

18. Разбор методом «сдвиг – свертка» (shift – reduce) на основе стека.
А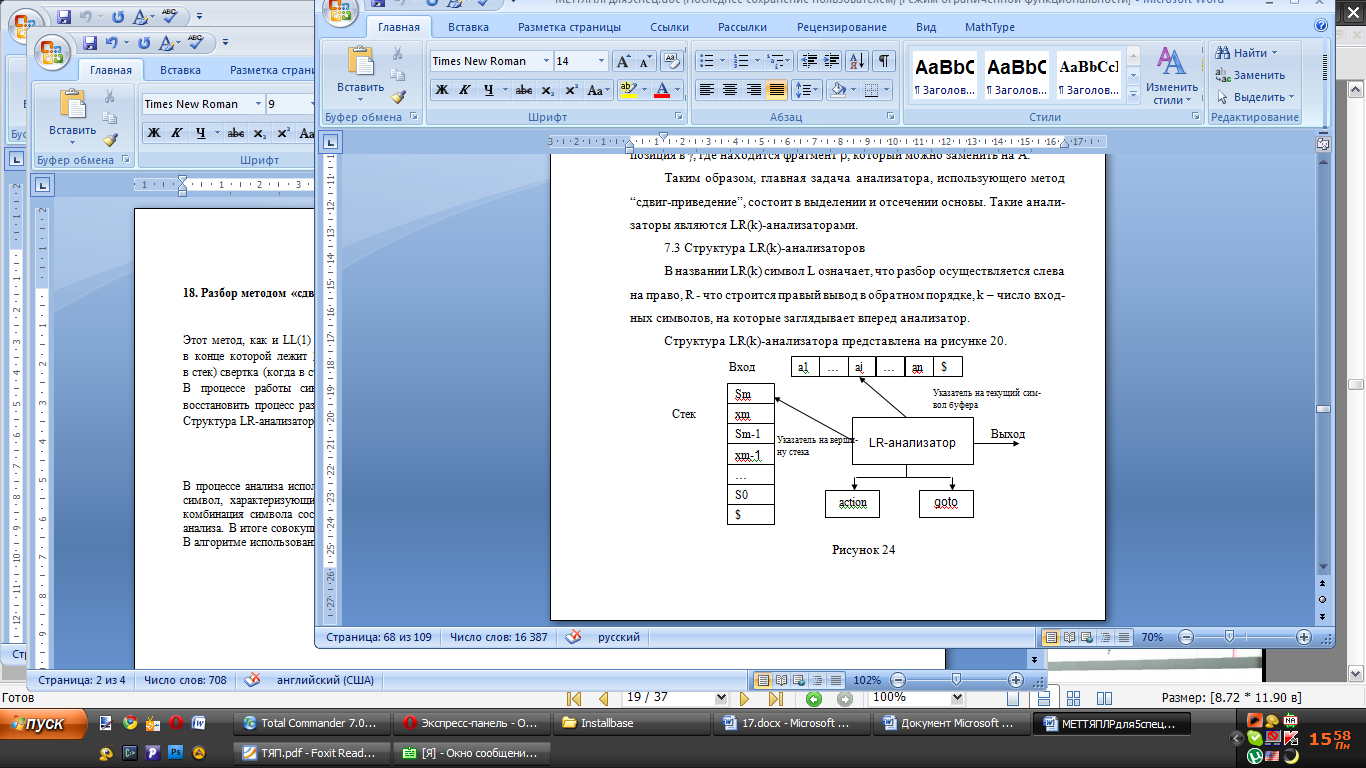 нализатор
пытается строить дерево разбора для
входной последовательности, начиная с
листьев и работая по направлению к корню
дерева (вверх). Этот процесс можно
рассматривать как свертку строки w
к стартовому символу грамматики. Этот
метод, как и LL(1)
анализатор использует стек. В самом
начале лежит $ и буфер в котором содержится
входная последовательность в конце
которой лежит $-конец.
нализатор
пытается строить дерево разбора для
входной последовательности, начиная с
листьев и работая по направлению к корню
дерева (вверх). Этот процесс можно
рассматривать как свертку строки w
к стартовому символу грамматики. Этот
метод, как и LL(1)
анализатор использует стек. В самом
начале лежит $ и буфер в котором содержится
входная последовательность в конце
которой лежит $-конец.
Анализ работы: Сдвигают 0 или более символов из буфера в стек, так чтобы в вершине стека оказалась основа В, затем сворачивает В нетерминалами левой части правила. Этот процесс повторяется до тех пор, пока не будет обнаружена ошибка или не возникает конфигурация стеке $S, а в буфере $.
С тек
Буфер
тек
Буфер
$ S $
Этот алгоритм должен выполнить 4 операции:
1)Сдвиг-символ из буфера заносим в стек.
2)Свертка-анализатор определяет, что в стеке находится основа, затем на левую часть правила.
3) Допуск - когда анализатор обнаруживает, что состояние соответствует успешному разбору.
4)Ошибка – обнаруживается ошибки и запускается приложение обработки ошибки.
20. SLR (1) – разбор. Ситуация. Пополненная грамматика.
SLR(1) — восходящий алгоритм синтаксического разбора. Представляет собой расширение алгоритма LR(0) и работает тогда когда LR(0) таблицы грамматики невозможно из-за конфликтов сдвиг-приведение или приведение-приведение.
В процессе работы в стеке формируется активный префикс, это начальная часть правой сентенциальной формы. Если активный префикс содержит основу то можно делать свертку. Основу в стеке мы будем распознавать конечным автоматом. В случае неоднозначности выбора операций будем использовать м-во FOLLOW.
Рассмотрим SLR методы.
Метод не анализирует, а использует множество Follow. Каждая продукция грамматики может ожидать в стеке свою основу, это ожидание разбивается на ряд этапов, в зависимости, какая часть основы уже распознана.
Фазу ожидания правила называют – ситуацией (Item), это продукция из заданной грамматики, в которую помещена точка, отделяющая распознанную часть от нераспознанной части.
Если есть правило [A→XYZ], то для этого правила возможны 4 ситуации (LR(0) – ситуации):
[A → • X Y Z]
[A → X • Y Z]
[A → X Y • Z]
[A → X Y Z •]
‘•’ – указывает какой фрагмент основы уже распознан в данной ситуации
f → ε [A→ •] эту ситуацию можно представить парой чисел:
Номер продукции;
Позиция точки;
Эти ситуации можно расшифровать как состояния конечного не детерминированного автомата распознающего основы.
Если грамматика G имеет стартовый символ S, то грамматика G’ будет для нее дополненной грамматикой, если в нее добавить стартовый символ S’ и продукцию S→ S’.
Начальное правило S' вводится для того, чтобы свертка, в которой используется нулевое правило, можно было интерпретировать как признак того, что входная цепочка допустима, т.е успешное завершение разбора (accept).