

Тема 1.2 Трансляторы, компиляторы и интерпретаторы — общая схема работы
Определение транслятора
Транслятор — это программа, которая переводит программу на исходном (входном) языке в эквивалентную ей программу на результирующем (выходном) языке.
В этом определении слово «программа» встречается три раза. Действительно, в работе транслятора участвуют три программы.
Во-первых, сам транслятор является программой. То есть транслятор — это часть программного обеспечения (ПО), он представляет собой набор машинных команд и данных и выполняется компьютером, как и все прочие программы, в рамках операционной системы (ОС). Все составные части транслятора представляют собой динамически загружаемые библиотеки или модули этой программы со своими входными и выходными данными.
Во-вторых, исходными данными для работы транслятора служит программа на исходном языке программирования — некоторая последовательность предложений входного языка. Эта программа называется входной, или исходной, программой. Обычно это символьный файл, но этот файл должен содержать текст программы, удовлетворяющий синтаксическим и семантическим требованиям входного языка. Кроме того, этот файл несет в себе некоторый смысл, определяемый семантикой входного языка. Часто файл, содержащий текст исходной программы, называют исходным файлом.
В-третьих, выходными данными транслятора является программа на результирующем языке. Эта программа называется результирующей программой. Результирующая программа строится по синтаксическим правилам выходного языка транслятора, а ее смысл определяется семантикой выходного языка.
Важным пунктом в определении транслятора является эквивалентность исходной и результирующей программ. Эквивалентность этих двух программ означает совпадение их смысла с точки зрения семантики входного языка (для исходной программы) и семантики выходного языка (для результирующей программы). Без выполнения этого требования сам транслятор теряет всякий практический смысл.
Итак, чтобы создать транслятор, необходимо, прежде всего, выбрать входной и выходной языки. С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик. Например, трансляция программы с языка С в язык ассемблера по сути ничем не отличается от перевода, скажем, с русского языка на английский, с той лишь разницей, что сложность языков несколько иная. Поэтому и само слово «транслятор» (англ.: translator) означает «переводчик».
Результатом работы транслятора будет результирующая программа, но только в том случае, если текст исходной программы является правильным — не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа неправильная (содержит хотя бы одну ошибку), то результатом работы транслятора будет сообщение об ошибке (как правило, с дополнительными пояснениями и указанием места ошибки в исходной программе). В этом смысле транслятор сродни переводчику, например, с английского, которому подсунули неверный текст.
Определение компилятора. Отличие компилятора от транслятора
Кроме понятия «транслятор» широко употребляется также близкое ему по смыслу понятие «компилятор».
Компилятор — это транслятор, который осуществляет перевод исходной программы в эквивалентную ей результирующую программу на языке машинных команд или на языке ассемблера.
Таким образом, компилятор отличается от транслятора лишь тем, что его результирующая программа всегда должна быть написана на языке машинных кодов или на языке ассемблера. Результирующая программа транслятора, в общем случае, может быть написана на любом языке — возможен, например, транслятор программ с языка Pascal на язык С.
ВНИМАНИЕ
Всякий компилятор является транслятором, но не наоборот — не всякий транслятор будет компилятором. Например, упомянутый выше транслятор с языка Pascal на С компилятором не является.
------------------------------------------------------------------------------------------------------------------------
Результирующая программа компилятора называется объектной программой, или объектным кодом, а исходную программу в этом случае часто называют исходным кодом. Файл, в который записана объектная программа, обычно называется объектным файлом. Даже в том случае, когда результирующая программа порождается на языке машинных команд, между объектной программой (объектным файлом) и исполняемой программой (исполняемым файлом) есть существенная разница. Порожденная компилятором программа не может непосредственно выполняться на компьютере.
Само слово «компилятор» происходит от английского термина «compiler» («составитель», «компоновщик»). Термин обязан своему происхождению способности компиляторов составлять объектную программу из фрагментов машинных кодов, соответствующих синтаксическим конструкциям исходной программы. Поскольку первоначально компиляторы ничего другого делать не умели, то этот термин и закрепился за ними.
Результирующая программа, созданная компилятором, строится на языке машинных кодов или ассемблера, то есть на языках, которые обязательно ориентированы на определенную вычислительную систему. Следовательно, такая результирующая программа всегда предназначена для выполнения на вычислительной системе с определенной архитектурой.
