

24. Компьютерная лексикография. Типология электронных словарей.
Компьютерная лексикография
Современная лексикография существенно расширила и усилила свой инструментарий компьютерными технологиями создания и эксплуатации словарей. Специальные программы — базы данных, компьютерные картотеки, программы обработки текста — позволяют в автоматическом режиме формировать словарные статьи, хранить словарную информацию и обрабатывать ее. Множество различных компьютерных лексикографических программ можно разделить на две больших группы: программы поддержки лексикографических работ и автоматические словари (АС) различных типов, включающие лексикографические базы данных.
Компьютерные программы поддержки лексикографических работ. Работа лексикографа непосредственно связана со словами, примерами их употребления и словарными статьями создаваемого словаря. Традиционная форма фиксации словарных данных — каталожная карточка, в ко торой указывается описываемое слово, пример употребления, источник примера, автор, а также различная дополнительная информация. Современные компьютерные технологии позволяют упростить процесс сбора и хранения лексикографической информации, используя вместо обычной картотеки базу данных, записи которой представляют собой аналог традиционной каталожной карточки. В отличие от обычной картотеки, записи базы данных дают возможность автоматически сортировать массив по вы бранным параметрам, отбирать нужные примеры, объединять их в группы и т.д. Специализированных лексикографических баз данных — имеются в виду специальные программные оболочки — на рынке нет. Однако современные базы данных типа D-Base, ACCESS, FOX-Base, PARADOX вполне подходят для ведения электронных словарных картотек. Приведем пример записи базы данных по современной русской идиоматике, созданной в Институте русского языка РАН, которая поддерживается программой ACCESS.
ЗАПИСЬ 28982 ID {идиома} у черта на куличках EXAMPLE {пример}
А когда, например, Баранов позвонил Ефиму и сказал, что может угостить свежей телятиной, тот немедленно выскочил из дому, схватил такси и поперся к Баранову к черту на кулички в Беляево-Богородское вовсе не в расчете на отбивную или ростбиф, а приехав, получил на очень короткое время то, ради чего и ехал, — книгу Солженицына “Бодался теленок с дубом”.
SOURCE {источник} Шапка AUTH {автор} Войнович В.
Лексикографические базы данных фиксируют первичный лексикографический материал, который используется для написания словарных статей словаря.
Еще один важный этап лексикографической работы — поиск примеров на слово и формирование картотеки примеров. В традиционной технологии сбор примеров производится вручную и отнимает огромное количество времени. Современные компьютерные программы дают возможность выбирать примеры на нужное слово из корпусов текстов, хранящихся в машинном формате на компьютере, в автоматическом режиме. Поиск примеров на употребление слова называется построением конкордансов. Некоторые компьютерные программы построения конкордансов по желанию пользователя могут преобразовывать найденные контексты в записи базы данных. Например, программа DIALEX позволяет получать конкордансы как в традиционной форме (в виде файла для текстового редактора), так и в формате базы данных PARADOX.
После подготовки первичного словарного материала — словарной картотеки — непосредственно следует этап составления словарной статьи. Технологическая цепочка словарных работ и здесь не остается без компьютерной поддержки. Новая словарная статья вводится в базу данных, которая становится исходной базой данных создаваемого словаря. Редактирование словарных статей также происходит в базе данных, а не в обычном текстовом файле. Все это существенно сокращает время разработки словаря, поскольку упрощается обработка системы отсылок, в автоматическом режиме происходят сортировки (в том числе алфавитизация словарных статей), сравнительно легко порождаются различные указатели. Для редактирования словаря можно привлекать компьютерные программы проверки орфографии.
Наконец, последний этап — формирование текста словаря, создание оригинал-макета книги — также существенно облегчается. Технологическая цепочка и здесь не прерывается: существующее программное обеспечение позволяет выдать текстовый материал сразу из базы данных с разметкой под топографематические выделения. Поля записи базы данных трансформируются в автоматическом режиме в зоны словарной статьи с соответствующими шрифтами, кеглями, курсивом, подчеркиваниями и пр.
