

Лабораторная работа 4 Преобразование речи в текст
Цель работы: изучить на примере системы преобразования речи в текст основные этапы распознавания речи. Освоить особенности проектирования речевых систем с использованием системы Matlab.
Порядок выполнения
Подключить к выходам звуковой карты микрофон и наушники (динамики).
Запустить из среды Matlab файл wav.m системы «Речь-текст». Откроется рабочая область программы (рисунок 4.1).
3. Сформировать обучающие выборки для каждого класса фонем.
Формирование обучающей выборки для нейросети
3.1 Установить частоту дискретизации равной 22050Гц, разрядность 16 бит (меню параметры/запись).
3.2 Последовательно записать речевые сигналы слов, приведенные в таблице 4.1, по три варианты каждое. Для каждой реализации провести предварительную обработку записанного сигнала, удалив речевые паузы в конце и начале записи. Для этого необходимо включить режим выделения и графически выделить записанное слово.
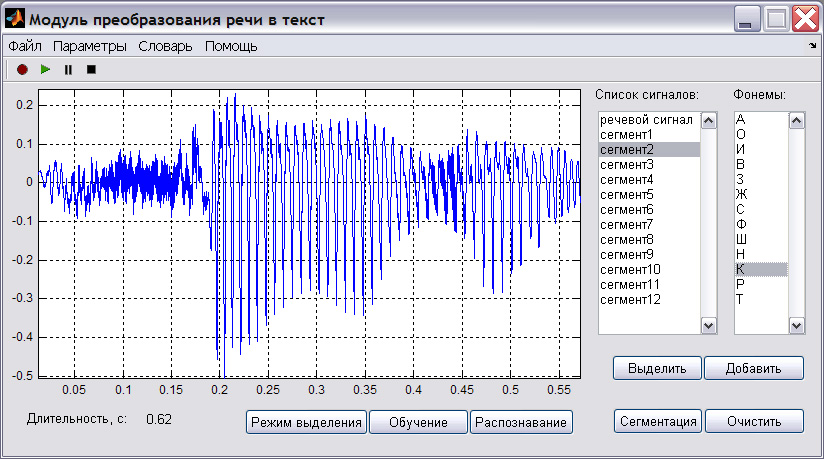
Рис. 4.1 - Пользовательский интерфейс системы «Речь-текст»
Затем выполнить команду Выделить, при этом из выбранной области сигнала сформируется отдельный объект, который отобразится в списке сигналов (рис. 4.1). Затем выбрать сигнал из списка и сохранить, как wav-файл.
Для автоматического выделения слов предназначена функция Сегментация. При использовании этой функции слитные участки речи из сигнала выделяются в отдельные сегменты, которые отображаются в Списке сигналов (рисунок 4.1). Выбрав из списка сигнал, его можно просмотреть, прослушать и сохранить в .wav файл. Для использования данной функции необходимо, чтобы первые 100мс сигнала не содержали речи.
Таблица 4.1. Файлы произнесенных слов
Слово |
Имя файла |
1. Ваза |
Ваза.wav Ваза1.wav Ваза2.wav |
2. Воз |
Воз.wav Воз1.wav Воз2.wav |
3. Завоз |
Завоз.wav Завоз1.wav Завоз2.wav |
4. Зов |
Зов.wav Зов1.wav Зов2.wav |
5. Ива |
Ива.wav Ива1.wav Ива2.wav |
6. Оса |
Оса.wav Оса1.wav Оса2.wav |
7. Сажа |
Сажа.wav Сажа1.wav Сажа2.wav |
8. Саша |
Саша.wav Саша1.wav Саша2.wav |
9. Фаза |
Фаза.wav Фаза1.wav Фаза2.wav |
10. Шов |
Шов.wav Шов1.wav Шов2.wav |
3.3 Формирование базы фонемных эталонов, для которых будут вычисляться признаки, производится путем выделения фонем из слов. Для этого необходимо открыть файл с записанным речевым сигналом слова и запустить Режим выделения, в котором предоставляется возможность графически отметить временной интервал речевого сигнала, соответствующий конкретной фонеме. По команде Выделить выбранный участок слова помещается в Список сигналов, где его можно прослушать, или сохранить на диск в виде .wav файла. В данном режиме включается разметка графика сигнала, и появляется возможность масштабирования (Нажатие левой кнопки мыши - увеличение, правой - сжатие, есть возможность выделения участка сигнала для просмотра под увеличением).
Обучающая выборка формируется с помощью команды Добавить, путем добавления нужных фонем-эталонов из Списка сигналов в Список фонем с указанием их символьного обозначения в диалоговом окне (рисунок 4.2). При этом выполняется предварительная обработка, и рассчитываются признаки выбранных фонем. Таким образом выделить все фонемы из сохраненных слов.

