

По теории вероятностей
Вопрос №1.1
Понятие о дискретных случайных величинах. Математическое ожидание и дисперсия дискретной случайной величины. Их свойства.
Случайная величина – это величина, которая в результате испытания примет значение, наперед не известное и зависящее от случайных причин, которые не могут быть учтены. (Дискретные и Непрерывные)
Дискретной (прерывной) называют случайную величину, которая принимает отдельное значение с определенной вероятностью. Число возможных значений этой величины может быть конечным или бесконечным.
Пересчитать значения – значит поставить им в соответствие натуральный ряд чисел.
Математическое ожидание дискретной случайной величины (д.с.в.) – это сумма произведений значений Х на их вероятности (р).
Математическое ожидание примерно равно среднему значению д.с.в. (тем точнее, чем больше число n). Оно больше наименьшего значения и меньше наибольшего – это центр распределения.
n
М(х)
= ∑
xi
pi
i
=1
Свойства математического ожидания:
Мат. ожидание (М.) постоянной величины равно постоянной: М(С) = С
Постоянный множитель можно выносить за знак М.: М(СХ) = С * М(Х)
М. произведения двух независимых случайных величин равно произведению их математических ожиданий: М(ХY) = М(Х) * М(Y)
М. суммы двух случайных величин равно сумме М. слагаемых: М(Х+Y) = М(Х) + М(Y)
Дисперсия д.с.в. равна разности между М. квадрата случайной величины Х и квадратом ее М.
D(X)
= M (X2)
- [M(X)]2
Отклонение значения Х от математического ожидания = Х – М(Х). На практике чаще пользуются квадратом отклонения, реже берут модуль.
Т.о. Дисперсия – это математическое ожидание квадрата отклонения случайной величины от математического ожидания.
n
D(X)
= М(х – М(х))2
= ∑ pi(xi
–
М(х))2
i
=1
Свойства:
Д. всегда больше или рана 0.
D(С) = 0. Дисперсия постоянной равно 0.
Постоянный множитель можно выносить за знак D, возведя его в квадрат: D(СХ) = С2 D(Х)
Д. суммы двух независимых случайных величин равна сумме дисперсий: D(Х+Y) = D(Х)+ D(Y)
Д. разности двух независимых случайных величин равна сумме дисперсий:
D(Х-Y) = D(Х) + D(Y)
1.2 Структурные средние и способы их вычисления
Медиана (Ме). Средняя арифметическая - одна из основных характеристик варьирующих объектов по тому или иному признаку. Однако она не лишена недостатков, так как очень чувствительна к увеличению числа наблюдений или к уменьшению за счет вариант, резко отличающихся по своей величине от основной массы. Поэтому на величину средней арифметической могут значительно влиять крайние члены ранжированного вариационного ряда, которые как раз и наименее характерны для данной совокупности. В связи с этим во многих случаях в качестве обобщающих характеристик совокупности более полезными могут оказаться так называемые структурные средние. Эти величины обычно представляют собой конкретные варианты имеющейся совокупности, которые занимают особое место в ряду распределения.
Одной из таких характеристик является медиана — средняя, относительно которой ряд распределения делится на две равные части: в обе стороны от медианы располагается одинаковое число вариант.
При наличии небольшого числа вариант медиана определяется довольно просто:
1)собранные данные ранжируют.
2) а) при нечетном числе членов ряда центральная варианта и будет его медианой.
б) при четном числе членов ряда медиана определяется по полусумме двух сосед них вариант, расположенных в центре ранжированного ряда.
Н/р, для ранжированных значений признака—12 14 16 18 20 22 24 26 28—медианой будет центральная варианта, т. е. Ме=20, так как в обе стороны от нее отстоит по четыре варианты. Для ряда с четным числом членов— -6 8 10 12 14 16 18 20 22 24 — медианой будет полусумма его центральных членов, т. е. Ме=(14+16)/2=15.
в) для данных, сгруппированных в вариационный ряд, медиана определяется следующим образом:
Сначала находят класс, в котором содержится медиана. Для этого частоты ряда кумулируют в направлении от меньших к большим значениям классов до величины, превосходящей половину всех членов данной совокупности, т. е. n/2. Первая величина в ряду накопленных частот ∑fi, которая превышает п/2, соответствует медианному классу.
Затем берут разность между n/2 и суммой накопленных частот ∑fi предшествующей медианному классу, которая относится к частоте медианного класса fМв;
результат умножают на величину классового интервала λ. Найденную таким способом величину прибавляют к нижней границе хн медианного класса. Если же исходные данные распределены в безынтервальный вариационный ряд, названную величину прибавляют к полусумме соседних классовых вариант. В результате получается искомая величина медианы. Описанные действия выражаются в виде следующей формулы:
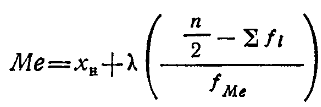
где хн— нижняя граница классового интервала, содержащего медиану, или полусумма соседних классов безынтервального ряда, в промежутке между которыми находится медиана; ∑fi — сумма накопленных частот, стоящая перед медианным классом; fме—частота медианного класса; λ —величина классового интервала; n — общее число наблюдений.
Мода (Мо). Модой называется величина, наиболее част встречающаяся в данной совокупности. Класс с наибольшей частотой называется модальным. Он определяется довольно просто в безынтервальных рядах.
Для определения моды интервальных рядов служит формула:
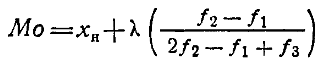
где Хн —нижняя граница модального класса, т. е. класса с наибольшей частотой f2; f1— частота класса, предшествующего модальному; fз—частота класса, следующего за модальным; λ —ширина классового интервала.
Квантили. Наряду с медианой и модой к структурным характеристикам вариационного ряда относятся так называемые квантили, отсекающие в пределах ряда определенную часть его членов. К ним относятся квартили, децили и перцентилн (про центили). Квартили — это три значения признака (Q1, Q2, Q3), делящие ранжированный вариационный ряд на четыре равные части. Аналогично, девять децилей делят ряд на 10 равных частей, а 99 перцентилей — на 100 равных частей.
В практике используют обычно перцентили Р3, Р10, Р25, P50, P75, Р90 и Р97. Причем Р25 И Р75 соответствуют первому и третьему квартилям, между которыми находится 50% всех членов ряда, а Р50 соответствует второму квартилю и равен Медиане, т. е. Р50=Ме. Любой перцентиль определяется рядом последовательных действий, которые можно выразить в виде следующей формулы:
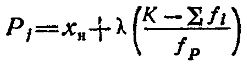
где хн — нижняя граница класса, содержащего перцентиль Рj. Она определяется по величине К=Ljn/100, превосходящей или равной ∑fi в ряду накопленных частот. Здесь Рj— выбранный перцентиль; λ — общее число наблюдений; К — ширина классового интервала; fр — частота класса, содержащего искомый рерцентиль; Lj—так называемый порядок перцентиля, показывающий, какой процент наблюдений имеет меньшую величину, чем Рj. Например, для Р25 и Р75 порядки окажутся соответственно равными 25 и 75%. Таким образом, как и при определе нии медианы, нахождение того или иного перцентиля связаной кумуляцией частот вариационного ряда в направлении от низ шего (начального) класса к высшему.
Вопрос №1.3 Биномиальное распределение и распределение редких событий Пуассона. Математическое ожидание и дисперсия для этих распределений.
Биномиальное распределение – это распределение вероятностей, определяемой формулой Бернулли.
Рn
(к) = Сnк
рк
(1 – р) n-к
Биномиальное распределение имеет 2 параметра: число наблюдений (n) и вероятность наступления события (р).
Если р = 0,5, то график распределения симметричен (рис 1.)
Если р < 0,5, то график наклонен влево (рис. 2)


 Если
р > 0,5, то многогранник распределения
склонен вправо (рис. 3)
Если
р > 0,5, то многогранник распределения
склонен вправо (рис. 3)
рис1 рис 2 рис 3
Распределение Пуассона.
В данном случае дискретная случайная величина может принимать бесконечное число значений n→∞, а р → 0. Принимается, что n*р = λ > 0.
Рλ(к)
=(λк
/к!) е-λ
Математическое ожидание для распределения Пуассона: М = λ
Дисперсия для распределения Пуассона: D = λ
Математическое ожидание для биномиального распределения:
Х – число наступления события А в n независимых испытаниях. Тогда общее число появления события А в этих испытаниях: Х = Х1 + Х2 + …+ Хn.
По 3. свойству математического ожидания М(Х) = М(Х1) + М(Х2) + … + М(Хn); М(Х1) – математическое ожидание числа появления событий в первом испытании … Математическое ожидание числа появления событий в одном испытании равно р, следовательно: М(Х1) = М(Х2) = … = М(Хn)= р.
Значит М(Х) = р + р + …+ р = n * р
Аналогично для дисперсии биномиального распределения:
D(Х) = D(Х1) + D(Х2) + … + D(Хn);
Вычислим дисперсию Х1 по формуле: D(X) = M (X2) - [M(X)]2
М(Х1)= р. M (X2) = р. Следовательно, подставив, получим: D(Х1) = р – р2 = р (1 – р) = рq.
Очевидно, что дисперсия для всех n случайных величин одинакова и равна рq. Таким образом, получили:
D(Х) = n рq.
Вопрос№1.4 Непрерывные случайные величины. Функция распределения непрерывной случайной величины. Плотность вероятности. Мат.ожидание и дисперсия.
Непрерывная – случайная величина (н.с.в.), которая может принимать все значения из некоторого конечного или бесконечного промежутка.
Число возможных ее значений бесконечно.
Функцией распределения н.с.в. называют функцию, определяющую вероятность того, что случайная величина Х в результате испытаний примет значение, меньшее х.
F(х) = Р(Х < х)
Свойства функции распределения:
Значение функции распределения принадлежит отрезку [0;1]
Функция F(х) – неубывающая : F(х2)≥ F(х1) при х1< х2
Если возможные значения случайной величины принадлежат промежутку (а;в), то функция F(х)=0 при х≤а F(х)=1 при х≥в
Следствие 1: Вероятность попадания н.с.в. в интервал [а;в] равна приращению на этом интервале:
Р(а< х <в) = F(в) - F(а)
Следствие 2: Вероятность того, что н.с.в. примет определенное значение d равняется 0. Однако, вероятность н.с.в. попасть в интервал ∆х равна Р(а< х <в) = F(в) - F(а) = ∫f(x) dx (нижний предел интегрирования – а, верхний в)
Т.о. н.с.в. – такая величина, у которой график функции распределения кусочно-дифференцируемая функция с непрерывной производной.
Плотностью распределения вероятности н.с.в. Х называют функцию f(x) = F′(х). График плотности распределения называют кривой распределения.
л
 я
дискретной с.в. существует функция
распределения, а для н.с.в. существуют
и функция и плотность распределения
я
дискретной с.в. существует функция
распределения, а для н.с.в. существуют
и функция и плотность распределения

 1
1
1
график асимптотически прибли
1
1
1
график асимптотически прибли
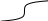 жается
к 1
жается
к 1

Функции распределения дискретной случайной величины и непрерывных случайных величин
Свойства плотности распределения вероятности:
f(x) ≥ 0, т.е. это неубывающая функция.
F(х) = ∫f(x) dx = 1 пределы интегрирования ±∞. Т.к. случайная величина все равно попадет в интервал (-∞; +∞) – это достоверное событие.
Числовые характеристики н.с.в.
М(Х)= ∫х f(x) dx пределы интегрирования ±∞ или, если возможные значения Х принадлежат интервалу (а;в), то тогда нижний предел а, верхний предел в.
D(X) = ∫ М(х – М(х))2 f(x) dx пределы интегрирования ±∞.
Рабочая формула: D(X) = M (X2) - [M(X)]2
Свойства М и D аналогичны свойствам для д.с.в.
1.5. Нормально распределенные случайные величины, их параметры. Основные свойства нормального распределения.
Случайные величины. Как было показано выше, варьирующие признаки в математике рассматривают как переменные случайные величины, способные в одних и тех же условиях испытания принимать различные числовые значения, которые заранее
невозможно предсказать. Случайные величины делят на дискретные и непрерывные. Случайная величина называется дискретной, если она может принимать только определенные фиксированные значения, которые обычно выражаются целыми числами.
Если же случайная величина способна принимать любые числовые значения, она называется непрерывной. Очевидно, что счетные признаки относятся к дискретным случайным величинам, тогда как признаки мерные, варьирующие непрерывно, являются
величинами непрерывными.
Случайная величина X в серии независимых повторных испытаний может принимать самые различные значения, но в каждом отдельном испытании она принимает единственное из возможных значений хi.
Закон распределения случайных величин. Функция f(x), связывающая значения хi
переменной случайной величины x с их вероятностями pi, называется законом распределения этой величины. Закон распределения случайной величины можно задать
таблично, выразить графически в виде кривой вероятности и описать соответствующей формулой. Закон распределения дискретной случайной величины может, например, выражаться в виде биномиальной кривой и описываться формулой Бернулли, которая позволяет находить вероятные значения этой величины в серии независимых испытаний. В отношении же непрерывной случайной величины речь может идти лишь о тех значениях, которые она способна принять с той или иной вероятностью в интервале
от и до. Этот интервал может быть каким угодно: и большим, и малым. Выдающиеся математики А. Муавр (1733), И. Г. Ламберт (1765), П. Лаплас (1795) и К. Гаусс (1821)—установили, что очень часто вероятность P любого значения xi непрерывно распределяющейся случайной величины х находится в интервале от х до х+dx и выражается формулой
Где dx – малая величина, определяющая ширину интервала; π и e математические константы ( π - отношение длины окружности к ее диаметру, равное 3,1416...; e = 2,7183 - основание натуральных логарифмов); σ - стандартное отклонение, характеризующее степень рассеяния значений хi случайной величины X вокруг средней μ, называемой математическим ожиданием. В показатель степени числа е входит нормированное отклонение t = ( xi – μ)/σ - величина, играющая важную роль в исследовании свойств нормального распределения, описываемого формулой (см. выше).
Как видно из этой формулы, закон нормального распределения (нормальный закон) выражает функциональную зависимость между вероятностью Р(Х) и нормированным отклонением t. Он утверждает, что вероятность отклонения любой варианты хi от
центра распределения μ, где xi – μ = 0 определяется функцией нормированного отклонения t.
Графически эта функция выражается в виде кривой вероятности, называемой нормальной
кривой. Форма и положение этой кривой определяются только двумя параметрами: μ и σ. При изменении величины форма нормальной кривой не меняется, лишь график ее смещается вправо или влево. Изменение же величины σ влечет за собой изменение только ширины кривой: при уменьшении σ кривая делается более узкой за счет меньшего рассеяния вариант вокруг средней, а при увеличении σ кривая расширяется. Во всех
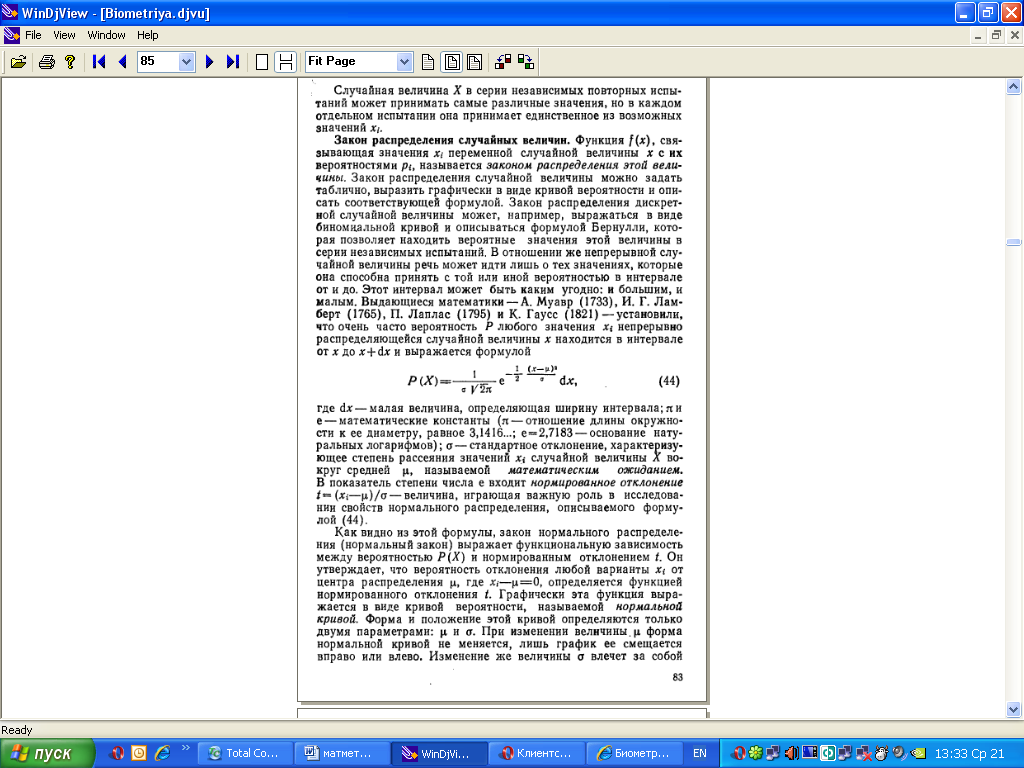
случаях, однако, нормальная кривая остается строго симметричной относительно центра распределения, сохраняя правильную колоколообразную форму (рис. 10).