Ниже на рис. 2 представлены этапы лексикографической работы в традиционном варианте (А) и компьютерная технология создания словаря (Б). Разумеется, в каждом конкретном случае проекты создания словарей могут модифицировать стандартные схемы. Например, в некоторых случаях для сбора корпуса примеров могут использоваться не только корпусы текстов, но и лексикографические базы данных. Так, проект фразеологического словаря современного русского языка опирается не только на корпус текстов по современному русскому языку (включающий тексты художественной прозы, публицистики, детективной литературы), но и на базу данных по современной идиоматике, включающей в настоящее время около 50 тысяч контекстов употребления
Рис 2. Традиционная и компьютерная технология создания словаря
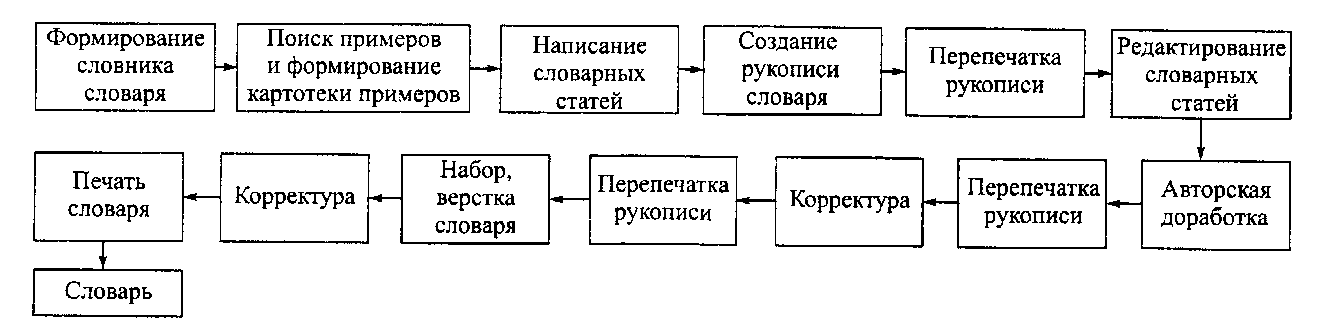
А. Традиционная технология
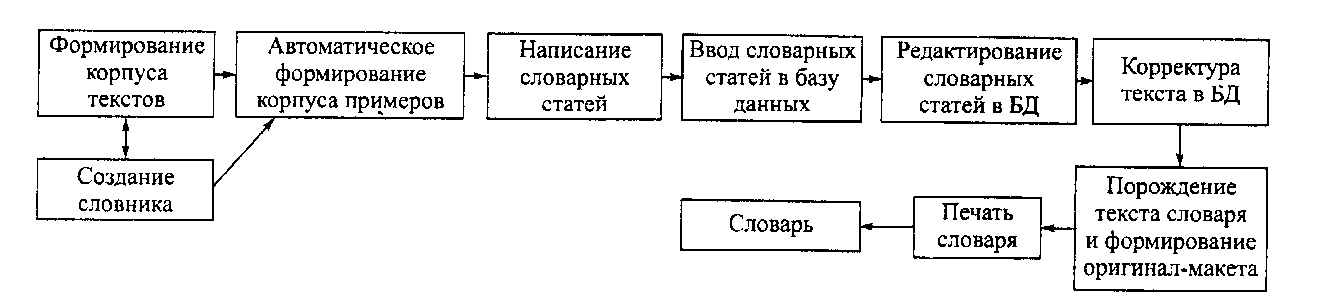
Б. Компьютерная технология
идиом [Баранов, Добровольский 1995]. Иными словами, корпус примеров формируется не только в результате обработки корпуса текстов, но и базы данных — см. рис, 3. Для словарей писателей может быть предусмотрен этап формирования корпуса текстов писателей-современников, необходимый для выявления различий между особенностями идиостиля данного автора и общими характеристиками языка соответствующей эпохи.
