

Эмпирическое корреляционное отношение (эко)
На основании правила сложения дисперсий вычисляется эмпирическое корреляционное отношение (ЭКО), которое равно квадратному корню из отношения межгрупповой дисперсии к общей. Такой порядок вычисления обусловлен разложением общей вариации на вариацию, зависящую от фактора, положенного в основу группировки (в нашем примере – повышение и неповышение квалификации), которая численно равна межгрупповой дисперсии, и общую вариацию.
Межгрупповая дисперсия составляет часть общей дисперсии и складывается под влиянием только одного группировочного фактора. Именно поэтому подкоренное выражение показывает долю вариации за счет группировочного признака.
ЭКО изменяется в переделах от нуля до единицы. Чем ближе его значение к единице, тем большая доля вариации падает на группировочный признак
Коэффициент детерминации (R2)— это квадрат множественного коэффициента корреляции. Он показывает, какая доля дисперсии результативного признака объясняется влиянием независимых переменных.
Формула для вычисления коэффициента детерминации:
![]()
де yi — выборочные данные, а fi — соответствующие им значения модели.
Также это квадрат корреляции Пирсона между двумя переменными. Он выражает количество дисперсии, общей между двумя переменными.
Коэффициент принимает значения из интервала [0;1]. Чем ближе значение к 1 тем ближе модель к эмпирическим наблюдениям.
В случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции, то есть R2 = r2.
Коэффициент детерминации показывает долю вариации результата Υ, обуславливаемую вариацией фактора Χ
Иногда показателям тесноты связи можно дать качественную оценку (шкала Чеддока):
Количественная мера тесноты связи Качественная характеристика силы связи
0,1 - 0,3 Слабая
0,3 - 0,5 Умеренная
0,5 - 0,7 Заметная
0,7 - 0,9 Высокая
0,9 - 0,99 Весьма высокая
Функциональная связь возникает при значении равном 1, а отсутствие связи — 0. При значениях показателей тесноты связи меньше 0,7 величина коэффициента детерминации всегда будет ниже 50 %. Это означает, что на долю вариации факторных признаков приходится меньшая часть по сравнению с остальными неучтенными в модели факторами, влияющими на изменение результативного показателя. Построенные при таких условиях регрессионные модели имеют низкое практическое значение.
22) Ряды распределения и их анализ при помощи показателей асимметрии и эксцесса
Важнейшей частью статистического анализа является построение рядов распределения (структурной группировки) с целью выделения характерных свойств и закономерностей изучаемой совокупности. В зависимости от того, какой признак (количественный или качественный) взят за основу группировки данных, различают соответственно типы рядов распределения.
Если за основу группировки взят качественный признак, то такой ряд распределения называют атрибутивным (распределение по видам труда, по полу, по профессии, по религиозному признаку, национальной принадлежности и т.д.).
Если ряд распределения построен по количественному признаку, то такой ряд называют вариационным. Построить вариационный ряд - значит упорядочить количественное распределение единиц совокупности по значениям признака, а затем подсчитать числа единиц совокупности с этими значениями (построить групповую таблицу).
Выделяют три формы вариационного ряда: ранжированный ряд, дискретный ряд и интервальный ряд.
Ранжированный ряд - это распределение отдельных единиц совокупности в порядке возрастания или убывания исследуемого признака. Ранжирование позволяет легко разделить количественные данные по группам, сразу обнаружить наименьшее и наибольшее значения признака, выделить значения, которые чаще всего повторяются.
Другие формы вариационного ряда - групповые таблицы, составленные по характеру вариации значений изучаемого признака. По характеру вариации различают дискретные (прерывные) и непрерывные признаки.
Дискретный ряд - это такой вариационный ряд, в основу построения которого положены признаки с прерывным изменением (дискретные признаки). К последним можно отнести тарифный разряд, количество детей в семье, число работников на предприятии и т.д. Эти признаки могут принимать только конечное число определенных значений.
Дискретный вариационный ряд представляет таблицу, которая состоит из двух граф. В первой графе указывается конкретное значение признака, а во второй - число единиц совокупности с определенным значением признака.
Если признак имеет непрерывное изменение (размер дохода, стаж работы, стоимость основных фондов предприятия и т.д., которые в определенных границах могут принимать любые значения), то для этого признака нужно строить интервальный вариационный ряд.
Групповая таблица здесь также имеет две графы. В первой указывается значение признака в интервале «от - до» (варианты), во второй - число единиц, входящих в интервал (частота).
