

Реализация виртуальных команд ввода-вывода
Чтобы понять, как реализуются виртуальные команды ввода-вывода, нужно понять, как файлы организуются и хранятся. Основной вопрос здесь — распределение памяти. Блоком размещения может быть один сектор на диске, но чаще он состоит из нескольких последовательных секторов.
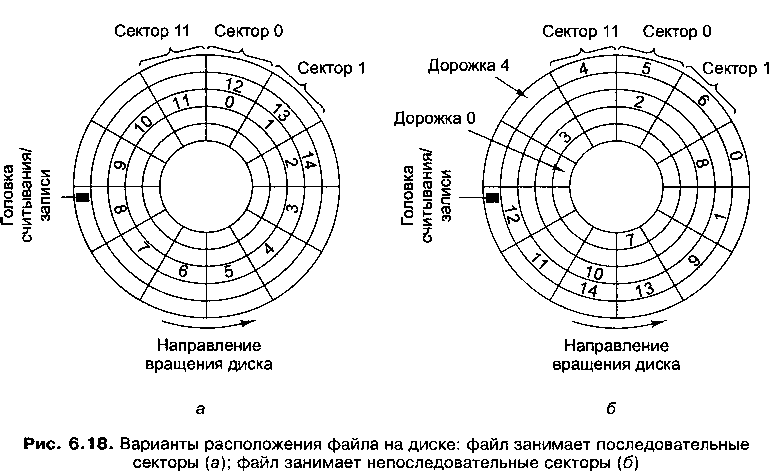
Еще одно фундаментальное свойство файловой системы — то, как располагаются блоки размещения, последовательно или нет. На рис. 6.18 изображен простой диск с одной поверхностью, состоящий из 5 дорожек по 12 секторов каждая. На рисунке 6.18, а файл состоит из последовательных секторов. Последовательное расположение блоков характерно для компакт-дисков. На рис. 6.18, б файл занимает непоследовательные секторы. Такая схема традиционна для жестких дисков.
Восприятие файла прикладным программистом значительно отличается от восприятия файла операционной системой. Программист воспринимает файл как линейную последовательность байтов или логических записей. Операционная система воспринимает файл как упорядоченную, хотя необязательно последовательную, совокупность блоков размещения на диске.
Для того чтобы операционная система по запросу могла доставить байт или логическую запись п из какого-то файла, она должна пользоваться каким-либо методом для определения местонахождения данных. Если файл расположен последовательно, чтобы вычислить позицию нужного байта или логической записи, операционная система должна знать только место начала файла.
Если файл расположен на диске не последовательно, то лишь по начальной позиции файла невозможно вычислить позицию произвольного байта или логической записи в этом файле. Чтобы найти произвольный байт или логическую запись, нужна таблица, называемая индексом файла и позволяющая получать хранящиеся на диске блоки и их физические адреса. Индекс файла может быть организован либо в виде списка адресов блоков (такая схема используется в UNIX), либо в виде списка логических записей, для каждой из которых даются адрес на диске и смещение. Иногда каждая логическая запись имеет ключ, и программы могут обращаться к записи по этому ключу, а не по номеру логической записи. В последнем случае каждый элемент таблицы должен содержать не только информацию о местонахождении записи на диске, но и ее ключ. Подобная структура обычно применяется в мэйнфреймах.
Альтернативный метод нахождения блоков размещения файла — организовать файл в виде связного списка. В этом случае каждый блок размещения содержит адрес следующего блока. Для реализации этой схемы нужно в основной памяти иметь таблицу со всеми последующими адресами. Например, для диска с 64-килобайтными блоками операционная система может иметь в памяти таблицу из 64 Кбайт элементов, в каждом из которых есть индекс следующего блока размещения. Так, если файл занимает блоки 4, 52 и 19, то элемент 4 в таблице будет содержать число 52, элемент 52 — число 19, а элемент 19 — специальный код, который указывает на конец файла (например, 0 или -1). Так работают файловые системы в MS-DOS, Windows 95 и Windows 98. ОС Windows ХР под-
держивает эту файловую систему, но имеет также собственную, которая больше похожа на файловую систему UNIX.
До сих пор мы говорили, что на диске файлы могут располагаться как последовательно, так и непоследовательно, но зачем нужны эти два варианта расположения мы еще не объяснили. Последовательными файлами лепсо управлять, но если максимальный размер файла заранее не известен, использовать эту технологию нельзя. Если файл начинается с сектора j и продолжается в направлении соседних секторов, он может наткнуться на другой файл в секторе k, тогда ему не хватит места на расширение. Если же файл располагается непоследовательно, то таких проблем не возникает, поскольку следующие блоки можно поместить в другое место на диске. Если диск содержит ряд «рабочих» файлов, конечные размеры которых могут меняться, записать их на диск в последовательные блоки размещения практически невозможно. Иногда можно переместить существующий файл, но это накладно.