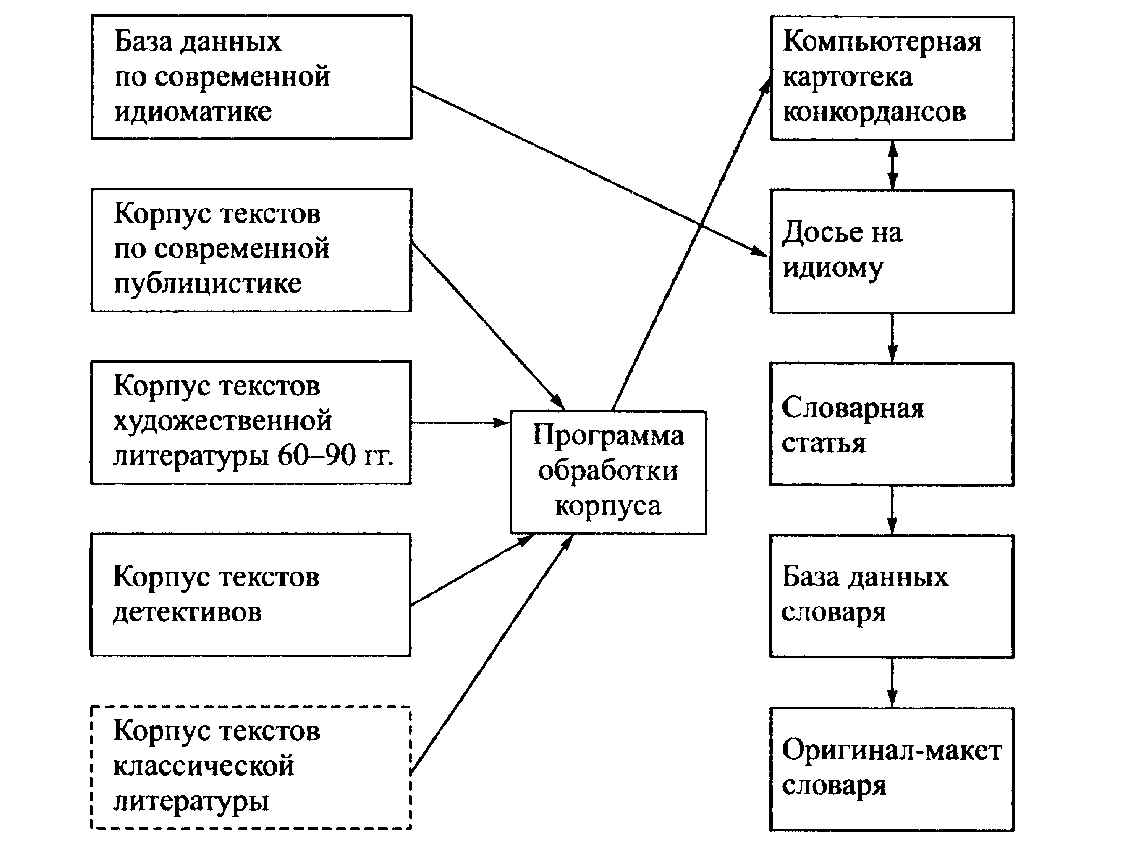
Рис. 3. Схема компьютерного обеспечения проекта Фразеологического словаря современного русского языка
Особо следует упомянуть о существовании издательских систем, используемых для создания оригинал-макета (верстки) словарей. К ним относятся, например, издательский пакет программ Quark-X-Press, различные версии программ Page-Maker и WinWord. Для словарной верстки наиболее удобны системы, имеющие встроенные языки, позволяющие формировать макросы — относительно простые, но технологически эффективные операции обработки редактируемого и верстаемого текста. К ним относятся процедуры приписывания стилей зонам словарной статьи, алфавитизации, создания указателей и т. п. Обратимость словарей
Под обратимостью переводного словаря мы понимаем возможность произвольно по желанию пользователя менять входной и выходной языки местами. Обратимость как рабочий прием достаточно часто используется в лексикографической практике для расширения целевой направленности словаря и круга его пользователей. Согласно определению, обратимый словарь должен иметь два разноязычных входа. Если смоделировать обратимый немецко-русский и русско-немецкий словарь на базе какого-либо конкретного немецко-русского словаря, то это означает, что в одном словаре два разноязычных входа будут иметь один выход - одну объяснительную часть, в этом примере - описание содержания лексики немецкого языка. Однако тем самым будет нарушено требование семантической эквивалентности словника и объяснительной части словаря, ибо в общем виде не может быть семантической эквивалентности между русскими словами и описанием содержания немецких слов, даже если между этими словами существуют отношения переводной эквивалентности. Значение слова как объект описания в словаре представляет собой составную сущность, включающую в себя абсолютную ценность (информация об обозначаемом внеязыковом факте), относительную ценность (информация о способности слова вступать в парадигматические отношения с другими словами, о его стилистической и статистической ценности, внутренней форме и др.) и сочетательную ценность (информация о способности слова сочетаться определенным образом с определенными словами). Переводной эквивалент в словарной статье переводного словаря фиксирует относительное равенство абсолютных ценностей двух разноязычных слов. Вся остальная информация в словарной статье - это сведения об относительной и сочетаемостной ценностях заголовочного слова, которые чаще всего не идентичны относительной и сочетательной ценностям его переводного эквивалента, так как эти ценности глубоко индивидуальны и существенно варьируются от слова к слову в пределах даже одного языка. Межъязыковые различия будут еще больше. Эти различия весьма существенны при описании однозначных слов или лексико-семантических вариантов многоязычных слов. Различия будут еще больше при описании многоязычных слов как единого целого. Поэтому столь непохожи друг на друга словарные статьи слов, связанных между собой отношением переводной эквивалентности, в разнонаправленных переводных словарях общей лексики, которые в целом сопоставимы по объему и по степени подробности описания значений входных лексических единиц.