Частота (частота повторения) - число повторений отдельного варианта значений признака, обозначается fi , а сумма частот, равная объему исследуемой совокупности, обозначается
![]()
где k - число вариантов значений признака
Очень часто таблица дополняется графой, в которой подсчитываются накопленные частоты S, которые показывают, какое количество единиц совокупности имеет значение признака не большее, чем данное значение.
Частоты ряда f могут заменяться частостями w, выраженными в относительных числах (долях или процентах). Они представляют собой отношения частот каждого интервала к их общей сумме, т.е.:
![]()
![]()
При построении вариационного ряда с интервальными значениями прежде всего необходимо установить величину интервала i, которая определяется как отношение размаха вариации R к числу групп m:
![]()
где R = xmax - xmin ; m = 1 + 3,322 lgn (формула Стерджесса); n - общее число единиц совокупности
23) Понятие о закономерностях распределения. Эмпирическое и теоретическое распределение. Кривые распределения. Схема анализа эмпирического распределения
24) Нормальное распределение. Построение кривой нормального распределения по эмпирическим данным. Правила «трех сигма»
Любая случайная величина имеет функцию распределения - зависимость плотности вероятности от значения случайной величины. Для нормального распределения (распределения Гаусса) функция распределения имеет следующий вид:
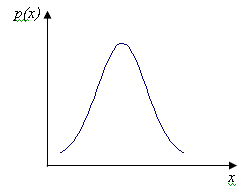
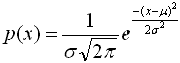
- матожидание (генеральное среднее)
- стандартное отклонение
Для проведения статистических расчетов часто необходимо располагать информацией о виде функции распределения.
Центральная предельная теорема Чебышева: Если случайная величина подвержена воздействию бесконечного числа бесконечно малых случайных факторов, то она имеет нормальное распределение.
Как правило, для аналитических измерений условие теоремы выполняется, поэтому для результатов химического анализа обычно постулируется нормальное распределение.
Нарушения нормального закона распределения:
1) Нарушаются условия теоремы (выделяется более весомая группа факторов). Например: анализ высокочистых веществ - неравномерное распределение примесей.
2) Произвольное объединение нескольких выборок (даже если каждая из них подчинялась распределению Гаусса):
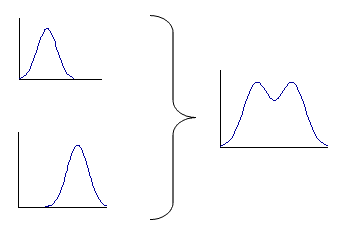
3) Косвенные измерения. Линейная комбинация нормально распределенных случайных величин также будет подчиняться нормальному распределению. А нелинейная комбинация (например, произведение двух величин) не сохранит нормального распределения. Однако, чем меньше погрешность, тем меньше отличие от нормального распределения, поэтому даже для нелинейных преобразований в некоторых случаях можно принять нормальное распределение.
4) Результат измерения является дискретной величиной (например, некоторые радиоактивационные методы анализа, ряд биохимических и рентгеноспектральных методов - так называемые счетные методы). В этом случае результат измерения подчиняется распределению Пуассона. Однако при больших распределение Пуассона переходит в нормальное распределение. (Примечание: формально любой результат измерения является дискретным - потому, что шкала прибора имеет дискретный набор делений, и результат округляется до ближайшего деления. Однако если измеряемый сигнал много больше цены деления, то результат подчиняется нормальному распределению).
Что делать, если результат не подчиняется нормальному распределению?
1) Возможно, нормальное распределение выполняется приблизительно и можно применять критерии для нормального распределения.
2) Если известен закон распределения
(например, распределение Пуассона), то
можно пользоваться критериями этого
распределения. (Например, для сравнения
двух нормально распределенных случайных
величин используется критерий Стьюдента
- см. Лекцию 4. Дисперсия рассчитывается
нелинейным преобразованием, и подчиняется
-
![]() распределению (хи-квадрат распределение
или распределение Фишера). Для сравнения
двух дисперсий используется критерий
Фишера.
распределению (хи-квадрат распределение
или распределение Фишера). Для сравнения
двух дисперсий используется критерий
Фишера.
3) Если распределение неизвестно, то на этот случай существуют непараметрические критерии. Например, сравнение двух средних на основе расчета числа возможных перестановок внутри объединенной выборки.
25) Оценка близости эмпирического и теоретического распределений при помощи критериев согласия: критерий пирсона «хи-квадрат», критерий романовского, критерий колмогорова.
