

Импорт данных и способы визуализации
Импорт данных из различных форматов является первым шагом в процессе анализа информации. Импортированные данные могут быть обработаны различными инструментами Deductor, полученные новые данные также могут быть в свою очередь опять обработаны. Результаты обработки можно просмотреть различными способами, используя методы визуализации и экспортировать в наиболее популярные форматы.
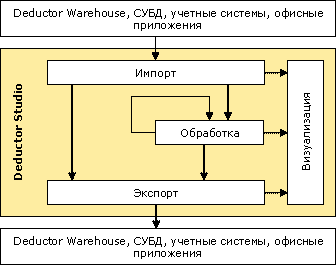
Рисунок 1. Схема функционирования Deductor Studio
В дальнейшем под сценарием будем понимать последовательность действий, которые необходимо провести для анализа данных. Под действиями подразумевается очистка от шумов и аномальных явлений, преобразование данных, построение моделей, при этом действия можно комбинировать произвольным образом, дабы достичь наилучшего результата.
Общий вид окна приложения Deductor ничем не отличается от тех, которые нам хорошо знакомы: строка заголовка, строка меню, панель инструментов и собственно рабочая область, которая разделена на две части. В левой части располагается область сценариев, которая в свою очередь имеет соответствующую панель инструментов, а в правой отображаются данные в том или ином состоянии.
Построение
сценария в Deductor
начинается с вызова мастера импорта
![]() ,
который располагается на панели
инструментов Сценарии,
или выбрать соответствующую команду
из контекстного меню, вызываемого в
любой области панели Сценарии.
,
который располагается на панели
инструментов Сценарии,
или выбрать соответствующую команду
из контекстного меню, вызываемого в
любой области панели Сценарии.
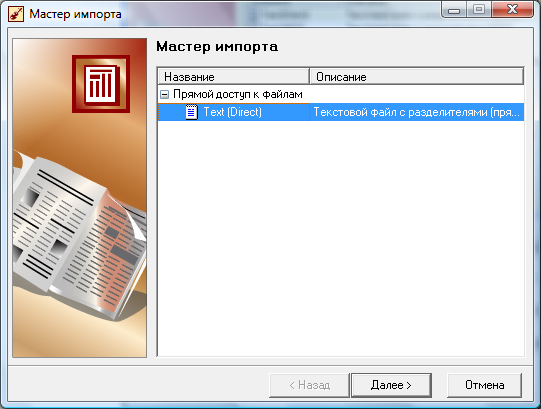
В диалоговом окне мастера импорта нужно выбрать из списка тип импортируемого формата и для перехода к следующему шагу щелкнуть по кнопке «Далее». Для различных источников данных количество шагов необходимых для импорта файла с тем или иным форматом разное.
Далее на втором
шаге указываем путь к файлу с помощь
кнопки
![]() .
.
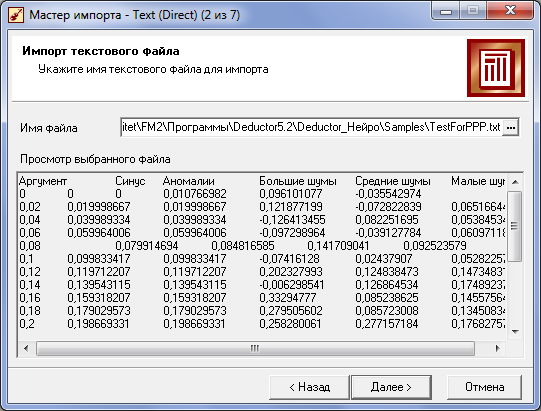
На
третьем шаге для текстового файла
требуется настроить поля (начать
импорт со строки
1, символом-разделителем
является в
данном случае запятая, разделитель
целой и дробной части
![]() )
и т.д.
)
и т.д.