Не всегда парные переводные словари составляются одним и тем же автором, как правило наоборот, разными авторами, которые не согласовывали между собой соответствующие словарные статьи, поэтому их непросто превратить в компьютерный обратимый словарь. Однако различия нетрудно заметить также в словарях, которые были построены как двуединое целое, состоящее из родно-иностранной и иностранно-родной частей. Можно отметить, что в переводных словарях заметна тенденция, которая проявляется в том, что чем подробнее описание, чем богаче словарная статья, тем больше расхождений между словарными статьями разноязычных слов, являющихся переводными эквивалентами друг друга. Вместе с тем стремление к экономии и расширению целевой направленности словаря ведет к тому, что лексикографы все чаще прибегают к использованию различных приемов для превращения словарей в обратимые словари. В некоторых многоязычных словарях один из языков является основным, стержневым, вокруг которого группируются другие языки. В словарной статье такого словаря заголовком является лексическая единица стержневого языка, лексические единицы остальных языков приводятся как переводные эквиваленты заглавного слова.
Широко принцип обратимости применяется в терминологической лексикографии. Это можно объяснить следующими причинами:
* терминологические словари ограничивают свою задачу описанием абсолютной ценности слова. Словарная статья терминологического словаря практически не содержит никакой другой информации, кроме переводных эквивалентов;
* проблема многозначности и омонимии в терминологии стоит не столь остро, как в общеупотребительной лексике;
* составители терминологических словарей предпочитают не включать с состав своих словарей многозначные слова, либо включают их в одном или двух значениях, которые они считают основными для выбранной тематики.
При таких условиях построение обратимого словаря не представляет технической сложности и не противоречит природе входного и выходного языков. По-другому обстоит дело в общей лексикографии, где снимаются все ограничения, существенно облегчающие задачу составителя терминологического словаря. Обратимые переводные словари обладают рядом свойств, которые существенно отличают их от однонаправленных переводных словарей:
* четко очерченная и узко функциональная направленность (словари учебные, лексической сочетаемости, терминологические);
* в словарных статьях таких словарей обычно описывается только один компонент значения заглавной единицы, чаще всего абсолютная или сочетательная ценность;
* в некоторых случаях описание значения заглавного слова или его компонента осуществляется не при помощи другого языка (выходного языка), а своими же собственными средствами (средствами входного языка), т.е. снимается или существенно уменьшается функциональная зависимость одного языка от другого.
Роль обратной связи в функционировании словаря
В обычных словарях обратная связь практически отсутствует. Для компьютерных электронных словарей она является одним из наиболее существенных признаков и оказывает заметное влияние на состав и структуру этих словарей, причем на структуру влияет в большей степени (в отличие от автономности). Обратная связь обеспечивает принципиальную переменность состава электронных словарей. Состав словаря определяется обратной связью, поскольку она допускает "пробность" информации к лексическим единицам. Можно включить в словарь какую-то информацию и в зависимости от результата, полученного при обработке текстов с помощью этого словаря, принять решение: либо эту информацию оставить в словаре и пополнить, либо исключить. Обычный словарь таким образом использован быть не может. Структура компьютерного словаря всецело определяется обратной связью. Однако это вовсе не означает, что электронный словарь абсолютно отличен от словаря на бумажном носителе. С одной стороны, даже структура его может быть такой же, как в обычном словаре, т.е. в ее основу может быть положен принцип алфавитного упорядочения лексических единиц, что способствует эффективности работы со словарем. С другой стороны, структура компьютерного словаря существенно отличается от структуры обычного, так как цель ее - в первую очередь обеспечить доступность любой части словаря и возможность постоянного внесения изменений и дополнений в его состав.
