

|
ФИНАНСОВЫЙ УНИВЕРСИТЕТ ПРИ ПРАВИТЕЛЬСТВЕ РФ
|
|
Кафедра “Информатика и программирования” |
||

Синицын и.В., Чипчагов м.С. Курс лекций по дисциплине «Базы данных» для студентов, обучающихся по направлению 230700.62 «Прикладная информатика»
Москва
2012
УДК 681.306
ББК 32.073
Т34
Синицын И.В., Чипчагов М.С.
Т34 |
Курс лекций по дисциплине «Базы данных» для студентов, обучающихся по направлению 230700.62 «Прикладная информатика»
|
УДК 681.306
ББК 32.073
Т34
© Финансовый университет при правительстве РФ
© Синицын Иван Васильевич
© Чипчагов Михаил Сергеевич
Лекция 1
Базы данных и системы баз данных
Дисциплина «Базы данных» является общепрофессиональной дисциплиной и имеет целью ознакомить будущего специалиста с современной теорией баз данных, теорией и практикой их проектирования, с современными тенденциями развития систем управления базами данных.
В результате изучения дисциплины студент должен знать:
· принципы современной организации баз данных и систем баз данных;
· основные категории и понятия баз данных;
· реляционную модель представления данных;
· методы проектирования баз данных;
· современные технологии обработки данных;
· основы администрирования баз данных.
В результате изучения дисциплины студент должен уметь:
· строить модель предметной области и создать соответствующую ей базу данных;
· организовать обработку информации в базе данных;
· организовать обеспечение целостности базы данных;
· формулировать запросы к базе данных на языке QBE и SQL;
· организовать защиту базы данных.
В результате изучения дисциплины студент должен владеть:
· навыками работы в конкретной системе управления базами данных, научиться создавать основные объекты базы данных (таблицы, формы, отчеты);
· навыками реализации основных функций, необходимых для решения поставленной задачи;
· навыками создания приложений для работы с базой данных;
· навыками работы с распределенной базой данных;
· информационными технологиями, используемыми при решении реальных экономических задач.
Понятие базы данных и системы баз данных
С начала развития вычислительной техники образовались два основных направления ее использования:
· выполнение расчетов, которые невозможно производить вручную;
· создание автоматизированных информационных систем (АИС).
Создание АИС стало возможным с появлением жестких дисков большой емкости, обеспечивающих произвольный доступ к данным. Это предопределило развитие АИС разного назначения и масштаба, в первую очередь в области бизнес-приложений. Примерами являются автоматизированные системы управления предприятием, банковские системы, системы резервирования и продажи билетов.
Параллельно развивались системы управления физическими экспериментами, обеспечивающие оперативную обработку в реальном времени огромных потоков данных от датчиков, и автоматизированные библиотечные информационно-поисковые системы. Все это привело к появлению новой информационной технологии интегрированного хранения и обработки данных – концепции баз данных.
Система баз данных (СБД) – это система специально организованных данных (баз данных), программных, технических, языковых, организационно-методических средств для централизованного накопления и коллективного многоцелевого использования данных.
Терминологическое единство в рассматриваемой сфере отсутствует. Термин «система баз данных» (database system) широко используется в современнойанглоязычной литературе для определения человеко-машинной системы, включающей БД, СУБД, оборудование и персонал. Значительно реже используется термин «банк данных», который многими авторами признается архаичным.
База данных (БД) – именованная совокупность данных, отображающая состояние объектов и их отношений в рассматриваемой предметной области.
В ранних определениях БД указывалось на отсутствие дублирования данных. Однако дублирование может быть вызвано спецификой модели данных или технологическими причинами (обеспечение надежности, сокращение времени реакции). Но это должно быть отслеживаемое и управляемое дублирование.
Система управления базами данных (СУБД) – это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Иногда в составе СБД выделяют систему управления архивами. Под оперативным управлением СУБД находится часть данных, остальные данные (архивы) располагаются на носителях, не управляемых СУБД.
Основные требования к СБД можно сформулировать следующим образом:
· адекватность отображения предметной области (полнота, целостность, непротиворечивость и актуальность данных);
· возможность взаимодействия пользователей разных категорий, обеспечение высокой эффективности доступа;
· дружественность интерфейса;
· обеспечение секретности и конфиденциальности;
· обеспечение взаимной независимости программ и данных;
· обеспечение надежности – защита данных от случайного и преднамеренного разрушения, возможность восстановления данных в случае сбоев в системе;
· распределенная обработка данных и обеспечение эффективного доступа пользователей к данным в любой точке сети.
Компоненты системы баз данных
СБД является сложной человеко-машинной системой, включающей различные взаимосвязанные и взаимозависимые компоненты (подсистемы) (рис. 1).
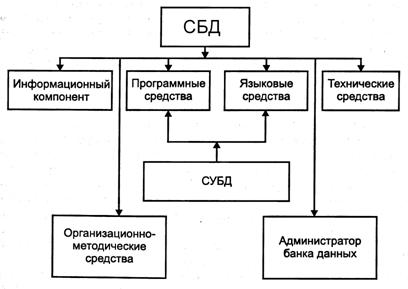
Рис. 1. Компоненты СБД
Данные, отражающие состояние предметной области и используемые АИС, принято называть информационной базой. Информационная база включает:
· собственно данные;
· метаданные (описания этих данных).
Данные отделены от описаний, но в то же время данные не могут использоваться без обращения к соответствующим описаниям.
Языковые средства СУБД являются важнейшим компонентом СБД, так как обеспечивают интерфейс пользователей разных категорий с СБД (рис. 2). Языковые средства современных СУБД относятся к 4-му поколению.
На рис. 3 приведены компоненты языка 4-го поколения. К 1-му поколению относят машинные языки, ко 2-му – языки ассемблера, к 3-му – алгоритмические языки типа PL и Cobol, которые назывались языками высокого уровня, но уровень которых гораздо ниже, чем у языков 4-го поколения. К 5му поколению относят языки систем искусственного интеллекта (Prolog).
Для выражения обобщенного взгляда на данные применяют язык описания данных (ЯОД), включаемый в состав СУБД. ЯОД позволяет определять схемы БД, характеристики хранимых данных, параметры хранения их в памяти и может включать средства поддержки целостности, ограничения доступа, секретности. Одна БД на ЯОД разных СУБД может описываться по-разному.
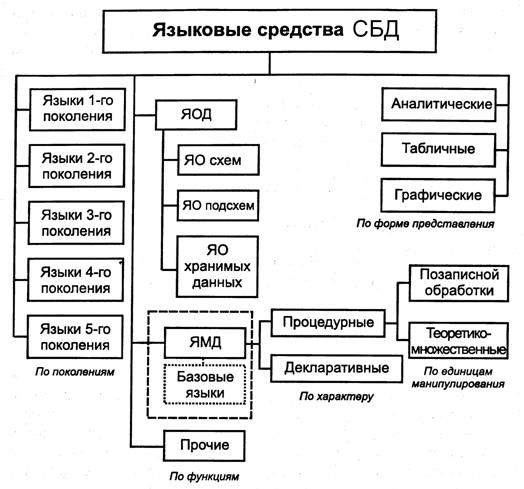
Рис. 2. Классификация языковых средств СБД
Рис. 3. Компоненты языка 4-го поколения
Язык манипулирования данными (ЯМД) включает в себя средства запросов к БД и поддержания БД (добавление, удаление, обновление данных, создание и уничтожение БД, обеспечение запросов к справочнику БД). ЯМД разделяются:
на процедурные;
непроцедурные (декларативные).
При пользовании процедурными языками надо указать, какие действия и над какими объектами необходимо выполнить, чтобы получить результат. В непроцедурных языках указывается, что надо получить в ответе, а не как этого достичь.
Процедурные языки могут различаться по основным информационным единицам, которыми они манипулируют. Это могут быть:
· языки, ориентированные на позаписную обработку данных;
· языки, ориентированные на операции над множеством записей.
Примерами непроцедурных языков являются языки, основанные на реляционном исчислении. К ним относятся язык запросов SQL и табличный язык QBE.
По форме представления различают следующие языковые средства:
· аналитические;
· табличные;
· графические.
В рамках одной СУБД могут использоваться языки разных типов. Во многих СУБД (dBase, FoxPro и др.) для манипулирования данными могут использоваться:
· табличный язык запросов типа QBE;
· аналитический язык запросов SQL;
· процедурный язык программирования (для dBase и FoxPro – язык xBase).
Кроме упомянутых языковых средств эти системы включают генераторы экранных форм, отчетов и приложений, а также язык разветвленной иерархической системы «меню», позволяющей пользователю выбрать нужные действия.
Наиболее распространенным языком является SQL (Structured Query Language), предоставляющий средства обработки запросов и функции по созданию, обновлению и управлению доступом. SQL соединяет в себе ЯОД и ЯМД. Он не является полноценным языком программирования. Для доступа к БД из прикладных программ SQL-выражения встраиваются в конструкции базового языка.
Программные средства СБД представляют собой сложный комплекс, обеспечивающий взаимодействие всех частей системы (рис. 4).
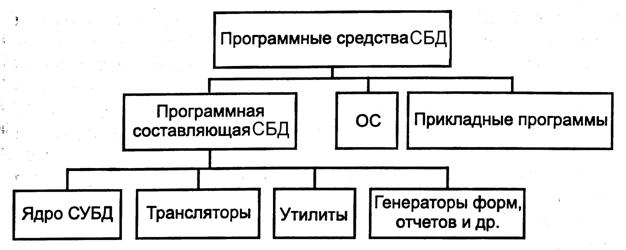
Рис. 4. Программные средства СБД
Программная составляющая СБД осуществляет обработку данных и взаимодействие с операционной системой (ОС) и прикладными программами. Взаимосвязь компонентов этого комплекса программных средств показана на рис. 5.
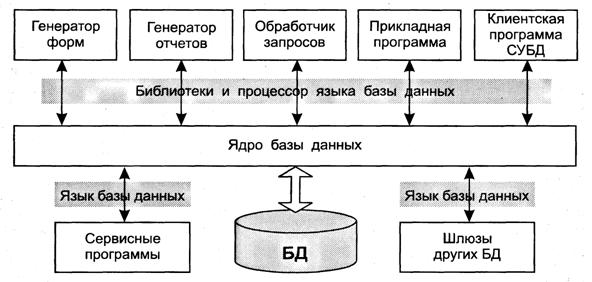
Рис. 5. Программная составляющая СБД
В составе комплекса выделяют следующие компоненты:
· ядро, обеспечивающее управление данными во внешней и оперативной памяти, а также протоколирование изменений;
· процессор языка БД, обеспечивающий обработку и оптимизацию запросов на выборку и изменение данных;
· подсистему (библиотеку) поддержки программных вызовов, которая обслуживает прикладные программы управления данными, взаимодействующие с СУБД через средства пользовательского интерфейса;
· сервисные программы (системные и внешние утилиты), обеспечивающие настройку СУБД, восстановление после сбоев и другое обслуживание.
Необходима координация между ОС и СУБД. Многопользовательские приложения, обработка распределенных запросов требуют эффективного использования ресурсов, которыми управляет ОС. Управление доступом и обеспечение защиты также интегрируются с соответствующими средствами ОС.
К техническим средствам СБД относятся: ЭВМ, периферийные средства ввода информации в БД, средства хранения данных и отображения выводимой информации. Для сетевых СБД необходимы коммуникационные средства (рис. 6).
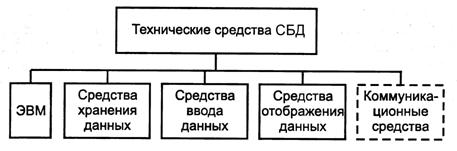
Рис. 6. Технические средства СБД
В качестве ЭВМ используются универсальные компьютеры и специализированные серверы – машины с повышенной отказоустойчивостью, высокопроизводительными подсистемами ввода-вывода и развитой периферией. Для распределенных БД важны коммуникационное оборудование и сетевые протоколы. Специализированные технические средства – машины баз данныхи сетевые компьютеры без дисковых накопителей широкого распространения не нашли. Карманные ПК используются в качестве коммуникационных устройств для доступа мобильных пользователей к корпоративным данным в глобальных сетях.
В СБД выполняются операции по вводу, хранению, обработке и выводу информации (рис. 7). При выполнении этих операций используются различные технологии и различные технические и программные средства.
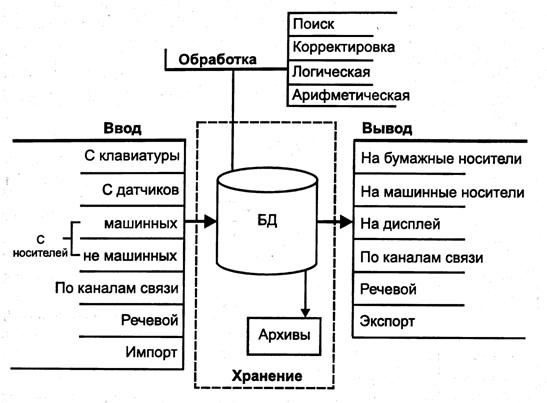
Рис. 7. Операции с БД
Организационно-методические средства СБД представляют собой инструкции, методические и регламентирующие материалы для пользователей разных категорий. К ним же относятся методики проектирования БД.
Администрация базы данных
Создание, функционирование и развитие СБД обеспечиваются администрацией базы данных (АБД), которая выполняет работы на протяжении всего жизненного цикла системы. В состав АБД входят:
· системные аналитики;
· проектировщики структур данных и внешнего по отношению к СБД информационного обеспечения;
· проектировщики технологических процессов обработки данных;
· системные и прикладные программисты;
· операторы;
· специалисты по техническому обслуживанию;
· специалисты по маркетингу (для коммерческих СБД).
В обязанности АБД входит выполнение следующих функций.
1. Анализ предметной области, ее описание, формулировка ограничений целостности, определение потребностей и статуса пользователей.
2. Проектирование структуры БД: определение состава и структуры информационных единиц БД, связей между ними.
3. Задание ограничений целостности при описании структуры БД и процедур обработки данных.
4. Первоначальная загрузка и ведение БД: разработка технологии загрузки и ведения БД, проектирование форм ввода, создание программных модулей.
5. Защита данных:
· обеспечение парольного входа в систему;
· определение прав доступа пользователей к данным;
· выбор и создание программно-технических средств защиты данных;
· тестирование средств защиты данных;
· сбор статистики об использовании данных;
· исследование случаев нарушения защиты данных;
· обеспечение восстановления БД, ведение системных журналов.
6. Анализ обращений пользователей к БД.
7. Работа с конечными пользователями.
8. Работа над совершенствованием и динамическим развитием СБД.
Взаимодействие компонентов системы баз данных
На рис. 8 представлена схема взаимодействия компонентов СБД в процессе создания и эксплуатации. Создание БД начинается с проектирования и описания на ЯОД (1). На этом этапе могут использоваться методики ручного проектирования и CASE-средства, автоматически генерирующие описания БД. Описания вводятся в СБД и запоминаются в соответствии с требованиями конкретной СУБД (2,3). После того как описание БД сохранено, в нее вводятся данные (4). При этом СУБД использует метаинформацию, зафиксированную в словаре данных.