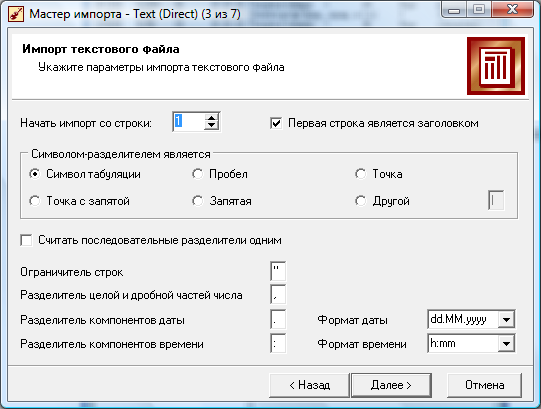
Важным этапом импорта является этап, на котором нужно настроить поля импортируемого файла. В строке имя столбца можно переименовать столбец для дальнейшего удобства работы.
Далее каждому полю присваивается соответствующий тип, если это необходимо:
логический – данные в этом поле принимают значения 0 и 1 (ложь или истина);
дата/время – данные типа дата/время;
вещественный – числа с плавающей точкой;
целый – значения данного поля целочисленные;
строковый – данные в виде строки символов.
После указывается вид данных:
непрерывный – значения поля могут принимать любое значение в рамках своего типа (как правило, непрерывными являются числовые значения);
дискретный – данные в столбце могут принимать ограниченное число значений (обычно дискретный характер носят строковый переменные).
К указанию типа и вида данных нужно отнестись внимательно, поскольку ошибка может привести к потере данных. Например, если в поле хранятся данные с плавающей точкой, а вид данных зададим «целый», то после импорта, в таблице все значения данного поля окажутся пустыми и появится сообщение об ошибке при преобразовании данных.
Затем, если это необходимо, нужно настроить назначение столбца:
используемое – поле будет использоваться в процедурах обработки данных;
первичный ключ – поле используется в качестве первичного ключа;
входное – поле таблицы, построенное на основе таблицы, которое будет являться входным полем для нейронной сети, дерева решений и т.д.;
выходное – поле таблицы, построенное на основе таблицы, которое будет являться выходным – целевым полем для нейронной сети, дерева решений и т.д.;
информационное – в данном поле находится вспомогательная информация, которая не обрабатывается, но ее полезно иногда отобразить;
измерение – поле будет использоваться в качестве измерения в многомерной модели данных;
факты – значения поля будут использованы в качестве фактов в многомерной модели данных;
транзакция – поле, содержащее идентификатор событий, происходящих совместно (одновременно). Например, номер чека, по которому приобретены товары. Тогда покупка товара – это событие, а их совместное приобретение по одному чеку – транзакция.
элемент – поле, содержащее элемент транзакции (событие).
На следующем шаге, нажатием кнопки «Пуск», запускается сам процесс импорта данных с настроенными параметрами. В строке «Название процесса» отображается этап процесса импорта данных, выполняемый в текущий момент. Процесс импорта отображается с помощью строки «Процент выполнения текущего процесса».
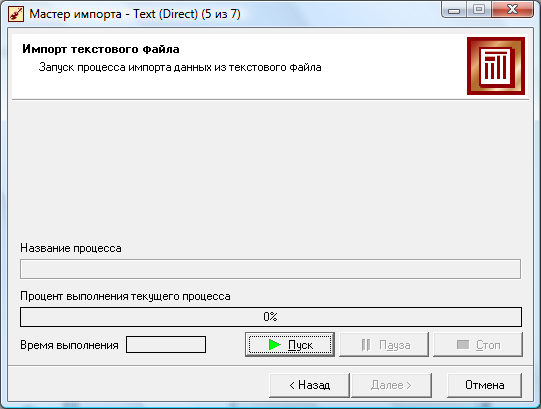
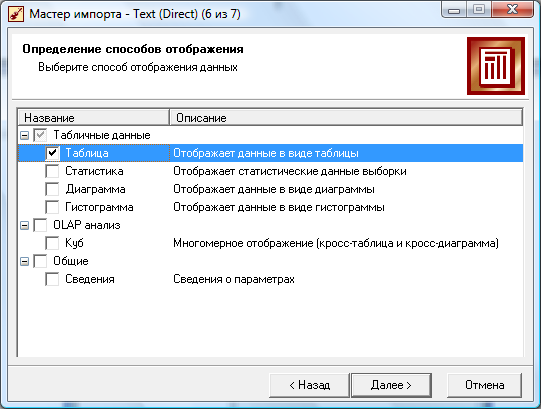
Если процесс импорта данных остановился, значит, возникли проблемы при доступе к источнику данных. В данном случае появится диалоговое окно с сообщением об ошибке и, исходя из текста, можно вернуться на необходимое количество шагов назад и попробовать внести соответствующие изменения. В случае возникновения ошибок, несвязанных с Deductor, необходимо внести должные изменения в исходный файл, сохранённый до его загрузки в Deductor. Также остановить процесс импорта можно с помощью кнопки «Стоп». После этого появляется возможность вернуться на предыдущие шаги процесса импорта для проверки и изменения параметров. Далее процесс импорта может быть запущен заново или отменен. Если импорт данных был завершен успешно, то в строке «Название процесса» появится сообщение «Успешное завершение». С помощью кнопки «Пауза» можно приостановить процесс импорта на определенное время. Следующий шаг позволяет выбрать метод визуализации.
При способе отображения - «Таблица», все поля выборки выводятся в отдельном столбце, они озаглавлены именами столбцов, если не были определены названия столбцов. В таблице имеется панель инструментов с помощь, которой можно:
управление конфигурациями (позволяет сохранить этапы обработки текущего файла);
настройка полей (позволяет в зависимости от типа данных применять особый формат, а также изменять их размер и способ выравнивания);
способ отображения (вывод данных в виде таблицы или формы);
показать онлайн статистику (отображает статистику импортированных данных);
фильтрацию (осуществляет выбор записей в таблице по заданному условию);
экспорт таблицы (осуществить экспорт данных в один из доступных форматов).
Визуализация «Таблица» доступна для любого инструмента обработки.
«Статистика» представляет основные характеристики текущей выборки данных (минимум, максимум, среднее, стандартное отклонение, сумма, сумма квадратов, количество уникальных значений, количество пустых значений). Данный вид отображения доступен для любого инструмента обработки.
Визуализация «Диаграмма» позволяет отображать результаты обработки в графическом виде, где показывается зависимость значений одного поля от другого.
При
настройке параметров диаграммы можно
выбрать поля данных, которые должны
отображаться на диаграмме, назначить
для них определенный цвет, определить
тип диаграммы, а также настроить
отображение подписей и значений по оси
X. Для отображения того или иного поля
на диаграмме нужно установить флажок
напротив соответствующего поля. Чтобы
выбрать тип диаграммы нужно воспользоваться
значком ![]() и в списке выбрать тот или иной вариант
(столбчатая диаграмма, непрерывные
линии, линии, точки, диаграмма с областями,
круговая диаграмма, лепестковая
диаграмма). Выбрав в списке «Подписи по
X» определяется поле, заголовок которого
будет использоваться в качестве подписи
по горизонтальной оси. Флажок «Значения
по X» позволяет сделать доступным список,
в котором можно выбрать поле, значения
которого будут отображаться по
горизонтальной оси.
и в списке выбрать тот или иной вариант
(столбчатая диаграмма, непрерывные
линии, линии, точки, диаграмма с областями,
круговая диаграмма, лепестковая
диаграмма). Выбрав в списке «Подписи по
X» определяется поле, заголовок которого
будет использоваться в качестве подписи
по горизонтальной оси. Флажок «Значения
по X» позволяет сделать доступным список,
в котором можно выбрать поле, значения
которого будут отображаться по
горизонтальной оси.
С помощью кнопок на панели инструментов в окне построенной диаграммы или в контекстном меню, вызываемом для поля диаграммы, доступны следующие действия:
– 3-х мерный вид – отображает данные в виде объемных столбцов или линий, что в ряде случаев улучшает наглядность диаграммы;
– ориентация меток – позволяет выбрать ориентацию меток;
– показать оси – включает или выключает отображение осей;
– легенда – позволяет показать или скрыть легенду;
– тип меток – позволяет включить или выключить отображение меток для каждого элемента диаграммы:
скрыть метки – метки не отображаются;
значение – отображается собственно значение, отображаемое элементом диаграммы;
проценты – выводится процентное соотношение данного элемента к итоговому результату;
метки – выводятся подсказки, необходимые для понимания смысла того или иного элемента;
метка, процент – одновременно выводятся и метки и проценты;
метка, знаение – одновременно выводятся и метки и знаения;
процент, итог – одновременно выводятся и процентное отношение элемента ко всему итоговому результату и сам этот результат;
метка, процент, итог – одновременно отображаются метка, процентное соотношение и итог;
координата Х – выводится координата столбца по оси X;
– отображать поля – позволяет пользователю выбрать поля, отображаемые на диаграмме;
– нормализация – приведение всех графиков к одному масштабу;
– перенести первый график на задний план – перемещает первый столбец в серии на последнее место, при повторном нажатии последнее место займет второй столбец и т.д.;
– выберите вид графика – выбирается один из доступных видов графика (столбчатая диаграмма, непрерывные линии, линии, точки, диаграмма с областями);
– детализация – позволяет детализировать тот или иной выбранный участок графика в нижней части окна в виде таблицы;
– экспорт таблицы (осуществить экспорт данных в один из доступных форматов).
«Гистограмма» показывает график разброса показателей в отличие от диаграммы, она отображает количество значений, попавших в заданный интервал, а не сами значения. По виду гистограммы можно оценить распределение данных, если столбцы примерно одинаковы, то можно сказать, что распределение носит равномерный характер, когда же имеется ярко выраженный максимум, то, по всей видимости, это нормальное распределение. Методы создания и работы с гистограммой аналогичны методам создания и работы с диаграммами.
«Куб» является распространенным методом многомерного представления данных, получивших название OLAP (On-Line Analyzing Process). Данные представлены в виде многомерных кубов, называемых также OLAP-кубами, или гиперкубами. Данные, организованные в OLAP-кубах, представляются в виде кросс-таблицы, которое является удобным средством визуализации многомерных данных и получения необходимых форм отчетов. Кросс-таблица строится на основе многомерного представления в виде OLAP-куба и содержит измерения и факты, определенные при построении куба. Основное преимущество кросс-таблицы в том, что ее структура не является жестко закрепленной. Манипулируя заголовками измерений, аналитик может добиться, чтобы кросс-таблица выглядела наиболее информативно. В платформе Deductor есть возможность строить на основе кросс-таблицы кросс-диаграмму, которая привязана к кросс-таблицы и будет автоматически перестраиваться в соответствии с любыми изменениями кросс-таблицы.
Для получения на основе текущей выборки данных кросс-таблицы необходимо выполнить:
настройка назначений полей куба (имя столбца, тип данных, назначение и вид данных);
настройка измерений (распределить из доступных измерений поля по строкам и столбцам);
настройка фактов (выбор полей, которые будет отображаться в качестве фактов в кросс-таблице с соответствующей агрегацией)
После построения кросс-таблицы доступна панель инструментов, с помощью которой выполнимы следующие операции:
![]() – управление
конфигурациями (позволяет сохранить
этапы обработки текущего файла);
– управление
конфигурациями (позволяет сохранить
этапы обработки текущего файла);
– настройка размещения измерений;
– настройка фактов – здесь можно выбрать факты для отображения в кросс-таблице, а также выбрать функцию агрегации для каждого факта;
– селектор – фильтрация записей в кросс-таблице, по значениям фактов, которое может выполняться отдельно по каждому измерению;
– сортировка значений измерений;
– настройка форматов отображения... – открывает окно «Настройка форматов отображения измерений и фактов», в котором можно настроить параметры отображения значений измерений и фактов в кросс-таблице;
– транспонирование – выполняет транспонирование кросс-таблицы, в результате чего измерения, располагавшиеся в столбцах, будут находиться в строках и наоборот;
– показывать итоги – сокрытие/отображение итогов: везде, в колонках, в строках, нигде.
