методе полной интерпретации, точное значение выводимой переменной вычисляется как значение "центра тяжести" функции принадлежности для нечеткого значения. В методе Максимума в качестве точного значения выводимой переменной принимается максимальное значение функции принадлежности нечеткого соответствия.
Пример: : Предположм, что переменные x, y, и z имеют значения из интервала [0,10], и что определены следующие правила и функции принадлежности :
Низко (t) = 1 - (t / 10) Высоко (t) = t / 10 Правило 1: если x низок и y низок тогда z высок Правило 2: если x низок и y высок тогда z низок Правило 3: если x высок и y низок тогда z низок Правило 4: если x высок и y высок тогда z высок
Обратите внимание, что вместо назначения единственного значения выводимой переменной z, каждому правилу назначено нечеткое подмножество значений из множества(низко или высоко). Примечания:
1. В этом примере, низко (t) +high (t) =1.0 для всех t. Это общесправедливое утверждение . 2. Значение t, для которого низко (t) является максимальным то же самое, что и значение t, для которого высоко (t) является минимальным, и наоборот. 3. Для всех переменных используются одни и те же функции принадлежности . При решении задачи , функции принадлежности, определенные на входных переменных, применяются к их фактическим значениям и вычисляется степень истинности для каждой предпосылки правила. Степень истинности для предпосылок правила иногда обозначается как АЛЬФА. Если предпосылка правила имеет степень истинности, отличную от нуля, то говорят, что правило АКТИВИЗИРУЕТСЯ.
Например
X; |
y |
низко(x) |
высоко (x) |
низко (y) |
высоко (y) |
alpha1 |
alpha2 |
alpha3 |
alpha4 |
0.0 |
0.0 |
1.0 |
0.0 |
1.0 |
0.0 |
1.0 |
0.0 |
0.0 |
0.0 |
0.0 |
3.2 |
1.0 |
0.0 |
0.68 |
0.32 |
0.68 |
0.32 |
0.0 |
0.0 |
0.0 |
6.1 |
1.0 |
0.0 |
0.39 |
0.61 |
0.39 |
0.61 |
0.0 |
0.0 |
0.0 |
10.0 |
1.0 |
0.0 |
0.0 |
1.0 |
0.0 |
1.0 |
0.0 |
0.0 |
3.2 |
0.0 |
0.68 |
0.32 |
1.0 |
0.0 |
0.68 |
0.0 |
0.32 |
0.0 |
6.1 |
0.0 |
0.39 |
0.61 |
1.0 |
0.0 |
0.39 |
0.0 |
0.61 |
0.0 |
10.0 |
0.0 |
0.0 |
1.0 |
1.0 |
0.0 |
0.0 |
0.0 |
1.0 |
0.0 |
3.2 |
3.1 |
0.68 |
0.32 |
0.69 |
0.31 |
0.68 |
0.31 |
0.32 |
0.31 |
3.2 |
3.3 |
0.68 |
0.32 |
0.67 |
0.33 |
0.67 |
0.33 |
0.32 |
0.32 |
10.0 |
10.0 |
0.0 |
1.0 |
0.0 |
1.0 |
0.0 |
0.0 |
0.0 |
1.0 |
В процессе вывода вычисляется значение истинности для предпосылок каждого правила и применяется заключение каждого правила. Это приводит к тому, что каждой выводимой переменной в каждом правиле назначается одно значение из нечеткого подмножества значений. Минимизация и Правила продукции - два МЕТОДА ВЫВОДА или ПРАВИЛА ВЫВОДА. При минимизирующем логическом выводе, функция принадлежности вывода ограничена сверху значением вычисленной степени истинности для предпосылки правила. Это соответствует традиционной интерпретации операции нечеткого логического И. В логическом выводе с использованием правил продукции функция принадлежности вывода масштабируется вычисленной степенью истинности предпосылки правила. Например, рассмотрим правило 1 для значений x = 0.0 и y = 3.2. Как показано в таблице , степень истинности предпосылки равна 0.68. Для этого правила, при использовании минимизирующего логического вывода, z получит значение из нечеткого подмножества значений, определенное функцией принадлежности: Rule1 (z) = {z / 10, если z < = 6.8 0.68, если z> = 6.8} Для тех же самых условий, логический вывод с использованием правил продукции назначит z значение из нечеткого подмножества значений, определенной функцией принадлежности: : Rule1 (z) = 0.68 * высоко (z) = 0.068 * z Заметьте, что терминология, использованная здесь, является слегка нестандартной. В большинстве статей, термин " метод вывода " используется для обозначения комбинации действий, упомянутых здесь как "вывод" и "композиция". Таким образом вы сможете встретить в литературе такие термины как вывод " MinMax " и вывод "Product - Sum " Они - комбинация композиции MAX и Минимизирующего вывода, или композиция SUM и Правил Продукций соответственно. Опишем два процесса отдельно. В процессе композиции все нечеткие подмножества значений, полученные для каждой выводимой переменной, объединяются для формирования единственного нечеткого подмножества для каждой выводимой переменной. Композиция MAX и композиция Sum - два ПРАВИЛА КОМПОЗИЦИИ . При использовании композиции MAX, объединенное выходное нечеткое подмножество создается взятием максимумального значения по всем нечетким подмножествам значений, полученных для выводимой переменной в соответствии с правилом вывода. При использовании композиции SUM, объединенное выходное нечеткое подмножество значений создается взятием суммы по всем значениям из нечетких подмножеств, полученным для выводимой переменной согласно правилу вывода.Заметьте, что может получиться более чем одно значение ! По этой причине, композиция SUM используется только тогда, когда она сопровождается методом точной интерпретации типа метода Полной интерпретации, который не имеет проблем с таким случаем. Иначе композиция Sum может быть объединена c нормализацией, что снова приводит к универсальному методу. Например, пусть x = 0.0 и y = 3.2. МИНИМУМИЗИРУЮЩИЙ логический вывод назначил бы для z следующие значения из четырех нечетких подмножеств:
Rule1 (z) = {z / 10, если z <= 6.8
0.68, если z> = 6.8}
Rule2 (z) = {0.32, если z <= 6.8
1 - z / 10, если z> = 6.8}
Rule3 (z) = 0.0 Rule4 (z) = 0.0
Композиция MAX привела бы к такому нечеткому подмножеству:
Нечеткий (z) = {0.32, если z <= 3.2 Z / 10, если 3.2 < = z < = 6.8 0.68, если z> = 6.8}
Логический вывод согласно правилам продукции назначил бы для z следующие значения из четырех нечетких подмножеств:
Rule1 (z) = 0.068 * z Rule2 (z) = 0.32 - 0.032 * z Rule3 (z) = 0.0 Rule4 (z) = 0.0
Композиция SUM привела бы к нечеткому подмножеству:
нечеткий(z) = 0.32+ 0.036 * z
Иногда полезно только исследовать нечеткие подмножества, которые являются результатом композиционного процесса, но более часто это НЕЧЕТКОЕ ЗНАЧЕНИЕ необходимо преобразовать к единственному ТОЧНОМУ ЗНАЧЕНИЮ. Именно это выполняет процесс точной интерпретации. Два наиболее общих метода -это метод полной интерпретации и интерпретация по максимуму функции принадлежности. В методе полной интерпретации, точное значение выводимой переменной вычисляется как значение "центра тяжести" функции принадлежности для нечеткого значения. В методе Максимума в качестве точного значения выводимой переменной принимается максимальное значение функции принадлежности нечеткого соответствия. Имеется несколько вариаций метода максимума , которые отличаются тем, что они делают, когда имеется более чем одно значение переменной, в котором достигается максимальное значение функции принадлежности. Один из них возвращает среднее из значений переменных, для в которых достигается максимальное значение функции принадлежности.
Например, вернемся к нашему предыдущему примеру. Использование MaxMin логического вывода и метода, определяющего " среднее значение из максимумов " вычисляет точное значение z = 8.4. Использование логического вывода Sum- Product и метода точной интерпретации приводит к точному значение z, равному 5.6 . Вычисления выполнялись следующим образом. Как было сказано, все переменные (включая z) имеют значения в диапазоне [0, 10]. Вычислять центр тяжести функции f (x), это значит разделить момент функции на площадь функции. Вычислить момент f (x), это значит вычислить интеграл x*f (x) dx, а вычислить площадь f (x), это значит вычислить интеграл f (x) dx. В нашем случае, мы должны были вычислить площадь как интеграл от функции (0.32+0.036*z) в диапазоне от 0 до 10 dz, который равен ( 0.32 * 10 + 0.018*100) =( 3.2 + 1.8) =5.0, а момент функции равен интегралу из (0.32*z+0.036*z*z) dz в диапзоне от 0 до 10 , или ( 0.16 * 10 * 10 + 0.012 * 10 * 10 * 10) = ( 16 + 12) =28. Наконец, центр тяжести есть - 28/5 или 5.6.
Замечание: Иногда объединение композиции и процесса точного представления нечетких соответствий упрощает математические зависимости для вычисления окончательного результата значения переменной
68. Искусственные нейронные сети (инс): структура, классификация, основные классы решаемых задач
Основные классы задач, решаемых с помощью ИНС.
Классификация образов. Задача состоит в указании принадлежности входного образа (например, речевого сигнала или рукописного символа), представленного вектором значений признаков, одному или нескольким предварительно определенным классам образов. К известным приложениям относятся:
классификация пользователя и последующая адаптация диалога со стороны системы к его индивидуальным характеристикам, потребностям и правам (экспертные и диалоговые системы, системы защиты информации от несанкционированного доступа),
компьютерный контроль знаний и сертификация качества подготовки специалистов,
контроль успешности деятельности сотрудников предприятий,
распознавание символов и речи,
медицинская, техническая и психологическая диагностика,
распознавание видеоизображений и классификация различных сигналов и др.
Решение задачи классификации обычно требует предварительного формирования обучающей последовательности образов, каждый из которых отнесен учителем к одному из классов образов. На основе этой обучающей последовательности производится обучение (настройка) системы классификации. Этот режим называется обучением с поощрением (обучением “с учителем”).
Кластеризация / категоризация. При решении задачи кластеризации или автоматической классификации отсутствует обучающая последовательность образов с метками классов. Этот режим называется обучением без поощрения. Для его обозначения иногда используется методологически менее корректный термин «обучение без учителя». Алгоритмы кластеризации оперируют мерами сходства и различия отдельных образов и на этой основе осуществляют разбиение образов на группы (кластеры), в каждой (в каждом) из которых обьединяются естественно близкие образы. Методы автоматической классификации (кластеризации) широко используются для извлечения знаний (Data Mining), сжатия данных, медицинской и технической диагностики.
Аппроксимация функций. Предположим, что имеется обучающая последовательность образов [(x1, y1), (x2, y2), … , (xn, yn)] (пары данных вход-выход), которая генерируется неизвестной функцией f(x), причем результаты измерения искажены шумом. Задача аппроксимации состоит в нахождении оценки f*(x) этой неизвестной функции f(x).
Предсказание / прогноз. Пусть заданы n дискретных отсчетов {y(t1), y(t2), … , y(tn)} некоторой величины (например, курса акций некоторой компании, показателя инвалидности и т.п.) в последовательные моменты времени t1, t2, … , tn. Задача состоит в предсказании значения y(tn+1) в некоторый будущий момент времени tn+1. Предсказание цен на фондовой бирже и прогноз погоды - типичные применения теории предсказания/прогноза.
Оптимизация. Многочисленные проблемы в социальной сфере, науке, технике, медицине, экономике часто ставятся как проблемы оптимизации. Задача алгоритма оптимизации при этом состоит в определении такого решения, которое максимизирует или минимизирует некоторую целевую функцию при выполнении ряда ограничений (задачи математического программирования на условный экстремум). Задача коммивояжера, состоящая в определении кратчайшего пути, соединяющего ряд городов, является классическим примером таких оптимизационных задач.
Ассоциативная память или память, адресуемая по содержанию. В ЭВМ обращение к памяти часто осуществляется по адресу, который не зависит от содержимого соответствующей ячейки памяти. Ассоциативная память - это память, адресуемая по содержанию. Ассоциативная память чрезвычайно желательна при создании мультимедийных информационных баз данных.
Системы управления различными процессами и обьектами. ИНС применяются для моделирования обьектов управления и построения самих систем управления.
Математическая модель нейрона и функции активизации.
Модель формального нейрона МакКаллока и Питтса
МакКаллок и Питтс предложили использовать бинарный пороговый элемент в качестве модели формального нейрона (рис. 1.2.).
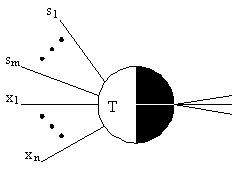
Рис. 1.2. Модель формального нейрона.
Нейрон имеет n возбуждающих входов x1, x2, ..., xn и m затормаживающих входов s1, s2, ..., sm. Если m ≥ 1 и хотя бы один из сигналов s1, s2, ..., sm равен 1, то нейрон считается «заторможенным» и результат на его выходе равен 0. Если тормозящие сигналы отсутствуют, то определяется взвешенная сумма n входных сигналов xj, j = 1,2, ..., n. Выход нейрона определяется на основе функцией активации или выхода в виде пороговой функции (Рис. 1.3.): если взвешенная сумма входов z превышает определенный порог T, то на выходе появляется 1, в противном случае случае - 0.

Рис. 1.3. Пороговая функция активизации или выхода формального нейрона.
С помощью такой модели нейрон может вычислить практически любую логическую функцию (кроме функции исключающего-ИЛИ, но ее можно вычислить путем соединения нескольких нейронов). Например нейрон на рис. 1.4. a может вычислить логическую функцию И (AND) трех аргументов, а нейрон на рис. 1.4. b - логическую функцию ИЛИ (OR) четырех аргументов.
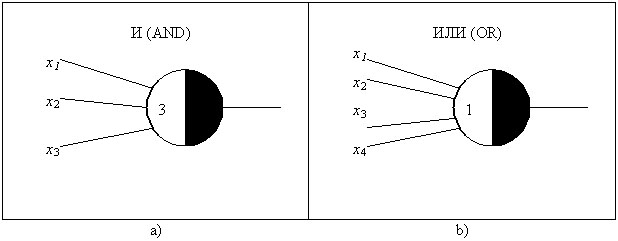
Рис. 1.4. Реализация функции И (AND) трех аргументов (a) функции ИЛИ (OR) четырех аргументов (b).
Часто удобно рассматривать порог Т как весовой коэффициент, связанный с дополнительным постоянным входом x0 = 1. Положительные веса соответствуют возбуждающим связям, а отрицательные - тормозящим. Формальный нейрон МакКаллока и Питтса моделирует некоторые свойства биологических нейронов. Так, веса связей соответствуют синапсам, а пороговая функция отражает активность сомы.
Можно получить простые нейроны и с более общими свойствами, если каждому входному сигналу (входу) сопоставить определенный вес. Пример такого нейрона приведен на Рис. 1.5.

Рис. 1.5. Простой нейрон с более общими свойствами.
Нейрон на рис. 1.5 вычисляет взвешенную сумму входов и сравнивает ее с порогом T. При превышении порога w1x1 + w2x2 +...+ wnxn ≥ T на выходе нейрона формируется единица. Покажем эквивалентность нейрона с взвешенными входами и нейрона МакКаллока-Питтса на простом примере: дан нейрон с взвешенными входами (рис. 1.6. a), вычисляющий: 0.2x1 + 0.4x2 + 0.3x3 ≥ 0.7. Он эквивалентен нейрону (рис. 1.6. b): 2x1 + 4x2 + 3x3 ≥ 7.

Рис. 1.6. Эквивалентность нейронов со взвешенными (a) и не взвешенными (b) входами.
В большинстве современных нейронных сетей используют именно нейроны со взвешенными входами.
Основная математическая модель формального нейрона
Рассмотрим сейчас математические соотношения для основной модели нейрона (рис. 1.7.).