Вычислительная система, на которой выполняется результирующая (объектная) программа, созданная компилятором, называется целевой вычислительной системой.
В понятие целевой вычислительной системы входит не только архитектура аппаратных средств компьютера, но и операционная система, а зачастую также и набор динамически подключаемых библиотек, которые необходимы для выполнения объектной программы. При этом следует помнить, что объектная программа ориентирована на целевую вычислительную систему, но не может быть непосредственно выполнена на ней без дополнительной обработки.
Целевая вычислительная система не всегда является той же вычислительной системой, на которой работает сам компилятор. Часто они совпадают, но бывает так, что компилятор работает под управлением вычислительной системы одного типа, а строит объектные программы, предназначенные для выполнения на вычислительных системах совсем другого типа.
Компиляторы, безусловно, самый распространенный вид трансляторов (многие считают их вообще единственным видом трансляторов, хотя это и не так). Они имеют самое широкое практическое применение, которым обязаны широкому распространению всевозможных языков программирования. Далее всегда будем говорить о компиляторах, подразумевая, что результирующая программа порождается на языке машинных кодов или языке ассемблера.
Естественно, трансляторы и компиляторы, как и все прочие программы, разрабатывают люди — обычно это группа разработчиков. В принципе, они могли бы создавать его непосредственно на языке машинных команд, однако объем кода и данных современных компиляторов таков, что их создание на языке машинных команд практически невозможно в разумные сроки при разумных трудозатратах. Поэтому практически все современные компиляторы также создаются с помощью компиляторов (чаще всего в этой роли выступают предыдущие версии компиляторов той же фирмы-производителя). И в этом качестве компилятор является результирующей программой для другого компилятора, которая ничем не отличается от всех прочих порождаемых результирующих программ1.
Определение интерпретатора. Разница между интерпретаторами и трансляторами
Кроме схожих между собой понятий «транслятор» и «компилятор» существует принципиально отличное от них понятие интерпретатора.
Интерпретатор — это программа, которая воспринимает исходную программу на входном (исходном) языке и выполняет ее.
Интерпретатор, так же как и транслятор, анализирует текст исходной программы. Однако он не порождает результирующую программу, а сразу же выполняет исходную в соответствии с ее смыслом, заданным семантикой входного языка. Таким образом, результатом работы интерпретатора будет результат, определенный смыслом исходной программы, в том случае, если эта программа синтаксически и семантически правильная с точки зрения входного языка программирования, или сообщение об ошибке в противном случае.
ВНИМАНИЕ
В отличие от трансляторов, интерпретаторы не порождают результирующую программу — в этом принципиальная разница между ними.
Чтобы исполнить исходную программу, интерпретатор так или иначе должен преобразовать ее в язык машинных кодов, поскольку иначе выполнение программ на компьютере невозможно. Он, конечно же, делает это, однако полученные машинные коды не являются доступными — их не видит пользователь интерпретатора. Эти машинные коды порождаются интерпретатором, исполняются и уничтожаются по мере надобности — так, как того требует конкретная реализация интерпретатора. Пользователь же видит результат выполнения этих кодов — то есть результат выполнения исходной программы (требование об эквивалентности исходной программы и порожденных машинных кодов и в этом случае, безусловно, должно выполняться).
Этапы трансляции. Общая схема работы транслятора
На рис. 1 представлена общая схема работы компилятора. Из нее видно, что в целом процесс компиляции состоит из двух основных этапов — анализа и синтеза.
На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит некое внутреннее представление программы, понятное компилятору.
На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код.
Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки.
Эти этапы, в свою очередь, состоят из более мелких этапов, называемых фазами компиляции. Состав фаз компиляции на рис. 1 приведен в самом общем виде, их конкретная реализация и процесс взаимодействия могут конечно, различаться в зависимости от версии компилятора. Однако в том или ином виде все представленные фазы практически всегда присутствуют в каждом конкретном компиляторе.
