

5.4 Локальные шины
Вычислительные системы в последнее время становятся требовательны к быстродействию микропроцессоров и различных периферийных устройств, в связи с этим пропускная способность шин расширения перестала удовлетворять современным требованиям. Поэтому стали создавать локальные шины, которые подключаются к шине микропроцессора и работают на его тактовой частоте, обеспечивая связь с скоростными устройствами: основной и внешней памятью, видеосистемами и т. д. Все шины имеют общий недостаток - низкую пропускную способность, из-за того, что шины разрабатываются в расчете на медленные процессоры. Очевидным выходом из создавшегося положения является осуществление части операций обмена данными, требующих высоких скоростей, не через шину ввода/вывода, а через шину процессора.
Существуют три основных стандарта универсальных локальных шин: VLB, PCI и AGP.
Шина VLB (Vesa Local Bus)- 32-х разрядная шина, разработанная в 1992 году ассоциацией стандартов видеооборудования (VESA - Video Equipment Standards Associations) и по существу, является расширением внутренней шины микропроцессора для связи с: видеоадаптером, винчестером, сетевым адаптером и реальной скорости передачи данных - 80 Мбайт/с. Кроме того обладает следующими возможностями:
-поддержки и 16-разрядного обмена;
-использование пакетного режима обмена;
-слот VL-bus устанавливается в линию за слотами ISA/EISA/MCA, поэтому VL-платам доступны все линии этих шин;
-поддержка как интегрированного в процессор кэш, так и кэш на материнской плате;
-напряжение питания 5 В. Устройства с уровнем выходного сигнала 3,3 В поддерживаются при условии, что они могут работать с уровнем входного сигнала 5 В.
Появление локальной шины позволило устранить два узких места в системе: низкие скорости обмена данными с графической картой и жестким диском. Однако скоро выяснилось, что VESA - это сиюминутное решение, из-за большого перечня недостатков, которые и предопределили ее судьбу:
-ориентация только на микропроцессоры 80386, 80486 (не адаптирована для процессоров класса Pentium);
-жесткая зависимость от тактовой частоты микропроцессора (шина рассчитана на конкретную частоту до 33 МГц);
-малое количество подключаемых устройств (четыре устройства);
-отсутствует арбитраж шины – возникают конфликты между подключаемыми устройствами.
Шина PCI (Peripheral Component Interconnect) - самая распространенная и универсальная, разработана в 1993 году фирмой Intel и имеет следующие характеристики:
-число подключаемых устройств до 10;
-имеет адаптер позволяющий работать с любым микропроцессором (от 80486 до различных Pentium);
-32-х разрядная шина данных;
-32 разрядная шина адреса (расширяемая до 64 бит). При этом для уменьшения числа контактов используется мультиплексирование;
-модификация 2.1 локальной шины имеет пропускную способность до 528 Мбайт/с (на тактовой частоте до 66 МГц, при разрядности 64);
-поддержка режима Plug and Play, Bus Mastering и автоконфигурации;
-поддержка метода передачи данных, называемого linear burst (метод линейных пакетов). Этот метод предполагает, что пакет информации считывается (или записывается) одним куском. При этом увеличивается скорость передачи данных за счет уменьшения числа передаваемых адресов;
-использование отличного от ISA способа передачи данных – способа рукопожатия, который заключается в том, что в системе определяется два устройства: передающее и приемное. Когда передающее устройство готово к передаче, оно выставляет данные на линии данных и сопровождает их соответствующим сигналом, при этом приемное устройство записывает их в свои регистры и подает сигнал Target Ready, подтверждая запись данных и готовность к приему следующих. Установка всех сигналов производится строго в соответствии с тактовыми импульсами шины;
-относительная независимость отдельных компонентов системы. В соответствии с концепцией PCI передачей пакета данных управляет не CPU, а мост, включенный между ним и шиной PCI. Процессор может продолжать работу и тогда, когда происходит обмен данными с ОЗУ;
-низкая нагрузка на процессор;
-частота работы шины 33 МГц (66 МГц) позволяет обеспечить широкий диапазон пропускных способностей (с использованием пакетного режима): 132 МВ/сек при 32-bit/33 МГц; 264 MB/сек при 32-bit/66 МГц; 264 MB/сек при 64-bit/33 МГц; 528 МВ/сек при 64-bit/66 МГц;
-поскольку шина процессора и шина расширения PCI соединены с помощью главного моста, то последняя может работать с CPU последующих поколений;
-полная поддержка multiply bus master (например, несколько контроллеров жестких дисков могут одновременно работать на шине);
-поддержка 5В и 3,3В логики. Разъемы для 5 и 3,3 В плат различаются расположением ключей;
-спецификация шины позволяет комбинировать до восьми функций на одной карте (например, видео +звук и прочее);
-шина позволяет устанавливать до 4 слотов расширения, однако возможно использование моста PCI to PCI для увеличения их количества;
-PCI-устройства оборудованы таймером, который используется для определения максимального промежутка времени, в течении которого устройство может занимать шину.
