

33. Блочные устройства
Драйверы блочных устройств предназначены для обслуживания периферийного оборудования, обеспечивающего обмен данными с помощью фрагментов фиксированной длины, называемыми блоками, размер которых значительно превышает один байт. В основном эти драйверы используются файловой подсистемой и подсистемой управления памятью. Например, свопинг характеризуется обменом данными с устройством вторичной памяти, размер которых обычно равен размеру страницы, что составляет 4 или 8 Кбайт. Файловая подсистема производит чтение и запись данных фрагментами, размер которых равен одному или нескольким блокам устройства. Типичными представителями блочных устройств являются жесткий и гибкий диски.
Блочные устройства можно разделить на два типа в зависимости от того, используются ли они для хранения файловой системы или нет. Соответственно различается и схема доступа к этим устройствам. В последнем случае доступ к устройству осуществляется только через специальный файл устройства, представляющий интерфейс низкого уровня. Хотя обращение к устройствам, содержащим файловые системы, может также осуществляться через интерфейс низкого уровня, доступ к таким устройствам, как правило, осуществляется процессом косвенно, через запросы к файловой системе. Например, чтение или запись обычного файла вызывает операции с драйвером блочного устройства (жесткого диска), на котором расположена файловая система, хранящая данный файл. В этом случае обмен данными происходит при активном участии буферного кэша, позволяющего минимизировать число обращений непосредственно к физическому устройству.
Вообще говоря, операции ввода/вывода для блочного устройства могут быть вызваны рядом событий:
- Чтением или записью в обычный файл.
- Чтением или записью непосредственно в специальный файл устройства.
- Операциями подсистемы управления памятью: страничным замещением или свопингом.
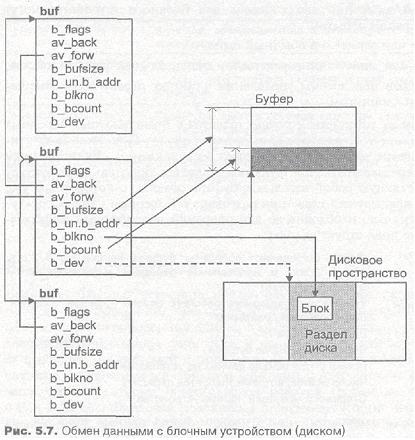
Доступ к блочным устройствам осуществляется с помощью трех основных точек входа: ххореп (), xxclose() и xxstrategy() . При этом за фактическое выполнение ввода/вывода отвечает xxstrategy(}. Единственным аргументом, передаваемым этой функции, является указатель на структуру buf, представляющую собой заголовок буфера обмена, с которой мы уже встречались в предыдущей главе при разговоре о буферном кэше. Структура buf содержит всю необходимую для операций ввода/вывода информацию. Основные поля структуры buf:
b_flags Флаги. Определяют состояние буфера (например, B_BUSY.
или B_DONE) и направление передачи данных (B_READ, B_WRITE, B_PHYS)
av_back, av_forw Указатели двухсвязного рабочего списка буферов, ожидающих обработки драйвером
b_bufsize Размер буфера
b_un.b_addr Виртуальный адрес буфера
b_blkno Номер блока начала данных на устройстве
b_bcount Число байтов, которые требуется передать
b_dev Старший и младший номера устройства
Использование заголовка buf при передачи блока данных показано на
рис. 5.7.
Ядро адресует дисковый блок, указывая vnode и смещение. Если доступ осуществляется к специальному файлу устройства, то смещение является физическим, отсчитываемым от начала устройства. Например, если специальный файл устройства /dev/dsk/cOtOdOsl обеспечивает доступ ко второму разделу жесткого диска, то смещение будет отсчитываться от начала этого раздела. Если vnode представляет обычный файл, то смещение является логическим, отсчитываемым от начала файла.
Таким образом, блок устройства, содержащего файловую систему, может быть адресован двумя способами — либо через обычный файл и логическое смещение, либо через специальный файл устройства и физическое смещение на этом устройстве. Это, в свою очередь, может привести к различной идентификации одного и того же блока и, как следствие, двум различным копиям блока в памяти. Результатом такого несоответствия может стать потеря или нарушение целостности данных. Поэтому непосредственный доступ к специальному файлу такого устройства возможен только при размонтированной файловой системе.
Поскольку каждый дисковый блок связан с каким-либо файлом и соответственно с его vnode, а его образ в памяти — с физическими страницами, которые также связаны с vnode (через структуры описания физической памяти — page в SVR4, pfdat в SVR3), все операции ввода/вывода связаны с подкачкой и сохранением страниц и идентифицируются vnode.
Символьные устройства
Символьные устройства представляют собой значительную часть периферийного оборудования системы, включая терминалы, манипуляторы (например, мышь), клавиатуру и локальные принтеры. Основное отличие этих устройств от блочных заключается в том, что они, как правило, передают небольшие объемы данных.
Обмен данными с символьными устройствами происходит непосредственно через драйвер, минуя буферный кэш. При этом данные обычно копи-
руются в драйвер из адресного пространства процесса, запросившего операцию ввода/вывода.
