

Приклад виконання роботи
Отримано набір статистичних даних, що характеризують залежність прибутку підприємства (у, тис.грн.) від виробничих витрат (х1, тис.грн.) і середньорічних залишків запасів (х2, тис.грн.) та середньої кількості працівників (х3, чол.). Перевірити на наявність мультиколінераності залежність у = f(x1,x2,х3) і знайти методи її усунення.
Таблиця з вхідними даними
Прибуток підприємства (у, тис.грн.) |
Виробничі витрати (х1, тис.грн.) |
Середньорічні залишки запасів (х2, тис.грн |
Середня кількость працівників (x3, чол.). |
4,2 |
6,9 |
6 |
200 |
1,5 |
2,9 |
5,4 |
210 |
2,8 |
3,5 |
3,1 |
230 |
5,6 |
9,1 |
7,2 |
200 |
2,5 |
5,2 |
4,6 |
250 |
3,9 |
6,5 |
3,9 |
240 |
3,8 |
2,9 |
3,8 |
205 |
4,6 |
1,4 |
2,6 |
210 |
4,9 |
8,8 |
6,8 |
230 |
7,2 |
11,5 |
8,5 |
210 |
5,3 |
4,9 |
1,8 |
200 |
Знайдемо часткові коефіцієнти кореляції ryx1, ryx2, ryx3 , rx1x2, rx1x3, rx2x3. і побудуємо кореляційну матрицю.
Побудуємо кореляційну матрицю використовуючи настройку “Аналіз даних – Кореляція” електронної таблиці Excel.
Кореляційна матриця матиме вигляд (табл.2).
Таблиця 2
Кореляційна матриця економічних показників
|
y |
x1 |
x2 |
x3 |
y |
1 |
|
|
|
x1 |
0,690433 |
1 |
|
|
x2 |
0,404724 |
0,819116 |
1 |
|
x3 |
-0,40934 |
-0,01483 |
-0,0979 |
1 |
Після аналізу кореляційної матриці можна зробити висновок, що коефіцієнти х1 і х2 мають велике значення коефіцієнту кореляції і це може свідчити про наявність лінійної залежності між ними. На основі даного висновку можна говорити про наявність мультиколінеарності в даній моделі.
2. Визначимо ступінь колінеарності. У разі відсутності мультиколінеарності у моделі множинний коефіцієнт детермінації R2yx1x2х3 буде приблизно дорівнювати сумі часткових коефіцієнтів детермінації R2yx1, R2yx2, R2yx3. Якщо мультиколенеарність присутня, тоді це рівняння виконуватись не буде і у якості виміру мультиколінеарності можна використати змінну М1:
М1 = R2yx1x2x3 – ( R2yx1 + R2yx2 +R2yx3 ).
Чим більше змінна М1 наближатиметься до нуля, тим менша мультиколінеарність.
Знайдемо коефіцієнти детермінації. Для цього використовуємо надстройку “Аналіз даних– Регресія”.
R2yx1x2x3 = 0,754283 (будуємо регресі ю між y та x1, x2, x3)
R2yx1= 0,476698 (будуємо регресі ю між y та x1)
R2yx2= 0,163801 (будуємо регресі ю між y та x2)
R2yx3= 0,167558 (будуємо регресі ю між y та x3)
M1= 0,754283 – 0,476698 – 0,163801 – 0,167558= – 0,053774
Відповідно, до нашого приклада: М1 ненаближається до 0, тому слід вважати наявність мультиколінеарності.
3. Перевіримо інтенсивність мультиколінеарності за формулою:

Відповідно до нашого приклада отримаємо:

Даний коефіцієнт значно більший нуля, тому можна говорити про високу інтенсивність мультиколінеарності.
4. Одним із методів усунення мультиколінеарності є метод виключення змінних за Фарраром та Глаубером.
Процедура відбору змінних складається з трьох кроків. При цьому передбачається нормальне розподілення залишків.
Крок 1. Мультиколінеарність виявляється в загальному вигляді. Для цього будується матриця R коефіцієнтів парної кореляції між пояснюючими змінними та визначається її визначник.

