

Вызов стартовой панели модуля и определение анализа
Для начала статистического анализа вам необходимо вызвать Стартовую панель модуля. Это основное диалоговое окно модуля, в котором необходимо задать различные опции анализа. Если Стартовая панель модуля закрыта, то откройте её. Для этого войдите в меню Analysis — Анализ и выберите команду Startup Panel — Стартовая панель.
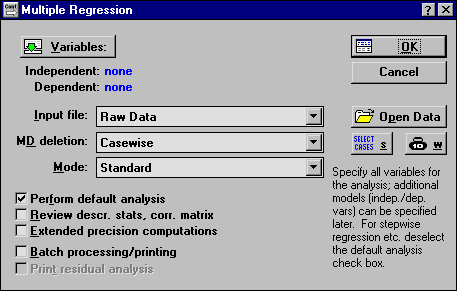
Рисунок 2.10. Стартовая панель модуля позволяет определить процедуру анализа. С её помощью можно также открыть данные, выбрать необходимое подмножество случаев для анализа и приписать вес переменным
Выбор переменных для анализа
Далее необходимо выбрать переменные для анализа. В нашем примере имеется одна зависимая переменная Цена_Лог и одна независимая переменная Возраст. Для их задания воспользуйтесь кнопкой Variables — Переменные из Стартовой панели.
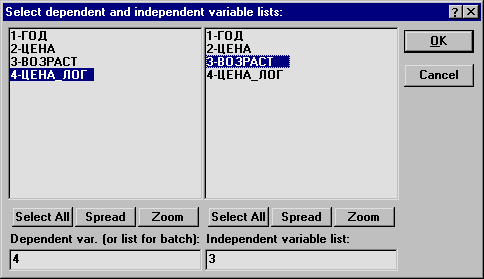
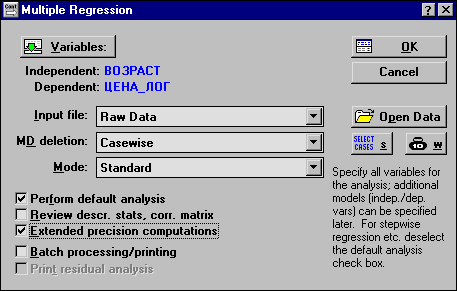
Рисунок 2.11 Диалоговые окна выбора переменных для анализа. Вид стартовой панели после выбора переменных
В открывшемся окне Select dependent and independent variable list — Выбор зависимой переменной и списка независимых переменных в качестве зависимой переменной выберите переменную с номером 4 — ЦЕНА_ЛОГ, а в качестве независимой переменной переменную с номером 3 — ВОЗРАСТ. Нажмите кнопку (Ж в правом верхнем углу. Вы вновь окажетесь в Стартовой панели модуля Множественная регрессия.
Задание дополнительных параметров анализа
Заметьте, что в Стартовой панели вы можете задать и дополнительные опции и параметры анализа. Например, вы можете выбрать определенное подмножество случаев для анализа, приписать вес переменным — эти опции относятся к исходным данным. Вы также можете задать и опции, которые относятся непосредственно к статистической процедуре: задать правило обработки пропущенных данных, выбрать метод анализа по умолчанию и др. Мы выбрали опцию — Расчет с расширенной точностью и выбор метода по умолчанию. Выбор этих опций не является необходимым.
Вывод результатов и их анализ
В стартовой панели нажмите на кнопку ОК. Система произведет вычисления, и через секунду окно результатов появится на вашем экране.
Окно результатов анализа имеет следующую простую структуру: верхняя часть окна — информационная, нижняя содержит функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа.
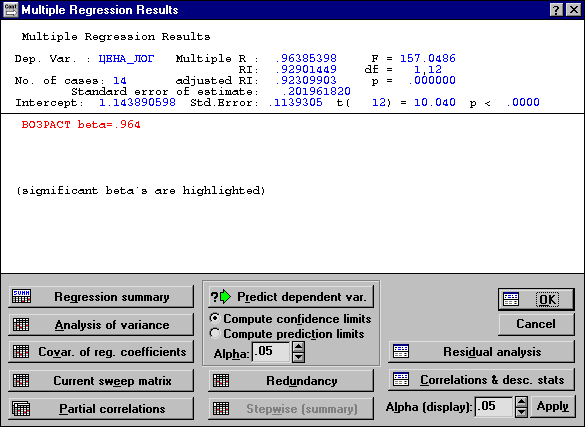
Рисунок 2.12 Окно результатов анализа
Информационная часть
Рассмотрим вначале информационную часть окна. В ней содержится краткая информация о проведенном анализе. А именно, следующая информация:
Dep. Var. — Имя зависимой переменной. В нашем случае — Цена _Лог.
No. of Cases — Число случаев, по которым построена регрессия. В примере число равно 14.
Multiple R — Коэффициент множественной корреляции (эта статистика полезна в множественной регрессии, когда вы хотите описать зависимости между переменными).
R-square — RI - Квадрат коэффициента множественной корреляции, обычно называемый коэффициентом детерминации. Коэффициент детерминации является одной из основных статистик в данном окне, он показывает долю общего разброса (относительно выборочного среднего зависимой переменной), которая объясняется построенной регрессией.
Adjusted R-square: adjusted Rl — Скорректированный коэффициент детерминации, определяемый как:
usted R-square = 1 - (1 - R-square)*( n/(n - p)),
где n — число наблюдений в модели, p — число параметров модели (число независимых переменных плюс 1 из-за свободного члена).
Std. Error of estimate — Стандартная ошибка оценки. Эта статистика является мерой рассеяния наблюдаемых значений относительно регрессионной прямой.
Intercept — Оценка свободного члена регрессии. Значение коэффициента b0 в уравнении регрессии.
Std. Error — Стандартная ошибка оценки свободного члена. Стандартная ошибка коэффициента b0 в уравнении регрессии.
t(df) and p-value — Значение t-критерия и уровня р. t-критерий используется для проверки гипотезы о равенстве 0 свободного члена регрессии.
F — Значения F критерия.
df— Число степеней свободы F критерия.
р — Уровень значимости.
В информационной части вы прежде всего смотрите на значение коэффициента детерминации. В нашем примере RI = 0.929... Это значит, что построенная регрессия объясняет 92.9% разброса значений ЦЕНА_ ЛОГ относительно среднего. Это хороший результат.
Далее вы смотрите на значение F - критерия и уровень его значимости р. F - критерий используется для проверки значимости регрессии. В данном случае для проверки гипотезы, утверждающей, что между зависимой переменной ЦЕНА_ ЛОГ и независимой переменной ВОЗРАСТ нет линейной зависимости, т. е. b1 = 0, против альтернативы b1 не равен 0. В данном примере большое значение F-критерия = 157.0486 и даваемый в окне уровень значимости р = 0.0000 показывают, что построенная регрессия высоко значима.