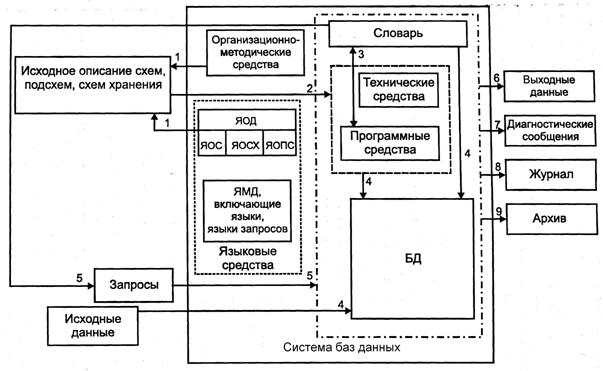
Рис. 8. Схема взаимодействия компонентов СБД
Заполненная БД используется для извлечения необходимой пользователям информации (5). При формулировании запросов используется информация, содержащаяся в схемах и подсхемах. В результате выполнения запроса пользователю выдаются выходные данные (6). Кроме данных выдается диагностическая информация (7). Для обеспечения надежности необходимо осуществлять журнализацию выполняемых действий (8) и регулярно архивировать данные (9).
Классификация баз данных
СБД являются сложными системами, и их классификация может быть произведена как для всей СБД, так и для каждого компонента отдельно (рис. 9). Центральным компонентом СБД является БД и большинство классификационных признаков относится к ней. По форме представления информации различают визуальные, а также системы аудио и мультимедиа. Эта классификация показывает, в каком виде информация хранится в БД и выдается пользователям.
По характеру организации данных БД могут быть разделены на неструктурированные, частично структурированные и структурированные. К неструктурированным могут быть отнесены БД, организованные в виде семантических сетей. Частично структурированными можно считать БД в виде обычного текста или гипертекстовые системы. Структурированные БД требуют предварительного проектирования и описания структуры. Структурированные БД по типу используемой модели делятся на иерархические, сетевые, реляционные, смешанные и мультимодельные. Эта классификация распространяется и на СУБД.
В структурированных БД различают несколько уровней информационных единиц (ИЕ), входящих одна в другую. Большинство систем поддерживает:
· поле – наименьшая семантическая единица информации;
· совокупность полей (или более сложных ИЕ) образует запись;
· множество однотипных записей представляет файл базы данных.
Многие СУБД в явном виде поддерживают и уровень базы данных как совокупности взаимосвязанных файлов БД.
По типу хранимой информации БД делятся на фактографические, документальные и лексикографические.
В фактографических БД хранится информация фактического характера – числовые или текстовые характеристики объектов, представленные в формализованном виде. В ответ на запрос выдается информация об интересующем объекте.
В документальных БД единицей хранения является документ и пользователю выдается ссылка на документ или сам документ. Документальные БД организуются без хранения и с хранением документа на машинных носителях. К первому типу относятся библиографические, реферативные и БД-указатели, отсылающие к источнику информации. Системы, хранящие полный текст документа, называются полнотекстовыми. Их разновидностью являются БД форм документов, в которых документ ищется для использования его в качестве шаблона.
К лексикографическим БД относятся различные словари (классификаторы, многоязычные словари, словари основ слов и т. п.).
По характеру организации хранения данных и обращения к ним различают локальные (персональные), общие (интегрированные, централизованные) и распределенные БД (рис. 10).
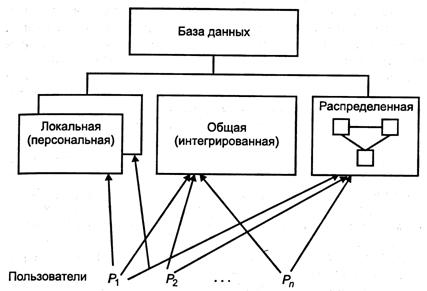
Рис. 10. Классификация БД по характеру хранения и обращения к данным
Персональная БД предназначена для локального использования одним пользователем. Локальные БД могут создаваться каждым пользователем самостоятельно, а могут извлекаться из общей БД.
Интегрированные и распределенные БД предполагают возможность одновременного обращения к информации нескольких пользователей (многопользовательский режим доступа). Части распределенных БД физически расположены на разных ЭВМ, но логически представляют собой единое целое.
Распределяться по узлам сети могут и другие компоненты СБД. Сама БД при этом может быть нераспределенной. Поэтому различают:
· распределенные БД;
· распределенные СБД (в которых распределен хотя бы один компонент).
В некоторых источниках упоминают экстенсиональные и интенсиональные БД. Первые строятся с помощью явного хранения данных в БД, вторые – с помощью правил, определяющих их содержание.
Также БД классифицируются по объему. Особое место здесь занимают так называемые очень большие БД. Для больших БД по-иному ставятся вопросы обеспечения эффективности хранения информации и обеспечения ее обработки.
Классификация СУБД
По языкам общения СУБД делятся на открытые, замкнутые и смешанные. В открытых системах для обращения к БД используются универсальные языки. Замкнутые системы имеют собственные языки общения с пользователями СБД.
По выполняемым функциям СУБД делятся на информационные и операционные. Информационные позволяют организовать хранение информации и доступ к ней. Для более сложной обработки необходимы специальные программы. Операционные выполняют сложную обработку и могут менять алгоритмы обработки.
По сфере возможного применения различают универсальные и специализированные (проблемно ориентированные СУБД).
Набор типов данных в разных СУБД различен. Ряд СУБД позволяет разработчику добавлять новые типы данных и новые операции. Такие системы называются расширяемыми системами баз данных. Дальнейшим развитием являются системы объектно-ориентированных баз данных, обладающие мощными возможностями моделирования сложных объектов.
По мощности СУБД делятся на настольные (Dbase, FoxBase/FoxPro, Clipper, Paradox, Access, Approach) и корпоративные (Oracle, DB2, Sybase, Informix, Ingres, Progress). Для первых характерны невысокие требования к техническим средствам, ориентация на конечного пользователя и низкая стоимость. Вторые обеспечивают работу в распределенной среде, высокую производительность, имеют развитые средства администрирования, широкие возможности поддержания целостности. Они сложны, дороги и требуют значительных ресурсов. Среди СУБД, занимающих промежуточное положение между настольными и промышленными системами, можно назвать Interbase, Microsoft SQL Server. В последние годы наметилась тенденция к стиранию границ между настольными и профессиональными системами.
По ориентации на преобладающую категорию пользователей можно выделить СУБД для разработчиков и для конечных пользователей. Первые должны иметь качественные компиляторы и позволять создавать отчуждаемые программные продукты, обладать развитыми средствами отладки, включать средства документирования. Вторые должны иметь удобный интерфейс, высокий уровень языковых средств, интеллектуальные модули подсказок, защиту от ошибок и т. п.
Существует разделение СУБД по поколениям. К 1-му поколению относят системы, основанные на иерархической и сетевой моделях (1960–70-е гг.), ко 2-му поколению – реляционные системы. СУБД 3-го поколения должны поддерживать сложные структуры данных и более развитые средства обеспечения целостности данных, отвечать требованиям, предъявляемым к открытым системам.
Классификация систем баз данных
По условиям предоставления услуг различают бесплатные и платные СБД. Платные делятся на бесприбыльные и коммерческие. Бесприбыльные функционируют на принципе самоокупаемости и не ставят целью получение прибыли. Это СБД социально значимой, научной, библиотечной информации. Основной целью создания коммерческих СБД является получение прибыли.
По характеру преобладающей обработки информации различают (табл. 1):
· системы OLTP (On-Line Transaction Processing);
· системы OLAP (On-Line Analytical Processing).
В качестве синонима OLAP используют термин «хранилища данных» (Data Warehousing). Хранилища данных могут быть разбиты на два типа:
· корпоративные хранилища данных (enterprise data warehouses);
· витрины данных (data marts).
Таблица 1
Характеристика |
OLTP |
OLAP |
Преобладающие операции
|
Ввод данных, поиск |
Анализ данных |
Характер запросов |
Много простых транзакций
|
Сложные транзакции |
Хранимые данные |
Оперативные, детализированные |
Охватывающие большой период времени, агрегированные
|
Вид деятельности |
Оперативная, тактическая |
Аналитическая, стратегическая
|
Тип данных |
Структурированные |
Разнотипные |
Корпоративные хранилища данных содержат информацию, относящуюся ко всей корпорации, собранную из множества оперативных источников для консолидированного анализа. Хранилища охватывают ряд аспектов деятельности корпорации и используются для принятия тактических и стратегических решений.
Витрины данных содержат подмножество корпоративных данных и строятся для отделов или подразделений организации. Строятся силами отдела и охватывают аспект, интересующий сотрудников отдела. Данные могут поступать из корпоративного хранилища или непосредственно из оперативных источников.
По степени доступности СБД делятся на общедоступные и с ограниченным кругом пользователей. По охвату СБД могут классифицироваться в разных разрезах (территориальный, временной, ведомственный, проблемный). По характеру взаимодействия с пользователями СБД делятся на активные и пассивные. В пассивных ведущая роль принадлежит пользователю, в активных – система может самостоятельно менять поведение. По форме собственности СБД делятся на государственные и негосударственные (частные, групповые, личные).
Лекция 2
Реляционная модель данных.
Модели данных
Ядром БД является модель данных – совокупность структур данных и операций их обработки. Различают иерархическую, сетевую и реляционную модели.
Иерархическая модель позволяет строить БД с древовидной структурой. В них каждый узел содержит свой тип данных (сущность). На верхнем уровне дерева имеется один узел – корень, на следующем уровне располагаются узлы, связанные с этим корнем, затем узлы, связанные с узлами предыдущего уровня, и т. д. Каждый узел может иметь только одного предка (рис. 11).
Рис. 11. Иерархическая древовидная структура модели БД
Поиск данных всегда начинается с корня. Затем производится спуск с одного уровня на другой пока не будет достигнут искомый уровень. Перемещения от одной записи к другой осуществляются с помощью ссылок.
Достоинствами иерархической модели являются простота описания иерархических структур реального мира, а также быстрое выполнение запросов, соответствующих структуре данных. Недостатки иерархической модели в том, что они часто содержат избыточные данные и не всегда удобно каждый раз начинать поиск нужных данных с корня.
В сетевой модели возможны связи всех информационных объектов со всеми. Например, каждый преподаватель может обучать много студентов и каждый студент может обучаться у многих преподавателей (рис. 12).
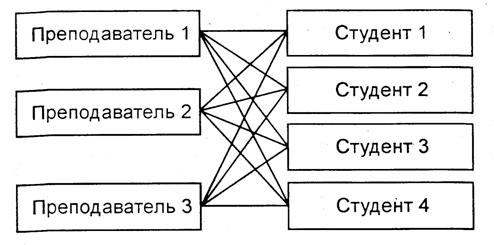
Рис. 12. Сетевая структура модели БД
Использование иерархической и сетевой моделей ускоряет доступ к информации, но требует значительных ресурсов памяти, так как каждый элемент данных содержит ссылки на другие элементы. Характерна сложность реализации СУБД.
Реляционная модель(РМД) была разработана в начале 1970-х годов Эдгаром Ф. Коддом. В ней информация представляется в виде двумерных таблиц, а операции сводятся к манипуляциям с таблицами. В 1980-х годах она получила широкое распространение, а реляционные СУБД стали промышленным стандартом. Причины доминирования РМД обусловлены тем, что имеются:
· развитая теория (реляционная алгебра);
· аппарат сведения других моделей данных к РМД;
·специальные средства ускоренного доступа к информации;
· стандартизированный высокоуровневый язык запросов к БД, позволяющий манипулировать данными без знания физической организации БД.
Объектно-ориентированная модель начала разрабатываться в 1990-е годы с появлением объектно-ориентированных языков. Такие БД хранят методы классов, что позволяет интегрировать данные и их обработку в приложениях.
Основные понятия реляционной модели данных
В математических дисциплинах понятию «таблица» соответствует понятие «отношение» (relation). Таблица отражает объект реального мира – сущность, а каждая ее строка отражает конкретный экземпляр сущности. Каждый столбец имеет уникальное для таблицы имя. Строки не имеют имен, порядок их следования не определен, а количество логически не ограничено. Одним из основных преимуществ РМД является однородность (каждая строка таблицы имеет один формат). Пользователь сам решает вопрос, обладают ли соответствующие сущности однородностью. Этим решается проблема пригодности модели. Основные элементы РМД показаны на рис. 13.
Отношение представляет собой двумерную таблицу, содержащую некоторые данные. Сущность – объект любой природы, данные о котором хранятся в БД. Атрибуты – свойства, характеризующие сущность (столбцы). Степень отношения – количество столбцов. Схема отношения – список имен атрибутов, например, СОТРУДНИК (№, ФИО, Год рождения, Должность, Кафедра). Домен – совокупность значений атрибутов отношения (тип данных). Кортеж – строка таблицы. Кардинальность (мощность) – количество строк в таблице.
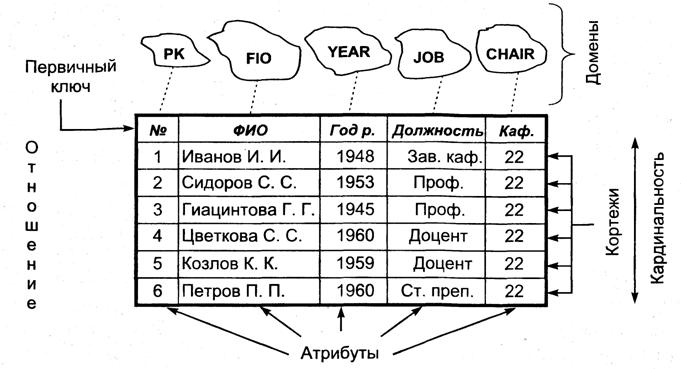
Рис 13. Элементы реляционной модели
Первичный ключ – это атрибут, уникально идентифицирующий строки отношения. Первичный ключ из нескольких атрибутов называется составным. Первичный ключ не может быть полностью или частично пустым (иметь значение null). Ключи, которые можно использовать в качестве первичных, называются потенциальными или альтернативными ключами. Внешний ключ – это атрибут (атрибуты) одной таблицы, который может служить первичным ключом другой таблицы. Является ссылкой на первичный ключ другой таблицы (рис. 14).

Рис 14. Связь отношений
Отношения СТУДЕНТ (ФИО, Группа, Специальность) и ПРЕДМЕТ (Назв Пр, Часы) связаны отношением СТУДЕНТ_ПРЕДМЕТ (ФИО, Назв Пр, Оценка), в котором внешние ключи ФИО и Назв_Пр образуют составной ключ.
Целостность реляционных данных
Логические ограничения, накладываемые на данные, называются ограничениями целостности. СУБД должна контролировать соответствие данных заданным ограничениям при переводе БД из одного состояния в другое. Использование ограничений связано также с адекватностью отражения предметной области.
