

Технология индексирования данных.
Одна из важнейших задач физического проектирования реляционной базы данных состоит в том, чтобы дать гарантию того, что база данных обеспечивает требуемый уровень производительности.
Индексирование (indexing) - это способ обеспечения быстрого доступа к значениям столбца или комбинации столбцов. Физически новые строки добавляются в конец таблицы, результатом чего становится неупорядоченное размещение значений в столбце. Без использования каких-либо методов упорядочения данных единственным способом просмотра значения столбца со стороны СУБД является последовательный просмотр каждой строки от начала таблицы к ее концу, так называемое сканирование таблицы. Производительность такого сканирования пропорционально размеру таблицы, размеру физической страницы базы данных и длине строки. Одним из способов внесения отношения порядка в значения колонок без нарушения физического расположения строк таблицы является создание объекта реляционной СУБД - индекса (index). Индекс - это объект в реляционной базе данных, который предназначен для организации быстрого доступа к строкам таблицы по значениям одного или более столбцов этих строк.
Концептуально действие индекса состоит в следующем. В индексе содержится упорядоченный список значений столбца или комбинации столбцов, а также сведения о местонахождении на жестком диске соответствующих этим значениям строк таблицы. Значения столбца в индексе упорядочены. Несмотря на то, что порядок строк в таблице случаен, индекс можно быстро просмотреть, чтобы найти конкретное значение. Упорядоченный индекс можно просмотреть во много раз быстрее, чем неупорядоченную таблицу. Чем выше степень различия значений ключа в столбце, тем быстрее будет выполняться доступ к строкам этой таблицы.
Так при вставке новой записи в таблицу проверка уникальности первичного ключа реализуется не реальным просмотром индекса, а тем, что требование уникальности предъявляется к значениям колонки первичного ключа в индексе. Таким образом, индекс - это объект базы данных, который может существенно сократить время поиска нужных строк в таблице.
Замечание. После того как вы создали индекс, оптимизатор СУБД будет использовать его всякий раз, когда это ускоряет считывание данных.
Индексы, несомненно, занимают место в базе данных. При вводе новых данных или удалении данных СУБД приходится обновлять и таблицы, и индексы. Это может замедлить выполнение операций модификации данных, особенно для таблиц с большим числом строк. Таким образом, может возникнуть проблема, суть которой состоит в возникновении конфликта между скоростью обновления данных в таблице и скоростью ее считываний. При разрешении этой проблемы следует придерживаться следующего эмпирического правила: создавайте индексы для колонок первичных ключей и других колонок, часто используемых в тех запросах, в которых для выборки данных применяются логические критерии. Если в результате скорость обновления данных ухудшается, то можно рассмотреть вопрос об удалении некоторых индексов.
Каждая таблица базы данных может иметь один или несколько индексов. Индексы могут создаваться по одному столбцу или нескольким столбцам таблицы. Столбцы, входящие в индекс, принято называть ключевыми полями (key fields) или ключами. Индексы могут быть уникальными и неуникальными. Неуникальный индекс может иметь несколько ключей с одинаковыми значениями.
Значения индексируемого столбца упорядочиваются (чаще всего, по возрастанию). Индекс обычно хранится в отдельном файле или отдельной области памяти. Пустые значения атрибутов (null) не индексируются.
Зачем создавать индекс для столбца или группы столбцов? Это важный вопрос, и мы на него можем ответить следующим образом:
чтобы ускорить поиск в таблицах (об этом мы только что говорили выше);
чтобы обеспечить уникальное значение в столбцах;
чтобы извлекать строки в заданном порядке на основании значений индексированных столбцов (эта мысль оправдана только для очень больших таблиц, когда использование предложения ORDER дает ухудшение производительности).
Хорошими кандидатами для индексирования обычно являются:
столбцы первичного ключа. По определению, столбцы первичного ключа должны иметь уникальный индекс;
столбцы внешнего ключа. Они дают хороший индекс по двум причинам. Во-первых, они часто применяются для выполнения соединений с родительскими таблицами. Во-вторых, они могут быть использованы СУБД при поддержке ссылочной целостности в операциях удаления строк родительской и дочерних таблиц;
любые столбцы, которые содержат уникальные значения;
столбцы, запросы или соединения по которым захватывают от 5 до 10% строк таблицы;
столбцы, которые часто входят как аргументы в функции агрегирования;
столбцы, которые часто используются для проверки правильности ввода данных в программах ввода/редактирования.