Рисунок 4.2 – Добавление фонемы в обучающую выборку
3.4 Сформированную обучающую выборку признаков фонем сохранить на диск для последующего использования. Сохранение и загрузка выборки выполняется с помощью диалоговых окон, вызываемых через соответствующие команды в меню Файл.
4. Функция Обучение запускает процедуру обучения нейросети на сформированном обучающем множестве с заданными параметрами. Настройка параметров нейросети доступна в меню Параметры – Сеть (рисунок 4.3), следует выбрать значения размера скрытого слоя и ошибки обучения (по умолчанию эти величины равны 20 и 0.1 , соответственно).
Процесс обучения нейросети отображается графически в виде зависимости значения ошибки на текущей итерации (рис. 4.3).

5. После обучения нужно сохранить значения весов связей нейросети, обученной под конкретного диктора, для дальнейшего использования при распознавании. Импорт и загрузка сети осуществляется через меню Файл.

Рисунок 4.3 – Окно установки параметров нейросети
6. Для распознавания необходимо загрузить сохраненную нейросеть (файл/загрузить сеть) и подключить словарь (файл diction_rus в директории программы) с помощью которого выполняется формирование грамматической формы слов (без использования словаря при распознавании в окне с текстом будет отображаться фонетическое представление слова). Для создания и изменения существующего словаря предоставляется инструмент - Редактор словаря, доступный в меню Словарь. С помощью пользовательского интерфейса Редактора словаря (рисунок 4.4) можно сформировать новый словарь грамматических словоформ распознаваемых слов, добавить или удалить слова из уже подключенного словаря. Результат работы редактора можно сохранить с помощью соответствующей команды в меню Словарь.

Рисунок 3.6 – Окно редактора словаря
Записать слово, или открыть заранее записанный .wav файл, не участвовавший в процессе формирования обучающей выборки. После процедуры сегментации для выделения изолированного слова, по команде Распознавание открывается окно, в котором отображается текстовая строка распознанного слова (рисунок 4.7).

Рисунок 4.7 – Окно с текстом распознанных слов
5.Определить надежность классификации изолированных слов.
Теоретическая часть
В вероятностно-сетевой модели преобразования речи в текст реализованы следующие функции:
• формирование обучающей выборки;
• обучение нейросети для классификации фонем;
• преобразование в текст речевого сигнала, представленного в виде изолированного слова;
• сохранение обучающей выборки в виде подключаемой БД с признаками фонем;
• импорт БД признаков фонем;
• автоматическая сегментация сигнала на речь и паузы, с построением списка выделенных сегментов и возможностью их прослушивания и сохранения на диск в виде wav-файла;
• формирование эталонов фонем путем их выделения в графическом окне отображения речевого сигнала;
• создание и редактирование словаря грамматических форм распознаваемых слов с возможностями его сохранения и загрузки;
• настройка параметров моделирования нейронной сети;
• сохранение значений весов связей обученной нейросети;
• импорт нейросети;
• настройка параметров нейронной сети (размер скрытого слоя, ошибка обучения);
• настройка параметров записи (частота дискретизации, разрядность);
• импорт данных, хранящихся в виде wav-файлов;
• сохранение сигнала в формате wav-файла;
• воспроизведение сигнала;
• просмотр речевого сигнала в отдельном окне с возможностью масштабирования;
• формирование фонем-эталонов путем их графического выделения из слов.
Интерфейс системы (рис. 4.1) дает возможность пользователю сформировать базу данных фонем, провести обучение нейронной сети. Для обучения используется сформированная выборка для каждого класса фонемы. Возможны управление записью/воспроизведением звука, настройка параметров записи, открытие и сохранение звуковых файлов с помощью диалоговых окон, графического отображение речевого сигнала.
Рассмотрим вероятностно-сетевую модель системы преобразования русской речи в текст, в которой для получения признаков используется кратномасштабное вейвлет-преобразование. Структурная схема разрабатываемой системы распознавания изолированных слов показана на рис. 4.8.