Для оценки близости эмпирических и теоретических частот применяются критерий согласия Пирсона, критерий согласия Романовского, критерий согласия Колмогорова.
Наиболее распространенным является
критерий согласия К. Пирсона ,
![]() который можно представить как сумму
отношений квадратов расхождений между
f' и f к теоретическим частотам:
который можно представить как сумму
отношений квадратов расхождений между
f' и f к теоретическим частотам:
![]()
Вычисленное значение критерия
![]() необходимо сравнить с табличным
(критическим) значением
необходимо сравнить с табличным
(критическим) значением
![]() . Табличное значение определяется по
специальной таблице, оно зависит от
принятой вероятности Р и числа степеней
свободы k (при этом k = m - 3, где m - число
групп в ряду распределения для нормального
распределения). При расчете критерия
согласия Пирсона должно соблюдаться
следующее условие: достаточно большим
должно быть число наблюдений (n 50), при
этом если в некоторых интервалах
теоретические частоты < 5, то интервалы
объединяют для условия > 5.
. Табличное значение определяется по
специальной таблице, оно зависит от
принятой вероятности Р и числа степеней
свободы k (при этом k = m - 3, где m - число
групп в ряду распределения для нормального
распределения). При расчете критерия
согласия Пирсона должно соблюдаться
следующее условие: достаточно большим
должно быть число наблюдений (n 50), при
этом если в некоторых интервалах
теоретические частоты < 5, то интервалы
объединяют для условия > 5.
Если
![]() ,
то расхождения между эмпирическими и
теоретическими частотами распределения
могут быть случайными и предположение
о близости эмпирического распределения
к нормальному не может быть отвергнуто.
,
то расхождения между эмпирическими и
теоретическими частотами распределения
могут быть случайными и предположение
о близости эмпирического распределения
к нормальному не может быть отвергнуто.
В том случае, если отсутствуют таблицы для оценки случайности расхождения теоретических и эмпирических частот, можно использовать критерий согласия В.И. Романовского КРом , который, используя величину , предложил оценивать близость эмпирического распределения кривой нормального распределения при помощи отношения
![]()
где m - число групп; k = (m - 3 ) - число степеней свободы при исчислении частот нормального распределения.
Если вышеуказанное отношение < 3, то расхождения эмпирических и теоретических частот можно считать случайными, а эмпирическое распределение - соответствующим нормальному. Если отношение > 3, то расхождения могут быть достаточно существенными и гипотезу о нормальном распределении следует отвергнуть.
Критерий согласия А.Н. Колмогорова
![]() используется при определении максимального
расхождения между частотами эмпирического
и теоретического распределения,
вычисляется по формуле
используется при определении максимального
расхождения между частотами эмпирического
и теоретического распределения,
вычисляется по формуле
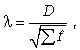
где D - максимальное значение разности
между накопленными эмпирическими и
теоретическими частотами;
![]() - сумма эмпирических частот.
- сумма эмпирических частот.
По таблицам значений вероятностей -критерия можно найти величину , соответствующую вероятности Р. Если величина вероятности Р значительна по отношению к найденной величине , то можно предположить, что расхождения между теоретическим и эмпирическим распределениями несущественны.
Необходимым условием при использовании критерия согласия Колмогорова является достаточно большое число наблюдений (не меньше ста).
26) Понятие о корреляционной зависимости. Виды взаимосвязей
Если же исследуется связь между случайными
величинами
![]() и
и
![]() ,
то говорить о функциональной зависимости,
как правило, не приходится. Действительно,
если в качестве независимой переменной
положить, например,
,
то сама по себе эта переменная уже
принимает не единственное значение, а
целый спектр значений, причем — случайным
образом. Далее — каждому значению
переменной
отвечает опять-таки некоторый спектр
из числа возможных значений переменной
, причем, заранее невозможно сказать,
какое именно значение эта переменная
примет.
,
то говорить о функциональной зависимости,
как правило, не приходится. Действительно,
если в качестве независимой переменной
положить, например,
,
то сама по себе эта переменная уже
принимает не единственное значение, а
целый спектр значений, причем — случайным
образом. Далее — каждому значению
переменной
отвечает опять-таки некоторый спектр
из числа возможных значений переменной
, причем, заранее невозможно сказать,
какое именно значение эта переменная
примет.
В этом случае можно говорить лишь о корреляционной зависимости между переменными и , которая понимается в том смысле, что значение, которое принимает одна из переменных, оказывает влияние на значение, которое принимает вторая из них, причем это влияние можно оценить лишь вероятностно.