rij=cov(xi, xj)/σxi σxj
Кореляційну матрицю можна отримати використовуючи пакет “Аналіз даних” електронної таблиці Excel інструмент “Кореляція”.
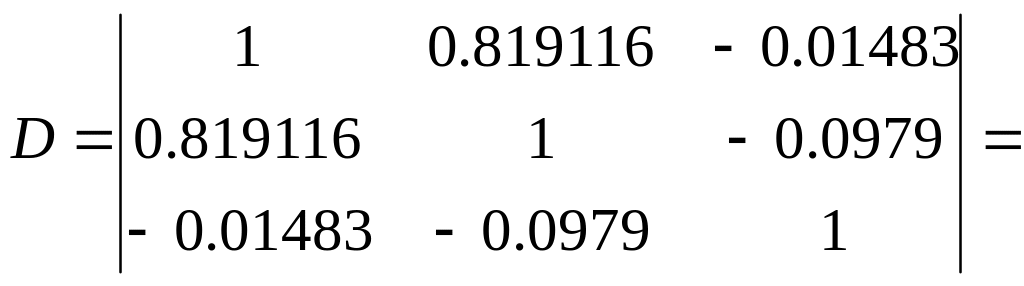 0,321622
0,321622
Далі для перевірки наявності мульколінеарності взагалі серед пояснюючих змінних використовується хі квадрат критерій χ2 (хі квадрат ).
Висувається нульова гіпотеза Н0: між пояснюючими змінними мультиколінеарність відсутня. Альтернативна гіпотеза Н1:між пояснюючими змінними є мультиколінеарність.
Розраховують значення χ2
χ2= – (n-1-1/6*(2*m+5))*lnD
де n–кількість спостережень, m– кількість пояснюючих змінних.
Ця величина має розподіл χ2 з f=1/2*m*(m-1) ступенями вільності. Якщо розраховане значення χ2 менше за табличне, то Н0 приймається. вважаємо, що мультиколінеарності між пояснюючими змінними немає. Інакше, визначають данні які сильно корелюють визначається на другому кроці.
χ2= – (10-1-1/6*(2*3+5))*ln(0,321622)=8,1297,
f=1/2*3*(3-1)=3.
Табличне значення χ2= 7,815 (при f=3 та α=0,05)
Таким чином (8,1297 ≥ 7,815), тому гіпотеза про наявність мультиколінеарності між пояснюючими змінним не суперечить даним дослідження
Крок 2. Використовуються коефіцієнти детермінації між пояснюючими змінними R2k12…k-1k+1…m. Оцінка мультиколінеарності основана на тому, що величина

має F-розподіл з f1=m-1 I f2=n-m ступенями вільності.
Якщо F≥Fα;f1,f2, то змінній xk в найбільшому ступені притаманна мультиколінеарність. По Фаррару і Глауберу вивчення m значень F-статистик має показувати, які з пояснюючих змінних в більшій мірі підверджені мультиколінеарності.
R2 x1,x2,x3 = 0,675265
F = (10-2)*0,675265/[(2-1)*(1–0,675265)]= 16,6355
F ≥ Fтабл.
R2 x2,x1,x3= 0,678307
F = (10-2)*0,678307/((2-1)*(1-0,678307))= 16,8684
F ≥ Fтабл.
R2 x3,x1,x2= 0,02257
F = (10-2)*0,02257/((2-1)*(1–0,02257))=5,367608/0,329049=0,18473
F < Fтабл.
Fтабл .= 5,32 з f1 = m-1 = 2-1 = 1 I f2 = n-m = 10-2=8 ступенями вільності.
F ≥ Fтабл.
Таким чином змінним х1 та х2 в найбільшому ступені притаманна мультиколінеарність
Крок 3. З’ясовується, яка пояснююча змінна породжує мультиколінеарність, та вирішується питання про її виключення з аналізу. Для цієї цілі розраховується коефіцієнт частинної кореляції rjk12…m (j, k=1,2,…,m; j <> k) між пояснюючими змінними. Змінна y в розрахунок не береться. В якості критерію використовується величина

