

8. Дополнительные возможности ntfs.
Hard Link – несколько имен для одного файла
fsutil hardlink create <новый файл> <существующий файл>
Пример: fsutil hardlink create c:\foo.txt c:\bar.txt
Точки подсоединения NTFS (junction point)
Другим новшеством в Windows 2000 стало монтирование устройств. Утилита Disk Administrator Windows NT позволяла назначить тому букву латинского алфавита. Этот довольно простой метод дает возможность обратиться к любому дисковому устройству из стандартного меню открытия файла. Естественным ограничением на количество локальных и подключенных сетевых устройств было число 26, соответствующее числу букв латинского алфавита.
Подмонтирование возможно только к пустым папкам на NTFS-томах, а точки монтирования вы можете создать или из оснастки «Управление дисками», или из командной строки при помощи команды mountvol. Для того, чтобы отличить подмонтированные накопители от обычных папок, Explorer показывает их иконками соответствующих устройств. Для чего это может понадобиться? Во-первых, можно таким образом преодолеть ограничение на количество доступных логических дисков (ранее их не могло быть больше 26 - по числу букв латинского алфавита), повысить ёмкость существующих томов не используя динамические и… создавать отказоустойчивые папки на обычных томах.
Например, при монтировании нового основного раздела к папке D:\My Work Stuff все последующие обращения к этой папке будут автоматически переадресованы на соответствующий новый основной раздел, даже если он расположен на другом физическом диске, чем устройство D:. Если новый том является отказоустойчивым, то и папка D:\My Work Stuff считается отказоустойчивой, даже если само устройство D: этим качеством не обладает.
С помощью утилиты mountvol.exe можно:
Отобразить корневую папку локального тома в некоторую папку NTFS 5.0 (другими словами, подключить том). Вывести на экран информацию о целевой папке точки соединения NTFS, использованной при подключении тома. Просмотреть список доступных для использования томов файловой системы. Уничтожить точки подключения томов, созданных с помощью mountvol.
Применяя утилиту mountvol, можно избежать использования большого количества имен устройств, поскольку обращение к необходимому тому происходит через корневую папку. Утилита mountvol создает неизменные связи с корневыми папками локального тома файловой системы. Она применяет в работе новую технологию, гарантирующую, что при изменениях в параметрах оборудования целевая папка не изменяется.
Синтаксис вызова утилиты mountvol;
mountvol [устройство:]путь Имя_тома
где:
[устройство:]путь — определяет существующую папку NTFS 5.0, являющуюся точкой подключения тома; имя_тома — определяет имя подключаемого тома.
Параметры утилиты mountvol:
/о — уничтожение существующей точки подключения у указанной папки.
/l — отображение списка томов, подключенных к данной папке.
7. Сравнение структуры логического диска fat (fat32) и тома ntfs.
FAT |
NTFS |
Поиск данных файла Выяснение того, в каких областях диска хранится тот или иной фрагмент файла - процесс, который имеет принципиально разное воплощение в различных файловых системах. Имейте в виду, что это лишь поиск информации о местоположении файла - доступ к самим данным, фрагментированы они или нет, здесь уже не рассматривается, так как этот процесс совершенно одинаков для всех систем. Речь идет о тех "лишних" действиях, которые приходится выполнять системе перед доступом к реальным данным файлов. На что влияет этот параметр: на скорость навигации по файлу (доступ к произвольному фрагменту файла). Любая работа с большими файлами данных и документов, если их размер - несколько мегабайт и более. Этот параметр показывает, насколько сильно сама файловая система страдает от фрагментации файлов. |
|
из-за большой области самой таблицы размещения будет испытывать огромные трудности, если фрагменты файла разбросаны по всему диску. Для доступа к фрагменту файла в системе FAT16 и FAT32 приходится обращаться к соответствующей ячейке таблицы FAT В системе FAT16, где максимальный размер области FAT составляет 128 Кбайт, это не составит проблемы – вся область FAT просто хранится в памяти, или же считывается с диска целиком за один проход и буферизируется. FAT32 же, напротив, имеет типичный размер области FAT порядка сотен килобайт, а на больших дисках – даже несколько мегабайт. |
способна обеспечить быстрый поиск фрагментов, поскольку вся информация хранится в нескольких компактных записях. Если файл очень сильно фрагментирован – NTFS придется использовать много записей, которые могут храниться в разных местах. |
Вывод: Абсолютный лидер - FAT16, он никогда не заставит систему делать лишние дисковые операции для данной цели. Затем идет NTFS - эта система также не требует чтения лишней информации, по крайней мере, до того момента, пока файл имеет разумное число фрагментов. FAT32 испытывает огромные трудности, вплоть до чтения лишних сотен килобайт из области FAT, если файл разбросан по разным областям диска. Работа с внушительными по размеру файлами на FAT32 в любом случае сопряжена с огромными трудностями - понять, в каком месте на диске расположен тот или иной фрагмент файла, можно лишь изучив всю последовательность кластеров файла с самого начала, обрабатывая за один раз один кластер (через каждые 4 Кбайт файла в типичной системе). Стоит отметить, что если файл фрагментирован, но лежит компактной кучей фрагментов - FAT32 всё же не испытывает больших трудностей, так как физический доступ к области FAT будет также компактен и буферизован. |
|
Поиск свободного места Данная операция производится в том случае, если файл нужно создать с нуля или скопировать на диск. Поиск места под физические данные файла зависит от того, как хранится информация о занятых участках диска. На что влияет этот параметр: на скорость создания файлов, особенно больших. Сохранение или создание в реальном времени больших мультимедийных файлов (.wav, к примеру), копирование больших объемов информации, т.д. Этот параметр показывает, насколько быстро система сможет найти место для записи на диск новых данных, и какие операции ей придется для этого проделать. |
|