Рис. 1.7. Математические соотношения для основной модели нейрона.
На рис. 1.7. представлен случай наличия лишь возбуждающих входов и отсутствия тормозящих входов si, i = 1, ..., m. Обозначим через x = (x1, ..., xn)' вектор значений признаков распознаваемого образа. Активность нейрона z можно представить в виде взвешенной суммы входов:
|
(1.1) |
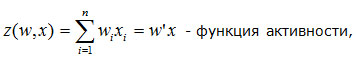
где w = (w1, w2, ..., wn)' - вектор весовых коэффициентов, а ' – знак транспонирования.
Очень часто для получения сигнала на выходе (аксоне) взвешенная сумма (активность) должна превышать значение некоторого порога (bias, threshold) T или
z(w, x) = w'х - Т |
(1.2) |
т.е. нейрон активен лишь в том случае, если взвешенная сумма его входов превышает порог T. Дополнительный член Т можно исключить путем использования расширенных векторов значений признаков и весовых коэффициентов с дополнительными нулевыми составляющими
х → х = (х0 = 1, х1, ..., хn)', w → w = (w0 = -T, w1, ..., wn)'. |
(1.3) |
Т.е. вводится дополнительный нулевой вход нейрона, на который подается +1 и который взвешивается с весовым коэффициентом w0 = -T. Этот дополнительный вход обозначают BIAS. С использованием расширенных векторов взвешенную сумму входов или активность нейрона можно представить так:
|
(1.4) |
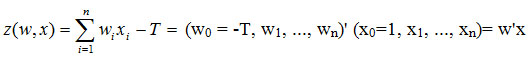
Выход у нейрона определяется функцией активации или выхода (activation function)
y = S(z), |
(1.5) |
которая в свою очередь определяется внутренней активностью z. Результирующую реакцию формального нейрона можно представить в виде результата лишь одной функции - функции преобразования нейрона:
y = S(z(w, x)) = A(w, x) |
(1.6) |
Теперь формальный нейрон можно определить подобно конечному автомату.
Определение: пусть заданы множества входов Х = {x}, выходов Y = {y} и состояний W = {w} нейрона. Формальный нейрон v можно представить в виде четверки (X, Y, A, L), где функции A и L – функции преобразования и перехода нейрона, определяемые в виде: А: W×X → Y; L: W×X×Y×Y → W.
На основе этого определения формального нейрона ИНС можно определить следующим образом: ИНС - это направленный граф G = (K, E), где K = {k} - множество узлов (нейронных элементов, формальных нейронов), а E⊆K×K - множество связей между нейронами. Связи между нейронами характеризуются весами, отражающими степень влияния передающих нейронов на принимающие нейроны.
Типичные функции активации или выхода, используемые в нейронах
Бинарная модель
В модели Мак-Каллока и Питтса для входов и выходов используются лишь бинарные величины (активировано/не активировано), а весовые коэффициенты принимают действительные значения. Для хi, y∈{0;1} и wi∈R функция активации или выхода принимает вид:
|
(1.6) |
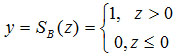
Это - функция единичного скачка (функция Хевисайда). Если использовать простые преобразования входов и выхода
хi → (2хi-1), y → (2y-1) |
(1.7) |
то для входов и выхода получаются значения –1 и +1. Функция активации или выхода является при этом знаковой функцией:
|
(1.8) |
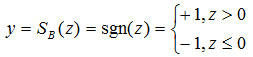
На Рис. 1.8 показаны оба варианта бинарной функции активации или выхода.
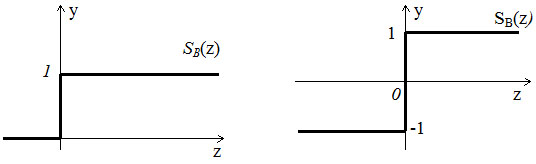
Рис. 1.8. Бинарные функции активации или выхода.
Линейная и ограниченно линейная функция активации или выхода
В случае линейной функции выхода имеем (рис. 1.9. a):
y = S(z) = z |
(1.9) |

Рис. 1.9. Линейная (a) и ограниченно линейная (b) функции активации или выхода.
Если выход симметричный, то можно использовать ограниченную линейную функцию выхода (рис. 1.9. b)
|
(1.10) |

На рис. 1.9. b представлен случай zmax = 1.
Сигмоидальная функция выхода
При использовании многих алгоритмов обучения используется не только значение функции активации или выхода, но и ее первой производной, причем эта производная должна быть непрерывной. Знание первой производной функции активации или выхода требуется, в частности, при применении алгоритма обучения с обратным распространением ошибок (Backpropagation), рассматриваемого ниже. Пороговая функция в них не применима, ибо в точке разрыва она не имеет производной. В этих случаях целесообразно использовать сигмоидальные функции. Один из примеров таких функций - известная из физики сигмоидальная функция Ферми:
|
(1.11) |
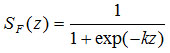
Она показана на рис 1.10.
Рис. 1.10. Сигмоидальная функция выхода.
Сигмоидальная функция выхода имеет верхний и нижний предел насыщения и графически отображается буквой S. В качестве функции активации или выхода часто применяются гиперболический тангенс Stanh(z) = (ex - e-x)/(ex + e-x) c диапазоном возможных значений от –1 до +1, а также функция колокола Гаусса: SG(z) = exp(- z2/σ2). Такую функцию активации или выхода имеют, в частности, нейроны скрытого слоя в нейросетях радиальных базисных функций.
На рис. 1.11. и 1.12. приведены примеры нейронов для ИНС.

Рис. 1.11. Пример нейрона для ИНС.

Рис. 1.12. Пример нейрона для ИНС.
На основе изложенного выше можно сделать следующие выводы:
"активация", аналог электрохимического потенциала живого нейрона, может быть выражена как:
-

(1.12)
обычно порог Т реализуется как дополнительный нулевой вход x0 = +1 с весовым коэффициентом w0 = -T (вход BIAS);
сумма входов, умноженных на веса, подается на вход нелинейной функции активации или выхода. Выход нейрона j: yj = S(zj);
нелинейность позволяет повысить моделирующую способность многослойной нейросети. При использовании процедуры обратного распространения ошибки для обучения нейросети эта нелинейная функция активации или выхода должна быть дифференцируемой, так как ее первая производная учитывается в алгоритме обучения. В качестве этой нелинейной функции активации или выхода нейрона часто используются сигмоидальные функции. Один из примеров – функция Ферми (1.11). Достоинством ее является автоматический контроль усиления: для слабых сигналов, когда величина z близка к нулю, кривая вход-выход имеет сильный наклон, что соответствует большому коэффициенту усиления. При увеличении z коэффициент усиления уменьшается.
1.4. Архитектуры искусственных нейронных сетей.
ИНС могут быть классифицированы по ряду признаков. Первый признак- наличие или отсутствие обратных связей. По нему ИНС могут быть сгруппированы в два класса:
сети прямого распространения сигналов без обратных связей (FeedForward-Netze или FF-Netze), в которых графы не имеют петель, и
рекуррентные сети или сети с обратными связями (Feedback-Netze или FB-Netze).
На рис. 1.13 приведены типичные примеры сетей прямого распространения информации и сетей с обратными связями.
Рис. 1.13. Классификация ИНС.
69. Сети Хопфилда: структура, способ определения весов связей между нейронами, классы решаемых задач, примеры
Среди различных архитектур искусственных нейронных сетей (ИНС) встречаются такие, которые по принципу настройки нельзя классифицировать ни как обучение с учителем, ни как обучение без учителя. В таких сетях весовые коэффициенты связей между нейронами рассчитываются перед началом их функционирования на основе информации об обрабатываемых образах, и все обучение сети сводится именно к этому расчету. С одной стороны, предъявление априорной информации можно расценивать как помощь учителя, но с другой – сеть фактически просто запоминает образы до того, как на ее вход поступают реальные данные, и не может изменять свое поведение. Из сетей с подобной логикой работы наиболее известна сеть Хопфилда, которая обычно используется для организации ассоциативной памяти.
Американский исследователь Хопфилд в 80-х годах предложил специальный тип нейросетей, названных в его честь. Они открыли новое направление в теории и практике нейросетей. Сети Хопфилда являются рекуррентными сетями или сетями с обратными связями (feedback networks) и были предназначены первоначально для решения следующей задачи. Имеется k образов (например, видеоизображений или фотоснимков), представленных, например, n-разрядными двоичными векторами. Задача нейросети состоит в запоминании и последующем распознавании этих k образов. Важно подчеркнуть, что распознаваемые образы при этом могут быть искажены или зашумлены.
Сети Хопфилда обладают рядом отличительных свойств:
симметрия дуг: сети содержат n нейронов, соединенных друг с другом. Каждая дуга (соединение) характеризуется весом wij , причем имеет место: ∀ i, j ∈ N : i ≠ j : ∃1wij где N = {1, 2, ..., n} – множество нейронов;
cимметрия весов: вес соединения нейрона ni с нейроном nj равен весу обратного соединения
-
wij = wji ; wii = 0;
(5.1)
бинарные входы: сеть Хопфилда обрабатывает бинарные входы {0,1} или {-1,1}. В литературе встречаются модели сетей как со значениями входов и выходов 0 и 1, так и –1, 1. Для структуры сети это безразлично. Однако формулы для распознавания образов (изображений) при использовании значений –1 и 1 для входов и выходов нейронов сети Хопфилда получаются нагляднее, поэтому эти значения и предполагаются ниже.
Определение. Бинарная сеть Хопфилда определяется симметричной матрицей W cвязей между нейронами с нулевыми диагональными элементами, вектором Т порогов нейронов и знаковой функцией активации или выхода нейронов. Каждый выходной вектор o (o от output) с компонентами –1 или 1, удовлетворяющий уравнению
o = S(Wo – T) , |
(5.2) |
называется образом для сети Хопфилда.
Принцип функционирования сетей Хопфилда отличается от ранее рассмотренных сетей. На так называемой recale-стадии на входы сети подается некоторый образ. Он оставляется на входах сети до тех пор, пока не завершатся изменения состояний сети. В этом случае говорят о сходимости сети.
Наглядно это можно представить следующим образом. В начале сеть находится на высоком энергетическом уровне, из которого возможны переходы в различные состояния. Затем энергетический уровень сети уменьшается до тех пор, пока не достигается некоторое конечное состояние, соответствующее в общем случае некоторому локальному минимуму. Ниже мы рассмотрим, как обучаются сети Хопфилда и как считывается (извлекается) запомненная в них информация.
Класс сетей Хопфилда содержит только один слой нейронов, причем каждый нейрон соединен с остальными. Обратные связи с выхода нейрона на его же вход отсутствуют. На рис. 5.1 приведен конкретный пример сети Хопфилда из четырех нейронов.
Рис. 5.1. Сеть Хопфилда из четырех нейронов.
На рис. 5.2 представлена структура сети Хопфилда общего вида, содержащая n нейронов.

Рис. 5.2. Структурная схема сети Хопфилда общего вида из n нейронов.
5.1. Алгоритм Хопфилда.
Обозначим через xs вектор значений признаков образа s-го класса, а через xsi – его i-ю составляющую. При этом алгоритм Хопфилда может быть описан следующим образом:
расчет весов связей между нейронами
-

(5.3)
где k – число запоминаемых классов образов;
инициализация сети путем ввода:
-
oi(0) = xi, 1 ≤ i ≤ n,
(5.4)
где oi(0) – выход (от output) i - го нейрона в начальный (нулевой) момент времени;
итерационное правило: Repeat
-

(5.5)
Until oj(t + 1) = oj(t), j = 1,2, ..., n где oi(t) – выход i – го нейрона в момент времени t.
Соотношения (5.4), (5.5) представим в векторной форме:
o(t+1) = S(Wo(t)), t = 1, 2, ... |
(5.6) |
o(0) = x(0), |
(5.7) |
где x – входной вектор, W – симметричная матрица сети Хопфилда, S – вектор-функция активации или выхода нейронов.
Взвешенная сумма входов j – го нейрона сети Хопфилда равна:
|
(5.8) |
Функция активации или выхода имеет вид:
|
(5.9) |
Таким образом, алгоритм Хопфилда может быть сформулирован следующим образом. Пусть имеется некоторый образ, который следует запомнить в сети Хопфилда, тогда веса искомой сети для распознавания этого образа могут быть рассчитаны, т.е. процесс обучения исключается. Если этот образ характеризуется n – мерным вектором x = (x1, ..., xn)', то веса соединений определяются по формулам:
|
(5.10) |
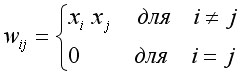
то есть вес связи i-го нейрона с j-м равен произведению i-й и j-й составляющих вектора x, характеризующего данный образ. В этом случае сеть Хопфилда, характеризуемая матрицей W и порогами Ti = 0, i = 1, 2,... , n, запоминает предъявленный образ. Для доказательства определим:
![]()
Веса wij можно умножить на некоторый положительный коэффициент (например, 1/n). Использование такого коэффициента особенно целесообразно в тех случаях, когда запоминаемые образы характеризуются большим числом признаков (например, видеоизображение отображается большим числом пикселов).
Пример 5.1. Имеется изображение из четырех пикселов:

Соответствующий вектор (образ) имеет вид: x = (1,-1,-1,1)'. Стационарная сеть Хопфилда содержит при этом 4 элемента (нейрона). Ее весовая матрица рассчитывается на основе (5.10) и принимает вид:

При этом легко можно убедиться в справедливости равенства x = S(W x).
Подадим на входы сети искаженный образ:
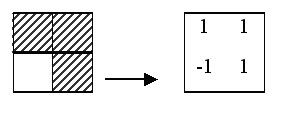
Можно легко установить, что сети потребуется лишь одна итерация, чтобы выдать корректное изображение.
5.2. Распознавание образов сетями Хопфилда.
Обычно сети Хопфилда разрабатываются для запоминания и последующего распознавания большого количества образов (изображений). Обозначим через x1, ..., xk эти образы, причем
xj = (xj1, ..., xjn)T, j = 1, 2, ..., k, |
(5.11) |
где xji , j = 1, 2, ..., k, i = 1, 2, ..., n – i-я составляющая j-го образа.
Подобно (5.10) введем матрицу Ws для s – го образа с весами:
|
(5.12) |
Из этих матриц можно образовать результирующую матрицу сети для всех k запоминаемых образов
W = (W1 + ... + Wk) / n, |
(5.13) |
где n – размерность векторов (например, число пикселов в представлении видеоизображения). Если имеется не много изображений (т.е. k мало), то сеть с матрицей (5.13) запоминает k образов, полагая, естественно, что изображения не сильно коррелированы. С ростом k уменьшается вероятность воспроизведения отдельного образа. Приведем утверждение относительно числа k запоминаемых образов при использовании сети Хопфилда из n нейронов.
Пусть k – число запоминаемых образов, а n – число признаков (пикселов), и образы, подлежащие запоминанию, не коррелированы, т.е. для двух изображений j и s сумма
|
(5.14) |
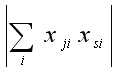
мала. В этом случае при подаче на вход сети с весовой матрицей (5.13) одного образа каждый пиксел корректно воспроизводится с вероятностью при выполнении условия:
|
(5.15) |
Пример 5.2. Образ характеризуется тысячью признаками (n = 1000). В этом случае бинарная сеть Хопфилда в состоянии запомнить и корректно воспроизвести до 150 образов (например, видеоизображений).
В работе сети Хопфилда можно выделить следующие три стадии:
Инициализация или фаза настройки сети: на этой стадии рассчитываются все веса сети для некоторого множества образов. Подчеркнем еще раз: эти веса не определяются на основе рекуррентной процедуры, используемой во многих алгоритмах обучения с поощрением. По окончании этой фазы сеть в состоянии корректно распознавать все запомненные образы.
Ввод нового образа: нейроны сети устанавливаются в соответствующее начальное состояние по алгоритму (5.3) – (5.7),
Затухающий колебательный процесс: путем использования итеративной процедуры рассчитывается последовательность состояний сети до тех пор, пока не будет достигнуто стабильное состояние, т.е.
-
oj(t+1) = oj(t), j = 1, 2, ..., n,
(5.16)
или в качестве выходов сети используются значения (5.16), при которых сеть находится в динамическом равновесии:
-
o = S(Wo),
(5.17)
где o – выходной вектор сети.
Динамическое изменение состояний сети может быть выполнено по крайней мере двумя способами: синхронно и асинхронно. В первом случае все элементы модифицируются одновременно на каждом временном шаге, во втором - в каждый момент времени выбирается и подвергается обработке один элемент. Этот элемент может выбираться случайно.
Выход бинарной сети Хопфилда, содержащей n нейронов, может быть отображен бинарным вектором o состояния сети. Общее число таких состояний – 2n (вершины n – мерного гиперкуба). При вводе нового входного вектора состояние сети изменяется от одной вершины к другой до достижения сетью устойчивого состояния.
Из теории систем с обратными связями известно: для обеспечения устойчивости системы ее изменения с течением времени должны уменьшаться. В противном случае возникают незатухающие колебания. Для таких сетей Коэном (Cohen) и Гроссбергом (Grossberg) (1983) доказана теорема, формулирующая достаточные условия устойчивости сетей с обратными связями:
Рекуррентные сети устойчивы, если весовая матрица W = (wij) симметрична, а на ее главной диагонали – нули:
wij = wji для всех i ≠ j; wii = 0 для всех i. |
(5.18) |
Обратим внимание, что условия данной теоремы достаточны, но не необходимы. Для рекуррентных сетей отсюда следует, что возможны устойчивые сети, не удовлетворяющие приведенному критерию.
Для доказательства приведенной теоремы Коэна и Гроссберга используем энергетическую функцию (функцию Гамильтона) E, принимающую лишь положительные значения. При достижении сетью одного из своих устойчивых состояний эта функция принимает соответствующее минимальное значение (локальный минимум) – для бинарных образов в результате конечного числа итераций. Эта функция определяется следующим образом:
|
(5.19) |
где xi – вход i-го нейрона, Ti – порог i-го нейрона.
Для каждого образа, вводимого в сеть, можно определить энергию E. Определив значение функции E для всех образов, можно получить поверхность энергии с максимумами (вершинами) и минимумами (низинами), причем минимумы соответствуют образам, запомненным сетью. Таким образом, для сетей Хопфилда справедливо утверждение: минимумы энергетической функции соответствуют образам, запомненным сетью. В результате итераций сеть Хопфилда в соответствии с (5.3) – (5.7) сходится к запомненному образу.
Для запоминания каждого следующего образа в поверхность энергии, описываемой энергетической функцией E, необходимо ввести новую «низину». Однако при таком введении уже существующие «низины» не должны быть искажены.
Для некоторого образа x = (x1, x2, ..., xn)' следует минимизировать обе составляющие функции E (5.19). Для того, чтобы второе слагаемое
![]()
было отрицательным, необходимо обеспечить различие знаков входов xi и порогов Ti. При фиксированных порогах это невыполнимо, поэтому выберем пороги равными нулю. При этом второе слагаемое в (5.19) исключается, а остается лишь первое:
|
(5.20) |
Из общего числа k образов выделим некоторый образ с номером s. При этом энергетическую функцию E (5.20) можно представить так:
|
(5.21) |
где wsij – составляющая весового коэффициента wij, вызванная s-м образом, w'ij – составляющая весового коэффициента wij , вызванная остальными образами, запомненными сетью, xsi – значение i-го входа для s-го образа.
Выделенный образ с номером s определяет лишь второе слагаемое в (5.21):
|
(5.22) |