Наиболее простым вариантом корреляционной зависимости является парная корреляция, т.е. зависимость между двумя признаками (результативным и факторным или между двумя факторными). Математически эту зависимость можно выразить как зависимость результативного показателя у от факторного показателя х. Связи могут быть прямые и обратные. В первом случае с увеличением признака х увеличивается и признак у, при обратной связи с увеличением признака х уменьшается признак у.
Могут иметь место различные формы связи:
Прямолинейная
![]()
криволинейная в виде:
параболы второго порядка (или высших порядков)
![]()
гиперболы
![]() и тд
и тд
27) Нахождение уравнения связи ( уравнения регрессии)
Уравнение регрессии. Прямая линия на плоскости (в пространстве двух измерений) задается уравнением Y=a+b*X; более подробно: переменная Y может быть выражена через константу (a) и угловой коэффициент (b), умноженный на переменную X. Константу иногда называют также свободным членом, а угловой коэффициент - регрессионным или B-коэффициентом. Например, значение GPA можно лучше всего предсказать по формуле 1+.02*IQ. Таким образом, зная, что коэффициент IQ у студента равен 130, вы могли бы предсказать его показатель успеваемости GPA, скорее всего, он близок к 3.6 (поскольку 1+.02*130=3.6).
В многомерном случае, когда имеется более одной независимой переменной, линия регрессии не может быть отображена в двумерном пространстве, однако она также может быть легко оценена. Например, если в дополнение к IQ вы имеете другие предикторы успеваемости (например, Мотивация, Самодисциплина), вы можете построить линейное уравнение, содержащее все эти переменные. Тогда, в общем случае, процедуры множественной регрессии будут оценивать параметры линейного уравнения вида:
Y = a + b1*X1 + b2*X2 + ... + bp*Xp
28) Определения параметров уравнения регрессии для различных форм связи
Параметры для всех этих уравнений связи, как правило, определяют из системы нормальных уравнений, которые должны отвечать требованию метода наименьших квадратов (МНК):
![]()
![]()
Если связь выражена параболой второго
порядка (![]() ),
то систему нормальных уравнений для
отыскания параметров a0 , a1 , a2 (такую
связь называют множественной, поскольку
она предполагает зависимость более чем
двух факторов) можно представть в виде
),
то систему нормальных уравнений для
отыскания параметров a0 , a1 , a2 (такую
связь называют множественной, поскольку
она предполагает зависимость более чем
двух факторов) можно представть в виде
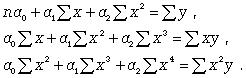
29) Показатели тесноты связи и их интерпретация: линейный коэффициент корреляции, коэффициент детерминации, коэффициент эластичности, теоретическое корреляционное отношение, теоретический коэффициент детерминации
Для определения степени тесноты парной линейной зависимости служит линейный коэффициент корреляции r, для расчета которого можно использовать, например, две следующие формулы:
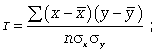
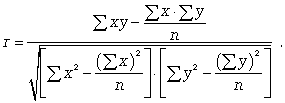
Линейный коэффициент корреляции может принимать значения в пределах от -1 до + 1 или по модулю от 0 до 1. Чем ближе он по абсолютной величине к 1, тем теснее связь. Знак указывает направление связи: «+» - прямая зависимость, «-» имеет место при обратной зависимости.
Коэффициент детерминации, называемый также коэффициентом смешанной корреляции или статистикой R2, - статистический показатель, отражающий объясняющую способность уравнения регрессии и представляющий собой отношение суммы квадратов регрессии SSR к общей вариации SST:
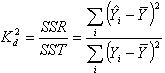
где
![]() – уровень ряда,
– уровень ряда,
![]() – смоделированное значение,
– смоделированное значение,
![]() – среднее по всем уровням ряда.
– среднее по всем уровням ряда.
Данный показатель является статистической мерой согласия, с помощью которой можно определить, насколько уравнение регрессии соответствует реальным данными.
Коэффициент детерминации изменяется в диапазоне от 0 до 1. Если он равен 0, это означает, что связь между переменными регрессионной модели отсутствует и вместо регрессионной модели для оценки значения выходной переменной можно с таким же успехом использовать простое среднее ее наблюдаемых значений. Напротив, если коэффициент детерминации равен 1, это соответствует идеальной модели, когда все точки наблюдений лежат точно на линии регрессии, т.е. сумма квадратов их отклонений равна 0. На практике, если коэффициент детерминации близок 1, это указывает на то, что модель работает очень хорошо (имеет высокую значимость). Близость коэффициента детерминации к 0 показывает низкую значимость модели, когда входная переменная плохо "объясняет" поведение выходной, т.е. линейная зависимость между ними отсутствует. Очевидно, что такая модель будет иметь низкую эффективность
КОЭФФИЦИЕНТ ЭЛАСТИЧНОСТИ
Коэффициент, показывающий процент изменения результативного признака (например, темпа роста индекса стоимости СМР) при изменении факторного признака (элемента затрат) на 1%.
