

Вопрос 4. Модели данных..Многомерная Объектно-ориентированная модель.
1) Объектно-ориентированная модель.
Структура БД представлена в виде дерева, узлами которого являются объекты. Свойства объектов можно описать некоторым стандартным типом, либо типом, конструируемым пользователем (Class). Значением свойства стандартного типа являются непосредственно данные. Значение свойства типа class является объект, который определен как экземпляр соответствующего класса. Каждый экземпляр является потоком объекта, в котором он определен как свойства. Свойства экземпляра класса так же могут быть стандартными или конструированными.

Основные свейства:
1) инкапсуляция – ограничивает область видимости имени свойства пределами того объекта, в котором оно определено;
2) наследование – распределяет область видимости свойства на всех потомков объекта;
3) полиморфизм – возможность одного и того же программного кода работать с разнотипными данными в зависимости от аргумента.
Достоинства:
- возможность отображения сложных взаимосвязей объектов;
- возможность идентификации отдельной записи БД с определенными функциями ее обработки.
Недостатки:
- высокая понятийная сложность;
- низкая скорость выполнения запросов;
- неудобство оперативной обработки данных.
2) Многомерная модель.
Все информационные системы развиваются по двум направлениям:
- повышение оперативности обработки данных;
- возможность аналитической обработки данных (система принятия решений).
Реляционная СУБД предназначалась для оперативной обработки данных, и были и были в них весьма эффективны. Использование их для аналитической обработки является малоэффективным и громоздким. Поэтому многомерные СУБД предназначались для аналитической обработки данных и обладают следующими свойствами:
1) агрегируемость – возможность рассмотрения информации на разных уровнях ее обобщения;
2) историчность - высокий уровень статичности и неизменности данных, обязательна привязка во времени;
3) прогнозируемость - возможность использовать функции прогноза, и применение их к различным интервалам.

В соответствии с многомерной моделью данные представляются в виде многомерных гиперкубов. Понятия для гиперкубов:
1) измерение (Dimension) – множество однотипных данных, образующих одну из граней гиперкуба (Фамилии, семестры, года и т.д.);
2) яейка (Cell) – это поле, значение которого однозначно определяется фиксированным набором измерений.
Для гиперкубов определены ряд специальных операций, расширяющих его свойства:
1) срез (Slice) – представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений;
2) вращение (Rotate) – используется при двумерном представлении данных и заключается в изменении порядка измерений при визуально представлении данных;
3) агрегация (drill up) – переход к более общему представлению информации из гиперкуба;
4) детализация (drill down) – переход к более частному представлению данных.
Т.к. данные в гиперкубе обязательно привязаны ко времени, то часто используют очень подробное представление измерений, связанных со временем.
Развитие многомерных СУБД сдерживается 2-мя причинами:
1) проблема экспорта существующих данных (реляционных) в многомерных СУБД;
2) неэффективность использования многомерных СУБД для оперативной обработки данных.
Реляционная СУБД относится к системам оперативной обработки данных, но при выполнении операций анализа данных они являются очень слабыми. Реляционная модель не подходит для систем ОLАР - анализ данных в режиме реального времени. В таких системах используют два вида реляционных таблиц: множество измерений и одна таблица фактов.
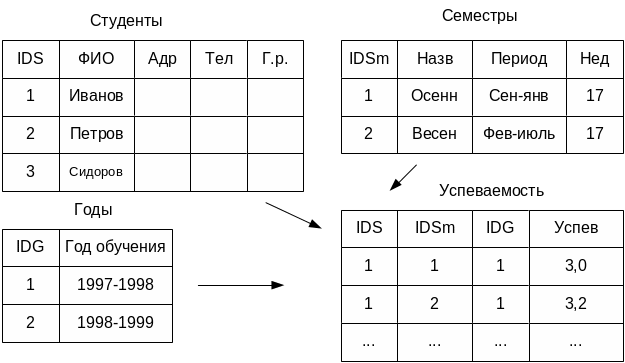
Заполнение подобных таблиц осуществляется простыми методами экспорта из существующих реляционных БД.
Достоинства:
- возможность и удобство аналитической обработки больших объемов данных;
- возможность создания хранилища данных
Недостатки:
- громоздкость при выполнении оперативной обработки данных.