Задача минимизации величины Es эквивалентна максимизации выражения
|
(5.23) |
Входы сети xsi принимают значения из множества {-1, 1}, поэтому (xsi)2 всегда положительны. Следовательно, путем разумного выбора весовых коэффициентов wsij можно максимизировать соотношение (5.23):
|
(5.24) |
где wsij = xsi xsj. Таким образом, минимум энергетической функции E (5.20) достигается при выборе следующего значения весового коэффициента
|
(5.25) |
Это справедливо для s-го образа, подлежащего запоминанию сетью Хопфилда. Для всех k образов, запоминаемых сетью, получаем
|
(5.26) |
Пример 5.3. Дана сеть из трех нейронов (рис. 5.3):

Рис. 5.3. Сеть Хопфилда с тремя нейронами и весами, равными 1.
Соответствующая весовая матрица имеет вид:

В качестве функции активации или выхода нейронов выберем знаковую функцию (sign) с нулевыми порогами. Пусть на вход такой сети подается вектор: x = (1,-1,1)'.
Рассчитаем для него выходной вектор сети. При этом в соответствии с (5.3) – (5.7) получим:
o(1) = S(W x) = (-1,1,-1)';
o(2) = S(Wo(1)) = (-1,-1,-1)';
o(3) = S(Wo(2)) = (-1,-1,-1)'.
Так как o(3) = o(2), то после 3-го шага выходы сети не изменятся, т.е. выходной вектор определяется сетью после 3-го шага.
Основная область применения сетей Хопфилда – распознавание образов. Например, каждое черно-белое изображение, представляемое пикселами, можно отобразить вектором x = (x1, ...,xn)', где xi для i – го пиксела равен 1, если он черный, и xi = -1, если – белый. При подаче на входы обученной сети Хопфилда искаженного изображения сеть после некоторого числа итераций выдает на выходы корректное изображение. На рис. 5.4 приведены корректные образы, запомненные сетью, а на рис. 5.5 – последовательность состояний сети Хопфилда при вводе искаженного образа (старт). Важно подчеркнуть, что для искаженного изображения (рис. 5.5) из четырех запомненных прототипов наиболее близким является второй прототип. После четвертой итерации сеть выдает корректный образ (второй прототип).
Рис. 5.4. Четыре видеоизображения для запоминания сетью Хопфилда
Рис. 5.5. Последовательность из четырех итераций по распознаванию искаженного изображения
5.3. Непрерывные сети Хопфилда.
В соответствии с предложением Хопфилда активация, функция активации и выходы сети Хопфилда могут быть непрерывными. Для этого может быть использована, например, сигмоидальная логистическая функция активации или выхода с параметром λ:
|
(5.27) |
Чем больше значение λ, тем лучше приближение сигмоидальной функции к бинарной пороговой функции. Для непрерывных сетей Хопфилда справедлива модификация теоремы Коэна и Гроссберга: сеть устойчива при выполнении следующих условий:
весовая матрица W симметрична: wij = wji для i ≠ j;
главная диагональ содержит нули: wii = 0 для всех i.
5.4. Применение сетей Хопфилда для решения проблем оптимизации.
Высокая степень распараллеливания обработки информации позволяет успешно применять ИНС для решения задач комбинаторной оптимизации. Среди задач оптимизации, эффективно решаемых нейросетями, в первую очередь следует отметить задачи транспортно-ориентированной оптимизации (задача коммивояжера и ее модификации) и задачи распределения ресурсов (задача о назначениях, задача целераспределения и другие). Решение таких задач традиционными методами математического программирования, большинство из которых ориентировано на вычислительняе системы с последовательной архитектурой, сопряжено с большими затратами времени, часто не приемлемыми для многих приложений.
Одной из известных «трудных» проблем оптимизации является задача о коммивояжере (Traveling Salesman Problem = TSP). Она состоит в определении кратчайшего пути, соединяющего некоторое множество городов, причем каждый город должен учитываться лишь один раз. Это пример NP – полной задачи. Хопфилд и Танк предложили подход к ее приближенному решению на основе сетей Хопфилда. Рассмотрим вкратце этот подход. Для описания возможных маршрутов авторы ввели специальный тип матрицы. В ней города образуют строки, а столбцы отображают последовательность городов в маршруте. В позиции (x, i) матрицы стоит 1 в том случае, когда город x занимает i-е место в маршруте. В табл. 5.1 отображен маршрут, в котором 5 городов A, B, C, D, E посещаются в следующей последовательности: D ⇒ B ⇒ E ⇒ A ⇒ C.
Таблица 5.1. Маршрут посещения городов.
Город |
Последовательность |
||||
1 |
2 |
3 |
4 |
5 |
|
A |
0 |
0 |
0 |
1 |
0 |
B |
0 |
1 |
0 |
0 |
0 |
C |
0 |
0 |
0 |
0 |
1 |
D |
1 |
0 |
0 |
0 |
0 |
E |
0 |
0 |
1 |
0 |
0 |
В случае n городов существует n!/2n различных маршрутов, среди которых необходимо найти кратчайший. Для получения решения задача отображается сетью Хопфилда. В ней каждый нейрон обозначается двумя индексами x и i, причем x отражает город, а i – позицию в маршруте. То есть oxi – это выход нейрона, в котором город x размещен на i-й позиции маршрута.
К энергетической функции E сети Хопфилда следует предъявить следующие условия:
она должна быть минимальна только для допустимых решений, которые содержат одну единицу в каждой строке и в каждом столбце матрицы описания маршрутов;
для решений с более короткими маршрутами она должна принимать меньшие значения.
Энергетическая функция, удовлетворяющая этим условиям, может иметь вид:
|
(5.28) |