30) непараметрические методы измерения взаимосвязей: коэффициенты Фехнера, Спримена, Кендэлла.
Наконец, следует упомянуть коэффициент Фехнера, характеризующий элементарную степень тесноты связи, который целесообразно использовать для установления факта наличия связи, когда существует небольшой объем исходной информации. Данный коэффициент определяется по формуле
![]()
где na - количество совпадений знаков отклонений индивидуальных величин от их средней арифметической; nb - соответственно количество несовпадений.
Коэффициент Фехнера может изменяться в пределах -1,0 Кф +1,0.
Коэффициент корреляции рангов Спирмэна (р) основан на рассмотрении разности рангов значений результативного и факторного признаков и может быть рассчитан по формуле

где d = Nx - Ny , т.е. разность рангов каждой пары значений х и у; n - число наблюдений.
Ранговый коэффициент корреляции Кендэла
(![]() )
можно определить по формуле
)
можно определить по формуле
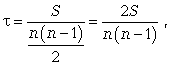
где S = P + Q.
31) Статистическое изучение зависимостей между качественными показателями с помощью коэф. Контингенции и ассоциации
К непараметрическим методам исследования можно отнести коэффициент ассоциации Кас и коэффициент контингенции Ккон , которые используются, если, например, необходимо исследовать тесноту зависимости между качественными признаками, каждый из которых представлен в виде альтернативных признаков.
Для определения этих коэффициентов создается расчетная таблица (таблица «четырех полей»), где статистическое сказуемое схематически представлено в следующем виде:
Признаки А (да) А (нет) Итого
В (да) a b a + b
В (нет) с d c + d
Итого a + c b + d n
Здесь а, b, c, d - частоты взаимного сочетания
(комбинации) двух альтернативных
признаков
![]() ;
n - общая сумма частот.
;
n - общая сумма частот.
Коэффициент ассоциации можно расcчитать по формуле
![]()
Коэффициент контингенции рассчитывается по формуле
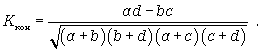
Нужно иметь в виду, что для одних и тех же данных коэффициент контингенции (изменяется от -1 до +1) всегда меньше коэффициента ассоциации.
32) Статистическое изучение зависимостей между качественными показателями при помощи коэффициентов Пирсона и Чупрова
Коэффициент взаимной сопряженности Пирсона определяется по формуле
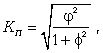
где
![]() - показатель средней квадратической
сопряженности:
- показатель средней квадратической
сопряженности:
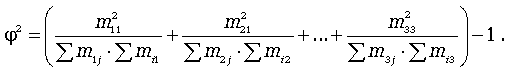
Коэффициент взаимной сопряженности изменяется от 0 до 1.
Коэффициент Чупрова измеряет взаимосвязь качественных неальтернативных признаков, измеренных по номинальной шкале. Подсчитывается по формуле:
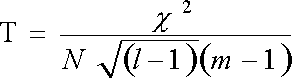
¯хи – квадрат, коэффициент квадратической сопряженности
l, m - число граф и строк в составленной таблице сопряженности признаков
N - общее число объектов в изучаемой совокупности
33) Понятие о множественной корреляции. Линейное уравнение множественной регрессии. Множественный коэффициенты корреляции, их интерпретация
М. к. — метод многомерного анализа, широко применяемый в психологии и др. поведенческих науках. М. к. можно рассматривать как расширение двумерной корреляции, а ее коэффициент — как показатель степени связи одной переменной с оптимально взвешенной комбинацией неск. др. переменных. Веса этих переменных определяются методом наименьших квадратов, так чтобы минимизировать остаточную дисперсию.
Коэффициент М. к. принимает значения от 0 до 1 и интерпретируется аналогично коэффициенту двумерной корреляции, если справедливы допущения о прямолинейности и др. характеристиках двумерных интеркорреляций, на основе к-рых вычисляется этот коэффициент.