Нормальная кривая с параметрами μ = 0 и σ=1 называется нормальной или стандартизованной кривой. Она описывается формулой

Любую нормальную кривую можно привести к стандартной (вычитанием μ из xi и
делением на σ). Стандартная кривая (второй график) имеет площадь, равную единице. Ее вершина, т. е. максимальная ордината ymax, соответствует началу прямоугольных
координат, в центр распределения, где xi – μ = 0. Вправо и влево от этого центра случайная величина X может принимать любые значения, и величина каждого отклонения
определяется функцией его нормированного отклонения f(t). Вероятности P таких отклонений, соответствующие разным значениям t, приведены в табл. I Приложений.
Для того чтобы ордината выражала не вероятности, а абсолютные числовые значения случайной величины, т. е. выравнивающие частоты вариант эмпирического распределения, нужно в правую часть формулы (см. выше) внести дополнительные множители: в числитель - общее число наблюдений n , умноженное на вели
чину классового интервала λ, а в знаменатель - величину среднего квадратического отклонения эмпирического ряда распределения Sx.
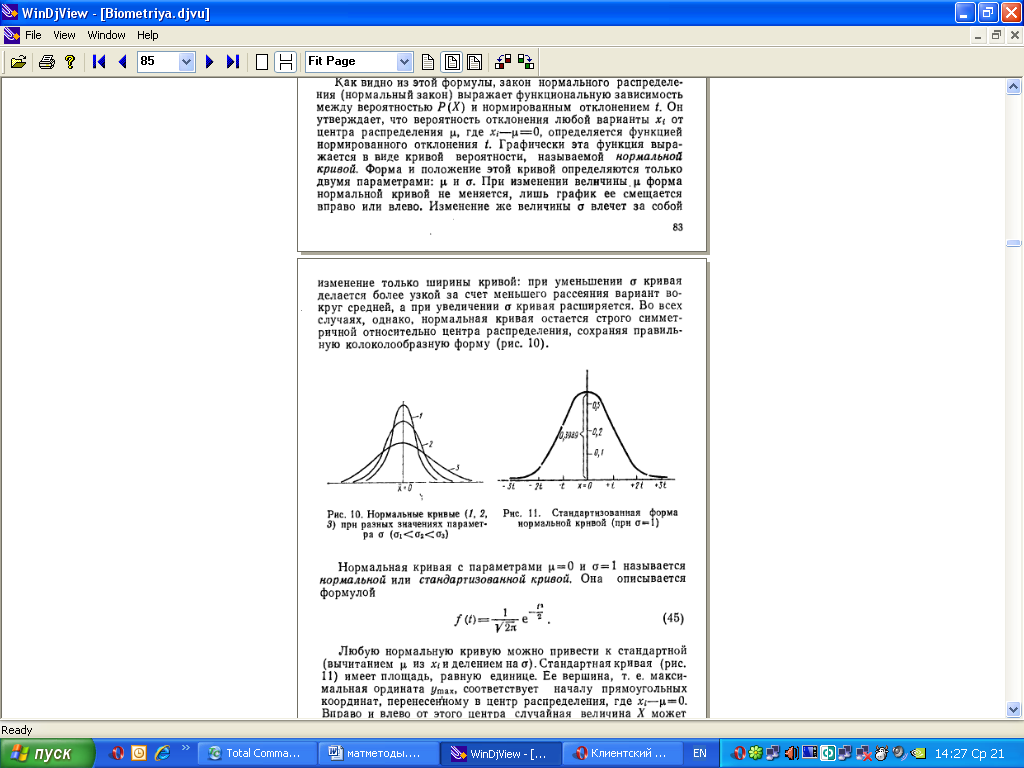
В результате можно записать формулу
Здесь f’ - теоретические (выравнивающие) частоты вариационного ряда, a f(t) - значения функции нормированного отклонения, рассчитанные по формуле (см. выше). Эти значения содержатся в табл. II Приложений. Применяя табл. I и II Приложений, можно по двум показателям (средней арифметической x и среднему квадратическому отклонению Sx) вычислить теоретические частоты эмпирического вариационного ряда, рассчитать ординаты и построить график нормальной кривой. Сравнивая частоты эмпирического вариационного ряда с частотами, вычисленными по формуле (см. выше), можно проверить, следуетэмпирическое распределение нормальному закону.
