

№1
Понятия архитектуры ВМ
Под архитектурой вычислительной машины обычно понимается логическое построение ВМ, то есть то, какой машина представляется программисту. Впервые термин «архитектура вычислительной машины» (computer architecture) был употреблен фирмой IBM при разработке машин семейства IBM 360 для описания тех средств, которыми может пользоваться программист, составляя программу на уровне машинных команд. Подобную трактовку называют «узкой», и охватывает она перечень и формат команд, формы представления данных, механизмы ввода/вывода, способы адресации памяти и т. п. Из рассмотрения выпадают вопросы физического построения вычислительных средств: состав устройств, число регистров процессора, емкость памяти, наличие специального блока для обработки вещественных чисел, тактовая частота центрального процессора и т. д. Этот круг вопросов принято определять понятием организация или структурная организация.
Типы архитектуры
Различают 2 основных типа структур ВМ
1) Структура с непосредственными связями (классическая Фон Неймановская структура). Особенности связи в такой структуре (число линий в шине)0 определяется видом информации, характером и интенсивностью обмена. Основное достоинство такой структуры связано с возможностью устранения узких мест в информации, обмене путем изменения лишь отдельных связей, не затрагивая систему в целом. Основной недостаток – невозможность изменения, реконфигурации.
2) Структура на основе общей шины.
Общая шина служит для передачи всей информации. Достоинство – простота реализации ВМ, простота реконфигурирования. В каждый момент времени идет передача информации через шину. Основную нагрузку на шину создает общая информация между процессором и основной памятью, связанная с извлечением команды данных из памяти и запись в нее результатов вычислений. На долю операции ввода-вывода остается небольшая часть пропускной способности шины.
1.3
Концепция машины с хранимой в памяти программой
ВМ, в которой определенным образом закодированные команды программы хранятся в памяти называется ВМ с хранимой в памяти программой. Все ВМ последних поколений основываются на концепциях Фон Неймана.
В основе концепции ВМ с хранимой в памяти программой лежат 4 принципа
1) Принцип двоичного кодирования
Все командные данные представляются (кодируются) двоичными значениями набором 0 и 1. Каждый вид инф использует формат представления. Последовательность битов в формате наделенном логическим смыслом называется полем в численном формате. Обычно выделяется поле знаков и поле значащих разрядов. В формате команды – поле кода операции, поле адресной части.
2) Принцип программного управления
Вычисления предусмотренные алгоритмом решения задачи выполнены согласно программе, состоящей из последовательности слов (команд). Каждая команда предписывает выполнение операции из набора операций, реализуемых данной ВМ.
Команды программы хранятся в последовательных ячейках памяти с последовательной нумерацией адресов. Команды выполняются в естественной последовательности т.е. в порядке их положения в программе. При необходимости изменения естественной последовательности команд используется специальная программа перехода. Решение об ее использовании принимается либо на основе результата предшествующего вычисления, либо безусловно.
3) Принцип однородности памяти
Это означает, что данные команды располагаются в ячейках единой области памяти и извне не различимы, а различимы только по способу использования. Такая идеология позволяет осуществлять над командами такие же операции, что и над числами, позволяет получать новую программу, в виде результата выполнения операций над командами другой программой. Эта идея используется в трансляторах.
разработка принстонского университета лежит в основе архитектур большинства ВМ.
Существует гарвардская архитектура с раздельной памятью, реализованная в кэш-памяти. Узкое место принстонской архитектуры – проблемы связанные с ограничением пропускной способности процессор-память.
4) Принцип адресности
Принцип заключается в том, что структура памяти организована в виде пронумерованных ячеек, причем процессору в любой момент доступно содержимое ячейки. Двоичные коды команд разделяются на единичные блоки называемые машинными словами, хранящимися в ячейках памяти. Для доступа к ячейкам используются их номера (адреса).
№2
^ Типы структур вычислительных машин и систем Достоинства и недостатки архитектуры вычислительных машин и систем изначально зависят от способа соединения компонентов. При самом общем подходе можно говорить о двух основных типах структур вычислительных машин и двух типах структур вычислительных систем. ^ Структуры вычислительных машин В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и на основе шины. Типичным представителем первого способа может служить классическая фон-неймановская ВМ (см. рис. 1.3). В ней между взаимодействующими устройствами (процессор, память, устройство ввода/вывода) имеются непосредственные связи. Особенности связей (число линий в шинах, пропускная способность и т. п.) определяются видом информации, характером и интенсивностью обмена. Достоинством архитектуры с непосредственными связями можно считать возможность развязки «узких мест» путем улучшения структуры и характеристик только определенных связей, что экономически может быть наиболее выгодным решением. У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между ЦП и памятью, и «развязать» его достаточно непросто [56]. Кроме того, ВМ с непосредственными связями плохо поддаются реконфигурации. В варианте с общей шиной все устройства вычислительной машины подключены к магистральной шине, служащей единственным трактом для потоков команд, данных и управления (рис. 1.4). Наличие общей шины существенно упрощает реализацию ВМ, позволяет легко менять состав и конфигурацию машины. Благодаря этим свойствам шинная архитектура получила широкое распространение в мини-и микроЭВМ. Вместе с тем, именно с шиной связан и основной недостаток архитектуры: в каждый момент передавать информацию по шине может только одно устройство. Основную нагрузку на шину создают обмены между процессором и памятью, связанные с извлечением из памяти команд и данных и записью в память результатов вычислений. На операции ввода/вывода остается лишь часть пропускной способности шины. Практика показывает, что даже при достаточно быстрой шине для 90% приложений этих остаточных ресурсов обычно не хватает, особенно в случае ввода или вывода больших массивов данных
№3
Из чего состоит любая вычислительная система? В первую очередь, это то, что в англоязычных странах принято называть словом hardware, или техническое обеспечение: процессор, память, монитор, дисковые устройства и т.д., обычно объединенные магистральным соединением, которое называется шиной. Итак что же такое симметричные мультипроцессорные системы (SMP). Системами с общей памятью называют системы, в которых несколько процессоров имеют общую оперативную память см. рис. 11.
Системы с массовым параллелизмом (МРР).
Системы с распределённой памятью содержат несколько процессоров, каждый из которых имеет свою оперативную память
№4
Два вида архитиктуры системных команд CISC и RISC
CISC (англ. Complex instruction set computing, или англ. complex instruction set computer — компьютер с комплексным набором команд) — концепция проектированияпроцессоров, которая характеризуется следующим набором свойств:
нефиксированное значение длины команды;
арифметические действия кодируются в одной команде;
небольшое число регистров, каждый из которых выполняет строго определённую функцию.