Для определения того, свободен ли данный кластер или нет, системы на основе FAT должны просмотреть одну запись FAT, соответствующую этому кластеру. Для поиска свободного места на диске может потребоваться просмотреть почти всего FAT – это 128 Кбайт (максимум) для FAT16 и до нескольких мегабайт (!) – в FAT32. Для того, чтобы не превращать поиск свободного места в катастрофу (для FAT32), ОС приходится идти на различные ухищрения. |
NTFS имеет битовую карту свободного места, одному кластеру соответствует 1 бит. Для поиска свободного места на диске приходится оценивать объемы в десятки раз меньшие, чем в системах FAT и FAT32. |
Вывод: NTFS имеет наиболее эффективную систему нахождения свободного места. Стоит отметить, что действовать "в лоб" на FAT16 или FAT32 очень медленно, поэтому для нахождения свободного места в этих системах применяются различные методы оптимизации, в результате чего и там достигается приемлемая скорость. (Одно можно сказать наверняка - поиск свободного места при работе в DOS на FAT32 - катастрофический по скорости процесс, поскольку никакая оптимизация невозможна без поддержки хоть сколь серьезной операционной системы). |
|
Работа с каталогами и файлами Каждая файловая система выполняет элементарные операции с файлами - доступ, удаление, создание, перемещение и т.д. Скорость работы этих операций зависит от принципов организации хранения данных об отдельных файлах и от устройства структур каталогов. На что влияет этот параметр: на скорость осуществления любых операций с файлом, в том числе - на скорость любой операции доступа к файлу, особенно - в каталогах с большим числом файлов (тысячи). |
|
FAT16 и FAT32 имеют очень компактные каталоги, размер каждой записи которых предельно мал. Работа с каталогами FAT производится достаточно быстро, так как в подавляющем числе случаев каталог не фрагментирован и находится на диске в одном месте. Единственная проблема – высокая трудоемкость поиска файлов в больших каталогах. Система хранения данных – линейный массив – не позволяет организовать эффективный поиск файлов в таком каталоге. |
NTFS использует гораздо более эффективный способ адресации – бинарное дерево. Сам каталог NTFS представляет собой гораздо менее компактную структуру, чем каталог FAT – это связано с гораздо большим (в несколько раз) размером одной записи каталога. Это обстоятельство приводит к тому, что каталоги на томе NTFS могут быть сильно фрагментированы. Размер типичного каталога в FAT укладывается в один кластер, тогда как сотня файлов (и даже меньше) в каталоге на NTFS уже приводит к размеру файла каталога, превышающему типичный размер одного кластера. Это, в свою очередь, может привести к фрагментации файла каталога, и уменьшить положительный эффект от более эффективной организации самих данных. |
Вывод: структура каталогов на NTFS теоретически гораздо эффективнее, но при размере каталога в несколько сотен файлов это практически не имеет значения. Фрагментация каталогов NTFS, однако, уверенно наступает уже при таком размере каталога. Для малых и средних каталогов NTFS, как это ни печально, имеет на практике меньшее быстродействие. Преимущества каталогов NTFS становятся реальными и неоспоримыми только в том случае, если в одно каталоге присутствуют тысячи файлов - в этом случае быстродействие компенсирует фрагментированность самого каталога и трудности с физическим обращением к данным (в первый раз - далее каталог кэшируется). Напряженная работа с каталогами, содержащими порядка тысячи и более файлов, проходит на NTFS буквально в несколько раз быстрее, а иногда выигрыш в скорости по сравнению с FAT и FAT32 достигает десятков раз. |
|
ИТОГИ:
Тома FAT32 могут теоретически быть больше 2 ТБ, но операционные системы Windows Server 2003, Windows 2000 и Windows XP могут форматировать диски объемом только до 32 ГБ. (Windows Server 2003, Windows 2000 и Windows XP Professional могут читать и записывать на большие по объему тома FAT32, отформатированные другими операционными системами).
Тома NTFS могут теоретически быть объемом до 16 эксабайт (ЭБ), но практический предел составляет 2 ТБ.
Пользователь может определить размер кластера при форматировании тома NTFS. Однако NTFS-сжатие не поддерживается для кластеров, размер которых больше 4 КБ.
Функции Win32 API для работы с файлами. Организация асинхронной работы с файлами.
Win32 API |
UNIX |
Описание |
CreateFile |
open |
создать новый файл или открыть существующий |
DeleteFile |
unlink |
удалить существующий файл |
CloseHandle |
close |
закрыть файл |
ReadFile |
read |
прочитать данные из файла |
WriteFile |
write |
записать данные в файл |
SetFilePointer |
Iseek |
установить указатель работы с файлом |
GetFileAttributes |
stat |
вернуть атрибуты файла |
LockFile |
fcntl |
заблокировать регион файла для решения взаимного исключения |
UnlockFile |
fcntl |
разблокировать регион файла |
CreateDirectory |
mkdir |
создать новый каталог |
RemoveDirectory |
rmdir |
удалить пустой каталог |
FindFirstFile |
opendir |
выполнить инициализацию для начала чтения записей каталога |
FindNextFile |
readdir |
прочитать следующую запись каталога |
MoveFile |
rename |
перенести файл из одного каталога в другой |
SetCurrentDirectory |
chdir |
изменить текущий каталог |
Работа с каталогами и файлами:
Функция |
Выполняемое действие
|
GetCurrentDirectory |
Получение текущего каталога |
SetCurrentDirectory |
Смена текущего каталога |
GetSystemDirectory |
Получение системного каталога |
GetWindowsDirectory |
Получение основного каталога системы |
CreateDirectory |
Создание каталога |
RemoveDirectory |
Удаление каталога |
CopyFile |
Копирование файла |
MoveFile MoveFileEx |
Перемещение или переименование файла |
DeleteFile |
Удаление файла |
Работа с томами:
Для выяснения того, какие логические диски существуют в системе, используется функция
DWORD GetLogicalDrives( void )
Каждый установленный бит возвращаемого значения соответствует существующему в системе логическому устройству. Например, если в системе существуют диски A:, C: и D:, то возвращаемое функцией значение равно 13(десятичное).
Функция DWORD GetLogicalDrivesStrings(DWORD cchBuffer, LPTSTR lpszBuffer) заполняет lpszBuffer информацией о корневом каталоге каждого логического диска в системе. В приведенном выше примере буфер будет заполнен символами: A:\<null>C:\<null>D:\<null><null>
Параметр cchBuffer определяет длину буфера. Функция возвращает реальную длину буфера, необходимую для размещения всей информации.
Для определения типа диска предназначена функция
UINT GetDriveType( LPTSTR lpszRootPathName )
В качестве параметра ей передается символическое имя корневого каталога (напр. A:\), а возвращаемое значение может быть одно из следующих:
Идентификатор |
Описание |
0 |
Тип устройства определить нельзя |
1 |
Корневой каталог не существует |
DRIVE_REMOVABLE |
Гибкий диск |
DRIVE_FIXED |
Жесткий диск |
DRIVE_REMOTE |
Сетевой диск |
DRIVE_CDROM |
Компакт диск |
DRIVE_RAMDISK |
RAM диск |
Для получения подробной информации о носителе используется функция GetVolumeInformation. Она заполняет параметры информацией об имени тома, названии файловой структуры, максимальной длине имени файла, дополнительных атрибутах тома, специфических для файловой структуры.
Функция GetDiskFreeSpace сообщает информацию о размерах сектора и кластера и о наличии свободных кластеров.
Создание и открытие файла:
HANDLE CreateFile (
LPCTSTR lpFileName, // pointer to name of the file
DWORD dwDesiredAccess, // access (read-write) mode
DWORD dwShareMode, // share mode
LPSECURITY_ATTRIBUTES lpSecurityAttributes, // pointer to security descriptor
DWORD dwCreationDistribution, // how to create
DWORD dwFlagsAndAttributes, // file attributes
HANDLE hTemplateFile // handle to file with attributes to copy
);
В случае удачи функция CreateFile возвращает описатель открытого файла как объекта ядра. Существенно, что в противном случае она возвращает не NULL, а INVALID_HANDLE_VALUE.
Параметры CreateFile ():
Параметр dwDesiredAccess задает тип доступа к файлу. Можно определить флаги GENERIC_READ и GENERIC_WRITE а так же их комбинацию для разрешения чтения или записи в файл.
Параметр dwShareMode определяет режим совместного использования файла различными процессами. Если этот параметр равен нулю, то никакой другой поток не сможет открыть этот же файл. Флаги FILE_SHARE_READ и FILE_SHARE_WRITE а так же их комбинация разрешают другим потокам осуществлять доступ к файлу для чтения или записи.
Параметр dwCreationDistribution определяет действия функции в зависимости от того, существует ли уже файл с указанным именем.
CREATE_NEW - Создает файл, если файл существует, то ошибка.
CREATE_ALWAYS - Создает файл , если файл существует, то старый файл удаляется и новый создается.
OPEN_EXISTING - Открывает существующий файл.
OPEN_ALWAYS - Создает файл, если файл не существует, то создается новый файл.
TRUNCATE_EXISTING - Открывает файл и урезает его до нулевой длины
Параметр dwFlagsAndAttributes определяет атрибуты файла, если он создается и задает режим работы с файлом.
FILE_ATTRIBUTE_ARCHIVE,
FILE_ATTRIBUTE_HIDDEN,
FILE_ATTRIBUTE_NORMAL,
FILE_ATTRIBUTE_READONLY,
FILE_ATTRIBUTE_SYSTEM,
FILE_ATTRIBUTE_TEMPORARY
Атрибуты файла могут комбинироваться за исключением FILE_ATTRIBUTE_NORMAL, который всегда используется в одиночестве.
Вместе с атрибутами могут комбинироваться и флаги, задающие режим работы с файлом.
FILE_FLAG_NO_BUFFERING - Не осуществлять кэширование и опережающее чтение
FILE_FLAG_RANDOM_ACCESS - Кэшировать как файл произвольного доступа
FILE_FLAG_SEQUENTIAL_SCAN - Кэшировать как файл последовательного доступа
FILE_FLAG_WRITE_TROUGH - Не буферизовать операцию записи. Производить запись на диск немедленно.
FILE_FLAG_DELETE_ON_CLOSE - Уничтожить файл при закрытии. Полезно комбинировать с атрибутом FILE_ATTRIBUTE_TEMPORARY.
FILE_FLAG_OVERLAPPED - Работа с файлом будет осуществляться асинхронно.
Синхронный и асинхронный ввод/вывод:
При синхронной работе с файлами прикладная программа, запустив операцию ввода вывода, переходит в состояние блокировки до ее окончания (т.е. ожидает завершения операции ввода вывода).
При асинхронной работе с файлами прикладная программа, запустив операцию ввода вывода, не ожидает ее завершения а продолжает исполняться.
Функции файлового ввод-вывода:
BOOL ReadFile(
HANDLE hFile, // handle of file to read
LPVOID lpBuffer, // address of buffer that receives data
DWORD nNumberOfBytesToRead, // number of bytes to read
LPDWORD lpNumberOfBytesRead, // address of number of bytes read
LPOVERLAPPED lpOverlapped // address of structure needed for overlapped I/O
);
BOOL WriteFile(
HANDLE hFile, // handle to file to write to
LPCVOID lpBuffer, // pointer to data to write to file
DWORD nNumberOfBytesToWrite, // number of bytes to write
LPDWORD lpNumberOfBytesRead, // pointer to number of bytes written
LPOVERLAPPED lpOverlapped // address of structure needed for overlapped I/O
);
Параметры функция файлового ввода-вывода:
Параметры функции ReadFile () имеют следующее предназначение:
- hFile – описатель объекта ядра “файл”, полученный в результате вызова функции CreateFile
- LpBuffer – адрес буфера, в который будет производиться чтение
- nNumberOfBytesToRead – количество байт, которые необходимо прочитать
- lpNumberOfBytesRead – адрес переменной, в которой будет размещено количество реально прочитанных байт. Существенно, что сразу после выполнения функции ReadFile, этот параметр не может быть установлен, так как операция чтения только началась.
- lpOverlapped – указатель на структуру OVERLAPPED, управляющую асинхронным вводом выводом.
Параметры функции WriteFile () аналогичны параметрам функции ReadFile ().
Пример синхронного копирования файла:
/* Open files for input and output. */
inhandle = CreateFile("data", GENERIC_READ, 0, NULL, OPEN_EXlSTING, 0, NULL);
outhandle=CreateFile("newf",GENERIC_WRITE, 0, NULL, CREATE_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL);
/* Copy the file. */
do {
s = ReadFile(inhandle, buffer, BUF_SIZE, &count, NULL);
if (s && count > 0)
WriteFile(outhandle, buffer, count, Socnt, NULL);
} while (s>0 && count>0);
/* Close the files. */
CloseHandle (inhandle):
CloseHandle (outhandle);
Асинхронный ввод-вывод:
Для организации асинхронной работы с файлами необходимо при вызове функции CreateFile () установить флаг FILE_FLAG_OVERLAPPED в параметре dwFlagsAndAttributes.