Явные ограничения задаются семантикой предметной области. Они описывают области допустимых значений атрибутов, соотношение между атрибутами, динамику их изменения и т. д. Внутренние ограничения свойственны собственно модели данных. Они накладываются на структуру отношений, на связи, на допустимые значения наборов данных, заложенные в выбранной модели данных. Способы реализации внутренних ограничений целостности зависят от СУБД.
В РМД существует два вида внутренних ограничений целостности.
1. Целостность по существованию – потенциальный ключ отношения не может иметь пустого значения (NULL).
2. Целостность по связи – определяется понятием внешнего ключа отношения и означает систему правил, используемых для поддержания связей между записями в связанных таблицах. Обеспечивает защиту от случайного удаления или изменения связанных данных, от некорректного изменения ключевых полей
Операции над отношениями
РМД стала первой работоспособной моделью данных, поскольку имела эффективный инструментарий – операции реляционной алгебры. Основной единицей обработки является отношение, а не его кортежи. К отношениям можно применить систему операций, позволяющих получить одни отношения из других. Исключение составляют операции создания и заполнения таблиц, а также операции описания и переименования столбцов. Результатом запроса к реляционной БД может быть новое отношение, вычисленное на основе имеющихся отношений.
Реляционная алгебра включает две группы операций.
1. Традиционные операции над множествами (модифицированные с учетом того, что их операндами являются отношения) – объединение, пересечение, разность (вычитание), декартово произведение и деление.
2. Специальные реляционные операции – выборка, проекция, соединение.
Объединение выполняется над двумя совместными отношениями R1, R2 с идентичной структурой. В результате операции строится новое отношение R = R1 U R2 , которое имеет тот же состав атрибутов и совокупность кортежей исходных отношений. В результирующее отношение по определению не включаются дубликаты кортежей. Ниже приведены исходные отношения: R1 (табл. 2) и R2 (табл. 3) и результат объединения – R (табл. 4).
Таблица 2
ФИО |
Год рождения |
Должность |
Кафедра |
Иванов И.И. |
1948 |
Зав. кафедрой |
22 |
Сидоров С.С. |
1953 |
Доцент |
22 |
Козлов К.К. |
1980 |
Ассистент |
23 |
Таблица 3
ФИО |
Год рождения |
Должность |
Кафедра |
Цветкова Н.Н. |
1965 |
Доцент |
23 |
Петрова П.П. |
1953 |
Ст. преподаватель |
22 |
Козлов К.К. |
1980 |
Ассистент |
23 |
Таблица 4
ФИО |
Год рождения |
Должность |
Кафедра |
Иванов И.И. |
1948 |
Зав. кафедрой |
22 |
Сидоров С.С. |
1953 |
Доцент |
22 |
Козлов К.К. |
1980 |
Ассистент |
23 |
Цветкова Н.Н. |
1965 |
Доцент |
23 |
Петрова П.П. |
1953 |
Ст. преподаватель |
22 |
Пересечение выполняется над двумя совместными отношениями R1, R2. Результирующее отношение RP = R1 ) R2 содержит кортежи, которые есть в каждом из исходных. Результат имеет тот же состав атрибутов, что и исходные отношения. Пересечение отношений R1 и R2 дает отношение RP (табл. 5).
Таблица 5
ФИО |
Год рождения |
Должность |
Кафедра |
Козлов К.К. |
1980 |
Ассистент |
23 |
Вычитание выполняется над двумя совместными отношениями R1, R2. В результате строится новое отношение RV = R1 - R2 с идентичным набором атрибутов, содержащее кортежи первого отношения R1, которые не входят в отношение R2. Вычитание отношения R2 из R1 дает отношение RV (табл. 6).
Таблица 6
ФИО |
Год рождения |
Должность |
Кафедра |
Иванов И.И. |
1948 |
Зав. кафедрой |
22 |
Сидоров С.С. |
1953 |
Доцент |
22 |
Декартово произведение выполняется над двумя отношениями R1 и R2, имеющими в общем случае разный состав атрибутов. В результате образуется новое отношение RD = R1 x R2, которое включает все атрибуты исходных отношений. Результирующее отношение состоит из всевозможных сочетаний кортежей исходных отношений. Число кортежей (мощность) отношения-произведения равно произведению мощностей исходных отношений.
Декартово произведение отношений R1 (табл. 7) и R2 (табл. 8) дает новое отношение RD (табл. 9), которое содержит все атрибуты исходных отношений. В него целесообразно добавить атрибут Оценка для записи результатов экзамена.
Номер студента |
ФИО студента |
11 |
Иванов И.И. |
12 |
Петров П.П. |
13 |
Сидоров С.С. |
Код дисциплины |
Наименование |
Д1 |
Математика |
Д2 |
Информатика |
Таблица 9
Номер студента |
ФИО студента |
Код дисциплины |
Наименование |
Оценка |
11 |
Иванов И.И. |
Д1 |
Математика |
5 |
12 |
Петров П.П. |
Д1 |
Математика |
3 |
13 |
Сидоров С.С. |
Д1 |
Математика |
5 |
11 |
Иванов И.И. |
Д2 |
Информатика |
5 |
12 |
Петров П.П. |
Д2 |
Информатика |
4 |
13 |
Сидоров С.С. |
Д2 |
Информатика |
4 |
Деление выполняется над двумя отношениями R1 и R2, имеющими в общем случае разные структуры и часть одинаковых атрибутов. В результате образуется новое отношение, содержащее атрибуты 1-го операнда, отсутствующие во 2-м операнде, и кортежи 1-го операнда, которые совпали с кортежами 2-го. Для выполнения этой операции 2-й операнд должен содержать лишь атрибуты, совпадающие с атрибутами 1-го.
Например, чтобы узнать, кто из студентов получил по математике 5 и по информатике 4, надо разделить отношения Экзаменационная ведомость на вспомогательное отношение Мат5Физ4 (Наименование, Оценка) с двумя кортежами: Математика, 5 и Информатика, 4. В результате получим отношение Итог (Номер студента, ФИО студента, Код дисциплины) с одним кортежем – 13, Сидоров, Д1.
Выборка выполняется над одним отношением R. Для отношения по заданному условию (предикату) осуществляется выборка подмножества кортежей. Результирующее отношение имеет ту же структуру, что и исходное, но число его кортежей будет меньше (или равно) числа кортежей исходного отношения. Например, выбрать студентов, сдавших математику на отлично (Код дисциплины = Д1) AND (Оценка = 5) (табл. 10).
Таблица 10
Номер студента |
ФИО студента |
Код дисциплины |
Наименование |
Оценка |
11 |
Иванов И.И. |
Д1 |
Математика |
5 |
13 |
Сидоров С.С. |
Д1 |
Математика |
5 |
Проекция выполняется над одним отношением R. Операция формирует новое отношение RPR с заданным подмножеством атрибутов исходного отношения R. Оно может содержать меньше кортежей, так как после отбрасывания в исходном отношении R части атрибутов (и возможного исключения первичного ключа) могут образоваться кортежи-дубли, которые из результирующего отношения исключаются по определению.
Ниже приведен пример исходного отношения R (табл. 11) и результат проекции этого отношения на два его атрибута - Должность и Номер отдела (табл. 12).
Таблица 11 Таблица 12
ФИО |
Номер отдела |
Должность |
|
Номер отдела |
Должность |
Иванов И.И. |
01 |
Инженер |
|
01 |
Инженер |
Петров П.П. |
02 |
Инженер |
|
02 |
Инженер |
Нестеров Н.Н. |
01 |
Инженер |
|
03 |
Лаборант |
Никитин К.К. |
02 |
Лаборант |
|
|
|
Соединение выполняется для заданного условия соединения над двумя логически связанными отношениями. Исходные отношения R1 и R2 имеют разные структуры, в которых есть одинаковые атрибуты – внешние ключи. Операция соединения формирует новое отношение, структура которого является совокупностью всех атрибутов исходных отношений. Результирующие кортежи формируются соединением каждого кортежа из R1 с теми кортежами R2, для которых выполняется условие соединения. В зависимости от этого условия соединение называется: естественным – равенство значений общих атрибутов отношений R1 и R2; эквисоединением – равенство значений атрибутов, входящих в условие соединения; тета-соединением – другой знак сравнения.
Операция соединения имеет большое значение для РБД, так как в процессе нормализации отношений исходное отношение разбивается на несколько более мелких отношений, которые при выполнении запросов пользователя требуется, как правило, вновь соединять для восстановления исходного отношения.
Рассмотренные выше операции в той или иной мере реализуются в языке манипулирования данными СУБД (SQL, QBE, другие языки запросов). Язык SQL является более чем реляционно-полным, так как кроме операций реляционной алгебры содержит полный набор операторов над кортежами – Включить, Удалить, Изменить, а также реализует арифметические операции и операции сравнения.
К достоинствам РМД относятся:
· простота представления данных благодаря табличной форме;
· минимальная избыточность данных при нормализации отношений;
· обеспечение независимости приложений пользователя от данных, допускающей включение или удаление отношений, изменение их атрибутного состава;
К недостаткам РМД можно отнести то, что нормализация данных приводит к значительной их фрагментации, в то время как в большинстве задач необходимо объединение фрагментированных данных.
Нормализация баз данных
Данные могут группироваться в таблицы (отношения) разными способами. При проектировании БД в качестве отправной точки может использоваться одно универсальное отношение, в которое включаются все необходимые атрибуты. Оно может содержать все данные, которые предполагается размещать в БД.
В качестве примера рассмотрим универсальное отношение сотрудники, содержащее информацию о сотрудниках предприятия (табл. 13).
Таблица 13
Код сотрудника |
ФИО |
Должность |
Номер отдела |
Наименование отдела |
Квалификация |
7513 |
Иванов И.И. |
Программист |
128 |
Отдел проектирования |
C, Java |
9842 |
Сергеева С.С. |
Администратор БД |
42 |
Финансовый отдел |
DB2 |
6651 |
Петров П.П. |
Программист |
128 |
Отдел проектирования |
VB, Java |
9006 |
Николаев Н.Н. |
Системный администратор |
128 |
Отдел проектирования |
Windows, Linux |
При использовании универсального отношения возникают две проблемы:
· избыточность данных;
· потенциальная противоречивость (аномалии).
Под избыточностью понимают повторение данных в разных строках одной таблицы или в разных таблицах БД. Так, для каждого сотрудника отдела 128 повторяются данные «128, Отдел проектирования».
Аномалии – это проблемы, возникающие в данных из-за дефектов проектирования БД. Существуют три вида аномалий: вставки, удаления и модификации.
Аномалии вставки проявляются при вводе данных в дефектную таблицу. Добавляя информацию о новом сотруднике, мы должны добавить номер и название отдела. Если ввести данные, не соответствующие имеющимся в таблице (например, 42, отдел проектирования), будет не ясно, какая из строк БД содержит правильную информацию.
Аномалии удаления возникают при удалении данных из дефектной схемы. Предположим, что все сотрудники отдела 128 уволились в один и тот же день. После удаления записей этих сотрудников в БД больше не будет ни одной записи, содержащей информацию об отделе 128.
Аномалии модификации возникают при изменении данных дефектной схемы. Предположим, что отдел 128 решили переименовать в отдел передовых технологий. Необходимо изменить соответствующие данные о каждом сотруднике отдела. Если мы пропустим хотя бы одну запись, возникнет аномалия модификации.
Правилом разработки хорошей структуры БД является необходимость избегать схем с большим числом пустых атрибутов. Если мы хотим указать, что один из ста служащих имеет особую квалификацию, для хранения этой информации не следует добавлять в таблицу еще один столбец, поскольку для остальных 99 работников значением столбца будет NULL. Вместо этого следует добавить новую таблицу, в которой будут храниться только кодовые номера и информация о квалификации тех работников, которых это касается.
Решение перечисленных проблем состоит в разделении данных и связей, что обеспечивается процедурой нормализации. Концепции и методы нормализации были разработаны Э. Ф. Коддом.
Нормализация отношений – это формальный аппарат ограничений на формирование отношений, который позволяет устранить дублирование и потенциальную противоречивость хранимых данных, уменьшает трудозатраты на ведение БД. Процесс нормализации заключается в декомпозиции исходных отношений на более простые отношения. Цель нормализации – получение такого проекта БД, в котором «каждый факт появляется лишь в одном месте».
Теория нормализации основана на наличии зависимостей между атрибутами отношения. Основными видами зависимостей являются:
· функциональные;
· многозначные;
· транзитивные.
Базовым является понятие функциональной зависимости, поскольку на его основе формируются определения всех остальных видов зависимостей. Атрибут В функционально зависит от атрибута А, если каждому значению А соответствует в точности одно значение В. Математически функциональную зависимость В от А обозначают А ’ В. Это означает, что во всех кортежах с одинаковым значением атрибута А атрибут В будет иметь также одно и то же значение. При этом А и В могут быть составными, то есть состоять из двух и более атрибутов.
Зависимость, при которой каждый неключевой атрибут зависит от всего составного ключа и не зависит от его частей, называется полной функциональной зависимостью. Если атрибут А зависит от атрибута В, а атрибут В зависит от атрибута С (С ’ В ’ А), но обратная зависимость отсутствует, то зависимость А от С называется транзитивной.
Многозначная зависимость. Говорят, что один атрибут отношения многозначно определяет другой атрибут того же отношения, если для каждого значения первого атрибута существует множество соответствующих значений второго атрибута. Многозначные зависимости могут быть:
· один-ко-многим (1:М);
· многие-к-одному (М:1);
· многие-ко-многим (М:М).
Каждая ступень процесса нормализации приводит схему отношений в последовательные нормальные формы. Для каждой ступени имеются наборы ограничений. Выделяют следующую последовательность нормальных форм:
· первая нормальная форма (1НФ);
· вторая нормальная форма (2НФ);
· третья нормальная форма (3НФ);
· усиленная 3НФ или нормальная форма Бойса-Кодда (БКНФ);
· четвертая нормальная форма (4НФ);
· пятая нормальная форма (5НФ).
Отношение находится в первой нормальной форме (1НФ), когда каждая строка содержит только одно значение для каждого атрибута (столбца), то есть все атрибуты отношения имеют единственное значение (являются атомарными).
В столбце Квалификация ненормализованной табл. 13 содержатся списки значений (С, Java и т. д.). Чтобы привести схему к 1НФ, необходимо разместить в этом столбце атомарные значения. Самый простой способ заключается в выделении по одной строке на каждый элемент квалификации (табл. 14).