Недостатки: высокая стоимость аппаратной части; сложности с распараллеливанием вычислений.
Методика построения системы комманд CISC противоположна другой методике - RISC. Различие этих концепций состоит в методах программирования, а не в реальной архитектуре процессора. Практически все современные процессоры эмулируют наборы команд как RISC так и CISC типа.
В рабочих станциях, серверах среднего звена и персональных компьютерах используются процессоры с CISC. Наиболее распространенная архитектура команд процессоров мобильных уcтройств - SOC и мэйнфреймов - RISC. В микроконтроллерах различных устройств RISC используется в подавляющем большинстве случаев.
RISC (англ. restricted (reduced) instruction set computer[1][2] — компьютер с сокращённым набором команд) — архитектура процессора, в которой быстродействие увеличивается за счёт упрощения инструкций, чтобы их декодирование было более простым, а время выполнения — короче. Первые RISC-процессоры даже не имели инструкций умножения и деления. Это также облегчает повышение тактовой частоты и делает более эффективной суперскалярность (распараллеливание инструкций между несколькими исполнительными блоками).
№5 ?
Сложность команд в том что Первый — это состав операций, выполняемых вычислительной машиной, и их сложность. Второй — место хранения операндов, что влияет на количество и длину адресов, указываемых в адресной части команд обработки данных. Классификация по составу и сложности команд.
№6
место хранения операндов, что влияет на количество и длину адресов, указываемых в адресной части команд обработки данных.
стековую; аккумуляторную; регистровую; с выделенным доступом к памяти.
1)Стеком называется память, по своей структурной организации отличная от основной памяти ЭВМ, Принципы построения стековой памяти детально рассматриваются позже, здесь же выделим только те аспекты, которые требуются для пояснения особенностей АСК на базе стека.
2) Архитектура на базе аккумулятора исторически возникла одной из первых. В ней для хранения одного из операндов арифметической или логической операции в процессоре имеется выделенный регистр — аккумулятор. В этот же регистр заносится и результат операции. Поскольку адрес одного из операндов предопределен, в командах обработки достаточно явно указать местоположение только второго операнда.
3) В машинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как регистры общего назначения (РОН), Эти регистры, в каком-то смысле, можно рассматривать как явно управляемый кэш для хранения недавно использовавшихся данных.
№7 типы и формы команд : Машинные команды оперируют данными, которые в этом случае принято называть операндами. К наиболее общим (базовым) типам операндов можно отнести: адреса, числа, символы и логические данные. Помимо них ЭВМ обеспечивает обработку и более сложных информационных единиц: графических изображений, аудио-, видео- и анимационной информации. Такая информация является производной от базовых типов данных и хранится в виде файлов на внешних запоминающих устройствах. Для каждого типа данных в ЭВМ предусмотрены определенные форматы.
Число в формате с фексированой запетой: Представление числа X в форме с фиксированной запятой (ФЗ), которую иногда называют также естественной формой, включает в себя знак числа и его модуль в q-ичном коде. Здесь q — основание системы счисления или база. Для современных ЭВМ характерна двоичная система (q=2), но иногда используются также восьмеричная (q= 8) или шестнадцатеричная (q =16) системы счисления. Запятую в записи числа называют соответственно двоичной, восьмеричной или шестнадцатеричной. Знак положительного числа кодируется двоичной цифрой 0, а знак отрицательного числа — цифрой 1.
Упакованные целые числа: В АСК современных микропроцессоров имеются команды, оперирующие целыми числами, представленными в упакованном виде. Связано это с обработкой мультимедийной информации. Формат предполагает упаковку в пределах достаточно длинного слова (обычно 64-разрядного) нескольких небольших целых чисел, а соответствующие команды обрабатывают все эти числа параллельно. Если каждое из чисел состоит из четырех двоичных разрядов, то в 64-разрядное слово можно поместить до 16 таких чисел. Неиспользованные разряды заполняются нулями, В микропроцессорах фирмы Intel, начиная с Pentium ММХ, присутствуют специальные команды для обработки мультимедийной информации (ММХ-команды), оперирующие целыми числами, упакованными в квадрослова (64-разрядные слова). Предусмотрены три формата (рисунок 2.12): упакованные байты (восемь 8-разрядных чисел); упакованные слова (четыре 16-разрядных числа) и упакованные двойные слова (два 32-разрядных числа). Байты в формате упакованных байтов нумеруются от 0 до 7, причем байт 0 располагается в младших разрядах квадрослова. Аналогичная система нумерации и размещения упакованных чисел применяется для упакованных слов (номера 0-3) и упакованных двойных слов (номера 0-1). Идентичные форматы упакованных данных применяются также в другой технологии обработки мультимедийной информации, предложенной фирмой AMD. Эта технология носит название 3DNow!, а реализована в микропроцессорах данной фирмы.
Числа с плавуещей запетой: От недостатков ФЗ в значительной степени свободна форма представления чисел с плавающей запятой (ПЗ), известная также под названиями нормальнойили полулогарифмической формы. В данном варианте каждое число разбивается на две группы цифр. Первая группа цифр называется мантиссой, вторая —порядком. Число представляется в виде произведения X = ± mq±p, где т – мантисса числа X, р – порядок числа, q – основание системы счисления.
№8
Типы команд:
Арифметические и логические |
Пересылки данных |
Управление потоком команд |
Системные операции |
Операции с плавающей точкой |
Десятичные операции |
Операции над строками |
Команды традиционного машинного уровня можно разделить на несколько типов, которые показаны на рис. 4.3.
Тип операции |
Примеры |
Арифметические и логические |
Целочисленные арифметические и логические операции: сложение, вычитание, логическое сложение, логическое умножение и т.д. |
Пересылки данных |
Операции загрузки/записи |
Управление потоком команд |
Безусловные и условные переходы, вызовы процедур и возвраты |
Системные операции |
Системные вызовы, команды управления виртуальной памятью и т.д. |
Операции с плавающей точкой |
Операции сложения, вычитания, умножения и деления над вещественными числами |
Десятичные операции |
Десятичное сложение, умножение, преобразование форматов и т.д. |
Операции над строками |
Пересылки, сравнения и поиск строк |
№9
Форматом команды называется заранее оговоренная структура полей ее кода с разметкой номеров разрядов (бит), определяющих границы отдельных полей команды, или с указанием числа разрядов (бит) в определенных полях, позволяющая ЭВМ распознавать составные части кода.
