

Вопрос 1. Схема абстрактного технологического процесса. Классы информационных технологий, их состав, примеры.
Информационные Технологии – совокупность методов воздействия на информационные объекты ( информация, данные, знания, системы, ресурсы, программы и т.д.) или процессы (обработка, поиск, хранение, представление, передача информации).
Схема абстрактного технологического процесса обработки информации:
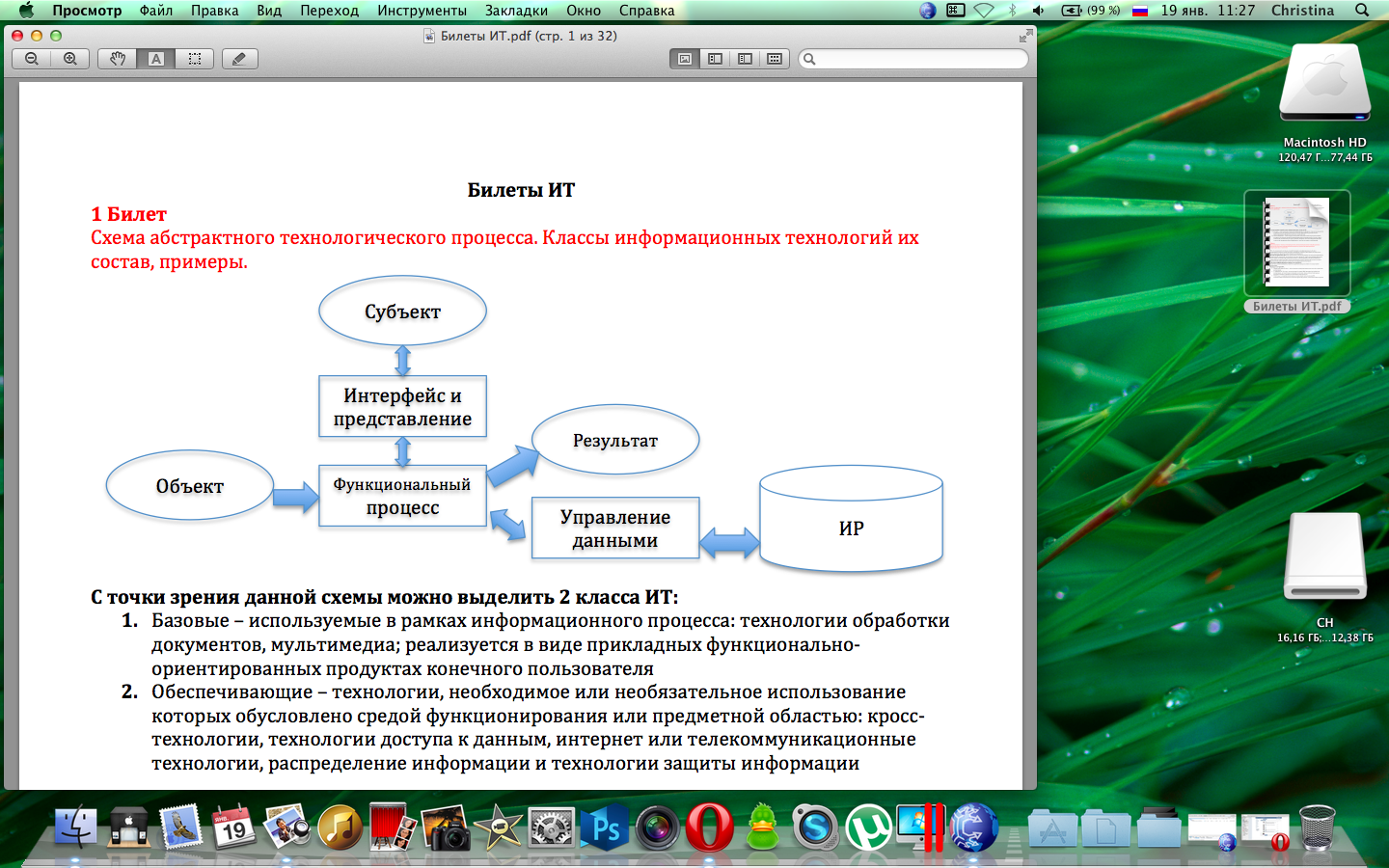
С точки зрения данной схемы можно выделить два класса информационных технологий:
1) Базовые Информационные Технологии;
2) Обеспечивающие Информационные Технологии;
К базовым относятся технологии, используемые в рамках национального процесса:
технологии обработки документов;
технологии обработки мультимедиа.