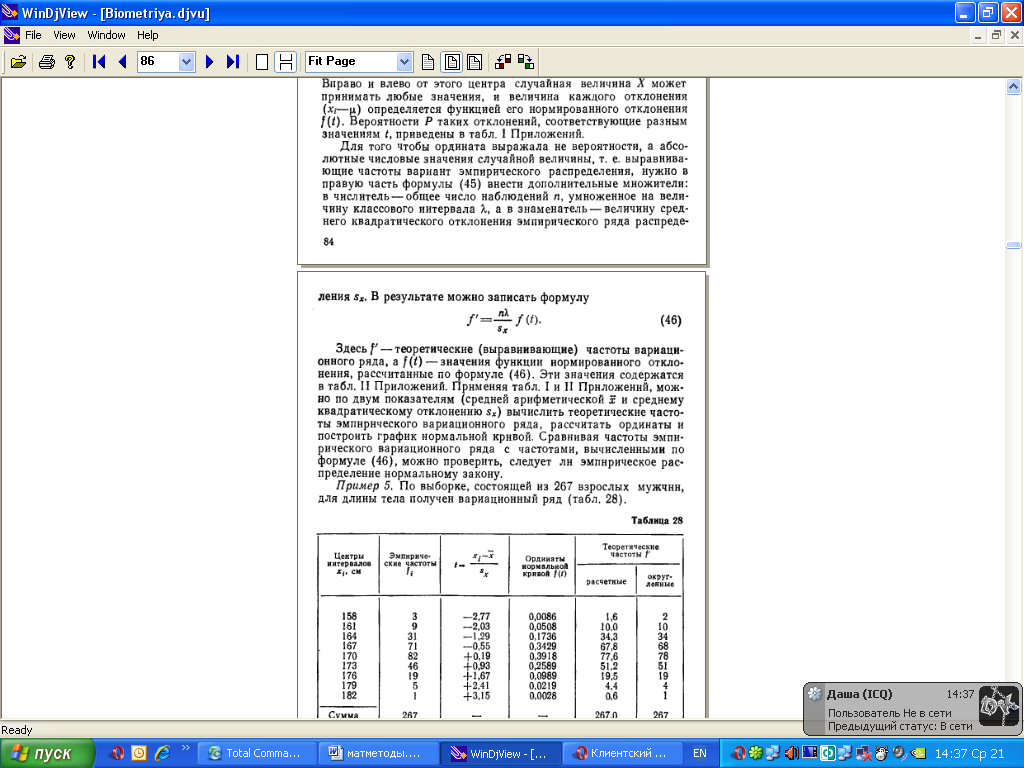
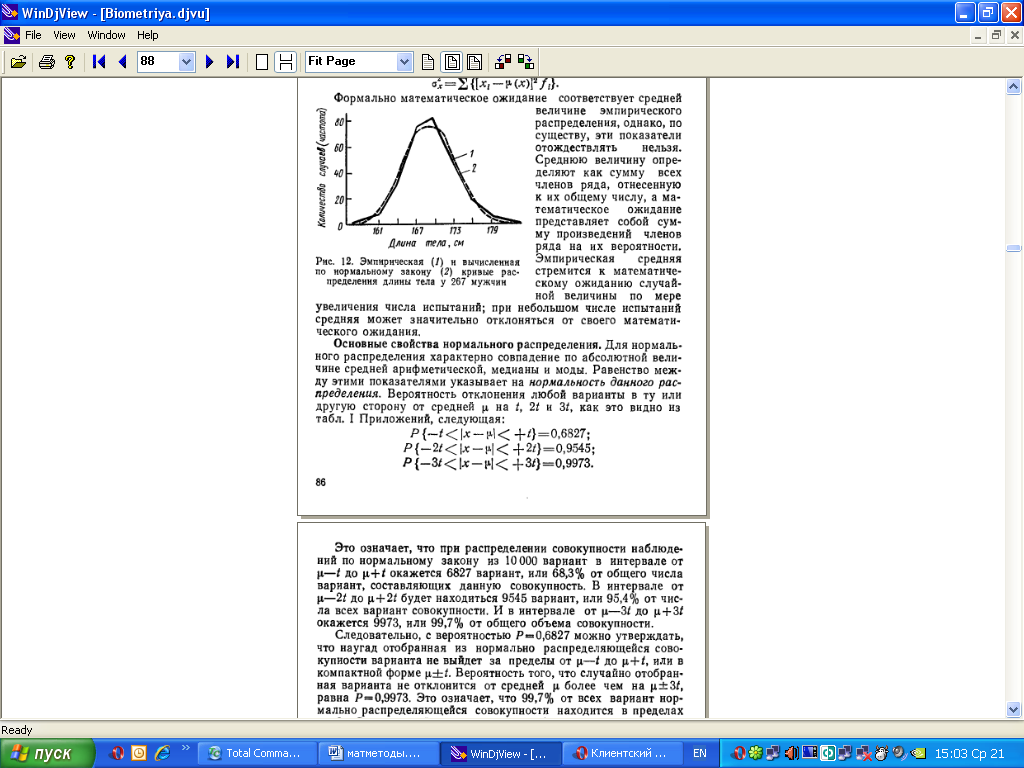
Пример 5. По выборке, состоящей из 267 взрослых мужчин, для длины тела получен вариационный ряд (табл. 28).
Характеристики этого распределения: x ср= 169,22 см и Sx = 4,06 см (эти показатели читатель может вычислить). Из табл. 28 видно, что расчет теоретических частот начинается с нормирования членов вариационного ряда, т. е. вычисления t.
Затем по табл. II Приложений находят значение функции f (t) для каждого нормированного отклонения t эмпирического ряда. Перемножая значения f(t) на величину nλ/Sx, равную в данном случае 267 * 3/406 =198, находят теоретические (выравнивающие)
частоты данного распределения. Из рис. 12 видно, что представленные в виде линейного графика эмпирические и вычисленные по нормальному закону частоты этого распределения согласуются между собой.
Параметры нормального распределения. Как было показано, нормальное распределение характеризуется двумя параметрами: средней величиной, или математическим ожиданием μ, и дисперсией σx2 случайной величины X. Первый параметр равен сумме произведений отдельных значений xi случайной величины X на
их вероятности pi ,т. е.

Второй параметр равен сумме квадратов отклонений отдельных значений хi
случайной величины X от ее математического ожидания μ, т. е.


или с учетом повторяемости fi
Формально математическое ожидание соответствует средней величине эмпирического
распределения, однако, по существу, эти показатели отождествлять нельзя.