Структура команды определяется составом, назначением и расположением полей в коде.
Длинна команд: 16 и 32 бай
№10
Подразумеваемый операнд
В команде может не содержаться явных указаний об операнде; в этом случае операнд подразумевается и фактически задается кодом операции команды.
Подразумеваемый адрес
В команде может не содержаться явных указаний об адресе участвующего в операции операнда или адреса, по которому должен быть размещен результат операции, но этот адрес подразумевается.
Непосредственная адресация
В команде содержится не адрес операнда, а непосредственно сам операнд. При непосредственной адресации не требуется обращения к памяти для выборки операнда и ячейки памяти для его хранения. Это способствует уменьшению времени выполнения программы и занимаемого ею объёма памяти. Непосредственная адресация удобна для хранения различного рода констант.
Прямая адресация
Адрес указывается непосредственно в виде некоторого значения, все ячейки располагаются на одной странице. Преимущество этого способа в том, что он самый простой, а недостаток — в том, что разрядность регистров общего назначения процессора должна быть не меньше разрядности шины адреса процессора.
Относительная (базовая) адресация
При этом способе адресации исполнительный адрес определяется как сумма адресного кода команды и базового адреса, как правило хранящегося в специальном регистре — регистре базы.
Относительная адресация позволяет при меньшей длине адресного кода команды обеспечить доступ к любой ячейке памяти. Для этого число разрядов в базовом регистре выбирают таким, чтобы можно было адресовать любую ячейку оперативной памяти, а адресный код команды используют для представления лишь сравнительно короткого «смещения». Смещение определяет положение операнда относительно начала массива, задаваемого базовым адресом.
Укороченная адресация
В адресном поле командного слова содержатся только младшие разряды адресуемой ячейки. Дополнительный указательный регистр.
Адресация с регистром страницы является примером сокращённой адресации. При этом вся память разбивается на блоки-страницы. Размер страницы диктуется длиной адресного поля.
Регистровая адресация
Регистровая адресация является частным случаем укороченной. Применяется, когда промежуточные результаты хранятся в одном из рабочих регистров центрального процессора. Поскольку регистров значительно меньше чем ячеек памяти, то небольшого адресного поля может хватить для адресации.
Косвенная адресация
Адресный код команды в этом случае указывает адрес ячейки памяти, в которой находится адрес операнда или команды. Косвенная адресация широко используется в малых и микроЭВМ, имеющих короткое машинное слово, для преодоления ограничений короткого формата команды (совместно используются регистровая и косвенная адресация).
Адресация слов переменной длины
Эффективность вычислительных систем, предназначенных для обработки данных, повышается, если имеется возможность выполнять операции со словами переменной длины. В этом случае в машине может быть предусмотрена адресация слов переменной длины, которая обычно реализуется путем указания в команде местоположения в памяти начала слова и его длины.
Стековая адресация
Стековая память, реализующая безадресное задание операндов, особенно широко используется в микропроцессорах и Мини-ЭВМ.
Автоинкрементная и автодекрементная адресации
Поскольку регистровая косвенная адресация требует предварительной загрузки регистра косвенным адресом из оперативной памяти, что связано с потерей времени, такой тип адресации особенно эффективен при обработке массива данных, если имеется механизм автоматического приращения или уменьшения содержимого регистра при каждом обращении к нему. Такой механизм называется соответственно автоинкрементной и автодекрементной адресацией. В этом случае достаточно один раз загрузить в регистр адрес первого обрабатываемого элемента массива, а затем при каждом обращении к регистру в нём будет формироваться адрес следующего элемента массива.
При автоинкрементной адресации сначала содержимое регистра используется как адрес операнда, а затем получает приращение, равное числу байт в элементе массива. При автодекрементной адресации сначала содержимое указанного в команде регистра уменьшается на число байт в элементе массива, а затем используется как адрес операнда.
Автоинкрементная и автодекрементная адресации могут рассматриваться как упрощенный вариант индексации — весьма важного механизма преобразования адресных частей команд и организации вычислительных циклов, поэтому их часто называют автоиндексацией.
Индексация
Для реализуемых на ЭВМ методов решения математических задач и обработки данных характерна цикличность вычислительных процессов, когда одни и те же процедуры выполняются над различными операндами, упорядоченно расположенными в памяти. Поскольку операнды, обрабатываемые при повторениях цикла, имеют разные адреса, без использования индексации требовалось бы для каждого повторения составлять свою последовательность команд, отличающихся адресными частями.
Программирование циклов существенно упрощается, если после каждого выполнения цикла обеспечено автоматическое изменение в соответствующих командах их адресных частей согласно расположению в памяти обрабатываемых операндов. Такой процесс называется модификацией команд, и основан на возможности выполнения над кодами команд арифметических и логических операций.
№11
Машинный цикл — составляющая часть машинной команды. Машинный цикл состоит из машинных тактов.
При реализации одного машинного цикла процессор может:
принять из памяти байт команды;
принять из памяти байт данных;
принять из устройства ввода-вывода (УВВ) байт данных;
принять из стека байт данных;
принять вектор прерывания;
выдать в память байт данных;
выдать в стек байт данных;
выдать на УВВ байт данных.
Основными показателями, характеризующими ЭВМ, в настоящее время являются:
1. Быстродействие или производительность; основной единицей измерения служит МИПС (англ. аббревиатура million instructions per second) — число миллионов операций в секунду. Первые ЭВМ имели быстродействие порядка 0,1 МИПС, современные супер-ЭВМ — сотни МИПС, быстродействие ЭВМ пятого поколения свыше 1000 МИПС).
2. Емкость памяти; единицей измерения являются байт — количество двоичных цифр, обрабатываемых или запоминаемых как единое целое, и его производные: кбайт — килобайт = 1024 байт или около 1000 байт; Мбайт — мегабайт — 1024 кбайт или около 1 млн. байт; Гбайт — гигабайт — 1024 Мбайт или приблизительно 1 млрд. байт; стандартная страница машинописного текста содержит около 2 кбайт).
3. Время доступа к ячейкам памяти, в соответствии с которым она делится на оперативную (внутреннюю), связанную непосредственно с работой процессора, и долговременную (внешнюю), информация из которой, перед тем как подвергнуться переработке или использоваться в виде комплекса программ, должна быть перенесена в оперативную.