В общем случае, процедура множественной регрессии оценивает линейное уравнение в виде:
Y = b0 + b1X1 + b2X2 + ... + bkXk,
где k - число предикторов. Отметим, что в этом уравнении регрессионные коэффициенты ( b1 ... bk) представляют независимые вклады каждой независимой переменной в предсказание зависимой переменной. Иначе, можно сказать, что переменная X1 коррелирована с переменной Y при условии, что все другие независимые переменные фиксированы. Этот тип корреляции называется частная корреляция
34) парные и частные коэффициенты корреляции, их интерпритация
35) Понятие о рядах динамики и их виды.
Ряд динамики, хронологический ряд, динамический ряд, временной ряд – это последовательность упорядоченных во времени числовых показателей, характеризующих уровень развития изучаемого явления. Всякий ряд динамики включает, следовательно, два обязательных элемента: во-первых, время и, во-вторых, конкретное значение показателя, или уровень ряда. Ряды динамики различаются по следующим признакам.
1. По времени – моментные и интервальные ряды. Интервальный ряд динамики – последовательность, в которой уровень явления относится к результату, накопленному или вновь произведенному за определенный интервал времени. Таковы, например, ряды показателей объема продукции по месяцам года, количества отработанных человеко-дней по отдельным периодам и т.д. Если же уровень ряда показывает фактическое наличие изучаемого явления в конкретный момент времени, то совокупность уровней образует моментный ряд динамики. Примерами моментных рядов могут быть последовательности показателей численности населения на начало года, величины запаса какого-либо материала на начало периода и т.д. Важное аналитическое отличие моментных рядов от интервальных состоит в том, что сумма уровней интервального ряда дает вполне реальный показатель – общий выпуск продукции за год, общие затраты рабочего времени, общий объем продаж акций и т.д., сумма же уровней моментного ряда, хотя иногда и подсчитывается, но реального содержания, как правило, не имеет.
2. По форме представления уровней – ряды абсолютных, относительных и средних величин.
3. По расстоянию между датами или интервалам времени выделяют полные и неполные хронологические ряды.
Полные ряды динамики имеют место, когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами. Это равноотстоящие ряды динамики. Неполные – когда принцип равных интервалов не соблюдается.
Чтобы о развитии явления можно было получить представление при помощи числовых уровней, при составлении ряда динамики должны приводиться в сопоставительный вид.
Статистические данные должны быть сопоставимы по территории, кругу охватываемых объектов, единицам измерения, времени регистрации, ценам, методологии расчета. Сопоставимость по территории означает, что данные по странам и регионам, границы которых изменились, должны быть пересчитаны в старых пределах. Сопоставимость по кругу охватываемых объектов означает сравнение совокупностей с равным числом элементов. Территориальная и объемная сопоставимость обеспечивается смыканием рядов динамики, при этом либо абсолютные уровни заменяются относительными, либо делается пересчет в условные абсолютные уровни. Не возникает особых сложностей при обеспечении сопоставимости данных по единицам измерения; стоимостная сравнимость достигается системой сопоставимых цен.
Числовые уровни рядов динамики должны быть упорядоченными во времени. Не допускается анализ рядов с пропусками отдельных уровней, если же такие пропуски неизбежны, то их восполняют условными расчетными значениями.
36). Аналитические показатели ряда динамики.
Абсолютный прирост выражает абсолютную скорость изменения ряда динамики и определяется как разность между данным уровнем и уровнем, принятым за базу сравнения.
Абсолютный прирост (базисный)
![]()
где yi - уровень сравниваемого периода; y0 - уровень базисного периода.
Абсолютный прирост с переменной базой (цепной), который называют скоростью роста,
![]()
где yi - уровень сравниваемого периода; yi-1 - уровень предшествующего периода.
Коэффициент роста Ki определяется как отношение данного уровня к предыдущему или базисному, показывает относительную скорость изменения ряда. Если коэффициент роста выражается в процентах, то его называют темпом роста.
Коэффициент роста базисный
![]()
Коэффициент роста цепной
![]()
Темп роста
![]()
Темп прироста ТП определяется как отношение абсолютного прироста данного уровня к предыдущему или базисному.
Темп прироста базисный
![]()
Темп прироста цепной
![]()
емп прироста можно рассчитать и иным путем: как разность между темпом роста и 100 % или как разность между коэффициентом роста и 1 (единицей):
Тп = Тр - 100%; 2) Тп = Ki - 1. (9.8)
Абсолютное значение одного процента прироста Ai . Этот показатель служит косвенной мерой базисного уровня. Представляет собой одну сотую часть базисного уровня, но одновременно представляет собой и отношение абсолютного прироста к соответствующему темпу роста.