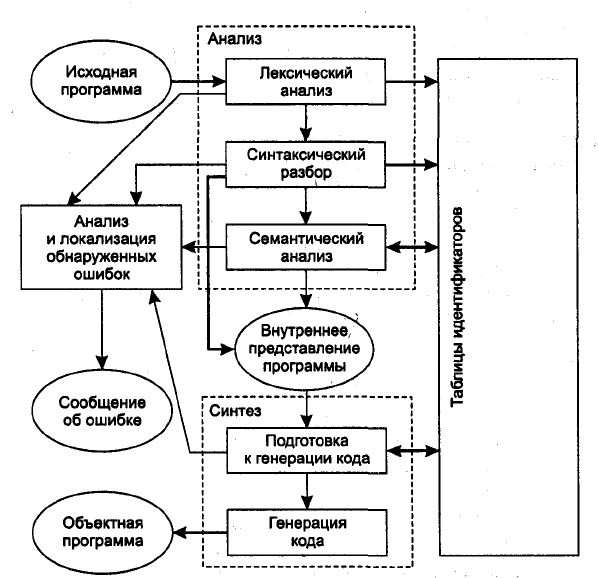
Рис. 1 - Общая схема работы компилятора
Компилятор выполняет две основные функции.
Во-первых, он является распознавателем для языка исходной программы. То есть он должен получить на вход цепочку символов входного языка, проверить ее принадлежность языку и, более того, выявить правила, по которым эта цепочка была построена. Интересно, что генератором цепочек входного языка выступает пользователь — автор исходной программы.
Во-вторых, компилятор является генератором для языка результирующей программы. Он должен построить на выходе цепочку выходного языка по определенным правилам, предполагаемым языком машинных команд или языком ассемблера. В случае машинных команд распознавателем этой цепочки будет выступать целевая вычислительная система, под которую создается результирующая программа.
Далее дается перечень основных фаз (частей) компиляции и краткое описание их функций.
Лексический анализ (сканер) — это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора. С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Однако существуют причины, которые определяют его присутствие практически во всех.
Синтаксический разбор — это основная часть компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы. Синтаксический разбор играет главную роль — роль распознавателя текста входного языка программирования.
Семантический анализ — это часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки семантический анализ должен выполнять преобразования текста, требуемые семантикой входного языка (например, такие, как добавление функций неявного преобразования типов). В различных реализациях компиляторов семантический анализ может частично входить в фазу синтаксического разбора, частично — в фазу подготовки к генерации кода.
Подготовка к генерации кода — это фаза, на которой компилятором выполняются предварительные действия, непосредственно связанные с синтезом текста результирующей программы, но еще не ведущие к порождению текста на выходном языке. Обычно в эту фазу входят действия, связанные с идентификацией элементов языка, распределением памяти и т. п.
Генерация кода — это фаза, непосредственно связанная с порождением команд, составляющих предложения выходного языка и в целом текст результирующей программы. Это основная фаза на этапе синтеза результирующей программы. Кроме непосредственного порождения текста результирующей программы генерация обычно включает в себя также оптимизацию — процесс, связанный с обработкой уже порожденного текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает существенное влияние на качество и эффективность результирующей программы.
Таблицы идентификаторов (иногда — «таблицы символов») — это специальным образом организованные наборы данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы. В конкретной реализации компилятора может быть как одна, так и несколько таблиц идентификаторов. Элементами исходной программы, информацию о которых необходимо хранить в процессе компиляции, являются переменные, константы, функции и т. п. — конкретный состав набора элементов зависит от используемого входного языка программирования. Понятие «таблицы» вовсе не предполагает, что это хранилище данных должно быть организовано именно в виде таблиц или других массивов информации — возможные методы их организации подробно рассмотрены далее.
Понятие прохода. Многопроходные и однопроходные компиляторы
Как уже было сказано, процесс компиляции программ состоит из нескольких фаз. В реальных компиляторах состав этих фаз может несколько отличаться от рассмотренного выше — некоторые из них могут быть разбиты на составляющие, другие, напротив, объединены в одну фазу. Порядок выполнения фаз компиляции также может меняться в разных вариантах компиляторов. В одном случае компилятор просматривает текст исходной программы, сразу выполняет все фазы компиляции и получает результат — объектный код. В другом варианте он выполняет над исходным текстом только некоторые из фаз компиляции и получает не конечный результат, а набор некоторых промежуточных данных. Эти данные затем снова подвергаются обработке, причем этот процесс может повторяться несколько раз.
Реальные компиляторы, как правило, выполняют трансляцию текста исходной программы за несколько проходов.
