

Обработка данных
«Мастер обработки» позволяет применять к импортированным данным необходимый инструмент обработки.
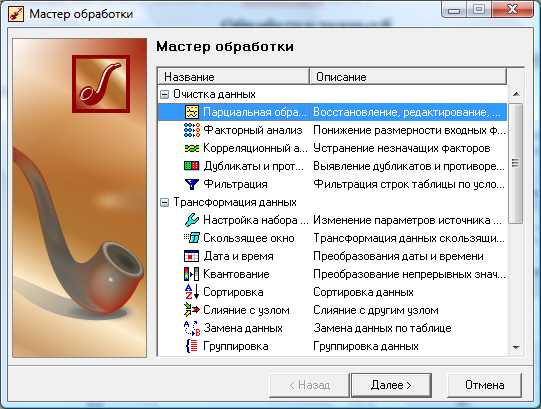
«Мастер обработки» содержит следующие инструменты обработки:
Очистка данных
парциальная (парциальный – частичный, отдельный, составляющий часть чего-нибудь.) предобработка (восстановление пропущенных данных, редактирование аномальных значений, спектральная обработка (сглаживание данных));
факторный анализ (понижение размерности входных факторов);
корреляционный анализ (устранение незначащих факторов);
дубликаты и противоречия (с помощью данного инструмента можно выявить дубликаты и противоречия в исходной выборке данных);
фильтрация (данный инструмент позволяет отфильтровать выборку по необходимому условию, а остальные данные скрыть);
Трансформация данных
настройка набора данных (изменение парметров источниа данных);
скользящее окно (Обработка данных методом скользящего окна применяется при предварительной обработки данных в задачах прогнозирования, когда на вход анализатора (например, нейронной сети) требуется подавать значения нескольких смежных отсчетов исходного набора данных. Термин "скользящее окно" отражает сущность обработки - выделяется некоторый непрерывный отрезок данных, называемый окном, а окно, в свою очередь, перемещается, "скользит", по всему исходному набору данных.
В результате будет получена выборка, где в каждой записи будет содержаться поле, соответствующее текущему отсчету (оно будет иметь то же имя, что и в исходной выборке), а слева и справа от него будут расположены поля, содержащие отсчеты, смещенные от текущего отсчета в прошлое и в будущее соответственно. Следовательно, обработка методом скользящего окна имеет два параметра: глубина погружения - количество отсчетов в "прошлое" и горизонт прогнозирования - количество отсчетов в "будущее".
Необходимо отметить, что для граничных положений окна (конец и начало исходной выборки) будут формироваться неполные записи: вначале исходной выборки будут формироваться пустые значения для "прошлых" отсчетов, а в конце - для "будущих". В зависимости от конкретной ситуации пользователь может включать такие неполные записи в результирующую выборку или исключать их.);
дата и время (позволяет изменять временную шкалу данных с целью оптимизации для дальнейшей обработки. Например, пусть для временного ряда, который задан по дням, требуется построить прогноз, но не подробный - по дням, а более общий - по неделям. Очевидно, что если подать на вход прогнозирующей модели (нейронной сети, линейной модели) данные по дням, то и прогноз будет по дням. Если же предварительно преобразовать данные к недельным интервалам, то и прогноз будет по неделям. Кроме этого, дата может быть преобразована в число или строку, если это необходимо для дальнейшей обработки.);
квантование (происходит распределение значений непрерывных данных по конечному числу интервалов заданной длины);
сортировка (сортировка данных);
слияние – объединение данных из двух таблиц по ключевым полям;
замена – замена значений по таблице подстановки, , которая содержит пары, состоящие из исходного значения и выходного значения, например, <кр> - <красный>, <зел> - <зеленый>, <син> - <синий> или <зима> - <январь>, <весна> - <апрель>, <лето> - <июль>, <осень> - <октябрь>. Для каждого значения исходного набора данных ищется соответствие среди исходных значений таблицы подстановок. Если соответствие найдено, то значение меняется на соответствующее выходное значение из таблицы подстановок. Если значение не найдено в таблице, оно может быть либо заменено значением, указанным для замены <по умолчанию>, либо оставлено без изменений (если такое значение не указано).
Кроме того, замену данных можно использовать для замены пустых значений на какое-то определенное значение.
группировка (позволяет уменьшить число записей исходной выборки, за счет объединения записей с одинаковыми данными, не утратив при этом информативности);
разгруппировка данных – восстанавливает выборку, к которой была применена операция группировки.
Data Mining
автокорреляция (определение степени статистической зависимости между различными значениями (отсчетами) случайной последовательности в исходном поле выборке данных. В процессе автокорреляционного анализа рассчитываются коэффициенты корреляции (мера взаимной зависимости) для двух значений выборки, находящихся друг от друга на определенном количестве отсчетов, называемые также лагом. Совокупность коэффициентов корреляции по всем лагам представляет собой автокорреляционную функцию ряда (АКФ): R(t)=corr(X(t),X(t+k)), где k>0 - целое число (лаг));
линейная регрессия (построение линейной регрессионной модели данных, позволяющая прогнозирования целевой переменной);
логистическая регрессия – строит бинарную логистическую регресионную модель. Логистическая регрессия – это разновидность множественной регрессии. С помощью логистической регрессии можно оценивать вероятность того, что событие наступит для конкретного испытуемого (больной/здоровый, возврат кредита/дефолт и т.д.). Логистическая регрессия описывается уравнением:
P=a1*x1+a2*x2+...+an*xn + a0, P=1/(1+exp(-y)) - логистическая функция.