Показатель эффективности - это производительность ЭВМ. Производительность ЭВМ характеризуется параметрами: пропускная способность - объем работы в единицу времени; время ответа - промежуток от момента приема задания пользователя до получения ответа; коэффициент готовности - степень готовности обработать запрос на вычисление.
Соотношение перечисленных факторов и назначения системы:
система реального времени - МIN t_ответа;
пакетная обработка - MAX пропускная способность;
система разделения времени (СРВ) - МАХ пропускной способности при соответствующих (разумных) ограничениях на t_ответа.
Критерии
эффективности вычислительного
процесса
1.
Среднее время ответа -
время пребывания работ в системе (среднее
время обращения).
![]() где
n - число заданий tзi - время завершения
i-ой работы;tni - время поступления i-ой
работы.
^ 2.
Среднее взвешенное время обращения
где
n - число заданий tзi - время завершения
i-ой работы;tni - время поступления i-ой
работы.
^ 2.
Среднее взвешенное время обращения
![]() где
i - трудоемкость i-ой работы (время
нахождения на цикле)
W
- определяет во сколько раз время ответа
превышает требуемое время выполнения
(t обслуживания).
Т-
суммарное (общее) время выполнения
работ. Чем меньше время выполнения, тем
выше загрузка ресурсов.
Количество
задач за единицу времени в системе.
Суммарная
загрузка всех устройств.
Штраф
за задержку задач (вперед про пустить
задачу за которую больше "платят",
т.е. у которой больше приоритет).
где
i - трудоемкость i-ой работы (время
нахождения на цикле)
W
- определяет во сколько раз время ответа
превышает требуемое время выполнения
(t обслуживания).
Т-
суммарное (общее) время выполнения
работ. Чем меньше время выполнения, тем
выше загрузка ресурсов.
Количество
задач за единицу времени в системе.
Суммарная
загрузка всех устройств.
Штраф
за задержку задач (вперед про пустить
задачу за которую больше "платят",
т.е. у которой больше приоритет).
№12 организация шин :Объединение функциональных блоков в ЭВМ с шинной архитектурой осуществляется посредством следующей системы шин: шины данных, по которой осуществляется обмен информацией между блоками ЭВМ; шины адреса, используемой для передачи адресов (номеров ячеек памяти или портов ввода-вывода, к которым производится обращение); шины управления для передачи управляющих сигналов.
Информационный поток ВМ — это совокупность циркулирующих в логистической системе, между логистической системой и внешней средой сообщений, необходимых для управления и контроля логистических операций. Информационный поток может существовать в виде бумажных и электронных документов.
Что бы охарактеризовать шину нужно описать следующее
1) совокупность сигнальных линий 2) Физические, механические, электрические параметры 3) используемые сигналы арбитража, состояния, управления, синхронизации.
№13
Типы шин: шин ЭВМ входят шина адреса ША, шина данных ШД, шина управления ШУ.
Шина ввода\ вывода.
Шина VME приобрела большую популярность как шина ввода/вывода в рабочих станциях и серверах на базе RISC-процессоров. Эта шина высоко стандартизована, имеется несколько версий этого стандарта. В частности, VME32 - 32-битовая шина с производительностью 30 Мбайт/с, а VME64 - 64-битовая шина с производительностью 160 Мбайт/с.
Системная шина (FSB) – канал, по которому процессор соединен с другими устройствами компьютера. К шине напрямую подключен только процессор, другие устройства компьютера подключены к ней через разнообразные контроллеры. Центральный процессор через Системную шину (FSB) подключается к системному контроллеру (Северный Мост или North Bridge). Северный мост оснащен контроллером ОЗУ (или же этот контроллер встроен в центральный процессор), а также контроллеры шин для подключения периферийных устройств.
?№14
Последовательная шина USB по своей организации существенно отличается от параллельных шин (интерфейсов), в ней нет отдельных линий для данных, адреса управления. Все протокольные функции связаны с обменом по шине, выполняются с помощью одной пары сигнальных проводов путем пересылки определенным образом организованных цепочек байт, называемых пакетами. Кабель USB состоит всего из четырех проводов. Два из них предназначены для передачи питающего напряжения. Физическая реализация кабеля USB - экранированная витая пара с длиной сегмента до 5 метров для полной скорости передачи или неэкранированная невитая пара с длиной сегмента до 3-х метров для низкой скорости передачи. Линии питания в USB обеспечивают подачу питающего напряжения на устройства, подключенные к ней, и не требует для этих устройств дополнительного источника питания. Передача данных по соответствующим линиям USB осуществляется в полудуплексном режиме.
№15
Шина данных — это основная шина, ради которой и создается вся система. Количество ее разрядов (линий связи) определяет скорость и эффективность информационного обмена, а также максимально возможное количество команд.
Шина адреса — вторая по важности шина, которая определяет максимально возможную сложность микропроцессорной системы, то есть допустимый объем памяти и, следовательно, максимально возможный размер программы и максимально возможный объем запоминаемых данных. Количество адресов, обеспечиваемых шиной адреса, определяется как 2N, где N — количество разрядов. Например, 16-разрядная шина адреса обеспечивает 65 536 адресов. Разрядность шины адреса обычно кратна 4 и может достигать 32 и даже 64. Шина адреса может быть однонаправленной (когда магистралью всегда управляет только процессор) или двунаправленной (когда процессор может временно передавать управление магистралью другому устройству, например контроллеру ПДП). Наиболее часто используются типы выходных каскадов с тремя состояниями или обычные ТТЛ (с двумя состояниями).
Шина управления — это вспомогательная шина, управляющие сигналы на которой определяют тип текущего цикла и фиксируют моменты времени, соответствующие разным частям или стадиям цикла. Кроме того, управляющие сигналы обеспечивают согласование работы процессора (или другого хозяина магистрали, задатчика, master) с работой памяти или устройства ввода/вывода (устройства-исполнителя, slave). Управляющие сигналы также обслуживают запрос и предоставление прерываний, запрос и предоставление прямого доступа.
№16
Приоритеты:
1) Статические
2) Динамические: а) случайные; б) циклический сдвиг; в) циклический сдвиг на основание последовательного запроса; г) равные приоритеты;
а) случ. приоритет – после текущей процедуре арбитража, арбитр случ. образом меняет приоритет;
б) циклический сдвиг – все устройства устраиваются в цепочку в зависимости от приоритета, после каждой процедуре арбитража приоритет понижается;
в) циклический сдвиг на основания последнего запроса – выстраиваются в цепочку, приоритет устройство, которое только что владел шинной, становится наименьшей.