При ее выборе учтены следующие соображения:
первое слагаемое равно нулю только в тех случаях, когда каждая строка матрицы описания маршрутов содержит лишь одну единицу;
второе слагаемое равно нулю только тогда, когда каждый столбец матрицы содержит лишь одну единицу;
третье слагаемое равно нулю лишь в тех случаях, когда в матрице описания маршрутов имеется n единиц, что означает: каждый город посещается лишь один раз;
четвертое слагаемое отражает длину маршрута. Обратим внимание, что для каждого города x, расположенного на i-й позиции, определяется расстояние distxy до его последователя y на позиции i+1 и его предшественника y на позиции i-1.
При такой энергетической функции необходимо определить веса wxi, yi сети, причем вес wxi, yi отражает силу соединения нейрона xi и нейрона yj. Способ расчета этих весов приведен, например, в книге Целля (Zell).
71. Понятие и назначение хранимой процедуры и триггера. Работа с хранимой процедурой и триггером
Хранимые процедуры
Хранимые процедуры представляют собой группы связанных между собой операторов SQL, применение которых делает работу программиста более легкой и гибкой, поскольку выполнить хранимую процедуру часто оказывается гораздо проще, чем последовательность отдельных операторов SQL. Хранимые процедуры представляют собой набор команд, состоящий из одного или нескольких операторов SQL или функций и сохраняемый в базе данных в откомпилированном виде. Выполнение в базе данных хранимых процедур вместо отдельных операторов SQL дает пользователю следующие преимущества:
необходимые операторы уже содержатся в базе данных;
все они прошли этап синтаксического анализа и находятся в исполняемом формате; перед выполнением хранимой процедуры SQL Server генерирует для нее план исполнения, выполняет ее оптимизацию и компиляцию;
хранимые процедуры поддерживают модульное программирование, так как позволяют разбивать большие задачи на самостоятельные, более мелкие и удобные в управлении части;
хранимые процедуры могут вызывать другие хранимые процедуры и функции;
хранимые процедуры могут быть вызваны из прикладных программ других типов;
как правило, хранимые процедуры выполняются быстрее, чем последовательность отдельных операторов;
хранимые процедуры проще использовать: они могут состоять из десятков и сотен команд, но для их запуска достаточно указать всего лишь имя нужной хранимой процедуры. Это позволяет уменьшить размер запроса, посылаемого от клиента на сервер, а значит, и нагрузку на сеть.
Хранение процедур в том же месте, где они исполняются, обеспечивает уменьшение объема передаваемых по сети данных и повышает общую производительность системы. Применение хранимых процедур упрощает сопровождение программных комплексов и внесение изменений в них. Обычно все ограничения целостности в виде правил и алгоритмов обработки данных реализуются на сервере баз данных и доступны конечному приложению в виде набора хранимых процедур, которые и представляют интерфейс обработки данных. Для обеспечения целостности данных, а также в целях безопасности, приложение обычно не получает прямого доступа к данным – вся работа с ними ведется путем вызова тех или иных хранимых процедур.
Подобный подход делает весьма простой модификацию алгоритмов обработки данных, тотчас же становящихся доступными для всех пользователей сети, и обеспечивает возможность расширения системы без внесения изменений в само приложение: достаточно изменить хранимую процедуру на сервере баз данных. Разработчику не нужно перекомпилировать приложение, создавать его копии, а также инструктировать пользователей о необходимости работы с новой версией. Пользователи вообще могут не подозревать о том, что в систему внесены изменения.
Хранимые процедуры существуют независимо от таблиц или каких-либо других объектов баз данных. Они вызываются клиентской программой, другой хранимой процедурой или триггером. Разработчик может управлять правами доступа к хранимой процедуре, разрешая или запрещая ее выполнение. Изменять код хранимой процедуры разрешается только ее владельцу или члену фиксированной роли базы данных. При необходимости можно передать права владения ею от одного пользователя к другому.
Хранимые процедуры в среде MS SQL Server
При работе с SQL Server пользователи могут создавать собственные процедуры, реализующие те или иные действия. Хранимые процедуры являются полноценными объектами базы данных, а потому каждая из них хранится в конкретной базе данных. Непосредственный вызов хранимой процедуры возможен, только если он осуществляется в контексте той базы данных, где находится процедура.
Типы хранимых процедур
В SQL Server имеется несколько типов хранимых процедур.
Системные хранимые процедуры предназначены для выполнения различных административных действий. Практически все действия по администрированию сервера выполняются с их помощью. Можно сказать, что системные хранимые процедуры являются интерфейсом, обеспечивающим работу с системными таблицами, которая, в конечном счете, сводится к изменению, добавлению, удалению и выборке данных из системных таблиц как пользовательских, так и системных баз данных. Системные хранимые процедуры имеют префикс sp_, хранятся в системной базе данных и могут быть вызваны в контексте любой другой базы данных.
Пользовательские хранимые процедуры реализуют те или иные действия. Хранимые процедуры – полноценный объект базы данных. Вследствие этого каждая хранимая процедура располагается в конкретной базе данных, где и выполняется.
Временные хранимые процедуры существуют лишь некоторое время, после чего автоматически уничтожаются сервером. Они делятся на локальные и глобальные. Локальные временные хранимые процедуры могут быть вызваны только из того соединения, в котором созданы. При создании такой процедуры ей необходимо дать имя, начинающееся с одного символа #. Как и все временные объекты, хранимые процедуры этого типа автоматически удаляются при отключении пользователя, перезапуске или остановке сервера. Глобальные временные хранимые процедуры доступны для любых соединений сервера, на котором имеется такая же процедура. Для ее определения достаточно дать ей имя, начинающееся с символов ##. Удаляются эти процедуры при перезапуске или остановке сервера, а также при закрытии соединения, в контексте которого они были созданы.
Создание, изменение и удаление хранимых процедур
Создание хранимой процедуры предполагает решение следующих задач:
определение типа создаваемой хранимой процедуры: временная или пользовательская. Кроме этого, можно создать свою собственную системную хранимую процедуру, назначив ей имя с префиксом sp_ и поместив ее в системную базу данных. Такая процедура будет доступна в контексте любой базы данных локального сервера;
планирование прав доступа. При создании хранимой процедуры следует учитывать, что она будет иметь те же права доступа к объектам базы данных, что и создавший ее пользователь;
определение параметров хранимой процедуры. Подобно процедурам, входящим в состав большинства языков программирования, хранимые процедуры могут обладать входными и выходными параметрами;
разработка кода хранимой процедуры. Код процедуры может содержать последовательность любых команд SQL, включая вызов других хранимых процедур.
Создание новой и изменение имеющейся хранимой процедуры осуществляется с помощью следующей команды:
<определение_процедуры>::=
{CREATE | ALTER } PROC[EDURE] имя_процедуры
[;номер]
[{@имя_параметра тип_данных } [VARYING ]
[=default][OUTPUT] ][,...n]
[WITH { RECOMPILE | ENCRYPTION | RECOMPILE,
ENCRYPTION }]
[FOR REPLICATION]
AS
sql_оператор [...n]
Рассмотрим параметры данной команды.
Используя префиксы sp_, #, ##, создаваемую процедуру можно определить в качестве системной или временной. Как видно из синтаксиса команды, не допускается указывать имя владельца, которому будет принадлежать создаваемая процедура, а также имя базы данных, где она должна быть размещена. Таким образом, чтобы разместить создаваемую хранимую процедуру в конкретной базе данных, необходимо выполнить команду CREATE PROCEDURE в контексте этой базы данных. При обращении из тела хранимой процедуры к объектам той же базы данных можно использовать укороченные имена, т. е. без указания имени базы данных. Когда же требуется обратиться к объектам, расположенным в других базах данных, указание имени базы данных обязательно.
Номер в имени – это идентификационный номер хранимой процедуры, однозначно определяющий ее в группе процедур. Для удобства управления процедурами логически однотипные хранимые процедуры можно группировать, присваивая им одинаковые имена, но разные идентификационные номера.
Для передачи входных и выходных данных в создаваемой хранимой процедуре могут использоваться параметры, имена которых, как и имена локальных переменных, должны начинаться с символа @. В одной хранимой процедуре можно задать множество параметров, разделенных запятыми. В теле процедуры не должны применяться локальные переменные, чьи имена совпадают с именами параметров этой процедуры.
Для определения типа данных, который будет иметь соответствующий параметр хранимой процедуры, годятся любые типы данных SQL, включая определенные пользователем. Однако тип данных CURSOR может быть использован только как выходной параметр хранимой процедуры, т.е. с указанием ключевого слова OUTPUT.
Наличие ключевого слова OUTPUT означает, что соответствующий параметр предназначен для возвращения данных из хранимой процедуры. Однако это вовсе не означает, что параметр не подходит для передачи значений в хранимую процедуру. Указание ключевого слова OUTPUT предписывает серверу при выходе из хранимой процедуры присвоить текущее значение параметра локальной переменной, которая была указана при вызове процедуры в качестве значения параметра. Отметим, что при указании ключевого слова OUTPUT значение соответствующего параметра при вызове процедуры может быть задано только с помощью локальной переменной. Не разрешается использование любых выражений или констант, допустимое для обычных параметров.
Ключевое слово VARYING применяется совместно с параметром OUTPUT, имеющим тип CURSOR. Оно определяет, что выходным параметром будет результирующее множество.
Ключевое слово DEFAULT представляет собой значение, которое будет принимать соответствующий параметр по умолчанию. Таким образом, при вызове процедуры можно не указывать явно значение соответствующего параметра.
Так как сервер кэширует план исполнения запроса и компилированный код, при последующем вызове процедуры будут использоваться уже готовые значения. Однако в некоторых случаях все же требуется выполнять перекомпиляцию кода процедуры. Указание ключевого слова RECOMPILE предписывает системе создавать план выполнения хранимой процедуры при каждом ее вызове.
Параметр FOR REPLICATION востребован при репликации данных и включении создаваемой хранимой процедуры в качестве статьи в публикацию.
Ключевое слово ENCRYPTION предписывает серверу выполнить шифрование кода хранимой процедуры, что может обеспечить защиту от использования авторских алгоритмов, реализующих работу хранимой процедуры.
Ключевое слово AS размещается в начале собственно тела хранимой процедуры, т.е. набора команд SQL, с помощью которых и будет реализовываться то или иное действие. В теле процедуры могут применяться практически все команды SQL, объявляться транзакции, устанавливаться блокировки и вызываться другие хранимые процедуры. Выход из хранимой процедуры можно осуществить посредством команды RETURN.
Удаление хранимой процедуры осуществляется командой:
DROP PROCEDURE {имя_процедуры} [,...n]
Выполнение хранимой процедуры
Для выполнения хранимой процедуры используется команда:
[[ EXEC [ UTE] имя_процедуры [;номер] [[@имя_параметра=]{значение | @имя_переменной}
[OUTPUT ]|[DEFAULT ]][,...n]
Если вызов хранимой процедуры не является единственной командой в пакете, то присутствие команды EXECUTE обязательно. Более того, эта команда требуется для вызова процедуры из тела другой процедуры или триггера.
Использование ключевого слова OUTPUT при вызове процедуры разрешается только для параметров, которые были объявлены при создании процедуры с ключевым словом OUTPUT.
Когда же при вызове процедуры для параметра указывается ключевое слово DEFAULT, то будет использовано значение по умолчанию. Естественно, указанное слово DEFAULT разрешается только для тех параметров, для которых определено значение по умолчанию.
Из синтаксиса команды EXECUTE видно, что имена параметров могут быть опущены при вызове процедуры. Однако в этом случае пользователь должен указывать значения для параметров в том же порядке, в каком они перечислялись при создании процедуры. Присвоить параметру значение по умолчанию, просто пропустив его при перечислении нельзя. Если же требуется опустить параметры, для которых определено значение по умолчанию, достаточно явного указания имен параметров при вызове хранимой процедуры. Более того, таким способом можно перечислять параметры и их значения в произвольном порядке.
Отметим, что при вызове процедуры указываются либо имена параметров со значениями, либо только значения без имени параметра. Их комбинирование не допускается.
Триггеры
Триггеры являются одной из разновидностей хранимых процедур. Их исполнение происходит при выполнении для таблицы какого-либо оператора языка манипулирования данными (DML). Триггеры используются для проверки целостности данных, а также для отката транзакций.
Триггер – это откомпилированная SQL-процедура, исполнение которой обусловлено наступлением определенных событий внутри реляционной базы данных. Применение триггеров большей частью весьма удобно для пользователей базы данных. И все же их использование часто связано с дополнительными затратами ресурсов на операции ввода/вывода. В том случае, когда тех же результатов (с гораздо меньшими непроизводительными затратами ресурсов) можно добиться с помощью хранимых процедур или прикладных программ, применение триггеров нецелесообразно.
Триггеры – особый инструмент SQL-сервера, используемый для поддержания целостности данных в базе данных. С помощью ограничений целостности, правил и значений по умолчанию не всегда можно добиться нужного уровня функциональности. Часто требуется реализовать сложные алгоритмы проверки данных, гарантирующие их достоверность и реальность. Кроме того, иногда необходимо отслеживать изменения значений таблицы, чтобы нужным образом изменить связанные данные. Триггеры можно рассматривать как своего рода фильтры, вступающие в действие после выполнения всех операций в соответствии с правилами, стандартными значениями и т.д.
Триггер представляет собой специальный тип хранимых процедур, запускаемых сервером автоматически при попытке изменения данных в таблицах, с которыми триггеры связаны. Каждый Триггер привязывается к конкретной таблице. Все производимые им модификации данных рассматриваются как одна транзакция. В случае обнаружения ошибки или нарушения целостности данных происходит откат этой транзакции. Тем самым внесение изменений запрещается. Отменяются также все изменения, уже сделанные триггером.
Создает триггер только владелец базы данных. Это ограничение позволяет избежать случайного изменения структуры таблиц, способов связи с ними других объектов и т.п.
Триггер представляет собой весьма полезное и в то же время опасное средство. Так, при неправильной логике его работы можно легко уничтожить целую базу данных, поэтому триггеры необходимо очень тщательно отлаживать.
В отличие от обычной подпрограммы, триггер выполняется неявно в каждом случае возникновения триггерного события, к тому же он не имеет аргументов. Приведение его в действие иногда называют запуском триггера. С помощью триггеров достигаются следующие цели:
проверка корректности введенных данных и выполнение сложных ограничений целостности данных, которые трудно, если вообще возможно, поддерживать с помощью ограничений целостности, установленных для таблицы;
выдача предупреждений, напоминающих о необходимости выполнения некоторых действий при обновлении таблицы, реализованном определенным образом;
накопление аудиторской информации посредством фиксации сведений о внесенных изменениях и тех лицах, которые их выполнили;
поддержка репликации.
Основной формат команды CREATE TRIGGER показан ниже:
<Определение_триггера>::=
CREATE TRIGGER имя_триггера
BEFORE | AFTER <триггерное_событие>
ON <имя_таблицы>
[REFERENCING
<список_старых_или_новых_псевдонимов>]
[FOR EACH { ROW | STATEMENT}]
[WHEN(условие_триггера)]
<тело_триггера>
Триггерные события состоят из вставки, удаления и обновления строк в таблице. В последнем случае для триггерного события можно указать конкретные имена столбцов таблицы. Время запуска триггера определяется с помощью ключевых слов BEFORE (Триггер запускается до выполнения связанных с ним событий) или AFTER (после их выполнения).
Выполняемые триггером действия задаются для каждой строки (FOR EACH ROW), охваченной данным событием, или только один раз для каждого события (FOR EACH STATEMENT).
Обозначение <список_старых_или_новых_псевдонимов> относится к таким компонентам, как старая или новая строка (OLD / NEW) либо старая или новая таблица (OLD TABLE / NEW TABLE). Ясно, что старые значения не применимы для событий вставки, а новые – для событий удаления.
При условии правильного использования триггеры могут стать очень мощным механизмом. Основное их преимущество заключается в том, что стандартные функции сохраняются внутри базы данных и согласованно активизируются при каждом ее обновлении. Это может существенно упростить приложения. Тем не менее следует упомянуть и о присущих триггеру недостатках:
сложность: при перемещении некоторых функций в базу данных усложняются задачи ее проектирования, реализации и администрирования;
скрытая функциональность: перенос части функций в базу данных и сохранение их в виде одного или нескольких триггеров иногда приводит к сокрытию от пользователя некоторых функциональных возможностей. Хотя это в определенной степени упрощает его работу, но, к сожалению, может стать причиной незапланированных, потенциально нежелательных и вредных побочных эффектов, поскольку в этом случае пользователь не в состоянии контролировать все процессы, происходящие в базе данных;
влияние на производительность: перед выполнением каждой команды по изменению состояния базы данных СУБД должна проверить триггерное условие с целью выяснения необходимости запуска триггера для этой команды. Выполнение подобных вычислений сказывается на общей производительности СУБД, а в моменты пиковой нагрузки ее снижение может стать особенно заметным. Очевидно, что при возрастании количества триггеров увеличиваются и накладные расходы, связанные с такими операциями.
Неправильно написанные триггеры могут привести к серьезным проблемам, таким, например, как появление "мертвых" блокировок. Триггеры способны длительное время блокировать множество ресурсов, поэтому следует обратить особое внимание на сведение к минимуму конфликтов доступа.
Реализация триггеров в среде MS SQL Server
В реализации СУБД MS SQL Server используется следующий оператор создания или изменения триггера:
<Определение_триггера>::=
{CREATE | ALTER} TRIGGER имя_триггера
ON {имя_таблицы | имя_просмотра }
[WITH ENCRYPTION ]
{
{ { FOR | AFTER | INSTEAD OF }
{ [ DELETE] [,] [ INSERT] [,] [ UPDATE] }
[ WITH APPEND ]
[ NOT FOR REPLICATION ]
AS
sql_оператор[...n]
} |
{ {FOR | AFTER | INSTEAD OF } { [INSERT] [,]
[UPDATE] }
[ WITH APPEND]
[ NOT FOR REPLICATION]
AS
{ IF UPDATE(имя_столбца)
[ {AND | OR} UPDATE(имя_столбца)] [...n]
|
IF (COLUMNS_UPDATES(){оператор_бит_обработки}
бит_маска_изменения)
{оператор_бит_сравнения }бит_маска [...n]}
sql_оператор [...n]
}
}
Триггер может быть создан только в текущей базе данных, но допускается обращение внутри триггера к другим базам данных, в том числе и расположенным на удаленном сервере.
Рассмотрим назначение аргументов из команды CREATE | ALTER TRIGGER.
Имя триггера должно быть уникальным в пределах базы данных. Дополнительно можно указать имя владельца.
При указании аргумента WITH ENCRYPTION сервер выполняет шифрование кода триггера, чтобы никто, включая администратора, не мог получить к нему доступ и прочитать его. Шифрование часто используется для скрытия авторских алгоритмов обработки данных, являющихся интеллектуальной собственностью программиста или коммерческой тайной.
Типы триггеров
В SQL Server существует два параметра, определяющих поведение триггеров:
AFTER. Триггер выполняется после успешного выполнения вызвавших его команд. Если же команды по какой-либо причине не могут быть успешно завершены, триггер не выполняется. Следует отметить, что изменения данных в результате выполнения запроса пользователя и выполнение триггера осуществляется в теле одной транзакции: если произойдет откат триггера, то будут отклонены и пользовательские изменения. Можно определить несколько AFTER-триггеров для каждой операции (INSERT, UPDATE, DELETE). Если для таблицы предусмотрено выполнение нескольких AFTER-триггеров, то с помощью системной хранимой процедуры sp_settriggerorder можно указать, какой из них будет выполняться первым, а какой последним. По умолчанию в SQL Server все триггеры являются AFTER-триггерами.
INSTEAD OF. Триггер вызывается вместо выполнения команд. В отличие от AFTER-триггера INSTEAD OF-триггер может быть определен как для таблицы, так и для просмотра. Для каждой операции INSERT, UPDATE, DELETE можно определить только один INSTEAD OF-триггер.
Триггеры различают по типу команд, на которые они реагируют.
Существует три типа триггеров:
INSERT TRIGGER – запускаются при попытке вставки данных с помощью команды INSERT.
UPDATE TRIGGER – запускаются при попытке изменения данных с помощью команды UPDATE.
DELETE TRIGGER – запускаются при попытке удаления данных с помощью команды DELETE.
Конструкции [ DELETE] [,] [ INSERT] [,] [ UPDATE] и FOR | AFTER | INSTEAD OF } { [INSERT] [,] [UPDATE] определяют, на какую команду будет реагировать триггер. При его создании должна быть указана хотя бы одна команда. Допускается создание триггера, реагирующего на две или на все три команды.
Аргумент WITH APPEND позволяет создавать несколько триггеров каждого типа.
При создании триггера с аргументом NOT FOR REPLICATION запрещается его запуск во время выполнения модификации таблиц механизмами репликации.
Конструкция AS sql_оператор[...n] определяет набор SQL- операторов и команд, которые будут выполнены при запуске триггера.
Отметим, что внутри триггера не допускается выполнение ряда операций, таких, например, как:
создание, изменение и удаление базы данных;
восстановление резервной копии базы данных или журнала транзакций.
Выполнение этих команд не разрешено, так как они не могут быть отменены в случае отката транзакции, в которой выполняется триггер. Это запрещение вряд ли может каким-то образом сказаться на функциональности создаваемых триггеров. Трудно найти такую ситуацию, когда, например, после изменения строки таблицы потребуется выполнить восстановление резервной копии журнала транзакций.
Программирование триггера
При выполнении команд добавления, изменения и удаления записей сервер создает две специальные таблицы: inserted и deleted. В них содержатся списки строк, которые будут вставлены или удалены по завершении транзакции. Структура таблиц inserted и deleted идентична структуре таблиц, для которой определяется триггер. Для каждого триггера создается свой комплект таблиц inserted и deleted, поэтому никакой другой триггер не сможет получить к ним доступ. В зависимости от типа операции, вызвавшей выполнение триггера, содержимое таблиц inserted и deleted может быть разным:
команда INSERT – в таблице inserted содержатся все строки, которые пользователь пытается вставить в таблицу; в таблице deleted не будет ни одной строки; после завершения триггера все строки из таблицы inserted переместятся в исходную таблицу;
команда DELETE – в таблице deleted будут содержаться все строки, которые пользователь попытается удалить; триггер может проверить каждую строку и определить, разрешено ли ее удаление; в таблице inserted не окажется ни одной строки;
команда UPDATE – при ее выполнении в таблице deleted находятся старые значения строк, которые будут удалены при успешном завершении триггера. Новые значения строк содержатся в таблице inserted. Эти строки добавятся в исходную таблицу после успешного выполнения триггера.
Для получения информации о количестве строк, которое будет изменено при успешном завершении триггера, можно использовать функцию @@ROWCOUNT; она возвращает количество строк, обработанных последней командой. Следует подчеркнуть, что триггерзапускается не при попытке изменить конкретную строку, а в момент выполнения команды изменения. Одна такая команда воздействует на множество строк, поэтому триггер должен обрабатывать все эти строки.
Если Триггер обнаружил, что из 100 вставляемых, изменяемых или удаляемых строк только одна не удовлетворяет тем или иным условиям, то никакая строка не будет вставлена, изменена или удалена. Такое поведение обусловлено требованиями транзакции – должны быть выполнены либо все модификации, либо ни одной.
Триггер выполняется как неявно определенная транзакция, поэтому внутри триггера допускается применение команд управления транзакциями. В частности, при обнаружении нарушения ограничений целостности для прерывания выполнения триггера и отмены всех изменений, которые пытался выполнить пользователь, необходимо использовать команду ROLLBACK TRANSACTION.
Для получения списка столбцов, измененных при выполнении команд INSERT или UPDATE, вызвавших выполнение триггера, можно использовать функцию COLUMNS_UPDATED(). Она возвращает двоичное число, каждый бит которого, начиная с младшего, соответствует одному столбцу таблицы (в порядке следования столбцов при создании таблицы). Если бит установлен в значение "1", то соответствующий столбец был изменен. Кроме того, факт изменения столбца определяет и функция UPDATE (имя_столбца).
Для удаления триггера используется команда
DROP TRIGGER {имя_триггера} [,...n]
72. Понятие транзакций и работа с транзакциями. Кэширование изменений: сохранение изменений и отказ от сохранения изменений
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Если вспомнить наш пример информационной системы с файлами СОТРУДНИКИ и ОТДЕЛЫ, то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника является объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо более важно в многопользовательских СУБД.
Например, рассмотрим операции, производимые при переводе денег с одного банковского счета на другой. Проведение такой операции требует выполнения следующих действий:
а) Снять деньги с одного счета:
UPDATE Bank SET Money=Money -1000 WHERE Chet=100;
б) Добавить эту сумму на другой счет:
UPDATE Bank SET Money=Money +1000 WHERE Chet=200;
в) Зафиксировать операцию перевода денег в банковском журнале:
INSERT Operation VALUES (SYSDATE, 100, 200, 1000, … );
Эти действия с базой данных банковских счетов должны быть выполнены либо все полностью, либо ни одно из них не должно быть выполнено. Таким образом, вышеперечисленные 3 операции необходимо рассматривать, как транзакцию.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег).
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
Свойства транзакций
Атомарность - транзакция является неделимой, она выполняется полностью или не выполняется вообще; если транзакция прерывается на середине, то происходит откат (ROLLBACK) и база данных должна остаться в том состоянии, которое она имела до начала транзакции;
Параллельность - эффект от параллельного выполнения нескольких транзакций должен быть таким же, как от их последовательного выполнения;
Целостность - транзакция переводит базу данных из одного непротиворечивого (целостного) состояния в другое;
Долговременность - после того, как транзакция завершена и зафиксирована (COMMIT), результат ее выполнения гарантированно сохраняется в базе данных.
Pеализация механизма транзакций:
Механизм транзакций используется для поддержания целостности БД: транзакция переводит БД из одного целостного состояния в другое. Транзакция может быть явной и неявной. Неявная транзакция запускается и завершается автоматически, явной транзакцией управляет программист. Для модификации данных в удаленной базе может использоваться SQL-запрос, выполняемый с помощью метода ExecSQLкомпонента TQuery. Такой запрос называют PassThrough SQL, его выполнение приводит к запуску неявной транзакции. Способ взаимодействия с сервером на уровне такой транзакции определяет параметр sqlpassthru mode псевдонима БД или драйвера InterBase, который может принимать следующие значения:
1) shared autocommit - операторами модификации БД, например, update или insert, автоматически запускается неявная транзакция (по умолчанию); после внесения изменений эта транзакция автоматически подтверждается; разные транзакции могут использовать общее соединение с БД;
2) shared no autocommit - операторами модификации БД также автоматически запускается неявная транзакция, но автоматического ее подтверждения не происходит, и нужно самостоятельно выполнять оператор commit; разные транзакции могут использовать общее соединение с БД;
3) not shared - транзакции должны использовать различные соединения с БД и подтверждаться выполнением оператора commit. Возможность явного управления транзакциями предоставляет язык SQL сервера, который имеет в своем составе следующие операторы:
set transaction - начать транзакцию;
commit - подтвердить транзакцию;
rollback - отменить транзакцию.
Оператор запуска явной транзакции имеет формат:
SET TRANSACTION [READ WRITE | READ ONLY] [WAIT | NO WAIT] [[ISOLATION LEVEL] {SNAPSHOT [TABLE STABILITY] | READ COMMITED}] [RESERVING <Список таблиц> [FOR [{SHARED | PROTECTED}] [{READ | WRITE}]];
Все операнды этого оператора являются необязательными и позволяют управлять перечисленными ниже режимами транзакции.
Режим доступа к данным:
read write - разрешены чтение и модификация записей (по умолчанию);
read only - разрешено только чтение записей. Поведение в случае конфликта транзакций при обновлении записей:
wait - ожидание завершения другой транзакции (по умолчанию);
no wait - прекращение данной транзакции. Уровень изоляции от других транзакций (операнд isolation level):
snapshot - чтение данных в состоянии на момент начала транзакции (по умолчанию); изменения, сделанные другими транзакциями, в данной транзакции не видны;
snapshot table stability - предоставление транзакции исключительного доступа к таблицам; другие транзакции могут читать записи из таблиц;
read commited - чтение только подтвержденных изменений в записях; если изменения еще не подтверждены, то читается предыдущая версия записи.
Блокирование таблиц, указанных в списке операнда reserving для других транзакций:
protected read - разрешено только чтение записей;
protected write - для транзакций с уровнем изоляции snapshot или read committed разрешено только чтение записей;
shared read - разрешены чтение и модификация записей;
shared write - разрешено чтение записей; Для транзакций с уровнем изоляции snapshot или read committed разрешена модификация записей. Действие операторов commit и rollback по утверждению и отмене транзакции аналогично действию одноименных методов компонента Database.
Использование механизма кэшированных изменений:
Механизм кэшированных изменений заключается в том, что на компьютере клиента в кэше (буфере) создается локальная копия данных, и все изменения в данных выполняются в этой копии. Для хранения локальной копии используется специальный буфер (кэш). Сделанные изменения можно утвердить, перенеся их в основную БД, хранящуюся на сервере, или отказаться от них. Этот механизм напоминает механизм транзакций, но, в отличие от него, снижает нагрузку на сеть, т. к. все изменения передаются в основную БД одним пакетом. Механизм кэшированных изменений реализуется в приложении, для чего компоненты, в первую очередь Database, TTable и TQuery, имеют соответствующие средства. Кроме того, механизм кэшированных изменений поддерживается предназначенным для этого компонентомUpdateSQL. Основные достоинства рассматриваемого механизма проявляются для удаленных БД, но его можно использовать и при работе с локальными БД.
74. Взаимосвязи в базе данных: «один-к-одному», «один-ко-многим» «многие-ко-многим», тренарные, циклические. Примеры использования
Для графического отображения инфологической (концептуальной) модели разработан специальный язык ER-диаграмм (Entity-Relationship, т. е. сущность-связь). Между двумя сущностями можно установить следующие типы связей. Приняты следующие обозначения: -ассотассоциация (связь, содержащая атрибуты) отображается ромбом; - связи отображаются ребрами (линиями) с указанием (или без) типа связи; - атрибуты отображаются овалами. а) связь «один-к-одному» В произвольный момент времени каждому экземпляру одной сущности будет соответствовать один экземпляр второй сущности (или отсутствовать экземпляр второй сущности). Например, каждый гражданин (сущность А), достигший возраста 16 лет, имеет один паспорт (сущность Б) (рисунок 1);
Рисунок 1- Связь «один-к-одному» б) связь «один-ко-многим» В произвольный момент времени каждому экземпляру одной сущности будет соответствовать один или несколько экземпляров второй сущности (или отсутствовать экземпляр второй сущности). Например, каждый поставщик (сущность А) 'поставляет в магазин несколько наименований (сущность Б) товаров, или одно наименование товара, или не поставляет товаров; в) связь «многие-к-одному» Этот тип связи имеет больше теоретическое значение, нежели практическое, и является зеркальным отображением связи «один- ко-многим»; г) связь «многие-ко-многим» В произвольный момент времени нескольким экземплярам одной сущности будет соответствовать несколько экземпляров второй сущности (или отсутствовать экземпляр второй сущности). Например, продавцы-тезки (сущность А) обслуживают покупателей-тезок (сущность Б) Тип связи «многие-ко-многим» носит избыточный характер, т. е. и первая, и вторая сущности имеют множественные повторяющиеся атрибуты. Для ликвидации повторений (не уникальности) используется процедура нормализации, которая будет рассмотрена ниже. В теории баз данных рассматриваются также и редко встречающиеся типы связей; д) циклические связи Циклические связи отличаются от связи «многие-ко- многим» тем, что имеют несколько ассоциаций, в то время как связь «многие-ко-многим» имеет одну ассоциацию; е) тренарные связи Тренарные связи характеризуются тем, что одна сущность имеет ассоциации с двумя другими сущностями (рисунок 2).
Рисноук 2- Тренарные связи Например, разные магазины могут получать однотипные товары от разных поставщиков или разные поставщики поставляют однотипные товары в разные магазины, или однотипные товары поступают в разные магазины от разных поставщиков. Для наглядности в приведенных примерах отсутствовали атрибуты. Добавление атрибутов существенным образом усложняет ER-модели (рисунок 3).
Рисунок 3 - ER-модель с указанием атрибутов Для автоматизации построения различных моделей базы данных создана специальная утилита ErWin, с помощью которой сначала создается логическая модель базы данных, а затем — физическая модель в формате одной из СУБД. |