В то же время, если максимальный размер всех файлов известен заранее (например, как бывает при создании компакт-диска), программа может определить последовательности секторов, точно равных по длине каждому файлу. Если файлы размером 1200, 700, 2000 и 900 секторов нужно поместить на компакт-диск, они просто могут начинаться с секторов 0, 1200, 1900 и 3900 соответственно (оглавление здесь не учитывается). Найти любую часть любого файла легко, поскольку известен первый сектор файла.
Чтобы выделить пространство на диске для файла, операционная система должна следить, какие блоки доступны, а какие уже заняты другими файлами. При записи на компакт-диск вычисление производится один раз и навсегда, а на жестком диске файлы постоянно записываются и удаляются. Один из способов отслеживать состояние диска — хранить список всех пустот (неиспользованных фрагментов), где пустой фрагмент может быть размером с любое число последовательных блоков размещения. Этот список называется списком свободной памяти (free list). На рис. 6.19, а изображен список свободной памяти для диска с рис. 6.18, б.
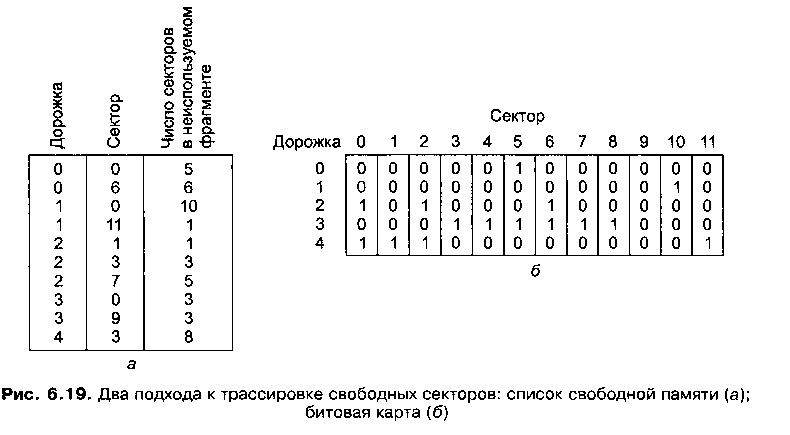
Альтернативный подход — хранить битовую карту диска (один бит на один блок размещения), как показано на рис. 6.19, б. Единичный бит показывает, что блок уже занят, а нулевой — что свободен.
Первый подход позволяет легко найти неиспользуемый фрагмент определенной длины. Однако у этого метода есть недостаток: по мере создания и уничтожения файлов размер списка будет меняться, а это нежелательно. Преимущество битовой карты состоит в том, что ее размер постоянен. Кроме того, для изменения статуса блока размещения (из свободного на занятый или наоборот) достаточно поменять значение всего одного бита. Однако при таком подходе трудно найти блок заданного размера. Оба метода требуют, чтобы при записи файла на диск или удаления файла с диска список размещения или карта обновлялись.
Перед тем как закончить обсуждение вопроса о реализации файловой системы, нужно сказать несколько слов о размере блока размещения. Здесь играют роль несколько факторов. Во-первых, тормозят доступ к диску время поиска и время, затрачиваемое на вращение диска. Если на нахождение начала блока тратится 10 мс, то гораздо выгоднее считать 8 Кбайт (это займет примерно 1 мс), чем 1 Кбайт (это займет примерно 0,125 мс), так как, если считывать 8 Кбайт как 8 блоков по 1 Кбайт, потребуется выполнять поиск 8 раз. Для повышения производительности нужны большие блоки размещения.
Чем меньше размер блока размещения, тем больше их должно быть. Большое количество блоков размещения, в свою очередь, влечет за собой длинные индексы файлов и большие структуры связных списков в памяти. Системе MS-DOS пришлось перейти на многосекторные блоки по той причине, что дисковые адреса хранились в виде 16-разрядных чисел. Когда размер дисков стал превышать 64 Кбайт секторов, представить их можно было, только используя блоки размещения большего размера, поэтому число таких блоков не превышало 64 Кбайт. В первом выпуске Windows 95 возникла та лее проблема, но в последующем выпуске уже использовались 32-разрядные числа. Windows 98 поддерживает оба варианта.
Маленькие блоки тоже имеют свои преимущества. Дело в том, что файлы очень редко занимают ровно целое число блоков размещения. Следовательно, практически в каждом файле в последнем блоке размещения останется неиспользованное пространство. Если размер файла значительно превышает размер блока размещения, то в среднем неиспользованное пространство составит половину блока. Чем больше блок, тем больше остается свободного пространства. Если средний размер файла намного меньше размера блока размещения, большая часть пространства на диске окажется неиспользованной. Например, в MS-DOS или в первой версии Windows 95 с 2-гигабайтным дисковым разделом размер блока размещения составляет 32 Кбайт, поэтому при записи на диск файла в 100 символов 32 668 байт дискового пространства теряются. С точки зрения распределения дискового пространства маленькие блоки размещения имеют преимущество над большими. В настоящее время самым важным фактором считается скорость передачи данных, поэтому размер блоков постоянно увеличивается.