Сравнение производительности для выборки с условием
Рассмотрим более сложные запросы, когда появляется условие для выборки данных, и нахождение данных может быть более сложной задачей.

CREATE TABLE stress2 (id INT PRIMARY KEY , num int );
begin
for i in 0..3000000 loop
insert into stress2(id,num) values (i,mod(i,100));
end loop;
end;
create table stress2_index(id, num, primary key (id,num) )
organization index as select upper(num), rowid from stress2;
select stress2.* from stress2,stress2_index
WHERE stress2.rowid = stress2_index.num
and stress2_index.id>10
and stress2_index.id<30
and ROWNUM <= n;
Построим таблицу в Oracle SQL. В таблице поиск усложним выборкой строчек из разных частей памяти. Введем таблицу организованную по индексу (кластерный индекс) позволит располагать данные в базе друг за другом на физическом диске, что позволит облегчить нахождение данных в базе.
Теперь модифицируем java приложение, работающее с nosql базой:
Создадим схему, используя метод putConditionalMany()
Метод SelectWhereFullMajor дополним условием new KeyRange(start, true, end, true); что позволит нам выбирать только нужные ключи.
Дополним главный метод вызовом только что созданных функций nosql.putConditionalMany("test/stress2/-/", 100, 30000);
nosql.SelectConditionalWhereFullMajor("test/stress2/-/", "10", "30");
Сравнение производительности
На основании проведенных экспериментов были получены результаты, приведенные в таблице 2. В таблице приведены результаты, являющимся средним арифметическим значением десяти выборок для каждого из значений. Были посчитаны коэффициенты увеличения производительности введения nosql решения по формуле K = t(sql)/t(nosql) для каждого значения нагрузки.
На основании полученных данных были построены графики зависимости времени выполнения операторов select с дополнительным условием в зависимости от нагрузки, приведенные на графике 4.
Таблица 2 Сравнение масштабируемости sql и nosql
|
Select where |
||
count |
Nosql |
sql |
K |
1000 |
0,1 |
0,3 |
3 |
10000 |
0,25 |
3,2 |
12,8 |
50000 |
0,8 |
9,1 |
11,3 |
100000 |
1,9 |
17,4 |
9,1 |
150000 |
2,4 |
22,3 |
9,2 |
200000 |
4,8 |
34,1 |
7,1 |
250000 |
5,2 |
42,5 |
8,1 |
300000 |
7,7 |
51,9 |
6,7 |
400000 |
11,1 |
68,4 |
6,1 |
500000 |
12,9 |
84,6 |
6,5 |
800000 |
30,3 |
130,5 |
4,3 |
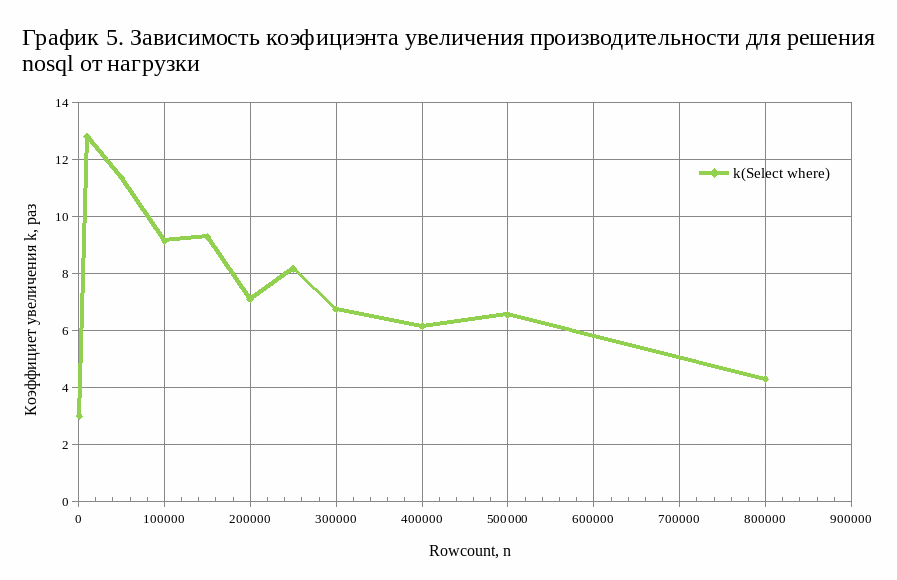
Построена зависимость коэффициента увеличения производительности для решения nosql от нагрузки, приведенная на графике 5. Определен коэффициент Kср = [6,1; 11,3], принимающих свое значение на выборках, соответствующих нагрузкам n = [10000, 500000]. Из полученных результатов видно, что в своей области метод multiGet() показывает результаты на порядок превосходящие, аналоги в реляционной базе данных. Следует отметить высокую погрешность для метода multiGet() c условием, составляющую 25%, в то в то время как для других методов погрешность не превышает 5%. В сравнении с предыдущем исследованием погрешность получилось ещё большей – это связано со спецификой расположения данных на диске при считывании данных из различных областей.