г) равный приоритет – у всех устройств приоритеты равны, и устройства сами, без центрального арбитра, договариваются, кто будет следующий.
д) Арбитраж с самостоятельным выбором – в этой схеме нет центрального арбитра, каждому устройству назначается номер (или адрес) и в процессе процедуре арбитража, все устройства желающие получить доступ, выставляют на общей шине свой адрес, затем просматривают шину, если устройство видит, что адрес на шине больше его собственного, то она снимает младшие биты; в результате выиграет то устройство, у которого адрес больше.
Схемы арбитража:
1) Централизованный – параллельный или последовательный (с цепочкой ШЗ, с цепочкой ЗШ, с цепочкой ПШ);
2) Децентрализованный – параллельный или последовательный;
1) Централизованный параллельный – устройство в любой момент выставить сигнал захват шины, арбитр выбранного устройства устанавливает сигнал подтверждения. Выбранное устройство может быть выбран только тогда, если снят сигнал с шины занятости. Если запросившие устройство обладает большим приоритетом, то арбитр шины прерывает его передачу, то есть снимает его сигнал подтверждения шины. То устройство, которому запретили передавать обязано завершить транзакцию. Для параллельного арбитража основной недостаток это большое число линии. Поэтому больше 8 устройств, как правило, не соединяют, если нужно больше, тогда делают каскадное соединение.
№167
Протокол шины pci:
Обмен информацией по шине PCI и PCI-X организован в виде транзакций — логически завершенных операций обмена. В типовой транзакции участвуют два устройства —инициатор обмена (initiator), он же ведущее устройство (master), и целевое устройство (ЦУ, target)), оно же ведомое (slave). Правила взаимодействия этих устройств определяются протоколом шины PCI. Устройство может следить за транзакциями на шине и не являясь их участником (не вводя никаких сигналов); режиму слежения соответствует термин Snooping. Есть особый тип транзакции (Special Cycle) — широковещательный, в котором инициатор протокольно не взаимодействует ни с одним из устройств. В каждой транзакции выполняется одна команда — как правило, чтение или запись данных по указанному адресу. Транзакция начинается с фазы адреса, в которой инициатор задает команду и целевой адрес. Далее могут следовать фазы данных, в которых одно устройство (источник данных) помещает данные на шину, а другое (приемник) их считывает. Транзакции, в которых присутствует множество фаз данных, называются пакетными. Есть и одиночные транзакции (с одной фазой данных). Транзакция может завершиться и без фаз данных, если целевое устройство (или инициатор) не готово к обмену. В шине PCI-X добавлена фаза атрибутов, в которой передается дополнительная информация о транзакции.
СИНХРОННЫЙ И АСИНХРОННЫЙ SCSI-ПРОТОКОЛЫ
Как интерфейс системного уровня SCSI для передачи данных от источника к получателю использует протокол с подтверждением установления соединения (handshaking). В SCSI-интерфейсе используются три типа таких протоколов: асинхронный, синхронный и быстрый синхронный. Асинхронный протокол напоминает протокол работы параллельного порта. Передача каждого байта должна быть затребована и подтверждена, прежде чем начнется передача следующего байта информации. Асинхронная передача данных является надежным, но медленным способом передачи данных. В синхронном и быстром синхронном протоколе передача данных (но не команд) осуществляется без циклов запрос/подтверждение. За счет этого удается немного увеличить скорость передачи данных по сравнению с асинхронным режимом, но для согласования прохождения сигналов запроса и подтверждения требуется определенная временная задержка (иногда называемая смещением). В быстром синхронном протоколе используются более короткие сигналы, что приводит к повышению скорости передачи данных. Важно понимать, что в SCSI-системах может использоваться любой из этих протоколов передачи данных. Необходимо лишь обеспечить использование одинакового протокола инициатором и исполнителем во время обмена информацией между ними. Обычно SCSI-устройства начинают обмен с использованием асинхронного протокола.
№18
Стандартизация шин.
Принцип IBM-совместимости подразумевает стандартизацию интерфейсов отдельных компонентов ПК, что, в свою очередь, определяет гибкость системы в целом, т.е. возможность по мере необходимости изменять конфигурацию системы и подключать различные периферийные устройства. В случае несовместимости интерфейсов используются контроллеры. Кроме того, гибкость и унификация системы достигаются за счет введения промежуточных стандартных интерфейсов, таких как интерфейсы последовательной и параллельной передачи данных. Эти итерфейсы необходимы для работы наиболее важных периферийных устройств ввода и вывода. Системная шина предназначена для обмена информацией между CPU, памятью и другими устройствами, входящими в систему. К системным шинам относятся: GTL, имеющая разрядность 64 бит, тактовую частоту 66, 100 и 133 МГц; EV6, спецификация которой позволяет повысить ее тактовую частоту до 377 МГц. Шины ввода/вывода совершенствуются в соответствии с развитием периферийных устройств ПК. В табл. 2.5 представлены характеристики некоторых шин ввода/вывода. Шина ISA в течение многих лет считалась стандартом ПК, однако и до сих пор сохраняется в некоторых ПК наряду с современной шиной PCI. Корпорация Intel совместно с Microsoft разработала стратегию постепенного отказа от шины ISA. Вначале планируется исключить ISA-разъемы на материнской плате, а впоследствии.
№19
№20
Иерархия запоминающих устройств:
Память часто называют "узким местом" фон-Неймановских ВМ из-за ее серьезного отставания по быстродействию от процессоров, причем, разрыв этот неуклонно увеличивается. Так, если производительность процессоров возрастает вдвое примерно каждые 1,5 года, то для микросхем памяти прирост быстродействия не превышает 9% в год (удвоение за 10 лет), что выражается в увеличении разрыва в быстродействии между процессором и памятью приблизительна на 50% в год. При создании системы памяти постоянно приходится решать задачу обеспечения требуемой емкости и высокого быстродействия за приемлемую цену. Наиболее эффективным решением является создание иерархической памяти. Иерархическая память состоит из ЗУ различных типов (см. рисунок ниже), которые, в зависимости от характеристик, относят к определенному уровню иерархии. Более высокий уровень меньше по емкости, быстрее и имеет большую стоимость в пересчете на бит, чем более низкий уровень. Уровни иерархии взаимосвязаны: все данные на одном уровне могут быть также найдены на более низком уровне, и все данные на этом более низком уровне могут быть найдены на следующем нижележащем уровне
№21
Остновная память:
Основная память представляет собой единственный вид памяти, к которой ЦП может обращаться непосредственно. Основную память образуют запоминающие устройства с произвольным доступом. Каждая ячейка имеет уникальный адрес, позволяющий различать ячейки при обращении к ним для выполнения операций записи и считывания. Основная память может включать в себя два типа устройств: оперативные запоминающие устройства (ОЗУ) и постоянные запоминающие устройства (ПЗУ).