После этого функции ReadFile () и WriteFile () будут работать асинхронно, т.е. только запускать операции ввода вывода и не ожидать их завершения.
В отличие от синхронных операций, при организации асинхронного чтения (записи) необходимо явно указать позицию, начиная с которой производится операция. Это связано с тем, что текущей позиции не существует, так как несколько операций чтения и записи могут производиться одновременно с разных позиций в одном файле.
typedef struct _OVERLAPPED {
DWORD Internal; //Используется операционной системой. Хранит статус завершения операции.
DWORD InternalHigh; //Используется ОС. Хранит количество переданных байт.
DWORD Offset; //Позиция в файле, начиная с которой необходимо
производить операцию чтения (записи).
DWORD OffsetHigh; //Количество байт для передачи.
HANDLE hEvent; //Описатель события, которое произойдет при завершении операции чтения (записи).
} OVERLAPPED;
Вариант 1 организации асинхронного ввода-вывода:
Перед запуском операции создается объект ядра “событие” и его описатель передается в функцию ReadFile () или WriteFile () в качестве элемента hEvent параметра lpOverlapped.
Программа, выполнив необходимые действия одновременно с операцией передачи данных, вызывает одну из функций ожидания (например, WaitForSingleObject), передавая ей в качестве параметра описатель события.
Выполнение программы при этом приостанавливается до завершения операции ввода-вывода.
Вариант 2 организации асинхронного ввода-вывода:
Событие не создается. В качестве ожидаемого объекта выступает сам файл. Его описатель передается в функцию WaitForSingleObject ().
Этот метод прост и корректен, но не позволяет производить параллельно несколько операций ввода-вывода с одним и тем же файлом.
Вариант 3 организации асинхронного ввода-вывода:
“Тревожный” асинхронный ввод-вывод. Схема построена на использовании функций ReadFileEx () и WriteFileEx (). В качестве дополнительного параметра в эти функции передается адрес функции завершения, которая будет вызываться всякий раз при завершении операции ввода-вывода.
Существенно, что эти функции выполняются в том же самом потоке что и функции файлового ввода/вывода. Это значит, что поток, запустивший операции чтения записи должен обратиться к функции ожидания, чтобы разрешить системе вызвать функцию завершения.
8 - 9. Классификация методов распределения памяти. Методы без использования внешней памяти. Методы с использованием внешней памяти. Защита памяти. Стратегии управления виртуальной памятью (свопинг).

Способы организации виртуальной памяти с использованием внешней памяти:
Понятие виртуальной памяти:
Уже достаточно давно пользователи столкнулись с проблемой размещения в памяти программ, размер которых превышал имеющуюся в наличии свободную память. Решением было разбиение программы на части, называемые оверлеями. 0-ой оверлей начинал выполняться первым. Когда он заканчивал свое выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами ОС. Однако разбиение программы на части и планирование их загрузки в ОП должен был осуществлять программист. Развитие методов организации вычислительного процесса в этом направлении привело к появлению метода, известного под названием виртуальная память. Термин виртуальная память обычно ассоциируется с возможностью адресовать пространство памяти, гораздо большее, чем емкость первичной (реальной) памяти конкретной вычислительной машины. Концепция виртуальной памяти является далеко не новой, впервые она была реализована в вычислительной машине Atlas, созданной в Манчестерском университете в Англии в 1960г.
Виртуальная память (ВП) – это совокупность программно-аппаратных средств, позволяющих выполнять программы, размер которых превосходит имеющуюся оперативную память.
Для этого менеджер ВП решает следующие задачи:
- размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске;
- перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память (свопинг);
- преобразует виртуальные адреса в физические.
Физические и виртуальные адреса:
Суть концепции виртуальной памяти заключается в том, что адреса, к которым обращается выполняющийся процесс, отделяются от адресов, реально существующих в первичной памяти:
- адреса, на которые делает ссылки выполняющийся процесс, называются виртуальными адресами (ВА);
- адреса, которые существуют в первичной памяти, называются реальными (или физическими) адресами (ФА).
Для установления соответствия между ВА и ФА разработаны различные способы. Так, механизмы динамического преобразования адресов (DAT - Dynamic Address Translation) обеспечивают преобразование ВА в ФА время выполнения процесса.

Все подобные системы обладают общим свойством: смежные адреса виртуального адресного пространства процесса не обязательно будут смежными в реальной памяти, это свойство называют “искусственной смежностью”.
- страничное распределение;
Виртуальное адресное пространство (ВАП) каждого процесса делится на части одинакового, фиксированного для данной ОС размера, называемые виртуальными страницами. Размер страницы кратен степени двойки, это позволяет упростить механизм преобразования адресов. ОП делится на физические страницы такого же размера. При загрузке процесса ОС создает для каждого процесса таблицу страниц, в которой устанавливается соответствие между номерами виртуальных и физических страниц для страниц, загруженных в ОП, или делается отметка о том, что виртуальная страница выгружена на диск.
При загрузке процесса часть виртуальных страниц процесса помещается в оперативную память, а остальные – на диск. При активизации очередного процесса в специальный регистр процессора загружается адрес таблицы страниц данного процесса.
Свопинг при страничном распределении:
При каждом обращении к памяти происходит чтение из таблицы страниц информации о виртуальной странице, к которой произошло обращение. Если данная виртуальная страница находится в ОП, то выполняется преобразование ВА в ФА. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди готовых. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу и пытается загрузить ее в ОП. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то решается вопрос, какую страницу следует выгрузить из ОП.
преобразование ВА в ФА:
Виртуальный адрес при страничном распределении может быть представлен в виде пары (p, s), где p - номер виртуальной страницы процесса (нумерация страниц начинается с 0), а s - смещение в пределах виртуальной страницы. Учитывая, что размер страницы равен 2 в степени k, смещение s может быть получено простым отделением k младших разрядов в двоичной записи виртуального адреса. Оставшиеся старшие разряды представляют собой двоичную запись номера страницы p.

