

Уровни изоляции: Serializable (упорядочиваемость)
Самый высокий уровень изолированности; транзакции полностью изолируются друг от друга. На этом уровне результаты параллельного выполнения транзакций для базы данных в большинстве случаев можно считать совпадающими с последовательным выполнением тех же транзакций (по очереди в каком-либо порядке).
Repeatable read (повторяемость чтения)
Уровень, при котором чтение одной и той же строки или строк в транзакции дает одинаковый результат. (Пока транзакция не завершена, никакие другие транзакции не могут модифицировать эти данные.)
Read committed (чтение фиксированных данных)
Принятый по умолчанию уровень для Microsoft SQL Server. Завершенное чтение, при котором отсутствует черновое, "грязное" чтение.(т.е. чтение одним пользователем данных, которые не были зафиксированы в БД командой COMMIT) Тем не менее в процессе работы одной транзакции другая может быть успешно завершена и сделанные ею изменения зафиксированы. В итоге первая транзакция будет работать с другим набором данных. Это проблема неповторяемого чтения.
В Oracle блокировки на чтение нет, вместо этого «читающая» транзакция получает ту версию данных, которая была актуальна в базе до начала «пишущей».
В Informix можно предотвратить конфиликты между читающими и пишущими транзакциями, установив параметр конфигурации USELASTCOMMITTED (начиная с версии 11.1), при этом читающая транзакция будет получать последние подтвержденные данные [1]
Read uncommitted (чтение незафиксированных данных)
Низший уровень изоляции, соответствующий уровню 0. Он гарантирует только отсутствие потерянных обновлений[2]. Если несколько транзакций одновременно пытались изменять одну и ту же строку, то в окончательном варианте строка будет иметь значение, определенное последней успешно выполненной транзакцией.
МОДУЛЬ 3
1. SQL (ˈɛsˈkjuˈɛl; англ. Structured Query Language — «язык структурированных запросов») — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. SQL основывается наисчислении кортежей.
Язык SQL представляет собой совокупность
операторов;
инструкций;
и вычисляемых функций.
Стандартный SQL содержит в себе два языковых подмножества : Язык описания данных и Язык манипулирования данными. Data Definition Language Data Manipulation Language Первое подмножество предназначено для метаданных - для генерации таблиц, индексов, табличных пространств, пользователей, ролей, прав и т.д. Второе подмножество для запросов данных из созданных структур, удаления, добавления и модификации данных.
3. RDBMS — Relational DataBase Management System(РСУБД — Реляционная Система Управления Базами Данных)
проблема хранения и обработки большого объема данных существовала всегда, но с развитием ИТ она стала беспокоить не только ряд крупнейших корпораций, но и гораздо более широкий круг компаний. Что же стало предпосылкой к ее появлению и в чем ее качественное отличие от типичной ситуации недостатка ИТ-ресурсов при бурном росте бизнеса? Есть, по крайней мере, несколько причин, которые послужили катализатором появления Big Data.
В первую очередь, возросло число генераторов данных, причем весьма большого объема – это Web 2.0 системы, а именно социальные сети разных видов, данные электронной почты, Twitter, Wiki-проекты. Кроме того, огромные объемы данных могут генерироваться датчиками различных типов – Сall Data Records (CDR) сотовых операторов, телеметрические данные, информация с камер видеонаблюдения и т.п. Во-вторых, значительное уменьшение стоимости хранения привело к тому, что многие компании могут позволить себе следовать парадигме «данные слишком ценны, чтобы их уничтожать».
Но главная проблема заключается в том, что кроме количества данных изменился и их характер. Основной объем этих данных – неструктурированная информация, поэтому ее хранение и обработка в привычных системах на основе реляционных БД, как правило, малоэффективна. И постепенно пришло осознание того, что реляционные СУБД не являются оптимальным решением для ряда ситуаций, а это, в свою очередь, привело к появлению целого семейства решений, которые можно классифицировать одним словом – NoSQL- системы.
Рис.
1. Работа данных в rDBMS-системе

Термин NoSQL расшифровывается как Not Only SQL (не только SQL). На сегодняшний момент существует большое количество таких систем, но все они, как правило, обладают следующими характеристиками:
гибкость использования: у подобных систем отсутствуют требования к наличию схемы данных, а в качестве модели хранения выступает JSON1;
встроенные возможности горизонтального масштабирования и параллельной обработки;
возможность быстрого получения первых результатов.
Сравним типичный сценарий работы с данными в RDBMS (Relational Database Management System, реляционная СУБД) и в NoSQL-системе. В случае с RDBMS необходимо разработать схему хранения данных. Кроме того, перед загрузкой в СУБД данные должны быть очищены и преобразованы в требуемые форматы, только после этого ими можно будет воспользоваться через язык SQL-запросов. Таким образом, необходимо пройти как минимум шесть этапов (причем трансформация и загрузка данных могут быть весьма длительными и трудоемкими процессами), прежде чем появятся первые результаты (см. рис. 1).
Рис.
2. Работа данных в noSqL-системе