Спецификация шины PCI определяет три типа ресурсов: два обычных (диапазон памяти и диапазон ввода/вывода и configuration space - конфигурационное пространство, которое состоит из трех регионов:
-заголовка, независимого от устройства (device-independent header region);
-региона, определяемого типом устройства (header-type region);
-региона, определяемого пользователем (user-defined region);
В заголовке содержится информация о производителе и типе устройства (сетевой адаптер, контроллер диска, мультимедиа и так далее) и прочая служебная информация.
Следующий регион содержит регистры диапазонов памяти и ввода/вывода, которые позволяют динамически выделять устройству область системной памяти и адресного пространства. В зависимости от реализации системы конфигурация устройств производится либо BIOS, либо программно. Базовый регистр expansion ROM аналогично позволяет отображать ROM устройства в системную память. Поле CIS PCMCIA. Последние 4 байта региона используются для определения прерывания и времени запроса/владения.
Разработчики шины поставили целью создание принципиально нового интерфейса, который бы не являлся усовершенствованиями других, не зависел от платформы (мог работать с будущими поколениями процессоров), имел высокую производительность. Благодаря отказу от использования шины процессора PCI оказалась процессоронезависимой и могла работать самостоятельно, не обращаясь к последней с запросами (процессор может работать с памятью, в то время как по шине PCI передаются данные). Основополагающим принципом шины PCI является применение мостов, которые осуществляют связь шины с другими компонентами системы. Другой особенностью является реализация принципов Bus Master и Bus Slave (карта PCI-Master может как считывать данные из оперативной памяти, так и записывать их туда без обращения к процессору, PCI-Slave - только считывать данные).
В настоящее время используется 32-разрядная шина PCI, работающая на частоте 33 МГц. Но получающихся при этом 132 Мбайт/с начинает нехватать, поэтому в ближайшем будущем будут использоваться более скоростные стандарты PCI (33-мегагерцевая 64-разрядная шина, так как не все карты, предназначенные для работы на 33 мегагерцах, смогут работать на 66).
К локальной PCI шине, имеющей несколько разъемов, можно подключить ряд устройств: видеокарты, звуковые карты, модемы, контроллеры SCSI и др. Конструктивно разъем шины состоит из двух секций по 64 контакта.
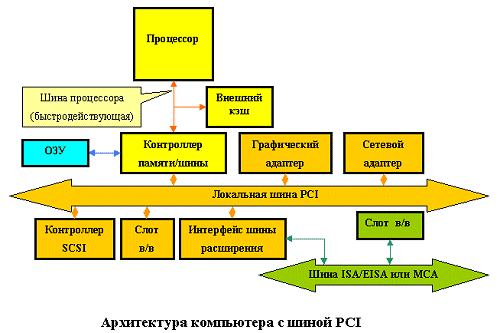
Рисунок 5- Конфигурация системы с шиной PCI
Шина PCI выполняет и многие функции шины расширения (ISA, EISA, MCA). Все устройства подключаются к шине, а не к микропроцессору, как у шины VLB, что позволяет существенно снизить загрузку микропроцессора, так как она может работать параллельно с шиной процессора, не обращаясь к ней за запросами.
В последнее время большое распространение получила 3D-графика, кроме того возросла нагрузка на PCI со стороны жестких дисков, сетевых карт и других устройств. Все это привело к тому, что пропускной способности локальной шины стало недоставать. В связи с этим компания Intel на базе того стандарта (PCI R2.1) разрабатывает новую шину - AGP (1.0, затем 2.0.
В результате пропускная способность шины составила 500 МВ/сек, и предназначалась для того, чтобы графические карты могли хранить необходимые данные не только в своей локальной памяти, установленной на карте, но и в дешевой системной памяти компьютера. При этом карты могли иметь меньший объем локальной памяти и дешевле стоить.