Таблица 14
Код сотрудника |
ФИО |
Должность |
Номер отдела |
Наименование отдела |
Квалификация |
7513 |
Иванов И.И. |
Программист |
128 |
Отдел проектирования |
C |
7513 |
Иванов И.И. |
Программист |
128 |
Отдел проектирования |
Java |
9842 |
Сергеева С.С. |
Администратор БД |
42 |
Финансовый отдел |
DB2 |
6651 |
Петров П.П. |
Программист |
128 |
Отдел проектирования |
VB |
6651 |
Петров П.П. |
Программист |
128 |
Отдел проектирования |
Java |
9006 |
Николаев Н.Н. |
Системный администратор |
128 |
Отдел проектирования |
Windows |
9006 |
Николаев Н.Н. |
Системный администратор |
128 |
Отдел проектирования |
Linux |
Такое решение далеко от идеального, поскольку порождает очевидную избыточность данных – для каждой комбинации сотрудник-квалификация приходится хранить все характеристики сотрудника.
Отношение находится во второй нормальной форме (2НФ), если оно находится в 1НФ, и каждый неключевой атрибут полностью функционально зависит от всех составляющих первичного ключа. Если атрибут не зависит полностью от первичного ключа, то он внесен ошибочно и должен быть удален. Нормализация производится путем нахождения существующего отношения, к которому относится данный атрибут, или созданием нового отношения, в который атрибут должен быть помещен.
Таблица Квалификации_сотрудников (табл. 14) находится в 1НФ, но не удовлетворяет 2НФ. Первичный ключ должен уникальным образом идентифицировать каждую строку. Единственным вариантом является использование в качестве первичного ключа комбинации Код сотрудника и Квалификация. Это порождает схему: Квалификации_сотрудников (Код сотрудника, ФИО, Должность, Номер отдела, Наименование отдела, Квалификация).
Одной из имеющихся здесь функциональных зависимостей будет: Код сотрудника, Квалификация ’ ФИО, Должность, Номер отдела, Наименование отдела. Но, кроме того, мы также имеем: Код сотрудника ’ ФИО, Должность, Номер отдела, Наименование отдела. Другими словами, можно определить имя, должность и отдел, используя только код сотрудника. Это значит, что указанные атрибуты функционально зависимы только от части первичного ключа, а не от всего первичного ключа. Следовательно, указанная схема не находится в 2НФ.
Для приведения этой схемы в 2НФ необходимо декомпозировать исходное отношение на два, в которых все неключевые атрибуты будут полностью функционально зависеть от ключа: сотрудники (Код сотрудника, ФИО, Должность, Номер отдела, Наименование отдела) и Квалификации_сотрудников (Код сотрудника, Квалификация) (табл. 15–16).
Таблица 15
Код сотрудника |
ФИО |
Должность |
Номер отдела |
Наименование отдела |
7513 |
Иванов И.И. |
Программист |
128 |
Отдел проектирования |
9842 |
Сергеева С.С. |
Администратор БД |
42 |
Финансовый отдел |
6651 |
Петров П.П. |
Программист |
128 |
Отдел проектирования |
9006 |
Николаев Н.Н. |
Системный администратор |
128 |
Отдел проектирования |
Таблица 16
Код сотрудника |
Квалификация |
7513 |
C |
7513 |
Java |
9842 |
DB2 |
6651 |
VB |
6651 |
Java |
9006 |
Windows |
9006 |
Linux |
Отношение находится в третьей нормальной форме (ЗНФ), если оно находится во 2НФ и ни один из его неключевых атрибутов не связан функциональной зависимостью с любым другим неключевым атрибутом. Атрибуты, зависящие от других неключевых атрибутов, нормализуются путем перемещения зависимого атрибута и атрибута, от которого он зависит, в новое отношение.
Формально, для приведения схемы в 3НФ необходимо исключить все транзитивные зависимости. Схема отношения сотрудники (табл. 15) содержит следующие функциональные зависимости: Код сотрудника ’ ФИО, Должность, Номер отдела, Наименование отдела и Номер отдела ’ Наименование отдела.
Первичным ключом является Код сотрудника, и все атрибуты полностью функционально зависимы от него (первичный ключ определяется единственным атрибутом). При этом Номер отдела ключом не является.
Функциональная зависимость Код сотрудника ’ Наименование отдела является транзитивной, поскольку содержит промежуточный шаг (зависимость Номер отдела ’ Наименование отдела). Для приведения в 3НФ необходимо исключить эту транзитивную зависимость, декомпозируя отношение на два: сотрудники (Код сотрудника, ФИО, Должность, Номер отдела) и отделы (Номер отдела, Наименование отдела) (табл. 17–18).
Таблица 17
Код сотрудника |
ФИО |
Должность |
Номер отдела |
7513 |
Иванов И.И. |
Программист |
128 |
9842 |
Сергеева С.С. |
Администратор БД |
42 |
6651 |
Петров П.П. |
Программист |
128 |
9006 |
Николаев Н.Н. |
Системный администратор |
128 |
Номер отдела |
Наименование отдела |
42 |
Финансовый отдел |
128 |
Отдел проектирования |
Нормальная форма Бойса-Кодда (БКНФ) является развитием ЗНФ и требует, чтобы в отношении были только такие функциональные зависимости, левая часть которых является потенциальным ключом отношения. Потенциальный ключ представляет собой атрибут (или множество атрибутов), который может быть использован для данного отношения в качестве первичного ключа. Фактически первичный ключ – это один из потенциальных ключей, назначенный в качестве первичного. Детерминантом называется левая часть функциональной зависимости. Отношение находится в БКНФ тогда и только тогда, когда каждый детерминант отношения является потенциальным ключом.
Алгоритм приведения ненормализованных схем в 3НФ показан на рис. 15. На практике построение 3НФ в большинстве случаев является достаточным и приведением к ней процесс построения реляционной БД заканчивается.
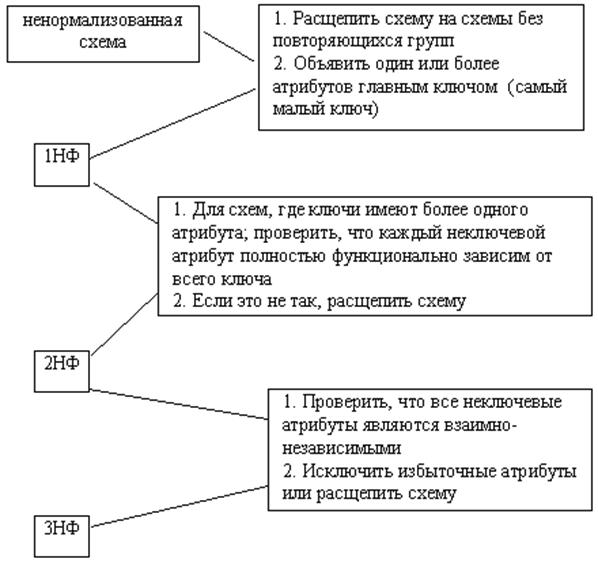
Рис. 15. Алгоритм приведения ненормализованных схем в 3НФ
![]()
Запомнить правила нормализации помогает изречение: «Нормализация – это ключ, целый ключ и ничего, кроме ключа».
|
|
|
|
Нормальные формы высших порядков (4НФ и 5НФ) представляют больший интерес для теоретических исследований, чем для практики проектирования БД. В них учитываются многозначные зависимости между атрибутами. Полной декомпозицией отношения называют такую совокупность произвольного числа его проекций, соединение которых позволяет получить исходное отношение.
Отношение находится в пятой нормальной форме (5НФ), когда в каждой его полной декомпозиции все проекции содержат возможный ключ. Отношение, не имеющее ни одной полной декомпозиции, также находится в 5НФ.
Четвертая нормальная форма (4НФ) является частным случаем 5НФ, когда полная декомпозиция должна быть соединением ровно двух проекций. На практике непросто подобрать отношение, которое находится в 4НФ, не будучи в 5НФ.
Нормализация – это процесс последовательной замены отношения его полными декомпозициями до тех пор, пока все они не будут находиться в 5НФ. Приведя отношения к БКНФ, можно с большой гарантией считать, что они находятся в 5НФ. Единственными функциональными зависимостями в любом отношении должны быть зависимости вида К ’ А, где К – первичный ключ, а А – атрибут.
Лекция 3
Проектирование реляционных баз данных
Уровни моделирования предметной области
БД отражает информацию об определенной предметной области – части реального мира, представляющей интерес для данного исследования. При проектировании БД организацию данных принято рассматривать на трех уровнях:
· информационно-логическом (инфологическом, или концептуальном);
· даталогическом;
· физическом.
Этим уровням соответствуют инфологическая, даталогическая и физическая модели предметной области.
Процесс создания БД начинается с определения концептуальных требований будущих пользователей, которые интегрируются в обобщенном представлении, называемом концептуальной моделью (рис. 16).

Рис. 16. Многоуровневое представление данных БД
Концептуальной, или инфологической (infological), моделью (ИЛМ) называется формализованное описание предметной области, выполненное без жесткой ориентации на программные и технические средства. Концептуальная модель отражает специфику предметной области, а не структуру БД.
Версия концептуальной модели, которая может быть реализована в конкретной СУБД, называется даталогической (datalogical) моделью. Модель отображает логические связи между элементами данных безотносительно к среде хранения. Модель строится в терминах информационных единиц, допустимых для СУБД. Описание логической структуры БД на языке СУБД называется схемой.
Внутренняя (физическая) модель данных определяет способ размещения данных непосредственно на машинном носителе, учитывает распределение данных, методы доступа и способы индексирования. В современных прикладных программных средствах этот уровень организации обеспечивается автоматически без вмешательства пользователя. Пользователь оперирует в прикладных программах и универсальных программных средствах представлениями СУБД. Таким образом, основная задача проектирования заключается в создании инфологической и даталогической моделей.
Различным пользователям соответствуют различные подмножества логической модели. Модель, описывающая логическую структуру БД с точки зрения конкретного пользователя (приложения), называется внешней, а ее описание называется подсхемой. Внешняя модель пользователя представляет отображение концептуальных требований этого пользователя.
Пользователь имеет доступ только к данным подсхемы, что является одним из способов защиты информации. В рамках каждой подсхемы задаются допустимые режимы обработки, что служит дополнительным механизмом защиты. Использование подсхем облегчает работу пользователя, так как он должен знать структуру только своей части БД. Внешние схемы БД конструируются на стадии разработки приложений.
Взаимосвязь этапов проектирования БД показана на рис. 17.
Первым шагом является построение инфологической модели. Предварительная модель строится на предпроектной стадии и уточняется на более поздних стадиях проектирования. Затем на ее основе строится даталогическая модель. Физическая и внешняя модели после этого могут строиться в любой последовательности, в том числе и параллельно. Возможен возврат на предыдущие уровни для пересмотра результата проектирования или уточнения модели.
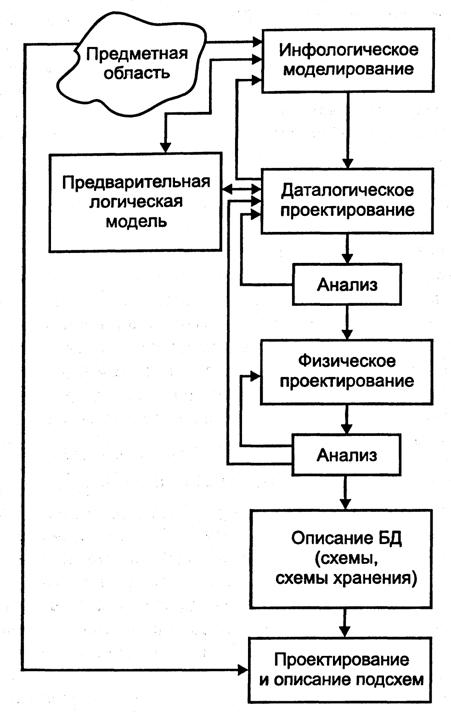
Рис. 17. Взаимосвязь этапов проектирования
Концептуальное проектирование баз данных
Одним из средств формализованного представления предметной области является модель «сущность-связь» (ERM – Entity-Relationship Model), предложенная Питером Ченом в 1976 г. Моделирование предметной области базируется на использовании ER-диаграмм, причем существует большое число нотаций и методик их построения. Базовыми понятиями модели являются сущность, связь и атрибут.
Сущность (Entity) – реальный или абстрактный объект, имеющий существенное значение для предметной области. Сущность должна иметь наименование, выраженное существительным в единственном числе (рис. 18). Примерами могут быть такие классы объектов, как Поставщик, Сотрудник, Заказ.

Рис. 18. Графическое представление сущности
Неформальный способ идентификации сущностей – это поиск абстракций, описывающих объекты, процессы, роли и другие понятия. Формальный способ идентификации сущностей – анализ текстовых описаний предметной области, выделение имен существительных и выбор их в качестве абстракций.
Экземпляр сущности – это конкретный представитель данной сущности. Например, экземпляром сущности Сотрудник может быть сотрудник Иванов.
Каждая сущность должна обладать следующими свойствами:
· иметь уникальное имя;
· обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
· обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности.
Атрибут (Attribute) – характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для идентификации, классификации, количественной характеристики или выражения состояния сущности.
Сущность Сотрудник может иметь атрибуты: Табельный номер, Фамилия, Имя, Отчество, Должность. Атрибуты изображаются в пределах прямоугольника, определяющего сущность (рис. 19). Существуют следующие виды атрибутов:
· простой – состоит из одного элемента данных;
· составной – состоит из нескольких элементов данных;
· однозначный – содержит одно значение для одной сущности;
· многозначный – содержит несколько значений для одной сущности;
· необязательный – может иметь пустое (неопределенное) значение;
· производный – значение, производное от значения другого атрибута.
Уникальным идентификатором называется набор атрибутов, значения которых в совокупности являются уникальными для каждого экземпляра сущности. Удаление любого атрибута из идентификатора нарушает его уникальность. Уникальные идентификаторы изображаются на диаграмме подчеркиванием (рис. 20).
|
|
Рис. 19. Сущность с атрибутами |
Рис. 20. Сущность с уникальным идентификатором |


Каждая сущность может обладать любым количеством связей с другими сущностями. Связь (Relationship) – поименованная ассоциация между сущностями, значимая для рассматриваемой предметной области. Степенью связи называется количество сущностей, участвующих в связи. Связь степени 2 называется бинарной, степени N – N-арной. Связь, в которой одна сущность участвует в разных ролях, называется рекурсивной (унарной). Один из вариантов графического изображения связи показан на рис. 21.
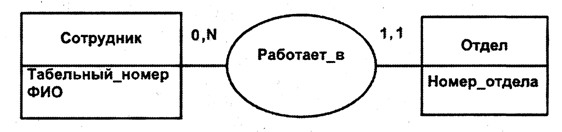
Рис. 21. Обозначение сущностей и связи
Пары чисел на диаграмме отражают две важные характеристики связи – класс принадлежности (первое число) и мощность связи (второе число).
Класс принадлежности характеризует обязательность участия экземпляра сущности в связи. Может принимать значение 0 (необязательное участие– экземпляр сущности может быть связан с одним, несколькими или ни с одним экземпляром другой сущности) или 1 (обязательное участие – экземпляр сущности должен быть связан не менее чем с одним экземпляром другой сущности). Классы принадлежности на рис. 21 означают: в каждом отделе работает хотя бы один сотрудник, некоторые сотрудники могут не работать в отделах (работают в цехах).