Гибкость словаря
Гибкость компьютерного словаря - это комплекс лингвистических и программных приемов, которые упрощают обращение к словарю, расширяют возможности пользователя при работе с иноязычным текстом, снижают требования к уровню знания входного языка, а также позволяют использовать автоматический компьютерный словарь не только для хранения лексических массивов, но и для решения других задач по автоматической обработке текстов и для автоматизации лексикографических работ. Наиболее важным средством повышения гибкости словаря является упрощение формы запроса, т.е. обращения к словарю. В традиционных переводных словарях форма обращения совпадает со словарной формой, т.е. с формой хранения лексических единиц в словаре. Словарная, каноническая, исходная форма слово - одна из словоформ, традиционно выбираемая в качестве представителя данной лексемы в словаре. Трудности определения словарной формы слова возникают даже в тех случаях, когда входной язык является для пользователя родным, но еще в большей степени возникают они при работе с неродными языками. Особенно эта проблема остро стоит для языков синтетического типа. Для русского языка наибольшие сложности возникают при обработке видовых форм глагола, причастий, супплетивных форм существительных, приставочных форм глаголов. В немецком языке такие трудности возникают при обработке сильных глаголов, форм существительных и прилагательных, образуемых с помощью умляута. Сложности усугубляются также тем, что несловарные формы слова встречаются в текстах значительно чаще, чем их словарные формы. В целом можно сказать, что выбор только одной словоформы в качестве представителя всей лексемы в традиционных словарях является вынужденным. С одной стороны это для лексикографа - достаточно удобное и экономное решение многих лингвистических проблем, но, с другой стороны, такое решение резко ограничивает количество входов в словарь, что в свою очередь снижает его ценность, так как качество словаря, помимо других его характеристик, находится в прямой зависимости от количества входов в этот словарь. Проблема сведения несловарных форм слова к словарным (лемматизация) столь же актуальна для автоматических словарей, как и для систем МП. Для решения проблем лемматизации в полном объеме используются разные методы. Основными среди них являются метод поискового массива словоформ и метод словаря основ с блоком морфологической обработки. Оба эти методы имеют свои положительные и отрицательные стороны.
Для немецкого словаря задача сведения текстовых форм к словарным решается на основе использования обоих подходов поискового массива словоформ (для существительных) и словаря основ (для прилагательных и глаголов). Выбор такого комбинированного способа решения проблемы лемматизации определяется особенностями словоизменительной системы немецкого языка. Язык достаточно экономен в именном словоизменении (не боле пяти графически разных форм для существительного). В то же время парадигма прилагательного может содержать до 14, а глагола - до 18 графических разных словоформ.
При использовании метода поискового массива словоформ в память заносятся все возможные словоформы лексем, включенных в словарь с отсылками к словарной форме, которая также включается в поисковый массив. Распознавание запроса осуществляется путем сравнения реализованной в тексте словоформы со словоформами поискового массива. Положительная сторона - запрашиваемая словоформа не подвергается никакому членению на составные части. Отрицательная сторона - повышенные требования к объему памяти.
Метод словаря основ предполагает распознавание запрашиваемой словоформы путем членения ее на составные части - основу и словоизменительную флексию. Затем следует отсылка к словарной форме запрошенной словоформы, которая хранится в памяти, либо синтез словарной формы из основы и соответствующей флексии. Использование этого метода предполагает создание алгоритма морфологической обработки со словарем основ и таблицами словоизменительных флексий. Отрицательной стороной данного подхода является более высокая по сравнению с методом поискового массива сложность лингвистических работ. Но этот подход позволяет решать большее количество задач и экономит память компьютера.
Проблема обращения к компьютерному словарю в естественной языковой форме является одной из основных при их построении. Без решения этой проблемы в полном объеме автоматический словарь не может претендовать на успешное решение своих основных задач - помощь человеку при работе с иноязычными текстами и автоматизацию лексикографических работ. В традиционной переводной лексикографии производные и сложные слова рассматриваются составителями словарей как существенный резерв компрессии словаря, которая может осуществляться двумя способами:
1. производное слово полностью отсутствует в словаре;
2. производное слово дается с отсылочным определением.
