

Особенности методов доступа
Физически последовательный метод. Записи хранятся в логической последовательности, файл имеет постоянный размер, указатели могут отсутствовать. Данные хранятся в главном файле, а обновление требует создания нового главного файла с упорядочением, для чего используется вспомогательный файл. Эффективность использования памяти близка к ста процентам, эффективность доступа низка.
Метод удобен для режима 1, однако быстродействие в режиме 2 мало: для его повышения необходимо использовать бинарный поиск (B- и B+-деревья). Время включения и удаления записей значительно.
Индексно-последовательный метод. Индексный файл упорядочен по первичному ключу (главному атрибуту физической записи). Индекс является разреженным, индексный файл (рис. 5.9) содержит ссылки не на каждую запись, а на группу записей Последовательная организация индексного файла допускает, в свою очередь, его индексацию (многоуровневая индексация). Процедура добавления возможна в двух видах.
Новая запись запоминается в отдельном файле (области), называемом областью переполнения. Блок этой области связывается в цепочку с блоком, которому логически принадлежит запись. Запись вводится в основной файл.
Если места в блоке основного файла нет, запись делится пополам и в индексном файле создается новый блок.
Наличие индексного файла большого размера снижает эффективность доступа. В большой БД основным параметром становится скорость выборки первичных и вторичных ключей. При большой интенсивности обновления данных следует периодически проводить реорганизацию БД. Эффективность хранения зависит от размера и изменяемости БД, а эффективность доступа - от числа уровней индексации, распределения памяти для хранения индекса, числа записей в БД, уровня переполнения.
При произвольных методах записи физически располагаются произвольно.
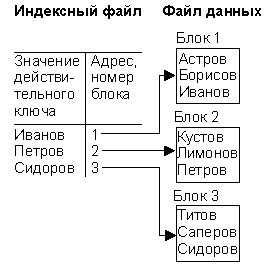
Рис.5.9. Схема организации индексно-последовательного метода
Индексно-прямой метод. В этом случае индексный файл (рис. 5.10) содержит плотный индекс, при котором каждой записи основного файла запись (индекс) в индексном файле. Записи хранятся в произвольном порядке. Создается отдельный файл, хранящий значение действительного ключа и физического адреса (индекса).
|
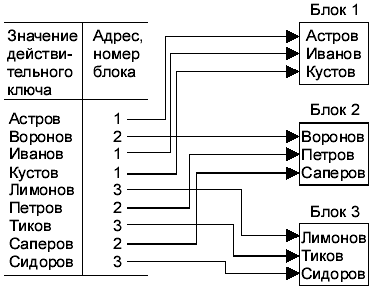
Рис. 5.10. Схема организации индексно-прямого метода доступа
Прямой метод. Имеется взаимнооднозначное соответствие (рис. 5.11) между ключом записи и ее физическим адресом.

Рис. 5.11. Схема организации прямого метода доступа
В этом методе необходимо преобразование и надо четко знать исходные данные и организацию памяти. Ключи должны быть уникальными.
Эффективность доступа равна 1, а эффективность хранения зависит от плотности ключей. Если не требовать взаимной однозначности, то этот метод называется метод с использованием хеширования - быстрого поиска данных, особенно при добавлении элементов непредсказуемым образом на основе хеш-функции. Хеширование - метод доступа, обеспечивающий прямую адресацию данных путем преобразования значений ключа в относительный или абсолютный физический адрес. Адрес является функцией значения поля и ключа записи. Записи, приобретающие один адрес, называются синонимами. В качестве критериев оптимизации алгоритма хеширования могут быть: потеря связи между адресом и значением поля, минимум синонимов. Память делится на страницы определенного размера, и все синонимы помещаются в пределах одной страницы или в область переполнения. Механизм поиска синонимов - цепочечный. Любой элемент хеш-таблицы имеет особый ключ, а само занесение осуществляется с помощью хеш-функции, отображающей ключи на множество целых чисел, которые лежат внутри диапазона адресов таблицы.
Хеш-функция должна обеспечивать равномерное распределение ключей по адресам таблицы, однако двум разным ключам может соответствовать один адрес. Если адрес уже занят, возникает состояние, называемое коллизией, которое устраняется специальными алгоритмами: проверка идет к следующей ячейке до обнаружения своей ячейки. Элемент с ключом помещается в эту ячейку.
Для поиска используется аналогичный алгоритм: вычисляется значение хеш-функции, соответствующее ключу, проверяется элемент таблицы, находящийся по указанному адресу. Если обнаруживается пустая ячейка, то элемента нет.
Размер хеш-таблицы должен быть больше числа размещаемых элементов. Если таблица заполняется на шестьдесят процентов, то, как показывает практика, для размещения нового элемента проверяется в среднем не более двух ячеек. После удаления элемента пространство памяти, как правило, не может быть использовано повторно.
Бинарное дерево является разновидностью B-дерева. B-дерево допускает более двух ветвей, исходящих из одной вершины. Любая вершина состоит из совокупности значений первичного ключа, указателей индексов и (ассоциированных) данных. Указатель индекса используется для перехода на следующий, более низкий уровень вершин. «Хранимые» в вершине данные фактически представляют собой совокупность указателей данных и служат для физической организации данных, определения положения данных, ключевое значение которых хранится в этой вершине индекса. Физическая организация ветвящейся вершины B-дерева подобна физической последовательной структуре. Этот метод дает хорошее использование памяти, обладает малым числом подопераций. Включение и удаление данных достаточно просто и эффективно.
Более распространенным вариантом B-дерева является B+-дерево. Здесь возможно использовать двунаправленные указатели, а в промежуточных вершинах имеет место дублирование ключей. Если происходит деление вершины, то в исходную вершину пересылается значение среднего ключа. Фактически B+-дерево есть индекс (указатель всех записей файла) вместе с B-деревом, как многоуровневым указателем на элементы последнего индекса.