Мощность связи – число экземпляров сущности, участвующих в связи. Мощность связи может быть равна 1, N или конкретному числу. Мощности связи на рис. 21 означают: каждый сотрудник может работать не более чем в одном отделе, а в каждом отделе может работать любое число сотрудников.
В зависимости от значения мощности связь может иметь один из трех типов:
· один-к-одному (обозначается 1:1), показана на рис. 22.
· один-ко-многим(обозначается 1:N), показана на рис. 21.
· многие-ко-многим(обозначается M:N), показана на рис. 23.
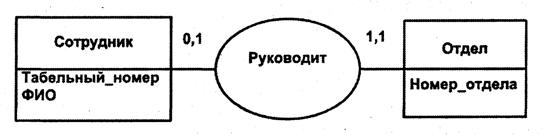
Рис. 22. Связь типа 1:1
Связи также могут иметь атрибуты. Чтобы узнать ставку сотрудника, нужно знать не только его табельный номер, но и номер отдела (рис. 23). Ставка является атрибутом обеих сущностей Сотрудник и Отдел. Это – атрибут связи.
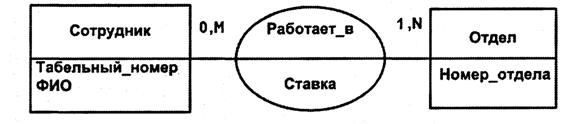
Рис. 23. Связь типа M:N
В связи «супертип-подтип» общие атрибуты типа определяются в сущности-супертипе, сущность-подтип (подкласс) наследует атрибуты супертипа. Экземпляр подтипа существует только при условии существования экземпляра супертипа. Подтип не может иметь идентификатора (он импортирует его из супертипа). Например, супертип УЧредитель образуют подтипы юридическое лицо и физическое лицо (рис. 24). Свойство, по которому проводится разбиение, называется дискриминатором.
Существуют следующие виды идентификаторов:
· первичный / альтернативный – сущность может иметь несколько идентификаторов (рис. 25). Один должен быть основным (первичным), другие – альтернативными. Первичный идентификатор на диаграмме подчеркивается. Альтернативные идентификаторы предваряются символами <1> для первого, <2> для второго и т. д.;
· простой / составной – идентификатор, состоящий из одного атрибута, является простым, из нескольких атрибутов – составным;
· абсолютный / относительный – если атрибуты, составляющие идентификатор, принадлежат сущности, то идентификатор является абсолютным. Если один или более атрибутов идентификатора принадлежат другой сущности, то идентификатор является относительным, а сущность определяется как зависимая.
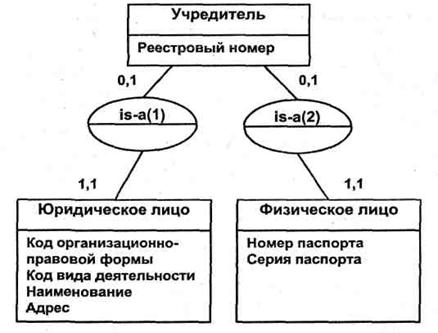
Рис. 24. Связь «супертип-подтип»
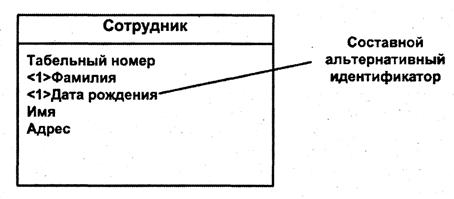
Рис. 25. Составной альтернативный идентификатор
На рис. 26 идентификатор сущности Строка_заказа является относительным. Он включает идентификатор сущности Заказ, что показывается подчеркиванием 1,1.
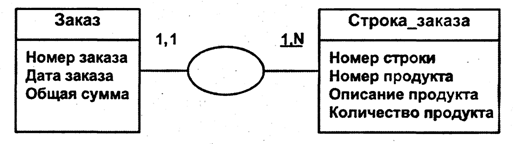
Рис. 26. Относительный идентификатор
При построении ER-модели необходимо ответить на вопросы:
·что следует считать сущностью, а что – атрибутом?
·когда следует делить класс на подклассы?
В качестве самостоятельного объекта следует изображать сущности:
· имеющие более одного идентификатора;
· для которых фиксируются какие-либо свойства;
· которые участвуют более чем в одной связи.
В случае сомнений лучше принять решение о создании самостоятельного объекта, так как это в дальнейшем потребует меньших переделок модели.
Количественные характеристики всегда являются атрибутами и никогда – сущностями. Они никогда не являются идентификаторами и не входят в состав идентификаторов. Следует стремиться отобразить информацию как можно более детально. Так, например, если Адрес, ФИО являются составными характеристиками, то желательно отразить это в модели.
Сущность-супертип следует вводить, чтобы подчеркнуть общность и различие сущностей, входящих в один класс, или если объекты разных подклассов участвуют в разных связях. Если для сотрудников мужского и женского пола фиксируются одни свойства, эти объекты участвуют в одних связях, то соответствующие подклассы выделять не следует. Если же для мужчин фиксируются сведения о воинской обязанности, а для женщин – нет, подклассы следует выделить.
Каждый подкласс может быть изображен в модели как самостоятельный объект, а не как подкласс какого-то родового класса. Чтобы иметь больше информации о предметной области и сократить число элементов (свойств, связей) в модели, в большинстве случаев лучше объединять подклассы в класс.
Связи устанавливаются на уровне сущностей. Нельзя устанавливать связь между атрибутом одной сущности и другой сущностью или ее атрибутом. Нельзя также непосредственно связывать сами связи. Подклассы могут участвовать в связях, так же как и классы.
Даталогическое проектирование
Следующим шагом является выбор конкретной СУБД и отображение в ее среду спецификаций инфологической модели предметной области. Эту стадию называют логическим (даталогическим) проектированием БД. Ее результатом является концептуальная схема БД, включающая определение всех информационных единиц и связей, в том числе задание типов, характеристик и имен.
Проектирование логической структуры РБД предполагает:
· разбиение всей информации по отношениям (таблицам);
· определение состава полей (атрибутов) каждого отношения;
· определение ключа каждого отношения;
· определение связей и обеспечение целостности по связям.
Часто при описании логической структуры РБД указывают, по каким полям надо индексировать отношение, а для ключевых полей индексация предусматривается автоматически. Индексация занимает промежуточное положение между логической и физической структурой данных. Она определяет способ логического упорядочения данных и доступ к ним, но при этом создаются вспомогательные индексные файлы, что меняет общую структуру БД.
Возможно несколько альтернативных вариантов отображения инфологической модели в даталогическую. Следует учитывать влияние следующих факторов:
1) связи предметной области могут отображаться как декларативным путем – в логической схеме, так и процедурным – через программные модули, обрабатывающие (связывающие) соответствующие данные.
2) существенное влияние оказывает характер обработки. Частые обращения к совместно обрабатываемым данным предполагают их совместное хранение, а данные, к которым обращаются редко, целесообразно хранить отдельно.
Рассмотрим по шагам общий подход к построению РБД на основе инфологической модели, представленной ER-диаграммой.
1. Каждая простая сущность превращается в таблицу (отношение). Имя сущности становится именем таблицы. Каждый простой атрибут становится столбцом таблицы с тем же именем: R1 (И1 , А1 , А2 , А3 ).
2. Компоненты уникального идентификатора сущности превращаются в первичный ключ. Если имеется несколько возможных уникальных идентификаторов, выбирается наиболее используемый. Учитываются также следующие факторы:
· длина ключа – в качестве первичного ключа выбирается, как правило, самый короткий из вероятных ключей;
· стабильность– желательно выбирать в качестве первичного ключа атрибуты, которые не изменяются;
· мнемоничность– при прочих равных условиях следует отдавать предпочтение тем из вероятных ключей, которые легче запомнить.
Некоторые СУБД (Access, Paradox и др.) позволяют автоматически генерировать в качестве ключа таблицы поле типа «счетчик». Этот искусственный код можно использовать для простых объектов, если в предметной области не предполагается применение другой системы кодирования (ОКПО, ОКОНХ, ИНН).
Если в состав уникального идентификатора входят связи, то к числу столбцов первичного ключа добавляется копия уникального идентификатора сущности, находящейся на дальнем конце связи (процесс может продолжаться рекурсивно).
3. Каждому из многозначных атрибутов ставится в соответствие отношение, полями которого будут идентификатор, выбранный в качестве первичного ключа, и многозначный атрибут. Ключ этого отношения будет составным, включающим оба эти атрибута. Для многозначных атрибутов МА4 и МА5 будут созданы отношения: R2 (И1 , МА4 ) и R3 (И1 ,МА5 ).
4. Если сущность имеет необязательный атрибут, возможны два варианта:
· если таким свойством обладают многие экземпляры объекта, его можно хранить как обычный атрибут в той же таблице (столбец может содержать неопределенные значения);
· если свойством обладает малое число экземпляров, то можно выделить отношение, включающее идентификатор и соответствующий атрибут: R4 (И1 , НА6 ). Отношение будет содержать столько строк, сколько объектов имеет свойство.
5. Если сущность имеет составной атрибут, то возможны два варианта:
· составному свойству ставится в соответствие отдельное поле;
· каждому из составляющих элементов составного свойства ставится в соответствие отдельное поле.
Выбор варианта зависит от характера обработки данных. При реализации запросов проще объединить поля, чем выделить часть поля. Если предполагается использование компонентов атрибута, лучше вариант 2, иначе – вариант 1.
6. Бинарные связи один-к-одному и один-ко-многим становятся внешними ключами. Создается копия уникального идентификатора с конца связи «один», и соответствующие столбцы составляют внешний ключ.
Связь один-к-одному между сущностями встречается редко. Если класс принадлежности обеих сущностей является обязательным, то для отображения обеих связанных сущностей можно использовать одну таблицу:
R3 (И1 , И2 , А1 , А2 ).
Однако таким решением злоупотреблять не следует. Если для каждого объекта потребуются свои связи или в запросах потребуется информация по каждой сущности, то выбранное решение усложнит или замедлит работу с БД.
Если для каждой сущности создаются отдельные отношения, то информацию о связях можно отразить, включив в одно из отношений идентификатор из другого отношения. Причем это можно сделать в любом из отношений:
R1 (И1 , А1 , И2 )
R2 (И2 , А2 )
или
R1 (И1 , А1 )
R2 (И2 , А2 , И1 ).
Если класс принадлежности одной из сущностей является необязательным, то идентификатор сущности с необязательным классом добавляется в отношение, соответствующее сущности с обязательным классом принадлежности.
Если класс принадлежности обеих сущностей является необязательным, то, чтобы избежать наличия пустых полей, следует использовать три отношения: по одному для каждой сущности и одно – для отображения связи между ними:
R1 (И1 , А1 )
R2 (И2 , А2 )
R3 (И1 , И2 ).
7. Преобразование бинарной связи один-ко-многим (1:N) зависит только от класса принадлежности N-связной сущности. Если он является обязательным, то можно использовать два отношения (по одному для каждой сущности). В отношение для N-связной сущности добавляется идентификатор 1-связной сущности:
R1 (И1 , А1 )
R2 (И2 , А2 , И1 ).
Если класс принадлежности N-связной сущности является необязательным, то для отображения связи создается третье отношение, которое будет содержать ключи каждой из связанных сущностей:
R1 (И1 , А1 )
R2 (И2 , А2 )
R3 (И1 , И2 ).
8. Для бинарной связи многие-ко-многим (М:N) потребуются три отношения: по одному для каждой сущности и одно дополнительное – для отображения связи между ними. Последнее отношение будет содержать идентификаторы связанных объектов. Ключ этого отношения будет составным:
R1 (И1 , А1 )
R2 (И2 , А2 )
R3 (И1 , И2 ).
9. В случае N-арной связи необходимо использовать (n+1) отношение – по одному для каждой сущности, и одно для связи. Идентификатор каждой сущности станет первичным ключом соответствующего отношения. Отношение, порождаемое связью, будет иметь среди своих атрибутов ключи каждой сущности. Если связь имеет атрибуты, то они становятся атрибутами отношения связи. Например:
R1 (И1 , А1 )
R2 (И2 , А2 )
R3 (И3 , А3 )
R4 (И1 , И2 , И3 , АС4 ).
10. Обобщающей сущности соответствует одно отношение, причем ключ сущности становится ключом отношения. Этому отношению приписываются общие для всех ролевых сущностей атрибуты.
Ролевые элементы и связи, их соединяющие, порождают такое число отношений, которое определяется ранее описанными правилами, причем каждая роль трактуется как обычная сущность. Связываются отношения с помощью ключевого атрибута. Каждому значению ключевого атрибута ролевой сущности соответствует одна запись в обобщающем отношении с таким же значением ключа.
11. Индексы создаются для первичного ключа (уникальный индекс), а также внешних ключей и тех атрибутов, которые будут часто использоваться в запросах.
Физические модели
Физическая модель БД определяет способ размещения данных на носителях (устройствах внешней памяти), а также способ и средства организации эффективного доступа к ним. Поскольку СУБД функционирует в составе и под управлением операционной системы, то организация хранения данных и доступа к ним зависит от принципов и методов управления данными операционной системы.
К вопросам организации данных относятся:
· выбор типа записи – единицы обмена в операциях ввода-вывода;
· выбор способа размещения записей в файле и, возможно, метода оптимизации размещения;
· выбор способа адресации и метода доступа к записям.
Стадия физического проектирования БД в общем случае включает:
· выбор способа организации БД;
· разработку спецификации внутренней схемы;
· описание отображения концептуальной схемы во внутреннюю.
В отличие от ранних СУБД, многие современные системы не предоставляют разработчику какого-либо выбора на этой стадии. Реально к вопросам проектирования физической модели можно отнести:
· выбор схемы размещения данных (разделение по файлам или тип RAID-массива);
· определение числа и типа индексов (например, кластеризованный или некластеризованный в случае MS SQL Server).
Способ хранения БД определяется механизмами СУБД автоматически по умолчанию на основе спецификаций концептуальной схемы БД, и внутренняя схема в явном виде в таких системах не используется. Внешние схемы БД обычно конструируются на стадии разработки приложений.
Лекция 4
Автоматизированное проектирование баз данных
Case-средства разработки баз данных
ER-модели широко используются в практике создания БД. Они применяются при ручном и автоматизированном проектировании с использованием CASE-средств, поддерживающих весь цикл разработки СБД или отдельные его стадии. Ктаким средствам относятся: ProKit*WORKBENCH, Design / IDEF, CASE Oracle (Designer / 2000), Power Designer (S-Designor), ERWin, SILVERRUN, ERStudio и другие. CASE-средства являются сравнительно новым направлением в информационных технологиях. Первая версия инструментария Oracle появилась в 1989 г.
CASE-средства поддерживают концептуальное проектирование, позволяют осуществить логическое и физическое проектирование путем автоматической генерации БД для целевой СУБД. Но следует обратить внимание на различия в терминологии. Во многих CASE-системах ER-модель называется логической моделью, а представление логической структуры целевой БД – физической моделью.