Проход — это процесс последовательного чтения компилятором данных из внешней памяти, их обработки и помещения результата работы во внешнюю память. Чаще всего один проход включает в себя выполнение одной или нескольких фаз компиляции. Результатом промежуточных проходов является внутреннее представление исходной программы, результатом последнего прохода — объектная программа.
В качестве внешней памяти могут выступать любые носители информации — оперативная память компьютера, накопители на магнитных дисках, магнитных лентах и т. п. Современные компиляторы, как правило, стремятся максимально использовать для хранения данных оперативную память компьютера, и только при недостатке объема доступной памяти используются накопители на жестких магнитных дисках. Другие носители информации в современных компиляторах не используются из-за невысокой скорости обмена данными.
При выполнении каждого прохода компилятору доступна информация, полученная в результате всех предыдущих проходов. Как правило, он стремится использовать в первую очередь только информацию, полученную на проходе, непосредственно предшествовавшем текущему, но, в принципе, может обращаться и к данным от более ранних проходов вплоть до исходного текста программы. Информация, получаемая компилятором при выполнении проходов, недоступна пользователю. Она либо хранится в оперативной памяти, которая освобождается компилятором после завершения процесса трансляции, либо оформляется в виде временных файлов на диске, которые также уничтожаются после завершения работы компилятора. Поэтому человек, работающий с компилятором, может даже не знать, сколько проходов выполняет компилятор — он всегда видит только текст исходной программы и результирующую объектную программу. Но количество выполняемых проходов — это важная техническая характеристика компилятора, солидные фирмы-разработчики компиляторов обычно указывают ее в описании своего продукта.
Понятно, что разработчики стремятся максимально сократить количество проходов, выполняемых компиляторами. При этом увеличивается скорость работы компилятора, сокращается объем необходимой ему памяти. Однопроходный компилятор, получающий на вход исходную программу и сразу же порождающий результирующую объектную программу, — это идеальный вариант.
Однако сократить число проходов не всегда удается. Количество необходимых проходов определяется прежде всего грамматикой и семантическими правилами исходного языка. Чем сложнее грамматика языка и чем больше вариантов предполагают семантические правила — тем больше проходов будет выполнять компилятор. Например, именно поэтому обычно компиляторы с языка Pascal работают быстрее, чем компиляторы с языка С — грамматика Pascal более проста, а семантические правила более жесткие.
Однопроходные компиляторы — редкость, они возможны только для очень простых языков. Реальные компиляторы выполняют, как правило, от двух до пяти проходов. Таким образом, реальные компиляторы являются многопроходными. Наиболее распространены двух- и трехпроходные компиляторы, например: первый проход — лексический анализ, второй — синтаксический разбор и семантический анализ, третий — генерация и оптимизация кода. В современных системах программирования нередко первый проход компилятора (лексический анализ кода) выполняется параллельно с редактированием кода исходной программы.
Интерпретаторы. Особенности построения интерпретаторов
Интерпретатор — это программа, которая воспринимает исходную программу на входном (исходном) языке и выполняет ее. Как уже было сказано выше, основное отличие интерпретаторов от трансляторов и компиляторов заключается в том, что интерпретатор не порождает результирующую программу, а просто выполняет исходную программу.
Термин «интерпретатор» (interpreter), как и «транслятор», означает «переводчик». С точки зрения терминологии эти понятия схожи, но с точки зрения теории формальных языков и компиляции между ними существует принципиальная разница. Если понятия «транслятор» и «компилятор» почти неразличимы, то с понятием «интерпретатор» их путать никак нельзя.
Простейшим способом реализации интерпретатора можно было бы считать вариант, когда исходная программа сначала полностью транслируется в машинные команды, а затем сразу же выполняется. В такой реализации интерпретатор, по сути, мало чем отличается от компилятора с той лишь разницей, что результирующая программа в нем недоступна пользователю. Недостатком такого интерпретатора является то, что пользователь должен ждать компиляции всей исходной программы прежде, чем начнется ее выполнение. По сути, в таком интерпретаторе не было бы никакого особого смысла — он не давал бы никаких преимуществ по сравнению с аналогичным компилятором.
Поэтому подавляющее большинство интерпретаторов действуют так, что исполняют исходную программу последовательно, по мере ее поступления на вход интерпретатора. Тогда пользователю не надо ждать завершения компиляции всей исходной программы. Более того, он может последовательно вводить исходную программу и тут же наблюдать результат ее выполнения по мере поступления.