Шина AGP (Accelerated Graphics Port - ускоренный графический порт) - имеет выход на системную память и предназначена для подключения видеоадаптера и обладает следующими основными характеристиками:
-частота системной шины до 133 МГц;
-шина способна передавать два блока данных за один 66 МГц цикл (AGP 2x);
-пиковая пропускная способность 1066 Мбайт/с (в режиме четырехкратного умножения AGP4x т.е. при передаче четырех блоков данных за такт), в режиме восьмикратного умножения AGP8x - 2112 Мбайт/с.
-отсутствует мультиплексированность линий адреса и данных (в PCI для удешевления конструкции адрес и данные передаются по одним и тем же линиям);
-доработана конвейеризация операций чтения/записи (позволяет устранить влияние задержек в модулях памяти на скорость выполнения операций);
-шина PCI 1.0 использует два режима работы: DMA и Execute.
В режиме DMA основной памятью является память карты. Текстуры хранятся в системной памяти, но перед использованием копируются в локальную память карты. Таким образом, AGP действует в качестве структуры, обеспечивающей своевременную доставку текстур в локальную память. Обмен ведется большими последовательными пакетами.
В режиме Execute локальная и системная память для видеокарты логически равноправны. Текстуры не копируются в локальную память, а выбираются непосредственно из системной. Таким образом, приходится выбирать из памяти относительно малые случайно расположенные куски. Поскольку системная память выделяется динамически, блоками по 4 Кb, в этом режиме для обеспечения приемлемого быстродействия необходимо предусмотреть механизм, отображающий последовательные адреса на реальные адреса 4-х килобайтных блоков в системной памяти. Эта задача выполняется путем использования специальной таблицы (GART), расположенной в памяти.
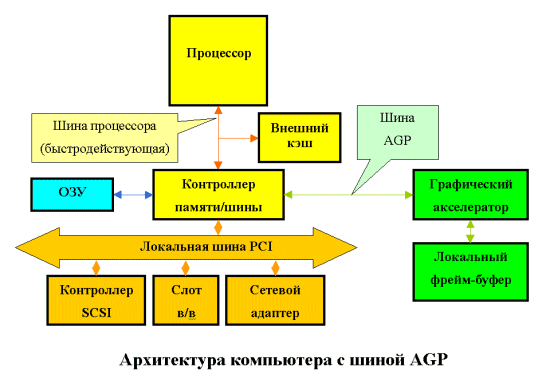
Рисунок 6- Конфигурация системы с шиной AGP
Принципиально AGP - это вторая магистраль PCI, которая соединена с другими компонентами системы специальным мультимедиа-мостом (Multimedia Bridge).
Шина AGP полностью поддерживает операции шины PCI, поэтому AGP-трафик может представлять из себя смесь чередующихся AGP и PCI операций чтения/записи. Операции шины AGP являются раздельными (запрос на проведение операции отделен от собственно пересылки данных). Такой подход позволяет AGP-устройству генерировать очередь запросов, не дожидаясь завершения текущей операции, что также повышает быстродействие шины.
В 1998 году спецификация шины AGP получила развитие - вышел Revision 2.0. В результате использования новых низковольтных электрических спецификаций появилась возможность осуществлять 4 транзакции (пересылки блока данных) за один 66-мегагерцовый такт (AGP 4x), что дает пропускную способность шины в 1Gb/s.
Однако потребности и запросы в области обработки видеосигналов все возрастают, и Intel приготовила новую спецификацию - AGP Pro, причем новый стандарт не видоизменяет шину AGP. Основное направление - увеличение энергоснабжения графических карт. С этой целью в разъем AGP Pro добавлены новые линии питания.
Существует два типа карт: AGP Pro - High Power и Low Power. Карты High Power могут потреблять от 50 до 110 W (нуждаются в хорошем охлаждении). С этой целью спецификация требует наличия двух свободных слотов PCI с component side (стороны, на которой размещены основные чипы карты). Причем данные слоты могут использоваться картой как дополнительные крепления, для подвода дополнительного питания.
Карты Low Power могут потреблять 25-50 W, поэтому для обеспечения охлаждения спецификация требует наличия только одного свободного слота PCI. В разъем AGP Pro, естественно, можно устанавливать и обычные карты AGP. С начала 2001-го года слоты AGP Pro начал вытеснять обычный AGP.