При сравнении CASE-систем кроме используемой методологии ER-моделирования, необходимо учитывать специфические критерии, связанные с реализацией функций автоматизированного проектирования:
· число и перечень поддерживаемых целевых СУБД;
· поддержку распределенных БД;
· поддержку коллективной работы при проектировании (управление правами пользователей, ведение репозитория и т. д.);
· построение концептуальной ER-модели по описанию структуры существующей БД – реверс-инжиниринг;
· автоматизируемые функции проектирования и степень их автоматизации;
· качество и жесткость проектных решений (возможность выбора из нескольких альтернативных решений, возможность ручного вмешательства в процесс);
· надежность работы;
· документирование проекта;
· открытость системы (возможность стыковки с другими средствами);
· удобство графического редактора;
· количественные ограничения (общее число сущностей, число уровней вложенности для обобщенной сущности и др.);
· возможность автоматической оценки объема памяти для проектируемой БД;
· возможность автоматической генерации процедур;
· наличие средств моделирования хранилищ данных;
· требования к ресурсам компьютера;
· операционную среду;
· стоимость системы.
CASE-средства показывают модель с разной степенью детализации:
· только обозначения сущностей и связей между ними;
· сущности + ключи;
· сущности + ключи + внешние ключи;
· сущности + все атрибуты.
Наличие таких возможностей создает существенные удобства, особенно при создании больших и сложных моделей.
Важной характеристикой CASE-средств является возможность получать подмодели из общей модели и обеспечивать интеграцию фрагментов в единую модель. Эти возможности могут быть полезны не только при коллективной разработке проекта – при обсуждении модели с конечными пользователями очень удобно каждому из них предоставлять только ту часть модели, которая имеет для него интерес. Декомпозиция модели облегчает процесс проектирования.
Еще одним критерием сравнения СASE-средств является степень проверки правильности построенных моделей. Ни одна система автоматизации проектирования не может гарантировать соответствия построенной концептуальной модели реалиям предметной области. Это определяется только квалификацией разработчиков, их пониманием предметной области и умением отобразить ее в модели.
Наличие средств проверки моделей может помочь устранить ошибки, связанные с невнимательностью – отсутствие идентификатора у сущности, отсутствие связи объекта с другими объектами, неправильное задание имен, отсутствие информации, необходимой при дальнейшем проектировании (объемные характеристики для классов объектов и связей между ними и т. п.), противоречия в модели (что особенно важно при коллективной разработке) и др.
Многие CASE-средства этим позволяют задавать в модели ограничения целостности и генерируют программы (триггеры, хранимые процедуры), проверяющие эти ограничения при эксплуатации БД. Кроме того, CASE-средства могут генерировать программы ведения БД.
Многие CASE-средства позволяют экспортировать модели в другие системы и, наоборот, импортировать их из других систем.
Пример нотации er-модели – метод idef1x
Методики представления ER-моделей, используемые в разных литературных источниках, а также в разных CASE-системах, несколько отличаются друг от друга. В ряде CASE-средств (ERwin, ERStudio) реализован метод IDEF1X, входящий в семейство стандартов IDEF. Метод разработан для армии США и широко используется в государственных учреждениях, финансовых и промышленных корпорациях. Он прост в изучении и обеспечивает возможность автоматизации. Позволяет построить модель данных, эквивалентную РМД, приведенной к 3НФ.
Каждой сущности присваиваются уникальное имя и номер, разделяемые косой чертой и помещаемые над блоком (рис. 27). Первичный ключ (Primary Key) – это атрибут (атрибуты), однозначно идентифицирующий экземпляр сущности. На диаграмме первичные ключи размещаются выше горизонтальной линии.

Рис. 27. Графическое обозначение сущности в IDEF1X
В одной сущности может быть несколько потенциальных ключей (Candidate Key) – атрибутов, претендующих на роль первичного ключа. Альтернативный ключ (Alternate Key) – потенциальный ключ, не ставший первичным. На диаграмме обозначается AK n.m, где n – номер ключа, m – номер атрибута в ключе. Инверсионный вход (Inversion Entries) – это атрибут или группа атрибутов, которые не определяют экземпляры сущности уникальным образом, но часто используются для обращения к этим экземплярам. На диаграмме обозначается IE n.m, где n – номер инверсионного входа, m – номер атрибута во входе.
Сущность является независимой, если каждый ее экземпляр может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность является зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности. Ассоциированная (ассоциативная) сущность – сущность, связанная с двумя и более другими сущностями. Изображения независимой и зависимой сущностей показаны на рис. 28.

Рис. 28. Зависимая и независимая сущности
Каждая сущность может обладать любым количеством связей с другими сущностями модели. Одна из участвующих в связи сущностей называется родительской сущностью, другая – дочерней или сущностью-потомком.
Связиименуются глаголами или глагольными фразами, которые выражают некоторые бизнес-правила и облегчают чтение диаграмм. Связь сотрудника с заказом может быть определена следующим образом (рис. 29):
·Сотрудник выполняет один или более Заказов;
· Заказ должен выполняться ровно одним Сотрудником.

Рис. 29. Связи на диаграмме
На логическом уровне можно установить:
1) идентифицирующую связь один-ко-многим (обозначается ѕ·);
2) неидентифицирующую связь один-ко-многим (обозначается ----·);
3) связь многие-ко-многим (обозначается ·ѕ·).
При установлении идентифицирующей связи дочерняя сущность автоматически превращается в зависимую. Атрибуты первичного ключа родительской сущности автоматически мигрируют в зону атрибутов первичного ключа дочерней сущности как внешние ключи (Foreign Key) (рис. 30).
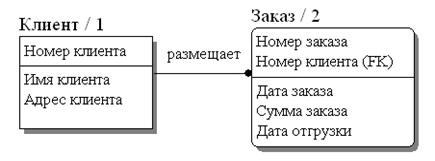
Рис. 30. Идентифицирующая связь
При установлении неидентифицирующей связи дочерняя сущность не превращается в зависимую, а ключевые атрибуты родительской сущности мигрируют в область неключевых атрибутов дочерней сущности (рис. 31).
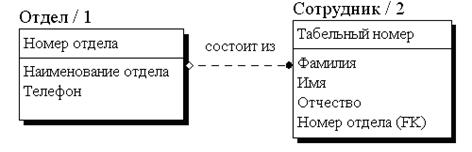
Рис. 31. Неидентифицирующая связь
В случае обязательной связи при генерации схемы БД атрибут внешнего ключа получит признак NOT NULL, хотя внешний ключ не войдет в состав первичного ключа дочерней сущности. В случае необязательной связи внешний ключ может принимать значение Null. Необязательная неидентифицирующая связь помечается прозрачным ромбом со стороны родительской сущности.
Мощность связи обозначает отношение числа экземпляров родительской сущности к числу экземпляров дочерней сущности. Различают случаи (рис. 32):
1) когда одному экземпляру родительской сущности соответствует 0, 1 или много экземпляров дочерней сущности (общий случай);
2) когда одному экземпляру родительской сущности соответствует 0 или 1 экземпляр дочерней сущности (исключены множественные значения);
3) когда одному экземпляру родительской сущности соответствует один или много экземпляров дочерней сущности (исключено нулевое значение);
4) когда одному экземпляру родительской сущности соответствует заданное число экземпляров дочерней сущности (например, 5).

Рис. 32. Мощность связи
Иерархия наследования – особый тип объединения сущностей, имеющих общие характеристики. Например, из общих свойств постоянных сотрудников и совместителей можно сформировать обобщенную сущность (предок) СОТРУДНИК. Специфическая информация может быть расположена в категориальных сущностях (потомках) ПОСТОЯННЫЙ СОТРУДНИК и СОВМЕСТИТЕЛЬ (рис. 33).
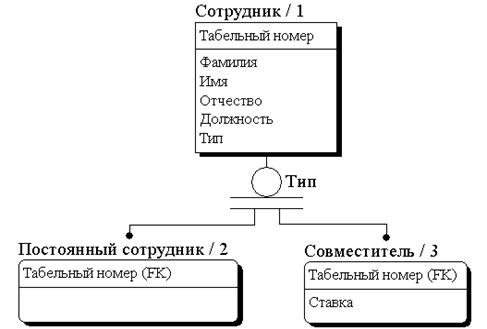
Рис. 33. Иерархия наследования
Дискриминатор – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой. В нашем примере – это тип.
Категория является неполной, если в родовом предке могут существовать экземпляры, не имеющие экземпляров в потомках. Например, сотрудник может быть консультантом, но сущность консультант не внесена в иерархию. Возможна комбинация полной и неполной категорий (рис. 34).
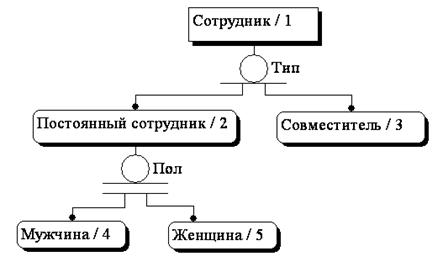
Рис. 34. Комбинация полной и неполной категорий
Отношения многие-ко-многим являются неспецифическими для РБД. Они могут быть установлены в концептуальной (в CASE – логической) модели. На этапе создания даталогической (в CASE – физической) модели такие отношения потребуют разрешения. CASE-средства автоматически преобразуют отношения в специфические с введением новых (ассоциативных) сущностей.
Неспецифическое отношение на рис. 35 указывает, что Студент может изучать много Предметов, а Предмет может изучаться многими Студентами. Мы не можем определить, какой студент изучает какой предмет, пока не введем третью (ассоциативную) сущность Изучение предмета. Каждый экземпляр введенной сущности связан с одним студентом и с одним предметом (рис. 36).

Рис. 35. Отношение многие-ко-многим
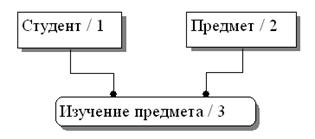
Рис. 36. Разрешение отношения многие-ко-многим
Автоматическая генерация базы данных
На рис. 37 показан интерфейс CASE-средства ER/Studio. Последовательность действий при создании логической модели типична для любой среды визуального проектирования. На панели инструментов выбирается необходимый компонент (сущность, связь, текстовый блок и т. д.) и размещается в окне логической модели. Добавляемые сущности и атрибуты отображаются в Проводнике.
Рис. 37. Интерфейс CASE-средства ER/Studio
Генерация физической моделиосуществляется автоматически. В некоторых средствах используется Мастер, проводящий пользователя через все этапы.
В CASE-средстве ER/Studio генерация физической модели осуществляется по команде Create Physical Model за восемь шагов.
1. Определяется имя физической модели, из списка выбирается целевая платформа будущей БД, принимается решение о проверке правильности модели.
2. Выбираются объекты (таблицы), включаемые в физическую модель. Определяется способ обработки внешних ключей от не вошедших в модель таблиц.
3. Принимается решение о включении или невключении в физическую модель подмоделей и текстовых блоков логической модели. Определяется способ разрешения связей многие-ко-многим.
4. Определяется, какие индексы будут генерироваться для включаемых таблиц (для первичных, альтернативных ключей, инверсионных входов и т. д.). Принимается решение, будет ли добавляться префикс к названию таблиц.
5. Определяется, как будут обрабатываться пробелы и символы верхнего и нижнего регистра в названиях.
6. Выбирается логика проверки законченности и целостности таблиц (таблицы без столбцов, таблицы без первичных ключей, таблицы с типом данных по умолчанию, превышение разрешенного количества столбцов).
7. Выбирается логика проверки соглашения об именах (длина имен, проверка ключевых слов, которые не должны использоваться как названия и т. д.).
8. Выбирается способ проверки целостности индексов таблицы (проверка таблиц без индексов, проверка таблиц с индексами, превышающими пределы).
Настройки, предлагаемые Мастером по умолчанию, во многих случаях можно оставить без изменений. По окончании генерации физической модели формируется отчет с информацией об ошибках, обнаруженных в процессе создания модели.
Следующим шагом является генерация кода. Возможны разные варианты воплощения физической модели. Пользователь должен определить, как реализовать ссылочную целостность, связи через первичные и внешние ключи или через триггеры. Необходим план генерации индексов. Для администратора БД важна настройка физических хранилищ и т. д. Эти действия за семь шагов выполняет Мастер генерации БД, запускаемый командой Generate Target SQL.
1. Выбираются таблицы и представления для включения в генерацию кода БД.
2. Определяется, как будут реализованы первичные и альтернативные ключи.
3. Определяется, будут ли генерироваться неуникальные индексы и триггеры и как будет осуществляться ссылочная целостность.
4. Определяются параметры имеющихся в наличии физических хранилищ.
5. Выбираются дополнительно к таблицам, индексам и триггерам другие типы объектов БД. Можно генерировать правила, значения по умолчанию, типы данных, определяемые пользователем, хранимые процедуры и т. д.
6. Выбирается вариант генерации исходного текста SQL или генерации объектов БД. Генерация SQL-скрипта позволяет создать БД в любое другое время.
7. Принимается решение, будет ли использована для генерации существующая БД или же создана новая. Создается источник данных ODBC.
После генерации БД на экран выводится отчет о создании БД. Наиболее распространенная ошибка – задание типов данных, не поддерживаемых выбранной платформой БД. После генерации БД работа с CASE-средством закончена. Созданная БД может быть открыта уже непосредственно из СУБД.
Лекция 5
Распределенная обработка данных
Требования к распределенным базам данных
Распределенная база данных (DDB – Distributed DataBase) – это совокупность множества взаимосвязанных БД, распределенных в компьютерной сети. БД распределена физически, но логически едина (имеет общую схему данных).
В системах с распределенными БД используются разные технологии распределения данных по узлам сети – фрагментация и тиражирование.
При использовании фрагментации единая логическая БД разбивается на составные части (фрагменты), хранящиеся в разных узлах сети. Разбиение может проводиться по территориальному, функциональному и временному критериям.
При использовании тиражирования в нескольких узлах сети создаются и поддерживаются в согласованном состоянии (синхронизируются) копии всей БД или ее фрагментов. Копия БД называется репликой.
В системах с централизованной БД (много клиентов/один сервер) проблемы управления БД решаются просто, поскольку вся она хранится на сервере. В системах с распределенной БД проектирование, реализация запросов и управление представляют собой сложные задачи. Однако такие системы обеспечивают большую гибкость, надежность и быстродействие. Технологии распределения данных видоизменяют преимущества и недостатки систем. Одно из преимуществ БД – сокращение дублирования – теряется при использовании тиражирования. При этом сохраняются возможности контроля целостности данных для всей системы.
Ведущими поставщиками СУБД сформулированы следующие свойства идеальной системы управления распределенными БД:
· прозрачность относительно расположения данных – СУБД должна представлять все данные так, как если бы они были локальными;
· гетерогенность системы – СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью;
· прозрачность относительно сети – СУБД должна одинаково работать в условиях разнородных сетей;
· поддержка распределенных запросов – пользователь должен иметь возможность объединять данные из любых баз, даже размещенных в разных системах;
· поддержка распределенных изменений – пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права;
· поддержка распределенных транзакций – СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность БД при возникновении отказов как в системах, так и в сети;
· безопасность – СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа;
· универсальность доступа – СУБД должна обеспечивать единую методику доступа ко всем данным.