що має t-розподіл з f = n – m ступенями вільності. Якщо tj,k > tα,f, то між змінними існує колінеарність и одна з них має бути виключеною. При виключенні змінної дослідник має опиратися як на власну інтуїцію, та і на змістовну теорію явища. Якщо tj,k ≤ tα,f, то дані не підтверджують наявність колінеарності між змінними xj та xk .
Знайдемо коефіцієнти частинної кореляції rjk12…m (j, k=1,2,…,m; j<>k) між пояснюючими змінними. Кореляційна матриця має вигляд.
|
x1 |
x2 |
x3 |
x1 |
1 |
|
|
x2 |
0,819116 |
1 |
|
x3 |
-0,01483 |
-0,0979 |
1 |
t0.05;8 = 2,31
r2 123 = r2 12+r213,
r2 231 = r2 23+r2 21
r2 312 = r2 31+r232
1. r2 123
r2 123 = 0,8191162+(–0,01483)2 = 0,671171, r 123 = 0,819225
![]() 4.040761
4.040761
t12 > t0.05;8 Між змінними х1 та х2 існує колінеарність.
2. r2 213
r2 231 = (–0,0979)2 + 0,8191162 = 0,68053, r 213 = 0,824946
![]() 4.12815
4.12815
t23 > t0.05;8 . Між змінними х2 та х3 існує колінеарність.
3. r2 312
r2 312 = (–0,01483)2+(–0,0979)2 = 0,009804 = 0,099017
![]() 0,281445
0,281445
t31 < t0.05;8. Між змінними х3 та х1 не існує колінеарність.
Висновок: змінну х2 потрібно вилучити з розгляду. Наша модель буде показувати залежність між y (прибутку підприємства, тис.грн.) та х1 (виробничих витрат, тис.грн.) та х3 (середньої кількості працівників, чол.).
Економетрична модель буде мати вигляд:
y = 9,976384 + 0,349471*x1 – 0,03592*x2
Контрольні питання:
1. Поняття мультиколінеарності.
2. Причини виникнення мультиколінеарності.
3. Тестування наявності мультиколінеарності.
4. Методи усунення мультиколінеарності.
Лабораторна робота № 7
(2 години)
Тема: “Гетероскедастичність у багатофакторному регресійному аналізі"
Мета роботи: Дослідити поняття гетероскедастичності та гомоскедастичності. Освоїти методики оцінки особливих випадків багатофакторного регресійного аналізу із допущенням гетероскедастичності.
Теоретичні відомості.
Одним з основних припущень моделі класичної лінійної регресії є припущення про сталість дисперсії кожної випадкової величини е. (гомоскедастичність). Формалізовано це припущення записується у вигляді:
![]()
Якщо це припущення не задовольняється у якомусь окремому випадку, то має місце гетероскедастичність:
![]()
Суть
припущення гомоскедастичності полягає
в тому, що варіація кожної et
навколо її математичного сподівання
не залежить від значення х. Дисперсія
кожної ei.
зберігається сталою незалежно від малих
чи великих значень факторів: σ2e
не є функцією xij
тобто σ2e<>
f(x1i,
x2i,...,xpi
). Якщо σ2e
не є сталою, а її значення залежать від
значень х, можемо записати
![]() У цьому разі маємо справу з
гетероскедастичністю.
У цьому разі маємо справу з
гетероскедастичністю.
Наслідками порушення умови гомоскедастичність є: неможливість перевірки значимості параметрів регресії та побудови інтервалів довіри (дисперсія випадкової величини не стала, а змінюється), якщо вони отримані за методом найменших квадратів:
 ;
;
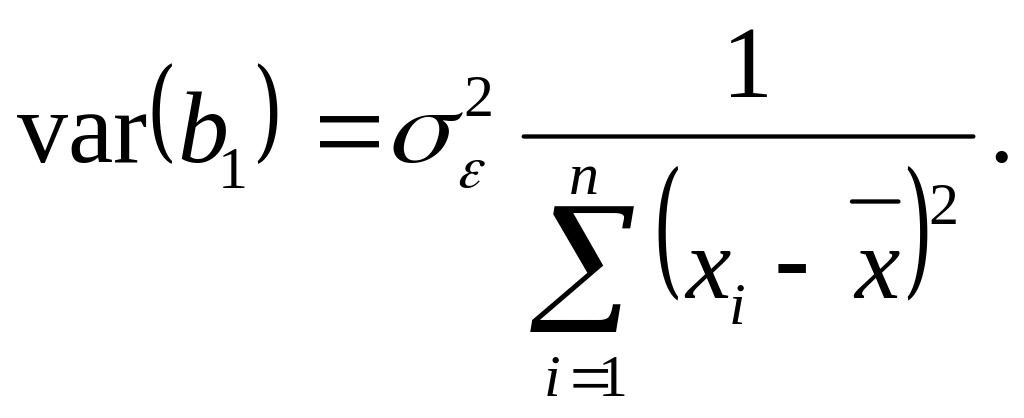
і таким чином, оцінки параметрів регресії втрачають таку перевагу над іншими оцінками, як те, що вони мали найменшу дисперсію. Тому оцінки параметрів доцільно знаходити за узагальненим методом найменших квадратів (інша назва – метод Ейткена)
Методи визначення гетероскедастичності .Єдиних правил виявлення гетероскедастичності немає, а є різноманітні тести.
1. Графічний аналіз. Суть методу у наступному:
а) Побудувати багатофакторну регресійну модель з припущенням про про відсутність гетероскедастичності.
б)
намалювати графік зележності відхилень
моделі
![]() і фактору у і з’ясувати, чи мають вони
якусь систематичність.
і фактору у і з’ясувати, чи мають вони
якусь систематичність.
в) намалювати графік зележності відхилень моделі і фактору х з’ясувати, чи мають вони якусь систематичність.
г) зробити висновок про саму форму зв’язку, що особливо корисно при трансформації наявних даних для побудови моделі з гомоскедастичністю помилок.
2. Тест рангової кореляції Спірмена. Алгоритм методу:
а) Представити модель у вигляді рівняння регресії: yi=β0 +β1xi+β2x2+εi.
б) На основі регресії розрахувати відхилення еi .
в) Взявши абсолютні значення | еi |, ранжуємо |ei | та уi у зростаючому чи спадному порядку і підрахувати коефіцієнт рангової кореляції Спірмена для всіх пар |ei | та уi за формулою:

де d — різниця між рангами, що приписуються двом характеристикам і-го об'єкта;
n — кількість об'єктів, що ранжуються.
г) Перевірити значимість отриманого коефіцієнта рангової кореляції за f-критерієм Ст'юдента. Для цього побудувати t-статистику:

де n — кількість спостережень;
![]() =
(n
- 2) — кількість ступенів вільності.
=
(n
- 2) — кількість ступенів вільності.
При даних ступенях вільності за таблицями Ст'юдента знайти t. Якщо розраховане значення перевищує tкр (t > tкр ), це підтверджує гіпотезу про гетероскедастичність. Якщо t ≤ tкр , тоді в регресійній моделі правильним є припущення про гомоскедастичність.
3. Тест Глейзера. Алгоритм методу:
а) Знайти невідомі параметри лінійної регресії методом найменших квадратів та обчислити помилки eі для кожного окремого спостереження.
б) Побудувати регресію е = f(у), яка пов'язує абсолютні значення знайдених на першому етапі помилок (|еі |) з незалежною змінною у. Необхідно взяти абсолютні значення помилок, а не їх справжні значення, оскільки Σе=0 , і тому неможливо буде підібрати регресію е = f(у).
в) Оскільки фактична форма цієї регресії не відома, тому до неї необхідно підібрати різні форми кривих (користуючись набором ліній тернду у майстері офісних програм). Обирають ту регресію, яка найкраще підходить з огляду на коефіцієнт кореляції (або детермінації) та середні квадратичні відхилення параметрів b0 та b1. Існують випадки:
- b0=0 та b1<> 0, така ситуація називається "чиста гетероскедастичність";
- b0 та b1><0, цей випадок називається "змішана гетероскедастичність".
г) Застосувати t-тест для перевірки статистичної значимості параметрів b0 та b1, якщо вони значно відрізняються від нуля, то у моделі існує гетероскедастичність.
Перевага тесту Глейзера в тому, що він дає також інформацію про форму гетероскедастичності, тобто про спосіб, яким пов'язані еі та у. Ця інформація є важливою, як ми зараз побачимо, для "корекції" гетероскедастичності.
Вилучення
гетероскедастичності. Коли
на базі будь-якого тесту встановлено
гетероскедастичність, то для її вилучення
змінюють початкову модель таким чином,
щоб помилки мали постійну дисперсію.
Далі невідомі параметри трансформованої
моделі розраховуються за методом
найменших квадратів. Трансформація
моделі зводиться до зміни первісної
форми моделі. Яким чином це проводиться,
залежить від специфічної форми
гетероскедастичності, тобто від форми
залежності
між дисперсією
![]() та значеннями незалежних змінних:
=f(xi).
Розглянемо можливі випадки трансформації
моделі на прикладі простої лінійної
регресії. Припустимо, що ми маємо
початкову модель yi
= β0
+ β1xi
+ еi
(де випадкова величина еi
гетероскедастична, але відповідає
всім іншим класичним припущенням
лінійної регресії.
та значеннями незалежних змінних:
=f(xi).
Розглянемо можливі випадки трансформації
моделі на прикладі простої лінійної
регресії. Припустимо, що ми маємо
початкову модель yi
= β0
+ β1xi
+ еi
(де випадкова величина еi
гетероскедастична, але відповідає
всім іншим класичним припущенням
лінійної регресії.
1. Метод зважених найменших квадратів (ЗНК), який є особливим випадком методу узагальнених найменших квадратів (УНК). У методі простих найменших квадратів мінімізують просту суму квадратів відхилень:
![]()
У
якій кожне відхилення має однакову вагу
(сума ваг =1). Тобто сума Σ![]() є незваженою сумою квадратних
відхилень, у якій припускається, що еі,
оцінені за допомогою еі.
Хоча, якщо дисперсія еі
не є сталою, зрозуміло, що більша дисперсія
спостереження дає менш точну вказівку
на те, де проходить правильна регресійна
лінія. Досягнути сталості дисперсії еі
можливо наданням різної ваги кожній
еі
(чи її оцінці). При цьому використовують
вагу як частку 1/
, тобто ділять кожне відхилення на
дисперсію випадкової величини. Отже,
замість мінімізації простої суми
квадратів відхилень мінімізують зважену
суму квадратів відхилень:
є незваженою сумою квадратних
відхилень, у якій припускається, що еі,
оцінені за допомогою еі.
Хоча, якщо дисперсія еі
не є сталою, зрозуміло, що більша дисперсія
спостереження дає менш точну вказівку
на те, де проходить правильна регресійна
лінія. Досягнути сталості дисперсії еі
можливо наданням різної ваги кожній
еі
(чи її оцінці). При цьому використовують
вагу як частку 1/
, тобто ділять кожне відхилення на
дисперсію випадкової величини. Отже,
замість мінімізації простої суми
квадратів відхилень мінімізують зважену
суму квадратів відхилень:

Такий метод і називається методом зважених найменших квадратів (ЗНК). Прирівнявши часткові похідні зваженої суми квадратів до нуля і розв'язавши систему рівнянь, отримаємо формули для знаходження невідомих параметрів b0 та b1, що можливо при відомій дисперсії .
2. Узагальнений метод найменших квадратів (метод Ейткена)
На відміну від звичайного методу найменших квадратів (МНК), узагальнений метод (УНК) враховує інформацію про неоднаковість дисперсії і тому здатний створити BLUE-оцінки, тобто оцінки, що мають найменшу дисперсію. Ідея УНК полягає в наступному. Маємо просту лінійну регресію:
![]()
Простою математичною маніпуляцією перепишемо попередній вираз у вигляді:
![]()
де x0t = 1 для кожного і.
Припустимо,
що наявна гетероскедастичність і всі
дисперсії
![]() відомі. Поділимо всі елементи рівняння
на σi,
тоді отримаємо:
відомі. Поділимо всі елементи рівняння
на σi,
тоді отримаємо:
![]()
Для зручності перепишемо рівняння у вигляді:
![]()
де зірочками помічені початкові змінні, поділені на відомі σi. Позначення β0* та β1* використовуються для того, щоб відрізнити їх від звичайних параметрів β0 та β1, отриманих методом найменших квадратів. Тепер дисперсія трансформованої помилки е* є постійною величиною, тобто для останньої моделі зберігається припущення про гомоскедастичність, і ми переходимо до класичної регресійної моделі. Для того, щоб знайти невідомі параметри за методом узагальнених найменших квадратів, мінімізуємо:
![]() або
або

За методом звичайних найменших квадратів невідомі параметри знаходяться шляхом мінімізації суми квадратів відхилень фактичних значень від теоретичних. Для простої лінійної регресії маємо:
![]()
В узагальненому методі найменших квадратів мінімізується вираз, який можна переписати у вигляді:
![]()
де γi=1/σi* — вагові коефіцієнти.
Тобто в узагальненому методі найменших квадратів мінімізуємо зважену суму квадратів відхилень з вагами, обернено пропорційними до σi.