Факторы, влияющие на низкую эффективность индексов:
Таблицы маленького размера. Одним из общих эмпирических правил является правило "не создавать индексы для таблиц размером менее пяти физических страниц". Для таких страниц стоимость поддержки индекса больше, чем стоимость сканирования всей таблицы. Конечно, уникальный индекс требуется для первичного ключа и поддержки ссылочной целостности.
Интенсивные обновления таблиц в пакетном режиме. Такие таблицы обычно имеют проблемы с переполнением индекса при интенсивной модификации таблицы. Если индекс необходим для такой таблицы, то целесообразнее его удалять перед обновлением и создавать после него.
Плохими кандидатами для индексирования обычно являются:
столбец имеет много неопределенных значений (NULL-значения). В этом случае неопределенные значения могут дать значительную асимметрию распределения значений столбца, несмотря на то, что кардинальность колонки будет подходящей для использования индекса;
столбцы с часто изменяемыми значениями. Индекс для таких столбцов часто обновляется, что приводит к его переполнению, поскольку в большинстве алгоритмов обработки B-Tree индексов физическая страница индекса становится доступной для распределения данных только после того, как из нее будут удалена последняя запись. В частности, это обстоятельство приводит к созданию дополнительных страниц индекса и уровней индекса;
значительная длина индексных колонок. Составной индекс или индекс для одного столбца с длиной более чем 50 байт будет приводить к росту числа уровней индекса, несмотря на то, что строк в таблице может быть немного. Большое число уровней снижает производительность операций выборки строк через индекс, т.к. каждый уровень требует по крайней мере одной операции ввода/вывода.
Принимая решение об индексировании, проектировщику базы данных следует соблюдать следующие общие правила при создании индексов.
Должно быть в наличии ограничение PRIMARY KEY.
Не следует создавать для таблицы несколько составных индексов, содержащих одни и те же колонки, но в другом порядке.
Обращение к записи через индексы осуществляется в два этапа: сначала в индексной структуре находится требуемое значение атрибута и соответствующий адрес записи, затем по этому адресу происходит обращение к внешнему запоминающему устройству (ВЗУ). Индекс загружается в ОП целиком (или хранится в ней постоянно во время работы с БД).
В том случае, если каждому значению индекса соответствует уникальное значение ключа, такой индекс называется первичным. Если же индекс строится по ключу, допускающему дубликаты значений, такой индекс называется вторичным. Для каждой БД можно одновременно поддерживать несколько первичных и вторичных индексов, что также относится к достоинствам индексирования.
Различают одиночные индексы и составные. Составной индекс включает два или более столбца одной таблицы. Последовательность вхождения столбцов в индекс определяется при создании индекса.
В
поле ключа индексного файла можно
хранить значения ключевых полей
индексируемой таблицы либо свертку
ключа (так называемый хеш-код). Преимущество
хранения хеш-кода вместо значения
состоит в том, что длина свертки независимо
от длины исходного значения ключевого
поля всегда имеет некоторую постоянную
и достаточно малую величину (например,
4 байта), что существенно снижает время
поисковых операций. Недостатком
хеширования является необходимость
выполнения операции свертки (требует
определенного времени), а также борьба
с возникновением коллизий (свертка
различных значений может дать одинаковый
хеш-код).
На
практике чаще всего используются два
метода поиска:
![]() последовательный
бинарный
(основан на делении интервала поиска
пополам).
Проиллюстрируем
организацию индексирования таблиц
двумя схемами: одноуровневой и
двухуровневой. При этом примем ряд
предположений, обычно выполняемых в
современных вычислительных системах.
Пусть ОС поддерживает прямую организацию
данных на магнитных дисках, основные
таблицы и индексные файлы хранятся в
отдельных файлах. Информация файлов
хранится в виде совокупности блоков
фиксированного размера, например, целого
числа кластеров.
.
Существует
множество способов организации индексов:
последовательный
бинарный
(основан на делении интервала поиска
пополам).
Проиллюстрируем
организацию индексирования таблиц
двумя схемами: одноуровневой и
двухуровневой. При этом примем ряд
предположений, обычно выполняемых в
современных вычислительных системах.
Пусть ОС поддерживает прямую организацию
данных на магнитных дисках, основные
таблицы и индексные файлы хранятся в
отдельных файлах. Информация файлов
хранится в виде совокупности блоков
фиксированного размера, например, целого
числа кластеров.