Обычно эти технологии реализуются в виде прикладных национально ориентированных продуктов для личного пользования.
Обеспечивающее Информационные Технологии – это технологии, не обязательность использования которых обусловлена характером задач предметной области или средой функционирования.
К обеспечивающим технологиям относятся:
кросс - технологии;
технологии доступа данным;
Интернет - технологии и телекоммуникационные технологии;
технологии распределённой обработки информации;
технологии защиты информации.
К инструментальным информационным технологиям относится технология обеспечения жизненного цикла информационных систем:
технология проектирования и создания баз данных,
программное обеспечение.
Выделяют также прикладные информационные технологии, то есть совокупности методов используемых в определённых предметных (прикладных) областях (например: банковские и.т., торговые и.т. и т.д. ). Любая прикладная И.Т. представляет собой совокупность применений базовых и обеспечивающих И.Т.. Специалист, занимающийся информатизацией, формирует свои И.Т.. Любой технологический процесс, использующий информационные технологии, представляет собой совокупность технологических операций. Каждая операция представляет собой реализацию базового информационного процесса. К базовым информационным процессам относят: извлечение информации, транспортирование информации, обработку информации, хранение информации, представление и использование информации.
Билет № 2: Информационные технологии (определение). Автоматизированные информационные технологии. Базовые информационные процессы. Краткая история развития информационных технологий.
Информационные Технологии – совокупность методов воздействия на информационные объекты (информация, данные, знания, системы, ресурсы, программы и т.д.) или процессы ( обработка, поиск, хранение, представление, передача информации).
Автоматизированные Информационные Технологии могут представлять собой как развитие не автоматизированных (предметов, технологий), так и новые способы, и процессы обработки информации ранее недоступные. Автоматизированные Информационные Технологии являются композициями четырёх взаимосвязанных и взаимозаменяемых факторов: интеллектуальных усилий, технических средств обработки данных, программного обеспечения и информационных ресурсов.
К базовым информационным процессам относят:
извлечение информации;
транспортирование информации;
обработку информации;
хранение информации;
представление;
использование информации.
Краткая история развития информационных технологий
Первая половина XX века: использование электромеханических способов обработки информации.
Середина 60-70 годов: использование больших ЭВМ, централизованная обработка информации, автоматизация рутинных операций, накопление фондов программных библиотек обработки данных, обработка данных в вычислительных центрах для коллективного пользования.
Середина 70 - конец 80: концепция персональных вычислений. Использование персональных компьютеров, автоматизация большинства областей обработки данных, вовлечение использования компьютерных технологий не профессиональных пользователей из различных предметных областей, развитие языков описания и манипулирования данными, развитие не процедурных подходов в разработке программного обеспечения.
Конец 80 - начало 90 : гуманизация использования ИТ, стандартизация ИТ, возрастание роли коммуникативных технологий и технологий передачи данных, использование ИТ не только в обеспечении производственной деятельности, но и для получения конкурентных преимуществ.
Билет №3. Логическая и физическая структура документа. Разметка. Виды разметки.
Структура документа:
Логическая структура документа:
Логическая структура документа определяет его составные части и их отношение. Например, составными частями документа могут являться авторские данные, аннотация, оглавление, главы, разделы, параграфы рисунки сноски.
Физическая структура документа:
Физическая – макетная структура, которая содержит описание терминов физических единиц: страниц, полос, колонтитулов, рамок для рисунков и т.д. Моделирование определений выполняется с одним из двух стандартов: ISO 8613( ODA – Office Document Architecture) ; ISO 8879( SGML – Standart Generalized Markup language).
Разметка - дополнительная информация, включаемая в документ и выполняющая функции:
выделение логических элементов документа;
определение особенностей обработки выделенных элементов документа.