Рис. 4.8. Структурная схема системы «Речь-текст»
Речевой сигнал после оцифровки поступает на блок предварительной обработки, задачей которого является фильтрация шума, удаление речевых пауз, нормализация сигнала и его сегментация на фиксированные интервалы во временной области, на которых будут вычисляться признаки фонем.
В режиме обучения на вход системы подается последовательность фонем, представляющая собой обучающее множество. Звуковые образы фонем формируются выделением их из слов. Коэффициент распознавания в первую очередь будет определяться качеством речевого материала, предназначенного для обучения.
Для
формирования признаков речевых единиц
обычно используются методы, основывающиеся
на преобразования Фурье или коэффициентах
линейного предсказания. Использование
этих методов требует соблюдения условия
стационарности сигнала в пределах
некоторого промежутка времени, что
ограничивает точность анализа локальных
изменений сигнала. Для формирования
признаков фонем использовалось
кратномасштабное вейвлет-преобразование,
основанное на представлении сигнала
последовательностью образов с разной
степенью детализации, что позволяет
выявлять его локальные особенности и
классифицировать их по интенсивности.
Выполняется разложение сигнала по
функциям, образующим ортонормированный
базис [3]. Функция на некотором заданном
уровне разрешения (масштабе)![]() представляется рядом вида
представляется рядом вида
 ,
(1)
,
(1)
где
![]() и
и
![]() – масштабированные и смещенные версии
скейлинг функции (масштабной функции)
– масштабированные и смещенные версии
скейлинг функции (масштабной функции)
![]() и «материнского вейвлета»
и «материнского вейвлета»
![]() ;
;
![]() – коэффициенты аппроксимации;
– коэффициенты аппроксимации;
![]() –
детализирующие коэффициенты.
–
детализирующие коэффициенты.
Масштабирование и смещение функций определяются по законам
![]() ,
(2)
,
(2)
![]() .
(3)
.
(3)
Таким образом, в
блоке выделения признаков на основе
кратномасштабного вейвлет-преобразования
для выбранного количества уровней
детализации рассчитываются
вейвлет-коэффициенты, характеризующие
данную фонему-эталон (рис. 4.9). Вычисленные
характеристики сохраняются в базе
данных (БД) признаков.
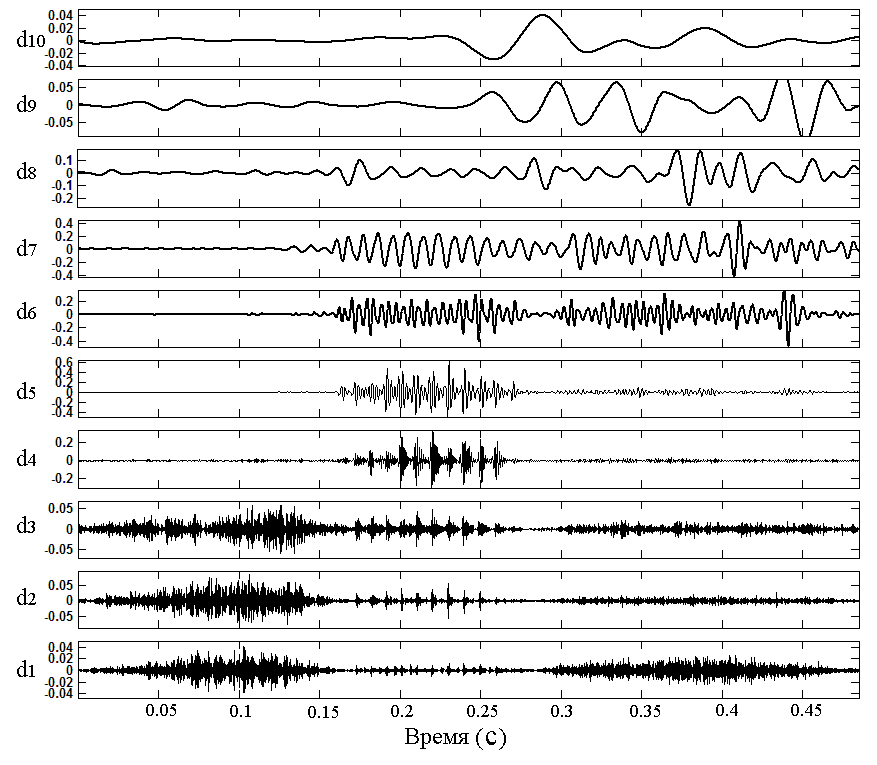
Рис. 4.9. Коэффициенты вейвлет-разложения речевого сигнала
на десять уровней детализации
Нейронные сети имеют различную архитектуру. В данной системе использовался двухслойный персептрон. Для обучения применялся алгоритм обратного распространения ошибки. Результатом обучения нейросети является такая подстройка ее весов, при которой поступление на ее входы вектора параметров приводит к требуемому выходному вектору. Обучение выполняется на обучающем множестве, представленном в виде наборов полученных признаков фонем. Значения весов связей нейросети, обученной под конкретного диктора, сохраняются и в дальнейшем используются при распознавании.
В режиме распознавания на вход системы подается речевой сигнал в виде изолированного слова. После оцифровки, предварительной обработки и выделения признаков, рассчитанные векторы признаков последовательно поступают на входы обученной нейросети (рис. 4.10), которая их классифицирует (определяет принадлежность к определенной фонеме).