Однако в обоих случаях необходимо последовательно включать в словарь в качестве самостоятельных вокабул наиболее продуктивные словообразовательные элементы с толкованием их значений и возможными переводными эквивалентами.
В традиционной лексикографии существуют специальные словари словообразовательных элементов. Включение в компьютерный словарь всех производных элементов трудновыполнимо и нецелесообразно. Гораздо удобнее для каждого входящего в состав автоматического словаря языка иметь набор стандартных терминоэлементов с указанием их значений и/или способов передачи на других языках, сопряженный с механизмом их вычленения в составе запрашиваемых лексических единиц. Тот же самый механизм можно использовать для выделения традиционных словообразовательных аффиксов в составе не найденных в словаре лексических единиц.
Отказ от включения в состав автоматических компьютерных словарей производных и сложных слов целесообразен только в том случае, если после автоматического разбиения этих слов на производящую основу и словообразовательные элементы или покомпонентного разложения сложного слова пользователь получит ответ в виде словарной статьи производящей основы и словарных статей словообразовательных элементов или компонентов сложных слов с описанием их значений и переводными эквивалентами на выходном языке. Выбор правильного значения основы и словообразовательного элемента и соответствующих переводных эквивалентов ложится на самого пользователя.
Статичность традиционных словарей и динамичность компьютерных словарей
Одно из свойств традиционных "бумажных" словарей - их статичность, которая проявляется как на уровне состава словника словаря, так и на уровне содержания словарной статьи. Сложный характер лексикографических работ, редакционно-издательские, типографические, а также экономические факторы не позволяют переиздавать большие словари достаточно часто. По этим причинам переводные словари опаздывают в среднем на 5-6 лет с момента реального обогащения терминологии. Запаздывание с включением новой лексики отмечается переводчиками как один из основных недостатков традиционных словарей. Разные задачи и разные уровни языковой подготовки читателя словаря предъявляют разные требования к составу и объему информации в словарной статье словаря, что в свою очередь требует создания словарей разных типов. Так, в переводных словарях интенсивного типа словарная статья содержит помимо переводных эквивалентов, различные сведения семантического и стилистического характера о заглавном слове и его эквивалентах в выходном языке, примеры употребления, типовые и идиоматические словосочетания, синонимы, антонимы. Как правило, значительная часть этой информации для читателя с глубоким знанием языка оригинала избыточна. С другой стороны, в переводных технических словарях, которые в большинстве своем словари экстенсивного типа, словарная статья значительно беднее и в большинстве случаев не содержит практически никакой информации, кроме переводных эквивалентов, что для читателя со слабым или среднем уровнем знания языка оригинала, явно недостаточно. В условиях традиционной лексикографии это противоречие между уровнем языковой подготовки читателя и разнообразием задач и целей словаря, с одной стороны, и объемом и характером информации в словарной статье этого словаря - с другой, неразрешимо в рамках одного словаря из-за статичности "бумажных" словарей.
Компьютерные словари обладают свойством динамичности. Отбор лексики не прекращается перед составлением словаря, а продолжается в течение всего времени его функционирования. Постоянно происходит исключение оказавшихся ненужными слов и включение новой лексики, коррекция и пополнение информации в любой зоне словарной статьи. Переменность состава и способность воспринимать изменения в ходе функционирования являются принципиальными характеристиками, отличающими компьютерные словари от обычных. Практически любой пользователь при желании может пополнить словарь недостающими, по его мнению, словами.
Отбор лексики для компьютерных словарей
Отбор лексики для компьютерных словарей можно рассматривать в тех же аспектах, что и для обычных словарей, а именно:
- регистрация слов и их значений (терминов, словосочетаний);
- нормативность употребления;
- постоянство состава;
- цель словаря.
Отличия в отборе лексики для компьютерных и обычных словарей
Регистрация лексических единиц и их значений происходит в вычислительной лексикографии, занимающейся созданием собственно машинных словарей в рамках определенных подъязыков, которые задаются совокупностями текстов. Цель регистрации - обеспечить наилучшее выполнение информационным языком, частью которого является словарь, коммуникативной функции за счет отказа от всех других функций, присущих человеческому языку. Решающую роль в выборе лексических единиц и их значений играет целевое назначение данного конкретного машинного словаря. Первостепенное значение приобретает нормирующий аспект употребления слов. Неточный выбор исходного массива, неэффективность работы словаря немедленно обнаруживаются, так как при этом понижается эффективность работы информационной системы в целом.