Если процесс сделал системный вызов ввода/вывода, например, read(2) или write(2) со специальным файлом символьного устройства, запрос направляется в файловую подсистему. Поскольку доступ к устройству обслуживается файловой системой specfs, рассмотренной ранее, в ответ на выполнение системного вызова процесса ядро выполняет вызов функции spec_read () или spec_write() соответственно для read(2) или write(2). Действия функций spec_read() и spec_write {) похожи. Обе проверяют тип vnode и определяют, что устройство является символьным. После этого с помощью коммутатора ядро выбирает соответствующую точку входа драйвера, используя старший номер, хранящийся в поле v_rdev vnode, и вызывает эту функцию (соответственно xxreadO или xxwriteO), передавая ей в качестве параметров старший и младший номера, ряд дополнительных параметров, зависящих от конкретного вызова, а также явно или неявно адресует область копирования данных в адресном пространстве процесса3.
Интерфейс доступа низкого уровня
Символьные драйверы обеспечивают доступ не только к символьным устройствам, например, к адаптеру последовательного или параллельного портов, манипулятору "мышь", монитору или терминалам. Часть символьных драйверов служит в качестве интерфейса доступа низкого уровня к блочным устройствам, таким как диски или накопители на магнитных лентах.
Большинство таких драйверов отличаются от соответствующих им драйверов блочных устройств характером выполнения операций ввода/вывода. В то время как драйверы блочных устройств производят обмен данными с буферным кэшем, драйверы доступа низкого уровня обеспечивают обмен данных непосредственно с адресным пространством процесса. Отсутствие посредника в виде буферного кэша устраняет необходимость в совершении дополнительных операций копирования (драйвер — буферный кэш -буфер процесса), но в то же время лишает процесс услуг кэширования данных, предоставляемых операционной системой.
Интерфейс доступа низкого уровня используется многими системными утилитами обслуживания файловой системы, например, fsck(JM), а также рядом приложений, работающих с накопителями на магнитной ленте, например tar(l) или cpio(l). Этот интерфейс используется некоторыми при-
ложениями, например СУБД, которые самостоятельно обеспечивают оптимизированные механизмы кэширования данных на уровне задачи.
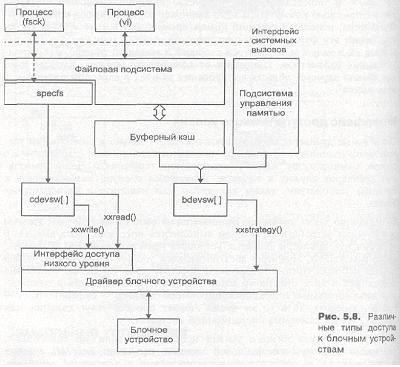
Поскольку драйверы низкого уровня не используют буферный кэш, они самостоятельно обеспечивают необходимые буферы для совершения операции ввода/вывода. На рис. 5.8 показаны отличия в характере выполнения операции ввода/вывода с блочными устройствами в случаях, когда запрос формируется при участии буферного кэша (драйверы блочных устройств}, и когда манипуляция буфером производится драйвером самостоятельно (драйверы низкого уровня).
Архитектура терминального доступа
Алфавитно-цифровой терминал — последовательное устройство, и операционная система производит обмен данными с терминалом через последовательный интерфейс, называемый терминальной линией. С каждой терминальной линией в UNIX ассоциирован специальный файл символьного устройства /dev/ttyxv4.
Терминальные драйверы выполняют ту же функцию, что и остальные драйверы: управление передачей данных от/на терминалы. Однако терми-
налы имеют одну особенность, связанную с тем, что они обеспечивают интерфейс пользователя с системой. Обеспечивая интерактивное использование системы UNIX, терминальные драйверы имеют свой внутренний интерфейс с модулями, интерпретирующими ввод и вывод строк. Модуль, отвечающий за такую обработку, называется дисциплиной линии (line discipline).
Существует два режима терминального ввода/вывода:
1. Канонический режим. В этом режиме ввод с терминала обрабатывается в виде законченных строк.
2. Неканонический режим, при котором ввод не интерпретируется.
В каноническом режиме интерпретаторы строк преобразуют неструктурированные последовательности данных, введенные с клавиатуры, в каноническую форму (то есть в форму, соответствующую тому, что пользователь имел в виду на самом деле) прежде, чем послать эти данные принимающему процессу. Например, программисты работают на клавиатуре терминала довольно быстро, но иногда допускают ошибки. На этот случай имеется клавиша стирания, и пользователь имеет возможность удалять часть введенной строки и вводить коррективы. Драйвер терминала получает всю введенную последовательность, включая и символы стирания. В каноническом режиме модуль дисциплины линии буферизует информацию в строку (набор символов, заканчивающийся символом возврата каретки) и стирает символы в буфере, прежде чем переслать исправленную последовательность считывающему процессу. В таком режиме, например, работает командный интерпретатор shell.
В режиме без обработки строковый интерфейс передает данные между процессами и терминалом без каких-либо преобразований. Например, текстовый редактор работает с драйвером в неканоническом режиме, благодаря чему любой символ, введенный пользователем интерпретируется самим процессом.
В функции модуля дисциплины линии входят:
1. Построчный разбор введенных последовательностей.
2. Обработка символов стирания.
3. Обработка символов удаления, отменяющих всех предыдущих символов.
4. Отображение символов, полученных терминалом.
5. Расширение выходных данных, например, преобразование символов табуляции в последовательности пробелов.
6. Предоставление возможности не обрабатывать специальные символы, такие как символы стирания, удаления и возврата каретки.
Существует дополнительная возможность обработки данных, получаемых и передаваемых устройству — отображение вводимых и выводимых символов