При таком порядке работы интерпретатора проявляется существенная особенность, которая отличает его от компилятора, — если интерпретатор исполняет команды по мере их поступления, то он не может выполнять оптимизацию исходной программы. Следовательно, фаза оптимизации в общей структуре интерпретатора будет отсутствовать. В остальном же структура интерпретатора будет мало отличаться от структуры аналогичного компилятора. Следует только учесть, что на последнем этапе — генерации кода — машинные команды не записываются в объектный файл, а выполняются по мере их порождения.
Далеко не все языки программирования допускают построение интерпретаторов, которые могли бы выполнять исходную программу по мере поступления команд. Для этого язык должен допускать возможность существования компилятора, выполняющего разбор исходной программы за один проход. Кроме того, язык не может интерпретироваться по мере поступления команд, если он допускает появление обращений к функциям и структурам данных раньше их непосредственного описания. Поэтому таким методом не могут интерпретироваться такие языки, как С и Pascal.
Отсутствие шага оптимизации ведет к тому, что выполнение программы с помощью интерпретатора является менее эффективным, чем с помощью аналогичного компилятора. Кроме того, при интерпретации исходная программа должна заново разбираться всякий раз при ее выполнении, в то время как при компиляции она разбирается только один раз, а после этого всегда используется объектный файл. Также очевидно, что объектный код будет исполняться всегда быстрее, чем происходит интерпретация аналогичной исходной программы. Таким образом, интерпретаторы всегда проигрывают компиляторам в производительности.
Преимуществом интерпретатора является независимость выполнения программы от архитектуры целевой вычислительной системы. В результате компиляции получается объектный код, который всегда ориентирован на определенную целевую вычислительную систему. Для перехода на другую целевую вычислительную систему исходную программу требуется откомпилировать заново. А для интерпретации программы необходимо иметь только ее исходный текст и интерпретатор с соответствующего языка.
Интерпретаторы долгое время значительно уступали в распространенности компиляторам. Как правило, интерпретаторы существовали для ограниченного круга относительно простых языков программирования (таких, например, как Basic). Высокопроизводительные профессиональные средства разработки программного обеспечения строились на основе компиляторов.
Новый импульс развитию интерпретаторов придало распространение глобальных вычислительных сетей. Такие сети могут включать в свой состав компьютеры различной архитектуры, и тогда требование единообразного выполнения на каждом из них текста исходной программы становится определяющим. Поэтому с развитием глобальных сетей и распространением всемирной сети Интернет появилось много новых систем, интерпретирующих текст исходной программы. Многие языки программирования, применяемые во всемирной сети, предполагают именно интерпретацию текста исходной программы без порождения объектного кода.
В современных системах программирования существуют реализации программного обеспечения, сочетающие в себе и функции компилятора, и функции интерпретатора — в зависимости от требований пользователя исходная программа либо компилируется, либо исполняется (интерпретируется). Кроме того, некоторые современные языки программирования предполагают две стадии разработки: сначала исходная программа компилируется в промежуточный код (некоторый язык низкого уровня), а затем этот результат компиляции выполняется с помощью интерпретатора данного промежуточного языка.
История интерпретаторов пока не столь богата, как история компиляторов. Как уже было сказано, изначально им не придавали большого значения, поскольку почти по всем параметрам они уступают компиляторам. Из известных языков, предполагавших интерпретацию, можно упомянуть разве что Basic, хотя большинству сейчас известна его компилируемая реализация Visual Basic, сделанная фирмой Microsoft. Тем не менее сейчас ситуация несколько изменилась, поскольку вопрос о переносимости программ и их аппаратно-платформенной независимости приобретает все большую актуальность с развитием сети Интернет (более подробно о принципах переносимости программного обеспечения и о программировании для глобальных сетей рассказано далее в главе 6 «Современные системы программирования»).
Широко распространенным примером интерпретируемого языка может служить HTML (Hypertext Markup Language) — язык описания гипертекста. На его основе в настоящее время функционирует практически вся структура сети Интернет. Другой пример — языки Java и JavaScript сочетают в себе функции компиляции и интерпретации (текст исходной программы компилируется в некоторый промежуточный код, не зависящий от архитектуры целевой вычислительной системы, этот код распространяется по сети и интерпретируется на принимающей стороне).