75. Назначение нормализации. Нормальные формы таблицы, процедура их применения
1. Нормализация, функциональные и многозначные зависимости
Нормализация – это разбиение таблицы на две или более, обладающих лучшими свойствами при включении, изменении и удалении данных. Окончательная цель нормализации сводится к получению такого проекта базы данных, в котором каждый факт появляется лишь в одном месте, т.е. исключена избыточность информации. Это делается не столько с целью экономии памяти, сколько для исключения возможной противоречивости хранимых данных.
Каждая таблица в реляционной БД удовлетворяет условию, в соответствии с которым в позиции на пересечении каждой строки и столбца таблицы всегда находится единственное атомарное значение, и никогда не может быть множества таких значений. Любая таблица, удовлетворяющая этому условию, называется нормализованной. Фактически, ненормализованные таблицы, т.е. таблицы, содержащие повторяющиеся группы, даже не допускаются в реляционной БД.
Всякая нормализованная таблица автоматически считается таблицей в первой нормальной форме, сокращенно 1НФ. Таким образом, строго говоря, "нормализованная" и "находящаяся в 1НФ" означают одно и то же. Однако на практике термин "нормализованная" часто используется в более узком смысле – "полностью нормализованная", который означает, что в проекте не нарушаются никакие принципы нормализации.
Теперь в дополнение к 1НФ можно определить дальнейшие уровни нормализации – вторую нормальную форму (2НФ), третью нормальную форму (3НФ) и т.д.
По существу, таблица находится в 2НФ, если она находится в 1НФ и удовлетворяет, кроме того, некоторому дополнительному условию, суть которого будет рассмотрена ниже. Таблица находится в 3НФ, если она находится в 2НФ и, помимо этого, удовлетворяет еще другому дополнительному условию и т.д.
Таким образом, каждая нормальная форма является в некотором смысле более ограниченной, но и более желательной, чем предшествующая. Это связано с тем, что "(N+1)-я нормальная форма" не обладает некоторыми непривлекательными особенностями, свойственным "N-й нормальной форме". Общий смысл дополнительного условия, налагаемого на (N+1)-ю нормальную форму по отношению к N-й нормальной форме, состоит в исключении этих непривлекательных особенностей. В п. 4.3 мы выявляли непривлекательные особенности таблицы рис. 4.2 и для их исключения выполняли "интуитивную нормализацию".
За время развития технологии проектирования реляционных БД были выделены следующие нормальные формы:
- первая нормальная форма (1NF);
- вторая нормальная форма (2NF);
- третья нормальная форма (3NF);
- нормальная форма Бойса-Кодда (BCNF);
- четвертая нормальная форма (4NF);
- пятая нормальная форма, или нормальная форма проекции-соединения (5NF).
Обычно на практике применение находят только первые три нормальные формы.
Теория нормализации основывается на наличии той или иной зависимости между полями таблицы. Определены два вида таких зависимостей: функциональные и многозначные.
Определение. Функциональная зависимость. Поле В таблицы функционально зависит от поля А той же таблицы в том и только в том случае, когда в любой заданный момент времени для каждого из различных значений поля А обязательно существует только одно из различных значений поля В. Отметим, что здесь допускается, что поля А и В могут быть составными.
Другими словами, в отношении R атрибут Y функционально зависит от атрибута X в том и только в том случае, если каждому значению X соответствует одно значение Y.
Схематично функциональную зависимость атрибута Y от атрибута X изображают гак:
R.X -> R.Y
R(X -> Y).
ФЗ(X -> Y)
Пример 1.
1. В таблице Блюда (б.д. Пансион) поля Блюдо и В функционально зависят от ключа БЛ.
2. Таблица Поставщики вида:Поставщик |
Статус |
Город |
Страна |
Адрес |
Телефон |
В таблице Поставщики поле Страна функционально зависит от составного ключа (Поставщик, Город). Однако последняя зависимость не является функционально полной, так как Страна функционально зависит и от части ключа – поля Город.
Отсюда определение:
Определение. Полная функциональная зависимость. Поле В находится в полной функциональной зависимости от составного поля А, если оно функционально зависит от А и не зависит функционально от любого подмножества поля А.
2. Нормальные формы
1НФ
Выше было дано определение первой нормальной формы (1НФ). Приведем здесь более строгое определение 1НФ, а также определения других нормальных форм.
Определение. Таблица находится в первой нормальной форме (1НФ) тогда и только тогда, когда ни одна из ее строк не содержит в любом своем поле более одного значения и ни одно из ее ключевых полей не пусто. |
2НФ
Определение. Таблица находится во второй нормальной форме (2НФ), если она удовлетворяет определению 1НФ и все ее поля, не входящие в первичный ключ, связаны полной функциональной зависимостью с первичным ключом. |
Пример 2. Отношение УСПЕВАЕМОСТЬ
Схема отношения: УСПЕВАЕМОСТЬ (№ ЗАЧЕТНОЙ КНИЖКИ, ФИО СТУДЕНТА, МЕСТО РОЖДЕНИЯ, ДАТА РОЖДЕНИЯ, КУРС, СРЕДНИЙ БАЛЛ). Первичным ключом отношения является совокупность атрибутов № ЗАЧЕТНОЙ КНИЖКИ, КУРС.
Можно выявить следующие функциональные зависимости:
№ ЗАЧЕТНОЙ КНИЖКИ -> ФИО СТУДЕНТА;
№ ЗАЧЕТНОЙ КНИЖКИ -> МЕСТО РОЖДЕНИЯ;
№ ЗАЧЕТНОЙ КНИЖКИ -> ДАТА РОЖДЕНИЯ;
№ ЗАЧЕТНОЙ КНИЖКИ, КУРС -> СРЕДНИЙ БАЛЛ.
Первичный ключ данного отношения состоит из атрибутов № ЗАЧЕТНОЙ КНИЖКИ, КУРС, однако в нашем случае, атрибуты ФИО СТУДЕНТА, МЕСТО РОЖДЕНИЯ и ДАТА РОЖДЕНИЯ функционально зависят только oт части первичного ключа - № ЗАЧЕТНОЙ КНИЖКИ.
Таким образом, при работе с таким ненормализованным отношением невозможно обеспечить корректную работу при выполнении операциивставки нового кортежа при занесении данных о студентах, сведений об успеваемости которых еще нет, т.к. первичный ключ не может содержать неопределенное значение (в нашем случае часть ключа КУРС не определена).
При удалении записи из отношения мы теряем связь конкретного студента с его успеваемостью за конкретный курс.
Аналогично мы получим неверный результат при выполнении подсчета общего количества студентов.
Такие неприятные явления называются аномалиями схемы отношения или коллизиями. Эти недостатки реляционных отношений устраняются путем нормализации по 2НФ.
Таблица УСПЕВАЕМОСТЬ не удовлетворяет требованиям 2НФ. Почему?. Приведение данного отношения к 2НФ заключается в его разбиении (декомпозиции) на два отношения, удовлетворяющих соответствующим требованиям нормализации. Можно произвести следующую декомпозицию отношения УСПЕВАЕМОСТЬ в два отношения СТУДЕНТЫ и УСПЕВАЕМОСТЬ СТУДЕНТОВ:

СТУДЕНТЫ (№ ЗАЧЕТНОЙ КНИЖКИ, ФИО СТУДЕНТА, МЕСТО РОЖДЕНИЯ, ДАТА РОЖДЕНИЯ)
УСПЕВАЕМОСТЬ СТУДЕНТОВ(№ ЗАЧЕТНОЙ КНИЖКИ, КУРС, СРЕДНИЙ БАЛЛ)
Первичным ключом отношения СТУДЕНТЫ являются атрибут № ЗАЧЕТНОЙ КНИЖКИ.
Можно выявить следующие функциональные зависимости:
№ ЗАЧЕТНОЙ КНИЖКИ -> ФИО СТУДЕНТА;
№ ЗАЧЕТНОЙ КНИЖКИ -> МЕСТО РОЖДЕНИЯ;
№ ЗАЧЕТНОЙ КНИЖКИ -> ДАТА РОЖДЕНИЯ;
Первичным ключом отношения УСПЕВАЕМОСТЬ СТУДЕНТОВ является атрибуты № ЗАЧЕТНОЙ КНИЖКИ, КУРС.
В этом отношении существует одна функциональная зависимость;
№ ЗАЧЕТНОЙ КНИЖКИ, КУРС -> СРЕДНИЙ БАЛЛ.
Каждое из этих двух отношений находится в 2НФ, и в них устранены отмеченные выше аномалии (легко проверить, что все указанные операции выполняются без проблем).
Ко второй нормальной форме не приведена таблица Поставщики из примера 1, в которой Страна зависит только от поля Город, который является частью первичного ключа (Поставщик, Город). Последнее обстоятельство приводит к проблемам при:
включении данных (пока не появится поставщик из Вильнюса, нельзя зафиксировать, что этот город Литвы),
удалении данных (исключение поставщика может привести к потере информации о местонахождении города),
обновлении данных (при изменении названия страны приходится просматривать множество строк, чтобы исключить получение противоречивого результата).
Разбивая эту таблицу на две таблицы Поставщики и Города, можно исключить указанные аномалии.
Ввод в таблицы отсутствующих в предметной области цифровых первичных и внешних ключей формально затрудняет процедуру выявления функциональных связей между этими ключами и остальными полями.
Например, в БД ПАНСИОН, легко установить связь между атрибутом Блюдо и В(ид) (блюда): Харчо – Суп, Лобио – Закуска и т.п., но нет прямой зависимости между полями БЛ и В(ид) (блюда), если не помнить, что значение БЛ соответствует номеру блюда.
Для упрощения нормализации таблиц с цифровыми ключами целесообразно использовать следующую рекомендацию.
Рекомендация. При проведении нормализации таблиц, в которые введены цифровые (или другие) заменители составных и (или) текстовых первичных и внешних ключей, следует хотя бы мысленно подменять их на исходные ключи, а после окончания нормализации снова восстанавливать. |
3НФ
Добавим в отношение СТУДЕНТЫ два атрибута: № ГРУППЫ и ФИО КУРАТОРА:
СТУДЕНТЫ (№ ЗАЧЕТНОЙ КНИЖКИ, ФИО СТУДЕНТА, МЕСТО РОЖДЕНИЯ, ДАТА РОЖДЕНИЯ, № ГРУППЫ, ФИО КУРАТОРА)
Первичным ключом отношения СТУДЕНТЫ является атрибут № ЗАЧЕГНОИ КНИЖКИ. Отношение находится во второй нормальной форме, поскольку отсутствуют зависимости атрибутов от части ключа.
Функциональная зависимость № ЗАЧЕТНОЙ КНИЖКИ -> ФИО КУРАТОРА здесь существует. Она называется транзитивной, поскольку является следствием функциональных зависимостей № ЗАЧЁТНОЙ КНИЖКИ -> № ГРУППЫ и № ГРУППЫ -> ФИО КУРАТОРА. Другими словами, ФИО КУРАТОРА является характеристикой не студента, а группы, в которой он учится.
В результате мы не сможем занести в базу данных информацию о кураторе группы до тех пор, пока в этой группе не появится хотя бы один студент, поскольку первичный ключ не может содержать неопределенное значение. При удалении кортежа, описывающего последнего студента данной группы, мы лишимся информации о том, кто являлся куратором этой группы.
Чтобы корректно изменить ФИО куратора группы, необходимо последовательно изменить все кортежи, описывающие студентов этой группы, т.е. в отношении СТУДЕНТЫ благодаря добавлению двух новых атрибутов по-прежнему существуют аномалии. Их можно устранить путем дальнейшей нормализации.
Определение. Таблица находится в третьей нормальной форме (3НФ), если она удовлетворяет определению 2НФ и не одно из ее неключевых полей не зависит функционально от любого другого неключевого поля. |
Приведение отношения к ЗНФ (нормализация по ЗНФ) также заключается в декомпозиции этого отношения. Можно произвести декомпозицию отношения СТУДЕНТЫ в два отношения СПРАВОЧНИК СТУДЕНТОВ и ГРУППЫ
СПРАВОЧНИК СТУДЕНТОВ (№ ЗАЧЕТНОЙ КНИЖКИ, ФИО СТУДЕНТА, МЕСТО РОЖДЕНИЯ, ДАТА РОЖДЕНИЯ, № ГРУППЫ)
(теперь это не стержневая сущность, а что?)
ГРУППЫ (№ ГРУППЫ, ФИО КУРАТОРА)
Первичным ключом отношения СПРАВОЧНИК СТУДЕНТОВ является атрибут № ЗАЧЕТНОЙ КНИЖКИ. В отношении имеют место следующие функциональные зависимости:
№ ЗАЧЕТНОЙ КНИЖКИ -> ФИО СТУДЕНТА;
№ ЗАЧЕТНОЙ КНИЖКИ -> ДАТА РОЖДЕНИЯ;
№ ЗАЧЕТНОЙ КНИЖКИ -> МЕСТО РОЖДЕНИЯ;
№ ЗАЧЕТНОЙ КНИЖКИ -> № ГРУППЫ.
Первичным ключом отношения КУРАТОРЫ ГРУПП является атрибут № ГРУППЫ. В этом отношении есть одна функциональная зависимость:
№ ГРУППЫ -> ФИО КУРАТОРА.
Результирующие отношения находятся в ЗНФ и свободны от отмеченных аномалий.
НФБК
При проектировании БД третья нормальная форма схем отношений достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Однако иногда полезно продолжить процесс нормализации.
Пример 3. Рассмотрим следующий пример. База данных ПАНСИОН. Отношения
Блюдо (БЛ, Блюдо, В, О, Выход, Труд)
Продукты (ПР, Продукт, Белки, …)
Данные таблицы не находятся в 3НФ после добавления цифрового первичного ключа. В них появились несуществовавшие ранее функциональные зависимости между неключевыми полями:
1) Блюдо->В, Блюдо->О и т.д.
2) Продукт->Белки, ит.д.
Следовательно, для приведения таблиц Блюда и Продукты к 3НФ их надо разбить на
Блюда(БЛ, Блюдо),
Вид_блюда(БЛ, В);
и т.д.
Продукты(ПР, Продукт);
Калор_прод(ПР,Калорийносить),
и т.д.
хотя интуиция подсказывает, что это лишнее разбиение, совсем не улучшающее проекта базы данных.
Столкнувшись с подобными несуразностями, которые могут возникать не только из-за введения кодированных первичных ключей, теоретики реляционных систем Кодд и Бойс обосновали и предложили более строгое определение для 3НФ, которое учитывает, что в таблице может быть несколько возможных ключей.
Определение. Таблица находится в нормальной форме Бойса-Кодда (НФБК), если и только если любая функциональная зависимость между его полями сводится к полной функциональной зависимости от возможного ключа. |
В соответствие с этой формулировкой таблицы Блюда и Продукты, имеющие по паре возможных ключей (БЛ и Блюдо) и (ПР и Продукт) находятся в НФБК или в 3НФ.
3. Процедура нормализации
Как уже говорилось, нормализация – это разбиение таблицы на несколько, обладающих лучшими свойствами при обновлении, включении и удалении данных. Теперь можно дать и другое определение: нормализация – это процесс последовательной замены таблицы ее полными декомпозициями до тех пор, пока все они не будут находиться в 5НФ. На практике же достаточно привести таблицы к НФБК и с большой гарантией считать, что они находятся в 5НФ. Разумеется, этот факт нуждается в проверке, однако пока не существует эффективного алгоритма такой проверки. Поэтому остановимся лишь на процедуре приведения таблиц к НФБК.
Эта процедура основывается на том, что единственными функциональными зависимостями в любой таблице должны быть зависимости вида K->F, где K – первичный ключ, а F – некоторое другое поле. Заметим, что это следует из определения первичного ключа таблицы, в соответствии с которым K->F всегда имеет место для всех полей данной таблицы. "Один факт в одном месте" говорит о том, что не имеют силы никакие другие функциональные зависимости. Цель нормализации состоит именно в том, чтобы избавиться от всех этих "других" функциональных зависимостей, т.е. таких, которые имеют иной вид, чем K->F.
Если воспользоваться рекомендацией 2 и подменить на время нормализации коды первичных (внешних) ключей на исходные ключи, то, по существу, следует рассмотреть лишь два случая:
1. Таблица имеет составной первичный ключ вида, скажем, (К1,К2), и включает также поле F, которое функционально зависит от части этого ключа, например, от К2, но не от полного ключа. В этом случае рекомендуется сформировать другую таблицу, содержащую К2 и F (первичный ключ – К2), и удалить F из первоначальной таблицы:
Заменить T(K1,K2,F), первичный ключ (К1,К2), ФЗ(К2->F)
на T1(K1,K2), первичный ключ (К1,К2),
и T2(K2,F), первичный ключ К2.
2. Таблица имеет первичный (возможный) ключ К, не являющееся возможным ключом поле F1, которое, конечно, функционально зависит от К, и другое неключевое поле F2, которое функционально зависит от F1. Решение здесь, по существу, то же самое, что и прежде – формируется другая таблица, содержащая F1 и F2, с первичным ключом F1, и F2 удаляется из первоначальной таблицы:
Заменить T(K,F1,F2), первичный ключ К, ФЗ(F1->F2)
на T1(K,F1), первичный ключ К,
и T2(F1,F2), первичный ключ F1.
Для любой заданной таблицы, повторяя применение двух рассмотренных правил, почти во всех практических ситуациях можно получить в конечном счете множество таблиц, которые находятся в "окончательной" нормальной форме и, таким образом, не содержат каких-либо функциональных зависимостей вида, отличного от (K->F).
Для выполнения этих операций необходимо первоначально иметь в качестве входных данных какие-либо "большие" таблицы (например, универсальные отношения). Но нормализация ничего не говорит о том, как получить эти большие таблицы. Приведем пример нормализации.
Пример 4. Применим рассмотренные правила для полной нормализации универсального отношения "Питание":
Питание (Блюдо, Вид, Рецепт, Порций, Дата Р, Продукт, Калорийность, Вес, Поставщик, Город, Страна, Вес, Цена, Дата П)
Шаг 1. Определение первичного ключа таблицы.
Предположим,
1) Каждое блюдо имеет уникальное название, относится к единственному виду и приготавливается по единственному рецепту, т.е. название блюда однозначно определяет его вид и рецепт.
2) Название организации поставщика уникально для того города, в котором он расположен, и названия городов уникальны для каждой из стран, т.е.название поставщика и город однозначно определяют этого поставщика, а город – страну его нахождения.
3) Поставщик может осуществлять в один и тот же день только одну поставку каждого продукта, т.е. название продукта, название организации поставщика, город и дата поставки однозначно определяют вес и цену поставленного продукта.
Тогда в качестве первичного ключа отношения "Питание" можно использовать следующий набор атрибутов:
Блюдо, Дата_Р, Продукт, Поставщик, Город, Дата_П.
Шаг 2. Выявление полей, функционально зависящих от части составного ключа.
Поле Вид функционально зависит только от поля Блюдо, т.е.
Блюдо->Вид
Аналогичным образом можно получить зависимости:
Блюдо->Рецепт
(Блюдо, Дата_Р)->Порций
Продукт->Калорийность
(Блюдо, Продукт)->Вес
Город->Страна
(Поставщик, Город, Дата_П)->Цена
Шаг 3. Формирование новых таблиц.
Полученные функциональные зависимости определяют состав таблиц, которые можно сформировать из данных универсального отношения:
Блюда (Блюдо, Вид)
Рецепты (Блюдо, Рецепт)
Расход (Блюдо, Дата_Р, Порций)
Продукты (Продукт, Калорийность)
Состав (Блюдо, Продукт, Вес)
Города (Город, Страна)
Поставки (Поставщик, Город, Дата_П, Цена).
Шаг 4. Корректировка исходной таблицы.
После выделения из состава универсального отношения указанных выше таблиц, там остались лишь сведения о поставщиках, для хранения которых целесообразно создать таблицу
Поставщики (Поставщик, Город),
т.е. использовать оставшуюся часть исходного первичного ключа.
4. Пример нормализации
Постановка задачи. Дано отношение.
1) определить первичный ключ отношения и все функциональные зависимости отношения;
2) привести отношение к 3НФ, указать первичные и внешние ключи полученных отношений, построить схему "Таблица-Связь".
R = {НаименованиеЭмитента, ТипЦБ, ДатаЭмиссии, НоминальнаяCтоимость}.
Наименование Эмитента |
ТипЦБ |
Дата Эмиссии |
Номинальная Стоимость |
ОАО “КрАЗ” |
акция обыкновенная |
23.06.1999 |
100 руб. |
ОАО “КрАЗ” |
акция обыкновенная |
23.06.1999 |
200 руб. |
ТОО “Искра” |
акция привилегирванная |
20.06.1999 |
500 руб. |
ТОО “Искра” |
акция привилегированная |
23.06.1999 |
500 руб. |
Решение
1. Функциональные зависимости:
<ДатаЭмиссии, НоминальнаяCтоимость> -> <НаименованиеЭмитента, ТипЦБ>
ТипЦБ -> НаименованиеЭмитента
Первичный ключ отношения R состоит из двух атрибутов:
<ДатаЭмиссии, НоминальнаяCтоимость>.
Таким образом, существует функциональная зависимость между неключевыми атрибутами отношения R, т.е. отношение R не находится в 3НФ.
2. Приведение отношения R к 3НФ состоит в декомпозиции (разбиении отношения R на два отношения):
R1= {НаименованиеЭмитента, ТипЦБ}, где
Функциональные зависимости:
ТипЦБ -> НаименованиеЭмитента,
первичный ключ – атрибут ТипЦБ,
R2={ТипЦБ, ДатаЭмиссии, НоминальнаяCтоимость},
Функциональные зависимости:
<ДатаЭмиссии, НоминальнаяCтоимость> -> ТипЦБ,
составной первичный ключ:
<ДатаЭмиссии, НоминальнаяCтоимость>,
внешний ключ:
ТипЦБ.
3. Схема "Таблица-Связь":

77. Синхронизация процессов. Тупики
Введение
В предыдущих лекциях мы рассматривали способы синхронизации процессов, которые позволяют процессам успешно кооперироваться. Однако в некоторых случаях могут возникнуть непредвиденные затруднения. Предположим, что несколько процессов конкурируют за обладание конечным числом ресурсов. Если запрашиваемый процессомресурс недоступен, ОС переводит данный процесс в состояние ожидания. В случае когда требуемый ресурс удерживается другим ожидающим процессом, первый процесс не сможет сменить свое состояние. Такая ситуация называется тупиком (deadlock). Говорят, что в мультипрограммной системе процесс находится в состоянии тупика, если он ожидает события, которое никогда не произойдет. Системная тупиковая ситуация, или "зависание системы", является следствием того, что один или более процессов находятся в состоянии тупика. Иногда подобные ситуации называют взаимоблокировками. В общем случае проблема тупиков эффективного решения не имеет.
Рассмотрим пример. Предположим, что два процесса осуществляют вывод с ленты на принтер. Один из них успел монополизировать ленту и претендует на принтер, а другой наоборот. После этого оба процесса оказываются заблокированными в ожидании второго ресурса (см. рис. 7.1).

Рис. 7.1. Пример тупиковой ситуации
Определение. Множество процессов находится в тупиковой ситуации, если каждый процесс из множества ожидает события, которое может вызвать только другой процесс данного множества. Так как все процессы чего-то ожидают, то ни один из них не сможет инициировать событие, которое разбудило бы другого члена множества и, следовательно, все процессы будут спать вместе.
Выше приведен пример взаимоблокировки, возникающей при работе с так называемыми выделенными устройствами. Тупики, однако, могут иметь место и в других ситуациях. Hапример, в системах управления базами данных записи могут быть локализованы процессами, чтобы избежать состояния гонок (см. лекцию 5 "Алгоритмы синхронизации"). В этом случае может получиться так, что один из процессов заблокировал записи, необходимые другому процессу, и наоборот. Таким образом, тупики могут иметь место как на аппаратных, так и на программных ресурсах.
Тупики также могут быть вызваны ошибками программирования. Например, процесс может напрасно ждать открытия семафора, потому что в некорректно написанном приложении эту операцию забыли предусмотреть. Другой причиной бесконечного ожидания может быть дискриминационная политика по отношению к некоторым процессам. Однако чаще всего событие, которого ждет процесс в тупиковой ситуации, – освобождение ресурса, поэтому в дальнейшем будут рассмотрены методы борьбы с тупикамиресурсного типа.
Ресурсами могут быть как устройства, так и данные. Hекоторые ресурсы допускают разделение между процессами, то есть являются разделяемыми ресурсами. Например, память, процессор, диски коллективно используются процессами. Другие не допускают разделения, то есть являются выделенными, например лентопротяжное устройство. Квзаимоблокировке может привести использование как выделенных, так и разделяемых ресурсов. Например, чтение с разделяемого диска может одновременно осуществляться несколькими процессами, тогда как запись предполагает исключительный доступ к данным на диске. Можно считать, что часть диска, куда происходит запись, выделена конкретному процессу. Поэтому в дальнейшем мы будем исходить из предположения, что тупики связаны с выделенными ресурсами , то есть тупики возникают, когда процессу предоставляется эксклюзивный доступ к устройствам, файлам и другим ресурсам.
Традиционная последовательность событий при работе с ресурсом состоит из запроса, использования и освобождения ресурса. Тип запроса зависит от природы ресурса и от ОС. Запрос может быть явным, например специальный вызов request, или неявным – open для открытия файла. Обычно, если ресурс занят и запрос отклонен, запрашивающий процесс переходит в состояние ожидания.
Далее в данной лекции будут рассматриваться вопросы обнаружения, предотвращения, обхода тупиков и восстановления после тупиков. Как правило, борьба с тупиками – очень дорогостоящее мероприятие. Тем не менее для ряда систем, например для систем реального времени, иного выхода нет.
Условия возникновения тупиков
Условия возникновения тупиков были сформулированы Коффманом, Элфиком и Шошани в 1970 г.
Условие взаимоисключения (Mutual exclusion). Одновременно использовать ресурс может только один процесс.
Условие ожидания ресурсов (Hold and wait). Процессы удерживают ресурсы, уже выделенные им, и могут запрашивать другие ресурсы.
Условие неперераспределяемости (No preemtion). Ресурс, выделенный ранее, не может быть принудительно забран у процесса. Освобождены они могут быть только процессом, который их удерживает.
Условие кругового ожидания (Circular wait). Существует кольцевая цепь процессов, в которой каждый процесс ждет доступа к ресурсу, удерживаемому другим процессом цепи.
Для образования тупика необходимым и достаточным является выполнение всех четырех условий.
Обычно тупик моделируется циклом в графе, состоящем из узлов двух видов: прямоугольников – процессов и эллипсов – ресурсов, наподобие того, что изображен на рис. 7.1. Стрелки, направленные от ресурса к процессу, показывают, что ресурс выделен данному процессу. Стрелки, направленные от процесса к ресурсу, означают, что процесс запрашивает данный ресурс.
Основные направления борьбы с тупиками
Проблема тупиков инициировала много интересных исследований в области информатики. Очевидно, что условие циклического ожидания отличается от остальных. Первые три условия формируют правила, существующие в системе, тогда как четвертое условие описывает ситуацию, которая может сложиться при определенной неблагоприятной последовательности событий. Поэтому методы предотвращения взаимоблокировок ориентированы главным образом на нарушение первых трех условий путем введения ряда ограничений на поведение процессов и способы распределения ресурсов. Методы обнаружения и устранения менее консервативны и сводятся к поиску и разрыву цикла ожидания ресурсов.
Итак, основные направления борьбы с тупиками:
Игнорирование проблемы в целом
Предотвращение тупиков
Обнаружение тупиков
Восстановление после тупиков
Игнорирование проблемы тупиков
Простейший подход – не замечать проблему тупиков. Для того чтобы принять такое решение, необходимо оценить вероятность возникновения взаимоблокировки и сравнить ее с вероятностью ущерба от других отказов аппаратного и программного обеспечения. Проектировщики обычно не желают жертвовать производительностью системы или удобством пользователей для внедрения сложных и дорогостоящих средств борьбы с тупиками.
Любая ОС, имеющая в ядре ряд массивов фиксированной размерности, потенциально страдает от тупиков, даже если они не обнаружены. Таблица открытых файлов, таблица процессов, фактически каждая таблица являются ограниченными ресурсами. Заполнение всех записей таблицы процессов может привести к тому, что очередной запрос на создание процесса может быть отклонен. При неблагоприятном стечении обстоятельств несколько процессов могут выдать такой запрос одновременно и оказаться в тупике. Следует ли отказываться от вызова CreateProcess, чтобы решить эту проблему?
Подход большинства популярных ОС (Unix, Windows и др.) состоит в том, чтобы игнорировать данную проблему в предположении, что маловероятный случайный тупикпредпочтительнее, чем нелепые правила, заставляющие пользователей ограничивать число процессов, открытых файлов и т. п. Сталкиваясь с нежелательным выбором между строгостью и удобством, трудно найти решение, которое устраивало бы всех.
Способы предотвращения тупиков
Цель предотвращения тупиков – обеспечить условия, исключающие возможность возникновения тупиковых ситуаций. Большинство методов связано с предотвращением одного из условий возникновения взаимоблокировки.
Система, предоставляя ресурс в распоряжение процесса, должна принять решение, безопасно это или нет. Возникает вопрос: есть ли такой алгоритм, который помогает всегда избегать тупиков и делать правильный выбор. Ответ – да, мы можем избегать тупиков, но только если определенная информация известна заранее.
Способы предотвращения тупиков путем тщательного распределения ресурсов. Алгоритм банкира
Можно избежать взаимоблокировки, если распределять ресурсы, придерживаясь определенных правил. Среди такого рода алгоритмов наиболее известен алгоритм банкира, предложенный Дейкстрой, который базируется на так называемых безопасных или надежных состояниях (safe state). Безопасное состояние – это такое состояние, для которого имеется по крайней мере одна последовательность событий, которая не приведет к взаимоблокировке. Модель алгоритма основана на действиях банкира, который, имея в наличии капитал, выдает кредиты.
Суть алгоритма состоит в следующем.
Предположим, что у системы в наличии n устройств, например лент.
ОС принимает запрос от пользовательского процесса, если его максимальная потребность не превышает n.
Пользователь гарантирует, что если ОС в состоянии удовлетворить его запрос, то все устройства будут возвращены системе в течение конечного времени.
Текущее состояние системы называется надежным, если ОС может обеспечить всем процессам их выполнение в течение конечного времени.
В соответствии с алгоритмом банкира выделение устройств возможно, только если состояние системы остается надежным.
Рассмотрим пример надежного состояния для системы с 3 пользователями и 11 устройствами, где 9 устройств задействовано, а 2 имеется в резерве. Пусть текущая ситуация такова:

Рис. 7.2. Пример надежного состояния для системы с 3 пользователями и 11 устройствами.
Данное состояние надежно. Последующие действия системы могут быть таковы. Вначале удовлетворить запросы третьего пользователя, затем дождаться, когда он закончит работу и освободит свои три устройства. Затем можно обслужить первого и второго пользователей. То есть система удовлетворяет только те запросы, которые оставляют ее в надежном состоянии, и отклоняет остальные.
Термин ненадежное состояние не предполагает, что обязательно возникнут тупики. Он лишь говорит о том, что в случае неблагоприятной последовательности событий система может зайти в тупик.
Данный алгоритм обладает тем достоинством, что при его использовании нет необходимости в перераспределении ресурсов и откате процессов назад. Однако использование этого метода требует выполнения ряда условий.
Число пользователей и число ресурсов фиксировано.
Число работающих пользователей должно оставаться постоянным.
Алгоритм требует, чтобы клиенты гарантированно возвращали ресурсы.
Должны быть заранее указаны максимальные требования процессов к ресурсам. Чаще всего данная информация отсутствует.
Наличие таких жестких и зачастую неприемлемых требований может склонить разработчиков к выбору других решений проблемы взаимоблокировки.
Предотвращение тупиков за счет нарушения условий возникновения тупиков
В отсутствие информации о будущих запросах единственный способ избежать взаимоблокировки – добиться невыполнения хотя бы одного из условий раздела "Условия возникновения тупиков".
Нарушение условия взаимоисключения
В общем случае избежать взаимоисключений невозможно. Доступ к некоторым ресурсам должен быть исключительным. Тем не менее некоторые устройства удается обобществить. В качестве примера рассмотрим принтер. Известно, что пытаться осуществлять вывод на принтер могут несколько процессов. Во избежание хаоса организуют промежуточное формирование всех выходных данных процесса на диске, то есть разделяемом устройстве. Лишь один системный процесс, называемый сервисом или демоном принтера, отвечающий за вывод документов на печать по мере освобождения принтера, реально с ним взаимодействует. Эта схема называется спулингом (spooling). Таким образом, принтер становится разделяемым устройством, и тупик для него устранен.
К сожалению, не для всех устройств и не для всех данных можно организовать спулинг. Неприятным побочным следствием такой модели может быть потенциальная тупиковая ситуация из-за конкуренции за дисковое пространство для буфера спулинга. Тем не менее в той или иной форме эта идея применяется часто.
Нарушение условия ожидания дополнительных ресурсов
Условия ожидания ресурсов можно избежать, потребовав выполнения стратегии двухфазного захвата.
В первой фазе процесс должен запрашивать все необходимые ему ресурсы сразу. До тех пор пока они не предоставлены, процесс не может продолжать выполнение.
Если в первой фазе некоторые ресурсы, которые были нужны данному процессу, уже заняты другими процессами, он освобождает все ресурсы, которые были ему выделены, и пытается повторить первую фазу.
В известном смысле этот подход напоминает требование захвата всех ресурсов заранее. Естественно, что только специально организованные программы могут быть приостановлены в течение первой фазы и рестартованы впоследствии.
Таким образом, один из способов – заставить все процессы затребовать нужные им ресурсы перед выполнением ("все или ничего"). Если система в состоянии выделить процессу все необходимое, он может работать до завершения. Если хотя бы один из ресурсов занят, процесс будет ждать.
Данное решение применяется в пакетных мэйнфреймах (mainframe), которые требуют от пользователей перечислить все необходимые его программе ресурсы. Другим примером может служить механизм двухфазной локализации записей в СУБД. Однако в целом подобный подход не слишком привлекателен и приводит к неэффективному использованию компьютера. Как уже отмечалось, перечень будущих запросов к ресурсам редко удается спрогнозировать. Если такая информация есть, то можно воспользоваться алгоритмом банкира. Заметим также, что описываемый подход противоречит парадигме модульности в программировании, поскольку приложение должно знать о предполагаемых запросах к ресурсам во всех модулях.
Нарушение принципа отсутствия перераспределения
Если бы можно было отбирать ресурсы у удерживающих их процессов до завершения этих процессов, то удалось бы добиться невыполнения третьего условия возникновения тупиков. Перечислим минусы данного подхода.
Во-первых, отбирать у процессов можно только те ресурсы, состояние которых легко сохранить, а позже восстановить, например состояние процессора. Во-вторых, если процесс в течение некоторого времени использует определенные ресурсы, а затем освобождает эти ресурсы, он может потерять результаты работы, проделанной до настоящего момента. Наконец, следствием данной схемы может быть дискриминация отдельных процессов, у которых постоянно отбирают ресурсы.
Весь вопрос в цене подобного решения, которая может быть слишком высокой, если необходимость отбирать ресурсы возникает часто.
Hарушение условия кругового ожидания
Трудно предложить разумную стратегию, чтобы избежать последнего условия из раздела "Условия возникновения тупиков" – циклического ожидания.
Один из способов – упорядочить ресурсы. Например, можно присвоить всем ресурсам уникальные номера и потребовать, чтобы процессы запрашивали ресурсы в порядке их возрастания. Тогда круговое ожидание возникнуть не может. После последнего запроса и освобождения всех ресурсов можно разрешить процессу опять осуществить первый запрос. Очевидно, что практически невозможно найти порядок, который удовлетворит всех.
Один из немногих примеров упорядочивания ресурсов – создание иерархии спин-блокировок в Windows 2000. Спин-блокировка – простейший способ синхронизации (вопросы синхронизации процессов рассмотрены в соответствующей лекции). Спин-блокировка может быть захвачена и освобождена процессом. Классическая тупиковая ситуациявозникает, когда процесс P1 захватывает спин-блокировку S1 и претендует на спин-блокировку S2, а процесс P2, захватывает спин-блокировку S2 и хочет дополнительно захватить спин-блокировку S1. Чтобы этого избежать, все спин-блокировки помещаются в упорядоченный список. Захват может осуществляться только в порядке, указанном в списке.
Другой способ атаки условия кругового ожидания – действовать в соответствии с правилом, согласно которому каждый процесс может иметь только один ресурс в каждый момент времени. Если нужен второй ресурс – освободи первый. Очевидно, что для многих процессов это неприемлемо.
Таким образом, технология предотвращения циклического ожидания, как правило, неэффективна и может без необходимости закрывать доступ к ресурсам.
Обнаружение тупиков
Обнаружение взаимоблокировки сводится к фиксации тупиковой ситуации и выявлению вовлеченных в нее процессов. Для этого производится проверка наличия циклического ожидания в случаях, когда выполнены первые три условия возникновения тупика. Методы обнаружения активно используют графы распределения ресурсов.
Рассмотрим модельную ситуацию.
Процесс P1 ожидает ресурс R1.
Процесс P2 удерживает ресурс R2 и ожидает ресурс R1.
Процесс P3 удерживает ресурс R1 и ожидает ресурс R3.
Процесс P4 ожидает ресурс R2.
Процесс P5 удерживает ресурс R3 и ожидает ресурс R2.
Вопрос состоит в том, является ли данная ситуация тупиковой, и если да, то какие процессы в ней участвуют. Для ответа на этот вопрос можно сконструировать графресурсов, как показано на рис. 7.3. Из рисунка видно, что имеется цикл, моделирующий условие кругового ожидания, и что процессы P2,P3,P5, а может быть, и другие находятся в тупиковой ситуации.