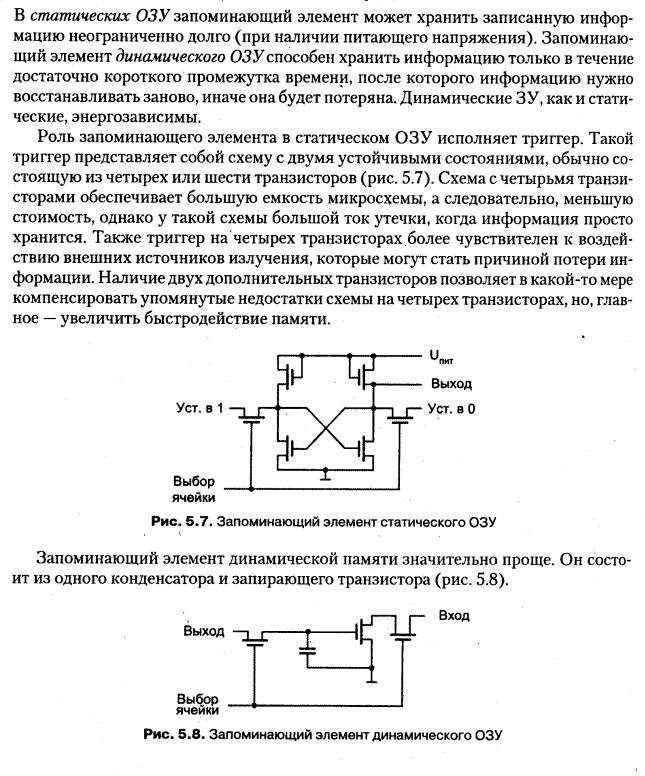
Преимущественную долю основной памяти образует ОЗУ, называемое оперативным, потому что оно допускает как запись, так и считывание информации, причем обе операции выполняются однотипно, практически с одной и той же скоростью. В англоязычной литературе ОЗУ соответствует аббревиатура RAM - Random Access Memory. Для большинства типов полупроводниковых ОЗУ характерна энергозависимость: даже при кратковременном прерывании питания хранимая информация теряется. Микросхема ОЗУ должна быть постоянно подключена к источнику питания и поэтому может использоваться только как временная память. Вторую группу полупроводниковых ЗУ основной памяти образуют энергонезависимые микросхемы ПЗУ (ROM - Read-Only Меmоrу). ПЗУ обеспечивает считывание информации, но не допускает ее изменения (в ряде случаев информация в ПЗУ может быть изменена, но этот процесс сильно отличается от считывания и требует значительно большего времени). Энергозависимые ОЗУ можно подразделить на две основные подгруппы: динамическую память (DRAM - Dynamic Rаndоm Access Меmory) и статическую память (SRAM - Static Rаndоm Access Меmory). В статических ОЗУ запоминающий элемент может хранить записанную информацию неограниченно долго (при наличии питающего напряжения). Запоминающий элемент динамического ОЗУ способен хранить информацию только в течение достаточно короткого промежутка времени, после которого информацию нужно восстанавливать заново, иначе она будет потеряна. Динамические ЗУ, как и статические, энергозависимы. Роль запоминающего элемента в статическом ОЗУ исполняет триггер. Taкой триггер представляет собой схему с двумя устойчивыми состояниями, обычно состоящую из четырех или шести транзисторов(см. рисунок ниже)
Вопрос 22
{Организация микросхем памяти}



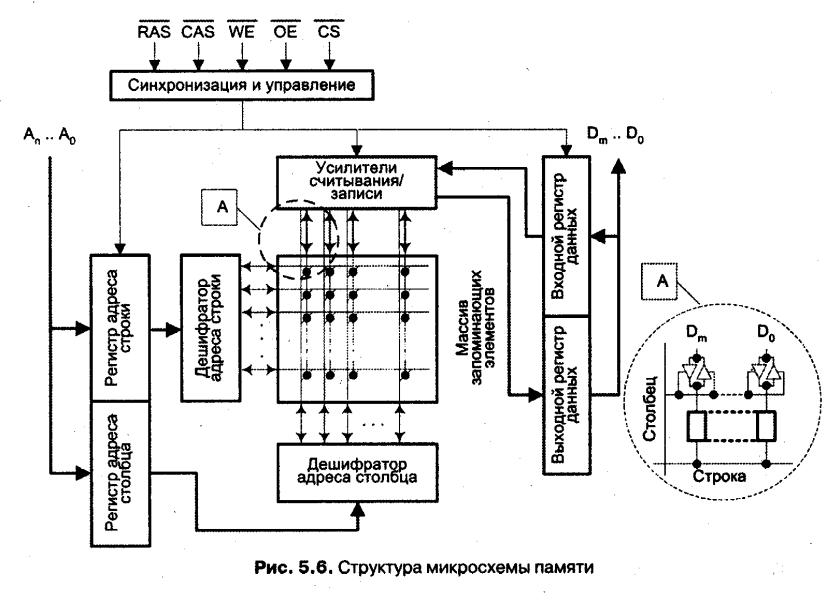









Вопрос 23
{ускорение ядра микросхем ЗУ}








Вопрос 24
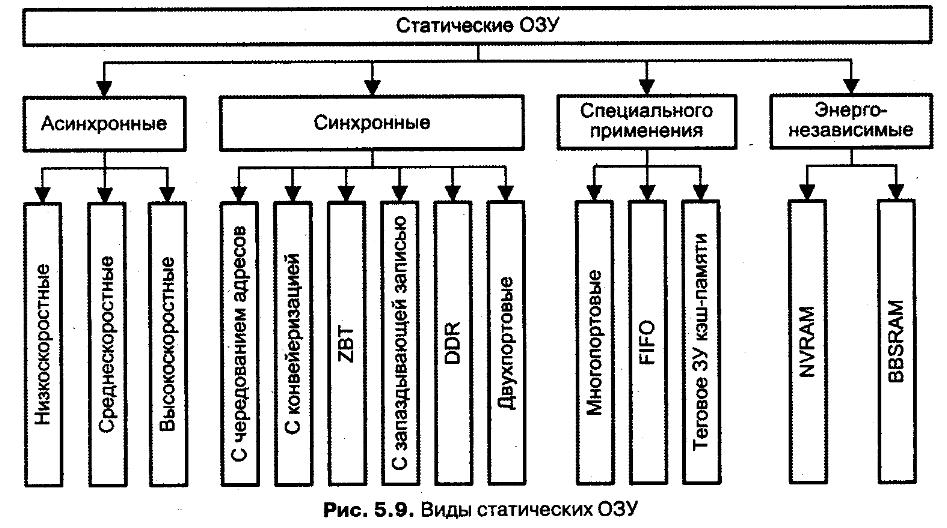
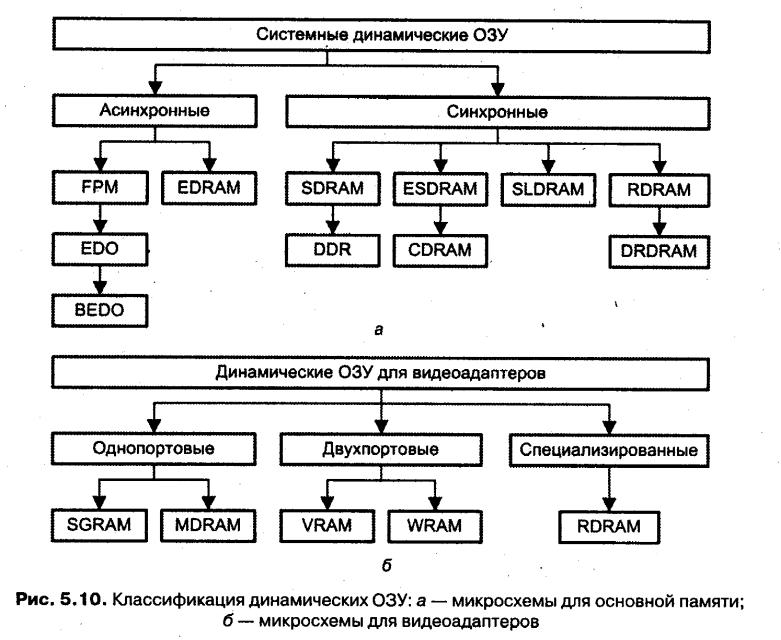
{статическая и динамическая память. классификация статических ОЗУ. классификация динамических ОЗУ }




Вопрос 25
{постоянные
зу. ПЗУ программируемые при