На основании начального адреса таблицы страниц, номера виртуальной страницы и длины записи в таблице страниц определяется адрес нужной записи в таблице,
Из этой записи извлекается номер физической страницы,
К номеру физической страницы присоединяется смещение.
Выбор размера страницы:
При малых страницах:
- меньшая внутренняя фрагментация страниц и повышается эффективность использования оперативной памяти;
- снижаются расходы времени на свопинг страниц (так как больше страниц помещаются в памяти);
При больших страницах:
- меньшие затраты на поиск и управление страницами (таблицы имеют меньший размер);
- выше эффективность обмена с внешней памятью.
Достоинства и недостатки страничного распределения:
Использование страниц размером кратным равен степени 2, позволяет применить операцию конкатенации (присоединения) вместо более длительной операции сложения, что уменьшает время получения ФА. На производительность системы со страничной организацией памяти влияют временные затраты, связанные с обработкой страничных прерываний и преобразованием ВА в ФА. Время преобразования виртуального адреса в физический в значительной степени определяется временем доступа к таблице страниц. В связи с этим таблицу страниц стремятся размещать в "быстрых" запоминающих устройствах. Это может быть, например, набор специальных регистров или память, использующая для уменьшения времени доступа ассоциативный поиск и кэширование данных.
- сегментное распределение;
При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным.
Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение.
Кроме того, разбиение программы на "осмысленные" части делает принципиально возможным разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же математическую подпрограмму, то в оперативную память может быть загружена только одна копия этой подпрограммы.
ВАП процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов ОС подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки.
Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если ВАП нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок ОП, в который данный сегмент загружается в единственном экземпляре.
Сегментное распределение: преобразование ВА в ФА
Система с сегментной организацией функционирует аналогично системе со страничной организацией: время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются, при каждом обращении к оперативной памяти выполняется преобразование ВА в ФА. Кроме того, при обращении к памяти проверяется, разрешен ли доступ требуемого типа к данному сегменту.
Виртуальный адрес при сегментной организации памяти может быть представлен парой (S#, d), где S# - номер сегмента, а d - смещение в сегменте. Физический адрес получается путем сложения начального физического адреса сегмента base, найденного в таблице сегментов по номеру S#, и смещения d.
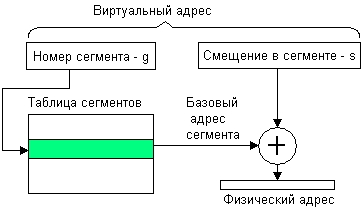
Недостатки сегментного распределения:
- Более медленное (по сравнению со страничным распределением) преобразование ВА в ФА в связи с использованием операции сложения.
- Высокий уровень фрагментации оперативной памяти.
- Сложность реализации свопинга, т.к. сегменты разного размера.
- сегментно-страничное распределение
Данный метод представляет собой комбинацию страничного и сегментного распределения памяти и, вследствие этого, сочетает в себе достоинства обоих подходов.
ВАП процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента.
Оперативная память делится на физические страницы.
Загрузка процесса выполняется ОС постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс.
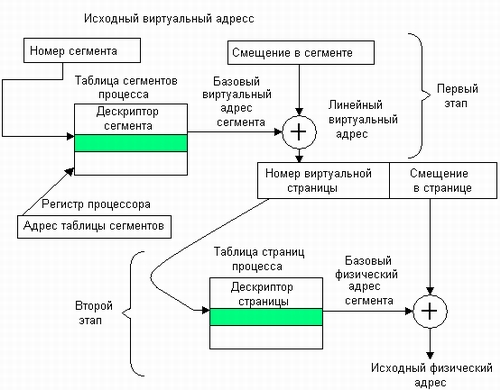
Преобразование ВА в ФА:
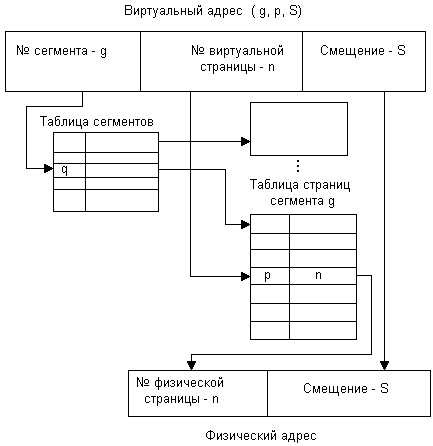

Общие выводы:
Страничная виртуальная память организует перемещение данных между памятью и диском страницами – частями ВАП фиксированного и сравнительно небольшого размера (достоинства – высокая скорость обмена, низкий уровень фрагментации; недостатки – сложно организовать защиту данных, разделенных на части механически);
Сегментная виртуальная память предусматривает перемещение данных сегментами – частями ВАП произвольного размера, полученными с учетом смыслового значения данных (достоинства – «осмысленность» сегментов упрощает их защиту; недостатки – медленное преобразование адреса, высокий уровень фрагментации);
Сегментно-страничная виртуальная память сочетает достоинства обоих предыдущих подходов.
Способы организации памяти без использования внешней памяти:
Распределение памяти фиксированными разделами:
Самым простым способом управления оперативной памятью является разделение ее на несколько
разделов фиксированного, но не обязательно равного размера, Этот способ иногда называется
Multiprogramming with a Fixed number of Tasks. Разбиение выполняется вручную оператором во время
старта системы или во время ее генерации. Очередная задача, поступившая на выполнение,
помещается либо в общую очередь (рисунок а), либо в очередь к некоторому разделу (рисунок б).
Подсистема управления памятью в этом случае выполняет следующие задачи:
сравнивая размер программы, поступившей на выполнение, и свободных разделов, выбирает подходящий раздел;
осуществляет загрузку программы и настройку адресов
 рисунки
а и б.
рисунки
а и б.
Недостатки распределения памяти фиксированными разделами:
При очевидном преимуществе – простоте реализации, данный метод имеет существенный недостаток – жесткость. Так как в каждом разделе может выполняться только одна программа, то уровень мультипрограммирования заранее ограничен числом разделов не зависимо от того, какой размер имеют программы (Multiprogramming with a Fixed number of Tasks).
