

24. Алгоритм заполнения таблиц разбора для slr (1) анализатора.
Таблица action в зависимости от пары <входной сигнал, состояние> определяет, достигнут ли конец основы. Если конец основы достигнут, то выполняется приведение, в противном случае выполняется сдвиг.
Таблица goto в зависимости от пары <нетерминал в вершине стека, состояние> определяет состояние конечного автомата после выполнения приведения.
Алгоритм заполнения таблиц анализа заключается в следующем.
1. Построить каноническую совокупность множества ситуаций.
2. Каждое множество I канонической совокупности определяет состояние конечного автомата с соответствующим номером, а следовательно, строку в таблицах анализа. Ячейки в таблице заполняются по следующим вариантам:
а) если ситуация [Aa] принадлежит множеству Ii и существует переход по терминалу a в некоторое множество Ij, то в ячейку action[i, a] заносим значение shift j. В приведенной ситуации основа не может быть найдена, так как для ее завершения как минимум необходимо распознать терминал a, то есть выполнить сдвиг;
б) если ситуация [A] принадлежит множеству Ii, то для всех терминалов а, принадлежащих follow(A), в ячейку action[i, a] заносим значение reduce A. Это происходит потому, что основа найдена полностью и распознавание любого символа, следующего за А, должно повлечь приведение основы;
в) если ситуация [SS] принадлежит множеству Ii, то есть можно осуществить редукцию для стартовой продукции, то в ячейку action[I, eof] записываем значение accept. Разбор успешно закончен, если достигнут конец входной последовательности.
3. Если существует переход из множества Ii во множество Ij по некоторому нетерминалу А, то в ячейку goto[i, А] заносим значение j.
4. Все незаполненные ячейки в таблицах action и goto заполняем значением «ошибка».
5. Начальным состоянием автомата является состояние, содержащее ситуацию [SS].
28. Построение абстрактного синтаксического дерева.
Транслятор на основе текста программы формирует некоторый промежуточный код. Этот код м.б. абстрактным синтаксическим деревом (АСД).
А![]() СД
– это абстрактное представление
конструкций языка, полученное из дерева
разбора. Обычно в АСД ключевые слова и
операторы не представляются в качестве
листьев,
они связываются
с внутренним узлом, который выступает
в дереве разбора родительским для этих
листьев. Другое упрощение, используемое
в синтаксических деревьях, заключатся
в том, что цепочка для одиночных продукций
могут быть свернуты так:
СД
– это абстрактное представление
конструкций языка, полученное из дерева
разбора. Обычно в АСД ключевые слова и
операторы не представляются в качестве
листьев,
они связываются
с внутренним узлом, который выступает
в дереве разбора родительским для этих
листьев. Другое упрощение, используемое
в синтаксических деревьях, заключатся
в том, что цепочка для одиночных продукций
могут быть свернуты так:
Также АСД - это абстрактное представление конструкции языка, полученное из дерева разбора. В этом дереве есть инф-ция, необходимая для распознавания синтаксиса языка и информация о структуре предложения.
Если есть выражение a*5+b: его представление в памяти
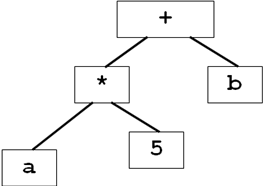
![]()
Построение синкт. деревьев для выражений подобно трансляции выражений в постфиксный вид. Мы строим поддеревья для подвыражений путем создания узлов для каждой операции и операндов. Узлы, дочерни по отношению к узлу операций, являются корнями поддеревьев для подвыражений, образующих операнды данной операции. Каждый узел в синтаксическом дереве может быть реализован как запись с несколькими полями. В узле операции одно поле идентифицирует операцию, а остальные поля содержат указатели на узлы операндов. Рассмотрим функции, которые можно применять для создания узлов: mknode(op,left,right) – создает узел операции с меткой op и двумя полями, содержащими указатель на left и right. mkleaf(id, entry) создает узел идентификатора с меткой id b и полем, содержащим entry, указатель на запись для этого идентификатора в таблице символов. mkleaf(num, val) – создает узел числа с меткой num и полем, содержащим val – значение числа. С помощью этих функций можно построить дерево для выражений (напр a-4+c)