

Сведение матричной игры к задачам линейного программирования. Приведите примеры.
Ответ:
Пусть
игрок А обладает матричными стратегиями
А1,…,Am,
игрок В – B1,…,Bn.
При этом платежная матрица имеет вид
P=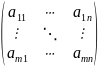 .
Необходимо определить оптимальные
стратегии для игрока А – SA*=(p1*,…,pm*),
и для игрока В – SB=(q1,…,qn).
При этом
.
Необходимо определить оптимальные
стратегии для игрока А – SA*=(p1*,…,pm*),
и для игрока В – SB=(q1,…,qn).
При этом
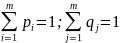 .
Оптимальная стратегия SA*
обеспечивает игроку А средний выигрыш,
не меньший чем цена игры ν при любой
стратегии игрока В и выигрыш, равный в
цене ν, при оптимальной стратегии игрока
В.
.
Оптимальная стратегия SA*
обеспечивает игроку А средний выигрыш,
не меньший чем цена игры ν при любой
стратегии игрока В и выигрыш, равный в
цене ν, при оптимальной стратегии игрока
В.
Для оптимальной стратегии SA* все средние выигрыши должны быть не меньше цены игры ν:
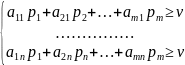
Пусть
 .
Поделим систему на
.
Поделим систему на
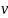
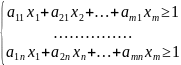
Цель
А – максимизировать выигрыш: νmax.
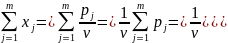 min
min
Получена ЗЛП f=x1+…+xm с ограничениями
Для определения оптимальной стратегии игрока В необходимо учесть, что он стремится минимизировать выигрыш А: νmin. ЗЛП: φ=y1+…+ymmax при тех же ограничениях
Матричная игра и взаимно двойственные задачи линейного программирования. Приведите примеры.
Ответ:
Принятие решений в условиях полной неопределенности. Критерии Вальда ,Сэвиджа, Гурвица, Лапласа.
Ответ: Для принятия решений в условиях полной неопределенности существуют 4 критерия:
1)
Критерий Вальда (принцип наибольшей
осторожности) – оптимальной будет та
стратегия, для которой достигается
значение W=
2) Критерий Сэвиджа (крайнего пессимизма) – оптимальной считается та стратегия, для которой минимизируется максимальный риск
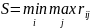
3)
Критерий Гурвица – оптимальна стратегия,
при которой достигается значение
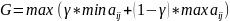
4)
Критерий Лапласа – все вероятности
состояния природы По
полагаются
равными qj=1/n.
Оптимальна стратегия, при которой
достигается значение L=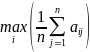
Постановка задачи динамического программирования. Состояния системы. Управление. Уравнение состояний. Поясните смысл отсутствия последействия в динамической системе.
Ответ: Рассмотрим динамическую систему, которая последовательно, за n
шагов, переходит из некоторого начального состояния s0 в конечное состояние sn. Промежуточные состояния si определяют состояния системы после i-ого шага. Как правило, состояния системы характеризуются несколькими числами, поэтому предполагается, что si являются векторами с m координатами, т.е. si=(si1,…, sim). Переход системы из состояния si-1 в состояние si определяется параметрами (управления) u1 (i=1,…,n) при помощи уравнений состояний si=Fi(si-1,ui), а эффективность каждого шага оценивается функциями fi(si-1,ui). Таким образом, эффективность всего процесса характеризуется суммой z0=f1(s0,u1)+f2(s1,u2)+…+fn(sn-1,un), а задача состоит в том, чтобы выбрать набор управлений u1,…,un, оптимизирующий z0: z0*=z0*(s0)=max z0
Процесс решения разбивается на n шагов, для этого введем функцию
zi(si)=fi+1(si,ui+1)+…+fn(sn-1,un), i=1,…,n-1, которая характеризует эффективность перехода от состояния si к sn. Последовательно оптимизируя zn-1(sn-1),…,z0(s0) по формулам
z*n-1(sn-1)=maxfn(sn-1,un)
z*n-2(sn-2)=max(fn-1(sn-2,un-1)+z*n-1(sn-1))
… … … … …
z*0(s0)=max(f1(s0,u1)+z1*(s1))
находим оптимальное решение задачи. Как видим, процесс решения задачи начинается с оптимизации последнего шага, что называется обратным ходом вычислений и свойственно многим задачам динамического программирования.