

5.3.2. Матричное представление линейных (систематических) кодов. Коды Хемминга.
В матричной форме систематическое кодирование задается порождающей матрицей Gk×n, тогда:
B1×n=
A1×k
 Gk×n,
Gk×n,
где B1× n= [ ] - вектор-строка кодового слова;
A1× k = [ ] - вектор-строка информационного слова;
Gk×n- порождающая матрица размером (kxn).
Порождающую матрицу Gk×n можно представить в виде:
Gk×n= [Ik×k Pk×r],
где Ik×k - единичная матрица по числу информационных символов;
Pk×r - правило формирования проверочных символов.
Заметим, что в матрице Pk×r включаются именно коэффициенты , которые и дают правило формирования проверочных символов.
Для рассмотренного ранее примера порождающая матрица будет иметь вид:
-
1

G4×7 =
0
0
0
0
1
1
0
1
0
0
1
0
1
0
0
1
0
1
1
0
0
0
0
1
1
1
1
Тогда можно определить любой вектор кодовой комбинации В по заданному вектору А, например:
Для A=[1010], найдем кодовое слово:
Напомним правила арифметики по модулю 2:
-
Сложение
Умножение
0
1
0
1
0
0
1
0
0
0
1
1
0
1
0
1
B=[1010] =[1010101]
=[1010101]
Проверим по правилу формирования проверочных символов:
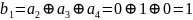 ,
,
 ,
,
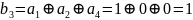 .
.
Для любого систематического кода с порождающей матрицей Gk×n в интересах его декодирования определяет проверочную матрицу
Hr×n= [PT k×r Ir×r],
где Ir×r – единичная матрица;
PTk×r - транспонированная матрица правила формирования проверочных символов.
Каждый столбец матрицы Hr×n соответствует синдрому некоторого символа кодовой комбинации:
Первые k-столбцов – синдромам информационных символов, а последние r-столбцов – синдромам проверочных символов.
Единицы
в каждой строке проверочной матрицы
Hr×n
показывают, какие из aj,
 информационные символы нужно сложить
по модулю 2, чтобы получить соответствующие
проверочные bi,
, т.е. правило их формирования.
информационные символы нужно сложить
по модулю 2, чтобы получить соответствующие
проверочные bi,
, т.е. правило их формирования.
Процесс декодирования сводится к выполнению следующей операции:
 ,
,
где
 - вектор-строка размерностью 1
- вектор-строка размерностью 1 r,
называемый синдромом кода;
r,
называемый синдромом кода;
 -
вектор-строка размерностью 1
n,
характеризующий принятую кодовую
комбинацию;
-
вектор-строка размерностью 1
n,
характеризующий принятую кодовую
комбинацию;
 -
транспонированная проверочная матрица.
-
транспонированная проверочная матрица.
Или

Если
в принятой кодовой комбинации
 отсутствуют ошибки, то
отсутствуют ошибки, то
Где 0=[0,0,…,0] – нулевой вектор-строка размерностью 1 r.
В противном случае C≠0.
Таким образом, декодирование систематических кодов основано на матричном умножении по модулю 2, которое осуществляется обычным образом, но с учетом правил умножения и сложения по модулю 2.
Проверочная матрица для рассмотренного ранее кода (7,4) будет иметь вид:
Pk×r
= ;
;
 [PT
k×r
Ir×r]=
[PT
k×r
Ir×r]=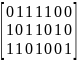
Проведем декодирование принятой кодовой комбинации
=[1010101]
при условии одиночной ошибки в четвертом
разряде
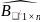 =[1011101]
=[1011101]
Найдем матрицу синдромов для принятой комбинации с ошибкой :
 =[1011
101]
=[1011
101] =[111]
=[111]
Сопоставляя полученный синдром со столбцами проверочной матрицы или строками транспонированной матрицы, находим его соответствие синдрому четвертого информационного символа и приходим к выводу, что ошибка произошла в символе a4. Следовательно, в принятой ошибочной комбинации надо исправить символ a4 на противоположный, тогда получим кодовую комбинацию с исправленной ошибкой в четвертом разряде
=[101 101]
101]
Если кодовая комбинация записана (сформирована) так, что синдром будет указывать на номер разряда (равен ему) в принятой комбинации, в котором произошла ошибка, то такой линейный (систематический) код называют кодом Хэмминга.
В
нашем примере, если символы алфавита a
и b
расположить [a4a3a2a1b3b2b1],
то синдром [111]
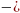 указывал
бы на седьмой разряд (отсчет разрядов
ведется справа налево) кодового слова,
т.е. на то, чтобы ошибка произошла в
символе a4.
указывал
бы на седьмой разряд (отсчет разрядов
ведется справа налево) кодового слова,
т.е. на то, чтобы ошибка произошла в
символе a4.
Пример: Самостоятельно проверить, что надо изменить в рассмотренном выше примере, чтобы код (7,4) можно было бы назвать кодом Хэмминга. Изменятся ли при этом порождающая и проверочная матрицы?
Таким образом, порождающая Gk×n и проверочная Hr×n матрицы обычно используются для построения кодеков. Поскольку между этими матрицами существует однозначное соответствие
Gk×n= [Ik×k Pk×r] и Hr×n= [PT k×r Ir×r], то в принципе организовать кодирование и декодирование можно с помощью одной из них.
Тогда,
при использовании линейных (систематических)
кодов, нет необходимости хранить в
памяти декодера все разрешенные кодовые
комбинации Np= ,
а это
,
а это
 - двоичных символов), и подмножества
запрещенных кодовых комбинаций(N-Np)
(а это
- двоичных символов), и подмножества
запрещенных кодовых комбинаций(N-Np)
(а это
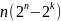 - двоичных символов), для организации
декодирования по методу максимального
правдоподобия. Достаточно для кодирования
и синдромного декодирования запомнить
проверочную Hr×n
матрицу, которая занимает объем памяти
(r×n)
ячеек.
- двоичных символов), для организации
декодирования по методу максимального
правдоподобия. Достаточно для кодирования
и синдромного декодирования запомнить
проверочную Hr×n
матрицу, которая занимает объем памяти
(r×n)
ячеек.