Другим существенным недостатком является то, что предлагаемая схема сильно страдает от внутренней фрагментации – потери части памяти, выделенной процессу, но не используемой им. Фрагментация возникает потому, что процесс не полностью занимает выделенный ему раздел или потому, что некоторые разделы слишком малы для выполняемых пользовательских программ.
Распределение памяти разделами переменной величины:
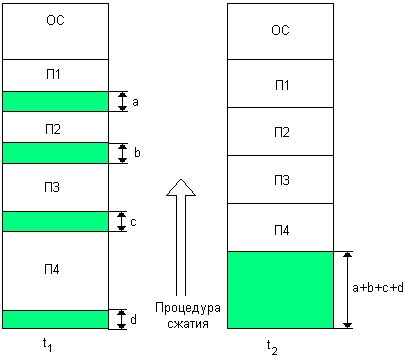
В этом случае память машины не делится заранее на разделы и исходно вся память считается свободной. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера.

На рисунке показано состояние памяти в различные моменты времени при использовании динамического распределения. В момент t0 в памяти находится только ОС, а к моменту t1 память разделена между 5-ю задачами, причем задача П4, завершаясь, покидает память. На освободившееся после задачи П4 место загружается задача П6, поступившая в момент t3.
Задачами операционной системы при реализации данного метода управления памятью является:
ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти;
при поступлении новой задачи - анализ запроса, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения поступившей задачи;
загрузка задачи в выделенный ей раздел (настройка адресов) и корректировка таблиц свободных и занятых областей;
после завершения задачи корректировка таблиц свободных и занятых областей.
Программный код не перемещается во время выполнения, то есть может быть проведена единовременная настройка адресов посредством использования перемещающего загрузчика.
Стратегии выбора раздела переменной величины:
В какой раздел помещать процесс? Наиболее распространены три стратегии.
Стратегия первого подходящего (First fit). Процесс помещается в первый подходящий по размеру раздел.
Стратегия наиболее подходящего (Best fit). Процесс помещается в тот раздел, где после его загрузки останется меньше всего свободного места.
Стратегия наименее подходящего (Worst fit). При помещении в самый большой раздел в нем остается достаточно места для возможного размещения еще одного процесса.
Моделирование показало, что доля полезно используемой памяти в первых двух случаях больше, при этом первый способ несколько быстрее. Попутно заметим, что перечисленные стратегии широко применяются и другими компонентами ОС, например, для размещения файлов на диске.
Достоинства и недостатки распределения памяти разделами переменной величины:
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток – фрагментация памяти.
Фрагментация в данном случае – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Распределение памяти перемещаемыми разделами:
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область (слайд). В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется "сжатием".
Сжатие может выполняться либо при каждом завершении задачи, либо только тогда, когда для вновь поступившей задачи нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц, а во втором – реже выполняется процедура сжатия.
Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то преобразование адресов должно выполняться динамическим способом.
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода
Защита памяти.
При мультипрограммном режиме работы ЭВМ в ее памяти одновременно могут находиться несколько независимых программ. Поэтому необходимы специальные меры по предотвращению или ограничению обращений одной программы к областям памяти, используемым другими программами.
Средства защиты при управлении памятью обычно выполняют:
проверку адреса ячейки памяти на корректность;
проверку разрешения доступа программы к адресуемой ячейке памяти;
проверку прав доступа (разрешенных операций) программы по отношению к ячейке памяти.
Основные классические подходы защиты:
защита отдельных ячеек памяти;
Защита отдельных ячеек памяти организуется в ЭВМ, предназначенных для работы в системах управления, где необходимо обеспечить возможность отладки новых программ без нарушения функционирования находящихся в памяти рабочих программ, управляющих технологическим процессом. Это может быть достигнуто выделением в каждой ячейке памяти специального "разряда защиты". Установка этого разряда в "1" запрещает производить запись в данную ячейку, что обеспечивает сохранение рабочих программ. Недостаток такого подхода – большая избыточность в кодировании информации из-за излишне мелкого уровня защищаемого объекта (ячейка).
В системах с мультипрограммной обработкой целесообразно организовывать защиту на уровне блоков памяти, выделяемых программам, а не отдельных ячеек.
Система со страничной организацией ATLAS предоставляла для каждого блока памяти однобитовый флаг-замок. Любая попытка получения доступа к «запертому» блоку приводила к прерыванию.
В страничной системе XDS 940 для каждой страницы виртуальной памяти был назначен однобитовый флаг rol. Если rol == 1, то блок используется только для чтения, иначе разрешен любой тип доступа.
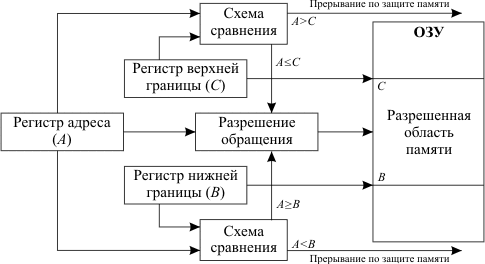
метод граничных регистров;
Метод граничных регистров реализовывает защиту по принципу «все или ничего» и заключается в использовании двух граничных регистров, указывающих верхнюю и нижнюю границы области памяти, куда программа имеет право доступа. Значения граничных регистров устанавливаются ОС при загрузке программы в память.
При каждом обращении к памяти проверяется, находится ли используемый адрес в установленных границах. При выходе за границы обращение к памяти не производится, а формируется запрос прерывания, передающий управление ОС.
Метод граничных регистров, обладая несомненной простотой реализации, имеет и определенные недостатки. Основным из них является то, что этот метод поддерживает работу лишь с непрерывными областями памяти.
Пример реализации – IBM 7090. Регистры верхней (UP) и нижней (LR) границы хранили допустимые верхний и нижний значения адресов.
метод ключей защиты;
Память в логическом отношении делится на одинаковые блоки, например, страницы. Операционная система каждому блоку памяти ставит в соответствие код, называемый ключом защиты памяти, а каждой программе присваивает код ключа программы.
Доступ программы к данному блоку памяти для чтения и записи разрешен, если ключи совпадают (то есть данный блок памяти относится к данной программе) или один из них имеет код «0» (код «0» присваивается программам операционной системы и общим блокам памяти).
Пример реализации – в IBM OS 360 для каждого 2KБ блока основной памяти был поставлен в соответствие 4-битовый ключ защиты. Реализовывался принцип защиты «все или ничего».