Выбор лексических единиц производится с помощью формальных методов, наиболее распространенные из которых - количественные. Логико-интуитивный метод не имеет первостепенного значения, как, например, в традиционной лексикографии; он существенно дополняется объективными методами регистрации актуального для данной задачи словарного состава. Отбор лексики в машинные и автоматические словари более нормативен, чем отбор лексики в обычные словари. Это в значительной мере объясняется тем, что критерии нормы в традиционной и вычислительной лексикографии различны. В традиционной лексикографии норма носит характер неформализованных общих рекомендаций, применение которых к большим словарным массивам затруднительно. Критерии нормы для машинных словарей носят более прагматический характер. "Ненормированное" отличается от "нормированного" по результатам выдачи. Можно поэтому утверждать, что критерий нормы реализуется в вычислительной лексикографии с помощью обратной связи, и в этом принципиальное отличие вычислительной лексикографии от традиционной. Обратная связь касается не только отбора лексических единиц, но и отбора значений лексических единиц, поскольку, например, в информационной системе выдача зависит не только от того, какие дескрипторы включены в поисковый образ документа и в поисковое предписание, но и какое значение придается этим дескрипторам в машинном словаре информационного языка.
Постоянство словарного состава является важной особенностью обычного словаря. Само собой разумеется, что в традиционной лексикографии ценность словаря определяется устойчивостью употребления включенных в него слов. Отбор лексики для обычных словарей есть одноразовая операция предшествующая составлению словаря, дальнейшей работе над ним. В отличие от этого в компьютерных словарях отбор слов не прекращается перед составлением словаря, а продолжается в течение всего времени его функционирования. Подобным же образом происходит и исключение слов устарелых или оказавшихся ненужными. Как уже упоминалось, переменность состава компьютерного словаря находится в прямой зависимости от его назначения и позволяет начать построение словаря с некоторого экспериментального макета, который при обследовании новых текстов в качестве исходных "обрастает" новыми словами.
Отличия в составе и структуре словарей
Итак, с точки зрения состава словари как обычные, так и компьютерные ориентируются на одну и ту же исходную единицу - слово. Однако традиционная лексикография эксплицитно или имплицитно понимает слово как сложную языковую единицу, вызывающую в сознании человека-пользователя обширную сферу коннотаций. Основная задача словаря - дать информацию, дополнительную к имеющейся уже у пользователя. Эта дополнительная информация может быть незначительной или вообще отсутствовать для известного слова (если словарь не сообщает потребителю ничего нового) и может быть достаточно обширной, если потребитель не знал ранее данного слова и имеющейся при нем информации. Разумеется, эта задача по-разному реализуется различными типами словарей, предназначенными для человека. Слово для компьютерного словаря - совокупность знаков между двумя пробелами. Компьютерный словарь может реализовать различные способы конструирования (и анализа) единиц, меньших или больших чем слово (имеется в виду формальная протяженность). Он не может давать какую-либо дополнительную информацию, а должен давать основную для работы последующего алгоритма автоматической обработки текстов. Для компьютера существует только та информация, которая в нем записана, и эту исходную запись может осуществлять только словарь (или некоторое подобное словарю устройство, принципиально от него не отличающееся). Таким образом, основное отличие в составе словарей заключается в том, как определяется исходная словарная единица и словарная информация.
Отличительной чертой структуры компьютерных словарей является переменность состава, необходимость которой диктуется требованиями повышения эффективности их работы или новыми ее условиями. Чуждая логической и формальной структуре обычных словарей переменность состава компьютерного словаря обусловлена его организацией - способом записи и поиска по словарю, программами изменения и пополнения словарного состава и словарной информации. Структура компьютерного словаря должна наилучшим образом соответствовать задаче алгоритма, который производит заданную обработку текста. В связи с этим представляется не совсем точным (требующим пояснений) замечание В.П. Беркова о том, что обычный переводной двуязычный словарь должен также удовлетворять требованиям машинного перевода (Берков, 1973, 17). Чтобы добиться осуществления такого требования, нужно существенно пересмотреть и изменить структуру переводного словаря.