В результате работы данного компонента строится бинарная логистическая регрессионная модель. Полученную в результате модель можно использовать для прогнозирования целевой бинарной переменной.
нейронная сеть (выполняет обработку данных с помощью многослойной нейронной сети. В этом режиме Мастер обработки позволяет сконструировать нейронную сеть с заданной структурой, определить ее параметры и обучить с помощью одного из доступных в системе алгоритмов обучения. В результате будет получен эмулятор нейронной сети, который может быть использован для решения задач прогнозирования, классификации, поиска скрытых закономерностей, сжатия данных и многих других приложений);
дерево решений (позволяет решать задачи отнесения какого-либо объекта (строчки набора данных) к одному из заранее известных классов);
карта Кохонена - выполняет кластеризацию данных. Алгоритм функционирования самоорганизующихся карт (Self Organizing Maps - SOM) Кохонена представляет собой один из вариантов кластеризации многомерных векторов - алгоритм проецирования с сохранением топологического подобия);
ассоциативные правила (обнаружение зависимостей между связанными событиями. Ассоциативные правила позволяют находить закономерности между связанными событиями. Примером такого правила, служит утверждение, что покупатель, приобретающий «Хлеб», приобретет и «Молоко» с вероятностью 75%. Впервые эта задача была предложена для поиска ассоциативных правил для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому иногда ее еще называют анализом рыночной корзины (market basket analysis);
пользовательская модель - задание модели вручную по формулам. Пользовательская модель позволяет создавать аналитические модели на основании формул и экспертных оценок. Такая возможность требуется в тех случаях, когда объем исходной выборки мал, либо ее качество недостаточно для того, чтобы обучить нейронную сеть. В этом случае можно воспользоваться хорошо известными простыми моделями, задающимися с помощью формул. Примером такой модели может служить скользящее среднее или модель авторегрессии.
Рассмотрим описанные выше инструменты на следующих примерах.
Импортируем файл «TestForPPP.txt», находящийся в папке…\Deductor Academic\Samples. Выполним команду «Выделить кнопку Сценарии/щелкнуть левой кнопкой мыши на кнопку мастера импорта /Выбрать «Текстовый файл с разделителями»/Далее/Используя кнопку … открываем файл TestForPPP.txt/Далее/Далее/Далее/Пуск/Далее. На 6 шаге (настройка предыдущих этапов остается по умолчанию) необходимо определить вид отображения, где наиболее информативным в данном случае будет диаграмма. Установим переключателя «Диаграмма» и нажмем кнопку «Далее». При настройке столбцов (7 шаге) выберем «Синус» и тип диаграммы «Линии», нажмем кнопку «Далее».
На последнем шаге необходимо указать название узла в дереве сценариев.
Озаглавим узел и нажмем «Готово». На этом этапе работа мастера импорта закончена, и в дереве сценариев появится новый узел. В рабочей области окна представлена диаграмма столбца «Синус» и соответствующая панель инструментов. Нажмём кнопку – 3-х мерный вид.
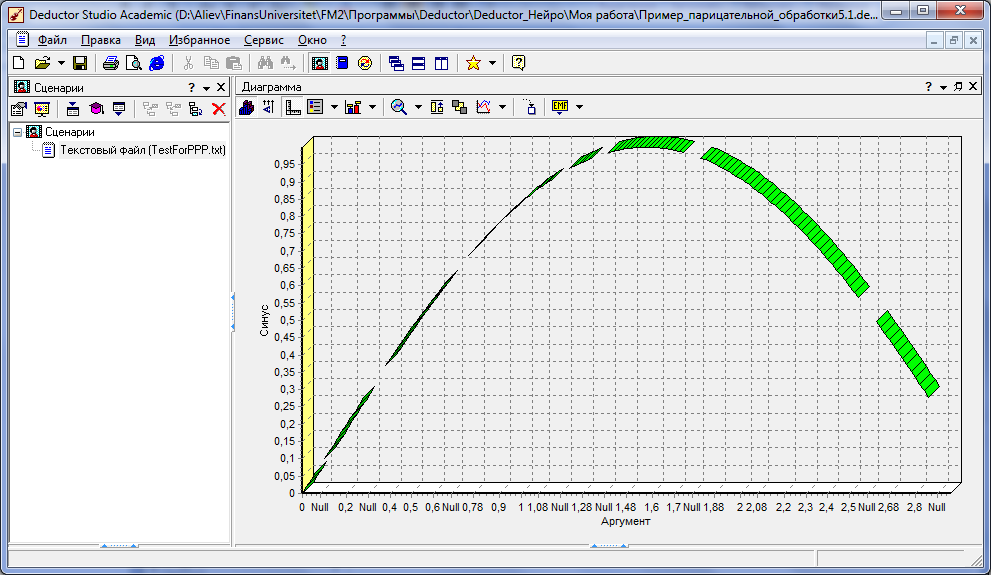
В большинстве случае исходные данные не соответствуют определенным критериям качества и не пригодны для анализа. Предобработка становится нужным шагом для обеспечения удовлетворительного результата анализа.