Среднюю величину определяют как сумму всех членов ряда, отнесенную к их общему числу, а математическое ожидание представляет собой сумму произведений членов ряда на их вероятности. Эмпирическая средняя стремится к математическому ожиданию случайной величины по мере увеличения числа испытаний; при небольшом числе испытаний средняя может значительно отклоняться от своего математического ожидания.

Основные свойства нормального распределения. Для нормального распределения характерно совпадение по абсолютной величине средней арифметической, медианы и моды. Равенство между этими показателями указывает на нормальность данного рас
пределения. Вероятность отклонения любой варианты в ту или другую сторону от средней μ на t, 2μ и 3μ, как это видно из табл. I Приложений, следующая:
Это означает, что при распределении совокупности наблюдений по нормальному закону из 10 000 вариант в интервале от μ – t до μ + t окажется 6827 вариант, или 68,3% от общего числа вариант, составляющих данную совокупность. В интервале от μ – 2t
до μ + 2t будет находиться 9545 вариант, или 95,4% от числа всех вариант совокупности. И в интервале от μ – 3t до μ + 3t окажется 9973, или 99,7% от общего объема совокупности. Следовательно, с вероятностью P = 0,6827 можно утверждать,
что наугад отобранная из нормально распределяющейся совокупности варианта не выйдет за пределы от μ - t до μ + t, или в компактной форме μ+-t. Вероятность того, что случайно отобранная варианта не отклонится от средней μ более чем на μ+-3t, равна P = 0,9973.
Это означает, что 99,7% от всех вариант нормально распределяющейся совокупности находится в пределах μ±3σ. Этот важный вывод известен в биометрии как правило плюс – минус трех сигм.