изготовлении.многократно программируемые
пзу }





Вопрос 26
{кэш-память. способы отображения оперативной памяти
на кэш - память }
КЭШ-ПА́МЯТЬ, вид сверхбыстродействующей компьютерной памяти, применяемый для ускорения доступа к данным из оперативной памяти (см.ОПЕРАТИВНАЯ ПАМЯТЬ). Кэш-память хранит копии наиболее часто используемых участков оперативной памяти. Поскольку время доступа к кэш-памяти в несколько раз меньше, чем к оперативной памяти, а в большинстве случаев необходимая информация находится в кэш-памяти, то кэширование позволяет существенно ускорить работу компьютера. Современные микропроцессоры обладают собственным встроенным запоминающим устройством, которое также используется как кэш-память. Ее в технической литературе называют кэш-памятью первого уровня. Кэш-память на основе статической памяти (SRAM), которая размещается на материнской плате (см. МАТЕРИНСКАЯ ПЛАТА), называют кэш-памятью второго уровня (level two cache, L2 cache). Микрокомпьютеры конца 1990-х годов обычно оснащаются кэш-памятью емкостью 256—512 килобайт.


Вопрос 27
{устройства управления. Функции уу. Модель уу. Структура уу. }
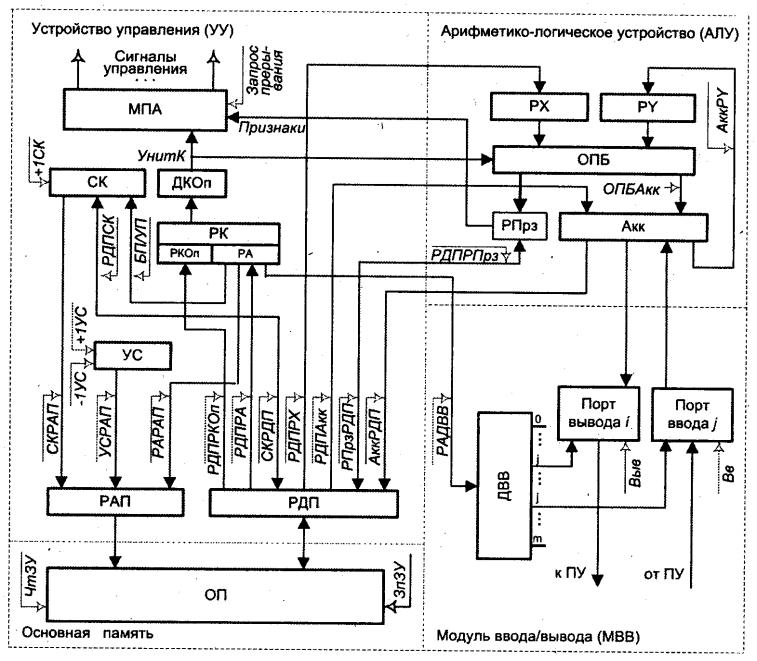
УСТРОЙСТВО УПРАВЛЕНИЯ ЭВМ - координирует совместную работу процессора, внешней памяти, устройств ввода-вывода и др. посредством управляющих сигналов, вырабатываемых устройством управления в соответствии с реализуемой программой.
Вопрос 28
{микропрограммный автомат с жесткой логикой. Межпрограмный автомат с программируемой логикой. Понятие мо,мк,мп }
Микропрограммный автомат с жесткой логикой
Тип микропрограммного автомата определяет название всего УУ. В микропрограммном автомате с жесткой логикой (см. рисунок ниже) выходные сигналы управления реализуются за счет однажды соединенных логических схем. Микропрограммный автомат с жесткой логикой. Код операций (КОП), хранящийся в регистре команды, используется для определения того, какие сигналы управления и в какой последовательности должны формироваться. При этом, желательно иметь в УУ отдельный логический сигнал для каждого кода операции (IK). Это может быть реализовано с помощью дешифратора.