В случае с NoSQL ситуация выглядит значительно проще: после поступления данных в хранилище система уже готова к работе, конечно, при условии что у вас есть готовая программа обработки (см. рис. 2).
4. Клиент-серверная технология - это стиль работы приложений, где клиентский процесс запрашивает обслуживание у процесса сервера. Проще говоря, сервер - это программа, предоставляющая доступ к каким-либо услугам, например к электронной почте, файлам, ftp, Web, или данным (в качестве сервера баз данных). Клиент – это приложение, которое соединяется с сервером, чтобы воспользоваться предоставляемыми им услугами.
Клиенты и серверы имеют различные функции. Некоторые примеры функций сервера: создание резервных копий для защиты от потери данных, защита от нежелательного вторжения, своевременный доступ к предоставляемым услугам, предоставление надежных средств хранения и обеспечение высокой доступности поставляемой услуги.
Некоторые примеры клиентских функций: предоставление дружественного пользователю интерфейса, экономное использование ресурсов сервера, и, разумеется, реализация целей приложения.
Например, приложения-клиенты типа Eudora или Microsoft Outlook представляют собой почтовых клиентов. Они соединяются с почтовым сервером, для получения и отправки почтовых сообщений. Internet Explorer - клиент, который соединяется с Web-сервером.
Приложения-клиенты MS SQL сервера, входящие в поставку этого программного продукта, включают Query Analyzer, SQL Server Enterprise Manager, Profiler, SQL Agent и Data Transformation Services. Каждое из этих приложений соединяется с механизмом базы данных и использует его услуги различным способом. Чтобы получить доступ к обслуживанию, каждый из этих клиентов посылает запроссерверу. Сервер обрабатывает запрос и посылает назад результаты.
Хотя это и не является требованием клиент-серверной модели, почти в каждом случае сервер позволяет соединяться с ним сразу многим клиентам. Клиент, в свою очередь, может (но не обязательно) соединяться сразу со многими серверами.
Ниже на рисунке представлена типичная среда баз данных с архитектурой клиент-сервер.
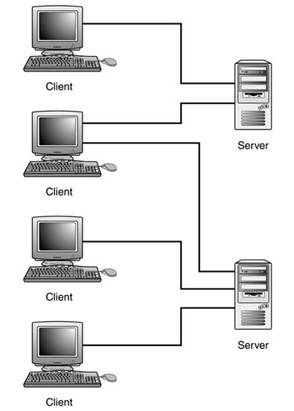
До клиент-серверной архитектуры были еще два других важных типа архитектуры:
Локальная архитектура. Здесь вся бизнес-логика, хранение данных, доступ к данным и вычисления производились на одном компьютере.
Файл-серверная архитектура. Здесь представительская и бизнес-логика сосредоточены на локальном компьютере. Данные могут быть размещены в локальной сети на файловом сервере.
Появившаяся им на смену многопользовательская система управления реляционными базами данных (relational database management system или RDBMS) была действительно ключевой технологией, которая реализовывала архитектуру вычислений в среде клиент-сервер. RDBMS служил центральным хранилищем данных организаций. RDBMS был предназначен для обеспечения многопользовательского доступа к общедоступному набору данных. Все управление блокировкой и соединениями реализуется RDBMS наряду с защитой. Был создан язык структурированных запросов (Structured Query Language или SQL) в качестве универсального языка программирования для запроса определенных данных от RDBMS.
Клиент-серверная архитектура включила в себя лучшие особенности как локальной, так и файл-серверной архитектуры. Она использует всю мощь PC для представления данных наряду со сложной бизнес-логикой. RDBMS предоставляет централизованное хранилище данных и обеспечивает управление одновременным параллельным доступом к данным. Архитектура клиент-сервер может принимать разные формы в зависимости от того, как Вы собираетесь разделить представительскую логику, бизнес-логику и организацию данных.
Традиционная клиент-серверная архитектура.
Большинство знакомо с традиционным двухуровневым видом клиент-серверной архитектуры, которая включает приложение-клиент, выполняющееся на рабочей станции, и приложение-сервер, выполняющееся на сервере.
В типичной двухуровневой клиент-серверной системе, приложение-клиент соединяется непосредственно с приложением-сервером, типа SQL-сервера. Это обычно означает, что каждая клиентская рабочая станция должна быть загружена специализированными библиотеками и драйверами для установки подключения к серверу. Приложения-клиенты ответственны за регистрацию на сервере и поддержание подключения, а также обработку сообщений об ошибках, и т.п. возвращенных с сервера.
В двухуровневой системе бизнес-логика может быть сосредоточена на клиенте, сервере или обоих сразу.
Трехуровневая и n-уровневая клиент-серверная архитектура.
Клиент-серверная модель действительно предполагает больше, чем только эти два уровня. Средний уровень - программа, которая находится между клиентом и сервером и обеспечивает выгодные услуги и серверному и клиентскому уровню. Приложения, которые используют средний уровень, называют обычно трехуровневыми или n-уровневыми приложениями. Когда между оконечными точками существует много средних уровней, каждый из которых предоставляет различные услуги, эту модель называют n-уровневой моделью.
Главная цель n-уровневой архитектуры состоит в том, чтобы отделить бизнес-логику от представительской и от уровней доступа к данным к набору объектов многократного использования, иногда называемых бизнес-объектами. Бизнес-объекты - подобно хранимым процедурам позволяют Вам централизовать в них бизнес-логику и хранятся отдельно от приложений-клиентов.
Этот тип архитектуры имеет много преимуществ. При реализации n-уровневой архитектуры, приложения могут быть намного проще в разработке и обслуживании. Вы можете относительно легко интерактивно добавить новые приложения, многократно используя существующие бизнес-объекты. Изменения в базах данных и бизнес-логике могут быть сделаны, не меняя приложений-клиентов. Программисты могут сконцентрироваться на разработке бизнес-правил, не заботясь о проблемах интерфейса пользователя.
В то же время наряду со множеством преимуществ n-уровневая архитектура для ее успешной реализации требует сложной инфраструктуры обработки услуг нижнего уровня, таких как пул подключений, обслуживание потоков и операционный контроль. Некоторые программные продукты, такие как Microsoft Transaction Server (MTS) и .NET Framework решают многие из этих сложных проблем с инфраструктурой и уменьшают сложность осуществления n-уровневой архитектуры.