Рис. 4. 10 Классификация фонемных сегментов нейронной сетью
Выходные сигналы нейронов сети формируют вектор, на основе которого строится символьная последовательность, отображающая соответствие каждого распознанного сегмента конкретной фонеме. Полученная цепочка поступает на вход модуля формирования слов (рис. 4.11) для построения грамматической формы слова.

Рис. 4.11 Модуль формирования слов
Так как временной интервал, на котором рассчитываются характеристики фонемы, меньше ее длины, то цепочка включает повторяющиеся сегменты, которые необходимо удалить (рис. 4.12).

Рис. 4.12. Формирование фонем из повторяющихся сегментов
Для устранения возникающих ошибок в полученной фонемной строке используются условные вероятности фонемных сочетаний в языке. Анализируются вероятностные характеристики сочетаний фонем в слове, выбиралется фонема, вероятность появления которой в слове максимальна.
Например: так как Р(ф/а)< Р(з/а), то принималось решение
ВАФЗА ВАЗА.
На выходе блока формирования фонетического представления слова получается строка, которая в случае правильной интерпретации будет являться фонетической формой распознаваемого слова.
Фонемной транскрипции соответствует грамматическая форма слова. Например, фонетическому представлению [СОНЦЕ] соответствует грамматическая форма “СОЛНЦЕ”. В случае ошибочного распознавания отдельных фонем также необходимо найти наиболее подходящее слово. Для поиска в системе предусмотрен словарь, который содержит грамматические словоформы распознаваемых слов. Использование словоформы в роли основной единицы словаря приводит к увеличению его объема, но упрощает процедуру идентификации единиц текста.
Ключевым моментом поиска по сходству является выбор меры степени "похожести". Одним из распространенных методов поиска по сходству в словаре является метрика (функция) Левенштейна, которую часто называют расстоянием редактирования. Расстояние редактирования равно минимальному числу элементарных операций редактирования, необходимых для преобразования одной строки в другую [4]. Для расстояния Левенштейна набор элементарных операций состоит из операции замены, вставки и удаления одной буквы.
Рассмотрим подробно алгоритм вычисления расстояния Левенштейна.
Пусть di,j есть расстояние между префиксами строк x и y, длины которых равны соответственно m и n:
di,j
=
d(xi,
yj) ,
где
i
=
![]() , j
=
, j
=
![]() .
(5)
.
(5)
Расстояния di,j вычисляются в соответствии с рекуррентным соотношениями:
![]() ,
(6)
,
(6)
где w(xi,) – цена удаления i-го символа строки x (замена на пустой символ ); w(,yj) - цена вставки j-го символа строки y; w(xi,yj) - цена замены i-го символа строки x j-м символом строки y;
Выберем следующие значения цен редактирования w:
w(xi,) = 1 w(,yj) = 1 w(xi,yj) = 1, если a b, (7)
w(xi,yj)= 0, если a = b
В процессе вычислений формируется матрица размером (m+1,n+1) элементами которой являются значения dij..
Матрица, полученная в ходе вычисления расстояния Левенштейна для слов “ваза” и “оса”, представлена в табл. 1. В данном случае минимальное расстояние dm,n = 3, т. е. для преобразования одного слова в другое потребуются три операции редактирования.
Таблица 1
Матрица расстояний
|
|
В |
А |
З |
А |
|
0 |
1 |
2 |
3 |
4 |
О |
1 |
1 |
2 |
3 |
4 |
С |
2 |
2 |
2 |
3 |
4 |
А |
3 |
3 |
2 |
3 |
3 |
Содержание отчета