

Алгоритм удаление записи из цепочки подчиненного файла.
Ищем удаляемую запись в соответствии с ранее рассмотренным алгоритмом. Отличием при этом является обязательное сохранение в специальной переменной номера предыдущей записи в цепочке (NP).
Запоминаем в специальной переменной указатель на следующую запись в найденной записи, заносим его в переменную NS. Переходим к шагу 3.
Помечаем специальным символом, например, символом «*» найденную запись, то есть в позиции указателя на следующую запись в цепочке ставим “*”. Это означает, что данная запись отсутствует, а место в файле свободно и может быть занято любой другой записью.
Переходим к записи с номером, который хранится в NP, и заменяем в ней указатель на содержимое переменной NS.
Для того чтобы эффективно использовать дисковое пространство при включении новой записи в подчиненный файл, ищется первое свободное место, то есть запись, помеченная символом “*”, и на ее место заносится новая запись. После этого производится модификация соответствующих указателей.
Инвертированные списки
До сих пор рассматривались структуры данных, которые использовались для ускорения доступа по первичному ключу. Однако достаточно часто в БД требуется проводить операции доступа по вторичным ключам. Возможно существование множества записей с одинаковыми значениями вторичного ключа. Например, в случае БД «Библиотека» вторичным ключом может служить место издания, год издания. Множество книг может быть издано в одном и том же месте.
Для обеспечения ускорения доступа по вторичным ключам используются структуры, называемые инвертированными списками, которые послужили основой организации индексных файлов для доступа по вторичным ключам.
Инвертированный список - это в общем случае двухуровневая индексная структура. Здесь на первом уровне находится файл или часть файла, в котором упорядоченно расположены значения вторичных ключей. Каждая запись с вторичным ключом имеет ссылку на номер первого блока в цепочке блоков, содержащих номера записей с данным значением вторичного ключа. На втором уровне находится цепочка блоков, содержащих номера записей, содержащих одно и тоже значение вторичного ключа. При этом блоки второго уровня упорядочены по значениям вторичного ключа.
И, наконец, на третьем уровне находится уже собственно файл. Механизм доступа по вторичному ключу заключается в следующем. На первом шаге ищем в области первого уровня заданное значение вторичного ключа, затем по ссылке считываем блоки второго уровня, содержащие номера записей с заданным значением вторичного ключа. Далее уже прямым доступом загружаем в рабочую область пользователя содержимое всех записей, содержащих заданное значение вторичного ключа. Размер блока ограничен 5-ю записями.
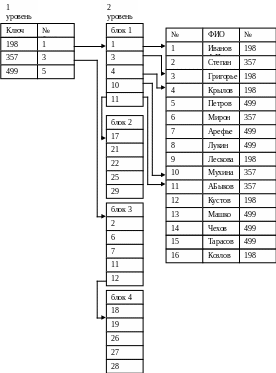
Пример инвертированного списка, составленного для вторичного ключа Номер группы в списке студентов некоторого учебного заведения.
К Рисунок 14 онтрольные вопросы
Какие файловые структуры используются для хранения данных во внешней памяти?
В чем заключаются различия между файлами прямого и последовательного доступа?
Что представляют собой индексные файлы? За счет чего повышается скорость обработки данных при использовании индексов?
Что содержится в основной и индексной области файлов с плотным индексом? Какие способы поиска применяются? Как осуществляется добавление, удаление записей?
Для каких файлов строится неплотный индекс? Что содержится в индексной области файлов с неплотным индексом?
Как выполняется включение новой записи в файл с неплотным индексом?
Как происходит удаление записи из файла с неплотным индексом?
Для каких областей задается процент первоначального заполнения блоков при использовании файлов с плотным и неплотным индексом?
Какова структура основного и подчиненного файла при использовании однонаправленных указателей для моделирования отношений 1:М?
Как организован поиск записей в подчиненном файле при использовании однонаправленных указателей?
Как происходит удаление записи из цепочки подчиненного файла?
Объясните принцип организации инвертированных списков и механизм поиска по вторичному ключу.