Развитием предыдущего способа (IBM OS 360/67) является использование дополнительно к ключу защиты еще одного флага – Разряда Режима Обращения (РРО).
В этом случае если при проверке ключ защиты и ключ программы не совпадает, то при значении РРО равном «0» все-таки разрешалось выполнить операцию чтения памяти, а при значении «1» доступ запрещается и выполняется прерывание.
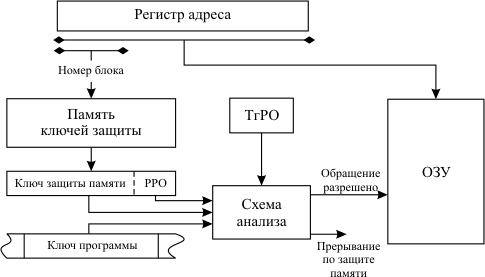
При обращении к памяти группа старших разрядов адреса ОЗУ, соответствующая номеру блока, к которому производится обращение, используется как адрес для выборки из памяти ключей защиты кода ключа защиты, присвоенного операционной системой данному блоку.
Схема анализа сравнивает ключ защиты блока памяти и ключ программы, находящийся в регистре слова состояния программы (ССП), и вырабатывает сигнал "Обращение разрешено" или сигнал "Прерывание по защите памяти". При этом учитываются значения режима обращения к ОЗУ (запись или считывание), указываемого триггером режима обращения ТгРО, и режима защиты, установленного в разряде режима обращения (РРО) ключа защиты памяти.
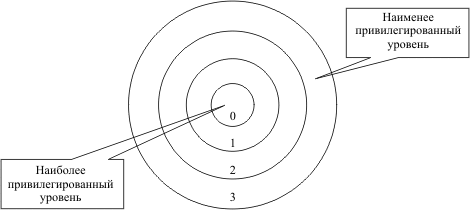
защита памяти по привилегиям.
В случае реализации защиты по привилегиям обычно реализуется уровневая (кольцевая) модель при которой более менее привилегированные программы не имеют доступа к ячейкам памяти более привилегированных программ.
метод матрицы доступа.
Развитием метода ключей защиты следует считать реализацию в системе SCC6700 матрицы доступа. Каждый процесс имел такую матрицу, определяющую защиту доступа к его сегментам.
Элемент aij этой матрицы определял тип доступа, разрешенный сегменту i к сегменту j :

Свопинг.
Для того, чтобы обеспечить все линейное адресное пространство процесса физическими ячейками памяти, Windows применяет свопинг. Организацией свопинга занимается VMM. При генерации системы на диске образуется специальный файл свопинга, куда записываются те страницы, которым не находится места в физической памяти. Процессы могут захватывать память в своем ВАП и, затем, использовать ее. Страница может иметь различные состояния. VMM использует локальный алгоритм LRU (Least Recently Used) – замещение дольше всех неиспользовавшихся страниц.
Стратегии управления виртуальной памятью:
Стратегия выборки (fetch policy) .
Выборка определяет, в какой момент необходимо переписать страницу с диска в ОП.
В Windows используется классическая схема выборки с упреждением: система переписывает в память не только выбранную страницу, но и несколько следующих по принципу пространственной локальности, гласящему: наиболее вероятным является обращение к тем ячейкам памяти, которые находятся в непосредственной близости от ячейки, к которой производится обращение в настоящий момент. Поэтому вероятность того, что будут востребованы последовательные страницы, достаточна высока. Их упреждающая подкачка позволяет снизить накладные расходы, связанные с обработкой прерываний
Стратегия размещения (placement policy).
Размещение определяет, в какое место оперативной памяти необходимо поместить подгружаемую страницу. Для систем со страничной организацией данная стратегия практически не имеет никакого значения, и поэтому Windows выбирает первую попавшуюся свободную страницу.
Стратегия замещения (replacement policy).
Замещение начинает действовать с того момента, когда в оперативной памяти компьютера не остается свободного места для размещения подгружаемой страницы. В этом случае необходимо решить, какую страницу вытеснить из физической памяти в файл подкачки (свопинг).
Реализация свопинга:

Реализация алгоритма замещения LRU:
VMM периодически просматривает список страниц с атрибутом Valid и пытается похитить их у процесса (1). Он помечает их как отсутствующие (P=0), но на самом деле оставляет их на месте, только переводит в разряд Modified или Standby в зависимости от значения бита D из PTE.
Если содержимое страницы была изменено в ОП (D=1), то VMM выполнит запись страницы на диск (4).
Если похищенная страница принадлежит рабочему множеству, то к ней в ближайшее время произойдет обращение. Это, конечно, вызовет исключение - ведь страница-то помечена как отсутствующая. Но VMM очень быстро сделает эту страницу вновь доступной процессу, поскольку она реально находится в памяти (2).
Далее если к странице не будет обращений (страница вне рабочего множества), то она со временем перейдет в состояние Free (5) и станет доступна для замещения страниц в рамках данного процесса (6).
Затем системный поток обнуляет страницу – Zeroed (7), и она станет доступна другим процессам системы (8).
Реализация алгоритма оптимального замещения:
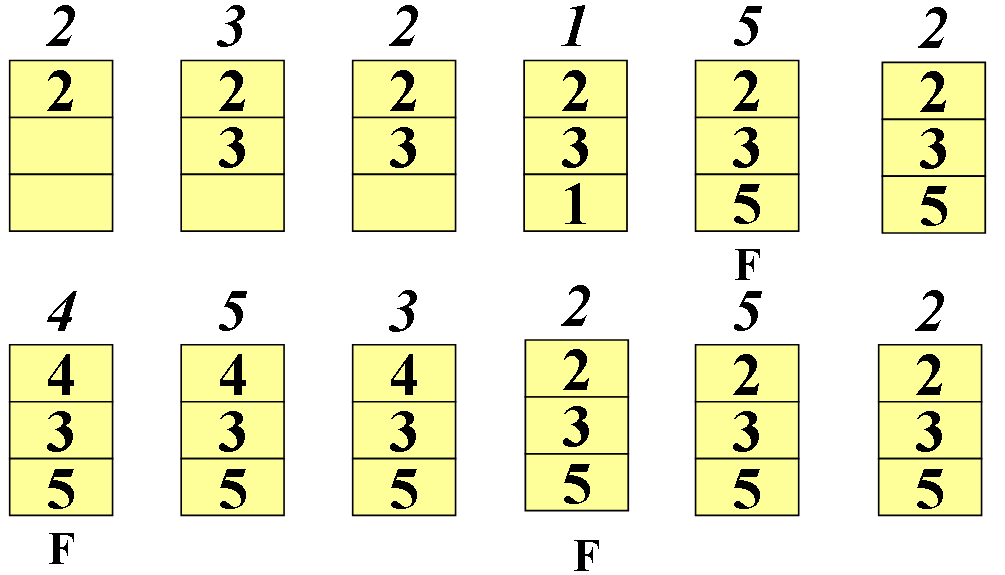
1’st page fault : страница 1 была вытеснена и заменена страницей 5, т.к. страница 1 в будущем больше не будет вызываться.