Ни одна из существующих СУБД не достигает этого идеала поскольку:
· низкая и несбалансированная производительность сетей снижает общую производительность обработки в распределенных транзакциях;
· обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего» и требует специального протокола, что приводит к длительной блокировке изменяемых данных;
· необходимо обеспечить совместимость данных, для хранения которых в разных системах используются разные форматы и кодировки;
· если каталог хранится в одной системе, то удаленный доступ будет замедлен; если будет размножен – изменения придется синхронизировать;
· необходимо обеспечить совместимость СУБД разных типов и поставщиков;
· велика потребность в ресурсах для обнаружения и устранения тупиковых ситуаций в распределенных транзакциях.
Эти причины определили поэтапность введения в СУБД возможностей распределенной обработки. В простейшем случае пользователь может обращаться по сети к записям в БД на других компьютерах. В других случаях СУБД сама проводит аутентификацию удаленного клиента и устанавливает сетевое соединение.
Изучая тенденции развития технологий обработки данных, можно выделить два класса систем:
· системы распределенной обработки данных;
· системы распределенных баз данных.
Системы распределенной обработки данных базировались на многопользовательских операционных системах с БД на центральном компьютере. Клиентские места реализовались в виде терминалов, не имеющих собственных ресурсов. Развитие сетевых технологий, распространение персональных ЭВМ и стандартов открытых систем привело к появлению систем распределенных БД, размещенных в сети разнотипных компьютеров. Система состоит из узлов, каждый из которых является СУБД. БД любого узла доступна пользователю.
При обработке данных в сетевой среде выделяют следующие группы функций:
· презентационная логика (PL – Presentation Logic): ввод и отображение данных – внешний (пользовательский) уровень реализации функциональной обработки и представления;
· бизнес-логика (BL – Business Logic): функциональная обработка, реализующая алгоритм решения задач пользователя;
· манипулирование данными БД в рамках приложения, которое обычно реализуется средствами SQL (DL – Database Logic);
· управление данными и другими ресурсами БД, реализуемое внутренними средствами конкретной СУБД обычно в рамках файловой системы ОС;
· управление процессами обработки: связывание и синхронизация процессов обработки данных разного уровня.
Базовые архитектуры распределенной обработки
Взаимодействие пользователя с БД строится на основе модели «клиент – сервер». Клиентская часть отвечает за целевую обработку данных и организацию взаимодействия с пользователем. Серверная часть обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки. В общем случае эти части функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры клиентов.
Разделение процесса на клиентскую и серверную компоненты позволяет:
· одновременно использовать БД различным прикладным программам;
· централизовать функции управления, такие как защита информации, обеспечение целостности данных, управление совместным использованием ресурсов;
· обеспечивать параллельную обработку запроса в распределенных БД;
· высвобождать ресурсы рабочих станций и сети;
· повышать эффективность управления данными за счет использования специальных серверов баз данных.
В архитектуре «файл-сервер» (рис. 38) средства организации и управления БД (в том числе СУБД) располагаются на машине клиента, а БД, представляющая собой набор специализированных файлов, – на машине-сервере.
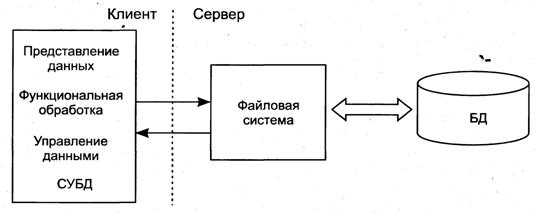
Рис. 38. Архитектура «файл – сервер»
В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми составляющими ОС, обеспечивающими удаленный разделяемый доступ к файлам. Запрос к БД, сформулированный на языке манипулирования данными, преобразуется СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
Недостатки архитектуры:
· высокая загрузка сети и машин-клиентов, так как обмен идет на уровне единиц информации файловой системы (физических записей, блоков, файлов);
· низкий уровень защиты данных, так как доступ к файлам БД управляется общими средствами ОС сервера;
· бизнес-правила функциональной обработки, сосредоточенные в клиентской части, могут быть противоречивыми.
Для схемы характерно наибольшее суммарное время обработки информации.
В архитектуре «выделенный сервер базы данных» (рис. 39) средства управления базой данных и база данных размещены на машине-сервере (DB-сервер).
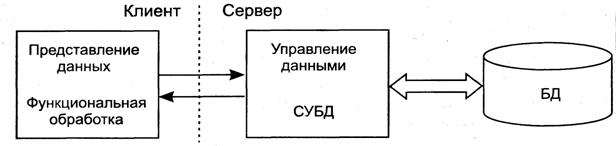
Рис. 39. Архитектура с выделенным сервером базы данных
Обращение к БД осуществляется на языке SQL, поэтому сервер БД часто называют SQL-сервером. Он поддерживается всеми реляционными СУБД (Oracle, Informix, MS SQL, DB2, ADABAS D, InterBase, SyBase). Сервер БД осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после обработки запроса передаваться пользователю. Клиентское приложение может быть реализовано на языке настольных СУБД (MS Access, FoxPro, Paradox, Clipper). Взаимодействие клиентского приложения с SQL-сервером осуществляется через ODBC-драйвер(Open DataBase Connectivity). ODBC стал стандартом де-факто на алгоритм доступа к разнородным БД.
Достоинства архитектуры:
· снижение нагрузки на машины сервера и клиентов;
· снижение сетевого трафика и повышение эффективности обработки за счет оптимизации и буферизации ввода-вывода;
· защита данных средствами СУБД, позволяющая блокировать не разрешенные пользователю действия;
· сервер реализует управление транзакциями и может блокировать попытки одновременного изменения одних и тех же записей.
Недостатки архитектуры:
· бизнес-логика функциональной обработки и представление данных могут быть одинаковыми для нескольких клиентских приложений, что увеличивает потребности в ресурсах (повторение кода программ и запросов);
· бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми.
В архитектуре «активный сервер баз данных» (рис. 40) непротиворечивость бизнес-логики контролируется на стороне сервера. Функции бизнес-логики разделяются между клиентской и серверной частями. Общие функции оформляются в виде хранимых процедур. Вводится механизм триггеров, отслеживающих события БД. При возникновении события (обычно изменения данных) выполняется оператор SQL или вызывается хранимая процедура, связанная с триггером.
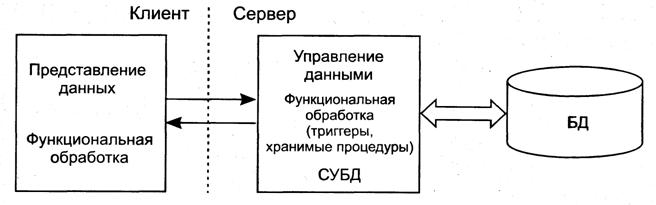
Рис. 40. Архитектура «активный сервер баз данных»
Хранимые процедуры и триггеры могут быть использованы любыми клиентскими приложениями, работающими с БД. Это снижает дублирование программных кодов и исключает необходимость компиляции каждого запроса. Недостатком архитектуры становится возрастающая загрузка сервера.
Такую архитектуру иногда называют моделью с тонким клиентом, в отличие от предыдущих архитектур, называемых моделью с толстым клиентом, где на стороне клиента выполняется большинство функций.
Дальнейшее снижение уровня требований к ресурсам клиента достигается за счет введения сервера приложений, на который переносится значительная часть программных компонентов управления данными и большая часть бизнес-логики. При этом серверы БД обеспечивают исключительно функции СУБД (рис. 41).
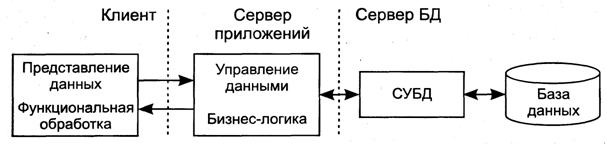
Рис. 41. Трехзвенная архитектура сервера приложений
Связь клиентских рабочих станций с прикладными программами на сервере приложений устанавливается через интерфейс API (Application Programming Interface). Работа клиентской части сводится к вызову функций сервера приложений. Прикладные программы обращаются к серверу БД с помощью SQL-запросов.
К достоинствам трехзвенной архитектуры относятся:
· многократное использование общих функций обработки данных в множестве клиентских приложений;
· централизованное ведение бизнес-логики (при внесении изменений их не нужно тиражировать в клиентских приложениях);
· на клиентских машинах не следует устанавливать компоненту программного обеспечения управления доступом к данным;
· оптимизация доступа к БД (диспетчеризация запросов выполняется сервером приложений);
· возможность отложенного обновления БД при изменении данных в автономном режиме (данные будут обновлены в БД при следующем соединении);
· повышение скорости и надежности за счет дублирования ПО на нескольких серверах приложений, которые могут заменять друг друга;
· перенос проверки полномочий пользователей с сервера БД на сервер приложений.
· уменьшение мощности сервера приложений за счет параллельной работы сервера приложений и сервера БД.
Транзакции
Транзакция – это законченная совокупность действий над БД, которая переводит ее из одного целостного состояния в другое. Если операторы транзакции выполняются, происходит ее нормальное завершение и БД переходит в обновленное (целостное) состояние (ситуация COMMIT на рис. 42). При сбое происходит откат к исходному состоянию БД (ситуация ROLLBACK на рис. 42).
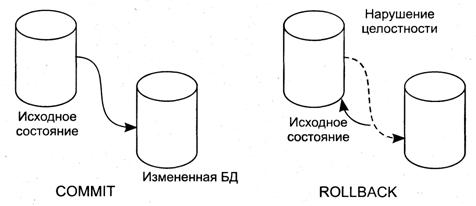
Рис. 42. Выполнение и откат транзакции
К транзакциям предъявляется набор требований, известный под названием ACID (Atomicity, Consistency, Isolation, Durability).
Атомарность (atomicity). Транзакция представляет собой набор законченных действий. Система обеспечивает их выполнение по принципу «все или ничего» – либо выполняются все действия, тогда транзакция фиксируется, либо (при сбое) транзакция откатывается назад, а БД остается в исходном состоянии.
Согласованность (consistency). Предполагается, что в результате выполнения транзакции система переходит из одного корректного состояния в другое.
Изолированность (isolation). При выполнении транзакции данные могут временно находиться в несогласованном состоянии. Такие данные не должны быть видны другим транзакциям до завершения изменений. Система обеспечивает каждой транзакции иллюзию изолированного выполнения, как если бы прочие транзакции либо завершились, либо начнут выполняться после ее завершения.
Долговечность (durability). Если транзакция зафиксирована, то ее результаты должны быть долговечными. Новые состояния всех объектов сохранятся даже в случае аппаратных или системных сбоев.
Рассмотрим две модели транзакций, используемые в большинстве коммерческих СУБД: модель автоматического выполнения транзакций и модель управляемого выполнения транзакций, основанные на инструкциях языка SQL – COMMIT и ROLLBACK.
Автоматическое выполнение транзакций. Модель создана на основе схемы, принятой в СУБД DB2. Транзакция автоматически начинается с выполнения пользователем или программой первой инструкции. Далее происходит последовательное выполнение инструкций, пока транзакция не завершится (рис. 43).
Транзакция заканчивается одним из двух способов:
· инструкцией COMMIT, которая выполняет завершение транзакции (внесенные в БД изменения становятся постоянными, а новая транзакция начинается сразу после инструкции COMMIT);
· инструкцией ROLLBACK, которая отменяет выполнение текущей транзакции (БД возвращается к состоянию начала транзакции, новая транзакция начинается сразу после инструкции ROLLBACK).
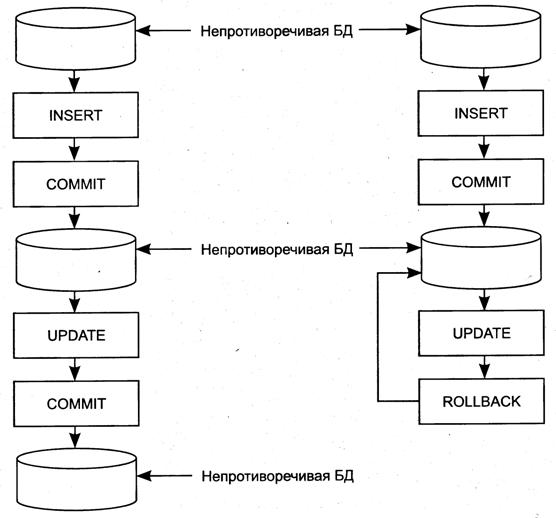
Рис. 43. Модель автоматического выполнения транзакций
Управляемое выполнение транзакций. Модель используется в СУБД Sybase, где применяется диалект Transact-SQL, в котором для обработки транзакций служат четыре инструкции (рис. 44):
· инструкция BEGIN TRANSACTION сообщает о начале транзакции (начало транзакции задается явно);
· инструкция COMMIT TRANSACTION сообщает об успешном выполнении транзакции (при этом новая транзакция автоматически не начинается);
· инструкция SAVE TRANSACTION позволяет создать внутри транзакции точку сохранения и присвоить сохраненному состоянию имя точки сохранения, указанное в инструкции;
· инструкция ROLLBACK отменяет выполнение текущей транзакции и возвращает БД к состоянию, где была выполнена инструкция SAVE TRANSACTION (если в инструкции указана точка сохранения – ROLLBACK TO имя_точки_сохранения) или к состоянию начала транзакции.
Сериализация транзакций
При совместной работе с БД нескольких пользователей СУБД должна гарантировать, что пользователи не будут мешать друг другу. Средства обработки транзакций позволяют изолировать пользователей друг от друга. Подходящими единицами изолированности пользователей являются транзакции.
Чтобы понять, как должны выполняться параллельные транзакции, рассмотрим проблемы, возникающие при параллельной работе с данными.
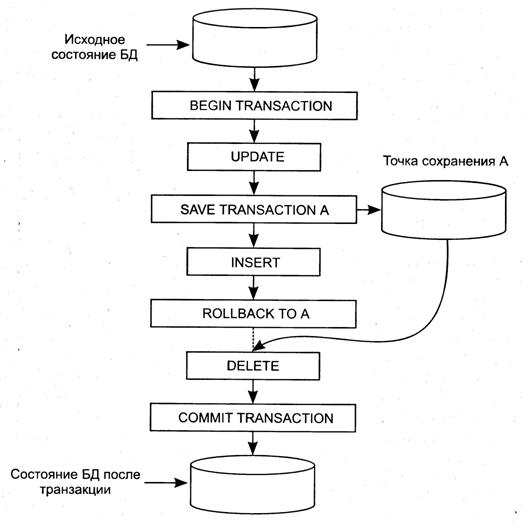
Рис. 44. Модель управляемого выполнения транзакций
Проблема утраченных обновлений заключается в том, что если пользователи параллельно обновляют одни и те же данные, то запомнится обновление, проведенное последним. Остальные будут потеряны (рис. 45).
