

Unit 5. Databases
I. Read the following words:
query, properties, schema, among, typically, categorized, determine, concurrency, area, failure, hierarchical, success, organization, technique, particular, associated, integer, essential, paradigm, impedance, convenient, retrieve, spawned, individual, floating, consuming, polymorphism, structured, focus, access.
II. Before you read the text try to answer these questions:
1. What is a database?
2. What is the main purpose of using databases?
3. What are the areas where databases can be applied?
III. Read and translate the following text. Databases
The term database originated within the computer industry. A database is a structured collection of records or data stored in a computer. The retrieved records are information that can be used to make decisions. The term database refers to the collection of related records and the software should be referred to as the database management system or DBMS. DBMS is software that organizes and retrieves data in a database. There is a structural description of facts held in the database and it is known as a schema. The schema describes the objects represented in the database and the relationships between them. There are different ways of organizing a schema, i.e. modeling the database structures known as database models (or data models). The most common type of database models is the relational model.
When the context is unambiguous, however, many database administrators and programmers use the term database to cover both meanings. Database management systems are usually classified according to the data model they support: relational, object-oriented, network and other models. The data model determines the query language that is available to access the database. The great part of the DBMS internal engineering, however, is independent of the data model and concerned with managing factors, such as performance, concurrency, integrity and recovery from hardware failures.
The term «database» was first used in June 1963, when the System Development Corporation sponsored a symposium Development and Management of a Computer-centered Data Base. Database, as a single word, became common in Europe in the early 1970s and by the end of the decade it had been used in American newspapers. The first database management systems were developed in the 1960s. A pioneer in this field was Charles Bachman. Bachman's early papers showed that his aim was to make more effective use of the new direct access storage devices. Two key data models appeared at that time. CODASYL developed the network model based on Bachman's concept. The second key model, hierarchical, was used in a system developed by North American Rockwell. Later, it was adopted by IBM as the cornerstone of its IMS product. The relational model was proposed by E. F. Codd in 1970. He criticized existing models for confusing the abstract description of information structure and description of physical access mechanism. For a long period of time, however, the relational model remained of academic interest only. During the 1980s, research activity focused on distributed database systems and database machines, but these developments had a little effect on the market. In the 1990s, the attention was focused on object-oriented databases that had some success in the fields where it was necessary to handle more complex data than relational systems could easily cope with. Nowadays, the fashionable area for innovation is the XML databases. Their aim is to remove the traditional division between documents and data, allowing the organization's information resources to be held in one place, whether they are highly structured or not.
Various techniques are used to model data structures. Most database systems are built around one particular data model, although it is common for products to offer support for more than one model. The serious implementations of the relational model allow creating indexes which provide fast access to rows in a table if the values of certain columns are known. A data model is not just a way of structuring data but it also defines a set of operations to be performed on the data.
The flat (or table) database consists of a single, two-dimensional array of data elements, where all members of a given column are assumed to be similar values and all members of a row are assumed to be related to one another. Each row would have a specific password associated with an individual user. This model is a basis of the spreadsheet.
In a hierarchical database, data relationships follow hierarchies or trees, which reflect either a one-to-one relationship or a one-to-many relationship among record types (See fig. 3). The uppermost record in a tree structure is called the root record. Data is organized into groups containing parent records and child records. One parent record can have many child records, but each child record can have only one parent record. Parent records are higher in the data structure than child records are; however, each child can become a parent and have its own child records. Hierarchical structures were widely used in the early mainframe database management systems, such as the Information Management System (IMS) by IBM. However, the hierarchical structure is inefficient for certain database operations when a full path is not included for each record.
