

Ответы на вопросы по дисциплине «Базы данных»
Оглавление
6. Запросы в реляционной СУБД 20
7. Распределенные информационные системы. Технология файлового сервера. 26
8. Понятие атрибута. Ключи и ключевые атрибуты. 27
9. Технологии и модели «клиент-сервер». 28
10. Проектирование БД фактографических АИС. 30
11. Распределенные информационные системы (РИС), основные понятия. 32
12. Понятие транзакции. Проблемы обновления таблиц-отношений. 38
13. Документальные информационные системы 40
14. Администрирование базы данных. 45
15. Реляционная модель данных. Понятие первой нормальной формы. 46
16. Реляционная модель данных. Понятие второй нормальной формы. 47
17. Реляционная модель данных. Понятие третьей нормальной формы. 48
18. Распределенные информационные системы. Технология сервера базы данных (DBS). 49
19. Распределенные информационные системы. Технология удаленного доступа к данным (RDA). 51
20. Распределенные информационные системы. Технология сервера приложений (AS). 52
21. Понятие полноты и точности информационного поиска. 53
22. Понятие релевантности и пертинентности в документальных ИПС. 55
23. Способы описания предметной области. ER модели. 57
1. Функции, классификация и структура СУБД.
Основные функции СУБД:
1.Управление данными во внешней памяти (на съемных дисках).
2.Управление данными в оперативной памяти.
3.Управление транзакциями.
4.Журнализация, применяемая при восстановлении программы после сбоя.
5.Поддержка языков БД (Язык определения и манипулирования данных)
1.Управление данными во внешней памяти.
Включает обеспечение необходимой структуры данных во внешней памяти, как для хранения непосредственно данных, так и для служебных целей, например организация индексов для ускорения доступа к данным. В одних СУБД активно используется возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. В развитых СУБД пользователи не обязаны знать как организованы файлы. В частности СУБД поддерживает собственную системы именования объектов.
2.Управление данными в оперативной памяти.
СУБД обычно работает с БД большого размера, которая больше чем оперативная память => при обращении к любому элементу данных будет производиться общение с внешней памятью и будет работать со скоростью внешних устройств. Единственный способ повысить скорость работы – буферизация оперативной памяти, поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной заменой.
3.Управление транзакциями.
Транзакция – это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД.
Поддержание механизма транзакций есть обязательное условие даже в однопользовательской СУБД. Но понятие транзакции гораздо существеннее для многопользовательских СУБД.
При соответствующем управлении каждой СУБД, каждый пользователь может ощущать себя единственным. Существует 2 типа систем обработки транзакциями: OLTP, OLAP
Система OLTP (On-Line Transaction Process – оперативная обработка транзакций) – Обработка транзакций используется в режиме реального времени и рассчитана на быстрое обслуживание большого числа пользователей, так же для защиты от несанкционированного доступа, нарушении целостности, сбоев. Применяются в банковских, биржевых системах и т.д.
Система OLAP (On-Line Analysis Process – оперативная аналитическая обработка) – рассчитаны на выполнение более сложных запросов требующих статистической обработки данных, накопленных за определенный промежуток времени, моделирование процессов предметной области, прогнозирование явлений. Эти аналитические системы часто включают средства обработки информации на основе искусственного интеллекта, используя при этом большой объем исторических данных.
Транзакция в OLTP системах должна обладать 4-мя свойствами: АСИД
Атомарность – транзакция выполняется как единая операция доступа к БД (принцип «все или ничего»).
Согласованность –обеспечивается ограничениями на данные, после окончания транзакции БД должна оставаться целостной.
Изолированность – транзакции выполняются отдельно друг от друга.
Долговечность – значит, если транзакция выполнена успешно, то изменения не будут потеряны ни при каких обстоятельствах.
Это и есть АСИД-транзакции.
4.Журнализация. Это надежность СУБД в хранении данных, т.е. способность восстанавливать последнее согласованное состояние БД после любого программного или аппаратного сбоя. Для этого ведется журнал (особая часть БД, в которую поступают данные об изменениях в основной части БД). Иногда поддерживаются 2 копии журнала и хранятся на разных винчестерах. Изменения в журнале производятся, до изменения в БД (WAL-протокол). После сбоя используется журнал и архивная копия БД (полная копия БД к началу заполнения БД). По журналу производятся все транзакции до момента сбоя.
5.Поддержка языков БД. Таким языком является непроцедурный язык SQL.
Классификация СУБД
По степени универсальности СУБД делят на два класса: СУБД общего назначения (СУБД ОН) и специализированные СУБД (СпСУБД).
СУБД ОН не ориентированы на какую-либо предметную область или на конкретные информационные потребности пользователей. Каждая система такого рода является универсальной и реализует функционально избыточное множество операция над данными. СУБД ОН имеют в своем составе средства настройки на конкретную предметную область, условия эксплуатации и требования пользователей. Производство этих систем поставлено на широкую коммерческую основу.
Специализированные СУБД создаются в тех случаях, когда ни одна из существующих СУБД общего назначения не может удовлетворительно решить задачи, стоящие перед разработчиками, например, не достигается требуемое быстродействие обработки или не обеспечивается поддержка необходимого объёма данных. СпСУБД предназначены для решения конкретной задачи, а приемлемые параметры этого решения достигаются:
за счёт знания особенностей конкретной предметной области,
путём сокращения функциональной полноты системы.
Создание СпСУБД – дело весьма трудоемкое, поэтому для того, чтобы выбрать этот путь, надо иметь действительно веские основания. В дальнейшем будут рассматриваться только СУБД общего назначения.
По модели данных различают иерархические, сетевые, реляционные и объектно-ориентированные СУБД.
По методам организации хранения и обработки данных СУБД делят на централизованные и распределённые. Первые работают с БД, которая физически хранится в одном месте (на одном компьютере). Это не означает, что пользователь может работать с БД только за этим же компьютером: доступ может быть удалённым (в режиме клиент–сервер). Большинство централизованных СУБД перекладывает задачу организации удаленного доступа к данным на сетевое обеспечение, выполняя только свои стандартные функции, которые, естественно, усложняются за счёт одновременности доступа многих пользователей к данным.
По мощности
В настоящее время наибольшее распространение получили реляционные СУБД трех групп:
Мощные крупные коммерческие СУБД, ориентированные на хранение огромных объемов информации (от гигабайт). Наиболее известными СУБД в этой группе являются: Oracle (Oracle Corp.), Ingres (Computer Associates International), Sybase SQL server (Sybase Inc.).
Мобильные компактные свободно распространяемые СУБД, использование которых оправдано и для БД объемом всего лишь в десятки килобайт. К наиболее популярным СУБД этой группы относятся: PostgreSQL (организации PostgreSQL), mySQL (T.C.X. DataKonsult AB), Microsoft SQL Server (Microsoft).
Настольные персональные СУБД, ориентированные на простые варианты построения БД, решение менее сложных задач, на персональные компьютеры и, на меньшие объемы и сравнительно простую структуру данных. К настольным СУБД относятся: Access, входящая в состав пакета Microsoft Office и рассчитанная на одного пользователя; Visual FoxPro.
СУБД первых двух групп построены по принципу «клиент-сервер».
Обычно современная СУБД содержит следующие компоненты (рис. 6.2):
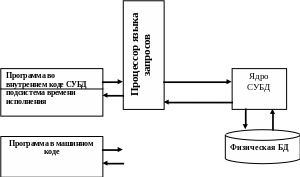
Рисунок 6.2 Схема СУБД
ядро (часто его называют Data Base Engine), которое отвечает за управление данными во внешней и оперативной памяти и журнализации;
процессор языка запросов (компилятор языка БД, обычно SQL), обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание машинно-независимого внутреннего кода;
подсистему поддержки времени выполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
набор утилит.
В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно, можно выделить такие компоненты ядра (по крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала. Функции этих компонентов взаимосвязаны, и для обеспечения корректной работы СУБД все эти компоненты должны взаимодействовать по тщательно продуманным и проверенным протоколам. Ядро СУБД обладает собственным интерфейсом, не доступным пользователям напрямую и используемым в программах, производимых компилятором SQL (или в подсистеме поддержки выполнения таких программ) и утилитах БД. Ядро СУБД является основной резидентной частью СУБД. При использовании архитектуры «клиент-сервер» ядро является основной составляющей серверной части системы.
Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Серьезной проблемой реляционных СУБД является то, что языки этих систем (а это, как правило, SQL) являются непроцедурными, т.е. в операторе такого языка специфицируется некоторое действие над БД, но эта спецификация не является процедурой, а лишь описывает в некоторой форме условия совершения желаемого действия. Поэтому компилятор должен решить, каким образом выполнять оператор языка прежде, чем произвести программу. Применяются достаточно сложные методы оптимизации операторов. Результатом компиляции является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка.
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и выгрузка БД, сбор статистики, глобальная проверка целостности БД и т.д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
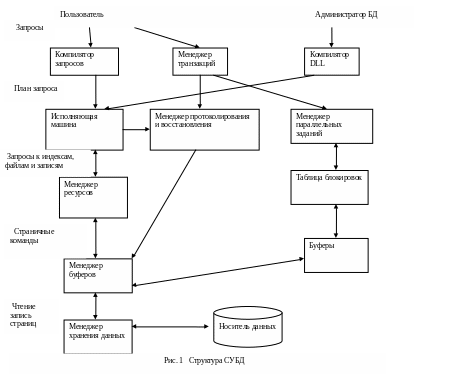
Получение = Менеджер ресурсов
Хранение = Менеджер хранения
Обработка = обработка Транзакций + обработка Запросов
Менеджер транзакций =
менеджер протоколирования и восстановления +
менеджер параллельных заданий (планировщик заданий)
Обработку запросов осуществляет процессор запросов, представленный в СУБД двумя компонентами - компилятор запросов и исполняющая машина
Компилятор запросов транслирует запрос во внутренний формат системы – план запроса (анализатор (древовидная структуру данных) препроцессор (дерево алгебраических операторов) оптимизатор (эффективная последовательность фактических операций над фактическими данными))
Исполняющая машина (несет ответственность за выполнение каждой из операций, предусмотренных планом запроса) направляет запрос на получение данных менеджеру ресурсов, который осведомлен об особенностях размещение информации в файлах (часто хранимых на устройствах внешней памяти). Далее запрос пересылается менеджеру буферов, который ответственен за разбиение свободной оперативной памяти на блоки для переноса в них информации. Менеджер хранения данных определяет положение файлов на диске.
Обычной практикой при обработке данных является оформление операций над БД в виде транзакций.
С целью удовлетворения требования долговечности (устойчивости) каждое изменение в БД фиксируется в специальных файлах (протоколах), которые изначально сохраняются в буфере. Менеджер протоколирования взаимодействует с менеджером буферов, чтобы убедиться, что содержимое буфера сохранено на диске. Менеджер восстановления в случае возникновения системных сбоев способен считать протокол изменений и привести БД в согласованное (устойчивое) состояние.
Транзакции должны выполняться изолированно друг от друга, но в реальных системах одновременно могут быть задействованы несколько процессов транзакций. Менеджер параллельных заданий должен обеспечить такой режим работы системы, чтобы результат выполнения пересекающихся во времени транзакций был таким же, как если бы транзакции инициировались, выполнялись и завершались в строгой очередности. Это достигается установлением блокировки на соответствующие фрагменты содержимого БД.
Признаки блокировок хранятся в таблице блокировок. Менеджер параллельных заданий запрещает управляющей машине обращаться к заблокированным порциям данных. Возможна ситуация, когда ни одна из транзакций не в состоянии продолжать работу в связи с тем, что необходимый ей ресурс блокирован (ситуация взаимоблокировок). Менеджер транзакций вмешивается в ситуацию и прерывает (откатывает назад) работу одной или нескольких транзакций, чтобы позволить остальным продолжать работу.