Данный показатель рассчитывают по формуле
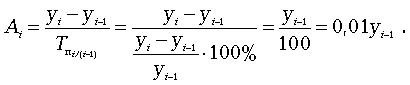
Для характеристики динамики изучаемого явления за продолжительный период рассчитывают группу средних показателей динамики. Можно выделить две категории показателей в этой группе: а) средние уровни ряда; б) средние показатели изменения уровней ряда.
37) средние показатели рядов динамики
Средние уровни ряда рассчитываются в зависимости от вида временного ряда.
Для интервального ряда динамики абсолютных показателей средний уровень ряда рассчитывается по формуле простой средней арифметической:
![]()
где n - число уровней ряда.
Для моментного динамического ряда средний уровень определяется следующим образом.
Средний уровень моментного ряда с равными интервалами рассчитывается по формуле средней хронологической:
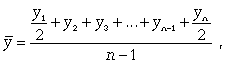
где n - число дат.
Средний уровень моментного ряда с неравными интервалами рассчитывается по формуле средней арифметической взвешенной, где в качестве весов берется продолжительность промежутков времени между временными моментами изменений в уровнях динамического ряда:
![]()
где t - продолжительность периода (дни, месяцы), в течение которого уровень не изменялся.
Средний абсолютный прирост (средняя скорость роста) определяется как средняя арифметическая из показателей скорости роста за отдельные периоды времени:
![]()
![]()
где yn - конечный уровень ряда; y1 - начальный уровень ряда.
Средний коэффициент роста (![]() )
рассчитывается по формуле средней
геометрической из показателей
коэффициентов роста за отдельные
периоды:
)
рассчитывается по формуле средней
геометрической из показателей
коэффициентов роста за отдельные
периоды:
![]()
где Кр1 , Кр2 , ..., Кр n-1 - коэффициенты роста по сравнению с предыдущим периодом; n - число уровней ряда.
Средний коэффициент роста можно определить иначе:
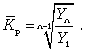
Средний темп роста, %. Это средний коэффициент роста, который выражается в процентах:
![]()
Средний темп прироста
![]() ,
%. Для расчета данного показателя
первоначально определяется средний
темп роста, который затем уменьшается
на 100%. Его также можно определить, если
уменьшить средний коэффициент роста
на единицу:
,
%. Для расчета данного показателя
первоначально определяется средний
темп роста, который затем уменьшается
на 100%. Его также можно определить, если
уменьшить средний коэффициент роста
на единицу:
![]()
Среднее абсолютное значение 1% прироста можно рассчитать по формуле

38) определение среднего уровня ряда динамики для различных видов рядов
Средние уровни ряда рассчитываются в зависимости от вида временного ряда.
Для интервального ряда динамики абсолютных показателей средний уровень ряда рассчитывается по формуле простой средней арифметической:
где n - число уровней ряда.
Для моментного динамического ряда средний уровень определяется следующим образом.
Средний уровень моментного ряда с равными интервалами рассчитывается по формуле средней хронологической:
где n - число дат.
Средний уровень моментного ряда с неравными интервалами рассчитывается по формуле средней арифметической взвешенной, где в качестве весов берется продолжительность промежутков времени между временными моментами изменений в уровнях динамического ряда:
где t - продолжительность периода (дни, месяцы), в течение которого уровень не изменялся.
39) Основные методы обработки и анализа рядов динамики: метод укрепления интервалов, метод скользяшей средней, аналитическое выравнивание рядов динамики.
В ходе обработки динамического ряда важнейшей задачей является выявление основной тенденции развития явления (тренда) и сглаживание случайных колебаний. Для решения этой задачи в статистике существуют особые способы, которые называют методами выравнивания.
Выделяют три основных способа обработки динамического ряда:
а) укрупнение интервалов динамического ряда и расчет средних для каждого укрупненного интервала;
б) метод скользящей средней;
в) аналитическое выравнивание (выравнивание по аналитическим формулам).
Укрупнение интервалов - наиболее простой способ. Он заключается в преобразовании первоначальных рядов динамики в более крупные по продолжительности временных периодов, что позволяет более четко выявить действие основной тенденции (основных факторов) изменения уровней.
По интервальным рядам итоги исчисляются путем простого суммирования уровней первоначальных рядов. Для других случаев расcчитывают средние величины укрупненных рядов (переменная средняя). Переменная средняя рассчитывается по формулам простой средней арифметической.