Виды разметки:
Командный подход заключается в использовании команд аналогичных командам размещения информации на печатающем устройстве. Пример: Escape – последовательности, использованные разработчиками Epson.
Описательная разметка заключается в использование меток (Tags), отмечающих начало и окончание элемента текста и способ интерпретации элемента, внешнее представление документа формируется процедурами обработки разметки и соответственно может изменяться в зависимости от реализации этих процедур.
Основным отличием описательной разметки является ориентированность на маркирование элементов документа не по критерию обработки (как отображать), а по критерию содержания (чем является).
Билет № 4. TeX. Разработчики. Наиболее известные варианты. Преимущества.
TEX
Система разработана Д. Кнутом.
Основные цели разработки:
Минимизация трудозатрат пользователя, создающего высококачественную печатную продукцию преимущественно научного направления;
Инвариантность (одинаковость) результатов использования системы на различных компьютерах.
Одним из основных преимуществ стала возможность включать в текст математические формулы путем использования символов форматирования, сходных с обозначением математических операций и функций, используемых в языках программирования.
Общий базовый вариант TEX включает приблизительно 300 команд. Вариант, разработанный Кнутом - PlanTex - добавляет около 600 команд. Довольно широко используется вариант, разработанный Лампортом – Latex.
AMS-TEX (American Mathematical Society)
TEX при обработке файла, соответствующего формата получает файл формата DVI. Фалы DVI могут быть напечатаны из средств просмотра интерактивной цифровой видео системы или преобразованных в файлы других общих форматов(PostScript, PDF). В большинстве областей научно технический читательской деятельности TEX стал стандартом.
Билет №5. PostScript. Разработчик концепции. Преимущества. Способы печати. История развития PostScript. Структура файла PostScript. PDF. Разновидности файлов PDF.
Был разработан в 1976 году Джоном Воноком. Целью разработки было совмещение достоинств матричной и векторной технологии внедрения информации. Матричные печатающие устройства первоначально предназначались для вывода текстовой информации и стали альтернативой тИповым принтерам. тИповые принтеры использовали технологию печати печатных машин, то есть пользовались только фиксированным шрифтом; матричные принтеры формировали изображение каждого символа как совокупность точек, это позволяло печатать текст различными шрифтами, настраиваемыми или загружаемыми в принтер, в дальнейшем матричные принтеры стали обрабатывать специальные escape-последовательности, содержащие наборы точек, то есть предоставили возможность печати растровой графики. Устройства вывода векторной графики (плоттеры или графопостроители) обрабатывали команды перемещения пишущего узла, что позволяло эффективно и качественно формировать чертежи. Достоинством векторной графики является то, что любое изображение, в том числе изображение символа шрифта, формируется путем рисования кривых, в результате чего изображение выглядит одинаково при любом масштабе и не проявляется лестничный эффект растрилизации. PostScript представляет любые изображения в виде совокупности прямых и кубических прямых Безье (cubic Bezier Curves), позволяет их вращать, масштабировать, осуществлять другие преобразования и растрилизовать. Интерпретаторы PostScript документов, выполняющие их растеризацию для вывода на любое устройство называют RIP (Raster Image Processor). Интерпретатор может быть реализован аппаратно или программно. Документ на языке PostScript представляет программу, использующую графические операторы. Запись выражения осуществляется в польской нотации RPN (Reverse Polish Notation). PostScript может быть написан вручную, но как правило формируется программно.
Язык PostScript пережил несколько этапов своего развития. Первая редакция PostScript Level 1 была выпущена Adobe в 1984 г. Основными ее преимуществами были:
Платформонезависимость. Независимость от печатающего устройства.
Лицензионная модель распространения интерпретатора PostScript. Любой производитель, лицензировавший интерпретатор, мог использовать PostScript со своим устройством.
Открытость спецификаций PostScript.
PostScript level 2, вышедший в 1991 г., содержал ряд улучшений, касающихся скорости и надежности работы, качества формирования изображений. Были реализованы поддержка цветоделения (формирования отдельных изображений по четырем составляющим CMYK для фотопечати) и распаковка сжатых изображений (в частности, JPEG) непосредственно в контроллере. Ряд менее значительных изменений был реализован в версии PostScript level 3.