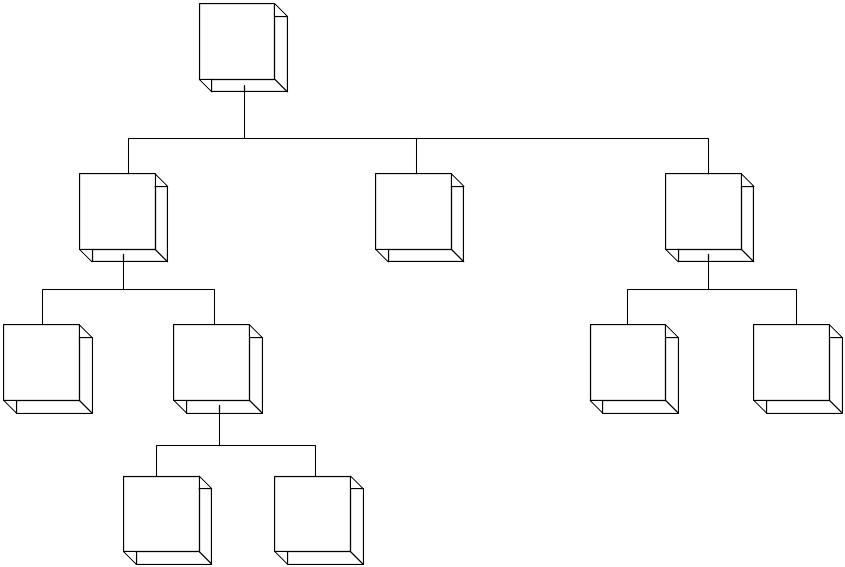
Fig. 3. Hierarchical data relationships
The network database organizes data using two fundamental constructs, called records and sets. Records contain fields (which may be organized hierarchically) and sets define one-to-many relationships between records (See fig. 4). It is similar to a hierarchical database except that each record can have more than one parent, thus creating a many-to-many relationship among the records. For example, a customer may be called on by more than one salesperson in the same company and a single salesperson may call on more than one customer. Within this structure, any record can be related to any other data element. The main advantage of a network database is its ability to handle relationships among various records.
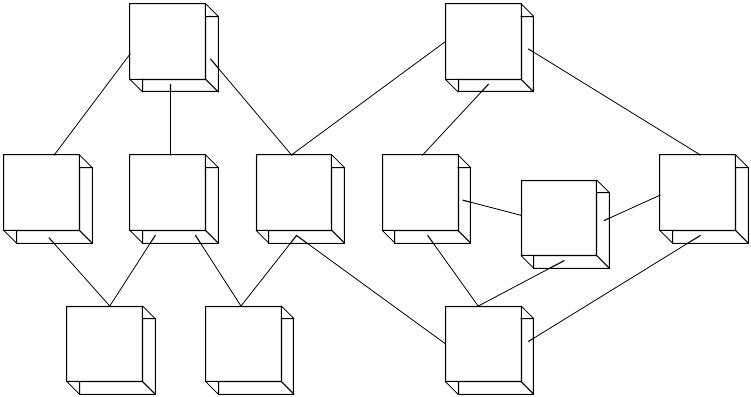
Fig. 4. Network data relationships
In both the network structure and the hierarchical structure, data access is fast because the data path is predefined. However, any relationship between data items must be defined when the database is being created. If a user wants to retrieve or manipulate data in a manner not defined when the database was originally created, it is costly and time-consuming to redesign the database structure. This limitation has led to the development of the relational database model.
The relational database is composed of many tables where data is stored. Tables in a relational database must have unique rows and the cells must be single-valued (name, address, identification number). The relational database management system (RDBSM) allows data to be created, maintained, manipulated and retrieved from the relational database. In this type of database, data relationships do not have to be predefined. Users query a relational database and establish data relationships spontaneously by joining common fields. A database query language acts as an interface between users and a relational database management system. The language helps the users of the relational database to manipulate, analyze and create reports from the data contained in the database. Although the relational database is well-suited to the needs of storing and manipulating business data, it is not appropriate for the data needs of certain complex applications, such as computer-aided design (CAD) and computer-assisted software engineering (CASE). Business data follow a defined data structure that the relational models handle well. However, applications, such as CAD and CASE, deal with a variety of complex data types that cannot be easily expressed by relational models.
The object-oriented database uses objects and messages to accommodate new types of data and provides advanced data handling. The object-oriented database management system (OODBSM) permits objects to be readily created, maintained, manipulated and retrieved from an object-oriented database. An OODBMS provides features that you would expect in any other DBMS, but there is still no clear standard for the object-oriented model. OODBMSs are expected to evolve and be used for applications with complex data needs. They are not, however, expected to replace relational databases. Instead, they work in tandem, each suited for different tasks.
Databases are used in many applications, spanning virtually the entire range of computer software. Databases are the preferred method of storage for large multiuser applications, where coordination between many users is needed. Even individual users find them convenient, though, and many electronic mail programs and personal organizers are based on standard database technology. Software database drivers are available for most database platforms so that applications software can use a common application programming interface (API) to retrieve the information stored in a database. Two commonly used database APIs are JDBC and ODBC. A database is also a place where you can store data and then arrange that data easily and efficiently.
IV. Answer the following questions: