

1 Иерархическая модель.
Отношения в иерархической модели данных организованы в виде совокупностей деревьев, где дерево - структура данных, в которой тип сегмента потомка связан только с одним типом сегмента предка.
Иерархическая модель данных, как следует из названия, имеет иерархическую структуру, т.е. каждый из элементов связан только с одним стоящим выше элементом, но в, то, же время на него могут ссылаться один или несколько стоящих ниже элементов


Рисунок 2 - Логическая иерархическая модель
В терминологии иерархической модели используются более конкретные понятия: «элемент» (узел); «уровень» и «связь». Узел чаще всего представляет собой атрибут (признак), описывающий некоторый объект.
Иерархически модель схематически изображается в виде графа, в котором каждый узел является вершиной .
Эта модель представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих граф – дерево с иерархической структурой (рисунок 2,3).
Т акой
граф имеет единственную вершину, не
подчиненную никакой другой вершине
и находящуюся на самом верхнем
(первом) уровне. Число вершин первого
уровня определяет число деревьев в базе
данных. Запрещены взаимосвязи на одном
уровне.
акой
граф имеет единственную вершину, не
подчиненную никакой другой вершине
и находящуюся на самом верхнем
(первом) уровне. Число вершин первого
уровня определяет число деревьев в базе
данных. Запрещены взаимосвязи на одном
уровне.



Рисунок 3 – Пример иерархической модели данных
2 Сетевая модель.
Сети - естественный способ представления отношений между объектами. Они широко применяются в математике, исследованиях операций, химии, физике, социологии и других областях знаний. Сети обычно могут быть представлены математической структурой, которая называется направленным графом. Направленный граф имеет простую структуру. Он состоит из точек или узлов, соединенных стрелками или ребрами.
Сетевая модель данных - это представление данных сетевыми структурами типов записей и связанных отношениями мощности один-к-одному или один-ко-многим.
Сетевая модель более демократична. В сетевой модели отсутствует понятие главного и подчиненного объекта (рисунок 4,5). Один и тот же объект может выступать как главный и как подчиненный, то есть иметь любое количество взаимосвязей. Здесь допустимы связи на одном уровне. Эта модель использует ту же терминологию, что и иерархическая модель: «узел», «уровень» и «связь».

Рисунок 4 - Логическая сетевая модель
Как известно из теории графов, сетевой граф может быть преобразован в граф-дерево.

Рисунок 5 – Пример сетевой модели данных
3 Реляционная модель.
В 1970-1971 годах Е.Ф.Кодд опубликовал две статьи, в которых ввел реляционную модель данных и реляционные языки обработки данных - реляционную алгебру и реляционное исчисление.
Реляционная алгебра Процедурный язык обработки реляционных таблиц.
Реляционное исчисление Непроцедурный язык создания запросов.
Все существующие к тому времени подходы к связыванию записей из разных файлов использовали физические указатели или адреса на диске. В своей работе Кодд продемонстрировал, что такие базы данных существенно ограничивают число типов манипуляций данными. Более того, они очень чувствительны к изменениям в физическом окружении. Когда в компьютерной системе устанавливался новый накопитель или изменялись адреса хранения данных, требовалось дополнительное преобразование файлов. Если к формату записи в файле добавлялись новые поля, то физические адреса всех записей файла изменялись. То есть такие базы данных не позволяли манипулировать данными так, как это позволяла бы логическая структура. Все эти проблемы преодолела реляционная модель, основанная на логических отношениях данных.
Существует два подхода к проектированию реляционной базы данных.
Первый подход заключается в том, что на этапе концептуального проектирования создается не концептуальная модель данных, а непосредственно реляционная схема базы данных, состоящая из определений реляционных таблиц, подвергающихся нормализации.
Второй подход основан на механическом преобразовании функциональной модели, созданной ранее, в нормализованную реляционную модель. Этот подход чаще всего используется при проектировании больших, сложных схем баз данных, необходимых для корпоративных информационных систем.
Основная идея реляционной модели данных заключается в том, чтобы представить любой набор данных в виде двумерного массива – таблицы. В простейшем случае реляционная модель описывает единственную двумерную таблицу (таблица 1), но чаще всего эта модель описывает структуру и взаимоотношения между несколькими различными таблицами.
Обязательным условием построения реляционной модели является наличие в каждой таблице первичного ключа. Этот вид модели имеет наибольшее распространение при построении баз данных.
Таблица 1 – Структура реляционной таблицы
Имя файла
|
||||||
Поле
|
Признак ключа |
Формат поля |
||||
Имя (обозначение)
|
Полное наименование
|
Тип |
Длина |
Точность (для чисел) |
N/NN |
|
имя1
|
|
|
|
|
|
|
…
|
|
|
|
|
|
|
имя n
|
|
|
|
|
|
|
Рассмотрим пример реляционной модели данных (таблица 2).
Таблица 2 - Детали приборов
Код |
Расположение поверхностей |
Дополнительная характеристика |
1 |
Тела вращения |
Валы |
2 |
Тела вращения |
Втулки |
3 |
Не тела вращения |
Плоские |
4 |
Не тела вращения |
Объемные |
На рисунке 6 показано разделение таблицы 2 на две связанные таблицы.
Код |
Дополнительная характеристика |
1.1 |
Валы |
1.2 |
Втулки |
2.1 |
Плоские |
2.2 |
Объёмные |
Код |
Расположение поверхностей |
1 |
Тела вращения |
2 |
Не тела вращения |

Реляционные модели данных, или реляционные базы данных, являются в настоящее время основным способом в проектировании и организации информационных систем в производстве и бизнесе.
Реляционная модель данных. Свойства отношений. Проектирование реляционной модели данных.
Реляционная модель основана на математическом понятии отношения, физическим представлением которого является таблица.
Отношение – это плоская таблица, состоящая из столбцов и строк.
В любой реляционной СУБД предполагается, что пользователь воспринимает базу данных как набор таблиц. Однако следует подчеркнуть, что это восприятие относится только к логической структуре базы данных, т.е. ко внешнему и концептуальному уровням архитектуры. Подобное восприятие не относится к физической структуре базы данных, которая может быть реализована с помощью различных структур хранения.
Атрибут – это поименованный столбец отношения.
В реляционной модели отношения используются для хранения информации об объектах, представленных в базе данных. Отношение обычно имеет вид двумерной таблицы, в которой строки соответствуют отдельным записям, а столбцы – атрибутам. При этом атрибуты могут располагаться в любом порядке – независимо от их переупорядочивания отношение будет оставаться одним и тем же, а потому иметь тот же смысл.
Домены в реляционной модели представляют собой множество значений атрибутов. Каждый атрибут реляционной базы данных определяется на некотором домене. Домены могут отличаться для каждого из атрибутов, но два и более атрибутов могут определяться на одном и том же домене. Понятие домена позволяет централизованно определять смысл и источник значений, которые могут получать атрибуты. В результате при выполнении реляционной операции системе доступно больше информации, что позволяет ей избежать семантически некорректных операций.
Элементами отношения являются кортежи, или строки, таблицы. Кортежи могут располагаться в любом порядке, при этом отношение будет оставаться тем же самым, а значит, и иметь тот же смысл.
Описание структуры отношения вместе со спецификацией доменов и любыми другими ограничениями возможных значений атрибутов иногда называют его заголовком (или содержанием (intension)). Обычно оно является фиксированным, до тех пор, пока смысл отношения не изменяется за счет добавления в него дополнительных атрибутов. Кортежи называются расширением (extension), состоянием (state) или телом отношения, которое постоянно меняется.
Степень отношения определяется количеством атрибутов, которое оно содержит. Отношение с двумя атрибутами называется бинарным (binary), отношение с тремя атрибутами – тернарным (ternary), а для отношений с большим количеством атрибутов используется термин n-арный (n-аrу). Определение степени отношения является частью заголовка отношения.
Кардинальность – это количество кортежей, которое содержит отношение. Эта характеристика меняется при каждом добавлении или удалении кортежей. Кардинальность является свойством тела отношения и определяется текущим состоянием отношения в произвольно взятый момент.
Таким образом, реляционная база данных – это набор нормализованных отношений.
Реляционная база данных состоит из отношений, структура которых определяется с помощью особых методов, называемых нормализацией (normalization).
Свойства отношений
Отношение обладает следующими характеристиками:
отношение имеет имя, которое отличается от имен всех других отношений;
каждая ячейка отношения содержит только атомарное (неделимое) значение;
каждый атрибут имеет уникальное имя;
значения атрибута берутся из одного и того же домена;
порядок следования атрибутов не имеет никакого значения;
каждый кортеж является уникальным, т.е. дубликатов кортежей быть не может;
теоретически порядок следования кортежей в отношении не имеет никакого значения (однако, практически этот порядок может существенно повлиять на эффективность доступа к ним).
Отношение не может содержать кортежей-дубликатов, т.е. каждая строка должна быть обязательно уникальной.
Основные этапы, на которые разбивается процесс проектирования базы данных информационной системы:
1) Концептуальное проектирование - сбор, анализ и редактирование требований к данным. Для этого осуществляются следующие мероприятия:
обследование предметной области, изучение ее информационной структуры
выявление всех фрагментов, каждый из которых характеризуется пользовательским представлением, информационными объектами и связями между ними, процессами над информационными объектами
моделирование и интеграция всех представлений
По окончании данного этапа получаем концептуальную модель, инвариантную к структуре базы данных. Часто она представляется в виде модели "сущность-связь".
2) Логическое проектирование - преобразование требований к данным в структуры данных. На выходе получаем СУБД-ориентированную структуру базы данных и спецификации прикладных программ. На этом этапе часто моделируют базы данных применительно к различным СУБД и проводят сравнительный анализ моделей.
3) Физическое проектирование - определение особенностей хранения данных, методов доступа и т.д.
Различие уровней представления данных на каждом этапе проектирования представлено в следующей таблице:
КОНЦЕПТУАЛЬНЫЙ УРОВЕНЬ - сущности - атрибуты - связи |
Представление аналитика |
ЛОГИЧЕСКИЙ УРОВЕНЬ - записи - элементы данных - связи между записями |
Представление программиста |
ФИЗИЧЕСКИЙ УРОВЕНЬ - группирование данных - индексы - методы доступа |
Представление администратора |
Нормализация отношений при проектировании реляционной базы данных.
Нормализация отношений — это процесс построения оптимальной структуры таблиц и связей в реляционной БД. В процессе нормализации данные группируются в таблицы, представляющие объекты и их взаимосвязи.
База данных - это не просто хранилище фактов (с этой задачей способны справиться и незатейливые плоские файлы). При проектировании баз данных упор в первую очередь делается на достоверность и непротиворечивость хранимых данных, причем эти свойства не должны утрачиваться в процессе работы с данными, т.е. после многочисленных изменений, удалений и дополнений данных по отношению к первоначальному состоянию БД.
Для поддержания БД в устойчивом состоянии используется ряд механизмов, которые получили обобщенное название средств поддержки целостности. Эти механизмы применяются как статически (на этапе проектирования БД), так и динамически (в процессе работы с БД).
Обратим внимание на те ограничения, которым должна удовлетворять БД в процессе создания, независимо от ее наполнения данными. Приведение структуры БД в соответствие этим ограничениям - это и есть нормализация.
В целом суть этих ограничений весьма проста: каждый факт, хранимый в БД, должен храниться один-единственный раз, поскольку дублирование может привести (и на практике непременно приводит, как только проект приобретает реальную сложность) к несогласованности между копиями одной и той же информации. Следует избегать любых неоднозначностей, а также избыточности хранимой информации.
В процессе нормализации постоянно встречается ситуация, когда отношение приходится разложить на несколько других отношений. Поэтому более корректно было бы говорить о нормализации не отдельных отношений, а всей их совокупности в БД.
Итак, что же представляет собой процесс нормализации? Фактически это не что иное, как последовательное преобразование исходной БД к НФ, при этом каждая следующая НФ обязательно включает в себя предыдущую (что, собственно, и позволяет разбить процесс на этапы и производить его однократно, не возвращаясь к предыдущим этапам).
Всего в реляционной теории насчитывается 6 НФ:
1-я НФ (обычно обозначается также 1НФ).
2НФ.
3НФ.
НФ Бойса-Кодда (НФБК).
4НФ.
5НФ.
На практике, как правило, ограничиваются 3НФ, ее оказывается вполне достаточно для создания надежной схемы БД.
Для таблицы будут выполнены условия первой нормальной формы, если:
каждое поле (концептуальное требование) неделимо;
отсутствуют повторяющиеся поля или группы полей.
Если перечисленные выше условия выполняются, то все концептуальные требования могут быть сведены либо в одну общую таблицу, либо можно создать по одной таблице для каждого структурного подразделения.
Условия второй нормальной формы:
выполняются условия первой нормальной формы;
первичный ключ однозначно определяет всю запись;
все поля зависят от первичного ключа;
первичный ключ не должен быть избыточным.
Сохраняя первичные и альтернативные ключи, назначенные на третьем этапе, назначаем, при необходимости, дополнительные первичные и внешние ключи, в результате чего выделяем из таблицы структурного подразделения одну или несколько таблиц. Таким образом, данные для одного структурного подразделения могут быть представлены как одной таблицей, так и несколькими таблицами. Переход между таблицами разных структурных подразделений осуществляется по первичным ключам, назначенным на третьем этапе, а переход между таблицами внутри одного структурного подразделения осуществляется по первичным ключам, назначенным при выполнении второй нормальной формы.
Условия третьей нормальной формы:
выполняются условия второй нормальной формы;
каждое не ключевое поле не должно зависеть от другого не ключевого
поля.
При выполнении третьей нормальной формы должны быть разрушены транзитивные связи внутри каждой таблицы. При этом одно (или несколько) зависимых не ключевых полей выделяются в новую таблицу с обязательным добавлением первичных ключей для связи вновь выделенной таблицы с другими таблицами.
Архитектура баз данных. Формирование внешнего уровня, разработка концептуального уровня, проектирование внутреннего уровня.
Основной целью любой СУБД является возможность предложить обычному пользователю базы данных абстрактное представление данных, скрыв от пользователя особенности хранения и управления ими. Поскольку база данных, как правило, разрабатывается как общий ресурс для большого количества пользователей, то каждому пользователю может потребоваться своё, отличное от других пользователей представление о данных, хранимых в БД. Это вызвано следующими причинами:
— каждый пользователь должен иметь право обращаться к общим данным, используя своё представление о них;
— взаимодействие пользователя с БД не должно зависеть от особенностей её физической организации;
— администратор базы данных (АБД) должен иметь возможность изменять структуру и формат данных, не оказывая влияния на пользовательские представления;
— внутренняя структура БД не должна зависеть от переключения на новое устройство хранения;
— АБД должен иметь возможность изменять концептуальную структуру данных без какого—либо влияния на всех пользователей.
Для удовлетворения этих потребностей архитектура большинства современных коммерческих СУБД, существующих на рынке программного обеспечения, в той или иной мере, строится на базе так называемой архитектуры ANSI—SPARC. Название произошло по названию комитета планирования стандартов и норм (Standards Planning and Requirements Committee, SPARC) национального института стандартизации (American National Standard Institute, ANSI) США. Комитет признал необходимость использования трехуровневого подхода к организации БД, отделяющего пользовательские представления базы данных от её физического представления посредством создания независимого уровня.
Архитектура БД представлена на рисунке 1. Внешний уровень – это совокупность индивидуальных представлений БД с точки зрения отдельных пользователей. Пользователи могут быть разные, с разным уровнем подготовки. Каждый пользователь представляет данные в соответствии с формами различных документов, присущих данной предметной области. При этом одни и те же данные могут иметь различную форму представления — тип, длину. Например, сведения о зарплате – их можно увидеть в виде итоговой суммы в записи ведомости, либо в виде перечня составляющих – различных начислений и удержаний.

ПП1 – представление 1—го пользователя, ППк – представление к—того пользователя
Рисунок 1 — Трехуровневая архитектура БД
Некоторые представления могут включать производные или вычисляемые данные, которые не хранятся в БД, а создаются по мере необходимости. Индивидуальное внешнее представление называют подсхемой.
Концептуальный уровень отображает обобщенное представление пользователей. Это промежуточный уровень в трехуровневой архитектуре БД, представляющий данные такими, какими они есть на самом деле, а не такими, какими их вынужден видеть пользователь в рамках какого—то инструментального средства или приложения. Концептуальный уровень поддерживает каждое внешнее представление, однако, не содержит сведений о методах хранения данных. Этот уровень интересен администратору БД и может быть представлен концептуальными схемами.
Внутренний уровень на языке определения данных выбранной СУБД представляет, в каком виде информация хранится в БД, описывает структуры объектов БД. Внутреннее представление не связано с физическим уровнем, так как в нем не рассматривается организация физических записей (блоков и страниц памяти), физической области хранения данных.
Описание уровней архитектуры БД можно представить в виде некоторого технического описания (в бумажном или электронном виде), разработанного с помощью различных средств и правил.
В соответствии с архитектурой БД, существуют несколько внешних схем или подсхем, каждая из которых соответствует разным представлениям данных, одна концептуальная схема БД и одна внутренняя схема БД. Каждая внешняя схема связана с концептуальной с помощью внешне концептуального отображения. Концептуальная схема связана с внутренней посредством концептуально внутреннего отображения. Схемы и отображения создаются администратором БД средствами СУБД.
Рассмотрим представление различных уровней архитектуры базы данных на примере БД, созданной для решения задачи автоматизации управлением персоналом некоторой фирмы.
Внешний уровень представляется внешней схемой, содержащей несколько подсхем, отображающих внешние представления различных пользователей БД. Во—первых, это представление сотрудника фирмы, выполняющего обязанности кадрового учета. Его функциями являются учет личных данных сотрудников, сведений о приеме их на работу, всех перемещений и увольнений. Сотрудник—кадровик представляет данные в таком виде: каждому сотруднику присваивается табельный номер, это 5—значное целое число. Личные данные сотрудника вводятся в базу данных из следующих документов: паспорта, диплома об образовании, договора о найме на работу. Сотрудник—кадровик создает личную карточку сотрудника, в которую, кроме личных данных, вводит сведения о том в какое подразделение и на какую должность принимается сотрудник. Эти данные он берет из приказов о приемах, переводах, увольнениях и отпусках. Сотрудник—кадровик также периодически формирует различные отчеты по качественному составу персонала для руководителя фирмы: список сотрудников, достигших пенсионного возраста на заданную дату, список сотрудников, имеющих более 2—х несовершеннолетних детей, список сотрудников, не имеющих высшего образования и тому подобное. Второе внешнее представление – это представление сотрудника, выполняющего функции начисления заработной платы. Он ведет учет количества отработанных дней каждого сотрудника, сведения о полагающихся сотруднику надбавках, ежемесячно осуществляет расчет заработной платы, формирует ряд отчетов, как для руководителей фирмы, так и для внешних организаций – налоговой инспекции, пенсионного фонда. Третий пользователь базы данных это руководитель фирмы, который может просматривать личные данные сотрудников, сведения о выплатах по зарплате. Четвертый внешний пользователь — это пользователь сети Интернет, который на сайте фирмы может получить следующие сведения о сотрудниках фирмы – фотографии, фамилии, имена и отчества, названия подразделений, должности, ученые звания, степени и другую общедоступную информацию. Таким образом, можно представить, что каждый пользователь видит «свой» фрагмент данных, при этом данные могут иметь разное представление по длине, по виду отображения. Описание всех представлений пользователей дает общее описание внешнего уровня БД. Оно обычно представляется в виде технической документации (технического задания), описаний входных и выходных документов, в виде схем, рисунков, словесного описания.
Концептуальный уровень базы данных рассматриваемого примера может быть отображен в виде 2—х схем, получаемых последовательно. Первая схема — концептуальная информационно—логическая модель предметной области (ИЛМ), представляющая классы объектов (сущности) предметной области и связи между ними. Вторая схема — концептуальная даталогическая модель базы данных (ДЛМ), отображающая описание предметной области в виде логической структуры данных в терминах выбранной модели данных. Каждая из этих схем обобщает представление всех пользователей базы данных и описывает все данные, которые должны храниться в БД, какие связи между ними существуют. Схемы могут быть отображены на бумаге, либо в электронном формате и являются проектной документацией. Формируют концептуальный уровень проектировщики базы данных, администратор данных и администратор базы данных. Это особая категория пользователей базы данных — её разработчики. Представление концептуального уровня БД в виде ИЛМ и ДЛМ, либо только в виде ДЛМ, зависит от выбранного метода проектирования БД.
Внутренний уровень рассматриваемой БД может быть представлен в виде SQL—скриптов объектов БД, если для реализации БД выбрана СУБД, поддерживающая стандарт языка SQL, либо в виде описания, содержащего конструкции языка определения данных выбранной СУБД.
Основным назначением трехуровневой архитектуры БД является обеспечение независимости описаний базы данных (схем БД), получаемых на различных уровнях архитектуры БД, друг от друга, что обеспечивает независимость прикладных программ от данных и является одним из основных достоинств базы данных.
Различают логическую и физическую независимость данных. Логическая независимость данных поддерживает защищенность внешних схем от изменений, вносимых на концептуальном уровне. Так, например, при функциональном развитии АИС проводится дообследование предметной области и в концептуальную схему добавляется описание новых данных. При этом некоторые внешние схемы даже не замечают этих изменений, часть пользователей работает с БД в прежнем виде. Физическая независимость поддерживает защищенность концептуальной схемы от изменений, вносимых на физическом уровне. Например, добавление индексов, создание триггеров не требуют внесения изменений в концептуальную схему. Также, возможен перевод физической модели БД на ЯОД другой СУБД без внесения изменений во внешние схемы. Пользователь сможет заметить только увеличение или уменьшение производительности системы.
Для того чтобы создать БД необходимо предварительно осуществить последовательное проектирование схем каждого уровня архитектуры БД.
Методология проектирования баз данных. Методы восходящего и нисходящего проектирования.
Целью проектирования БД является адекватное отображение в базе данных сути предметной области, рассматриваемой с точки зрения решения задачи автоматизации.
В теории баз данных существует ряд методов разработки моделей БД, отображающих разные уровни её архитектуры. Распространены два основных подхода к проектированию систем баз данных: "нисходящий" и "восходящий":
При «восходящем» подходе осуществляют структурное проектирование снизу—вверх. Этот процесс называют синтезом, попыткой получения целого (адекватно отображающего описание предметной области) на основе описания составляющих его частей.
Этапы проектирования БД методом «восходящего» проектирования представлены на рисунке 2.

Пр Обл – предметная область; ДЛМ – даталогическая модель; НФ – нормальная форма; ИЛМ – информационно—логическая модель; ФМ – физическая модель.
Рисунок 1 — Этапы проектирования БД методом «восходящего» проектирования
Работа над проектом БД начинается с определения свойств объектов (атрибутов сущностей) предметной области, которые на основе анализа существующих между ними связей группируются в реляционные отношения (таблицы), отображающие эти объекты (в том случае, если мы проектируем структуру реляционной БД). Как правило, получают два — три, связанных между собой, реляционных отношения. Для того чтобы полученная структура БД (ДЛМ) не обладала различными аномалиями при добавлении, обновлении или удалении данных вследствие их избыточности, необходимо осуществить проверку каждой полученной схемы отношения, как минимум, на соответствие 3НФ. Если схемы отношений не соответствуют этому условию, а они, скорее всего, не будут соответствовать, необходимо проводить процесс нормализации схем отношений.
Для успешного проведения нормализации необходимо на основе анализа предметной области (анализа документов предметной области) для каждой схемы реляционного отношения:
— выявить потенциальные ключи;
— увидеть повторяющиеся группы и не атомарные атрибуты;
— привести схемы отношения к 1НФ;
— определить функциональные зависимости между не ключевыми атрибутами и первичным ключом;
— определить частичные функциональные зависимости;
— осуществить декомпозицию (деление) соответствующих схем отношений для удалений частичных функциональных зависимостей;
— увидеть транзитивные зависимости между не ключевыми атрибутами и первичным ключом;
— исключить транзитивные зависимости путем декомпозиции соответствующих схем отношений.
Эти виды работ являются достаточно трудоемкими, и их успех будет определяться хорошим знанием предметной области, теории множеств и предикатной логики. Значительный объем мероприятий по нормализации схем реляционных отношений даже дал второе название методу «восходящего» проектирования. Этот метод часто называют методом «нормализации».
«Восходящее» проектирование – это достаточно сложная и устаревшая методика, которая подходит для проектирования только небольших баз данных.
При «нисходящем» проектировании осуществляется структурное проектирование сверху—вниз. Такой процесс называют анализом – происходит изучение целого (описания предметной области), затем разделение целого на составные части и далее следует последовательное изучение этих частей.
Этапы проектирования БД методом «нисходящего» проектирования представлены на рисунке 3. Для отображения метода использованы следующие обозначения: в кругах описаны названия этапов проектирования, в прямоугольниках – результаты. Проектирование начинается с анализа предметной области и формирования описания внешнего уровня БД, объединяющего представления всех пользователей разрабатываемой БД, выявления классов объектов (сущностей) предметной области, связей между ними (определения, описания предметной области). На основе описания внешнего уровня БД строится концептуальная информационно—логическая модель предметной области (ИЛМ), затем на её основе получают даталогическую модель (ДЛМ) базы данных. ДЛМ является основой для следующего этапа проектирования БД – этапа формирования физической модели базы данных.
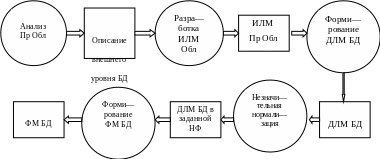
Пр Обл – предметная область; ИЛМ – информационно—логическая модель предметной области; ДЛМ – даталогическая модель; НФ – нормальная форма; ФМ – физическая модель.
Рисунок 2 — Этапы проектирования БД методом «нисходящего» проектирования
Метод «нисходящего» проектирования достаточно формализован и используется в CASE (Computer Aided System /Software Engineering — компьютерное проектирование программного обеспечения и систем) средствах. Проведение тщательного анализа предметной области, выявление всех присущих ей классов объектов и связей между ними, правильное их отображение в ИЛМ предметной области, ведет к получению высоко нормализованной схемы логической структуры реляционной БД.
Для того чтобы сравнить эти два метода, используемых для проектирования реляционных баз данных, необходимо понимать, что при использовании «восходящего» метода проектирования сразу формируется схема БД. Термины реляционной модели (схемы отношений) не предусматривают возможность описания полного смысла (семантики) предметной области. Неправильное отображение в даталогической модели БД сути предметной области приводит к ошибкам в последующей работе АИС. Установлено, что цена ошибки (стоимость исправления) быстро возрастает с увеличением интервала времени (технологического времени: числа выполненных операций между двумя событиями) между появлением погрешности и её обнаружением. В литературе по базам данных приводятся такие цифры: на интервале от выработки требований на программу до сдачи программного продукта заказчику стоимость расходов на исправление ошибки возрастает в среднем в 80 раз. Большая цена ошибки определяет необходимость тщательной проработки проекта.
Также необходимо отметить, что ручное проектирование, каким является метод «восходящего» проектирования или метод «нормализации», является достаточно трудоемким.
Более удобный, приятный и современный метод проектирования БД – это «нисходящий» метод. Его часто называют методом концептуального проектирования БД. Такое проектирование, прежде всего, связано с попыткой более полного представления семантики предметной области в модели БД. Это стало возможным с появлением семантических моделей данных, которые позволяют описать конкретную предметную область достаточно формальным, но в тоже время понятным и разработчику и заказчику образом, что дает возможность отображения в модели общего понимания сути предметной области.
Помимо этих подходов, для проектирования БД могут применяться другие методы. Например, известен метод "изнутри наружу". Он похож на метод «восходящего» проектирования, но отличается от него начальной идентификацией набора основных классов объектов с последующим расширением круга рассматриваемых классов объектов, связей и свойств, которые взаимодействуют с первоначально определенными классами объектов. Известен также подход "смешанной стратегии" — сначала «восходящий» и «нисходящий» методы используются для разных частей модели, после чего все подготовленные фрагменты собираются в единое целое.
Признаки эффективности структуры баз данных. Понятие целостности. Критерии целостности.
Эффективность структуры БД
При проектировании БД необходимо создать наиболее эффективную структуру данных. Признаками эффективности структуры БД считаются:
1. Обеспечение быстрого доступа к данным в таблицах.
2. Исключение ненужного повторения данных, которое может явиться причиной ошибок при вводе и нерационального использования дискового пространства компьютера.
3. Обеспечение целостности данных таким образом, чтобы при изменении одних объектов автоматически происходило соответствующее изменение других, связанных с ними объектов.
В СУБД процесс создания реляционной базы данных включает создание схемы данных. Схема данных наглядно отображает таблицы и связи между ними и обеспечивает использование связей при обработке данных. В схеме данных устанавливаются параметры обеспечения связной целостности в базе данных.
Чтобы информация, хранящаяся в базе данных, была однозначной и непротиворечивой, в реляционной модели устанавливаются некоторые ограничительные условия. Ограничительные условия - это правила, определяющие возможные значения данных. Они обеспечивают логическую основу для поддержания корректных значений данных в базе. Такие ограничения целостности позволяют свести к минимуму ошибки, возникающие при обновлении и обработке данных.
Важнейшими ограничениями целостности данных являются:
категорийная целостность
ссылочная целостность.
Ограничение категорийной целостности заключается в следующем.
Ни одна строка не может быть занесена в базу данных до тех пор, пока не будут определены все атрибуты ее первичного ключа. Это правило называется правилом категорийной целостности и кратко формулируется следующим образом: никакой атрибут первичного ключа строки не может быть пустым.
Ссылочная целостность:
Если две таблицы связаны между собой, то внешний ключ таблицы должен содержать только значения, уже имеющиеся среди значений ключа, по которому осуществляется связь. Если корректность значений внешних ключей не контролируется СУБД, то может нарушиться ссылочная целостность данных. Например: пусть имеются две связанные таблицы СТУДЕНТ и УСПЕВАЕМОСТЬ, которые связаны по полю номер студента. Если удалить из таблицы СТУДЕНТ строку (например, при отчислении студента), имеющую хотя бы одну связанную-с ней строку в таблице УСПЕВАЕМОСТЬ, то это приведет к тому, что в таблице УСПЕВАЕМОСТЬ останутся записи об успеваемости студента, который уже отчислен. Целостность данных будет нарушена и в случае ошибочного ввода в поле внешнего ключа НС (номер студента) подчиненной таблицы УСПЕВАЕМОСТЬ сведений о студенте, запись о котором отсутствует в главной таблице СТУДЕНТ.
Ограничения категорийной и ссылочной целостности должны поддерживаться СУБД . Для соблюдения целостности таблицы достаточно гарантировать отсутствие в любой таблице полей с одним и тем же значением первичного ключа.
Обеспечить ссылочную целостность БД несколько сложнее. При обновлении ссылающегося отношения (при вводе новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. А вот при удалении кортежа из отношения, на которое имеется ссылка, можно использовать один из трех подходов, обеспечивающих ссылочную целостность:
запрещается производить удаление кортежа, на который существуют ссылки, нужно сначала либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа;
при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа должно автоматически становиться неопределенным;
при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения должны автоматически удаляться все ссылающиеся кортежи (это называется каскадным удалением).
В реляционных СУБД обычно можно выбрать способ поддержания ссылочной целостности для каждой отдельной ситуации определения внешнего ключа, но для принятия такого решения необходимо анализировать требования конкретной прикладной области.
Критерии целостности:
Каждой записи основной (главной, родительской) таблицы соответствует нуль или более записей дополнительной (подчинённой, дочерней) таблицы.
В дополнительной таблице нет записей, которые не имеют родительских записей в основной таблице.
Каждая запись дополнительной таблицы имеет только одну родительскую запись основной таблицы.
Транзакция. Свойства транзакций. Способы завершения транзакций.
Механизм транзакций используется в СУБД для поддержания целостности в БД
Транзакцией называют неделимую с позиции воздействия на БД последовательность операций манипулирования данными. Транзакция может состоять из операций чтения, удаления, вставки, модификации данных. Транзакция обладает четырьмя основными свойствами:
Атомарности
Согласованности
Изолированности (сериализуемости)
Долговечности
Атомарность
Свойство атомарности означает, что транзакция должна выполняться как единая операция доступа к БД. Она должна быть выполнена полностью либо не выполнена совсем. Т.е. должны быть выполнены все операции манипулирования данными, которые входят в транзакцию, либо, если по каким-то причинам выполнение части операций невозможно, ни одна из операций не должна выполняться.
Согласованность
Свойство согласованности гарантирует взаимную целостность данных, т.е. выполнение ограничений целостности БД после окончания обработки транзакции. Следует отметить, что база данных может обладать такими ограничениями целостности, которые сложно не нарушить, выполняя только один оператор ее изменения.
Примеры ограничений целостности:
1. Возраст сотрудника не может быть < 18 и > 65 лет.
2. Каждый сотрудник имеет уникальный табельный номер.
3. Сотрудник обязан числиться в одном отделе
Изолированность
Современные СУБД являются многопользовательскими системами, т.е. допускают параллельную одновременную работу большого количества пользователей.
Транзакция разных пользователей не должны мешать друг другу, т.е. транзакции выполняются независимо друг от друга. Транзакции необходимо выполнить одновременно, но так, чтобы результат был бы такой же, как если бы транзакции выполнялись по очереди.
Принципы совместной обработки (сериализации) транзакций:
Транзакция не может получить доступ к незафиксированным данным, т.е. к данным, в которых произведены изменения, но эти изменения еще не зафиксированы.
Результат совместного выполнения транзакций должен быть эквивалентен результат)' их последовательного выполнения. Т.е., если две транзакции выполняются параллельно, то полагается, что результат будет такой же, как если бы сначала выполнялась первая, а затем вторая транзакция, или сначала вторая, а потом первая.
В современных СУБД сериализация транзакций реализуется через механизм блокировок. На время выполнения транзакции СУБД блокирует часть БД (отношение, строку или группу строк), к которой транзакция обращается. Блокировка сохраняется до момента фиксации транзакции
При выполнении транзакции современные СУБД могут блокировать всю БД, отношение, группу строк или отдельную строку.
Чем больше блокируемый элемент данных, тем медленнее СУБД обрабатывает транзакции — велико время ожидания снятия блокировок.
При работе в режиме оперативного доступа к БД, как правило, реализуется блокировка на уровне отдельных строк. В этом случае можно добиться максимальной производительности за счет того, что блокируемый объект — минимальная структурная единица БД.
Транзакции могут попасть в ситуацию взаимоблокировки
Для предотвращения взаимоблокировки СУБД периодически проверяет блокировки, установленные выполняющимися транзакциями. Если обнаруживается ситуация взаимоблокировки, то одна из транзакций, вызвавших эту ситуацию, прерывается. Это разрешает тупиковые ситуации. Программа, которая сгенерировала прерванную транзакцию, получает сообщение об ошибке.
Долговечность
Если транзакция выполнена, то результаты ее должны сохраняться в системе, даже если в следующий момент произойдет сбой системы.
Казалось бы, самый простой способ обеспечить такую гарантию - это во время каждой операции сразу записывать все изменения на дисковые носители.
Такой способ не является удовлетворительным, т.к. имеется существенное различие в скорости работы с оперативной и с внешней памятью. Единственный способ достичь приемлемой скорости работы состоит в буферизации страниц БД в оперативной памяти. Это означает, что данные попадают во внешнюю долговременную память не сразу после внесения изменений, а через некоторое (достаточно большое) время.
Возможны два варианта завершения транзакции. Если все операторы выполнены успешно и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется.
Фиксация транзакции — это действие, обеспечивающее запись в БД всех изменений, которые были произведены в процессе ее выполнения. До того как транзакция зафиксирована, возможна отмена всех сделанных изменений и возврат БД в то состояние, в котором она была до начала выполнения транзакции.
Если нормальное завершение транзакции невозможно, напр., нарушены ограничения целостности БД, или пользователь выдал специальную команду, происходит откат транзакции. БД возвращается в исходное состояние, все изменения аннулируются. Механизм корректного отката и фиксации транзакций основан на использовании журнала транзакций.
Если транзакция работает с БД, расположенной на одном узле, то ее называют локальной. Таким образом, логически распределенная транзакция состоит из нескольких локальных.
Локальные и глобальные транзакции
С точки зрения пользователя, локальные и глобальные транзакции обрабатываются одинаково, т.е. СУБД должна организовать процесс выполнения распределенной транзакции так, чтобы все локальные транзакции, входящие в нее, синхронно фиксировались на затрагиваемых ими узлах распределенной системы.
Однако распределенная транзакция должна фиксироваться только в случае, когда зафиксированы все локальные транзакции, ее составляющие. Если прерывается хотя бы одна из локальных транзакций, должна быть прервана и распределенная транзакция.
Системы управления базами данных. Классификация, функциональность СУБД.
Системой управления БД называет программную систему предназначенной для создания на ЭВМ общей БД, используемой для решения множества задач.
Подобные системы служат для поддержания баз данных в актуальном состоянии и обеспечивают эффективный доступ пользователей к содержащимся в ней данным в рамках предоставленных пользователем полномочий. СУБД предназначена для централизованного управления базой данных в интересах всех работающих в этой системе.
По степени универсальности различают две степени СУБД:
системы общего назначения;
специализированные системы.
СУБД общего назначения не ориентированные на какую-либо предметную область или на информационную потребности какой-либо группы пользователей. СУБД общего назначения это сложные программные комплексы предназначены для выполнения всей совокупности функций, связанных с созданием и эксплуатацией БД.
Специализированные СУБД создаются редких случаях при невозможности или нецелесообразности использования СУБД общего назначения.
Основными характеристиками СУБД являются:
Производительность;
Обеспечение целостности данных на уровне БД;
Обеспечение безопасности;
Работа в многопользовательских средах;
Импорт, экспорт;
Доступ к данным посредством языка SQL;
Возможности запросов и инструментальные средства разработки прикладных программ.
Производительность СУБД оценивается:
временем выполнения запроса;
скоростью поиска информации в неиндексированных полях;
временем выполнения операций импортирования базы данных из других форматов;
скоростью создания индексов и выполнения таких массовых операций как обновление, вставка, удаление данных;
максимальным числом параллельных обращений к данным в многопользовательском режиме;
временем генерации отчетов.
На производительность СУБД оказывают влияние два фактора:
СУБД, которые следят за соблюдением целостности данных, несут дополнительную нагрузку, которую не испытывают другие программы;
производительность приложений сильно зависит от правильного проектирования и построения базы данных.
Обеспечение целостности подразумевает наличие средств позволяющих удостовериться, что информация в БД всегда остается корректной и полной. Должны быть установлены правила целостности, и они должны храниться вместе с базой данных и соблюдаться на глобальном уровне. Целостность данных должна обеспечивать независимо от того, каким образом данные заполняются в память. К средствам обеспечения целостности данных на уровне СУБД относятся:
встроенные средства для назначения первичного ключа, в том чис-
ле средства для работы с типом полей с автоматическими приращением, когда СУБД самостоятельно присваивает новые уникальные значения;
средства поддержания ссылочной целостности, которые обеспечи-
вают запись информации о связях таблиц и автоматически пресекают любую операцию приводящую к нарушению ссылочной целостности.
Некоторые СУБД предусматривают средства обеспечения безопасности данных.
Такие средства обеспечивают выполнение следующих операций:
шифрование прикладных программ;
шифрование данных;
защиту паролем;
ограничение уровня доступа.
Практически все рассматриваемые СУБД предназначены для работы в многопользовательских средах, но обладают для этого различными возможностями. Обработка данных в многопользовательских средах предполагает выполнение программным продуктом следующих функций:
блокировку БД, файла, записи, поля;
идентификацию станции, установившей блокировку;
обновление информации после модификации;
контроль за временем и повторение обращений;
обработка транзакций;
работу с сетевыми системами.
Импорт, экспорт отражает:
возможность обработки СУБД информации, подготовленной
другими программными средствами;
возможность использования другими программами данных
сформулированные средствами рассматриваемые СУБД.
Доступ к данным посредством языка SQL
Язык запросов SQL реализован в целом ряде популярных СУБД для различных типов ЭВМ типа как базовой, либо как альтернативной. В силу своего широкого использования является международным стандартом языка запроса. Язык SQL предоставляет развитые возможности как конечным пользователям, так и специалистам в области обработки данных.
СУБД имеет доступ к данным SQL в следующих случаях:
БД совместима с ОDВС (Open Database Connectivity – открытое
соединение БД);
реализована естественной поддержкой SQL-баз данных;
возможна реализация SQL запросов локальных данных.
Многие СУБД могут «прозрачно» подключаться к входным SQL-подсистемам с помощью ODBC или драйверов, являющихся их частью, поэтому существует возможность создания прикладных программ для них. Некоторые программные продукты совместимы также с SQL при обработке интерактивных запросов на получение данных, находящихся на сервере или на рабочем месте.
Можно напрямую управлять базами данных Access с помощью языка SQL и передавать сквозные SQL-запросы совместимым со спецификацией ODBC SQL-базам данных, таким, как MS SQL Server и Oracle, так что Access способна служить средством разработки масштабируемых систем клиент-сервер.
Возможности запросов и инструментальные средства разработки прикладных программ.
СУБД, ориентированные на разработчика обладает развитыми средствами для создания приложения. К элементам инструментария разработки приложения можно отнести:
мощные языки программирования;
средства реализации меню, экранных форм, ввода вывода данных
и генерации отчетов;
средства генерации приложений (прикладных программ);
генерацию исполнимых файлов;
Функциональные возможности модели данных доступны пользователям СУБД, благодаря ее языковым средствам.
Языковые средства используются для выполнения двух основных функций:
описание представления базы данных;
выполнение операций манипулирования данными.
Первая из этих функций используется языком описания данных (ЯОД). Описание БД средствами языка описание данных называется схемой базы данных. Оно включает описание структуры БД и налагаемых на нее ограничений целостности в рамках тех правил, которые регламентированы моделью данных используемой СУБД. ЯОД не всегда синтаксически оформляется в виде самостоятельного языка. Он может быть составной частью единого языка данных, сочетающего возможности определения данных и манипулирования данными.
Язык манипулирования данными (ЯМД) позволяет запрашивать предусмотренные в системе операции над данными из базы данных.
Классификация СУБД
Иерархические СУБД - поддерживают древовидную организацию информации. Связи между записями выражаются в виде отношений предок/потомок, а у каждой записи есть ровно одна родительская запись. Это помогает поддерживать ссылочную целостность. Когда запись удаляется из дерева, все ее потомки также должны быть удалены.
Иерархические базы данных имеют централизованную структуру, т.е. безопасность данных легко контролировать.
В иерархической БД следует правильно упорядочивать записи, чтобы время их поиска было минимальным. Это трудно, так как не все отношения, существующие в реальном мире, можно выразить в иерархической базе данных. Отношения "один ко многим" являются естественными, но практически невозможно описать отношения "многие ко многим" или ситуации, когда запись имеет несколько предков.
Сетевые СУБД - Сетевая модель расширяет иерархическую модель СУБД, позволяя группировать связи между записями в множества. С логической точки зрения связь — это не сама запись. Связи лишь выражают отношения между записями. Как и в иерархической модели, связи ведут от родительской записи к дочерней, но на этот раз поддерживается множественное наследование.
В сетевой модели допускаются отношения "многие ко многим", а записи не зависят друг от друга. При удалении записи удаляются и все ее связи, но не сами связанные записи.
В сетевой модели требуется, чтобы связи устанавливались между существующими записями во избежание дублирования и искажения целостности. Данные можно изолировать в соответствующих таблицах и связать с записями в других таблицах.
Реляционные СУБД. В реляционной модели база данных представляет собой централизованное хранилище таблиц, обеспечивающее безопасный одновременный доступ к информации со стороны многих пользователей. В строках таблиц часть полей содержит данные, относящиеся непосредственно к записи, а часть — ссылки на записи других таблиц. Таким образом, связи между записями являются неотъемлемым свойством реляционной модели.
Каждая запись таблицы имеет одинаковую структуру. Например, в таблице, содержащей описания автомобилей, у всех записей будет один и тот же набор полей: производитель, модель, год выпуска, пробег и т.д. Такие таблицы легко изображать в графическом виде.
В реляционной модели СУБД достигается информационная и структурная независимость. Записи не связаны между собой настолько, чтобы изменение одной из них затронуло остальные, а измененная структура СУБД, базы данных не обязательно приводит к перекомпиляции работающих с ней приложений. В реляционных СУБД применяется язык SQL, позволяющий формулировать произвольные, нерегламентированные запросы. Это язык четвертого поколения, поэтому любой пользователь может быстро научиться составлять запросы. К тому же, существует множество приложений, позволяющих строить логические схемы запросов в графическом виде.
Объектно-ориентированные СУБД - позволяет программистам, которые работают с языками третьего поколения, интерпретировать все свои информационные сущности как объекты, хранящиеся в оперативной памяти. Дополнительный интерфейсный уровень абстракции обеспечивает перехват запросов, обращающихся к тем частям базы данных, которые находятся в постоянном хранилище на диске. Изменения, вносимые в объекты, оптимальным образом переносятся из памяти на диск.
Преимуществом ООСУБД является упрощенный код. Приложения получают возможность интерпретировать данные в контексте того языка программирования, на котором они написаны. Реляционная база данных возвращает значения всех полей в текстовом виде, а затем они приводятся к локальным типам данных. В ООБД этот этап ликвидирован. Методы манипулирования данными всегда остаются одинаковыми независимо от того, находятся данные на диске или в памяти.
Данные в ООСУБД способны принять вид любой структуры, которую можно выразить на используемом языке программирования. Отношения между сущностями также могут быть произвольно сложными.
С помощью ООСУБД решаются две проблемы. Во-первых, сложные информационные структуры выражаются в них лучше, чем в реляционных базах данных, а во вторых, устраняется необходимость транслировать данные из того формата, который поддерживается в СУБД. Например, в реляционной СУБД размерность целых чисел может составлять 11 цифр, а в используемом языке программирования — 16. Программисту придется учитывать эту ситуацию.
Большим недостатком объектно-ориентированных баз данных является их тесная связь с применяемым языком программирования. К данным, хранящимся в реляционной СУБД, могут обращаться любые приложения, тогда как, к примеру, Java-объект, помещенный в ООСУБД, будет представлять интерес лишь для приложений, написанных на Java.
Объектно-реляционные СУБД объединяют в себе черты реляционной и объектной моделей. Их возникновение объясняется тем, что реляционные базы данных хорошо работают со встроенными типами данных и гораздо хуже — с пользовательскими, нестандартными. Когда появляется новый важный тип данных, приходится либо включать его поддержку в СУБД, либо заставлять программиста самостоятельно управлять данными в приложении.
Не всякую информацию имеет смысл интерпретировать в виде цепочек символов или цифр. Представим себе музыкальную базу данных. Песню, закодированную в виде аудиофайла, можно поместить в текстовое поле большого размера, но как в таком случае будет осуществляться текстовый поиск?
Перестройка архитектуры СУБД с целью включения в нее поддержки нового типа данных — не лучший выход из положения. Вместо этого объектно-реляционная СУБД позволяет загружать код, предназначенный для обработки "нетипичных" данных. Таким образом, база данных сохраняет свою табличную структуру, но способ обработки некоторых полей таблиц определяется извне, т.е. программистом.
По архитектуре СУБД и организации хранения данных делятся:
локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
По способу доступа СУБД к базе данных:
Файл-серверные СУБД. В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере СУБД. Ядро СУБД располагается на каждом клиентском компьютере. Доступ к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на ЦП сервера, а недостатком — высокая загрузка локальной сети.
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера СУБД (см. Клиент-сервер). Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и мало загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по надобности его можно заменить другим. Недостаток клиент-серверных СУБД в самом факте существования сервера СУБД (что плохо для локальных программ — в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером.
Встраиваемые СУБД. Встраиваемая СУБД — библиотека, которая позволяет унифицированным образом хранить большие объёмы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объёмами данных (например, геоинформационные системы).
Функциональность СУБД
СУБД выполняет несколько очень важных функций, обеспечивающих целостность и непротиворечивость данных, хранящихся в БД. Большинство этих функций для конечного пользователя незаметны, и основную их часть выполняет СУБД. Сюда включаются управление словарем данных, управление хранением данных, преобразование данных и их представление, обеспечение безопасности, обслуживание многопользовательского доступа, резервное копирование и восстановление, целостность данных, языки доступа к данным и интерфейсы прикладного программирования, а также интерфейсы взаимодействия с базой данных.
Управление словарем данных. Функционирование СУБД предусматривает, что определения элементов данных и их отношений (метаданные) хранятся в словаре данных (data dictionary). В свою очередь любые программы получают доступ к данным БД посредством СУБД. Для поиска необходимых структур данных и их отношений СУБД использует словарь данных, помогая избежать кодирования таких сложных взаимосвязей в каждой программе. Вдобавок любые изменения, которые делаются в структуре базы данных, автоматически регистрируются в словаре данных, что также освобождает нас от необходимости модифицировать программы доступа к изменившимся структурам данных. Другими словами, СУБД обеспечивает абстракцию данных, тем самым устраняя в системе структурную зависимость и зависимость по данным.
Управление хранением данных. СУБД создает сложные структуры, необходимые для хранения данных, опять-таки освобождая нас от трудной задачи определения и программирования физических свойств данных. Современные СУБД обеспечивают хранение не только данных, но и связанных с данными экранных форм, схем отчетов, правил проверки данных, кода процедур, систем обработки видео, форматы изображений и т. д.
Преобразование и представление данных. СУБД берет на себя задачу структурирования вводимых данных, преобразуя их в форму, удобную для хранения. Поэтому СУБД и здесь избавляет нас от рутинной работы преобразования логического формата данных в физический формат. Обеспечивая независимость данных, СУБД преобразует логические запросы в команды, обеспечивающие определение физического местоположения необходимой информации и ее извлечение, т. е. СУБД форматирует физически полученные данные для придания им удобочитаемой формы. Иными словами, СУБД обеспечивает программную независимость и абстракцию данных.
Управление безопасностью. СУБД создает систему безопасности, которая обеспечивает защиту пользователя и конфиденциальность данных внутри БД. Правила безопасности устанавливают, какие пользователи могут получить доступ к базе данных, к каким элементам данных пользователь может получить доступ, а также какие операции с данными (чтение, добавление, удаление или изменение) может выполнять пользователь. Это имеет особое значение в многопользовательских системах, где несколько пользователей могут одновременно получить доступ к данным.
Управление многопользовательским доступом. СУБД создает сложные структуры, обеспечивающие доступ к данным нескольким пользователям одновременно. Для того чтобы обеспечить целостность и непротиворечивость данных, в СУБД используются сложные алгоритмы, гарантирующие, что несколько пользователей могут получить одновременный доступ к базе данных без риска нарушить ее целостность.
Управление резервным копированием и восстановлением. В СУБД имеются процедуры резервного копирования и восстановления данных, обеспечивающие их безопасность и целостность. Современные СУБД содержат специальные утилиты, с помощью которых администраторы базы данных могут выполнять регулярные и экстренные процедуры резервного копирования и восстановления данных. Восстановление данных производится после повреждения БД, например, в случае появления сбойного сектора на жестком диске или после аварийного отключения питания. Такая возможность необходима для обеспечения целостности данных.
Управление целостностью данных. В СУБД предусмотрены правила, обеспечивающие целостность данных, что позволяет минимизировать избыточность данных и гарантировать их непротиворечивость. Для обеспечения целостности данных используются их связи, которые хранятся в словаре данных. Целостность данных имеет особенно большое значение в транзакционных БД.
Языки доступа к данным и интерфейсы прикладного программирования. СУБД обеспечивает доступ к данным с помощью языка запросов. Язык запросов это непроцедурный язык, т. е. он предоставляет пользователю возможность определять, что необходимо выполнить, без необходимости указывать, как это нужно выполнять. В состав языка запросов СУБД входят два основных компонента: язык определения данных (data definition language, DDL) и язык манипулирования данными (data manipulation language, DML). DDL определяет структуры, в которых размещаются данные, a DML позволяет конечным пользователям извлекать данные из БД. СУБД также предоставляет программистам доступ к данным из процедурных языков третьего поколения (3GL), таких как COBOL, С, PASCAL, Visual Bask и др. В составе СУБД имеются административные утилиты, предназначенные для администраторов базы данных (DBA) и проектировщиков БД, для внедрения, текущего контроля и обслуживания базы данных.
Интерфейсы взаимодействия с базой данных. Текущее поколение СУБД обеспечивает специальные программы взаимодействия, разработанные для того, чтобы БД могла принимать запросы конечных пользователей в сетевом окружении. Фактически возможности взаимодействия с базой данных являются неотъемлемой составляющей современных СУБД. Например, СУБД предоставляет функции взаимодействия для получения доступа к базе данных, используя в качестве внешнего интерфейса интернет-браузер (Internet Explorer). В подобной среде взаимодействие может осуществляться несколькими спосабами:
- конечный пользователь может получать ответ на запросы, заполняя экранные формы с помощю выбранного им браузера;
- с помощью СУБД можно автоматизировать публикацию форм отчетов в Интернете с помощью Web-форматирования, что позволяет просматривать их с помощью любого браузера;
- с помощью СУБД можно подключатся к независимым системам для распространения информации по электронной почте (e-mail) или с помощью других эффективных приложений, например, Louis Notes.
Технология хранилищ данных. Подготовка среды хранения. Методы проектирования хранилищ данных.
Хранилище данных (англ. Data Warehouse) — очень большая предметно-ориентированная информационная корпоративная база данных, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес-процессов с целью поддержки принятия решений в организации. Строится на базе клиент-серверной архитектуры, реляционной СУБД и утилит поддержки принятия решений. Данные, поступающие в хранилище данных, становятся доступны только для чтения.
Для того чтобы обеспечить возможность анализа накопленных данных, организации стали создавать хранилища данных, которые представляют собой интегрированные коллекции данных, которые собраны из различных систем оперативного доступа к данным. Хранилища данных становятся основой для построения систем принятия решений. Несмотря на различия в подходах и реализациях, всем хранилищам данных свойственны следующие общие черты:
Предметная ориентированность. Информация в хранилище данных организована в соответствии с основными аспектами деятельности предприятия (заказчики, продажи, склад и т.п.); это отличает хранилище данных от оперативной БД, где данные организованы в соответствии с процессами (выписка счетов, отгрузка товара и т.п.). Предметная организация данных в хранилище способствует как значительному упрощению анализа, так и повышению скорости выполнения аналитических запросов. Выражается она, в частности, в использовании иных, чем в оперативных системах, схемах организации данных. В случае хранения данных в реляционной СУБД применяется схема "звезды" (star) или "снежинки" (snowflake). Кроме того, данные могут храниться в специальной многомерной СУБД в n-мерных кубах.
Интегрированность. Исходные данные извлекаются из оперативных БД, проверяются, очищаются, приводятся к единому виду, в нужной степени агрегируются (то есть вычисляются суммарные показатели) и загружаются в хранилище. Такие интегрированные данные намного проще анализировать.
Привязка ко времени. Данные в хранилище всегда напрямую связаны с определенным периодом времени. Данные, выбранные их оперативных БД, накапливаются в хранилище в виде "исторических слоев", каждый из которых относится к конкретному периоду времени. Это позволяет анализировать тенденции в развитии бизнеса.
Неизменяемость. Попав в определенный "исторический слой" хранилища, данные уже никогда не будут изменены. Это также отличает хранилище от оперативной БД, в которой данные все время меняются, "дышат", и один и тот же запрос, выполненный дважды с интервалом в 10 минут, может дать разные результаты. Стабильность данных также облегчает их анализ.
Необходимыми системными ресурсами для работы БД являются четыре основных компонента аппаратного обеспечения, которые будут взаимодействовать между собой и влиять на уровень производительности.
1 Процессор. Выполняет пользовательские процессы, управляет задачами других системных ресурсов. У него должна быть высокая тактовая частота. Для организации сервера БД может быть использовано несколько процессоров одновременно.
2 Оперативная память. Чем больше её объем, тем быстрее работают приложения баз данных. Рекомендуют планировать объем, чтобы в процессе работы системы выполнялось условие: всегда есть в наличии свободными 5 процентов от всего объема памяти.
3 Внешняя память. Для определения этого ресурса важным является количество операций ввода/ вывода в секунду. Также на общую производительность системы влияет способ организации в ней хранения данных. Рекомендуется равномерно распределять сохраняемые данные между всеми доступными в системе устройствами. Существуют следующие принципы распределения данных на дисковых устройствах:
— файлы операционной системы должны быть отделены (располагаться физически на разных носителях) от файлов базы данных;
— основные файлы БД должны быть отделены от индексных файлов;
— журнал восстановления должен быть отделен от остальной части БД.
4 Сеть. При организации сетевого доступа к БД узким местом всей системы может стать чрезмерный рост сетевого трафика. Оптимальная загрузка сети должна быть реализована в клиентских приложениях БД.
Для планирования оптимальных характеристик среды хранения должны быть обсуждены также следующие вопросы.
1 Определение функциональных характеристик транзакций, которые будут выполняться в базе данных.
Транзакция – неделимый с точки зрения СУБД набор действий, выполняемых пользователем БД с целью доступа или изменений содержимого БД.
Изучаются качественные и количественные характеристики присущих проектируемой БД транзакций – ожидаемая частота выполнения; таблицы, поля таблиц и операции над данными транзакции, используемые индексы; ограничения, устанавливаемые на выполнение транзакции. Далее определяются самые «важные» (наиболее активные) транзакции, зависимость их друг от друга, возможные проблемы и конфликты. Разработчики БД должны найти оптимальные способы взаимодействия транзакций, для каждой транзакции определить максимальную производительность.
2 Выбор файловой структуры. Возможны следующие варианты типов файлов: последовательные файлы, хешированные файлы, индексно—последовательные файлы, двоичные деревья. Структура файлов изучается и документируется, обосновывается выбор конкретного варианта.
Необходимо, однако, отметить, что современные СУБД не предоставляют разработчику больших возможностей выбора или изменения способа организации файлов БД.
3 Анализ необходимости введения контролируемой избыточности данных. В том случае, если требования к производительности системы не удается удовлетворить никакими другими способами, снижают требования к уровню нормализации данных. Такую процедуру называют оптимизацией использования. Денормализация целесообразна, если данные в БД обновляются редко, а количество выполняемых запросов велико. В противном случае требования к непротиворечивости данных должны превышать требования к производительности системы.
4 Определение требований к дисковой памяти. Выделяемая для хранения БД память должна иметь размер, позволяющий накапливать данные. В среде каждой конкретной СУБД необходимо опытным путем определять возможный рост требуемого объема памяти для проектируемой БД.
Подготовка среды хранения является важной задачей, определяющей производительность дальнейшего использования БД.
Любой проект в конечном счете должен принести прибыль. По общему мнению, хранилище данных создается для информационной поддержки процесса принятия решений, осуществляет процесс доставки необходимой, актуальной и верной информации нужным людям в нужное время, с тем, чтобы они могли принимать обоснованные и своевременные решения.
Для большой организации число лиц, принимающих решения и нуждающихся в определенной информационной поддержке, достаточно велико. Реализация проекта, охватывающего деятельность всей организации, потребует длительного времени и больших затрат. К тому же, конкретные требования к доставляемой информации меняются достаточно быстро, и возможно, что по окончании проекта его актуальность будет далека от ожидаемой. Осознание этого факта приводит нас к двум выводам. Во-первых, создание хранилища данных должно осуществляться короткими и быстро дающими ощутимые результаты этапами. Во-вторых, созданное хранилище данных не будет статической, раз и навсегда созданной системой. Требования к доставляемой для принятия решений информации будут меняться в процессе его эксплуатации и развития, поэтому логическая и физическая структура хранилища данных, должна позволять достаточно быстро и безболезненно осуществлять требуемые изменения.
Каждый этап построения хранилища реализуется как отдельный проект, который имеет основные стадии, представленные на рис. 1.
|
Рис. 1. Основные стадии построения хранилища данных |
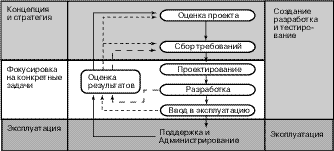
С самого начала необходимо оценить условия для реализации проекта, которые помимо традиционных условий, таких как достаточный бюджет и наличие команды разработчиков, включают понимание концепции хранилищ данных, определенный уровень информационной инфраструктуры и другие. Для эффективного контроля над ходом выполнения проекта важно также с самого начала выбрать четкие и ясные критерии оценки проекта.
Затем необходимо выявить основные проблемы организации в целом, а также определить доступные источники данных, чтобы, получив общую, концептуальную модель деятельности организации, использовать ее как базис для стратегии построения хранилища.
Из всего разнообразия задач выбирается наиболее значимая задача, как цель первого (или очередного) этапа построения хранилища данных.
2.2. Сбор требований
На стадии сбора требований осуществляется определение круга пользователей, связанных с решаемой на данном этапе проблемой, и их опрос. Параллельно осуществляется анализ имеющихся источников информации и способов доступа к ним. В результате этой стадии конкретизируются:
Структура данных в источниках
Основные предметные области, связанные с задачей
Требования пользователей
На этой же стадии вводится четко определенные и согласованные со всеми участниками проекта критерии завершения проекта или его очередной итерации.
2.3. Проектирование хранилища данных
На основе информации, собранной на предыдущих стадиях, производится анализ и проектирование структуры будущей системы, в частности, на этой стадии формируются:
Логическая и физическая модели данных
Схемы процессов загрузки
Модели приложений
2.4. Разработка хранилища данных
Эта стадия включает следующие шаги:
Разработка процедур начальной загрузки
Проведение начальной загрузки
Разработка процедур регулярной загрузки
Разработка приложений
Проведение тестовых испытаний
2.5. Ввод в эксплуатацию
Ввод в эксплуатацию включает в себя:
Обучение пользователей
Перевод проекта в стадию эксплуатации (определение администраторов, регламентов и т.д.)
2.6. Оценка результатов
В процессе всего этапа необходимо проводить регулярные оценки результатов ведения проекта с целью минимизировать последствия возникающих проблем на самом раннем этапе их возникновения. В случае необходимости производится откат на предыдущие стадии.
Каждый из этапов проведения проекта заканчивается оценкой результатов и презентацией этих результатов всем членам рабочей группы, включая и будущих пользователей системы. Участие конечных пользователей на всех стадиях проектирования, а не только на стадии сбора требований, является ключевым моментом. Это дает возможность пользователю почувствовать себя творцом данного проекта, существенно облегчает процесс внедрения и способствует общему успеху процесса.
3. Архитектура хранилища данных
Ясное и четкое представление об архитектуре будущей системы должно быть у всех участников проекта: от архитекторов и разработчиков, до опрашиваемых представителей конечных пользователей. Основными элементами доставки требуемой информации являются:
Загрузка данных из источников, в число которых входят различные СУБД, ERP (Enterprise Resource Planning) системы, а также электронные таблицы, текстовые файлы, ленты новостей и т.д.
Хранение данных в специально спроектированных структурах, отражающих их предметную специфику и обеспечивающих эффективный доступ
Использование информации через многочисленные типы приложений в терминах, хорошо понятных конечному пользователю
Все элементы системы базируются на краеугольном камне хранилища данных – метаданных. В метаданных содержится вся жизненно важная информация о хранилище, в том числе:
Логическая и физическая структура хранилища
Процессы загрузки и их регламент
Приложения и возможные способы представления информации.
Индексирование и хеширование данных в базе данных.
Вопросы представления данных тесно связаны с операциями, при помощи которых эти данные обрабатываются. К числу таких операций относятся: выборка, изменение, включение и исключение данных. В основе всех перечисленных операций лежит операция доступа, которую нельзя рассматривать независимо от способа представления. В задачах поиска предполагается, что все данные хранятся в памяти с определенной идентификацией и, говоря о доступе, имеют в виду, прежде всего доступ к данным (называемым ключами), однозначно идентифицирующим связанные с ними совокупности данных.
Определение ключа для таблицы означает автоматическую сортировку записей, контроль отсутствия повторений значений в ключевых полях записей и повышение скорости выполнения операций поиска в таблице. Для реализации этих функций в СУБД применяют индексирование.
Термин «индекс» тесно связан с понятием «ключ», хотя между ними есть и некоторое отличие.
Под индексом понимают средство ускорения операции поиска записей в таблице, а, следовательно, и других операций, использующих поиск: извлечение, модификация, сортировка и т. д. Таблицу, для которой используется индекс, называют индексированной.
Индекс выполняет роль оглавления таблицы, просмотр которого предшествует обращению к записям таблицы. В некоторых системах, например, FoxPro, индексы хранятся в индексных файлах, хранимых отдельно от табличных файлов.
Варианты решения проблемы организации физического доступа к информации зависят в основном от следующих факторов:
вида содержимого в поле ключа записей индексного файла;
типа используемых ссылок (указателей) на запись основной таблицы;
метода поиска нужных записей.
При создании индекса в нем сохраняется информация о местонахождении записей, относящихся к индексируемому столбцу таблицы. При добавлении в таблицу новых записей или удалении существующих индекс также модифицируется.
При выполнении запроса к базе данных, в условие поиска которого входит индексированный столбец, поиск значений производится в первую очередь в индексе. Если этот поиск оказывается успешным, то в индексе устанавливается точное местоположение искомых данных в таблице базы данных.
В приведённом примере индекс построен по полю ИМЯ. В индексе записи хранятся в отсортированном виде (в отличие от таблицы БД), что позволяет ускорить доступ к данным.
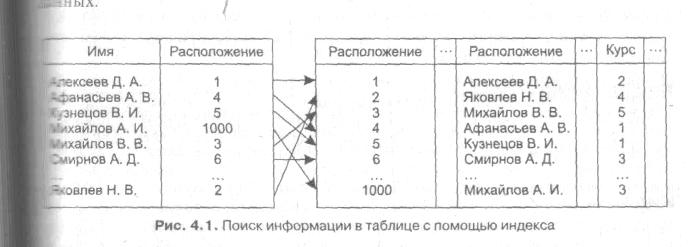
Наибольший эффект повышения производительности работы с индексированными таблицами достигается для значительных по объему таблиц. Индексирование требует небольшого дополнительного места на диске и незначительных затрат процессора на изменение индексов в процессе работы.
Еще один интересный подход, применяемый для повышения эффективности доступа к данным,— хеширование (свертка ключа). Этот метод используется тогда, когда все множество ключей заранее известно и на время обработки может быть размещено в оперативной памяти. В этом случае строится специальная функция, однозначно отображающая множество ключей на множество указателей, называемая хеш-функцией. Имея такую функцию можно вычислить адрес записи в файле по заданному ключу поиска. В общем случае ключевые данные, используемые для определения адреса записи, организуются в виде таблицы, называемой хэш-таблицей. Преимущество хранения хеш - кода в поле ключа индексного файла вместо значения состоит в том, что длина свертки независимо от длины исходного значения ключевого поля всегда имеет постоянную и достаточно малую величину ( напр. 4 байта), что существенно снижает время поисковых операций. Недостатком является необходимость выполнения операции свертки (требуется дополнительное время), а также борьба с возникновением коллизий (свертка различных значений может дать одинаковый хеш-код).
Защита данных в базе данных.
В современных СУБД поддерживается один из двух наиболее общих подходов к вопросу обеспечения безопасности данных: избирательный подход и обязательный подход. В обоих подходах единицей данных или "объектом данных", для которых должна быть создана система безопасности, может быть как вся база данных целиком, так и любой объект внутри базы данных.
Эти два подхода отличаются следующими свойствами:
В случае избирательного управления некоторый пользователь обладает различными правами (привилегиями или полномочиями) при работе с данными объектами. Разные пользователи могут обладать разными правами доступа к одному и тому же объекту. Избирательные права характеризуются значительной гибкостью.
В случае неизбирательного управления, наоборот, каждому объекту данных присваивается некоторый классификационный уровень, а каждый пользователь обладает некоторым уровнем допуска. При таком подходе доступом к определенному объекту данных обладают только пользователи с соответствующим уровнем допуска.
Для реализации избирательного принципа предусмотрены следующие методы. В базу данных вводится новый тип объектов БД — это пользователи. Каждому пользователю в БД присваивается уникальный идентификатор. Для дополнительной защиты каждый пользователь кроме уникального идентификатора снабжается уникальным паролем, причем если идентификаторы пользователей в системе доступны системному администратору, то пароли пользователей хранятся чаще всего в специальном кодированном виде и известны только самим пользователям.
Пользователи могут быть объединены в специальные группы пользователей. Один пользователь может входить в несколько групп. В стандарте вводится понятие группы PUBLIC, для которой должен быть определен минимальный стандартный набор прав. По умолчанию предполагается, что каждый вновь создаваемый пользователь, если специально не указано иное, относится к группе PUBLIC.
Привилегии или полномочия пользователей или групп — это набор действий (операций), которые они могут выполнять над объектами БД.
В последних версиях ряда коммерческих СУБД появилось понятие "роли". Роль — это поименованный набор полномочий. Существует ряд стандартных ролей, которые определены в момент установки сервера баз данных. И имеется возможность создавать новые роли, группируя в них произвольные полномочия. Введение ролей позволяет упростить управление привилегиями пользователей, структурировать этот процесс. Кроме того, введение ролей не связано с конкретными пользователями, поэтому роли могут быть определены и сконфигурированы до того, как определены пользователи системы.
Пользователю может быть назначена одна или несколько ролей.
Объектами БД, которые подлежат защите, являются все объекты, хранимые в БД: таблицы, представления, хранимые процедуры и триггеры. Для каждого типа объектов есть свои действия, поэтому для каждого типа объектов могут быть определены разные права доступа.
На самом элементарном уровне концепции обеспечения безопасности баз данных исключительно просты. Необходимо поддерживать два фундаментальных принципа: проверку полномочий и проверку подлинности (аутентификацию).
Проверка полномочий основана на том, что каждому пользователю или процессу информационной системы соответствует набор действий, которые он может выполнять по отношению к определенным объектам. Проверка подлинности означает достоверное подтверждение того, что пользователь или процесс, пытающийся выполнить санкционированное действие, действительно тот, за кого он себя выдает.
Система назначения полномочий имеет в некотором роде иерархический характер. Самыми высокими правами и полномочиями обладает системный администратор или администратор сервера БД. Традиционно только этот тип пользователей может создавать других пользователей и наделять их определенными полномочиями.
СУБД в своих системных каталогах хранит как описание самих пользователей, так и описание их привилегий по отношению ко всем объектам.
Далее схема предоставления полномочий строится по следующему принципу. Каждый объект в БД имеет владельца — пользователя, который создал данный объект. Владелец объекта обладает всеми правами-полномочиями на данный объект, в том числе он имеет право предоставлять другим пользователям полномочия по работе с данным объектом или забирать у пользователей ранее предоставленные полномочия.
Средства защиты БД в различных СУБД несколько отличаются друг от друга. Но условно их можно разделить на две группы: основные и дополнительные.
К основным средствам защиты информации можно отнести следующие средства:
парольной защиты;
шифрования данных и программ;
установления прав доступа к объектам БД;
защиты полей и записей таблиц БД.
Парольная защита представляет простой и эффективный способ защиты БД от несанкционированного доступа. Пароли устанавливаются конечными пользователями или администраторами БД. Учет и хранение паролей производится самой СУБД. Обычно пароли хранятся в определенных системных файлах СУБД в зашифрованном виде. Поэтому просто найти и определить пароль невозможно. После ввода пароля пользователю СУБД предоставляются все возможности по работе с защищенной БД. Саму СУБД защищать паролем большого смысла нет.
Шифрование данных (всей базы или отдельных таблиц) применяют для того, чтобы другие программы, «знающие формат БД этой СУБД», не могли прочитать данные. Такое шифрование (применяемое в Microsoft Ассess), по-видимому, даст немного, поскольку расшифровать БД может любой с помощью -«родной» СУБД
Шифрование исходных текстов программ позволяет скрыть от несанкционированного пользователя описание соответствующих алгоритмов.
В целях контроля использования основных ресурсов СУБД во многих системах имеются средства установления прав доступа к объектам БД. Права доступа определяют возможные действия над объектами. Владелец объекта (пользователь, создавший объект), а также администратор БД имеют все права. Остальные пользователи к разным объектам могут иметь различные уровни доступа.
По отношению к таблицам в общем случае могут предусматриваться следующие права доступа:
просмотр (чтение) данных;
изменение (редактирование) данных;
добавление новых записей;
добавление и удаление данных;
все операции, в том числе изменение структуры таблицы.
Применительно к защите данных в полях таблиц можно выделить следующие уровни прав доступа;
полный запрет доступа;
только чтение;
разрешение всех операций (просмотр, ввод новых значений, удаление и изменение).
Для исключения просмотра и модификации (случайной и преднамеренной) текстов программ, используемых в приложениях СУБД, помимо шифрации, может применяться их парольная защита.
К дополнительным средствам защиты БД можно отнести такие, которые нельзя прямо отнести к средствам защиты, но которые непосредственно влияют на безопасность данных. Их составляют следующие средства:
встроенные средства контроля значений данных в соответствии с типами;
повышения достоверности вводимых данных;
обеспечения целостности связей таблиц;
организации совместного использования объектов БД в сети.
Язык SQL, назначение, основные команды языка.
SQL (англ. Structured Query Language — «язык структурированных запросов») — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных.
SQL является, прежде всего, информационно-логическим языком, предназначенным для описания хранимых данных, для извлечения хранимых данных и для модификации данных. SQL не является языком программирования. (Вместе с тем стандарт языка спецификацией SQL/PSM предусматривает возможность его процедурных расширений).
Изначально, SQL был основным способом работы пользователя с базой данных и представлял собой небольшую совокупность команд (операторов) допускающих создание таблиц, добавление в таблицы новых записей, извлечение записей из таблиц (в соответствии с заданным условием), удаление записей и изменение структур таблиц. В связи с усложнением язык SQL стал более прикладным языком программирования, а пользователи получили возможность использовать визуальные построители запросов.
Первая версия языка SQL появилась в середине 70-х гг., которая была разработана в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка сиквел - SEQUEL (Structered English QUEry Language) только частично отражает суть этого языка. Конечно, язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционной БД. Но на самом деле он уже являлся полным языком БД, содержащим, помимо операторов формулирования запросов и манипулирования данными, средства определения и манипулирования схемой БД; определения ограничений целостности и триггеров; возможности определения структур физического уровня, поддерживающих эффективное выполнение запросов; средства авторизации доступа к отношениям и их полям; средства определения точек сохранения транзакции и откатов.
Первый официальный стандарт языка SQL был принят ANSI в 1986 году и ISO (Международной организацией по стандартизации) в 1987 году (так называемый SQL-86) и несколько уточнён в 1989 году. Дальнейшее развитие языка поставщиками СУБД потребовало принятия в 1992 году нового расширенного стандарта (ANSI SQL-92 или просто SQL2). Следующим стандартом стал SQL:1999 (SQL3). В настоящее время действует стандарт, принятый в 2003 году (SQL:2003) с небольшими модификациями, внесёнными позже.
Язык SQL предназначен для манипулирования данными в реляционных базах данных, определения структуры баз данных и для управления правами доступа к данным в многопользовательской среде.
Поэтому, в язык SQL в качестве составных частей входят:
язык манипулирования данными (Data Manipulation Language, DML)
язык определения данных (Data Definition Language, DDL)
язык управления данными (Data Control Language, DCL).
Подчеркнем, что это не отдельные языки, а различные команды одного языка. Такое деление проведено только лишь с точки зрения различного функционального назначения этих команд.
Язык манипулирования данными используется, как это следует из его названия, для манипулирования данными в таблицах баз данных. Он состоит из 4 основных команд:
SELECT |
(выбрать) |
INSERT |
(вставить) |
UPDATE |
(обновить) |
DELETE |
(удалить) |
Язык определения данных используется для создания и изменения структуры базы данных и ее составных частей - таблиц, индексов, представлений (виртуальных таблиц), а также триггеров и сохраненных процедур. Основными его командами являются:
CREATE DATABASE |
(создать базу данных) |
CREATE TABLE |
(создать таблицу) |
CREATE VIEW |
(создать виртуальную таблицу) |
CREATE INDEX |
(создать индекс) |
CREATE TRIGGER |
(создать триггер) |
CREATE PROCEDURE |
(создать сохраненную процедуру) |
ALTER DATABASE |
(модифицировать базу данных) |
ALTER TABLE |
(модифицировать таблицу) |
ALTER VIEW |
(модифицировать виртуальную таблицу) |
ALTER INDEX |
(модифицировать индекс) |
ALTER TRIGGER |
(модифицировать триггер) |
ALTER PROCEDURE |
(модифицировать сохраненную процедуру) |
DROP DATABASE |
(удалить базу данных) |
DROP TABLE |
(удалить таблицу) |
DROP VIEW |
(удалить виртуальную таблицу) |
DROP INDEX |
(удалить индекс) |
DROP TRIGGER |
(удалить триггер) |
DROP PROCEDURE |
(удалить сохраненную процедуру) |
Язык управления данными используется для управления правами доступа к данным и выполнением процедур в многопользовательской среде. Более точно его можно назвать "язык управления доступом". Он состоит из двух основных команд:
GRANT |
(дать права) |
REVOKE |
(забрать права) |
С точки зрения прикладного интерфейса существуют две разновидности команд SQL:
интерактивный SQL
встроенный SQL.
Интерактивный SQL используется в специальных утилитах (типа WISQL или DBD), позволяющих в интерактивном режиме вводить запросы с использованием команд SQL, посылать их для выполнения на сервер и получать результаты в предназначенном для этого окне. Встроенный SQL используется в прикладных программах, позволяя им посылать запросы к серверу и обрабатывать полученные результаты, в том числе комбинируя set-ориентированный и record-ориентированный подходы.
Базы знаний. Определения и свойства баз знаний.
База знаний - семантическая модель, описывающая предметную область и позволяющая отвечать на такие вопросы из этой предметной области, ответы на которые в явном виде не присутствуют в базе. База знаний является основным компонентом интеллектуальных и экспертных систем
Система, основанная на знаниях - система искусственного интеллекта, в которой предметные знания представлены в явном виде и отделены от прочих знаний системы
Искусственный интеллект - способность прикладного процесса обнаруживать свойства, ассоциируемые с разумным поведением человека.
Искусственный интеллект - раздел информатики, занимающийся вопросами имитации мышления человека с помощью компьютера.
Механизм вывода - в системах искусственного интеллекта - процедура нахождения решений задач. Принципы построения механизма вывода определяются способом представления знаний и видом моделируемых рассуждений.
При изучении интеллектуальных систем традиционно возникает вопрос — что же такое знания и чем они отличаются от обычных данных, десятилетиями обрабатываемых ЭВМ. Можно предложить несколько рабочих определений, в рамках которых это становится очевидным.
Данные — это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства.
При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы:
D1 — данные как результат измерений и наблюдений;
D2 — данные на материальных носителях информации (таблицы, протоколы, справочники);
D3 — модели (структуры) данных в виде диаграмм, графиков, функций;
D4 — данные в компьютере на языке описания данных;
D5 — базы данных на машинных носителях информации.
Знания основаны на данных, полученных эмпирическим путем. Они представляют собой результат мыслительной деятельности человека, направленной на обобщение его опыта, полученного в результате практической деятельности.
Знания — это закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи а этой области.
При обработке на ЭВМ знания трансформируются аналогично данным.
Z1 — знания в памяти человека как результат мышления;
Z2 — материальные носители знаний (учебники, методические пособия);
Z3 — поле знаний — условное описание основных объектов предметной области, их атрибутов и закономерностей, их связывающих;
Z4 — знания, описанные на языках представления знаний (продукционные языки, семантические сети, фреймы — см. далее);
Z5 — база знаний на машинных носителях-нформации.
Часто используется такое определение знаний.
Знания — это хорошо структурированные данные, или данные о данных, или метаданные.
Знания делятся на четыре вида: понятийные, конструктивные, процедурные и фактографические.
1) Понятийные или концептуальные знания - это набор понятий из некоторой области знания, их свойства и взаимосвязи.
2) Конструктивные знания — знания о структуре объектов, о взаимодействии их частей.
3) Процедурные или алгоритмические знания - это уже известные людям методы решения задач, алгоритмы, программы.
4) Фактуальные или фактографические знания - это количественные и качественные характеристики конкретных объектов.
Например, если в качестве объекта взять обычный письменный стол, то знания о нем можно распределить следующим образом:
Понятийное знание: стол предназначен для того, чтобы на нем писать; он изготовлен из некоторого материала, имеет вес, длину, ширину, высоту, цвет и пр.
Конструктивное знание: стол имеет столешницу, четыре ножки, два ящика. Столешница расположена сверху, горизонтально. Ножки расположены под столешницей по углам, на некотором расстоянии от края столешницы с небольшим наклоном внутрь стола. Ящики расположены справа под столешницей друг под другом. Ножки закреплены на болтах; ящики — тоже. Ящики снабжены ручками и замками. И т. д.
Фактуальное знание: стол изготовлен из дерева, болты — стальные; высота стола — 70 см, длина — 110 см, ширина — 60 см, цвет — коричневый и пр.
Алгоритмическое знание — это правила сборки стола из составных частей (правила установки ножек и ящиков), правила крепления деталей с помощью болтов, правила установки замков на ящиках, правила запирания/отпирания замков и пр.
Для хранения данных используются базы данных (для них характерны большой объем и относительно небольшая удельная стоимость информации), для хранения знаний — базы знаний (небольшого объема, но исключительно дорогие информационные массивы).
База знаний — основа любой интеллектуальной системы.
База знаний — это особого рода база данных, разработанная для оперирования знаниями (метаданными). Полноценные базы знаний содержат в себе не только фактическую информацию, но и правила вывода, допускающие автоматические умозаключения о вновь вводимых фактах и, как следствие, осмысленную обработку информации. Область наук об искусственном интеллекте, изучающая базы знаний и методы работы со знаниями, называется инженерией знаний.
Современные базы знаний обычно работают совместно с продвинутыми системами поиска информации и имеют тщательно продуманную структуру и формат представления знаний.
Иерархический способ представления в базе знаний набора понятий и их отношений называется онтологией. Онтологию некоторой области знаний вместе со сведениями о свойствах конкретных объектов также можно назвать базой знаний.
Любая база знаний (БЗ) содержит в себе базу данных (БД) в качестве составляющей, но не сводится к ней. Главное отличие БЗ от БД с точки зрения пользователя — ее активность. База данных — пассивна. Из базы данных можно извлечь лишь ту фактическую информацию, которая в нее заложена. База знаний — активна. Благодаря процедурной компоненте она может сама выводить новые факты, которые непосредственно в нее заложены не были, может по своей инициативе вступать во взаимодействие с другими установленными на компьютере системами и с человеком.
При построении баз знаний традиционные средства, основанные на численном представлении данных, являются неэффективными. Для этого используются специальные языки представления знаний, основанные на символьном представлении данных. Они делятся на типы по формальным моделям представления знаний. Один из самых интересных вопросов при работе со знаниями — это вопрос о средствах представления знаний.
Необходимо различать три уровня представления:
внешнее представление - знания в том виде, в котором их видит пользователь (при вводе информации в систему и при получении информации из системы),
внутреннее представление - знания в том виде, в котором они хранятся в системе,
смысловое (модельное) представление - знания в том виде, в каком пользователь может их себе представлять при работе с системой.
Например, пусть требуется представить информацию о дорогах между населенными пунктами района. Представлять себе ее удобней всего в виде графа, вершинами которого являются населенные пункты, а ребрами (или дугами) - дороги. Это и будет модельное представление знаний. Однако ввод его в ЭВМ в таком виде может быть затруднен. Разные уровни представления могут и совпадать.
Существует несколько возможных модельных представлений знаний - продукционные и логические модели; представление знаний в виде графов, фреймов и т. д. Многие варианты представлений знаний в виде графов имеют свои собственные названия: семантические сети, ассоциативные сети, вычислительные модели, модели «сущность-связь», бинарные модели и др.
Когнитивное моделирование. Технологии проектирования баз знаний.
К концу 90-х годов созрели предпосылки для качественного скачка в интенсификации познавательного использования компьютерных технологий: компьютер реально стал не только и не столько вычислительным устройством (как это, собственно, и должно было следовать из его названия), и не столько просто устройством для хранения и обработки больших объемов информации, сколько комплексным познавательным инструментом - массовым атрибутом современного образовательного процесса и научных исследований.
В связи с этим особую актуальность приобретают исследования в области изучения и анализа именно познавательных (правомерно использование и более специфического термина: когнитивных) функций компьютерных технологий. Основная цель таких исследований заключается в более глубоком понимании и, как следствие, в существенно более эффективном использовании когнитивных возможностей современного компьютера.
Интерактивная машинная графика (ИМГ) стала уже практически обязательным атрибутом всех современных систем моделирования. Следующим шагом в данном направлении должно стать всестороннее, комплексное и целенаправленное использование ИМГ для максимальной активизации творческого и познавательного потенциала человеческого интеллекта.
Важнейшим атрибутом когнитивного компьютерного моделирования являются когнитограммы, т.е. специальным образом организованная визуализация моделей, данных и результатов моделирования, ориентированная на максимальную активизацию образно-интуитивных механизмов мышления. Можно выделить три категории когнитограмм: искусственные (абстрактные), естественные (в той или иной степени имитирующие реальную или виртуальную визуальную обстановку) и комбинированные или совмещенные, объединяющие свойства первых двух категорий.
Самыми распространенными в настоящее время являются искусственные когнитограммы, наиболее простым вариантом реализации которых можно считать использование традиционной визуализации результатов в виде разнообразных графиков и диаграмм различной размерности.
Еще одним видом когнитограмм данного класса являются так называемые когнитивные карты, отображающие в виде специальных структурных схем концептуальные и логические зависимости различных когнитивных моделей.
Этапы проектирования баз знаний
Многие созданные к настоящему времени ЭС ориентированы на решение конкретных задач и сконструированы с использованием разнообразных инструментальных средств. Однако к настоящему времени выделены основные принципы их построения.
Каждая конкретная ЭС является человеко-машинной системой. В ее разработке необходимо участие экспертов, инженеров по знаниям и консультантов.
Эксперты – это специалисты в данной ПО, знания которых требуются ввести в база знаний ЭС, чтобы в дальнейшим система смогла их использовать при выполнении своих не посредственных функций.
Эксперт – профессионал обладает знаниями двух типов – вербализуемые и невербализуемые Вербализуемые знания выражаются словесно или письменно, с использованием различных графиков, схем, обобщаются в виде статей, монографий, научных отчетов.
Невербализуемые знания отражают тот профессиональный опыт специалиста, который он накопил в процессе своей профессиональной деятельности который желают его эксперты. Зачастую эти знания представляют наибольший интерес для проектируемой ЭС. Однако они являются невербализуемыми, т.е. трудновыразимыми, так как существует у специалиста подсознательно. Получение таких знаний и является в настоящее время одной из центральных задач для специалистов искусственному интеллекту. Разрабатываются специальные психологические методы и примеры косвенного выявления таких знаний.
Конструкторы – группа специалистов в области АС обработки данных, поддерживающий инструментальный пакет программ, и других технологических средств, на базе которых создаются ЭС.
Методы проектирования баз знаний
В настоящее время основным узким местом при проектировании баз знаний ЭС является приобретение необходимых знаний для ЭС. Знания о ПО можно взять из разных источников (научные отчеты, монографии, статьи, БД, опытные данные и т.п., а также личный опыт эксперта проффесионала). Работа по сбору и обработке знаний выполняется специалистом инженером по знаниям. Обычно большую часть профессиональных знаний инженер по знания получает от эксперта. К настоящему времени уже сформировался ряд методов проектирования баз знаний, ориентированных на получение информации от экспертов. Рассмотрим их.
Беседы с экспертом. В данной группе методов различают наблюдательный и интуитивный подходы.
При наблюдательном подходе следят за работой эксперта, стараясь не сделать что могло бы повлиять на работу эксперта при решении задачи. За наблюдение следует этап уточнения, на котором инженер по знаниям совместно с экспертом анализирует запись сеанса работы эксперта, выполненную наблюдателем. Такой подход еще называют анализом протоколов.
При интуитивном подходе в одном случае эксперт выступает как разработчик модели своего проведения при решении задач, во втором как инженер познаниям изучает литературу и другие источники информации, разрабатывает представление знаний о ПО и затем проверяет их достоверность с экспертами.
Обсуждение задач. Инженер по знаниям подготавливает некоторый набор задач и затем в свободной обстановке обсуждает их с экспертом, стараясь определить как, организованы знания эксперта об этих задачах какими понятиями и гипотезами по По он руководствуется в своей работе, как работает с неполными, неточными либо противоречивыми данными по той или иной задаче.
Описание задачи. Эксперт подготавливает описание типичных задач ПО. Этот метод очень хорошо работает на задачах диагностического типа.
Анализ задач. Инженер по знаниям подготавливает несколько задач, близких к реальным и просит эксперта решить их. Цель того – выявить стратегию, используемою при решении задачи. Рассуждая в слух, работающие стремятся выделить как можно больше промежуточных шагов решения и проанализировать их.
Оценивание системы. Эксперт анализирует и критически оценивает правила вводимые в базу знаний ЭС, анализирует стратегии выбора правил системой при решении задач рассматривает обоснованность их применения, постоянно сравнивая их со своими методами решении задач.
Проверка системы. Инженер по знаниям представляет задачи и результаты их решения, выполненные как экспертом, так и прототипом создаваемой системы другим экспертом. Цель – выявление элементов, вызывающих разногласия.
Кроме выше названых, существует еще целый ряд практических методов, используемых при проектировании базы знаний на каждом этапе.
Полученные от экспертов и из других источников знания необходимо зафиксировать в виде концептуальной базы знаний первого варианта системы. Для этого выполняется следующая спецификация выявленных знаний.
Базы знаний и системы управления знаниями организации.
Понятие «управление знаниями» (КМ — Knowledge Management) появилось в середине 90-х годов в крупных корпорациях, где проблемы обработки информации приобрели особую остроту и стали критическими. При этом стало очевидным, что основным узким местом является обработка знаний, накопленных специалистами компании, так как именно знания обеспечивают преимущество перед конкурентами. Часто информации в компаниях накоплено даже больше, чем они в состоянии обработать. Различные компании пытаются решать этот вопрос по-разному, но при этом каждая компания стремится увеличить эффективность обработки знаний.
Ресурсы знаний различаются в зависимости от отраслей индустрии и приложений, но, как правило, включают руководства, письма, новости, информацию о заказчиках, сведения о конкурентах и данные, накопившиеся в процессе разработки. Для применения КМ-систем используются разнообразные технологии:
электронная почта;
базы и хранилища данных (Data Wharehouse);
системы групповой поддержки;
броузеры и системы поиска;
корпоративные сети и Интернет;
экспертные системы и базы знаний; интеллектуальные системы.
Традиционно проектировщики систем КМ ориентировались лишь на отдельные группы потребителей — главным образом менеджеров. Более современные КМ-системы спроектированы уже в расчете на целую организацию.
Хранилища данных, которые работают по принципу центрального склада, были одним из первых инструментариев КМ. Как правило, хранилища содержат многолетние версии обычной БД, физически размещаемые в той же самой базе. Когда все данные содержатся в едином хранилище, изучение связей между отдельными элементами может быть более плодотворным.
При этом активы знаний могут находиться в различных местах: в базах данных, базах знаний, в картотечных блоках, у специалистов и могут быть рассредоточены по всему предприятию. Слишком часто одна часть предприятия повторяет работу другой части просто потому, что невозможно найти и использовать знания, находящиеся в других частях предприятия.
Управление знаниями — это совокупность процессов, которые управляют созданием, распространением, обработкой и использованием знаний внутри предприятия.
Необходимость разработки систем КМ обусловлена следующими причинами:
• работники предприятия тратят слишком много времени на поиск необходимой информации;
• опыт ведущих и наиболее квалифицированных сотрудников используется только ими самими;
• ценная информация захоронена в огромном количестве документов и данных, доступ к которым затруднен;
• дорогостоящие ошибки повторяются из-за недостаточной информированности и игнорирования предыдущего опыта.
Важность систем КМ обусловлена также тем, что знание, которое не используется и не возрастает, в конечном счете становится устаревшим и бесполезным, так же, как деньги, которые сохранены без того, чтобы стать оборотным капиталом, в конечном счете теряют свою стоимость, пока не обесценятся. Напротив, знание, которое распространяется, приобретается и обменивается, генерирует новое знание.
Управление знаниям и корпоративная память
Большинство обзоров концепции управления знания (КМ) уделяет внимание только первичной обработке корпоративной информации типа электронной почты, программного обеспечения коллективной работы или гипертекстовых баз данных (например fWiig, 1996]). Они формируют существенную часть из необходимой, но определенно не достаточной технической инфраструктуры для управления знаниями.
Одним из новых решений по управлению знаниями является понятие корпоративной памяти (corporate memory), которая по аналогии с человеческой памятью позволяет пользоваться предыдущим опытом и избегать повторения ошибок.
Корпоративная память фиксирует информацию из различных источников предприятия и делает эту информацию доступной специалистам для решения производственных задач.
Корпоративная память не позволяет исчезнуть знаниям выбывающих специалистов (уход на пенсию, увольнение и пр.). Она хранит большие объемы данных, информации и знаний из различных источников предприятия. Они представлены в различных формах, таких как базы данных, документы и базы знаний.
При разработке систем КМ можно выделить следующие этапы:
1. Накопление. Стихийное и бессистемное накопление информации в организации.
2 Извлечение. Процесс, идентичный традиционному извлечению знаний для ЭС. Это один из наиболее сложных и трудоемких этапов. От его успешности зависит дальнейшая жизнеспособность системы.
3 Структурирование. На этом этапе должны быть выделены основные понятия, выработана структура представления информации, обладающая максимальной наглядностью, простотой изменения и дополнения.
4 Формализация. Представление структурированной информации в форматах машинной обработки, то есть на языках описания данных и знаний.
5 Обслуживание. Под процессом обслуживания понимается корректировка формализованных данных и знаний (добавление, обновление): «чистка», то есть удаление устаревшей информации; фильтрация данных и знаний для поиска информации, необходимой пользователям.
Если первые четыре этапа обычны для инженерии знаний, то последний является специфичным для систем управления знаниями. Как уже было сказано, он распадается на три более мелких процесса:
Корректировка формализованных знаний (добавление, обновление).
Удаление устаревшей информации.
Фильтрация знаний для поиска информации, необходимой пользователю, выделяет компоненты данных и знаний, соответствующие требованиям конкретного пользователя. При помощи той же процедуры пользователь может узнать местонахождение интересующей его информации.
Экспертные системы. Определение, назначение требования к экспертным системам. Структура экспертных систем.
Экспертная система - система искусственного интеллекта, включающая знания об определенной слабо структурированной и трудно формализуемой узкой предметной области и способная предлагать и объяснять пользователю разумные решения. Экспертная система состоит из базы знаний, механизма логического вывода и подсистемы объяснений.
Важность экспертных систем состоит в следующем:
технология экспертных систем существенно расширяет круг практически значимых задач, решаемых на компьютерах, решение которых приносит значительный экономический эффект;
технология ЭС является важнейшим средством в решении глобальных проблем традиционного программирования: длительность и, следовательно, высокая стоимость разработки сложных приложений;
высокая стоимость сопровождения сложных систем, которая часто в несколько раз превосходит стоимость их разработки; низкий уровень повторной используемости программ и т.п.;
объединение технологии ЭС с технологией традиционного программирования добавляет новые качества к программным продуктам за счет: обеспечения динамичной модификации приложений пользователем, а не программистом; большей "прозрачности" приложения (например, знания хранятся на ограниченном ЕЯ, что не требует комментариев к знаниям, упрощает обучение и сопровождение); лучшей графики; интерфейса и взаимодействия.
Экспертная система - это программа, которая ведет себя подобно эксперту в некоторой, обычно узкой прикладной области. Типичные применения экспертных систем включают в себя такие задачи, как медицинская диагностика, локализация неисправностей в оборудовании и интерпретация результатов измерений. Экспертные системы должны решать задачи, требующие для своего решения экспертных знаний в некоторой конкретной области. В той или иной форме экспертные системы должны обладать этими знаниями. Поэтому их также называют системами, основанными на знаниях. Однако не всякую систему, основанную на знаниях, можно рассматривать как экспертную. Экспертная система должна также уметь каким-то образом объяснять свое поведение и свои решения пользователю, так же, как это делает эксперт-человек. Это особенно необходимо в областях, для которых характерна неопределенность, неточность информации (например, в медицинской диагностике). В этих случаях способность к объяснению нужна для того, чтобы повысить степень доверия пользователя к советам системы, а также для того, чтобы дать возможность пользователю обнаружить возможный дефект в рассуждениях системы. В связи с этим в экспертных системах следует предусматривать дружественное взаимодействие с пользователем, которое делает для пользователя процесс рассуждения системы "прозрачным".
Часто к экспертным системам предъявляют дополнительное требование - способность иметь дело с неопределенностью и неполнотой. Информация о поставленной задаче может быть неполной или ненадежной; отношения между объектами предметной области могут быть приближенными. Например, может не быть полной уверенности в наличии у пациента некоторого симптома или в том, что данные, полученные при измерении, верны; лекарство может стать причиной осложнения, хотя обычно этого не происходит. Во всех этих случаях необходимы рассуждения с использованием вероятностного подхода.
В самом общем случае для того, чтобы построить экспертную систему, мы должны разработать механизмы выполнения следующих функций системы:
1. решение задач с использованием знаний о конкретной предметной области возможно, при этом возникнет необходимости иметь дело с неопределенностью;
2. взаимодействие с пользователем, включая объяснение намерений и решений системы во время и после окончания процесса решения задачи.
Экспертные системы и системы искусственного интеллекта отличаются от систем обработки данных тем, что в них в основном используются символьный (а не числовой) способ представления, символьный вывод и эвристический поиск решения (а не исполнение известного алгоритма).
Экспертные системы применяются для решения только трудных практических (не игрушечных) задач. По качеству и эффективности решения экспертные системы не уступают решениям эксперта-человека. Решения экспертных систем обладают "прозрачностью", т.е. могут быть объяснены пользователю на качественном уровне. Это качество экспертных систем обеспечивается их способностью рассуждать о своих знаниях и умозаключениях. Экспертные системы способны пополнять свои знания в ходе взаимодействия с экспертом. Необходимо отметить, что в настоящее время технология экспертных систем используется для решения различных типов задач (интерпретация, предсказание, диагностика, планирование, конструирование, контроль, отладка, инструктаж, управление ) в самых разнообразных проблемных областях, таких, как финансы, нефтяная и газовая промышленность, энергетика, транспорт, фармацевтическое производство, космос, металлургия, горное дело, химия, образование, целлюлозно-бумажная промышленность, телекоммуникации и связь и др.
Обобщенная структура экспертной системы представлена на рисунке 8. Следует учесть, что реальные экспертные системы могут иметь более сложную структуру.
Процесс функционирования экспертной системы можно представить следующим образом: пользователь, желающий получить необходимую информацию, через пользовательский интерфейс посылает запрос к экспертной системе, решатель пользуясь базой знаний, генерирует и выдает пользователю подходящую рекомендацию, объясняя ход своих рассуждений при помощи подсистемы объяснений.

Пользователь Инженер + Эксперт
по знаниям
Рисунок 8: Структура экспертной системы
Пользователь – специалист предметной области, для которого предназначена система. Обычно его квалификация недостаточно высока и поэтому он нуждается в помощи и поддержке своей деятельности со стороны ЭС.
Инженер по знаниям – специалист в области искусственного интеллекта, выступающий в роли промежуточного буфера между экспертом и базой знаний. Синонимы: когнитолог, инженер-интерпритатор, аналитик.
Интерфейс пользователя – комплекс программ, реализующих диалог пользователя с ЭС как на стадии ввода информации, так и при получении результатов.
База знаний – ядро ЭС, совокупность знаний предметной области, записанная на машинный носитель в форме, понятной эксперту и пользователю.
Решатель – программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в БЗ. Синонимы: дедуктивная машина, машина вывода, блок логического вывода.
Подсистема объяснений – программа, позволяющая пользователю полечить ответы на вопросы: «Как была получена та или иная рекомендация?» и «Почему система приняла такое решение?» Ответ на вопрос «как» - это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ, то есть всех шагов цепи умозаключений. Ответ на вопрос «почему» - ссылка на умозаключение, непосредственно предшествовавшие полученному решению, то есть отход на один шаг назад. Развитые подсистемы объяснений поддерживают и другие типы вопросов.
Интеллектуальный редактор БЗ – программа, представляющая инженеру по знаниям возможность создавать БЗ в диалоговом режиме. Включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок («help» - режим) и других сервисных средств, облегчающих работу с базой.
Структура экспертных систем
Типичная статическая ЭС состоит из следующих основных компонентов (рис. 9.):
решателя (интерпретатора);
рабочей памяти (РП), называемой также базой данных (БД);
базы знаний (БЗ);
компонентов приобретения знаний;
объяснительного компонента;
диалогового компонента.
База данных (рабочая память) предназначена для хранения исходных и промежуточных данных решаемой в текущий момент задачи. Этот термин совпадает по названию, но не по смыслу с термином, используемым в информационно-поисковых системах (ИПС) и системах управления базами данных (СУБД) для обозначения всех данных (в первую очередь долгосрочных), хранимых в системе.
База знаний (БЗ) в ЭС предназначена для хранения долгосрочных данных, описывающих рассматриваемую область (а не текущих данных), и правил, описывающих целесообразные преобразования данных этой области.
Решатель, используя исходные данные из рабочей памяти и знания из БЗ, формирует такую последовательность правил, которые, будучи примененными к исходным данным, приводят к решению задачи.
Компонент приобретения знаний автоматизирует процесс наполнения ЭС знаниями, осуществляемый пользователем-экспертом.
Объяснительный компонент объясняет, как система получила решение задачи (или почему она не получила решение) и какие знания она при этом использовала, что облегчает эксперту тестирование системы и повышает доверие пользователя к полученному результату.
Рисунок 9: Структура статической ЭС
Диалоговый компонент ориентирован на организацию дружественного общения с пользователем как в ходе решения задач, так и в процессе приобретения знаний и объяснения результатов работы.
В разработке ЭС участвуют представители следующих специальностей:
эксперт в проблемной области, задачи которой будет решать ЭС;
инженер по знаниям - специалист по разработке ЭС (используемые им технологию, методы называют технологией (методами) инженерии знаний);
программист по разработке инструментальных средств (ИС), предназначенных для ускорения разработки ЭС.
Необходимо отметить, что отсутствие среди участников разработки инженеров по знаниям (т. е. их замена программистами) либо приводит к неудаче процесс создания ЭС, либо значительно удлиняет его.
Эксперт определяет знания (данные и правила), характеризующие проблемную область, обеспечивает полноту и правильность введенных в ЭС знаний.
Инженер по знаниям помогает эксперту выявить и структурировать знания, необходимые для работы ЭС; осуществляет выбор того ИС, которое наиболее подходит для данной проблемной области, и определяет способ представления знаний в этом ИС; выделяет и программирует (традиционными средствами) стандартные функции (типичные для данной проблемной области), которые будут использоваться в правилах, вводимых экспертом.
Программист разрабатывает ИС (если ИС разрабатывается заново), содержащее в пределе все основные компоненты ЭС, и осуществляет его сопряжение с той средой, в которой оно будет использовано.
Экспертная система работает в двух режимах: режиме приобретения знаний и в режиме решения задачи (называемом также режимом консультации или режимом использования ЭС).
Инструментальные средства построения экспертных систем. Языки и оболочки для создания экспертных систем.
Рассмотрим особенности инструментальных средств для создания статических ЭС на примере комплекса ЭКО, разработанного в РосНИИ ИТ и АП. Наиболее успешно комплекс применяется для создания ЭС, решающих задачи диагностики (технической и медицинской), эвристического оценивания (риска, надежности и т.д.), качественного прогнозирования, а также обучения.
Комплекс ЭКО используется: для создания коммерческих и промышленных экспертных систем на персональных ЭВМ, а также для быстрого создания прототипов экспертных систем с целью определения применимости методов инженерии знаний в некоторой конкретной проблемной области.
На основе комплекса ЭКО было разработано более 100 прикладных экспертных систем. Среди них отметим следующие:
- поиск одиночных неисправностей в персональном компьютере;
- оценка состояния гидротехнического сооружения (Чарвакская ГЭС);
- подготовка деловых писем при ведении переписки с зарубежными партнерами;
- проведение скрининговой оценки иммунологического статуса;
- оценка показаний микробиологического обследования пациента, страдающего неспецифическими хроническими заболеваниями легких;
Комплекс ЭКО включает три компонента.
Ядром комплекса является интегрированная оболочка экспертных систем ЭКО, которая обеспечивает быстрое создание эффективных приложений для решения задач анализа в статических проблемных средах типа.
При разработке средств представления знаний оболочки преследовались две основные цели: эффективное решение достаточно широкого и практически значимого класса задач средствами персональных компьютеров; гибкие возможности по описанию пользовательского интерфейса и проведению консультации в конкретных приложениях. При представлении знаний в оболочке используются специализированные (частные) -утверждения типа "атрибут - значение" и частные правила, что позволяет исключить ресурсоемкую операцию сопоставления по образцу и добиться эффективности разрабатываемых приложений. Выразительные возможности оболочки удалось существенно расширить за счет интегрированности, обеспечиваемой путем вызова внешних программ через сценарий консультации и стыковки с базами данных (ПИРС и dBase IV) и внешними программами. В оболочке ЭКО обеспечивается слабая структуризация БЗ за счет ее разделения на отдельные компоненты - для решения отдельных подзадач в проблемной среде - модели (понятию "модель" ЭКО соответствует понятие "модуль" базы знаний системы G2).
С точки зрения технологии разработки ЭС оболочка поддерживает подходы, основанные на поверхностных знаниях и структурировании процесса решения.
Оболочка функционирует в двух режимах: в режиме приобретения знаний и в режиме консультации (решения задач). В первом режиме разработчик ЭС средствами диалогового редактора вводит в БЗ описание конкретного приложения в терминах языка представления знаний оболочки. Это описание компилируется в сеть вывода с прямыми адресными ссылками на конкретные утверждения и правила. Во втором режиме оболочка решает конкретные задачи пользователя в диалоговом или пакетном режиме. При этом решения выводятся от целей к данным (обратное рассуждение).
Для расширения возможностей оболочки по работе с глубинными знаниями комплекс ЭКО может быть дополнен компонентом К-ЭКО (конкретизатором знаний), который позволяет описывать закономерности в проблемных средах в терминах общих (абстрактных) объектов и правил. К-ЭКО используется на этапе приобретения знаний вместо диалогового редактора оболочки для преобразования общих описаний в конкретные сети вывода, допускающие эффективный вывод решений средствами оболочки ЭКО. Таким образом, использование конкретизатора обеспечивает возможность работы с проблемными средами типа 2.
Третий компонент комплекса - система ИЛИС, позволяющая создавать ЭС в статических проблемных средах за счет индуктивного обобщения данных (примеров) и предназначенная для использования в тех приложениях, где отсутствие правил, отражающих закономерности в проблемной среде, возмещается обширным экспериментальным материалом. Система ИЛИС обеспечивает автоматическое формирование простейших конкретных правил и автономное решение задач на их основе; при этом используется жесткая схема диалога с пользователем. Поскольку при создании реальных приложений эксперты представляют, как правило, и знания о закономерностях в проблемной среде, и экспериментальный материал (для решения частных подзадач), возникает необходимость в использовании правил, сформированных системой ИЛИС, в рамках более сложных средств представления знаний. Комплекс ЭКО обеспечивает автоматический перевод таких правил в формат оболочки ЭКО. В результате удается получить полное (адекватное) представление реальной проблемной среды, кроме того, задать гибкое описание организации взаимодействия ЭС с конечным пользователем.
Традиционные языки программирования
Языки искусственного интеллекта
Это прежде всего Лисп (LISP) и Пролог (Prolog) [8] - наиболее распространенные языки, предназначенные для решения задач искусственного интеллекта. Есть и менее распространенные языки искусственного интеллекта, например РЕФАЛ, разработанный в России. Универсальность этих языков меньшая, нежели традиционных языков, но ее потерю языки искусственного интеллекта компенсируют богатыми возможностями по работе с символьными и логическими данными, что крайне важно для задач искусственного интеллекта. На основе языков искусственного интеллекта создаются специализированные компьютеры (например, Лисп-машины), предназначенные для решения задач искусственного интеллекта. Недостаток этих языков - неприменимость для создания гибридных экспертных систем.
Специальный программный инструментарий
В эту группу программных средств искусственного интеллекта входят специальные инструментарии общего назначения. Как правило, это библиотеки и надстройки над языком искусственного интеллекта Лисп: KEE (Knowledge Engineering Environment), FRL (Frame Representation Language), KRL (Knowledge Represantation Language), ARTS и др. [1,4,7,8,10], позволяющие пользователям работать с заготовками экспертных систем на более высоком уровне, нежели это возможно в обычных языках искусственного интеллекта.
"Оболочки"
Под "оболочками : (shells) понимают "пустые" версии существующих экспертных систем, т.е. готовые экспертные системы без базы знаний. Примером такой оболочки может служить EMYCIN (Empty MYCIN - пустой MYC1N) [8], которая представляет собой незаполненную экспертную систему MYCIN. Достоинство оболочек в том, что они вообще не требуют работы программистов для создания готовой экспертной системы. Требуется только специалисты) в предметной области для заполнения базы знаний. Однако если некоторая предметная область плохо укладывается в модель, используемую в некоторой оболочке, заполнить базу знаний в этом случае весьма не просто.
Технология разработки экспертной системы. Этапы разработки.
Разработка ЭС имеет существенные отличия от разработки обычного программного продукта. Опыт создания ЭС показал, что использование при их разработке методологии, принятой в традиционном программировании, либо чрезмерно затягивает процесс создания ЭС, либо вообще приводит к отрицательному результату.
Использовать ЭС следует только тогда, когда разработка ЭС возможна, оправдана и методы инженерии знаний соответствуют решаемой задаче. Чтобы разработка ЭС была возможной для данного приложения, необходимо одновременное выполнение по крайней мере следующих требований:
1) существуют эксперты в данной области, которые решают задачу значительно лучше, чем начинающие специалисты;
2) эксперты сходятся в оценке предлагаемого решения, иначе нельзя будет оценить качество разработанной ЭС;
3) эксперты способны вербализовать (выразить на естественном языке) и объяснить используемые ими методы, в противном случае трудно рассчитывать на то, что знания экспертов будут "извлечены" и вложены в ЭС;
4) решение задачи требует только рассуждений, а не действий;
5) задача не должна быть слишком трудной (т.е. ее решение должно занимать у эксперта несколько часов или дней, а не недель);
6) задача хотя и не должна быть выражена в формальном виде, но все же должна относиться к достаточно "понятной" и структурированной области, т.е. должны быть выделены основные понятия, отношения и известные (хотя бы эксперту) способы получения решения задачи;
7) решение задачи не должно в значительной степени использовать "здравый смысл" (т.е. широкий спектр общих сведений о мире и о способе его функционирования, которые знает и умеет использовать любой нормальный человек), так как подобные знания пока не удается (в достаточном количестве) вложить в системы искусственного интеллекта.
Приложение соответствует методам ЭС, если решаемая задача обладает совокупностью следующих характеристик:
1) задача может быть естественным образом решена посредством манипуляции с символами (т.е. с помощью символических рассуждений), а не манипуляций с числами, как принято в математических методах и в традиционном программировании;
2) задача должна иметь эвристическую, а не алгоритмическую природу, т.е. ее решение должно требовать применения эвристических правил. Задачи, которые могут быть гарантированно решены (с соблюдением заданных ограничений) с помощью некоторых формальных процедур, не подходят для применения ЭС;
3) задача должна быть достаточно сложна, чтобы оправдать затраты на разработку ЭС. Однако она не должна быть чрезмерно сложной (решение занимает у эксперта часы, а не недели), чтобы ЭС могла ее решать;
4) задача должна быть достаточно узкой, чтобы решаться методами ЭС, и практически значимой.
При разработке ЭС, как правило, используется концепция "быстрого прототипа". Суть этой концепции состоит в том, что разработчики не пытаются сразу построить конечный продукт. На начальном этапе они создают прототип (прототипы) ЭС. Прототипы должны удовлетворять двум противоречивым требованиям: с одной стороны, они должны решать типичные задачи конкретного приложения, а с другой - время и трудоемкость их разработки должны быть весьма незначительны, чтобы можно было максимально запараллелить процесс накопления и отладки знаний (осуществляемый экспертом) с процессом выбора (разработки) программных средств (осуществляемым инженером по знаниям и программистом). Для удовлетворения указанным требованиям, как правило, при создании прототипа используются разнообразные средства, ускоряющие процесс проектирования.
Прототип должен продемонстрировать пригодность методов инженерии знаний для данного приложения. В случае успеха эксперт с помощью инженера по знаниям расширяет знания прототипа о проблемной области. При неудаче может потребоваться разработка нового прототипа или разработчики могут прийти к выводу о непригодности методов ЭС для данного приложения. По мере увеличения знаний прототип может достигнуть такого состояния, когда он успешно решает все задачи данного приложения. Преобразование прототипа ЭС в конечный продукт обычно приводит к перепрограммированию ЭС на языках низкого уровня, обеспечивающих как увеличение быстродействия ЭС, так и уменьшение требуемой памяти. Трудоемкость и время создания ЭС в значительной степени зависят от типа используемого инструментария.
Технология их разработки ЭС, включает в себя шесть этапов (рис.5): этапы идентификации, концептуализации, формализации, выполнения, тестирования, опытной эксплуатации. Рассмотрим более подробно последовательности действий, которые необходимо выполнить на каждом из этапов.
1) На этапе идентификации необходимо выполнить следующие действия:
определить задачи, подлежащие решению и цели разработки,
определить экспертов и тип пользователей.
2)На этапе концептуализации:
проводится содержательный анализ предметной области,
выделяются основные понятия и их взаимосвязи,
определяются методы решения задач.
3) На этапе формализации:
выбираются программные средства разработки ЭС,
определяются способы представления всех видов знаний,
формализуются основные понятия.
4) На этапе выполнения (наиболее важном и трудоёмком) осуществляется наполнение экспертом БЗ, при котором процесс приобретения знаний разделяют:
на "извлечение" знаний из эксперта,
на организацию знаний, обеспечивающую эффективную работу ЭС,
на представление знаний в виде, понятном для ЭС.
Процесс приобретения знаний осуществляется инженером по знаниям на основе деятельности эксперта.
5) На этапе тестирования эксперт и инженер по знаниям с использованием диалоговых и объяснительных средств проверяют компетентность ЭС. Процесс тестирования продолжается до тех пор, пока эксперт не решит, что система достигла требуемого уровня компетентности.
6) На этапе опытной эксплуатации проверяется пригодность ЭС для конечных пользователей. По результатам этого этапа возможна существенная модернизация ЭС.
Процесс создания ЭС не сводится к строгой последовательности этих этапов, так как в ходе разработки приходится неоднократно возвращаться на более ранние этапы и пересматривать принятые там решения.