– положение фактов – позволяет выбрать одну из 2-х позиций положения фактов:
![]() – в колонках –
заголовки фактов расположены горизонтально
над таблицей значений фактов.
– в колонках –
заголовки фактов расположены горизонтально
над таблицей значений фактов.
– в строках – заголовки фактов расположены вертикально слева от таблицы значений фактов. Такое положение фактов удобно использовать при большом количестве фактов.
– выравнивание ширины колонок – позволяет выбрать один из следующих способ выравнивания ширины колонок с фактами в кросс-таблице:
![]() –
равная ширина
фактов – включает режим, при котором
изменение ширины одной колонки приводит
к тому, что ширина всех колонок, относящихся
к одному факту, становится равной ширине
изменяемой колонки;
–
равная ширина
фактов – включает режим, при котором
изменение ширины одной колонки приводит
к тому, что ширина всех колонок, относящихся
к одному факту, становится равной ширине
изменяемой колонки;
– равная ширина колонок – включает режим, при котором изменение ширины одной колонки приводит к тому, что ширина всех колонок становится равной ширине изменяемой колонки;
– произвольная ширина – включает режим, при котором ширина всех колонок с фактами независимы;
– детализация – открывает окно «Таблица», в котором компактно отображается вся информация, связанная с выделенной ячейкой или ячейками кросс-таблицы. Это особенно удобно при работе с большими массивами данных, когда кросс-таблица занимает большую площадь. В таблицу детализации входят все измерения, факты и столбцы, помеченные как информационные при настройке назначения полей;
– отображать кросс-диаграмму – во включенном режиме слева от кросс-таблицы отображается кросс-диаграмма;
– возможность экспорта данных в доступные форматы: MS Excel, MS Word, HTML формат; · Экспорт в - экспортировать полученный отчет в MS Excel.
Диаграмма, построенная на основе кросс-таблицы, называется, кросс-диаграммой, и представляет с собой точное соответствие текущему состоянию кросс-таблицы и при любых ее изменениях меняется соответственно.
В окне кросс-диаграммы имеется панель инструментов подобная той, которая имеется в окне диаграммы, но с дополнительными функциями:
![]() – ограничения –
открывает окно с информацией об
ограничениях на отображаемую информацию
(если кнопка имеет синий цвет – ограничения
не превышены, если красный, то на
кросс-диаграмме размещена не вся
информация)
– ограничения –
открывает окно с информацией об
ограничениях на отображаемую информацию
(если кнопка имеет синий цвет – ограничения
не превышены, если красный, то на
кросс-диаграмме размещена не вся
информация)
– транспонирование – аналогично операции транспонирования таблицы;
Вместе с тем визуализация кросс-диаграмма не содержит кнопки «Нормализация» и «Перенести первый график на задний план».
Если
процесс импорта данных в Deductor
прошел успешно, тогда на панели
инструментов Сценарии
доступны кнопки –
![]() – Мастер визуализации...,
– Мастер обработки,
– Мастер экспорта и
– Удалить узел. Каждая кнопка вызывает
соответствующее диалоговое окно, за
исключением команды «Удалить узел».
– Мастер визуализации...,
– Мастер обработки,
– Мастер экспорта и
– Удалить узел. Каждая кнопка вызывает
соответствующее диалоговое окно, за
исключением команды «Удалить узел».
С помощью кнопки «Мастер визуализации...» мы можем добавить и настроить тот или иной визуализатор, о чем было подробно изложено выше.
Диалоговое окно «Мастер экспорта» позволяет экспортировать данные в доступные форматы (Microsoft Excel, Microsoft Word, HTML, TEXT, DBF и т.д.).
Команда «Удалить узел» позволяет после выделения удалить тот или иной узел.