2’nd page fault: страница 2 была вытеснена и заменена страницей 4, т.к. страница 2 будет вызвана позже чем остальные две страницы (страницы 5 и 3).
3’rd page fault: страница 4 была вытеснена и заменена страницей 2, т.к. страница 4 в будущем больше не будет вызываться.
Алгоритмы замещения страниц (свопинга):
Глобальные – оперируют всей совокупностью страниц оперативной памяти.
Локальные – оперируют множеством страниц оперативной памяти, принадлежащих конкретному процессу.
FIFO (First In First Out) – замещение первой использованной страницы
FIFO 2nd Chance (похож на clock)
LRU (Least Recently Used) – замещение дольше всех неиспользовавшихся страниц
NRU (Not Recently Used) или clock – замещение не использовавшихся в последнее время страницы
NFU (Not Frequently Used) – замещение наименее часто используемых страниц
Пример действия FIFO:

FIFO 2nd Chance:
Модификация алгоритма FIFO, которая использовалась в ранних версиях UNIX. Позволяет избежать потери часто используемых страниц с помощью анализа признака использования R для самой «старой» страницы.
Если признак установлен (R = 1), то страница, в отличие от FIFO, не выталкивается, а очищается бит (R = 0) и страница становится в конец очереди.
Недостаток – недостаточная эффективность алгоритма, потому что постоянно передвигает страницы по списку. Поэтому лучше хранить описания страничных блоков в виде кольцевого списка и использовать указатель на старейшую страницу – алгоритм NRU (clock).
Алгоритм LRU:
Для замещения выбирается дольше всего неиспользовавшаяся страница. Часто используется и считается хорошим.
Основная проблема – реализация (требуется аппаратная поддержка).

Реализация LRU №1:
Основана на использовании специального признака обращения (reference bit) к странице (требуется аппаратная поддержка).
Каждой странице назначается свой счетчик обращений.
С некоторым постоянным временным интервалом для каждой страницы выполняется:
если признак обращения = 0 (страница не использовалась), увеличить счетчик на 1;
если признак обращения = 1 (страница использовалась), обнулить счетчик;
сбросить признак обращения.
Счетчик будет содержать число интервалов, в течение которых страница не использовалась, страница с максимальным значение счетчика – дольше всего не использовавшаяся.
Реализация LRU №2:
В некоторых архитектурах (например, Intel) признак обращения отсутствует. Для эмуляции признака обращения можно использовать признак достоверности (valid bit), сбрасывая его для возникновения «псевдосбоев» страниц – пример ОС Windows 2000-2008.
Недостаток – огромное количество дополнительных страничных прерываний.
NRU или clock:
все страничные кадры ОП выстраиваются в один большой круг (часы) реализуемый обычным кольцевым списком;
“стрелка часов” указывает следующего кандидата на вытеснение движется по списку страниц как стрелка часов;
если признак обращения сброшен, значит, страница давно не использовалась, и она – подходящая жертва;
если признак обращения установлен, он сбрасывается, и стрелка переводится на следующую страницу.
Особенности:
чем чаще требуются страницы, тем быстрее движется стрелка;
при достаточно большом объеме памяти дополнительные расходы невелики;
если памяти очень много, точность используемой информации снижается и приходится использовать еще одну стрелку для сброса признаков обращения

NFU (Not Frequently Used):
Программная реализация алгоритма, близкого к LRU, - алгоритм NFU.
Для него требуются программные счетчики, по одному на каждую страницу, которые сначала равны нулю. При каждом прерывании по времени ОС сканирует все страницы в памяти и у каждой страницы с установленным флагом обращения увеличивает на единицу значение счетчика, а флаг обращения сбрасывает. Таким образом, кандидатом на освобождение оказывается страница с наименьшим значением счетчика, как страница, к которой реже всего обращались. Главный недостаток алгоритма NFU состоит в том, что он ничего не забывает. Например, страница, к которой очень часто обращались в течение некоторого времени, а потом обращаться перестали, все равно не будет удалена из памяти, потому что ее счетчик содержит большую величину (глубина истории ограничена разрядностью счетчика). Возможна небольшая модификация алгоритма, которая позволяет ему "забывать". Достаточно, чтобы при каждом прерывании по времени содержимое счетчика сдвигалось вправо на 1 бит, а уже затем производилось бы его увеличение для страниц с установленным флагом обращения. Другим, уже более устойчивым недостатком алгоритма является длительность процесса сканирования таблиц страниц.
Понятие «trashing».
Высокая частота страничных прерываний называется трешинг (thrashing).
Процесс находится в состоянии трешинга, если он занимается подкачкой страниц больше времени, чем выполнением. Критическая ситуация такого рода возникает вне зависимости от конкретных алгоритмов замещения. В результате все процессы попадают в очередь запросов на свопинг, а очередь процессов в состоянии готовности пустеет. ОС видит это и постепенно увеличивает степень мультипрограммирования. Таким образом, пропускная способность системы падает из-за трешинга.
Решение проблемы trashing:
Эффект трешинга, возникающий при использовании глобальных алгоритмов, может быть ограничен за счет использования локальных алгоритмов замещения. В этом случае если даже один из процессов попадает в трешинг, это напрямую не сказывается на других процессах. Однако этот процесс много времени проводит в очереди на свопинг своих страниц, затрудняя подкачку страниц остальных процессов.