Основные три способа использования PostScript документа при печати:
1) Использование PostScript принтера, обрабатывающего непосредственно команды языка аппаратно; 2) Использование аппаратного PostScript адаптера к не PostScript принтеру; 3) Использование программного драйвера GhostScript, выполняющего аналогичную функцию.
Файл PostScript состоит из четырех частей:
заголовка;
пролога;
тела;
эпилога.
PDF – Portable Document Format. Был разработан в начале 1990х годов фирмой Adobe, владевшим на то время форматом PostScipt, формат PDF основан на использовании трех технологий:
1) Подмножество языка PostScipt; 2) Система встраивания и замена шрифтом для обеспечения структурированния; 3) Система хранения.
Три разновидности файлов PDF:
неструктурированные;
структурированные;
размеченные.
Неструктурированные файлы предназначены для хранения текста, разделенного на абзацы. Структурированные файлы хранят также внутреннее форматирование текста, например, атрибуты шрифта. Размеченные файлы хранят элементы разметки, т.е. тэги, т.е. позволяют полноценно описывать структуру документа: списки, таблицы, оглавления и т.п.
Вопрос 6. SGML. Три составных части документа SGML. Три основных типа конструкций SGML. HTML. Назначение. Базовые элементы HTML. Тэги физической разметки. Тэги логической разметки. Тэги оформления списков и таблиц.
SGML – standard generalized markup language
Представляет собой метод создания структурированных документов и языков их разметки, в этом языке каждый документ имеет 3 части:
Декларации (объявления или определения) привязывающие к определенным значениям параметры обработки и имена синтаксиса
Пролог состоит из декларации о типе документа, определяющих типы элементов документа, взаимосвязи между элементами и их атрибуты, а также условные обозначения, которые могут быть задействованы при разметке
Данные - состоящие из разметки документа и собственно информации
Основные типы конструкции языка:
Описание элементов <!ELEMENT …>
Описание объектов <!ENTITY …>
Описание атрибутов <!ATTLIST …>
Элемент – основная компонента документа
Объект – группа или род элементов
Атрибут – характеристика элемента
Декларации и пролог на языке SGML задают структуру документов и будучи отделены от размеченного текста, образуют описание типа документа DTD – Document Type Definition.
Тип документа объявляется в документе путем включения DTD фрагмента или ссылки на DTD файл.
Пример:
<!DOCTYPE type1 [ <!ENTITY greeting “helloworld”>]>
<!DOCTYPE html PUBLIC “- // W3C // DTD XHTML 1.0 Transitional // EN” “ http: //www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>
<!DOCTYPE people_list SYSTEM “example.dtt”>
Пример DTD описания:
<!ELEMENT people_list (person*) > - список элементов person
<!ELEMENT person (name, birthdate?, gender?, socialsecuritynumber?)> - совокупность имя… (с ? – не обязательно)
<!ELEMENT name (#PCDATA)> - строковые фрагменты
<!ELEMENT birthdate (#PCDATA)>
<!ELEMENT gender (#PCDATA)>
<!ELEMENT socialsecuritynumber (#PCDATA)>
HTML – HyperText Markup Language
Синтаксис описывается в DTD
Ориентирован на решение следующих задач:
Описание структуры документа (заголовки, шрифты и …)
Создание гипертекстовых ссылок и управление навигацией в глобальных и локальных сетях
Реализация пользовательских интерфейсов
Базовые элементы HTML документы HEAD и BODY
BODY содержит всю информацию составляющую документ и называется контент, HEAD содержит только информацию о документе.
В HTML имеются следующие средства настройки отображения текстовой информации:
Маркирование заголовков (Н1-6)
Физическая разметка (I B U Strike BIG Small Sub Sup)
Логическая EM(выделение) Strong(более четкое выделение) CODE(код) SAMP(последов-ть символов) VAR (имя переменной, в примерах, формулах) DFN (определение к какому либо термину, обычно жирный и курсив) CITE (цитата, обычный курсив)
Теги оформления списков UL – маркированный, OL – нумерованный, DL – список определений, LI – элемент списка
Теги оформления таблиц TABLE – объявление таблиц, thead – заголовок, tr – строка, td – ячейка, th – заголовочный элемент таблицы