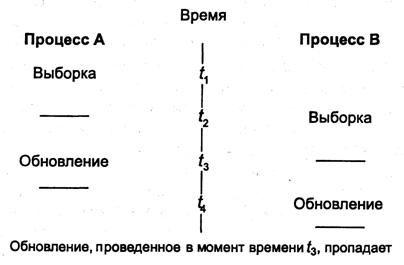
Рис. 45. Проблема утраченного обновления
Проблема зависимости от незафиксированных обновлений состоит в том, что пользователь А может увидеть данные, которые были обновлены пользователем В, но эти обновления не были окончательно зафиксированы. Пользователь В может провести откат БД в исходное состояние (рис. 46).
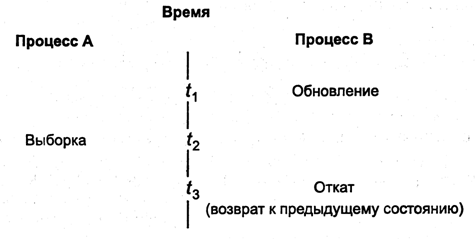
Рис. 46. Преждевременное чтение
Пользователь А будет предпринимать действия над ошибочными данными. Иногда для такого рода проблем используется термин преждевременное чтение.
Еще одна проблема возникает, если пользователь проводит групповую обработку данных, не связанную с корректировкой (вычисляет сумму или среднюю величину), а какие-то значения обрабатываемого множества в этот момент претерпевают изменения в результате выполнения параллельной транзакции. Иногда разделяют ситуации, когда проводится изменение существующих записей и когда осуществляется вставка новой записи. Первая проблема называется неповторяющееся чтение, а вторая – фантомная вставка (строки-призраки) (рис. 47).
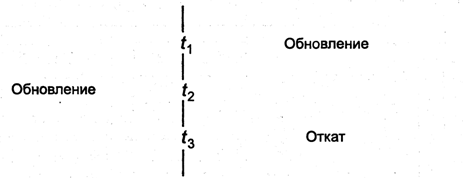
Рис. 47. Фантомная вставка
Чтобы добиться изолированности транзакций, СУБД должна использовать специальные методы регулирования совместного выполнения транзакций.
Метод сериализации транзакций – это механизм их выполнения по такому плану, когда результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Обеспечение такого механизма является основной функцией управления транзакциями. Сериализация транзакций реально обеспечивает изолированность пользователей.
Простейшим решением является действительно последовательное выполнение транзакций, но существуют ситуации, когда можно выполнять операторы разных транзакций в любом порядке, и это не приведет к проблемным ситуациям. Примерами могут служить транзакции, выполняющие только операции чтения, или транзакции, работающие с разными объектами БД.
Между транзакциями могут существовать следующие виды конфликтов:
· транзакция 2 пытается изменять объект, измененный незакончившейся транзакцией 1 (конфликт W-W, запись-запись);
· транзакция 2 пытается изменять объект, прочитанный незакончившейся транзакцией 1 (конфликт R-W, чтение-запись);
· транзакция 2 пытается читать объект, измененный незакончившейся транзакцией 1 (конфликт W-R, запись-чтение).
Для обеспечения сериализации транзакций применяются методы захвата и освобождения объектов по инициативе транзакции. Транзакция захватывает объект, что приводит к его блокировке для других транзакций, и освобождает его только при своем завершении.
Захваты объектов на чтение несколькими транзакциями совместимы (нескольким транзакциям разрешается читать один объект), захват объекта одной транзакцией на чтение не совместим с захватом другой транзакцией этого объекта на запись, захваты одного объекта разными транзакциями на запись не совместимы.
Тем самым, выделяются два основных режима захватов:
· совместный режим – S(Shared), означающий разделяемый захват объекта и необходимый для выполнения операции чтения объекта;
· монопольный режим – X(eXclusive), означающий монопольный захват объекта и необходимый для выполнения операций записи, удаления и модификации.
В СУБД, основанных на архитектуре «клиент–сервер», наиболее распространен подход, реализующий соблюдение протокола двухфазного блокированияобъектов БД. Перед выполнением любой операции над объектом БД от имени транзакции запрашивается захват объекта в совместном или монопольном режиме. Выполнение транзакции разбивается на две фазы:
· фаза роста – накопление захватов (установление блокировок);
· фазафиксации или отката – освобождение захватов (снятие блокировок).
Реализуемость транзакций гарантируется, если блокировки, относящиеся к одновременно выполняемым транзакциям, удовлетворяют правилу: «Ни одна блокировка от имени какой-либо транзакции не должна устанавливаться, пока не будет снята ранее установленная блокировка».
В реляционных БД объектами для захвата могут быть:
· файл – физический (с точки зрения БД) объект, область хранения нескольких отношений и индексов;
· таблица – логический объект, соответствующий множеству записей данного отношения;
· страница данных – физический объект, хранящий записи одного или нескольких отношений, индексную или служебную информацию;
· запись – элементарный физический объект БД.
Блокировка на уровне поля не реализована, поскольку приводит к перегрузке менеджера блокировок и к падению производительности системы.
Выбор вида блокировки и объекта зависит от того, какая операция выполняется, как много таких операций, каковы ограничения по времени обработки. Например, если осуществляется массовая корректировка файла, то лучше открыть его в эксклюзивном режиме, чем последовательно блокировать каждую запись.
Очевидно, что чем крупнее объект захвата, тем меньше захватов будет поддерживаться в системе и на это будут тратиться меньшие накладные расходы. Если выбрать в качестве уровня объектов для захватов файл или отношение, то будет решена даже проблема фантомных вставок.
Однако при использовании для захватов крупных объектов возрастает вероятность конфликтов транзакций и уменьшается возможность их параллельного выполнения. При укрупнении объекта захвата мы умышленно огрубляем ситуацию и видим конфликты в тех ситуациях, когда на самом деле конфликтов нет.
Некоторые системы предусматривают динамическую схему блокировки, заключающуюся в том, что сначала транзакция блокирует большой объект, например страницу. Если проявляется другая транзакция, претендующая на какую-то запись внутри этой страницы, то первая транзакция автоматически уменьшает зону блокировки до уровня записи.
Представления, хранимые процедуры, триггеры
Представление (View) – это виртуальная таблица, содержащая результаты выполнения запроса (оператора SELECT) к одной или нескольким таблицам. Для конечного пользователя представление выглядит как обычная таблица, над которой можно выполнять операторы SELECT, INSERT, UPDATE и DELETE.
Выбор типа представления полностью зависит от задач приложения. Выделяют следующие типы представлений:
· подмножество полей таблицы состоит из одного или более полей таблицы. Используется для упрощения представления данных и обеспечения безопасности;
· подмножество записей таблицы включает определенное количество записей таблицы и также применяется для обеспечения безопасности;
· соединение двух и более таблиц создается соединением нескольких таблиц и используется для упрощения сложных операций соединения;
· агрегирование информации создается группированием данных и также применяется для упрощения сложных операций.
Представления позволяют логически объединять данные нескольких таблиц в более крупную виртуальную таблицу. Представления могут иметь более низкий уровень безопасности, чем исходные таблицы. Запрос для представления выполняется согласно уровню безопасности пользователя. Таким образом, представление можно применять для сокрытия данных от определенной группы пользователей.
Для создания представлений используется мастер или команда CREATE VIEW.
Хранимая процедура (stored procedure) – это набор операторов T-SQL, скомпилированных в единый план выполнения. Этот план сохраняется в кэше процедур, его можно повторно использовать уже без рекомпиляции при каждом вызове. Хранимая процедура может принимать входные параметры, возвращать данные и коды завершения.
Существует два типа хранимых процедур:
· системные, применяемые для управления сервером и отображения информации о БД и пользователях;
· пользовательские, создаваемые пользователями для прикладных задач.
Применение хранимых процедур улучшает производительность и позволяет централизованно контролировать выполнение задачи, что гарантирует соблюдение бизнес-правил.
Для создания хранимых процедур используется мастер или команда CREATE PROCEDURE.
Триггер (trigger) – это особый тип хранимой процедуры, которая автоматически выполняется при изменении таблицы с помощью операторов UPDATE, INSERT или DELETE. Триггеры содержат операторы T-SQL, но в отличие от процедур запускаются не индивидуально, а автоматически при выполнении операций изменения данных. Обеспечивают целостность данных и соблюдение бизнес-правил.
Триггер создается на одной таблице (таблица триггера) в текущей БД, хотя может использовать данные других таблиц и объекты других БД. Триггеры нельзя создавать на представлениях, временных и системных таблицах.
В программе-триггере нельзя использовать операторы создания, реструктуризации, удаления объектов, реконфигурации и восстановления.
Триггеры возвращают результаты своей работы в приложение, подобно хранимым процедурам.
Возможно создание нескольких триггеров на таблице и рекурсивный вызов триггера. Допускаются вложенные триггеры, которые срабатывают в результате выполнения других триггеров.
Для создания триггера используется мастер или команда CREATE TRIGGER.
Тиражирование данных
Тиражирование (репликация) – технология, предусматривающая поддержку копий всей БД или ее фрагментов в нескольких узлах сети. Копия БД называется репликой. Копии БД обычно приближены к местам использования информации.
Синхронизация – процесс обновления реплик, при котором происходит передача обновляемых записей и согласование дублирующихся данных. Обмен данными между репликами может быть как односторонним, так и двусторонним.
Терминология и подходы к реализации репликации отличаются от системы к системе. В некоторых системах используются метафоры из издательской деятельности (издатель, публикация, подписчик). Совокупность данных, которые могут подвергаться тиражированию, называется публикацией.
Использование технологии тиражирования имеет следующие преимущества:
· сокращение сетевого трафика при выполнении запросов;
· повышение доступности данных (доступ к локальной копии БД обеспечивается, даже если доступ к центральному серверу невозможен);
· повышение производительности (данные приближены к месту их использования, не нужно ждать доступности всех частей распределенной БД);
· повышение автономности рабочих мест пользователей;
· повышение надежности системы (наличие множества копий повышает вероятность восстановления системы в критических ситуациях).
Дублирование данных при использовании тиражирования влечет за собой:
· дополнительный расход памяти;
· возможность возникновения конфликтов при корректировке;
· наличие временного лага между фиксацией события в БД и доступностью этой информации для всех пользователей сети;
· повышенные требования к рабочим станциям;
· необходимость тщательного продумывания схемы тиражирования.
Требования к механизму тиражирования зависят от задач, которые решает вся система. Существует много схем обновления копий в распределенной БД. По моменту внесения изменений в реплики различают:
· синхронное тиражирование;
· асинхронное тиражирование.
При асинхронном тиражировании обновление всех копий БД может проводиться неодновременно. При этом возможна некоторая рассинхронизация состояния локальных БД во времени. При этом удается обойти проблему ограниченной пропускной способности и недостаточной надежности сети. Если один сервер, требующий обновления данных, выходит из строя, то система продолжает работать с остальными. Обновление данных на сбойном сервере произойдет автоматически после восстановления его работоспособности.
Механизм асинхронного тиражирования данных особенно актуален при работе в глобальной сети. При использовании телефонных линий механизм двухфазовой фиксации транзакции практически нереализуем, поскольку все оборудование одновременно в работоспособном состоянии почти никогда не находится.
Асинхронное тиражирование может быть:
· периодическим;
· апериодическим.
Периодическое тиражирование выполняется через заданные интервалы времени. Время тиражирования выбирается исходя из частоты и интенсивности изменений, допустимого времени рассинхронизации состояний источника и приемника, объема передаваемых данных, допустимой загрузки коммуникаций. Момент выполнения апериодического тиражирования определяется каким-либо событием и может быть реализован с помощью хранимых процедур или триггеров.
Синхронное тиражирование предполагает завершение транзакции только после успешной модификации всех копий. Используется механизм двухфазной фиксации (2РС): основная система связывается с подчиненными копиями БД и одновременно вносит в них изменения, блокируя соответствующие записи. Если хотя бы одна копия недоступна, изменения не выполняются. Механизм двухфазовой фиксации предъявляет высокие требования к системе и снижает степень автономности узлов, поэтому в технологии тиражирования используется редко.
Наиболее жестким является критерий полной эквивалентности копий, требующий, чтобы по завершении транзакции все копии логического элемента данных были идентичны. Такая технология синхронизации противоречит одной из основных целей тиражирования (повышение производительности за счет большей автономности частей системы) и используется редко.
Типичным протоколом тиражирования по критерию полной эквивалентности копий является Read-Once/Write-All (ROWA) – одно чтение (какой-либо одной копии), запись во все физические копии. Протокол ROWA прост, но требует доступности всех копий элемента данных для завершения транзакции. Сбой на одном из узлов приведет к дублированию транзакции.
Реплики в БД с тиражированием могут быть:
· равноправными;
· неравноправными (одна из реплик считается основной).
При наличии неравноправных реплик изменения можно вносить только в основную реплику. Другие реплики доступны пользователям только по чтению. Такая схема называется тиражированием из основного узла. При этом данные асинхронно копируются из основной в иные реплики. При такой схеме предъявляются повышенные требования к сохранности основной реплики и надежности функционирования основного узла, поэтому иногда модель дополняют горячим резервированием основного узла. Основной узел тиражирует изменения на подчиненные узды и на узел с резервной копией. Если основной узел выходит из строя, то владельцем данных становится резервный.
Тиражирование слиянием предполагает выполнение операций на удаленном компьютере, который может быть отключен от сети. Автономная СУБД записывает операции с данными и их очередность. Автономный компьютер связывается с издателем (сервером, на котором корректируется тиражируемая БД) и пересылает последовательность операций, проведенных в удаленной БД. Тиражирование слиянием обеспечивает максимальную автономность удаленной БД.
Инициаторами обновления реплик могут быть:
· рабочие станции (обновление по запросу, выполняемое по определенному графику или вручную);
· сервер (принудительная рассылка тиража, осуществляемая в момент появления изменений или по графику).
Обновление содержания реплик может быть обеспечено также:
· копированием моментального снимка БД;
· копированием и выполнением очереди подтвержденных транзакций;
· копированием изменений из журнала БД.
Моментальный снимок БД (snapshot) отражает состояние БД или ее фрагмента на момент получения снимка. При копировании моментального снимка БД часто передаются не только данные, но и служебная информация.
В процессе тиражирования транзакций от издателя к подписчикам передаются не данные, а операции над ними. Само обновление происходит на рабочей станции. Передачу транзакций можно использовать, когда в автономной БД уже хранится копия основной БД. При использовании этой схемы периодически необходимо выполнять полную синхронизацию данных по методу моментального снимка. Тиражирование транзакций лучше использовать, когда объем БД велик, а операций над ними выполняется немного. В случае обновления на подписчике тиражирование инициируется издателем. Как только издатель подтверждает транзакцию, он сообщает дистрибьютеру о том, что данные изменены.