Скользящая средняя - это такая динамическая средняя, которая последовательно рассчитывается при передвижении на один интервал при заданной продолжительности периода. Если, предположим, продолжительность периода равна 3, то скользящие средние рассчитываются следующим образом:
![]()
![]()
![]()
При четных периодах скользящей средней можно центрировать данные, т.е. определять среднюю из найденных средних. К примеру, если скользящая исчисляется с продолжительностью периода, равной 2, то центрированные средние можно определить так:
![]()
![]()
![]()
Первую рассчитанную центрированную относят ко второму периоду, вторую - к третьему, третью - к четвертому и т.д. По сравнению с фактическим сглаженный ряд становится короче на (m - 1)/2, где m - число уровней интервала.
Важнейшим способом количественного выражения общей тенденции изменения уровней динамического ряда является аналитическое выравнивание ряда динамики, которое позволяет получить описание плавной линии развития ряда. При этом эмпирические уровни заменяются уровнями, которые рассчитываются на основе определенной кривой, где уравнение рассматривается как функция времени. Вид уравнения зависит от конкретного характера динамики развития. Его можно определить как теоретически, так и практически. Теоретический анализ основывается на рассчитанных показателях динамики. Практический анализ - на исследовании линейной диаграммы.
Задачей аналитического выравнивания является определение не только общей тенденции развития явления, но и некоторых недостающих значений как внутри периода, так и за его пределами. Способ определения неизвестных значений внутри динамического ряда называют интерполяцией. Эти неизвестные значения можно определить:
1) используя полусумму уровней, расположенных рядом с интерполируемыми;
2) по среднему абсолютному приросту;
3) по темпу роста.
Способ определения количественных значений за пределами ряда называют экстраполяцией. Экстраполирование используется для прогнозирования тех факторов, которые не только в прошлом и настоящем обусловливают развитие явления, но и могут оказать влияние на его развитие в будущем.
Экстраполировать можно по средней арифметической, по среднему абсолютному приросту, по среднему темпу роста.
При аналитическом выравнивании может иметь место автокорреляция, под которой понимается зависимость между соседними членами динамического ряда. Автокорреляцию можно установить с помощью перемещения уровня на одну дату. Коэффициент автокорреляции вычисляется по формуле
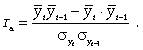
Автокорреляцию в рядах можно устранить, коррелируя не сами уровни, а так называемые остаточные величины (разность эмпирических и теоретических уровней). В этом случае корреляцию между остаточными величинами можно определить по формуле
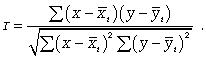
Анализ рядов динамики предполагает и исследование сезонной неравномерности (сезонных колебаний), под которыми понимают устойчивые внутригодовые колебания, причиной которых являются многочисленные факторы, в том числе и природно-климатические. Сезонные колебания измеряются с помощью индексов сезонности, которые рассчитываются двумя способами в зависимости от характера динамического развития.
При относительно неизменном годовом уровне явления индекс сезонности можно рассчитать как процентное отношение средней величины из фактических уровней одноименных месяцев к общему среднему уровню за исследуемый период:
![]()
В условиях изменчивости годового уровня индекс сезонности определяется как процентное отношение средней величины из фактических уровней одноименных месяцев к средней величине из выровненных уровней одноименных месяцев:
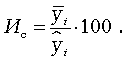
40) Способы определения формы тренда при аналитическом выравнивании рядов динамики.
Первая задача, которая возникает при анализе рядов динамики,
заключается в выявлении и описании основной тенденции развития
изучаемого явления (тренда).
Трендом называется плавное и устойчивое изменение
уровней явления во времени, свободное от случайных колебаний.
Изучение тренда включает в себя два этапа:
1. Проверка ряда на наличие тренда;
2. Выравнивание ряда динамики и непосредственное выделение
тренда.
Проверка ряда на наличие тренда проводится разными методами,
самым простым из которых является метод средних. Суть его заключается
в следующем: изучаемый ряд динамики разбивается на несколько
интервалов (чаще всего на два), для каждого из которых определяется
средняя величина - y и y . Выдвигается гипотеза о существенном
различии средних. Если выдвинутая гипотеза принимается, то признается
наличие тренда.
Для непосредственного выявления тренда используют следующие
методы:
• метод укрупнения интервалов;
• метод скользящей средней;
• метод аналитического выравнивания.
Все перечисленные методы относятся к группе методов
сглаживания, предполагающих наличие в исходном ряду динамики только
одной компоненты – тренда.