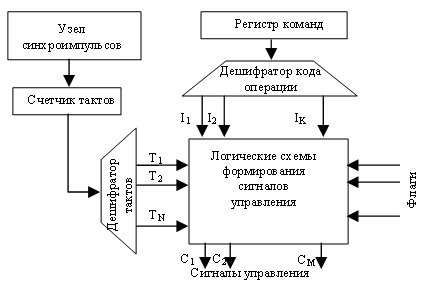
Микропрограммный автомат с жесткой логикой
Сигналы управления, по которым выполняется микрооперация, должны вырабатываться в строго определенные моменты времени, поэтому все сигналы управления "привязаны" к импульсам синхронизации. Счетчик тактов сбрасывается (устанавливается в состояние Т1) по окончании цикла очередной команды. Цикл команды может потребовать разного количества тактов. На каждом такте вырабатывается своя микрокоманда, состоящая из нескольких сигналов управления. Дополнительным фактором, влияющим на выработку сигналов управления, являются флаги.
Микропрограммный автомат с программируемой логикой
Отличительной особенностью микропрограммного автомата с программируемой логикой является наличие памяти микропрограмм. Каждой команде вычислительного устройства в этой памяти соответствует микропрограмма. Идею микропрограммирования сигналов управления предложил в 1951 г. Морис Уилкс (Кембриджский университет, Британия). ЭВМ стала иметь три уровня выполнения команд: между командами и сигналами управления появилась микропрограмма. Команда ЭВМ интерпретировалась в микропрограмму. Аппаратное обеспечение должно было выполнять только микропрограммы с ограниченным набором микрокоманд, отсюда существенно уменьшались аппаратные затраты. К 70-м годам идея о том, что написанная программа сначала должна интерпретироваться микропрограммами, а не выполняться непосредственно электроникой, стала преобладающей. Однако в современных процессорах, когда аппаратные затраты стали менее существенны, отказались от идеи микропрограммирования, так как она стала сдерживать рост производительности. Типичная схема микропрограммного автомата приведена на рисунке ниже.
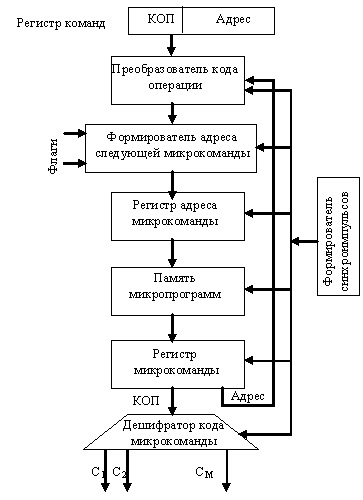
Микропрограммный автомат с программируемой логикой
Запуск микропрограммы выполнения операции осуществляется путем передачи кода операции из регистра команды на вход преобразователя, в котором код операции (КОП) преобразуется в начальный адрес микропрограммы. Выбранная по этому адресу из памяти микропрограмм микрокоманда заносится в регистр. Микрокоманда содержит КОП и адресную часть. КОП поступает на дешифратор и формирует управляющие сигналы, адрес передается для формирования адреса следующей микрокоманды. Этот адрес может зависеть от флагов, КОП, внешних устройств.
Известны два подхода к построению логики формирования управляющих импульсов (УИ), необходимых для работы операционных устройств (ОУ) процессора. Один из них заключается в том, что каждой операции процессора соответствует набор логических (комбинационных) схем, формирующих управляющие импульсы (УИ), необходимые для работы ОУ. Если подать сигналы, соответствующие коду микрооперации (МО), а тактже сигналы условий выполнения этой МО на входы комбинационной схемы (КС), то требуемое действие будет выполнено с помощью определенных УИ на выходах КС в момент подачи тактового сигнала. Набор таких КС, оптимизированных для формирования УИ, управляющих работой ОУ при выполнении совокупности определенных МО, называется управляющим автоматом (УА). Такой принцип формирования УИ получил название жесткой логики и широко применяется во многих компьютерах. Преимуществом такой способа формирования УИ является большое быстродействие при выполнении МО, т.к. большинство из них выполняются за один такт работы процессора. Недостатками являются большие аппаратные затраты и трудности при внесении изменений в работу ОУ.
Другой принцип организации управления ОУ, заключается в том, что каждой МО ставится в соответствие слово (или часть слова), называемое микрокомандой (МК) и хранимое в памяти внутри процессора подобно тому, как хранятся в памяти команды компьютера. Каждой команде процессора соответствует микропрограмма (МП), т. е. набор МК указывающих, какие УИ и в какой последовательности необходимо возбуждать для выполнения данной операции. Такой подход получил название микропрограммирования или мягкой логики. При микропрограммной реализации команд процессора логика управления ОУ реализуется не в виде электронной схемы, а в виде закодированной информации, находящейся в каком-то массиве регистров процессора или памяти. Как правило микропрограммы хранятся в постоянном запоминающем устройстве (ПЗУ), находящемся внутри процессора. По сути при такой реализации команд процессора, внутри него используется УА, построенный по принципу фон-неймоновской вычислительной машины.
Основные положения, на которых основан принцип микропрограммного управления ОУ, заключаются в следующих пунктах :
Любая операция процессора рассматривается как сложное действие и разделяется на совокупность элементарных действий, называемых микрооперациями (МО). Выполнение каждой МО осуществляется специальной комбинационной схемой (КС) за один такт машинного времени;
Порядок выполнения МО задается алгоритмом операции и зависит от значений логических условий (ЛУ). ЛУ принимают значения истина или ложь в зависимости от резудьтатов операции. ЛУ используются в качестве условий альтернативных переходов в алгоритмах операций;
Алгоритм, представленный, записанный в терминах МО и ЛУ, называется микропрограммой (МП). МП задает порядок выполнения МО и проверки ЛУ во времени.
Совокупность микропрограмм реализует любую команду процессора.
Преимуществом микропрограммного управления ОУ является, легкость модернизации процессора, которая может заключаться в изменении кода имеющихся МП или внесением новых, расширяющих систему команд процессора. К недостаткам можно отнести увеличение времени выполнения команд, т.к. появляются дополнительные операции, обеспечивающие выполнение микропрограмм. Данный недостаток, с развитием элементной базы стал несущественным, т.к. достигнуто значительное увеличение быстодействия элементов СБИС.