.
Существует
множество способов организации индексов:
1. В плотных индексах для каждого значения ключа имеется отдельная статья индекса, указывающая место размещения конкретной записи. Неплотные индексы строятся в предположении, что на каждой странице памяти (или в блоке) хранятся записи, отсортированные по значениям ключа индексирования. Тогда для каждой страницы индекс задаёт диапазон значений ключей хранимых в ней записей, и поиск записи осуществляется среди записей на указанной странице.
2. Для больших индексов актуальна проблема сжатия ключа. Наиболее распространенный метод сжатия основан на устранении избыточности хранимых данных. Последовательно идущие значения ключа обычно имеют одинаковые начальные части, поэтому в каждой статье индекса можно хранить не полное значение ключа, а лишь информацию, позволяющую его восстановить из известного предыдущего значения.
3. Одноуровневый индекс представляет собой линейную совокупность значений одного или нескольких полей записи. На практике он используется только в простейших случаях, когда количество индексируемых записей невелико. В более сложных случаях индекс занимает много памяти (иногда – несколько страниц), и возникает задача минимизации доступа к нему. Тогда индекс разбивается на несколько иерархических уровней, что позволяет ускорить поиск требуемого значения.
4.Особенно эффективной является организация многоуровневых индексов в виде сбалансированных деревьев (balance trees, B-деревьев), в которых все пути от корня к листьям имеют одинаковую длину.
Индекс на основе сбалансированной иерархической структуры, или индекс B-Tree (Balanced Tree structured object), используется как индекс по умолчанию в СУБД Oracle. Эта структура напоминает дерево (если смотреть снизу вверх), в котором сначала считывается самый верхний блок - корневой узел (root), затем блок на следующем уровне - блок-ветвь (branch) и так до тех пор, пока не будет извлечен блок-лист (leaf) с идентификатором строки. Значения ключа сохраняются в индексе (рис.1). Такая структура позволяет сократить до минимума число операций ввода/вывода. Для получения идентификатора строки обычно требуется одно посещение блок-листа, т.е. физической страницы базы данных, отведенной под индекс.
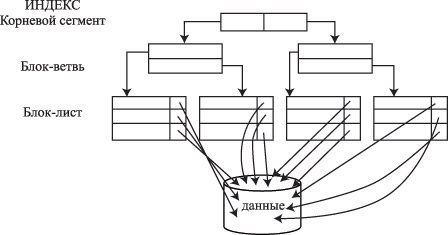
Рис.1. Концептуальная организация B-Tree индекса
Индекс B-Tree характеризуется количеством уровней в индексе (height). Чем меньше уровней, тем выше производительность.
Индекс B-Tree - это физический объект реляционной базы данных, организованный по принципу сбалансированной иерархической структуры и обладающий набором свойств. Значения колонок NULL не индексируются. Если для таких колонок строится индекс, то СУБД будет отказываться примерять его в некоторых операциях, например ORDER BY.
Блоки В – дерева организованы в виде древовидного графа. В – дерево является сбалансированным т.к. длины всех путей от корневой вершины до любой из вершин листьев равны. Типичное В – дерево содержит три уровня: корневую вершину, промежуточную вершину и листья, хотя способно включать и промежуточное количество уровней. Каждый блок В – дерева обладает пространством достаточным для размещения n значений ключа и n+1 указателей.
В В – дереве ключевые значения, указанные в вершинах листьях, являются копиями ключей записей файла данных. Ключи распределены по вершинам листьям слева направо в порядке возрастания значений.













В системах, поддерживающих язык SQL, индекс создаётся командой CREATE INDEX. Индексы повышают производительность запросов, которые выбирают относительно небольшое число строк из таблицы. Для определения целесообразности создания индекса нужно проанализировать запросы, обращённые к таблице, и распределение данных в индексируемых столбцах.
Главная причина повышения скорости выполнения различных операций в индексированных таблицах состоит в том, что основная часть работы производится с небольшими индексными файлами, а не с самими таблицами. Наибольший эффект повышения производительности работы с индексированными таблицами достигается для значительных по объему таблиц. Индексирование требует небольшого дополнительного места на диске и незначительных затрат процессора на изменение индексов в процессе работы. Индексы в общем случае могут изменяться перед выполнением запросов к БД, после выполнения запросов к БД, по специальным командам пользователя или программным вызовам приложений.