Рис. 7.3. Граф ресурсов
Визуально легко обнаружить наличие тупика, но нужны также формальные алгоритмы, реализуемые на компьютере.
Один из таких алгоритмов описан в [Таненбаум, 2002], там же можно найти ссылки на другие алгоритмы.
Существуют и другие способы обнаружения тупиков, применимые также в ситуациях, когда имеется несколько ресурсов каждого типа. Так в [Дейтел, 1987] описан способ, называемый редукцией графа распределения ресурсов, а в [Таненбаум, 2002] – матричный алгоритм.
Восстановление после тупиков
Обнаружив тупик, можно вывести из него систему, нарушив одно из условий существования тупика. При этом, возможно, несколько процессов частично или полностью потеряют результаты проделанной работы.
Сложность восстановления обусловлена рядом факторов.
В большинстве систем нет достаточно эффективных средств, чтобы приостановить процесс, вывести его из системы и возобновить впоследствии с того места, где он был остановлен.
Если даже такие средства есть, то их использование требует затрат и внимания оператора.
Восстановление после тупика может потребовать значительных усилий.
Самый простой и наиболее распространенный способ устранить тупик – завершить выполнение одного или более процессов, чтобы впоследствии использовать его ресурсы. Тогда в случае удачи остальные процессы смогут выполняться. Если это не помогает, можно ликвидировать еще несколько процессов. После каждой ликвидации должен запускаться алгоритм обнаружения тупика.
По возможности лучше ликвидировать тот процесс, который может быть без ущерба возвращен к началу (такие процессы называются идемпотентными). Примером такого процесса может служить компиляция. С другой стороны, процесс, который изменяет содержимое базы данных, не всегда может быть корректно запущен повторно.
В некоторых случаях можно временно забрать ресурс у текущего владельца и передать его другому процессу. Возможность забрать ресурс у процесса, дать его другому процессу и затем без ущерба вернуть назад сильно зависит от природы ресурса. Подобное восстановление часто затруднительно, если не невозможно.
В ряде систем реализованы средства отката и перезапуска или рестарта с контрольной точки (сохранение состояния системы в какой-то момент времени). Если проектировщики системы знают, что тупик вероятен, они могут периодически организовывать для процессов контрольные точки. Иногда это приходится делать разработчикам прикладных программ.
Когда тупик обнаружен, видно, какие ресурсы вовлечены в цикл кругового ожидания. Чтобы осуществить восстановление, процесс, который владеет таким ресурсом, должен быть отброшен к моменту времени, предшествующему его запросу на этот ресурс.
Заключение
Возникновение тупиков является потенциальной проблемой любой операционной системы. Они возникают, когда имеется группа процессов, каждый из которых пытается получить исключительный доступ к некоторым ресурсам и претендует на ресурсы, принадлежащие другому процессу. В итоге все они оказываются в состоянии бесконечного ожидания.
С тупиками можно бороться, можно их обнаруживать, избегать и восстанавливать систему после тупиков. Однако цена подобных действий высока и соответствующие усилия должны предприниматься только в системах, где игнорирование тупиковых ситуаций приводит к катастрофическим последствиям.
78. Способы управления периферийными устройствами. Драйверы устройств ввода – вывода
Одной из главных функций ОС является управление всеми устройствами ввода-вывода компьютера. ОС должна передавать устройствам команды, перехватывать прерывания и обрабатывать ошибки; она также должна обеспечивать интерфейс между устройствами и остальной частью системы. В целях развития интерфейс должен быть одинаковым для всех типов устройств (независимость от устройств).
Подсистема Управление периферийными устройствами (УПУ) предназначена для выполнения следующих функций:
· передачи информации между ПУ и ОП, то есть ввод/вывод информации;
· слежения за состоянием периферийных устройств;
· обеспечения интерфейса между устройствами, а также подключения и отключения периферийных устройств и поддержки схемы распределения устройств;<
· модификации конфигурации;
· обработки ошибок.
Физическая организация периферийных устройств
В общем случае ПУ называют средство ввода/вывода, способное осуществлять передачу информации между ЦП или ОП компьютера и внешними носителями информации. Многообразие внешних носителей и способов кодирования информации обусловили существование большого числа периферийных различных устройств, каждое из которых характеризуется:
· быстродействием;
· порцией обмена информации (1 бит, байт, слово, сектор, трек);
· системой кодирования;
· набором операций управления устройством.
Внешнее устройство состоит из механической и электронной компонент, и узким местом является механическая часть.
Постоянная забота об эффективном использовании ЦП, снижении его простоев во время выполнения операций ввода/вывода привели к росту автономии устройств ввода/вывода и появлению специализированных процессоров ввода/вывода, называемыхканалами (chanel).
Канал ввода/вывода (КВВ) - это специализированный процессор, осуществляющий обмен данными между ОП и ПУ и работающий независимо от ЦП. В системах ввода/вывода с каналами ЦП лишь запускает операцию ввода/вывода и по окончании ввода/вывода через прерывания от канала уведомляется об окончании операции ввода/вывода.
КВВ решают проблему различного быстродействия ЭВМ и устройств ввода/вывода. Канал может управлять одним устройством с высокой пропускной способностью (типа дисковода) или быть распределенным между несколькими устройствами с меньшей пропускной способностью (это, например, модемы). Обычно к каналу подключается совокупность быстродействующих или медленно действующих устройств, которыми канал управляет поочередно или одновременно.
По способам параллельного выполнения запросов ЦП на ввод/вывод каналы ввода/вывода подразделяются на три типа:
1.Байт-мультиплексные каналы, допускающие одновременный побайтовый обмен с несколькими медленными устройствами.
2. Селекторные каналы, допускающие поочередный, быстрый обмен с ПУ блоками ввода/вывода, каждый из которых имеет свой адрес.
3. Блок-мультиплексные каналы, допускающие одновременный блочный обмен данными с несколькими устройствами.
Как мы уже замечали, КВВ решает только проблему различия быстродействия ПУ и ЦП. Для решения же проблемы стандартного интерфейса ПУ с внутрисистемной шиной (магистралью) ЭВМ предназначено устройство управления (УУ) ПУ, называемое контроллером или адаптером устройства.
Контроллер ПУ - устройство управления, обеспечивающее стандартный интерфейс и подключение ПУ к системным магистралям ЭВМ. Если интерфейс между контроллером и устройством стандартизован, то независимые производители могут выпускать совместимые как контроллеры, так и устройства.
Контроллеры бывают как групповые, так и одиночные. Групповые контроллеры обеспечивают подключение группы однотипных устройств. Такие контроллеры обеспечивают в каждый момент времени передачу информации с одним устройством с одновременным выполнением других операций, не связанных с передачей данных, других устройств (например, перемотку магнитной ленты, перемещение головки НМД).
Разделение функций между контроллером и периферийным устройством зависит от типа ПУ: логические функции (соединение и синхронизация операций, передача сигналов об окончании операции или исключительных ситуациях) выполняются контроллером, афизические (передача данных) - периферийным устройством.
Операционная система обычно взаимодействует не с устройством, а с контроллером. Контроллер, как правило, выполняет простые функции, например, преобразует поток бит в блоки, состоящие из байт, и осуществляют контроль и исправление ошибок. Каждый контроллер имеет несколько регистров, которые используются для взаимодействия с центральным процессором. В некоторых компьютерах такие регистры являются частью физического адресного пространства, а специальные операции ввода-вывода отсутствуют. В других компьютерах адреса регистров ввода-вывода, называемых часто портами, образуют собственное адресное пространство за счет введения специальных операций ввода-вывода:
· регистр управления и состояния, через который ЭВМ задает команды ПУ и получает информацию о его состоянии и результатах выполнения команды;
· регистр данных, через который передается байт в коде ЭВМ.
ОС выполняет ввод-вывод, записывая команды в регистры контроллера. Например, контроллер гибкого диска IBM PC принимает 15 команд, таких, как READ, WRITE, SEEK,FORMAT и т.д. Когда команда принята, процессор оставляет контроллер и занимается другой работой. При завершении команды контроллер организует прерывание для того, чтобы передать управление процессору операционной системы, которая должна проверить результаты операции. Процессор получает результаты и статус устройства, читая информацию из регистров контроллера.
В настоящее время распространены три основные схемы организации ввода/вывода, соответствующие конфигурациям микро-, мини- и больших ЭВМ
В этой конфигурации шина разделяется между различными устройствами и выполняется побайтная передача информации между ЦП и памятью. Память подключается непосредственно на специализируемую магистраль.
УПДП - устройство прямого доступа памяти (DMA-direct memory access) обеспечивает пересылку блоков данных независимо от ЦП и упрощает канал ввода/вывода.
На больших ЭВМ контроллер может быть связан с несколькими каналами ввода/вывода, а периферийное устройство - с несколькими контроллерами.
Контроллер может иметь несколько адресов и путей доступа.
Адресация периферийных устройств на больших ЭВМ осуществляется составным адресом, включающим: номер канала, номер котроллера, номер устройства на контроллере:
0 0 F
№ канала №контр. № устройства.
В мини- и микро- ЭВМ для адресации устройств используются зарезервированные ячейки памяти.
Доступ к периферийным устройствам здесь осуществляется как обычный доступ к ячейкам ОП, что значительно упрощает программирование ввода/вывода.
Организация программного обеспечения ввода-вывода
Основная идея организации программного обеспечения ввода-вывода состоит в разбиении его на несколько уровней, причем нижние уровни обеспечивают экранирование особенностей аппаратуры от верхних, а те в свою очередь обеспечивают удобный интерфейс для пользователей.
Ключевым принципом является независимость от устройств. Вид программы не должен зависеть от того, читает ли она данные с гибкого диска или с жесткого диска. Очень близкой к идее независимости от устройств является идея единообразного именования, то есть для именования устройств должны быть приняты единые правила.
Другим важным вопросом для программного обеспечения ввода-вывода является обработка ошибок. Вообще говоря, ошибки следует обрабатывать как можно ближе к аппаратуре. Если контроллер обнаруживает ошибку чтения, то он должен попытаться ее скорректировать. Если же это ему не удается, то исправлением ошибок должен заняться драйвер устройства. Многие ошибки могут исчезать при повторных попытках выполнения операций ввода-вывода, например, ошибки, вызванные наличием пылинок на головках чтения или на диске. И только если нижний уровень не может справиться с ошибкой, он сообщает об ошибке верхнему уровню.
Еще один ключевой вопрос - это использование блокирующих (синхронных) и неблокирующих (асинхронных) передач. Большинство операций физического ввода-вывода выполняется асинхронно - процессор начинает передачу и переходит на другую работу, пока не наступает прерывание. Пользовательские программы намного легче писать, если операции ввода-вывода блокирующие - после команды READ программа автоматически приостанавливается до тех пор, пока данные не попадут в буфер программы. ОС выполняет операции ввода/вывода асинхронно, но представляет их для пользовательских программ в синхронной форме.
Последняя проблема состоит в том, что одни устройства являются разделяемыми, а другие - выделенными. Диски - это разделяемые устройства, так как одновременный доступ нескольких пользователей к диску не представляет собой проблему. Принтеры - это выделенные устройства, потому что нельзя смешивать строчки, печатаемые различными пользователями. Наличие выделенных устройств создает для операционной системы некоторые проблемы. Для решения поставленных проблем целесообразно разделить программное обеспечение ввода-вывода на четыре слоя:
1. Независимый от устройств слой операционной системы.
2. Обработка прерываний.
3. Драйверы устройств.
4. Пользовательский слой программного обеспечения.
Независимый от устройств слой операционной системы
Это компонент представляет собой супервизор ввода/вывода, через который процессы пользователя получают доступ к операциям ввода/вывода.
Точная граница между драйверами и независимыми от устройств программами определяется системой, так как некоторые функции, которые могли бы быть реализованы независимым способом, в действительности выполнены в виде драйверов для повышения эффективности или по другим причинам.
Типичными функциями для независимого от устройств слоя являются:
· обеспечение общего интерфейса к драйверам устройств;
· именование устройств;
· защита устройств;
· обеспечение независимого размера блока;
· буферизация;
· распределение памяти на блок-ориентированных устройствах;
· распределение и освобождение выделенных устройств;
· уведомление об ошибках;
· прием запросов на ввод/вывод от пользователей процессов;
· создание и обслуживание очереди запросов на ввод/вывод;
· обеспечивание запуска драйверов и их динамическую загрузку;
· обработка прерывания ввода/вывода.
Остановимся на некоторых функциях данного перечня. Верхним слоям программного обеспечения неудобно работать с блоками разной величины, поэтому данный слой обеспечивает единый размер блока, например, за счет объединения нескольких различных блоков в единый логический блок. В связи с этим верхние уровни имеют дело с абстрактными устройствами, которые используют единый размер логического блока независимо от размера физического сектора.
При создании файла или заполнении его новыми данными необходимо выделить ему новые блоки. Для этого ОС должна вести список или битовую карту свободных блоков диска. На основании информации о наличии свободного места на диске может быть разработан алгоритм поиска свободного блока, независимый от устройства и реализуемый программным слоем, находящимся выше слоя драйверов.
Обработка прерываний
Прерывания должны быть скрыты как можно глубже в недрах операционной системы, чтобы как можно меньшая часть ОС имела с ними дело. Наилучший способ состоит в разрешении процессу, инициировавшему операцию ввода-вывода, блокировать себя до завершения операции и наступления прерывания. Процесс может блокировать себя, используя, например, вызов DOWN для семафора, или вызов WAIT для переменной условия, или вызов RECEIVE для ожидания сообщения. При наступлении прерывания процедура обработки прерывания выполняет разблокирование процесса, инициировавшего операцию ввода-вывода, используя вызовы UP, SIGNAL или посылая процессу сообщение. В любом случае эффект от прерывания будет состоять в том, что ранее заблокированный процесс теперь продолжит свое выполнение.
Драйверы устройств
Драйвером устройства называется программа управления функционированием периферийными устройствами, которая выполняет следующие функции:
· управление интерфейсом контроллера ПУ;
· обработку передаваемых через супервизор прерываний;
· обнаружение и обработка ошибок.
Весь зависимый от устройства код помещается в драйвер устройства. Каждый драйвер управляет устройствами одного типа или, может быть, одного класса. В операционной системе только драйвер устройства знает о конкретных особенностях какого-либо устройства. Например, только драйвер диска имеет дело с дорожками, секторами, цилиндрами, временем установления головки и другими факторами, обеспечивающими правильную работу диска.
Драйвер устройства принимает запрос от супервизора или программного слоя и решает, как его выполнить. Типичным запросом является чтение n блоков данных. Если драйвер был свободен во время поступления запроса, то он начинает выполнять запрос немедленно. Если же он был занят обслуживанием другого запроса, то вновь поступивший запрос присоединяется к очереди уже имеющихся запросов, и он будет выполнен, когда наступит его очередь. С точки зрения пользователя, драйверы являются невидимыми, так как пользователи получают доступ к вводу/выводу через супервизор с применением функций и команд ввода/вывода используемых систем программирования.
Первый шаг в реализации запроса ввода-вывода, например, для диска, состоит в преобразовании его из абстрактной формы в конкретную. Для дискового драйвера это означает преобразование номеров блоков в номера цилиндров, головок, секторов, проверку, работает ли мотор, находится ли головка над нужным цилиндром. Короче говоря, он должен решить, какие операции контроллера нужно выполнить и в какой последовательности.
После передачи команды контроллеру драйвер должен решить, блокировать ли себя до окончания заданной операции или нет. Если операция занимает значительное время, как при печати некоторого блока данных, то драйвер блокируется до тех пор, пока операция не завершится, и обработчик прерывания не разблокирует его. Если команда ввода-вывода выполняется быстро (например, прокрутка экрана), то драйвер ожидает ее завершения без блокирования. Драйверы могут работать с периферийными устройствами тремя основными способами:
· по опросу готовности;
· по прерываниям;
· по прямому доступу к памяти.
По опросу готовности драйвер выполняет следующие действия:
1. Запрещает прерывания от устройства и инициирует операцию на устройстве.
2. Переходит в состояние ожидания.
3. Циклически проверяет завершенность операции.
4. Дождавшись завершения операции, проверяет отсутствие ошибки при ее выполнении, разрешает прерывания и возвращает управление прерванному процессу.
По опросу готовности реализуется синхронный ввод/вывод, при котором отсутствует параллелизм между обработкой и передачей информации. ЦП находится в активном ожидании завершения операции ввода/вывода. Такой способ работы драйверов используется в однопрограммных однопользовательских ОС.
Достоинство - простота. Недостаток - синхронный ввод/вывод, отсутствие параллелизма между вводом/выводом и обработкой.
При работе по прерываниям действия выполняются в следующей последовательности:
1. Инициализируется операция ввода/вывода и разрешает прерывания от устройства.
2. Возвращает управление ЦП для выполнения других действий до момента прерывания.
3. При прерывании происходит переход на программу обработки, в которой проверяется отсутствие ошибки ввода/вывода, и после завершения обработки осуществляется возврат на прерванную программу.
Достоинство - асинхронный ввод/вывод, то есть параллельная работа ЦП и ПУ. Используется в мультипрограммных системах.
При работе по прямому доступу к памяти (ПДП) (Direct Memory Access-DMA)действия выполняются в следующем порядке:
1. ЦП запускает канальную программу командой "запустить канал", которая содержит адрес канала и периферийного устройства. С этого момента канал и ЦП работают параллельно.
2. Канал выполняет свою программу, которая заканчивается нормально либо с ошибкой, либо по команде ЦП "остановить канал".
3. В любой момент ЦП может проверить состояние канала, выполняющего канальную программу, командой "тестировать канал". Эта проверка не влияет на выполнение программы. Обработка ошибок ввода/вывода здесь осуществляется супервизором ввода/вывода.
Пользовательский слой программного обеспечения
Хотя большая часть программного обеспечения ввода-вывода находится внутри ОС, некоторая его часть содержится в библиотеках, связанных с пользовательскими программами. Системные вызовы, включающие вызовы ввода-вывода, обычно делаются библиотечными процедурами. Если программа, написанная на языке С, содержит вызовcount = write (fd, buffer, nbytes), то библиотечная процедура write будет связана с программой. Набор подобных процедур является частью системы ввода-вывода. В частности, форматирование ввода или вывода выполняется библиотечными процедурами. Примером может служить функция printf языка С, которая принимает строку формата и, возможно, некоторые переменные в качестве входной информации, затем строит строку символов ASCII и делает вызов write для вывода этой строки. Стандартная библиотека ввода-вывода содержит большое число процедур, которые выполняют ввод/вывод и работают как часть пользовательской программы.
Другой категорией программного обеспечения ввода/вывода является подсистемаспулинга (spooling). Спулинг - это способ работы с выделенными устройствами в мультипрограммной системе. Рассмотрим типичное устройство, требующее спулинга - строчный принтер. Хотя технически легко позволить каждому пользовательскому процессу открыть специальный файл, связанный с принтером, такой способ опасен из-за того, что пользовательский процесс может монополизировать принтер на произвольное время. Вместо этого создается специальный процесс - монитор, который получает исключительные права на использование этого устройства. Также создается специальный каталог, называемый каталогом спулинга. Для того чтобы напечатать файл, пользовательский процесс помещает выводимую информацию в этот файл и помещает его в каталог спулинга. Процесс-монитор по очереди распечатывает все файлы, содержащиеся в каталоге спулинга.
В ОС MS-DOS стандартный набор ПУ поддерживается базовой системой ввода/вывода (БСВВ), расположенной в ПЗУ, в числе прочих задач выполняет функции обслуживания системных вызовов и прерываний. Дополнительные устройства MS-DOS поддерживаются модулем расширенной системы ввода/вывода, посредством перечисления в файле конфигурации CONFIG.SYS дополнительных драйверов в формате команды
DEVICE = [ путь ] имя файла [ параметры] .
80. Семафоры. Решение проблемы производителя и потребителя с помощью семафоров
Семафоры
Одним из первых механизмов, предложенных для синхронизации поведения процессов, стали семафоры, концепцию которых описал Дейкстра (Dijkstra) в 1965 году.
Концепция семафоров
Семафор представляет собой целую переменную, принимающую неотрицательные значения, доступ любого процесса к которой, за исключением момента ее инициализации, может осуществляться только через две атомарные операции: P (от датского слова proberen – проверять) и V (от verhogen – увеличивать). Классическое определение этих операций выглядит следующим образом:
P(S): пока S == 0 процесс блокируется;
S = S – 1;
V(S): S = S + 1;
Эта запись означает следующее: при выполнении операции P над семафором S сначала проверяется его значение. Если оно больше 0, то из S вычитается 1. Если оно меньше или равно 0, то процесс блокируется до тех пор, пока S не станет больше 0, после чего из S вычитается 1. При выполнении операции V над семафором S к его значению просто прибавляется 1. В момент создания семафор может быть инициализирован любым неотрицательным значением.
Подобные переменные-семафоры могут с успехом применяться для решения различных задач организации взаимодействия процессов. В ряде языков программирования они были непосредственно введены в синтаксис языка (например, в ALGOL-68), в других случаях реализуются с помощью специальных системных вызовов. Соответствующая целая переменная располагается внутри адресного пространства ядра операционной системы. Операционная система обеспечивает атомарность операций P и V, используя, например, метод запрета прерываний на время выполнения соответствующих системных вызовов. Если при выполнении операции P заблокированными оказались несколько процессов, то порядок их разблокирования может быть произвольным, например, FIFO.
Решение проблемы producer-consumer с помощью семафоров
Одной из типовых задач, требующих организации взаимодействия процессов, является задача producer-consumer (производитель-потребитель). Пусть два процесса обмениваются информацией через буфер ограниченного размера. Производитель закладывает информацию в буфер, а потребитель извлекает ее оттуда. На этом уровне деятельность потребителя и производителя можно описать следующим образом.
Producer: while(1) {
produce_item;
put_item;
}
Consumer: while(1) {
get_item;
consume_item;
}
Если буфер заполнен, то производитель должен ждать, пока в нем появится место, чтобы положить туда новую порцию информации. Если буфер пуст, то потребитель должен дожидаться нового сообщения. Как можно реализовать эти условия с помощью семафоров? Возьмем три семафора: empty, full и mutex. Семафор full будем использовать для гарантии того, что потребитель будет ждать, пока в буфере появится информация. Семафор empty будем использовать для организации ожидания производителя при заполненном буфере, а семафор mutex – для организации взаимоисключения на критических участках, которыми являются действия put_item и get_item (операции "положить информацию" и "взять информацию" не могут пересекаться, так как в этом случае возникнет опасность искажения информации). Тогда решение задачи на C-подобном языке выглядит так:
Semaphore mutex = 1;
Semaphore empty = N; /* где N – емкость буфера*/
Semaphore full = 0;
Producer:
while(1) {
produce_item;
P(empty);
P(mutex);
put_item;
V(mutex);
V(full);
}
Consumer:
while(1) {
P(full);
P(mutex);
get_item;
V(mutex);
V(empty);
consume_item;
}
Легко убедиться, что это действительно корректное решение поставленной задачи. Попутно заметим, что семафоры использовались здесь для достижения двух целей: организации взаимоисключения на критическом участке и взаимосинхронизации скорости работы процессов.
82. Прямой и обратный методы вывода
При обратном порядке вывода вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам, пытаясь найти те, которые подтверждают гипотезу (рис. 1.5, правая часть). Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями, или управляемым консеквентами. Обратный поиск применяется в тех случаях, когда цели известны и их сравнительно немного.
 .
.
Рис. 1.5. Стратегии вывода
В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует (см. рис. 1.5, левая часть). Если такое заключение удается найти, то оно заносится в рабочую память. Прямой вывод часто называют выводом, управляемым данными, или выводом, управляемым антецедентами. Существуют системы, в которых вывод основывается на сочетании упомянутых выше методов – обратного и ограниченного прямого. Такой комбинированный метод получил название циклического.
Пример 2.5
Имеется фрагмент базы знаний из двух правил:
Ш. Если «отдых – летом» и «человек – активный», то «ехать в горы».
П2. Если «любит солнце», то «отдых летом». Предположим, в систему поступили факты – «человек активный» и «любит солнце».
ПРЯМОЙ ВЫВОД – исходя из фактических данных, получить рекомендацию.
1-й проход.
Шаг 1. Пробуем П1, не работает (не хватает данных «отдых – летом»).
Шаг 2. Пробуем П2, работает, в базу поступает факт «отдых – летом».
2-й проход.
Шаг 3. Пробуем П1, работает, активируется цель «ехать в горы», которая и выступает как совет, который дает ЭС.
ОБРАТНЫЙ ВЫВОД – подтвердить выбранную цель при помощи имеющихся правил и данных. 1-й проход.
Шаг 1. Цель – «ехать в горы»: пробуем П1 – данных «отдых – летом» нет, они становятся, новой целью и ищется правило, где цель в левой части.
Шаг 2. Цель «отдых – летом»: правило П2 подтверждает цель и активирует ее. 2-й проход. Шаг 3. Пробуем Ш, подтверждается искомая цель.